
記住我
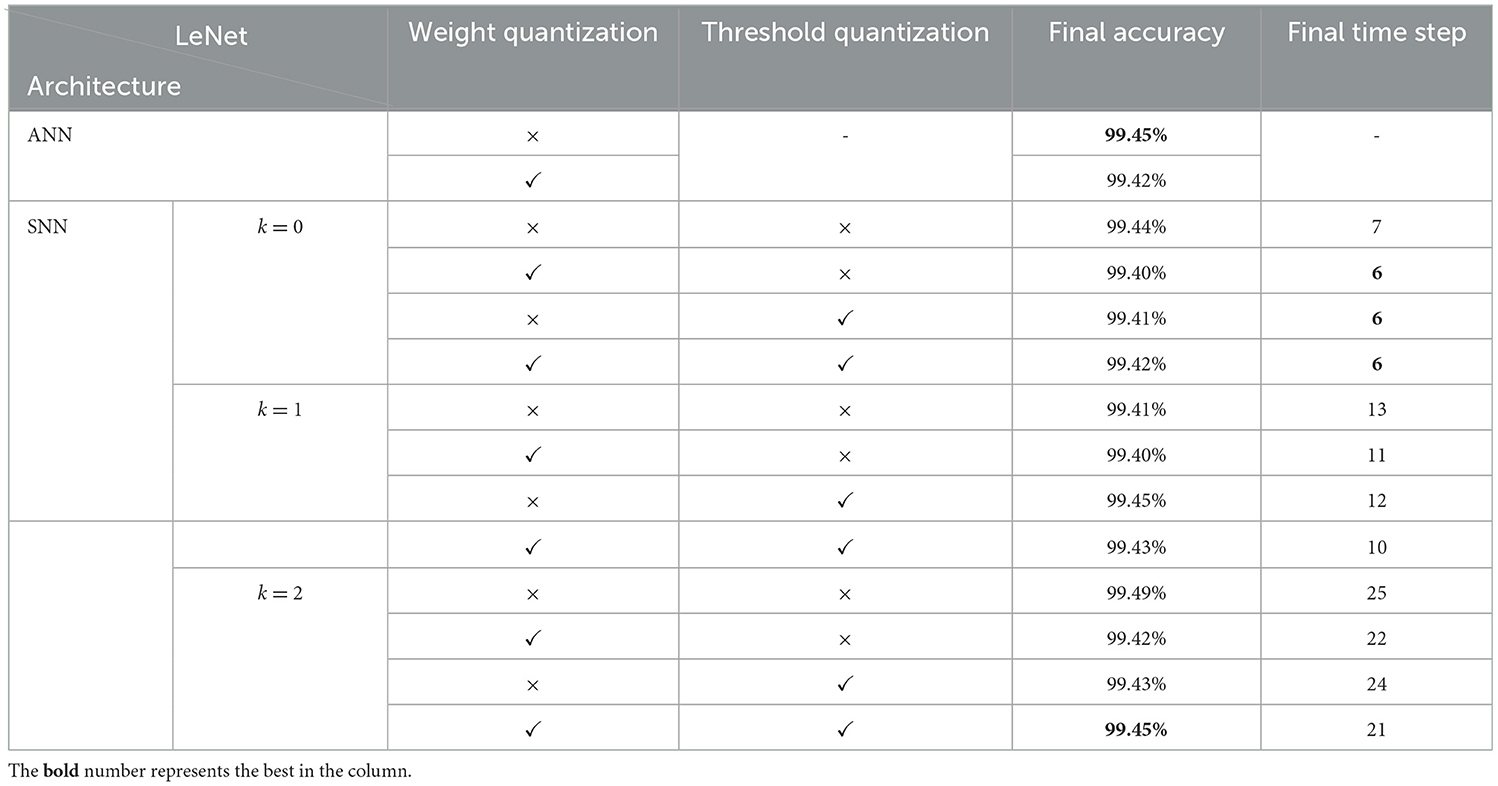
Table 1. Classification accuracy for LeNet of different configurations on MNIST.
