
記住我
Early warning of clinical deterioration can provide substantial support for clinicians by facilitating prompt identification of adverse events, allowing for proactive measures or timely interventions (Muralitharan et al., 2021). Accordingly, early warning systems hold immense potential in clinical contexts, particularly where the accurate timing of recognition or treatment is paramount. Of particular interest are sepsis and septic shock, extensively examined in early warning systems due to their elevated mortality rates and diagnostic complexity.Sepsis is defined as life-threatening organ dysfunction caused by a dysregulated host response to infection, while septic shock is defined as a subset of sepsis in which underlying circulatory and cellular metabolism abnormalities are profound enough to substantially increase mortality (Singer et al., 2016) and is characterized by hyperlactataemia and hypotension requiring vasopressor therapy (Hotchkiss et al., 2016). While early treatment can improve patient outcomes (Evans et al., 2021), delayed intervention or recurring symptoms can lead to irreversible deterioration (Kumar et al., 2006). Thus, the development of an early warning system for septic shock can play a crucial role in timely treatment and prevention of recurrence.
Recent approaches to early warning systems for septic shock mainly employ data-driven machine learning based methodologies to generate warnings (Henry et al., 2015; Lin et al., 2018; Khoshnevisan et al., 2018; Darwiche and Mukherjee, 2018; Giannini et al., 2019; Liu et al., 2019; Fagerström et al., 2019; Yee et al., 2019; Khoshnevisan and Chi, 2020; Kim et al., 2020; Mollura et al., 2020; Misra et al., 2021; Wardi et al., 2021; Agor et al., 2022), enabling personalized early prediction with high sensitivity and specificity (Muralitharan et al., 2021). Most of these early warning systems aim to screen patients who are highly likely to show septic deterioration before onset as early as possible. These screening systems can be classified into two categories based on the timing of their alarm mechanisms. The first category, which we refer to as the ‘left-aligned approach’, is centered on making predictions during the initial phase of a patient’s admission. In contrast, the second category, termed as the ‘right-aligned approach’, is designed to forecast septic shock events at a specific duration prior to their actual occurrence. Thus, the ‘left-aligned approach’ aligns cohort data to the start of each patient’s admission, while the ‘right-aligned approach’ aligns data points to the onset of events or the end of a patient’s admission. However, both systems may not be clinically applicable due to their inability to timely identify the risk, as they merely predict if patients would suffer from an adverse event in the future without providing sufficient information regarding the exact time of onset, making it difficult to preemptively prepare for timely actions.
We note that the development of timely early warning systems for clinical deterioration, such as septic shock, necessitates the incorporation of three components: (1) continuous calculation of future risk based on the patient’s health status, (2) consideration of the timely adequacy of predictions based on their located time frame, and (3) appropriate evaluation of predictive performance achieved by the system. First, the incapability of alerting continuously restricts the system to making singular predictions, falling short in meeting the requisites of timeliness. Second, in the context of continuous warning systems, the establishment of a precise interval for timely warnings serves not only to accurately gauge the system’s predictive performance but also to ensure its effective management. Lastly, given the inherent disparity between a warning system designed to capture the onset of adverse events and a screening system, standard metrics employed in previous approaches may not be able to adequately measure the performance of timely warning systems.
In Table 1, prevailing studies on early warning systems for septic shock are summarized with respect to the three essential components for timeliness. To the best of the authors’ knowledge, no current frameworks satisfy all three criteria comprehensively, as most have been developed with a focus on screening rather than continuous monitoring. Although some systems leverage machine learning models capable of generating continuous warnings, such as LSTM (Long Short-Term Memory), XGBoost (Extreme Gradient Boosting), or Cox regression, and have set time windows for true warnings, these systems are still evaluated as screening tools rather than continuous warning systems. Specifically, the time windows used to define true warnings typically fall into one of three categories: the entire duration leading up to septic shock onset, the initial period post-admission, or a distant interval before the onset. As a result, despite their ability to produce continuous alerts, these systems are not optimized for issuing timely warnings. Note the difference between screening-based systems and continuous warning systems, as depicted in Figure 1.
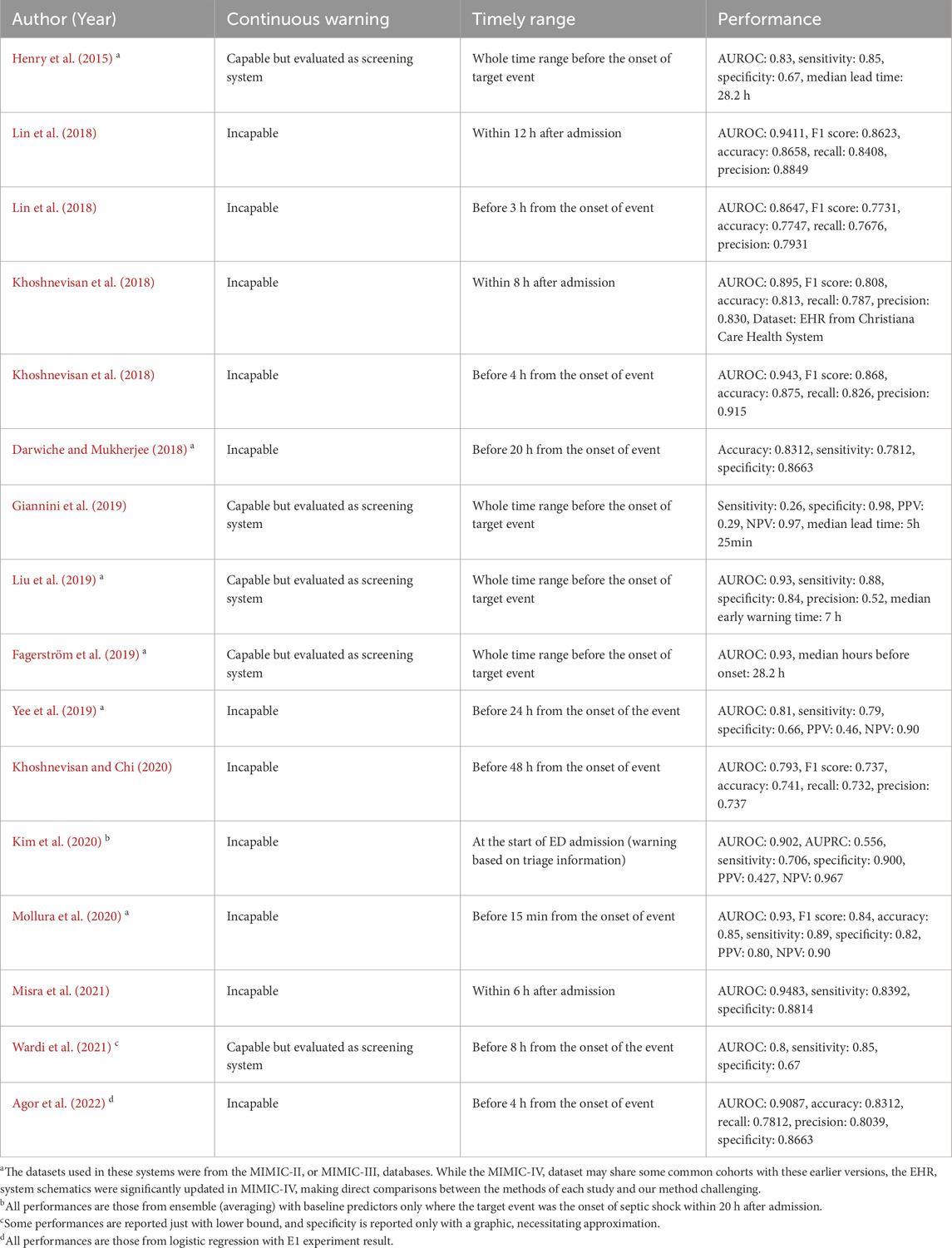
Table 1. Summary of previous early warning systems developed for septic shock.
