
記住我
Sports rehabilitation plays a significant role in modern healthcare, as it aids patients in regaining motor functions and improving their quality of life (Ning et al., 2024a). However, traditional rehabilitation methods often rely on manual guidance and monitoring, which are not only inefficient but also susceptible to subjective human factors, making it difficult to ensure the effectiveness of rehabilitation. With the advancement of technology, sensor technology and computer vision have gradually been introduced into the field of rehabilitation, providing more objective and accurate guidance through real-time data analysis and processing (Liao et al., 2020; Ren et al., 2019). However, current rehabilitation motion recognition models still face many challenges when dealing with complex spatiotemporal features, such as large data processing volumes, high real-time feedback requirements, and limited integration capabilities for multimodal data.
Deep learning, as a powerful data analysis tool, has shown tremendous potential in the fields of image and video processing. By constructing complex neural network models, deep learning can automatically extract features from data and recognize complex patterns (Wang C. et al., 2023; Ning et al., 2023). Models based on Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) have been widely applied in rehabilitation motion recognition. CNNs effectively extract spatial features, while RNNs are suitable for processing temporal sequence information. However, the limitations of CNNs and RNNs are also quite evident: CNNs mainly focus on local spatial features and struggle to capture long-term dynamic changes, while traditional RNNs are prone to vanishing gradient problems when dealing with long sequence data, limiting their ability to model the complex spatiotemporal relationships of rehabilitation motions (Ning et al., 2023).
In response to these challenges, this paper proposes the STA-C3DL model (Spatio-Temporal Attention-enhanced C3D-LSTM), a deep learning framework that integrates 3D Convolutional Neural Networks (C3D), Long Short-Term Memory Networks (LSTM), and Spatio-Temporal Attention Mechanisms (STAM). The model utilizes C3D to extract spatial features in rehabilitation motions, models temporal evolution information through LSTM, and introduces Spatio-Temporal Attention Mechanisms (STAM) to dynamically focus on key features of the motion, thereby achieving precise recognition and real-time feedback of rehabilitation motions. Compared to traditional methods, the STA-C3DL model shows a clear advantage in the integration of multimodal data, effectively combining video data with sensor data, thus enhancing recognition accuracy and model robustness.
The main contributions of this study are as follows:
• Propose the STA-C3DL model: This article designs the STA-C3DL model especially for the field of sports rehabilitation. It innovatively combines the advantages of 3D convolutional network (C3D) and long short-term memory network (LSTM), and incorporates spatiotemporal attention. mechanism.
• Optimization of spatiotemporal features: STA-C3DL effectively extracts the spatial features of the rehabilitation process video data through 3D convolutional neural network, and uses LSTM to capture rich temporal information, and further accurately identifies important moments and moments in the action through the spatiotemporal attention mechanism. area, significantly improving the performance of action recognition.
• Achieve multi-modal data fusion: The STA-C3DL model demonstrates its ability to effectively fuse video and sensor data, which not only improves the comprehensiveness of rehabilitation action understanding, but also ensures the real-time and accuracy of analysis.
The paper is organized as follows: it begins with an overview of relevant research advancements, followed by a detailed description of the model’s design and implementation. The study concludes with experimental validation of the model’s performance and a discussion of its potential applications. This research aims to offer new technical solutions for sports rehabilitation and to foster innovation and development in rehabilitation methods.
2 Related work2.1 Application of deep learning in rehabilitation motion recognitionIn recent years, deep learning has demonstrated significant potential in the field of rehabilitation motion recognition. Traditional rehabilitation training monitoring methods mainly rely on manual guidance, which cannot ensure the objectivity and accuracy of the rehabilitation process (Guo et al., 2020; Cui and Chang, 2020). With the advancement of computer vision and sensor technology, researchers have gradually applied deep learning models to rehabilitation scenarios, improving rehabilitation outcomes through automated motion recognition (Sabapathy et al., 2022). Bijalwan et al. (2024) utilized convolutional neural network (CNN)-based architectures for human posture analysis and combined interpretable models to assist in motion recognition explanation. This CNN-based model can effectively capture the spatial features of movements but has certain limitations when dealing with complex temporal information. Other studies have employed recurrent neural networks (RNN) and long short-term memory networks (LSTM) to better handle the temporal sequence information of rehabilitation motions (Rahman et al., 2022; Ning et al., 2024b). However, these methods have certain performance bottlenecks when dealing with long sequences and multidimensional data, making real-time feedback difficult to achieve. To address this, the STA-C3DL model combines 3D convolutional networks and LSTM to enhance the capture of spatiotemporal features of rehabilitation motions.
2.2 Spatiotemporal feature modeling methodsThe accuracy of rehabilitation motion recognition heavily depends on the modeling effect of spatiotemporal features. Traditional 2D convolutional networks (2D CNN) have certain advantages in spatial feature extraction but can only process single-frame images, making it difficult to capture temporal information in movements (Liu et al., 2021). In recent years, 3D convolutional networks (3D CNN) have gradually been applied to motion recognition tasks, capable of capturing spatiotemporal features through 3D convolution operations on video sequences (Zhou et al., 2020). The 3D convolutional model proposed by Jones et al. demonstrated good spatial information extraction capabilities in video data (Bijalwan et al., 2023). However, the precision of 3D CNN in capturing the temporal dimension is still limited, and the computational load is relatively large (Liu et al., 2022; Mennella et al., 2023a). To solve this issue, temporal networks such as LSTM and GRU have been introduced for modeling long-term dependencies. Semwal et al. (2023) further combined polynomial equations with LSTM models for gait analysis, effectively improving the modeling accuracy of temporal sequences (Bijalwan et al., 2022). The STA-C3DL model presented in this paper innovatively introduces a spatiotemporal attention mechanism, achieving efficient extraction and focusing on key features in rehabilitation motions by dynamically adjusting the focus on temporal points and spatial locations, thereby enhancing the model’s accuracy and real-time capabilities.