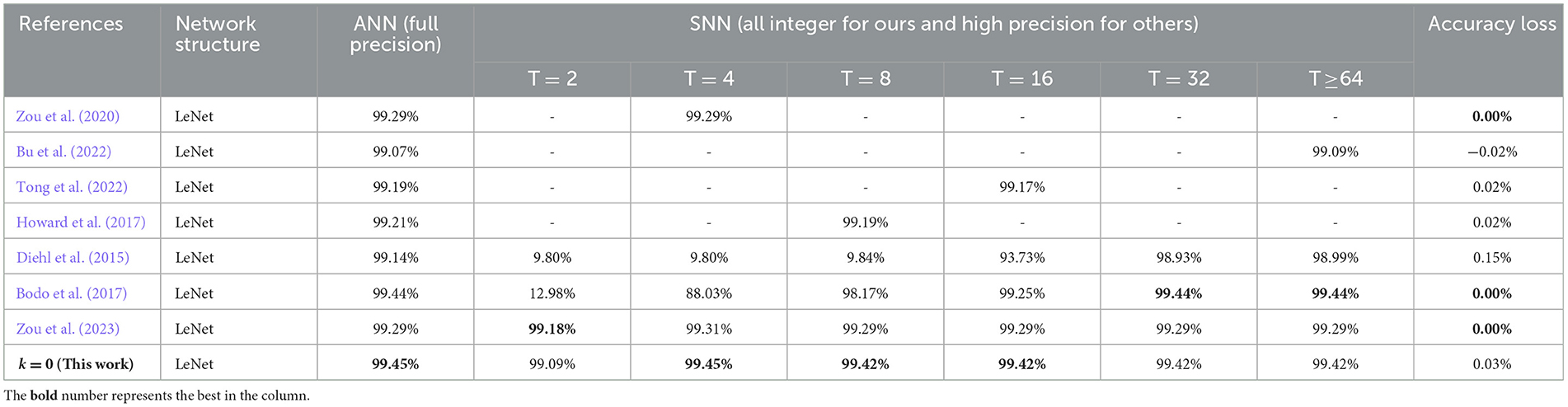
Table 2. Comparison for the proposed spiking LeNet on MNIST with other works.
4.2 Experiments on CIFAR-10CIFAR-10 (Krizhevsky and Hinton, 2009) is regarded as a more challenging real image classification dataset, which consists of total 60000 color images with 32 × 32 pixels. This dataset is divided into 50000 training images and 10000 test images with 10 classes. For this task, a VGG-Net (Simonyan and Zisserman, 2014) variant with 11 layers (96C3-256C3-2P2-384C3-2P2-384C3-256C3-2P2-1024C3-1024FC-10FC) is designed. No extra data augmentation technique is used other than standard random image flipping and cropping for training. Test evaluation is based solely on central 24 × 24 crop from test set.
Similarly, we give the ablation study results of different quantization configurations in Table 3 and compare the performance results with other works