
記住我







We used data from a cross-sectional study conducted by icddr,b from October – November 2019 in Bangladesh. The study was conducted in 13 sub-districts located adjacent to 12 different hard-to-reach coastal areas of Bangladesh (Additional file 1: Appendix 1).
Study population, sampling technique and sample sizeThe study included mothers who delivered six months prior to the survey. The survey’s inclusion criteria were recently delivered mothers with a child aged 0 to 6 months. A simple cluster sampling procedure was implemented to select the mothers. A total of 1300 recently delivered mothers were finally interviewed.
Data collectionThe data was collected through a face-to-face interview with the help of structured questionnaires. The questionnaire consisted of socio-demographic characteristics, ANC history, PNC history, delivery history. It specifically asked the information on the number of ANC visits, PNC visits, and the place of delivery. A team of field research managers and six female data collectors were trained in research ethics and questionnaire administration. Face to face interviews were conducted to collect the data.
Outcome variablesThis study employed four outcome variables: receiving four or more ANC, facility-based delivery, PNC within 42 days, and receiving all these three above-mentioned maternal health services. These four variables were considered being binary variables in conducting the analysis. The first outcome variable, four or more ANC visits was recorded as a 1 for mothers who had four or more ANC visits, whereas those who had less than 4 visits were coded as 0. The place of the delivery is indicated by the second outcome variable, facility-based delivery. Respondents were asked about whether the delivery was at home or health facilities, including medical college hospital, district hospital, upazilla health complex, family welfare center, NGO clinic, private medical college hospital/clinic. The place of delivery had been grouped into two categories, home and facility-based delivery and coded as 0 for home delivery and 1 for facility-based delivery. A response to the third outcome variable, PNC within 42 days, was recorded as 1 if the respondents received PNC within 42 days, otherwise, it was coded as 0. The fourth outcome variable receiving all maternal health services (four or more ANC, facility-based delivery and PNC within 42 days) coded as 1 if the respondents received all above-mentioned maternal health services otherwise coded as 0.
ExposureIn this study, we considered maternal educational level as the exposure, analysing it both as a continuous variable and as a binary categorised scale. The education system in Bangladesh has three levels: primary, secondary and higher education [28]. Aside from that, as indicated by the National Education Policy (2010), the primary education level has been extended to the eighth grade [29]. This study categorised the mother’s education level into two groups. An education level with > 8 was used to classify the individual as exposed to secondary or higher education level, coded as 1, otherwise introduced as having below the secondary level of education, coded as 0.
CovariatesSeveral socioeconomic and demographic characteristics were considered as potential covariates in this study based on the literature review and the design of the study. These included religion (Islam and Others), husband education (> 8 and < = 8), distance to health centre in km (0–1, 2–3, and 4 or more), age at marriage in years (less than 18, 18 or more), pregnancy number (1, 2, 3, and 4 or more) and wealth quintile (poorest, poorer, middle, richer and richest). Wealth quintile was calculated based on ownership of household goods (such as housing materials, type of latrines, availability of electricity, and ownership of radio and/or television, etc.) using the principal component analysis (PCA) method.