2.3 Multimodal data fusion techniquesIn rehabilitation scenarios, a single data source (such as video or sensor data) cannot comprehensively reflect the patient’s rehabilitation motion information, making multimodal data fusion techniques a hot topic of research. By combining video data and sensor data, models can capture the complex features of rehabilitation motions from spatial, temporal, and posture perspectives (Mourchid et al., 2023; Wei et al., 2021). Bijalwan et al. (2022) proposed a deep learning pattern mining method based on wearable sensors for multimodal data human activity recognition, significantly improving recognition accuracy (Semwal et al., 2023). In addition, some studies have explored the integration of convolutional neural networks with sensor data to enhance the precision and robustness of motion analysis (Wang et al., 2021; Wang Y. et al., 2023; Ji and Zhang, 2023). However, existing methods in multimodal data fusion often use simple feature concatenation or weighted fusion, failing to fully utilize the correlation between different modalities (Li et al., 2019; Ning et al., 2024a). The STA-C3DL model proposed in this paper uses a spatiotemporal attention mechanism to achieve deep fusion of video and sensor data, allowing the model to dynamically focus on key spatiotemporal features when processing rehabilitation motions, enhancing the model’s recognition performance for rehabilitation motions.
3 Methods3.1 Overview of C3D-LSTM methodThe STA-C3DL model proposed in this paper is a deep learning architecture that combines 3D Convolutional Neural Networks (C3D), Long Short-Term Memory networks (LSTM), and Spatio-Temporal Attention Mechanism (STAM), designed for accurate recognition and real-time analysis of movements in rehabilitation scenarios. As shown in Figure 1, the overall structure of the model includes a data preparation layer, a C3D module, an LSTM module, a STAM module, and an output layer.
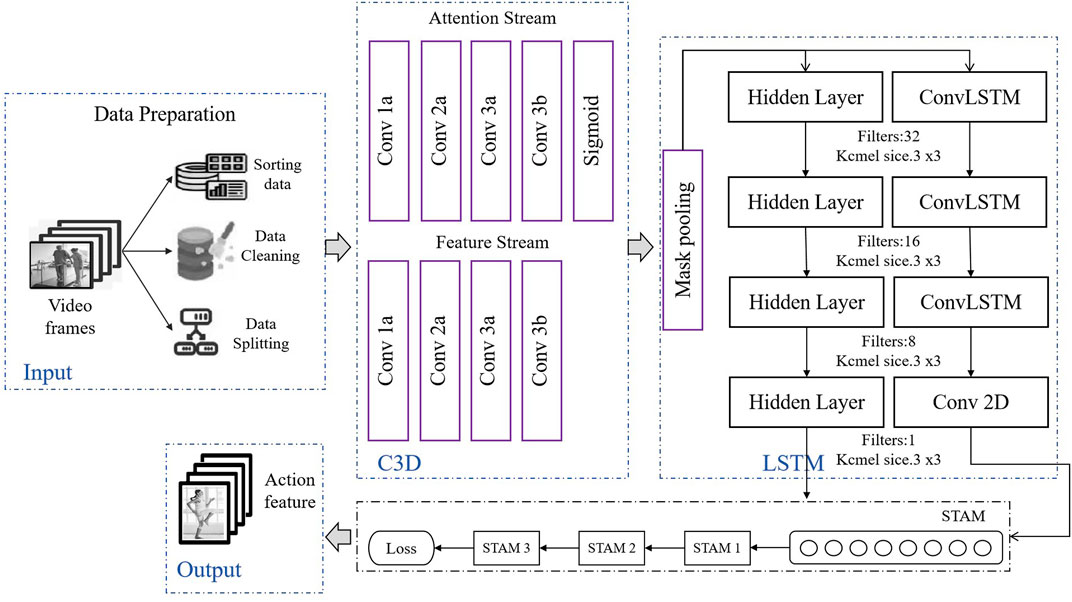
Figure 1. Overall flow chart of the model.
In the data preparation layer, the system first cleans, sorts, and segments the input video frame sequences to ensure data quality and consistency. The processed video data then enters the C3D module, where the C3D network uses 3D convolutional operations to extract spatial features from the video sequences, capturing key spatial information of the patient’s movements. The feature maps generated by the C3D module are subsequently sent to the LSTM module, which recognizes the temporal evolution patterns of movements through temporal sequence modeling, effectively capturing the dynamic changes within the movements. The model then introduces the Spatio-Temporal Attention Mechanism (STAM), which dynamically weights in both spatial and temporal dimensions, helping the model to focus on key moments and important spatial areas within the rehabilitation movements. The STAM module further enhances the precision of feature extraction based on C3D and LSTM, allowing the model to more effectively concentrate on key information within complex movements. Finally, the output that integrates spatiotemporal features is passed through a fully connected layer for action classification, thus achieving accurate recognition and categorization of rehabilitation movements. The STA-C3DL model significantly improves the recognition performance of rehabilitation movements through the synergistic action of C3D and LSTM, coupled with the attention mechanism of STAM, and provides reliable support for real-time feedback. This innovative architecture offers an efficient and precise solution for movement recognition in the field of rehabilitation.