in Table 4. It also shows that higher quantization levels could bring slightly better accuracy while longer simulation time steps. Besides, the reported inference accuracy and speed of spiking VGG-Net in Table 4 indicates that our proposed conversion and quantization method can still maintain excellent performance (accuracy vs. speed) with the smallest accuracy loss for deeper VGG-Net with more than 10 layers and complex BN operations (Ioffe and Szegedy, 2015). Compared with many other high-precision SNN works, our proposed spiking models are all integer-based and show strong potential for direct implementation on some dedicated hardware.
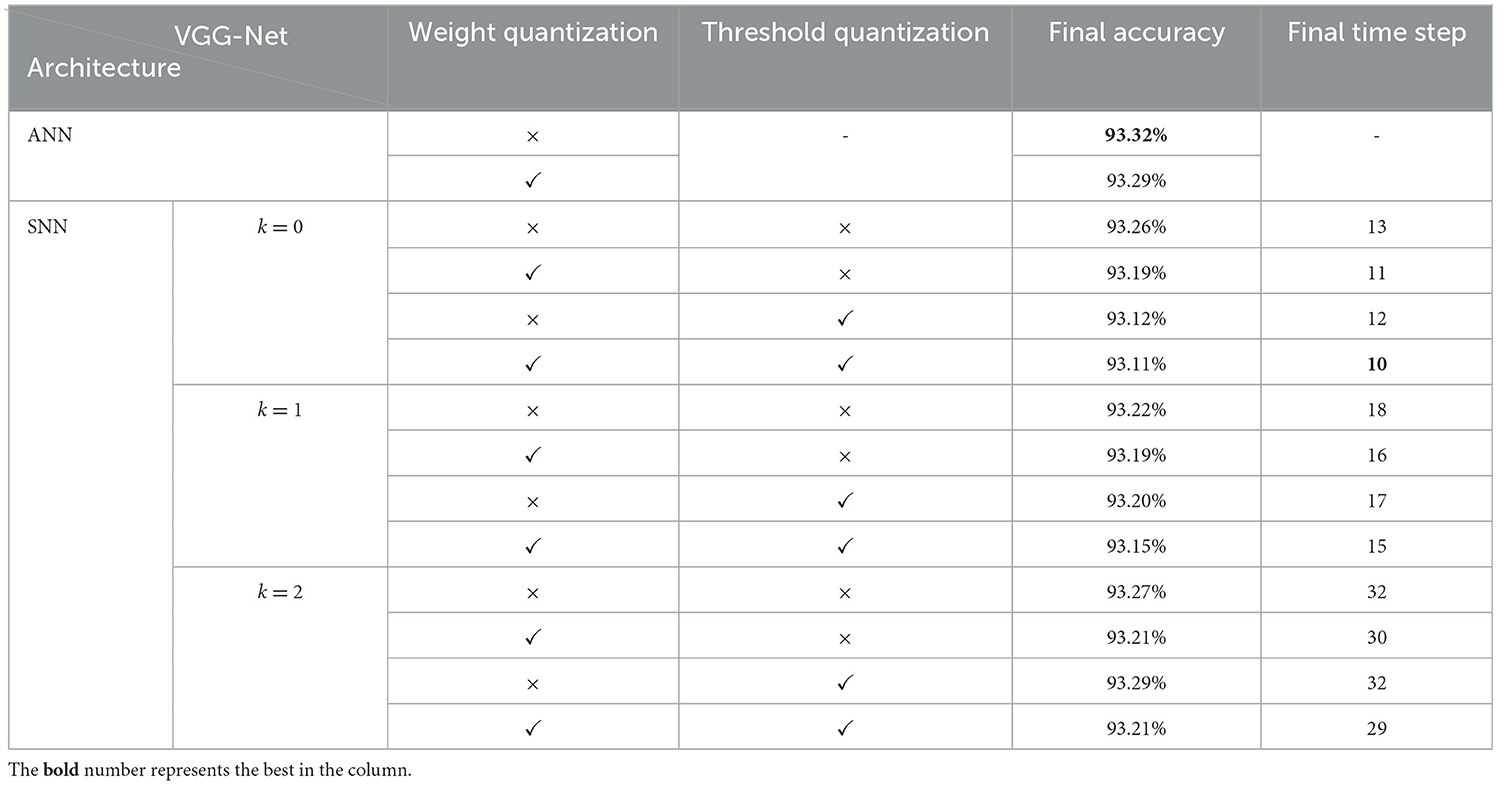
Table 3. Classification accuracy for VGG-Net of different configurations on CIFAR-10.
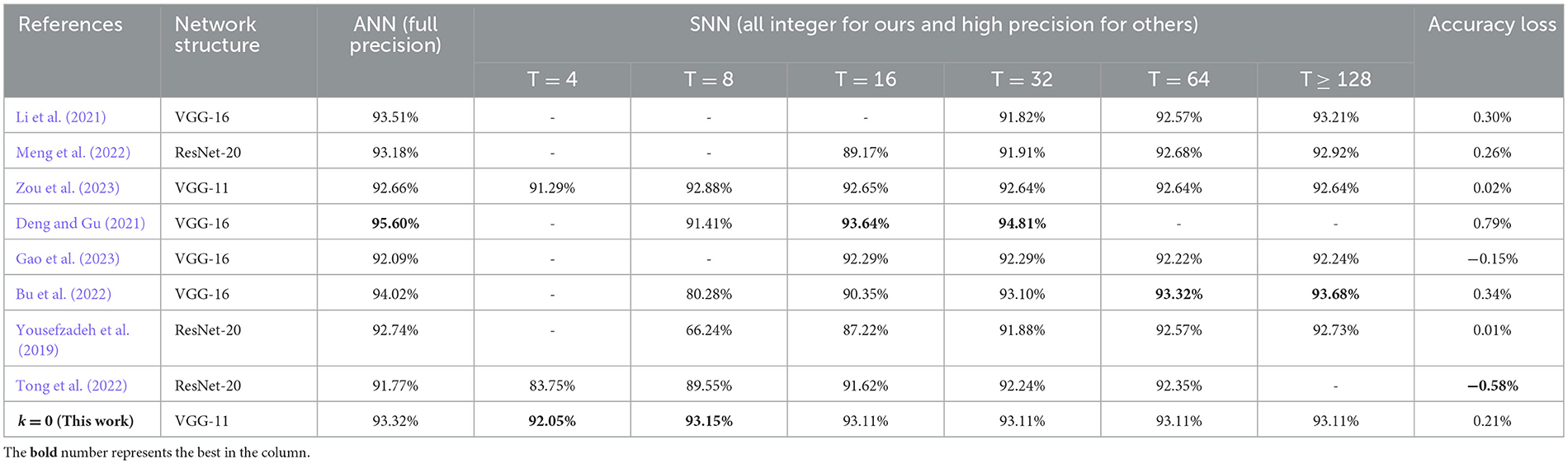
Table 4. Comparison for the proposed spiking VGG-Net on CIFAR-10 with other works.
