
記住我







In this section, we first show how the VAE supports searches of the feasible molecules. Further, we state the limitations of the Vanilla VAE in proceeding with this work. Then, we establish that VAE along with a property estimator (an experimentally proven model [17, 19, 20, 25]) can adjust the latent space to over this limitation. Thereby, we elucidate theoretically aspects of the previous approach.
Variational Auto-Encoder (VAE)We describe first a paradigm of VAE. VAE is trained to maximize the evidence lower bound(ELBO) of \(\log }}()\) with the inferred \(}}(|)\) as follows [26, 27]:
$$\begin \begin }_}}(,)}[\log }}(|)]-}_}}()}[}_(}}(|)||())] \end, \end$$
(1)
where both \(\) and \(\) parameterize the encoder distribution and generator distribution; \(}_(\cdot ||\cdot )\) is the Kullback-Leibler divergence that stands for approximating the posterior \(}}(|)\) to the prior \(()\) (typically \(()=}(0,1)\)). In this regard, minimizing \(}_}}()}[}_(}}(|)||())]\) can be interpreted as minimizing
$$\begin I^}(;)+}_(}}()||}}()), \end$$
(2)
where \(I^}(\cdot ;\cdot )\) is the mutual information, which follows the encoder distribution \(\) [28, 29]. Moreover, maximizing \(}_}}(|)}[\log }}(|)]\) can be interpreted as minimizing
$$\begin -I^}(;)+}_}}()}[}_(}}(|)||}}(|))]. \end$$
(3)
Therefore, both \(}_\) and the reconstruction error oppositely control \(I^}(,),\) which is proportionate to the amount of information that can be transmitted through the latent space [29, 30]. Then, we can rewrite the ELBO of the VAE as
$$\begin \begin -}_}}()}[}_(}}(|)||}}(|))]-}_(}}()||}}()) \end, \end$$
(4)
which is the same as \(}_(}}(,)||}}(,))\). One can also derive that global optimum is reached when satisfying \(}}(,)=}}(,)\) [29]. That is, the VAE approximates the encoder distribution and generator distribution while training.
VAE for discovering optimal moleculesIn this section, we formulate a way for finding user-preferred molecules in VAE-based model. We suppose the situation about the encoder and generator are approximated to the each other, i.e., \(}}(,)=}}(,)\). Also, we let \(=c\) as a optimal properties, and we introduce both \(}}(,,)\) and \(}}(,,)\) for explanation.
$$\begin }}(,,)=(|)}}(,),\;}}(,,)=(|)}}(,). \end$$
(5)
Simply, if we know the distribution \(}}(|=c)\), we can apply ancestral sampling \(\sim }}(|)}}(|=c)\) to find \(\) that meet \((=c)\) constraint. Here, with the condition \(}}(,)=}}(,)\), we can replace \(}}(|)\) to the \(}}(|)\) (Because, \(}}(,,)=}}(,,)\) is satisfied). Then, we can also sample the \(\sim }}(|)\) by sampling from \(\sim }}(|)(|)\). The entire procedure is described as
$$\begin \sim }}(|)}}(|)(|=c). \end$$
(6)
Intuitively, we get samples \(\sim (|=c)\) from the dataset. Next, we randomly sample \(\sim }}(|)\) with \(\). Then, we can generate \(\) from the \(}}(|)\) with randomly sampled \(\). That is, we can get a theoretical way for imitating \(\sim }}(|=c)\).
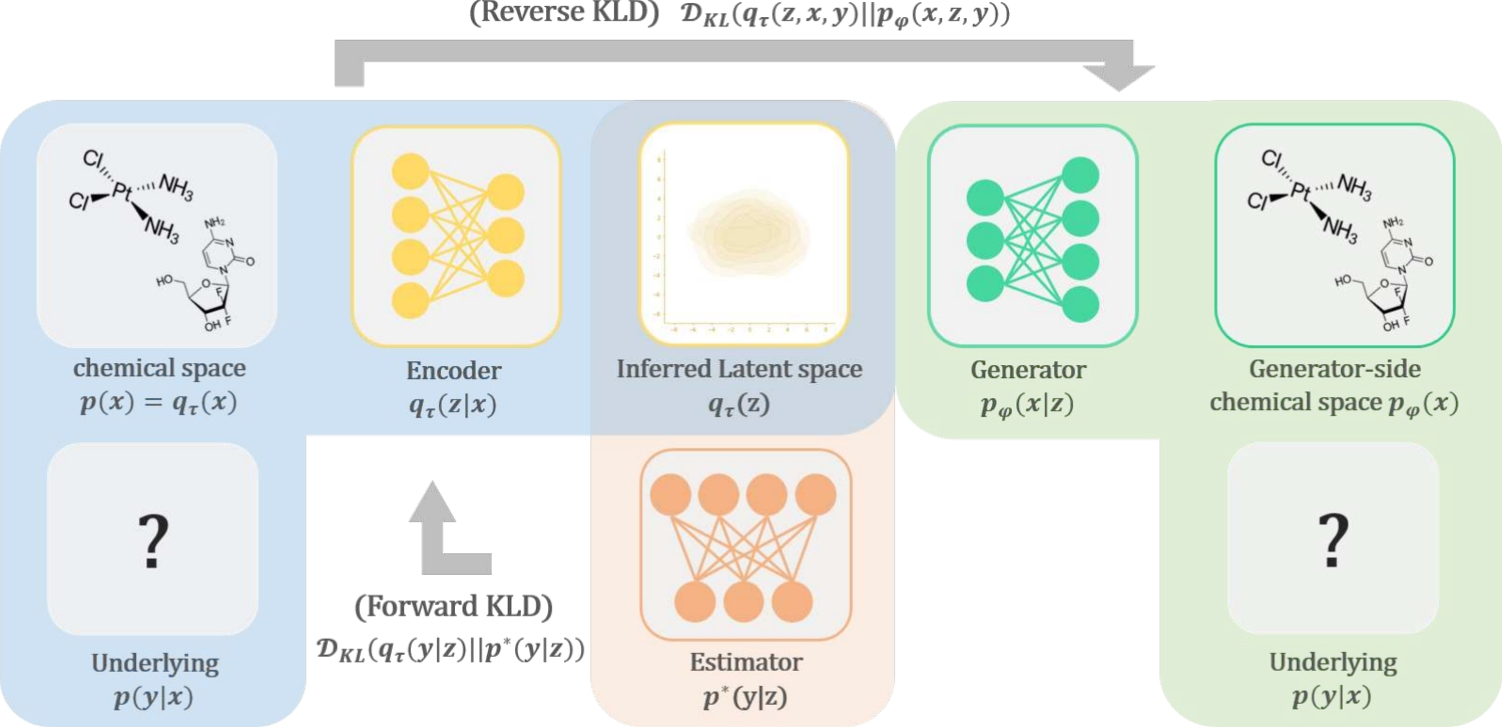
Fig. 1
Illustration of the proposed model. The two important approximations are forward \(}_\) between \(}}(,)\) and \(^(,)\) and reverse \(}_\) between \(}}(,,)\) and \(}}(,,)\) (In the Equation (5)). Here, for the domain of the \(}}()\), it indirectly approximates \(^(,)\) and \(}}(,)\)