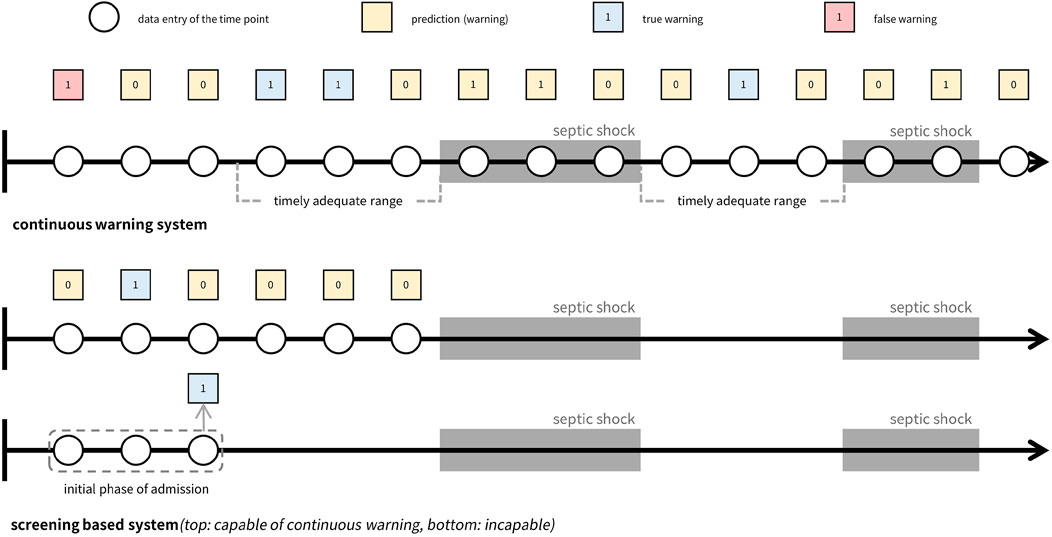
Figure 1. Comparison of continuous warning system versus screening system. The top figure illustrates a continuous warning system that can be managed to generate timely adequate warnings, while the figures below show two types of screening systems. Both screening systems make predictions before the event occurs and concentrates on screening whether a patient will suffer from the event in the future or not. The difference between the systems is their capability of generating continuous warnings where the first screening system is capable of generating continuous warnings while the second type is not capable.
While prevailing research on septic shock prediction systems has not adequately addressed the importance of timeliness, other prediction systems for clinical deterioration have recognized its significance (Tomašev et al., 2019; Hyland et al., 2020). Employing various machine learning techniques, these systems were designed to trigger warnings based on real-time risk score calculations for acute kidney injury and circulatory shock. They defined prediction time windows for true warnings and optimized system performance within these windows to ensure an adequate amount of lead time before the onset of deterioration. This acknowledgment of the importance of timeliness underscores its critical role in facilitating effective disease management across various clinical contexts.
Therefore, in this study, we propose a novel approach to develop a clinically applicable early warning system that addresses all aspects of timeliness. We refer to this approach as the ‘timeliness focusing approach’, which we apply to the development of an early warning system for septic shock, named TEW3S (Timely Early Warning System for Septic Shock). Using the MIMIC-IV (Medical Information Mart for Intensive Care) database (Alistair et al., 2022), we designed TEW3S to generate continuous timely alarms every hour.
2 Materials and methods2.1 Cohort extractionIn this study, we utilized version 2.0 of the MIMIC-IV database, a comprehensive open-source repository containing de-identified health-related data from patients who underwent intensive critical care at Beth Israel Deaconess Medical Center between 2008 and 2019 (Alistair et al., 2022). The database encompasses records of 53,569 adult ICU patients, comprising a total of 76,943 stays. A wide array of medical information, including demographic details, laboratory findings, vital signs, test results, prescriptions, pharmaceutical information, and diagnoses, were extracted from the database to construct the sequential patient data. Supplementary Tables S1, S2 provide a detailed list of the medical information employed in this research, along with the corresponding MIMIC-IV identifiers or extraction methods. Additionally, Supplementary Table S3 summarizes the average frequency of physiological signals, encompassing vital signs and laboratory results.
Given that septic shock constitutes a subset of sepsis and the diagnosis of sepsis necessitates cohorts with suspected infections (Singer et al., 2016), our study cohorts were defined as patients with suspected infections and sepsis prior to the onset of septic shock. Hence, before selecting the cohorts, we excluded those lacking variables necessary for defining sepsis or septic shock, such as systolic blood pressure (SBP), diastolic blood pressure (DBP), PaO2, FiO2, Glasgow Coma Scale (GCS), bilirubin, platelets, creatinine, and lactate.
Suspected infection was defined for admissions meeting three conditions: (1) received antibiotics, (2) blood culture tests had been taken, and (3) infection-related ICD-9 or 10 codes had been issued. Sepsis was only defined for cohorts with suspected infections, with its onset marked when the Sequential Organ Failure Assessment (SOFA) score reached or exceeded two points. Septic shock was only defined after the onset of sepsis, resulting in the exclusion of cohorts where septic shock occurred prior to sepsis. This decision is based on the assumption that timely prediction is more effective in cases where sepsis precedes septic shock, compared to cases where septic shock occurs prior to sepsis, as early intervention is more likely to have already taken place in the latter instances. Note that this approach can lead to the restriction of our research cohort to patients with nosocomial septic shock, and as such, our predictive model may not be applicable to cases of non-nosocomial septic shock. The onset of septic shock was determined when the lactate level equaled or exceeded 2 mmol/L and vasopressor therapy was administered, given that the definition of septic shock includes hyperlactataemia and vasopressor therapy (Hotchkiss et al., 2016).