4.3 Experiments on CIFAR-100 and ImageNetCIFAR-100 (Krizhevsky and Hinton, 2009) is just like the CIFAR-10 but more challenging. It has 100 classes containing 600 images each. There are 500 training images and 100 testing images per class. ImageNet (Russakovsky et al., 2015) is a much larger dataset, which consists of more than one million image samples and falls into 1000 categories. To verify the effect of our conversion algorithm on these two datasets, we adopt the VGG-11 (the same as the network for CIFAR-10) and a 29-layer MobileNet-V1 (43) for experiment running, respectively. Similarly, we do not use any other optimization techniques for training and the test evaluation is based solely on central crop from test set. It should be noted we train MobileNet-V1 on ImageNet dataset for only 60 epochs, because it needs quite long simulation time and vast parallel computing resources. The experimental results on these two large-scale datasets are summarized in Tables 5, 6, and some comparison data of (Gao et al., 2023; Bu et al., 2022) are collected from self-implementation results (Li et al., 2021). It can be seen that the accuracies of both the proposed spiking VGG-Net and MobileNet could achieve much faster convergence along early time steps, when compared with other works respectively. This phenomenon may be attributed to our good solution of synchronization error which is discussed in Section 2.1. The final accuracy is slightly damaged because our ANN counterparts are trained using some basic optimization techniques and fewer epochs.
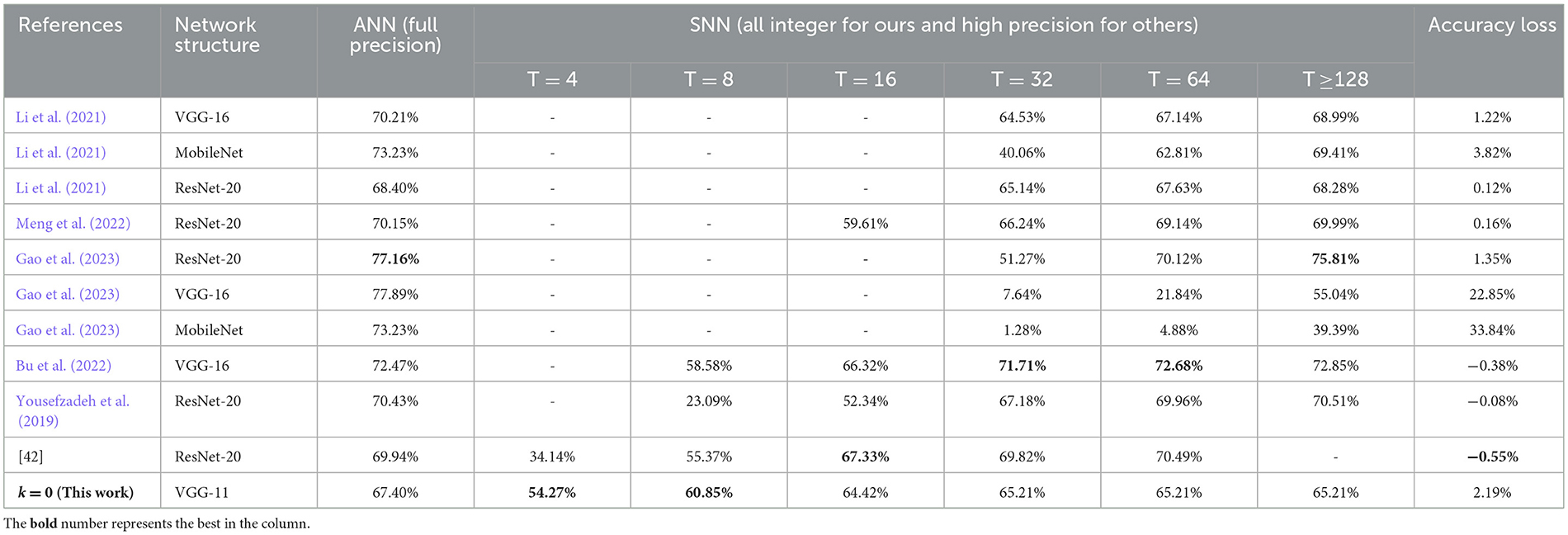
Table 5. Comparison for the proposed spiking VGG-Net on CIFAR-100 with other works.
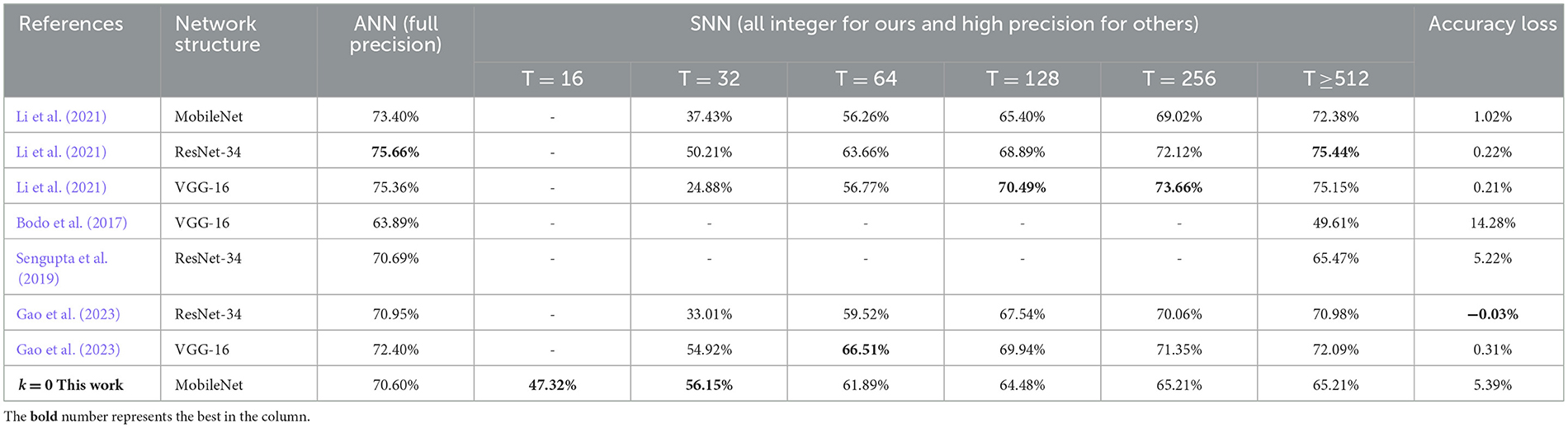
Table 6. Comparison for the proposed spiking MobileNet on ImageNet with other works.