Limitation of the vanilla VAEDue to the inherent problems of VAE, the mentioned approach in the above section may not work properly. Let’s consider a case about \(}}(|)=}}()\). In this case, \(}}(|)\) also becomes \(}}()\) (the global optimum reveals \(}}(,,)=}}(,,)\)). Then, we can not consider properties \(\). Therefore, if we want to generate a molecule considering the properties \(\), \(}}()\) should have the information of \(\) as
$$\begin \text \; I^}(;), \end$$
(7)
which maximizes how much the \(\) information can say about the information of \(\). However, VAE cannot ensure that \(I^}(;)\) becomes sufficiently enough. Basically, VAE is independent of this term. Also, Equation (4) is an ill-posed problem [31, 32]. Thus, the content of the latent space information is not guaranteed [33, 34]. Also, the VAE can not sample \(\sim }}(|=v)\) when the condition v is unseen label in the dataset.
Attaching properties estimatorBy attaching property estimator to the latent space, the previous research showed successful experimental results [17]. In this study, the objective function which should be maximized was defined as follows.
$$\begin \begin }=}_}}(,)}[\log }}(|)]-}_()}[}_(}}(|)||())]&\\ +}_}}(,)}[\log ^*(|)}]&\end, \end$$
(8)
where the last RHS term is the negative prediction error of \(\), and \(}}(,|)=}}(|)(|)\). Note that \(^*(|)\) is a property estimator defined with an regression model to estimate the continuous \(\) on \(}}()\):
$$\begin ^*(|)=-}())^2)}/}, \end$$
(9)
where \(}()\) is a neural-network which returns the average of \(^(|)\). In the next section, we attempt to elucidate how this simple model overcomes the aforementioned limitations.
Information-theoretic reinterpretationFirst, we describe what is the benefits of the mentioned models above. In this aspect, we reformulate Equation (8). Recall that \(}_}}(,)}[\log }}(|)]-}_}}()}[}_(}}(|)||())]\) is interpreted in the Equation (4). In addition, the negative prediction error \(}_}}(,)}[\log ^*(|)}]\) can be formulated as
$$\begin \begin&}_}}(,)}[\log ^*(|)}]=}_}}(,)}[\log \frac^(|)}}}(|)}\frac}}(|)}()}()]\\&=}_}}()}[-}_(}}(|)||^(|))]+I^(;)-}(), \end \end$$
(10)
where the last-term is constant. By integrating above equation and Eq. 4, we can interpret \(}\) as following
$$\begin \begin }&=I^}(;)-}_}}()}[}_(}}(|)||^*(|))]\\&-}_(}}()||}}())-}_}}()}[}_(}}(|)}||}}(|))]\\&-}()-}(). \end \end$$
(11)
Then, it satisfies the constraint of latent optimization by maximizing \(I^(;)\) in a supervised manner. Also, it minimizes \(}_}}()}[}_(}}(|)||^*(|))]\). Thus, for the domain of \(}}()\), this approximates \(}}(|)\) and \(^*(|)\) to each other. Thus, we can get a approximation relationship between \(}},}}\), and \(^\) (shown in the Fig. 1). Here, even the condition v is unseen before, their approximation enables finding a latent code \(\eta\) having high \(\log }}(=v|=\eta )\).
Enabling gradient-based searchIf the model reaches to the global optimum, \(}}(,,)=}}(,,)\) and \(\sim }}(),\;}}(|)=^(|)\) are satisfied. Consequently, \(}}(|)=^(|)\) is also satisfied. Then, as an alternative of sampling from \(}}(|=c)\), we can consider finding latent code \(\eta\) with high \(\log }}(=c|=\eta )\) to sample \(\sim }}(|=\eta )\). That is, it make sense to find \(\eta\) maximizing
$$\begin \log ^(=c|=\eta )=}(\eta ))^2}-\log }. \end$$
(12)
Then, based on the differentiability of the neural-network, the gradient-based search can be performed with \(\nabla _}}()\).
留言 (0)