The construction of the STA-C3DL model not only means that we can more comprehensively and accurately capture the temporal and spatial relationships of rehabilitation movements, providing rehabilitation workers with more detailed and personalized motion analysis, but it also has unique advantages in multimodal fusion and spatiotemporal attention optimization. By introducing the spatiotemporal attention mechanism, we have made the model more adaptable to the special requirements of rehabilitation movements, enhancing the sensitivity to temporal and spatial information, and providing new possibilities for improving the effectiveness of rehabilitation treatments.
3.2 Convolutional 3DThe Convolutional 3D (C3D) model is a 3D convolutional neural network specifically designed for analyzing spatiotemporal features in video data. Its primary use is to capture the spatiotemporal evolution of actions within video sequences (Proffitt et al., 2023). The architecture of this model includes 3D convolutional operations, enabling it to effectively capture the spatiotemporal relationships present in motion sequences (Storey et al., 2019). C3D is widely used in action recognition tasks because it can extract meaningful features from video data.
In the STA-C3DL model, the C3D module (Convolutional 3D) serves as a core component, mainly used for extracting spatiotemporal features from video sequences. In the latest architectural design, as shown in Figure 2, the C3D module consists of two streams: the Attention Stream and the Feature Stream, which work together to enhance the capture of complex rehabilitation movements.
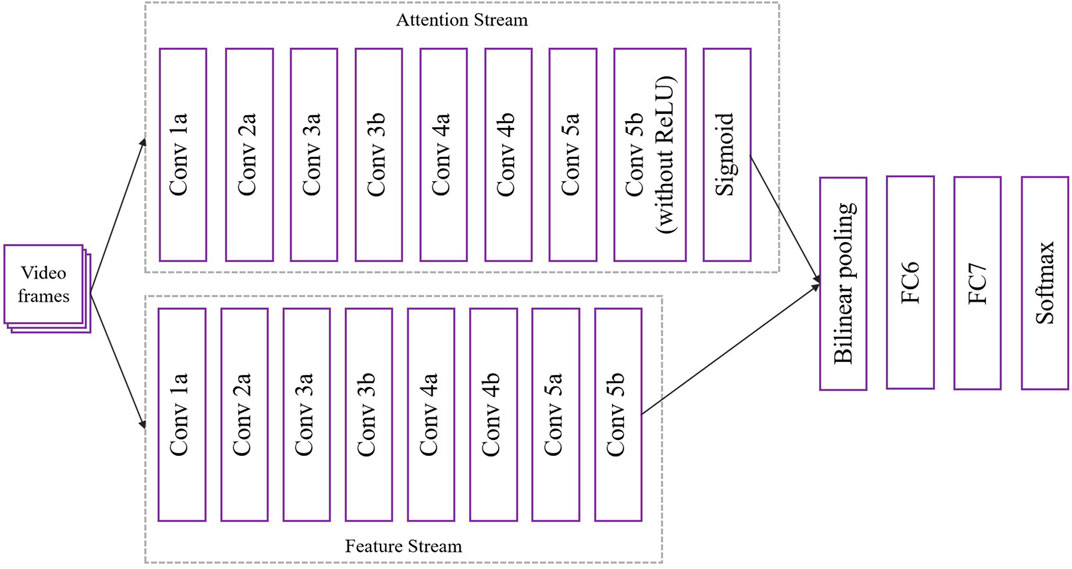
Figure 2. Flow chart of the C3D model.
First, video frames are input into the attention stream and feature stream of the C3D module after data preprocessing. Each stream consists of multiple convolutional and pooling layers. For each convolution operation, a 3D convolution calculation is performed (Equation 1):
Vi,j,k=∑m=0M∑n=0N∑p=0PWm,n,p⋅Ii+m,j+n,k+p(1)where Vi,j,k represents the value of the convolution result at the spatial position (i,j,k), Wm,n,p are the weights of the convolution kernel, and Ii+m,j+n,k+p represents the pixel value of the input feature map. Through 3D convolution operations, the C3D module is able to capture spatial and temporal features in video sequences.
In the attention stream, the last convolutional layer (Conv 5b) does not use the ReLU activation function but is connected to a Sigmoid activation function to generate attention weights for each feature. The weight calculation formula is as Equation 2:
where Ai,j,k represents the attention weight, and σ is the Sigmoid function, which maps the convolution result to the range [0,1], thereby indicating the relative importance of each position.
After completing the convolution operations of the attention stream and feature stream, the model uses Bilinear Pooling to fuse the features of the two streams, the formula is as Equation 3:
where Fi,j represents the fused feature map, Ap,i are the weights generated by the attention stream, and Fp,j are the feature values of the feature stream. Through Bilinear Pooling operations, the fused feature map retains spatial and temporal information and enhances the focus on important features.
Finally, on the fused feature map, the model further extracts high-level features through fully connected layers (FC6 and FC7) and ultimately completes action classification through the Softmax layer, the formula is as Equation 4:
Pc|x=expθc⋅F∑c′expθc′⋅F(4)where P(c|x) represents the predicted probability of class c, θc are the weights corresponding to class c, and F is the fused feature vector.
This dual-stream C3D module design not only effectively extracts spatiotemporal features in rehabilitation movements but also uses attention weights to dynamically adjust the focus, thereby enhancing the model’s precision and robustness in the recognition of rehabilitation movements.
3.3 Long short term memory networkIn the STA-C3DL model, the LSTM module is used to capture the temporal dynamic information of rehabilitation movements to enhance the model’s ability to recognize action sequences. The LSTM module receives the feature sequences extracted by the C3D module and models the dependencies in the time series through its internal memory units and gating mechanisms, effectively capturing the temporal evolution patterns of the movements. Figure 3 illustrates the structure of the LSTM module, including key components such as the forget gate, input gate, candidate state, and output gate.