2.2 Data refinementWe refined the data through several steps, including unit unification, outlier removal, adjustment of time errors, and correction of variable-specific errors. Initially, unit unification was applied to variables with measurements in different units, such as height, weight, temperature, vasopressors, and fluids. We consulted with professional clinicians to establish outlier criteria, drawing on the guidelines from (Hyland et al., 2020), as detailed in Supplementary Table S4. This ensured alignment with both theoretical considerations and practical feasibility in clinical settings. For instance, heart rate values were accepted within the range of 0–300 beats per minute, as values below 0 are theoretically impossible, and values above 300 are extremely rare in clinical practice. Entries falling outside these criteria were identified as errors and subsequently removed.
Time errors, defined as data entries assigned to a patient sequence with timestamps incongruent with the sequence, were adjusted. Entries recorded more than 2 days before admission or 2 days after discharge were deleted. For variables with specific timestamps, such as lab values, entries recorded outside the interval between ICU admission and discharge were excluded. Conversely, for variables recorded continuously, such as pharmaceutical variables and ventilator data, entries with start and end times outside the admission-to-discharge interval were omitted.
Additionally, errors specific to GCS and urine output were addressed. GCS comprises three component variables (eye, motor, and verbal), and its calculation relies on the summation of these components, necessitating consistency in the recorded timing of each variable. For every timestamp of the GCS components, we assumed all GCS information were recorded but some random missing entries could occur. To handle missing values, we employed a forward-and-backward imputation strategy. Urine output calculations involve unique variables, including irrigant in and out values. To accurately measure urine output at specific time points, we subtracted cumulative irrigant in amounts from cumulative irrigant out amounts. For irrigant out values immediately followed by irrigant in values, we recorded the cumulative sum of irrigant out values minus the cumulative sum of irrigant in values, retaining these records for further preprocessing. In cases where no irrigant in values preceded irrigant out values, we assigned the irrigant in value as 0.
2.3 Sequential merging and resamplingAs some data entries were distributed across distinct datasets using different identifiers despite representing the same variable, merging the data into a sequential representation was necessary. We consolidated data entries in the MIMIC-IV datasets according to their respective variables. For entries categorized as vital signs, lab results, height, and weight, all values and corresponding timestamps were collated into a unified sequential timeline for each variable. Pharmaceutical instances were aggregated based on shared timestamps, while administration rates were listed individually. Age at admission and gender were also incorporated into the sequential data. Variables used to define sepsis and septic shock shared identical timestamps and were imputed accordingly based on variable-specific schemes. We adhered to predefined definitions for sepsis and septic shock, excluding cohorts without sepsis and those where sepsis occurred after the onset of septic shock. Subsequently, we performed data resampling, discretizing the concatenated data into predefined time intervals by aggregating or averaging variable values. A 1-h interval was chosen, considering both the dynamic nature of septic shock and the practical frequency of warnings in clinical settings.
For feature engineering, summary statistics were computed within each time interval, including the mean, median, maximum, and minimum values, with the mean serving as the representative value. Additionally, slope features were generated by calculating the difference between values at current and past time points (one, three, and 5 hours prior). These features capture temporal dynamics within and across intervals, facilitating the predictive model’s learning process. Features were not derived for unsuitable variables such as age, drug-related items, and ventilator data. In cases where no feature values were available for a given interval, different imputation methods were applied based on the nature of the data. Lab-related features were imputed using backward and forward filling, while vital signs (excluding GCS), height, and weight were linearly interpolated. This choice of imputation methods reflects the typical frequency with which these variables are recorded in clinical practice (See Supplementary Table S3). Lab measurements are usually taken less frequently and sporadically, so forward and backward filling ensures that the last known value is carried forward until a new measurement is available, preserving temporal continuity. In contrast, vital signs are monitored more frequently, allowing for the use of linear interpolation to estimate values between measurements, which assumes a more gradual and consistent change over time. If a variable was not recorded at all across the cohort, all values for that variable were imputed as 0. To distinguish true zero feature values from imputed ones, we appended presence features indicating whether values were filled by imputation (0) or not (1). This approach accounts for the uncertainty of feature values during prediction generation, as proposed in warning systems for acute kidney injury (Tomašev et al., 2019). Finally, we defined sepsis and septic shock and excluded cohorts using the same procedures as in the sequential merging process. The resulting resampled dataset comprised 11,780 stays, of which 4,369 exhibited septic shock. We partitioned the dataset into training (70%), validation (10%), calibration (10%), and test (10%) sets.
2.4 Timeliness focusing approach via data-task engineeringThe ultimate aim of our approach was to demonstrate a clinically applicable early warning system via successful integration of timeliness within the development course. In pursuit of such a goal, we introduce a timeliness focusing approach which encompasses three main considerations.
First, to ensure the clinical relevance of our system, we evaluated predictive performance from multiple perspectives. We assessed performance not only on all instances of shock onset but also specifically on the first occurrences of shock, which may hold greater clinical significance. Compared to recurring septic shocks, the first onset of septic shock may be of more clinical value as clinicians may not have been aware of the patient’s deteriorating health status. Furthermore, we analyzed performance variations by adjusting the definition of timely warnings through what we termed the ‘evaluation window’, exploring different time points relative to shock onset to accommodate varying clinical needs. Relative to the septic shock onset time denoted as t = 0, the earliest time point of the evaluation window was defined as t = −8 and the latest time point as t = 0. Varying time points between t = −8 and t = 0 were employed to assess the robustness of our system against the varying needs of specific clinical application contexts.
Second, in addition to standard metrics used in screening systems or machine learning models, we introduced two metrics to measure timeliness: Target Event Recall (TER) and True Alarm Rate (TAR). TER measures the proportion of events warned by timely alarms, while TAR quantifies the fraction of timely warnings among both false and timely warnings. Timely warnings are defined as those occurring within the evaluation window, while false warnings exclude those generated during prolonged septic shock events. Although alarms occurring during prolonged shock events fall outside the evaluation window, they remain critical indicators of ongoing elevated risk and should not be classified as false alarms. Furthermore, we utilized modified versions of TER and TAR, termed ‘TER stay’ and ‘TAR stay’, respectively. These metrics provide an average assessment of TER and TAR specifically for stays with septic shock.