4.4 Energy efficiencyAs shown in Figure 3, we count the average amount of positive and negative spikes for one sample simulation of the spiking LeNet (total 10,728 neurons) on MNIST and VGG-Net (total 280,832 neurons) on CIFAR-10 except for the first input layer and last classification layer. It can be seen that for networks with higher quantization levels, higher spike activities occur while the negative/positive ratio slightly increases. For example, as quantization level k varies from 0 to 2, the spike amount on CIFAR-10 for one sample simulation increases from 147,976 to 363,385 (averagely), and the negative/positive ratio of spikes increases from 0.23 to 0.25 (nearly). Overall, there are only about 0.5, 0.74, and 1.3 spikes per neuron with respective kε. In contrast, the negative/positive ratio of spikes in spiking LeNet (nearly 0.15–0.2) is relatively smaller than VGG-Net (nearly 0.23 to 0.25), which means the negative spikes play a key role in deeper networks with higher quantization levels.
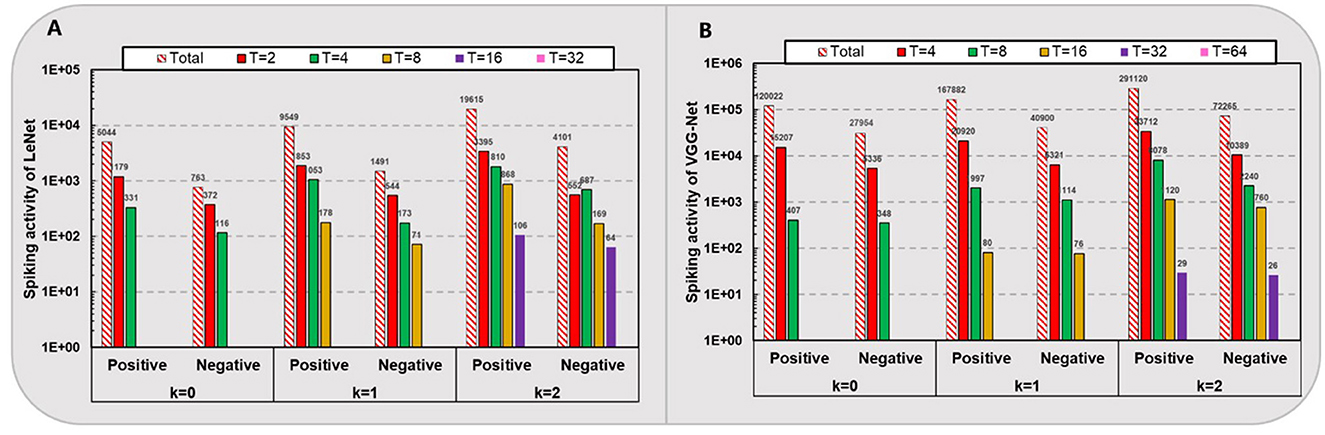
Figure 3. Spiking activity of LeNet (A) on MNIST and VGG-Net (B) on CIFAR-10.
Furthermore, we compare the amount of needed computational operations in above spiking models and their ANN counterparts in Figure 4. For our proposed SNNs with ternary synaptic weights and integer thresholds, there is no need for any high-precision multiplication, only a low-bit SOP, i.e., addition is required when there is a pre-synaptic spike coming. In contrast, for ANNs running on traditional CPUs or GPUs, massive matrix MAC will be performed. Here, we hypothesize that a high-precision MAC is equivalent to 4 low-bit SOPs. In fact, the power and area cost of a floating-point multiplication are always much more expensive than that of several integer-based additions in most of hardware systems (Hu et al., 2023; Courbariaux et al., 2016; Howard et al., 2017). As shown in Figure 4, it can be seen that our proposed SNNs with quantization level kε consume nearly 7.2, 3.7, and 1.9 times fewer computational operations for LeNet and 5.9, 3.8, and 2.2 times fewer for VGG-Net compared to their ANN counterparts, respectively. These results prove that the converted SNNs can achieve much higher energy efficiency than ANNs, while maintaining comparable accuracy.