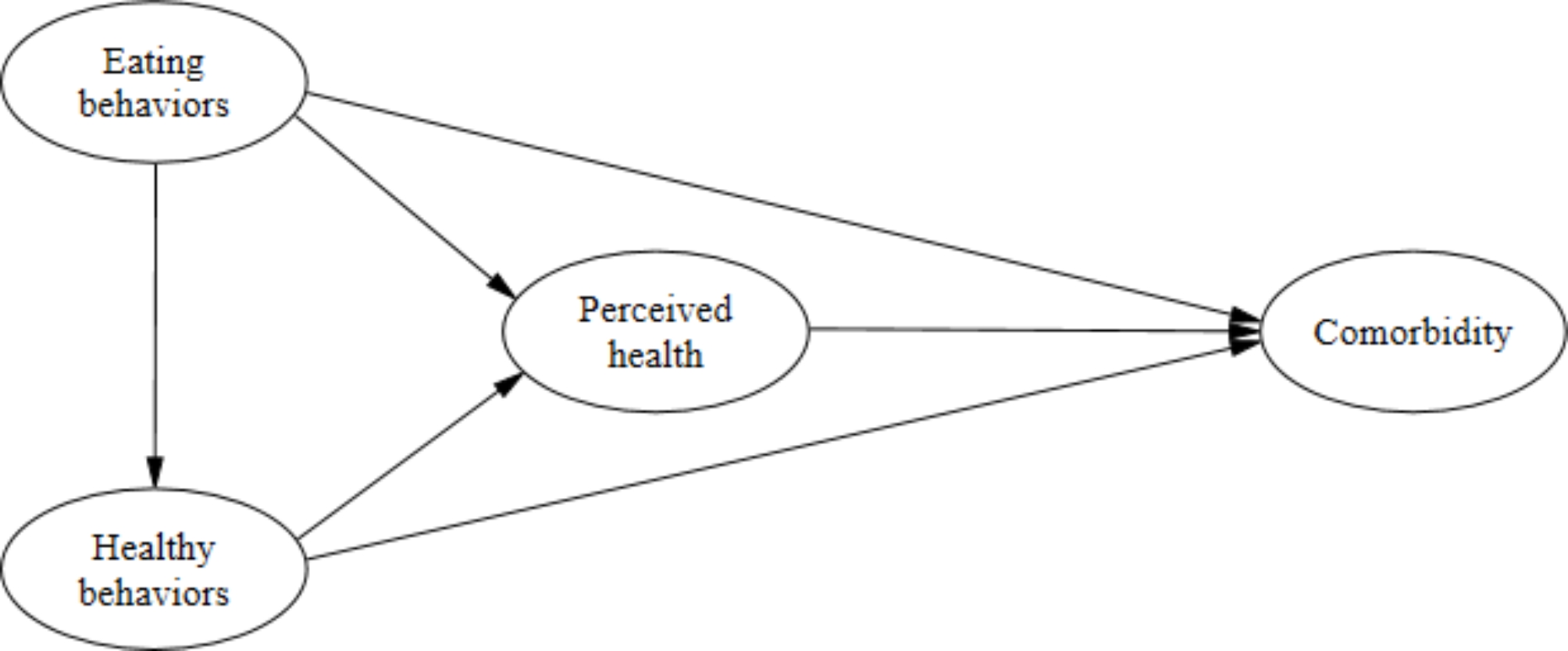
Figure 1 presents the relationships between the variables to illustrate the hypothesised causal relationships between maternal education and the utilisation of maternal health services. We identified maternal education as exposure and utilisation of maternal health services as outcome variables, and rest of the variables as covariates as we aimed to isolate the total effect of maternal education on receiving maternal health services without any decomposition, by adjusting for all measured covariates.
Fig. 1
Causal diagram indicating relationship among covariates, maternal education and the utilisation of maternal health services
Statistical analysisWe used the statistical software package Stata 14 [30] and R 4.3.3 [31] to perform the analysis. Descriptive statistics, including frequency and percentage were used to illustrate the distribution of the mothers receiving maternal health services across a set of socioeconomic and demographic characteristics. To show the distribution of maternal education within the same set of characteristics, we reported frequency and percentage for categorised maternal education, and mean and standard deviation (SD) for continuous scale of maternal education. The p-value from the chi-square test in case of categorical variables and two sample t-test (covariates with two categories) or ANOVA (covariates with more than two categories) for continuous variables were reported to show the association or difference, respectively. We used the propensity score (PS) methods to reduce the confounding effect and assess the causal effect of exposure considering both binary and continuous exposure to investigate whether the effects of maternal education on receiving maternal health services (ANC, facility-based delivery and PNC) exists. We fitted modified log-Poisson regression models employing generalised estimating equations (GEE) framework to account for clustered data obtained from 13 sub-districts for our four binary outcome variables. The modified log-Poisson approach is generally preferred to estimate risk ratio (RR) in case of binary outcome variables [32]. In the context of GEE to analyse clustered outcome data, we have used an exchangeable working correlation matrix. It is natural to use such a working correlation matrix when the outcome data are measured at a single point in time and the clustering arises through some natural grouping of individuals (e.g., in different areas) [32]. We reported crude RR, adjusted RR, RR after incorporating PS and their corresponding 95% confidence interval (CI) from the modified log-Poisson regression models under GEE approach. A study conducted by Elze et al. (2017) using four observational cardiovascular studies, reported standard error (SE) on the effect (i.e., log hazrd ratio) scale, and compared which method provides precise estimates based on SE. We compared the commonly used PS methods (matching, weighting, covariate adjustment), along with unadjusted and multivariate adjusted method in terms of CI range. We considered the usual sandwich variance estimator when employing weighting approach. Absolute standardised mean differences (SMDs) before and after incorporating PS were used to assess the balance in covariates. For binary variable, SMDs are calculated as difference between two sample percentage derived from exposed and unexposed groups divided by the pooled standard deviation, \(\:_=\:\frac_-_}_\left(1-_\right)+_(1-_)}}}\), where \(\:_\:\) and \(\:_\) are the weighted prevalence of covariate j in exposed and unexposed group. Absolute SMDs values of less than 0.1 are considered negligible [33].