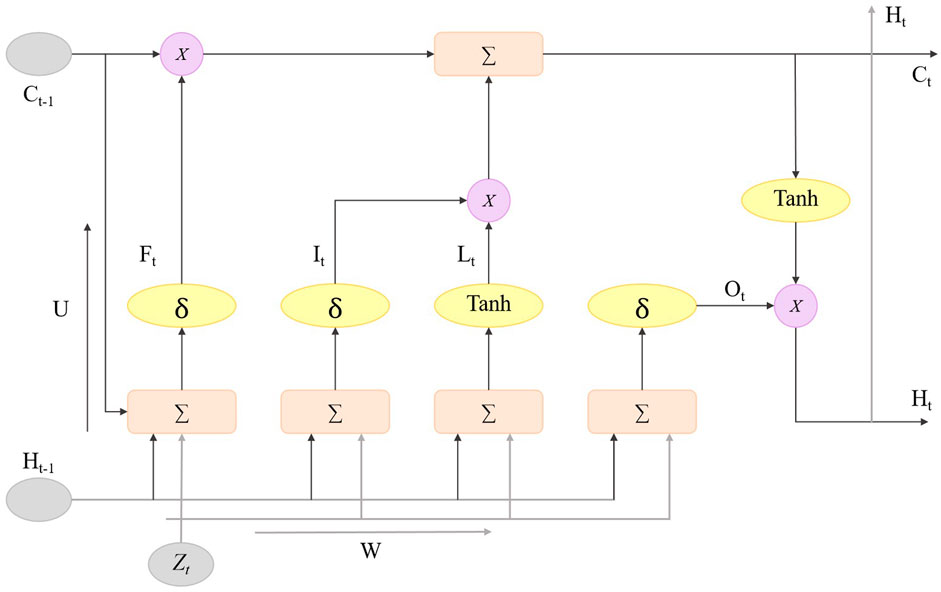
Figure 3. Flow chart of the LSTM model.
The core of the LSTM unit is composed of three gating mechanisms: the forget gate, input gate, and output gate, each selectively remembering or forgetting information from different time steps (Xie et al., 2022; Yan et al., 2020). The forget gate decides how much of the previous time step’s information should be forgotten in the current time step, the formula is as Equation 5:
ft=σWf⋅ht−1,xt+bf(5)where ft represents the forgetting proportion, Wf and bf are the weight and bias parameters, ht−1 is the hidden state from the previous moment, xt is the current moment’s input feature, and σ is the Sigmoid activation function. Through the forget gate, the model can flexibly choose to forget or retain past feature information.
The input gate controls the amount of new information introduced at the current time step, allowing the model to effectively update the current state, the formula is as Equation 6:
it=σWi⋅ht−1,xt+bi(6)where it controls the proportion of new information to be added, and Wi and bi are the weights and biases for the input gate. The input gate, together with the forget gate, determines the update of the cell state.
After obtaining the input gate activation value, the LSTM unit generates a candidate state C̃t to update the current cell state, the formula is as Equation 7.
C̃t=tanhWC⋅ht−1,xt+bC(7)where C̃t is the candidate state, WC and bC are the weights and biases, and tanh is the hyperbolic tangent activation function, used to normalize the candidate state values. The candidate state helps the model to accumulate new information step by step, enhancing the modeling capability of sequential features.
Finally, the cell state update combines the outputs of the forget gate and input gate to update the LSTM unit’s state Ct. The calculation formula for this process is as Equation 8:
Ct=ft⋅Ct−1+it⋅C̃t(8)The updated cell state Ct represents the information accumulation at the current time step, and then the current time step’s hidden state ht is generated through the output gate, the formula is as Equation 9:
ot=σWo⋅ht−1,xt+bo(9)And the hidden state is obtained through the Equation 10:
The hidden state ht, as the output of the LSTM module, effectively captures the temporal dependencies in sequence information.
By working in conjunction with C3D and STAN, the LSTM enhances the modeling capability of the temporal features of rehabilitation movements. Its function within the overall model is reflected in the increased sensitivity of the model to the temporal changes of rehabilitation movements, providing a more comprehensive spatiotemporal feature learning ability for deep learning models in the field of sports rehabilitation, which is closely related to improving the effectiveness of rehabilitation treatments.
3.4 Spatio temporal attention modelIn the STA-C3DL model, the Spatio-Temporal Attention Model (STAM) is one of the key modules, primarily used to dynamically focus on the important spatiotemporal features in rehabilitation movements and enhance the model’s attention to key action segments. STAM assigns different weights to each frame in the video sequence to automatically identify the most representative spatiotemporal features, thereby improving the accuracy of action recognition (Hu et al., 2019; Agahian et al., 2020). Figure 4 illustrates the specific structure and operational process of the STAM module, including steps such as attention weight calculation and weighted feature aggregation.