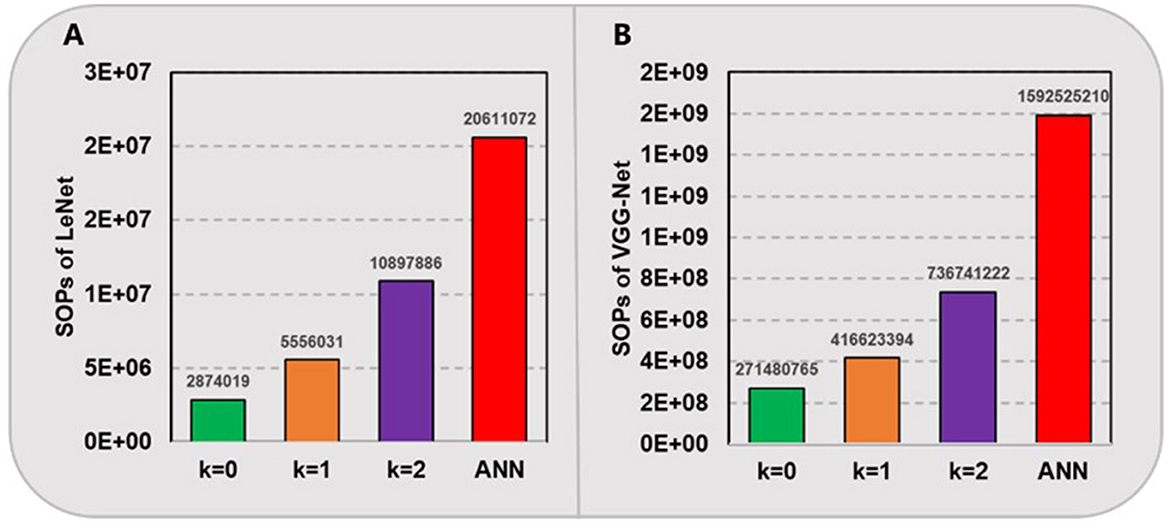
Figure 4. Computational operations (SOPs) of LeNet (A) on MNIST and VGG-Net (B) on CIFAR-10.
Furthermore, because our proposed spiking models run with 0 or ±1 weights and spikes, integer threshold and leakage variables, these integer-based operations could be replaced by the efficient bit-operation such as XNOR-popcount, which is introduced in the binary neural networks (BNNs) (Courbariaux et al., 2016) and ternary neural networks (TNNs) (Liu et al., 2023). Even though the computing cost and latency of SNNs may be greater than these two kinds of special ANN-domain models (Tavanaei et al., 2019), the high-accuracy and spatio-temporal processing abilities on some more complex applications still make them the first choice. Of course, a more fair or in-depth comparison between BNNs/TNNs and SNNs may be a perennial topic and will be considered in the future works.
5 ConclusionIn this work, we introduce a novel dynamic threshold adaptation technique into traditional ANN2SNN conversion process to eliminate common spike approximation error, and further present an all integer-based quantization method to obtain a lightweight and hardware-friendly SNN model. Experimental results show that the proposed spiking LeNet and VGG-Net can obtain more than 99.45% and 93.15% accuracy on MNIST and CIFAR-10 dataset with only 4 and 8 time steps, respectively. Besides, the captured spiking activity and computational operations in SNNs indicate that our proposed spiking models can achieve much higher energy efficiency with comparable accuracy than their ANN counterparts. Finally, our future works will concentrate on the conversion and quantization methods for some special architecture, such as ResNet, RNN and transformer-based models. More importantly, try to map these models onto some dedicated neuromorphic hardware is more rewarding, this will bring a real running performance improvement for some edge computing applications.
Data availability statementThe original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author contributionsCZ: Methodology, Writing – original draft. XC: Funding acquisition, Writing – original draft, Writing – review & editing. SF: Formal analysis, Validation, Writing – review & editing. GC: Formal analysis, Validation, Writing – review & editing. YZ: Data curation, Software, Writing – review & editing. ZD: Data curation, Software, Writing – review & editing. YW: Funding acquisition, Writing – review & editing.