As defined, TER and TAR are calculated for individual septic shock events, which may differ from evaluation metrics commonly used in conventional machine learning classification tasks (e.g., True Positive Rate) or those in prevailing screening systems for septic shock. To distinguish these metrics, we term the metrics introduced in this study (TER and TAR) as ‘event-based metrics’. In contrast, standard machine learning task metrics evaluate predictions at each time point, while screening system evaluation metrics are computed for each cohort (e.g., the proportion of cohorts adequately predicted). Hence, we classify the conventional evaluation metrics from machine learning tasks as ‘time point-based metrics’ and those from screening systems as ‘cohort-based metrics’. Figure 2 illustrates the differences between these three types of metrics.
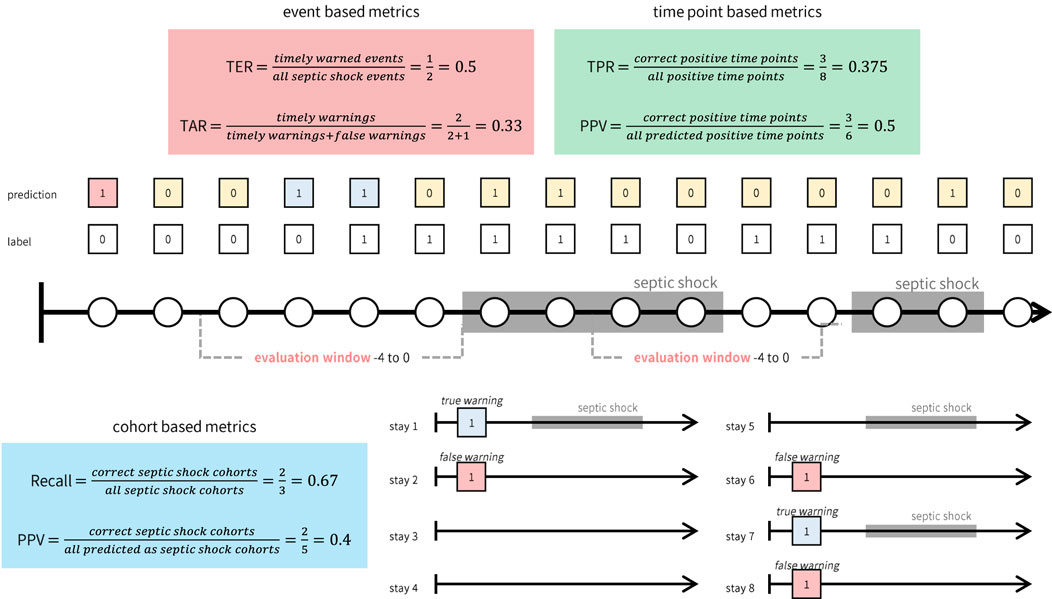
Figure 2. Illustrative example of how event, time point, and cohort based metrics are calculated. While event based metrics (red box) and time point based metrics (green box) are computed based on the continuous warnings generated by the system, cohort based metrics (blue box) can only be computed for each cohort.
Third, to optimize the timeliness of our early warning system, we investigated the impact of various factors on prediction timeliness. These factors encompassed model architecture, deliberate data provision, and the utilization of calibration and oversampling techniques. Our primary focus was placed on data provision, which involves selecting data samples for training and designing prediction tasks with different time windows (prediction window). We termed this approach ‘data-task engineering’, akin to feature engineering, as it aims to optimize predictive performance by manipulating the relationship between input data and prediction targets. This approach distinguishes itself from traditional machine learning-based early warning systems, where timeliness is often overlooked. Even when considered, the typical methodology involves training models with fixed prediction windows and including all possible data samples in the training set. We hypothesized that each data entry possesses distinct characteristics depending on its relative timing to the onset of target events. Thus, systematic inclusion of data samples can guide the model to learn the intended relationship between input data and target events.
As depicted in Figure 3, data-task engineering encompasses three distinct schemes, each tailored to capture specific correlations between the samples and the prediction tasks. The first scheme involves manipulating the prediction window, adjusting the timeframe from 1 hour to 12 h. This variation alters the nature of the tasks learned by the model. The second scheme centers on restricting the use of data after the onset of septic shock. Specifically, we confine the training data to a window spanning from zero to 2 hours post-onset, termed the ‘training window’. Additionally, we consider utilizing all training data samples post-shock onset, labeled as training window ‘all’. Lastly, in the third scheme, we experiment with retaining only the data entries around the initial occurrence of septic shock, referred to as ‘first shock focus’. Through data-task engineering, we aim to further refine the model’s learned function, thus enhancing predictive performance beyond conventional approaches.
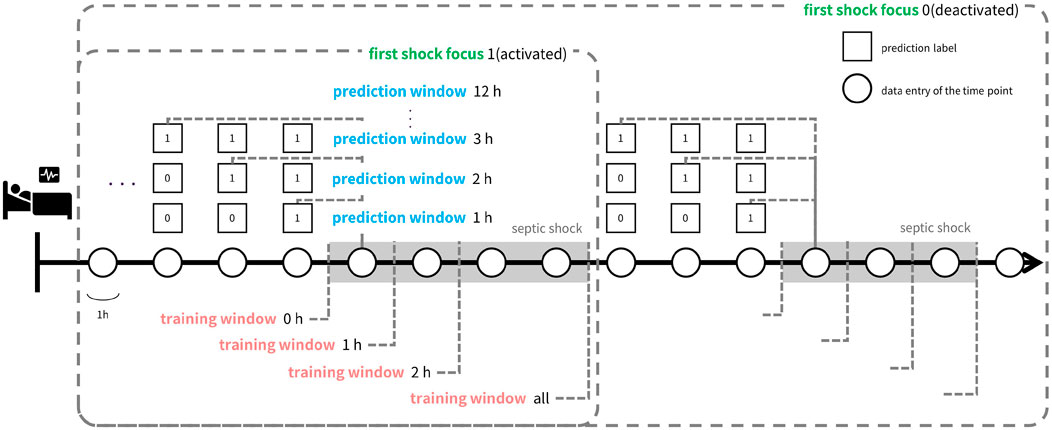
Figure 3. Illustration of data-task engineering approach. Data-task engineering involves three schemes: Prediction window (blue text) alters data labels by labeling the time points within prediction window prior to septic shock onset as positive labels. Training window (red text) determines how much time points after shock onset to include in the train set and first shock focus (green text) controls whether to include data points after the first shock onset in the train set. Thus, prediction window is related to the task of the learning objective while training window and first shock focus controls train set data.