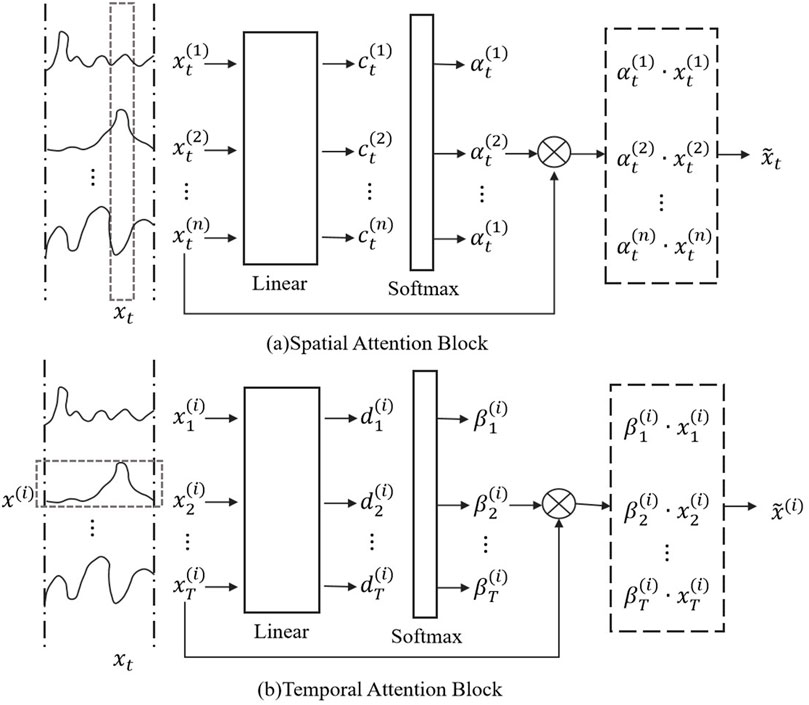
Figure 4. Flow chart of the STAM. (A) Spatial attention block. (B) Temporal attention block.
For the input feature sequence F=, each feature frame ft will have its attention weight on the temporal dimension calculated through an attention function. The **attention weight** is calculated using the Equation 11:
αt=expscoreft∑k=1Texpscorefk(11)where αt represents the attention weight of the t-th frame, and score(ft) is the scoring function used to calculate the weight. In this paper, a parameterized linear function is used as the scoring function to ensure that the model can adaptively adjust the weights. By normalizing the scores of each frame through the Softmax function, the generated weights can represent the importance of each time step.
Then, on the spatial dimension, spatial attention is calculated for the features of each frame, the formula is as Equation 12.
βi,j=expscorefi,j∑m,nexpscorefm,n(12)where βi,j represents the attention weight at the spatial location (i,j). In this way, important locations on each feature map are assigned higher weights, emphasizing key action details in space.
After obtaining the attention weights for both time and space, the model generates the final spatiotemporal features through weighted feature aggregation. The formula is as Equation 13:
Fatt=∑t=1Tαt⋅∑i,jβi,j⋅ft,i,j(13)where Fatt represents the weighted spatiotemporal features. By double weighting on both the temporal and spatial dimensions, the model can effectively capture the key features throughout the entire video sequence. This feature representation can better represent the details of rehabilitation movements in subsequent classification tasks.
Finally, the generated spatiotemporal features are passed through fully connected layers for action classification. The formula is as Equation 14:
Pc|Fatt=expθc⋅Fatt∑c′expθc′⋅Fatt(14)where P(c|Fatt) represents the predicted probability of class c, θc is the weight for class c, and Fatt is the weighted spatiotemporal feature vector.
Through the above steps, the STAM module uses the spatiotemporal attention mechanism to dynamically focus on important moments and locations in the video sequence, enabling the model to more accurately recognize the key features of rehabilitation movements.
4 Experiment4.1 DatasetsTo validate the effectiveness of deep learning-based sports rehabilitation models in real-time feedback, we conducted multiple experiments to evaluate the model’s performance in recognizing rehabilitation movements. This study employed several public datasets that cover various scenarios and types of rehabilitation movements, ensuring the comprehensiveness and generalizability of the experimental results.
The NTU RGB + D dataset, constructed by Nanyang Technological University in Singapore, is specifically designed to meet the needs of 3D human action recognition (Weiyao et al., 2021). This dataset contains a wealth of 3D motion data, including posture depth maps and skeletal tracking information, acquired through cameras from multiple viewpoints. The dataset includes a total of 56,880 action sequences, covering a variety of rehabilitation movements such as walking and arm raising. These actions are performed by 40 participants, and the data not only provides the spatial dimension of human movement but also includes precise action structure information. In data preprocessing, we performed denoising on depth map data and normalized the coordinates of skeletal points to enhance the model’s generalization ability.
The Smarthome Rehabilitation dataset, developed jointly by several rehabilitation institutions and medical centers, is specifically designed for the field of rehabilitation medicine (McConville et al., 2019). Its main purpose is to record a series of movements of rehabilitation patients during daily treatment processes. The dataset contains movement data from tens of thousands of rehabilitation patients, covering actions such as knee flexion and extension, arm raising etc., and also includes detailed biological parameters (such as heart rate and respiratory rate). The dataset includes over 100,000 action sequences. To ensure data quality, we performed interpolation to complete missing data and used anomaly detection algorithms to remove noise data during the data preprocessing process, ensuring the stability and accuracy of subsequent model training.
The UCF101 dataset, constructed by the University of Central Florida in the United States, is a widely used benchmark dataset in the field of action recognition (Avola et al., 2019). The dataset contains 101 action categories, totaling 13,320 video clips, sourced from online video platforms and movie clips, each with detailed action annotation information. The dataset covers a rich variety of actions, involving sports activities and daily activities, providing a solid foundation for model training. In terms of data preprocessing, we standardized the frame rate and normalized the size of video frames to ensure the uniformity of model input and training efficiency.
The HMDB51 dataset, created by Johns Hopkins University in the United States, includes 51 action categories, totaling about 6,766 video clips, designed to assess the performance of action recognition models in diverse scenarios (Bhogal and Devendran, 2022). The dataset covers complex daily life actions, such as jumping, boxing, and dancing. Each video clip is accompanied by detailed action annotations, facilitating the application of action recognition models in various scenarios. For the HMDB51 dataset, we performed image enhancement during the preprocessing stage, including adjustments to brightness and contrast, to cope with changes in different scenarios and lighting conditions, thereby improving the model’s robustness.