FundingThe author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the National Postdoctoral Research Station of CQBDRI.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
ReferencesAndrew, A. M. (2003). Spiking neuron models: single neurons, populations, plasticity. Kybernetes 32:7–8. doi: 10.1108/k.2003.06732gae.003
Crossref Full Text | Google Scholar
Bengio, Y., Nicholas, L., and Courville, A. (2013). Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv [Preprint] arXiv:1308.3432. doi: 10.48550/arXiv.1308.3432
Crossref Full Text | Google Scholar
Bodo, R., Iulia-Alexandra, L., Hu, Y., Michael, P., and Liu, S. C. (2017). Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 11:682. doi: 10.3389/fnins.2017.00682
PubMed Abstract | Crossref Full Text | Google Scholar
Bouvier, M., Valentian, A., Mesquida, T., Rummens, F., Reyboz, M., Vianello, E., et al. (2019). Spiking neural networks hardware implementations and challenges: A survey. ACM J. Emerg. Technol. Comp. Syst. 15, 1–35. doi: 10.1145/3304103
Crossref Full Text | Google Scholar
Bu, T., Ding, J., Yu, Z., and Huang, T. (2022). Optimized potential initialization for low-latency spiking neural networks. arXiv [Preprint].arXiv:2202.01440. doi: 10.48550/arXiv.2202.01440
PubMed Abstract | Crossref Full Text | Google Scholar
Cheng, Y., Wang, D., Zhou, P., and Zhang, T. (2017). A survey of model compression and acceleration for deep neural networks. arXiv [Preprint].arXiv:1710.09282. doi: 10.48550/arXiv.1710.09282
Crossref Full Text | Google Scholar
Courbariaux, M., Hubara, I., Soudry, D., El-Yaniv, R., and Bengio, Y. (2016). Binarized neural networks: training deep neural networks with weights and activations constrained to +1 or−1. arXiv [Preprint].arXiv:1602.02830. doi: 10.48550/arXiv.1809.03368
Crossref Full Text | Google Scholar
Dampfhoffer, M., Mesquida, T., Valentian, A., and Anghel, L. (2023). Backpropagation-based learning techniques for deep spiking neural networks: a survey. IEEE Trans. Neural Netw. Learn Syst. 35, 11906–11921. doi: 10.1109/TNNLS.2023.3263008
PubMed Abstract | Crossref Full Text | Google Scholar
Deng, S., and Gu, S. (2021). “Optimal conversion of conventional artificial neural networks to spiking neural networks,” in Proceedings of the 9th International Conference on Learning Representations (ICLR).
PubMed Abstract | Google Scholar
Diehl, P. U., Neil, D., Binas, J., Cook, M., Liu, S. C., and Pfeiffer, M. (2015). “Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,” in 2015 International Joint Conference on Neural Networks (IJCNN) (Killarney: IJCNN).
PubMed Abstract | Google Scholar
Esser, S. K., Merolla, P. A., Arthur, J. V., Cassidy, A. S., Appuswamy, R., Andreopoulos, A., et al. (2016). Convolutional networks for fast, energy-efficient neuromorphic computing. Proc. National Acad. Sci. USA. 113, 11441–11446. doi: 10.1073/pnas.1604850113
PubMed Abstract | Crossref Full Text | Google Scholar
Gao, H., He, J., Wang, H., Wang, T., Zhong, Z., Yu, J., et al. (2023). High-accuracy deep ANN-to-SNN conversion using quantization-aware training framework and calcium-gated bipolar leaky integrate and fire neuron. Front. Neurosci. 17, 254–268. doi: 10.3389/fnins.2023.1141701
PubMed Abstract | Crossref Full Text | Google Scholar
Glorot, X., Bordes, A., and Bengio, Y. (2011). “Deep sparse rectifier neural networks,” in Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS) 15: 315–323.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Las Vegas, NV: IEEE), 770–778.
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., et al. (2017). MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv [preprint] arXiv.1704.04861. doi: 10.48550/arXiv.1704.04861
Crossref Full Text | Google Scholar
Hu, Y., Zheng, Q., Jiang, X., and Pan, G. (2023). Fast-SNN: fast spiking neural network by converting quantized ANN. IEEE Trans. Pattern Anal. Mach. Intell. 45, 14546–14562. doi: 10.1109/TPAMI.2023.3275769
PubMed Abstract | Crossref Full Text | Google Scholar
Ioffe, S., and Szegedy, C. (2015). “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in Proceedings of the 32nd International Conference on Machine Learning (ICML) (Lille: PMLR),448–456.
PubMed Abstract | Google Scholar
Kasabov, N. K. (2019). Evolving spiking neural networks. In: time-space, spiking neural networks and brain-inspired artificial intelligence. Springer Series on Bio- and Neurosyst. 7:169–199. doi: 10.1007/978-3-662-57715-8_5
Crossref Full Text | Google Scholar
Lecun, Y., and Bottou, L. (1998). Gradient-based learning applied to document recognition. Proc. IEEE. 86, 2278–2324. doi: 10.1109/5.726791
Crossref Full Text | Google Scholar
Lee, C., Srinivasan, G., Panda, P., and Roy, K. (2019). Deep spiking convolutional neural network trained with unsupervised spike-timing-dependent plasticity. IEEE Trans. Cogn. Dev. Syst. 11, 384–394. doi: 10.1109/TCDS.2018.2833071
Crossref Full Text | Google Scholar
Li, Y., Deng, S., Dong, X., Gong, R., and Gu, S. (2021). “A free lunch from ANN: towards efficient, accurate spiking neural networks calibration,” in Proceedings of the 38th International Conference on Machine Learning (ICML), 6316–6325.