Focusing on the importance of timeliness, we devised a comprehensive modeling and validation process. Initially, we trained and validated the system by exploring various combinations of model architecture, data-task engineering schemes, and auxiliary techniques such as oversampling and calibration. We assessed the predictive performance of each combination, aiming to exceed a clinically applicable threshold. This threshold was meticulously determined in consultation with clinical experts and was defined as a TER of 0.9 and a TAR of 0.2 when predicting all shocks within the evaluation window of −8 to 0. Throughout the training and validation process, our primary objective was to improve TER while maintaining a TAR of 0.2. Once combinations surpassing the threshold were identified, we employed an ensemble approach to consolidate these into the final early warning system, TEW3S. This rigorous approach ensured that our system met the clinical requirements for timely detection of septic shock.
2.5 Predictive modeling for TEW3STEW3S was developed using supervised machine learning models, including CatBoost (Hancock and Khoshgoftaar, 2020), LightGBM (Ke et al., 2017), XGBoost (Chen and Guestrin, 2016), Random Forest (Breiman, 2001), Logistic Regression (Wright, 1995), Decision Tree (CART) (Lewis, 2000), and Multinomial Naive Bayes (Webb et al., 2010). Our predictive model was designed to generate timely predictions every hour, leveraging current-hour data entries that encompassed not only the mean values but also temporal variability features within and across time steps which were derived through feature engineering, along with presence features to enhance model performance. Throughout the development process of TEW3S, auxiliary techniques such as oversampling and calibration were employed. Oversampling techniques like SMOTE (Synthetic Minority Over-sampling Technique) (Chawla et al., 2002) and ADASYN (Adaptive Synthetic Sampling) (He et al., 2008) were utilized to balance the class distribution, while isotonic and sigmoid regression were used for calibration of resultant risk score of prediction models. The hyperparameters of each model were set as Supplementary Table S5.
In assessing the timeliness of model predictions, we also calculated time point-based metrics such as the area under the precision-recall curve (AUPRC). AUPRC aided in selecting candidate settings during training and validation, complementing timeliness metrics by capturing the density of warnings within prediction windows. High AUPRC values, coupled with high timeliness, indicated a high true alarm rate, underscoring the importance of incorporating AUPRC in the training and validation process.
The overall training and validation process for TEW3S comprised three main steps. Initially, we trained and evaluated various supervised machine learning models with several training datasets engineered by data-task engineering scheme combinations, selecting those surpassing clinically applicable thresholds of TER and TAR. We further refined our selection based on time point-based AUPRC metric by identifying combinations with AUPRC values that exceeded the average of selected combinations. Note that these combinations consisted of which machine learning model and data-task engineering schemes to use. Subsequently, we applied auxiliary oversampling and calibration techniques to enhance either TER or TAR and diversified the pool of training settings for constructing ensemble models. This phase yielded 31 distinct training settings that met the clinically applicable criteria for an early warning system, defined as TER 0.9 and TAR 0.2. In the final phase, both soft and hard voting ensembles were constructed using the clinically applicable settings, with the hard voting ensemble outperforming the soft voting ensemble. Thus, we identified the hard voting ensemble as our ultimate choice for TEW3S, an early warning system tailored for septic shock. We implemented this predictive modeling process using Python 3.9 and relevant libraries, including Numpy, Pandas, Matplotlib, and Sklearn.
2.6 Calculation of misalignment between event versus cohort and time point-based metricsTo accurately gauge the predictive timeliness of TEW3S, we relied on event-based metrics, namely, TER and TAR. These metrics offer unique advantages over conventional types of metrics, including both cohort-based and time point-based ones, not only in terms of their intrinsic meanings but also based on the results of numerical experiments. This distinction becomes evident when examining the discrepancy between event-based metrics and other metrics, which is calculated as follows:
1. Initially, we determined the proportion of training settings, comprising various combinations of models and three data-task engineering schemes, that exhibited clinically applicable timeliness (i.e., TER 0.9 and TAR 0.2 within the evaluation window of −8 to 0). We denote this proportion as ‘p’ and the set of settings meeting these criteria as ‘C’. Note that in this context, settings involving oversampling and calibration techniques were excluded, as these auxiliary techniques were only applied to a subset of the training settings.
2. For the cohort and time point-based metrics which include measures related to both event sensitivity and alarm precision, we calculated the one-p percentile of these metrics.
3. Subsequently, for each cohort- and time point-based metrics, we computed the proportion of settings within set ‘C’ that failed to achieve the one-p percentile of the respective metric. This proportion represents the level of discrepancy observed in settings that demonstrated high timeliness but attained lower-ranked performance in other metrics.
This calculated discrepancy proportion underscores the indispensable role of TER and TAR in evaluating predictive timeliness effectively.
3 Results3.1 Predictive performance of TEW3SFigure 4 provides a detailed case study of a septic shock patient from our study cohorts, illustrating the sequential information pertinent to their condition. It presents the patient’s risk score, derived through our timeliness focusing approach, alongside various physiological values and intervention-related variables. Note that the risk score is generated from a model utilized within the TEW3S ensemble.
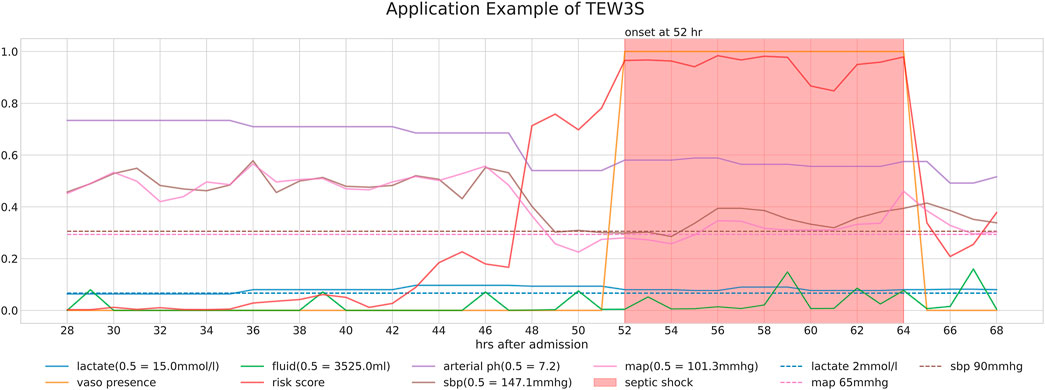
Figure 4. Detailed case study of a septic shock patient from our study cohorts, illustrating the sequential information relevant to their condition. The figure displays the patient’s risk score, derived through our timeliness-focused approach, alongside various physiological values and intervention-related variables.