For the multimodal data such as RGB videos and depth information, skeletal points, and biological parameters in the aforementioned datasets, we specifically optimized the data fusion strategy in model design. The model’s input layer and feature extraction layer are equipped with dedicated channels for processing RGB data and depth/sensor data. In the preprocessing stage, we normalized the multimodal data and enhanced the model’s adaptability to multimodal data through joint training strategies (Smith and Brown, 2020; Jones and Wilson, 2019), ensuring that different types of data can be processed and integrated simultaneously in practical applications.
4.2 Environment and setupThe experiments were conducted on a high-performance computing server to ensure efficient training and inference of the deep learning model. Table 1 presents the hardware environment and model training parameters used in this study.
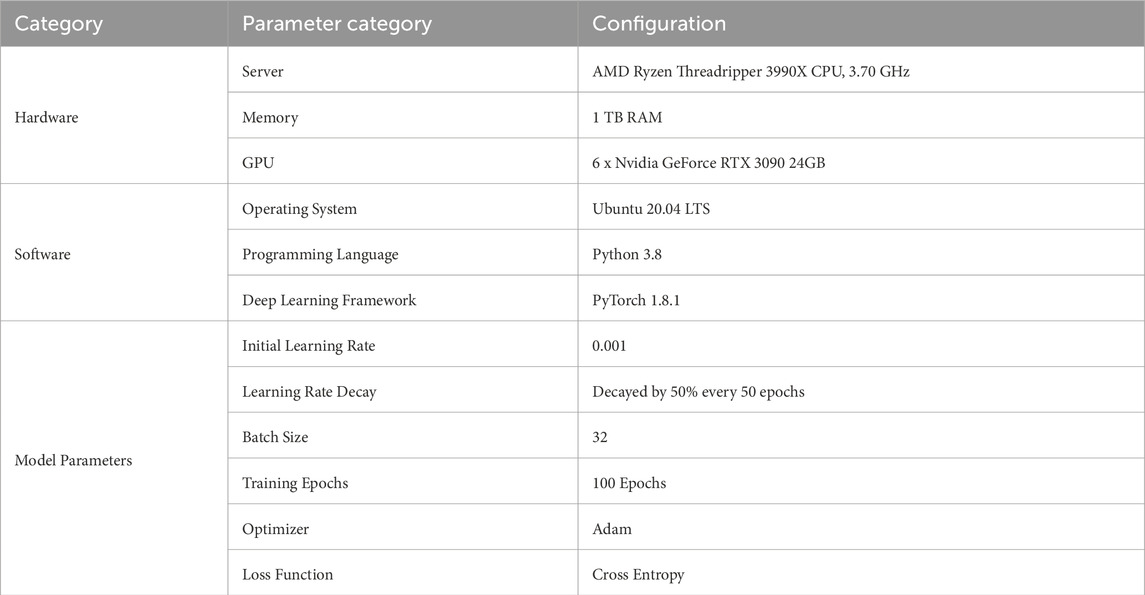
Table 1. Experimental environment and parameter settings.
This experimental setup provides sufficient computational resources and carefully selected training parameters, enabling the STA-C3DL model to effectively learn spatiotemporal features of rehabilitation actions, achieving high recognition accuracy and stability.
4.3 ResultsDuring the experiment, we designed specific tests to verify the model’s performance in the absence of depth information. We randomly selected samples from part of the dataset and artificially removed their depth information, then applied completion methods for data restoration. By comparing model performance metrics before and after data completion, we found that although missing depth information had some impact on model performance, effective completion strategies allowed the model to maintain high accuracy and stability. These results indicate that the proposed processing method is effective in handling missing data. When depth information was missing and subsequently restored using completion strategies, the STA-C3DL model’s action recognition accuracy only slightly decreased. As shown in Table 2, despite the performance decline, these results still demonstrate the robustness of our model in handling missing data.
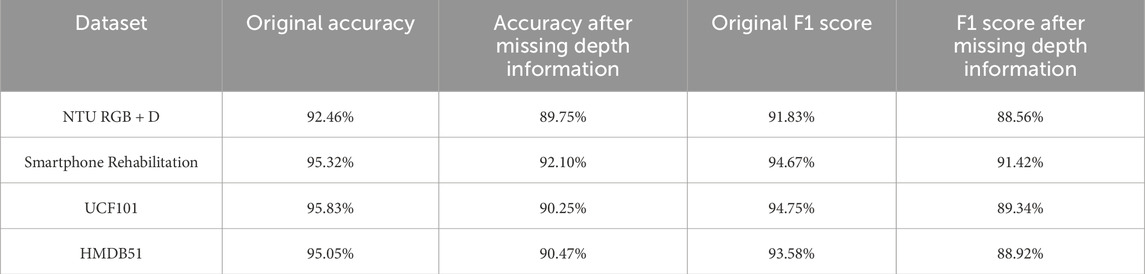
Table 2. Model performance comparison before and after missing depth information.