Li, Y., Deng, S., Dong, X., and Gu, S. (2022). Converting artificial neural networks to spiking neural networks via parameter calibration. arXiv [Preprint].arXiv:2205.10121. doi: 10.48550/arXiv.2205.10121
Crossref Full Text | Google Scholar
Liu, B., Li, F., Wang, X., Zhang, B., and Yan, J. (2023). “Ternary weight networks,” in 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Rhodes Island: IEEE), 1–5.
Massa, R., Marchisio, A., Martina, M., and Shafique, M. (2020). “An efficient spiking neural network for recognizing gestures with a DVS camera on the Loihi neuromorphic processor,” in 2020 International Joint Conference on Neural Networks (IJCNN) (Glasgow: IJCNN), 1–9.
Meng, Q., Yan, S., Xiao, M., Wang, Y., Lin, Z., and Luo, Z. (2022). Training much deeper spiking neural networks with a small number of time-steps. Neural Netw. 153, 254-268. doi: 10.1016/j.neunet.2022.06.001
PubMed Abstract | Crossref Full Text | Google Scholar
Neftci, E. O., Mostafa, H., and Zenke, F. (2019). Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 36, 51–63. doi: 10.1109/MSP.2019.2931595
Crossref Full Text | Google Scholar
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 115, 211–252. doi: 10.1007/s11263-015-0816-y
Crossref Full Text | Google Scholar
Schuman, C. D., Potok, T. E., Patton, R. M., Birdwell, J. D., Dean, M. E., Rose, G. S., et al. (2017). A survey of neuromorphic computing and neural networks in hardware. arXiv [Preprint] arXiv.1705.06963. doi: 10.48550/arXiv.1705.06963
Crossref Full Text | Google Scholar
Sengupta, A., Ye, Y., Wang, R., Liu, C., and Roy, K. (2019). Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 13:95. doi: 10.3389/fnins.2019.00095
PubMed Abstract | Crossref Full Text | Google Scholar
Simonyan, K., and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
Taherkhani, A., Belatreche, A., Li, Y., Cosma, G., Maguire, L. P., and Mcginnity, T. M. (2020). A review of learning in biologically plausible spiking neural networks. Neural Netw. 122, 253–272. doi: 10.1016/j.neunet.2019.09.036
PubMed Abstract | Crossref Full Text | Google Scholar
Tavanaei, A., Ghodrati, M., Kheradpisheh, S. R., Masquelier, T., and Maida, A. (2019). Deep learning in spiking neural networks. Neural Netw. 111, 47–63. doi: 10.1016/j.neunet.2018.12.002
PubMed Abstract | Crossref Full Text | Google Scholar
Tong, B., Wei, F., Jian, D., Peng, D., Zhao, Y., and Tie, H. (2022). “Optimal ANN-SNN conversion for high-accuracy and ultra-low-latency spiking neural networks,” in Proceedings of the 10th International Conference on Learning Representations (ICLR).
Xu, Y., Tang, H., Xing, J., and Li, H. (2017). “Spike trains encoding and threshold rescaling method for deep spiking neural networks,” in 2017 IEEE Symposium Series on Computational Intelligence (SSCI) (Honolulu, HI: IEEE), 1–6. doi: 10.1109/SSCI.2017.8285427
Crossref Full Text | Google Scholar
Yousefzadeh, A., Hosseini, S., Holanda, P., Leroux, S., Werner, T., Serrano-Gotarredona, T., et al. (2019). “Conversion of synchronous artificial neural network to asynchronous spiking neural network using sigma-delta quantization,” in 2019 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS) (Hsinchu: IEEE), 81–85.
Zou, C., Cui, X., Chen, G., Jiang, Y., and Wang, Y. (2023). Towards a lossless conversion for spiking neural networks with negative-spike dynamics. Adv. Intellig. Syst. 5, 1–12. doi: 10.1002/aisy.202300383
Crossref Full Text | Google Scholar
Zou, C., Cui, X., Ge, J., Ma, H., and Wang, X. (2020). “A novel conversion method for spiking neural network using median quantization,” in 2020 IEEE International Symposium on Circuits and Systems (ISCAS) (Seville: IEEE), 1–5.
Zou, C., Cui, X., Kuang, Y., Liu, K., Wang, Y., Wang, X., et al. (2021). A scatter-and-gather spiking convolutional neural network on a reconfigurable neuromorphic hardware. Front. Neurosci. 15:694170. doi: 10.3389/fnins.2021.694170
留言 (0)