The temporal changes in these variables and their correlation with the risk score yield insightful observations. During periods of low risk scores, most physiological variables remain stable, except for lactate levels. However, around the 44-h mark, a slight increase in the risk score precedes a subsequent drop in both systolic and diastolic blood pressure (SBP and DBP) approximately 5 hours later. This temporal relationship suggests our approach’s potential to predict future events. Subsequently, around the 48-h mark, a significant spike in the risk score coincides with a sharp decline in both SBP and MAP, falling below critical clinical thresholds of 90 mmHg and 65 mmHg, respectively, further validating the physiological plausibility of the risk score’s increase. Interestingly, despite poor physiological signs after the 44-h mark, there are instances where the risk score decreases, typically following fluid administration. However, the risk score remains significantly elevated after the onset of septic shock at the 52-h mark, persisting until the end of the observation period, even as other physiological variables return to pre-septic shock levels. This persistence suggests the model’s ability to recognize the heightened risk associated with the septic shock state.
Ultimately, our predictive model aims to generate alerts based on the risk score, starting 8 h before the onset of septic shock. The risk score notably begins to rise distinctly from the 44-h mark, precisely 8 h prior to the event, underscoring its predictive capability. Therefore, the TEW3S, resulting from an ensemble of such risk score-based models, demonstrates excellent performance in reflecting both current and future physiological states and the risk of septic shock, offering valuable insights for clinical practitioners. Given the exemplary predictive performance demonstrated in this single case, we further evaluate the predictive accuracy of the hard ensemble-based model TEW3S across all patient stays. By utilizing a hard voting ensemble of models that surpass the predefined threshold, TEW3S achieved a strong performance of TER of 0.9403 and TAR of 0.2018 when predicting all shocks within the evaluation window of −8 to 0. The detailed predictive performance of the early warning system is presented in Table 2. In summary, TEW3S accurately identified 94.0% of septic shock onsets and 93.1% of first septic shock onsets within an 8-h window, with an average of one true alarm for every four false alarms. Additionally, TAR stay, representing the average true alarm rate among septic shock cohorts, reached 0.43 for predicting all shocks and 0.77 for predicting the first shock in the evaluation window of −8 to 0.
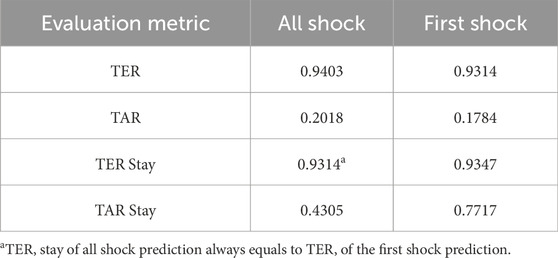
Table 2. Predictive performances of TEW3S in evaluation window –8 to 0.
To assess TEW3S’s effectiveness in clinical settings, we analyzed the number of septic shock events predicted by timely alarms before clinicians initiated interventions (i.e., treatments for septic shock). We defined the initiation of septic shock intervention as the time point of vasopressor and fluid co-administration. Alarms triggered prior to this intervention start time were considered timely. Remarkably, 49% of septic shock events were anticipated by these timely alarms, implying almost half of septic shock events were identified through timely alarms preceding clinicians’ interventions, demonstrating the practical utility of TEW3S in clinical practice.
Additionally, we analyzed TER within different evaluation windows, ranging from −8 to −4 as the earliest time point and −2 to 0 as the latest. The sensitivity analysis results presented in Table 3 illustrate that TEW3S successfully identified over 75% of septic shock events 2 hours prior to onset in the evaluation window starting from −8. Even when considering alarms only within 4 h prior to onset, 91.7% of all septic shock events were accurately predicted in advance. Notably, nearly 70% of septic shock events were timely warned by TEW3S even in the most restrictive evaluation window of −4 to −2, highlighting its robustness across various scenarios.
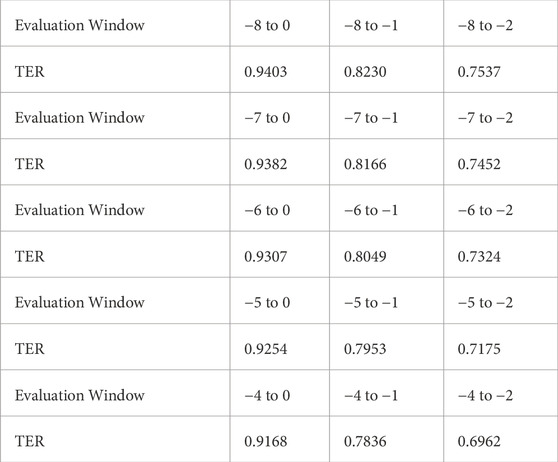
Table 3. TER variation in various evaluation windows.
In comparison to existing literature, we further assessed TEW3S’s predictive performance using cohort-based metrics, including sensitivity, specificity, precision, accuracy, and the F1 score. Note that as TEW3S was constructed using a hard-voting ensemble, AUROC could not be utilized. Given the focus on timeliness, our main evaluation metrics are event-based metrics (TER and TAR) as they are most appropriate for continuous warning systems. Conventional metrics were utilized for comparison purposes only, as they cannot fully capture the performance of continuous warning systems. In evaluating these metrics, we considered only the initial warning when labeling the entire cohort as positive. Consequently, TEW3S demonstrated a sensitivity of 0.9634, specificity of 0.4818, precision of 0.5230, accuracy of 0.6604, and an F1 score of 0.6779. When compared to previous research (Henry et al., 2015; Liu et al., 2019), which reported sensitivities of 0.85 and 0.88, and specificities of 0.67 and 0.84, respectively, TEW3S’s predictive performance aligned closely with these prior approaches. It is worth noting that although TEW3S was primarily designed for superior timeliness rather than optimal screening performance, its effectiveness was comparable to these established models. This suggests that our proposed methodology allows for the development of an early warning system proficient not only in generating timely continuous warnings but also in effectively screening high-risk cohorts.