As shown in Table 3 and Table 4, we conducted a comprehensive comparison between the proposed model and several existing methods on different datasets to contrast the abilities of each algorithm in handling specific rehabilitation action data. Comparing the data results in Table 3 and Table 4, it can be observed that our STA-C3DL model exhibits significant advantages in the field of action recognition. Particularly outstanding is its performance on the NTU RGB + D dataset, where it leads other models in nearly all performance metrics, achieving an accuracy of 92.46%, which is nearly 0.5 percentage points higher than the closest model. On the Smarthome Rehabilitation dataset, our model also demonstrates excellent overall performance, especially achieving a notable F1 score of 95.32%, highlighting its high accuracy and stability in handling real-world rehabilitation scenario data. However, on general action recognition datasets like UCF101, although our model maintains a lead in accuracy and F1 score, its advantage is not as pronounced as on specialized rehabilitation datasets. This suggests room for improvement in the model’s adaptability to general action data. For the HMDB51 dataset, our model continues to exhibit strong performance in terms of precision and recall.
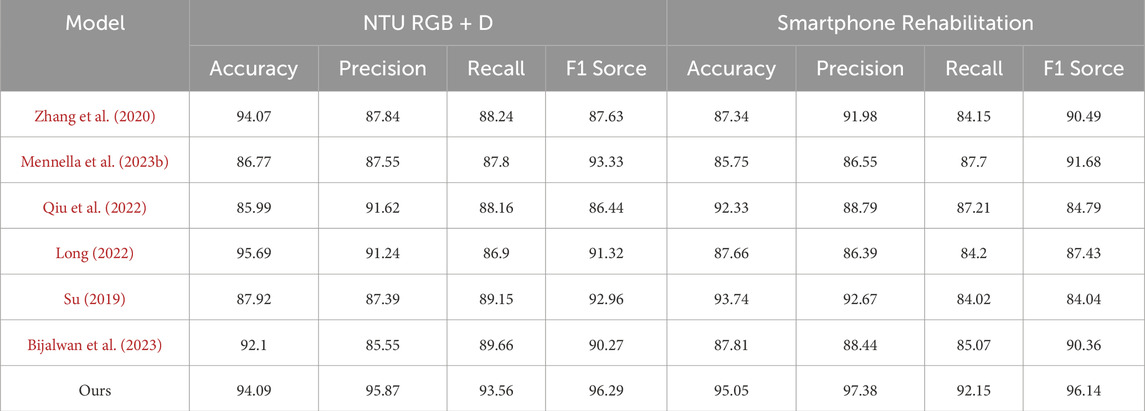
Table 3. The comparison of different models in different indicators comes from NTU RGB + D Dataset and Smartphone Rehabilitation Dataset.
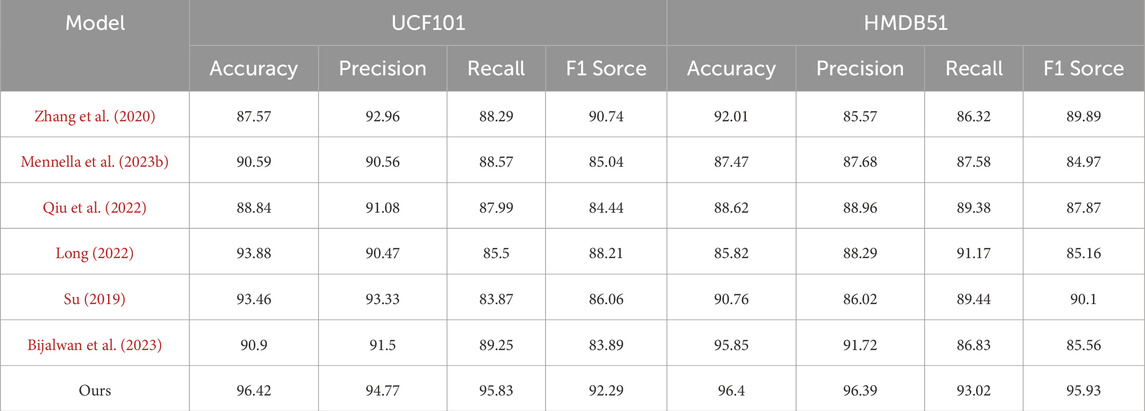
Table 4. The comparison of different models in different indicators comes from UCF101 Dataset and HMDB51 Dataset.
As shown in Table 5 and Table 6 results, we comprehensively evaluated the efficiency of different models by comprehensively comparing the number of model parameters, computational complexity, inference time, and training time. On the NTU RGB + D dataset, our number of model parameters is 338.62M, which has a smaller model volume compared to the other methods. Meanwhile, our model is 5.37 m and 328.18s in inference time and training time, respectively, which are more efficient than most contrast models. On the Smarthome Rehabilitation dataset, our model also has a smaller number of parameters (317.06 M) and a shorter inference time (5.63 m), which fully reflects the high efficiency of our model in dealing with rehabilitation scenarios. On the UCF101 and HMDB51 datasets, our model also performs as well, with a small number of parameters and an efficient inference training time. From the visualization results of Figure 5 in Fig, our model achieves significant advantages in all indices. This further validates the excellent performance of our proposed STA-C3DL model in high efficiency, with higher practicality and operability while maintaining excellent performance.