Propensity score methods for binary exposurePropensity scoreThe probability of receiving a treatment conditional on a set of observed covariates is known as the propensity score [23]. It can be defined as, \(\:}_}=\varvec(}_}=1|}_})\); \(\:\varvec=\text,\dots\:\varvec\), where \(\:_\) is the treatment indicator (exposure: maternal education, taking 1 if mothers exposed to secondary or higher level of education), \(\:_^}\text\) (religion, husband education, distance to health centre, age at marriage, pregnancy number and wealth quintile) are the given covariates and \(\:_\) is the propensity scores (PS) [23]. The propensity scores (\(\:_\)) were estimated using modified log-Poisson under GEE approach, where maternal education status as the dependent variable and all other given covariates serving as covariates in the model.
PS matchingPS matching is the process of producing matched sets of exposed and unexposed subjects who have a propensity score that is similar in value to one another [34]. Pair matching (one-to-one matching) is the most common application of PS matching [33]. Only one untreated subject (below the secondary level of education) is matched to one treated subject (exposed to secondary or higher education level) who have similar estimated PS value to produce matching pairs in pair matching. As a result, this method may not utilise data from all participants. This matching can be improved by persisting that pairs cannot differ by more than a fixed value which is called caliper. We considered a caliper of width equal to 0.2 of the standard deviation of the logit of the propensity score as this caliper width has been found to perform well in a wide variety of settings [35]. We also considered two-to-one matching in our analysis to have a larger sample in PS matching analysis, where two untreated subjects are matched to one treated subject. PS matching provides an estimation of the average treatment effect among the treated (ATT) parameter [21], focusing on the mothers who received secondary or higher education.
PS weightingThis method utilise data from all participants. There are various types of weighting methods, including inverse probability of treatment weighting (IPTW), standardised mortality ratio weighted (SMRW) and stabilised weighting (SW) method. This present study samples are weighted using commonly used inverse probability of treatment (exposed to secondary or higher education level or not) weighting [33, 36] to ensure that they are representative of specific populations [37]. The IPTW that documents estimation of the average treatment effect (ATE) parameter can be defined as, \(W_1=\frac z+\frac\). An alternate weight that documents estimation of the ATT can be defined as,\(W_2=Z+\left(1-Z\right)\frac_i}_i}\) (Z is the indicator of maternal education status and \(_i\) is the estimated propensity score) [34]. These weights are then incorporated into the outcome model. Marginal computations was conducted to determine the treatment effect (maternal education) on the outcome (usage of maternal health services) [38].
PS covariate adjustmentThis method utilise data from all participants. In the covariate adjustment approach, an indicator variable denoting exposure condition (exposed to secondary or higher education level or not) and the estimated PS is used to model the outcome variable (usage of maternal health services) [33]. This approach provides us with the estimation of ATE parameter [21].
Generalised propensity score methods for continuous exposureAustin et al. (2019) [39] considers \(\:r\left(t,x\right)\) to designate the conditional density of the continuous exposure given the observed baseline covariates, using the terms \(\:r\left(t,x\right)=\:_\left(t\right|x)\) [40]. In our case, considered T as the continuous exposure, where \(\:R=\:r\left(t,x\right)\) is the generalised propensity score. It is suggested that one may set out that, the continuous exposure T given covariate X, is normally distributed with mean \(\:^X\) and variance \(\:^\) [41]. Thus, we estimated \(\:_\) by the normal density \(\:\frac^}}^^X)}^}^}}\). This is a two-step process where a regression model is first fitted to the data, and in the second step, the value of the conditional density function is determined at the value of quantitative exposure. To estimate the GPS, we fitted linear model under GEE approach where continuous maternal education is the dependent variable and baseline covariates worked as covariate in the model. However, in the context of a binary exposure, matching is a well-established approach in causal inference. Though, in the context of a continuous treatment or exposure, matching is not [42].
GPS weightingA stabilising factor is considered in practice in GPS to discard the large weights [43]. We derived weights from the GPS and that is defined as \(\frac\) [39, 44, 45], where the numerator is included to make stable the weights, final estimated stabilised IPW. A reasonable choice for W has been suggested as an estimate of the marginal density function of T [45]. This density function was determined by computing the mean and the variance of the continuous exposure in the overall sample [39], \(W\left(T_i\right)=\frac1^2}}e^\right)^2}^2}}\). These weights then were applied in a weighted outcome regression in order to estimate a causal effect. This approach provides the ATE estimation parameter [41].
GPS covariate adjustmentTo perform the covariate adjustment using the GPS, the outcome is regressed on the quantitative exposure and the estimated GPS [40]. This approach yields the estimated parameter for the average treatment effect (ATE) [41].
Simple and multiple regressionsFor both cases (binary exposure and continuous exposure), simple and multiple modified log-Poisson regressions within GEE framework were used to estimate the effect of maternal education on maternal health services. Simple model that is unadjusted method estimates the crude association between maternal education and the utilisation of maternal health services without controlling for confounders. Multiple adjusted method performs regression model adjusting for potential confounders, shared adjusted estimate of association.
留言 (0)