We further carried out failure case analysis, examining both false alarms and instances where timely alarms were absent. Several rational causes of failures were identified. First, for false alarms, we found that 95% of false alarms were associated with vasopressor, fluid administration, or mechanical ventilation within a 3-h interval. This suggests that most false alarms adequately reflected real patient risk, but subsequent septic shock onsets could have been prevented due to timely treatment by clinicians. Second, for the false negative cases, we observed that 13% of stays without timely warnings experienced a rapid onset of septic shock within 12 h after admission. This indicates that TEW3S may not have had sufficient time to generate timely predictions in these instances. Third, we compared the average values of clinical variables for each failure case: those with false negative cases versus false positive cases (refer to Table 4). The comparison revealed that false warning cases exhibited a worse health state on average than no warning cases. This difference was particularly notable in lactate levels, where the average lactate value for no warning cases was 1.36, whereas for false warning cases, it was 2.42. The proportion of false negative stays with lactate value below 2, 1.5, and 1.1 were 85.7%, 73.5%, and 26.5%, respectively, implying the predictive capability of TEW3S heavily relies on lactate value. Lastly, we extended the timely adequate ranges used in our evaluation criteria. Given that patient risk of septic shock may extend beyond the current 8-h window prior to onset, we evaluated warnings within 24, 48, and 96 h before septic shock onset. This adjustment led to a decline in the ratios of false negatives and false alarms from 4.2% to 42.4%–2.3% and 36.8%, 2.0% and 33.2%, and 1.6% and 30.0%, respectively. Notably, when considering all warnings prior to septic shock as true positives, consistent with the evaluation criteria of previous early warning systems, the proportions of false negatives and false positives dropped to 1.3% and 24.9%, respectively. This finding underscores the importance of incorporating timeliness metrics into the evaluation process and conducting a comprehensive review of the model’s predictive capabilities. In conclusion, the majority of failure cases of TEW3S may be attributed to the mitigation of risk due to timely treatment, the intractability of temporal relationships due to insufficient time before septic shock onsets, and the evaluation criteria that accepts alarms only within 8 h window prior to septic shock onset.

Table 4. Clinical variable level comparison between false negative cases and false positive cases.
3.2 Misalignment of cohort, time point, and event-based metricsAs aforementioned, disparities can exist between event-based timeliness measures and time point or cohort-based metrics due to their inherent differences, emphasizing the importance of selecting adequate evaluation metrics. To explore this incongruity across various training settings, we conducted a range of analyses.
During the initial phase of the training and validation process, we observed an intriguing pattern: training settings demonstrating clinically applicable prediction timeliness did not necessarily yield commendable performances when assessed using time point or cohort-based metrics. This observation is summarized in Table 5, which outlines the proportion of training settings exhibiting this discrepancy. The proportion was calculated as the ratio of settings in which time point or cohort-based performance ranked lower than the percentile corresponding to clinically acceptable prediction timeliness. This analysis revealed that 70% of clinically applicable settings would not be retained if time point-based metrics or cohort-based metrics were the sole criteria for evaluation. This incongruity was particularly pronounced when considering cohort-based metrics, accounting for 100% of clinically applicable settings. Moreover, the maximum event-based metric value achievable among the misaligned settings, indicated by maximum TER or TAR, underscores the potential pitfalls associated with evaluating early warning systems solely based on time point-based metrics or cohort-based metrics.

Table 5. Misalignment proportions of conventional metrics.
To further illustrate the misalignment between timeliness measured by event-based metrics and performance measured by cohort or time point-based metrics, we visualized the correlation of event-based metrics with the other two metrics, as depicted in Figure 5. From the variation of the mean TER in relation to the time point metric, we observed an almost flat or even declining trend in the middle bins, while the mean TAR in relation to the cohort-based metric demonstrated fluctuations at positive predictive values (PPV) lower than 0.4. Additionally, the shaded areas within the figures, indicating the minimum and maximum values of the corresponding TER or TAR, demonstrated a large dispersion of TER and TAR for each binned metric. Overall, the disparity between event-based metrics and other customary metrics was substantial and exhibited considerable variations.
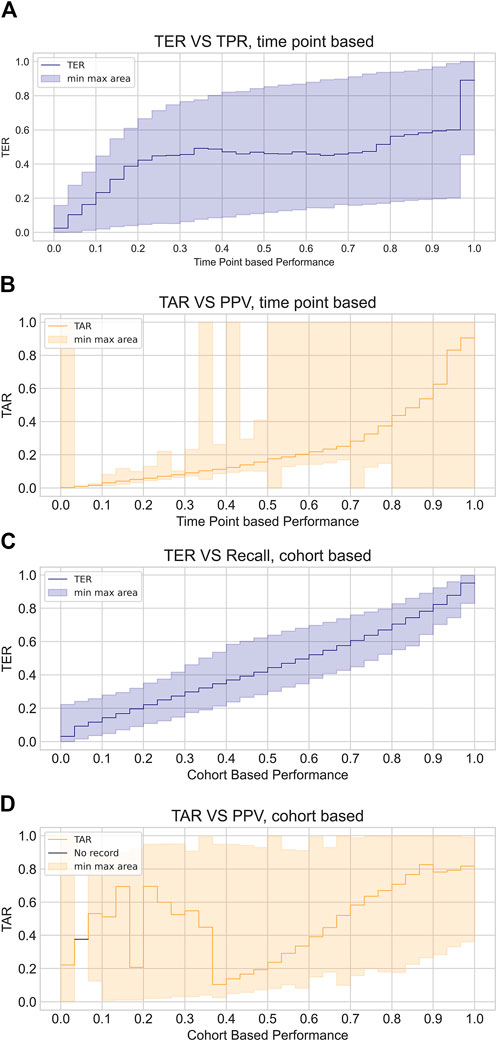
Figure 5. Visualized discrepancy between event based metrics and customary metrics. The plots illustrate the average event based performance corresponding to each binned intervals of time point based measures or cohort based measures, where plot (A) and (B) demonstrate TER and TAR variation with respect to time point based metrics while plot (C) and (D) show those in relation to cohort based metrics. TER is depicted in blue line and shaded area while TAR is depicted with orange line and shaded area. Line indicates average TER and TAR of each bins and shaded area shows maximum and minimum values of TER and TAR of the corresponding bins.
3.3 Variation of prediction timeliness by data-task engineeringBased on several hypotheses regarding the impact of data-task engineering schemes and auxiliary techniques on prediction timeliness, we systematically integrated these factors into the system development process. Initially, we conjectured that factors leading to an increase in positive samples would elevate TER but decrease TAR, given their influence on augmenting the probability of positive instances within the model input distribution. Furthermore, we anticipated that data-task engineering schemes could enhance prediction timeliness while potentially introducing a trade-off between TER and TAR. For example, expanding the prediction window could broaden the model’s foresight, potentially leading to heightened overall risk assessment before shock onset. Similarly, extending the training window to include samples during septic shock prolongation might enable the model to discern physiological cues indicative of critical health states, but this could also induce overreliance on these cues. Additionally, training the model using information encompassing the dynamics around every septic shock event might render the model sensitive to predicting all septic shock onsets but less so to first shock events. These scenarios could result in higher TER but reduced TAR, while the last data engineering scheme can also provoke a trade-off of system performance on early prediction of all shock onsets versus initial onsets.