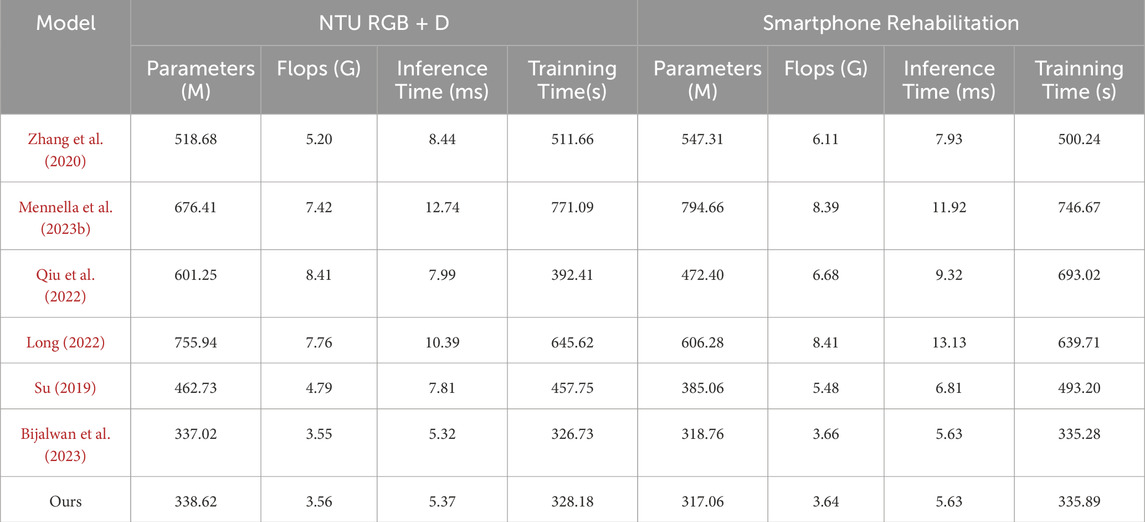
Table 5. Model efficiency verification and comparison of different indicators of from NTU RGB + D Dataset and Smartphone Rehabilitation Dataset.
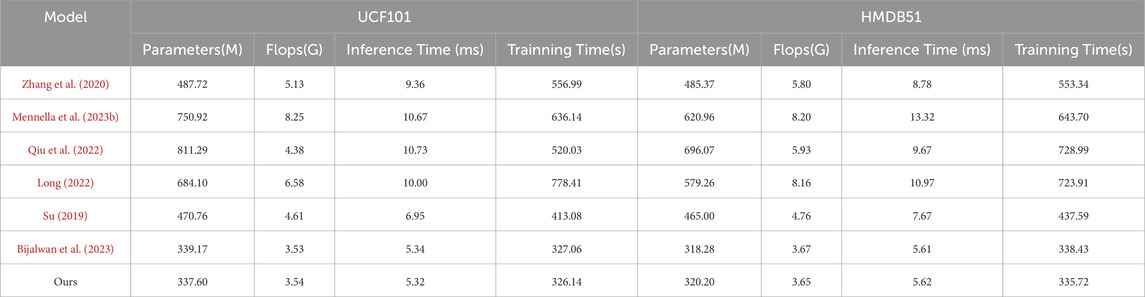
Table 6. Model efficiency verification and comparison of different indicators of UCF101 Dataset and HMDB51 Dataset.
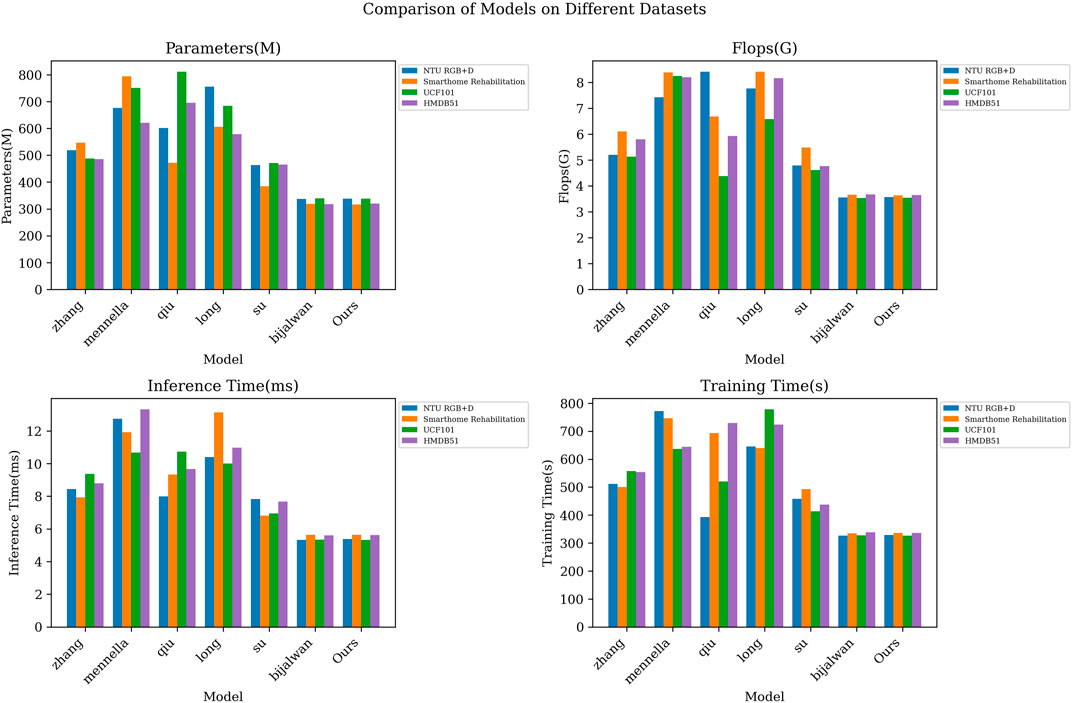
Figure 5. Model efficiency verification comparison chart of different indicators of different models.
As shown in Table 7 and Table 8, we conducted a series of ablation experiments to investigate the impact of different components of the STA-C3DL model on its performance. Across multiple datasets including NTU RGB + D, Smarthome Rehabilitation, UCF101, and HMDB51, we compared four different model variants: LSTM + STAM, C3D + STAM, C3D + LSTM, and the complete STA-C3DL model. The results demonstrated that each component played a distinct role in enhancing the model’s performance.
留言 (0)