To numerically validate these hypotheses, we computed the average TER and TAR of each data-task engineering scheme, focusing on the prediction of all shocks within the evaluation window of −8 to 0. Figure 6 presents the average TER (6a, 6b, 5c) and TAR (6d, 6e, 6f) variations along the risk threshold for each setting of the prediction window, training window, and restrictive data usage around septic shock, respectively. The visualized results support our hypotheses regarding the impact of data-task engineering schemes on TER and TAR. Overall, the plots depict a tendency where wider prediction windows and training windows, as well as using all septic shock events as training samples, tend to raise TER but decrease TAR. Moreover, the TAR variation averaged by prediction window peaked at higher thresholds as the corresponding prediction window increased, aligning with the conjecture that widening prediction windows would lead to an increase in risk scores before septic shock onset. Lastly, restricting the training set to the data entries around the first shock onset only enhanced system performances. These results suggest the existence of a trade-off for each data engineering scheme, emphasizing the need for a deliberate exploration of these schemes to achieve an optimal-performing system.
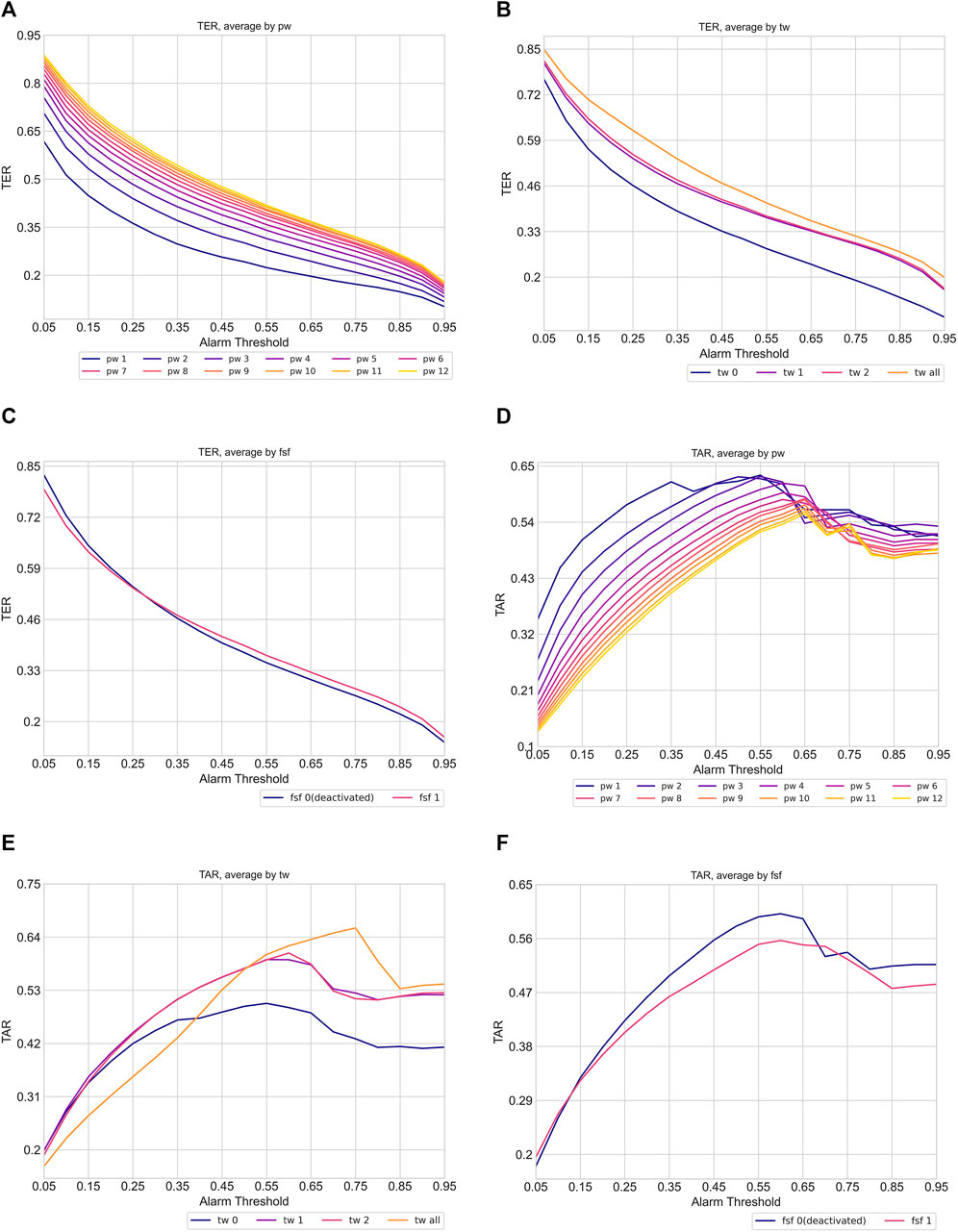
Figure 6. Variation of timeliness averaged by data task engineering schemes (pw: prediction window, tw: training window, fsf: first shock focus). The plot (A), (B) and (C) show TER variation while plot (D), (E), and (F) indicate TAR variation. Each line in the plots indicates the average TER and TAR of corresponding data task engineering scheme configuration. The color of the line becomes brighter when corresponding scheme configuration increases.
Furthermore, to demonstrate the necessity of data-task engineering, we investigated training settings that achieved high timeliness (TER 0.9 and TAR 0.2 in the evaluation window −8 to 0) using conventional early warning system development approaches. In standard development approaches without considering data-task engineering, the most commonly utilized settings would involve employing the same prediction window as the evaluation window (prediction window of eight when evaluating −8 to 0), using all data samples as the training set including those during shock duration (training window ‘all’) or not using at all (training window 0), and not differentiating between first and recurring septic shock events (first shock focus 0). Notably, there were no training settings that achieved high timeliness with conventional approaches. Even when the TER criterion was reduced to 0.85, only 1.9% of the settings comprised standard schemes. These results underscore the substantial enhancement in timeliness achieved by employing data-task engineering schemes, which were scarcely employed in previous approaches.
4 DiscussionIn this study, we developed TEW3S, a continuous early warning system designed to timely identify septic shock by utilizing various machine learning techniques and carefully selecting training samples from the MIMIC-IV dataset. TEW3S successfully predicted 94.1% of all septic shock onsets and 93.1% of first septic shock onsets, providing a lead time of up to 8 hours at a ratio of four false warnings for every true warning. Notably, TEW3S demonstrated a high predictive sensitivity even within highly restricted windows of early warnings, managing to predict more than 75% of septic shock events 2 hours in advance and 91% of septic shock events within a 4-h window. The strong performance of TEW3S under the constraints of a timely adequate range emphasizes the effectiveness of our development approach in constructing a clinically applicable septic shock early warning system. Furthermore, despite TEW3S not originally being designed for screening high-risk patients, it achieved comparable results to previous research studies in this regard. While our system showed significant sensitivity in an
留言 (0)