
記住我

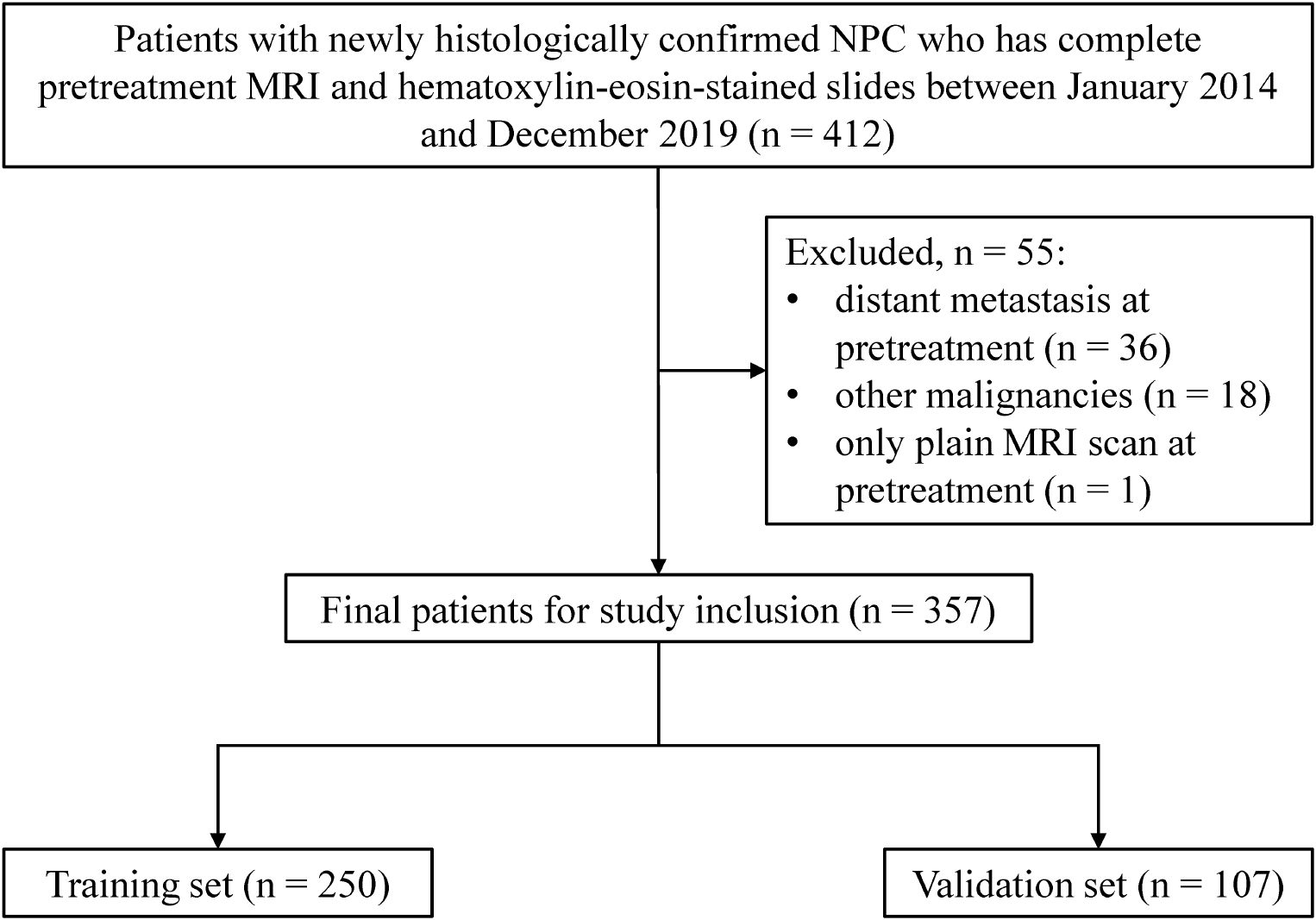


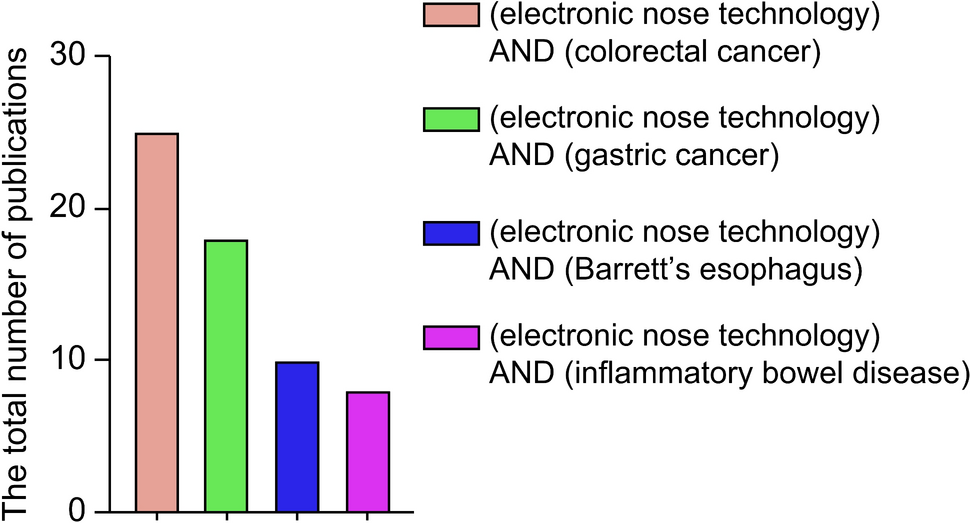
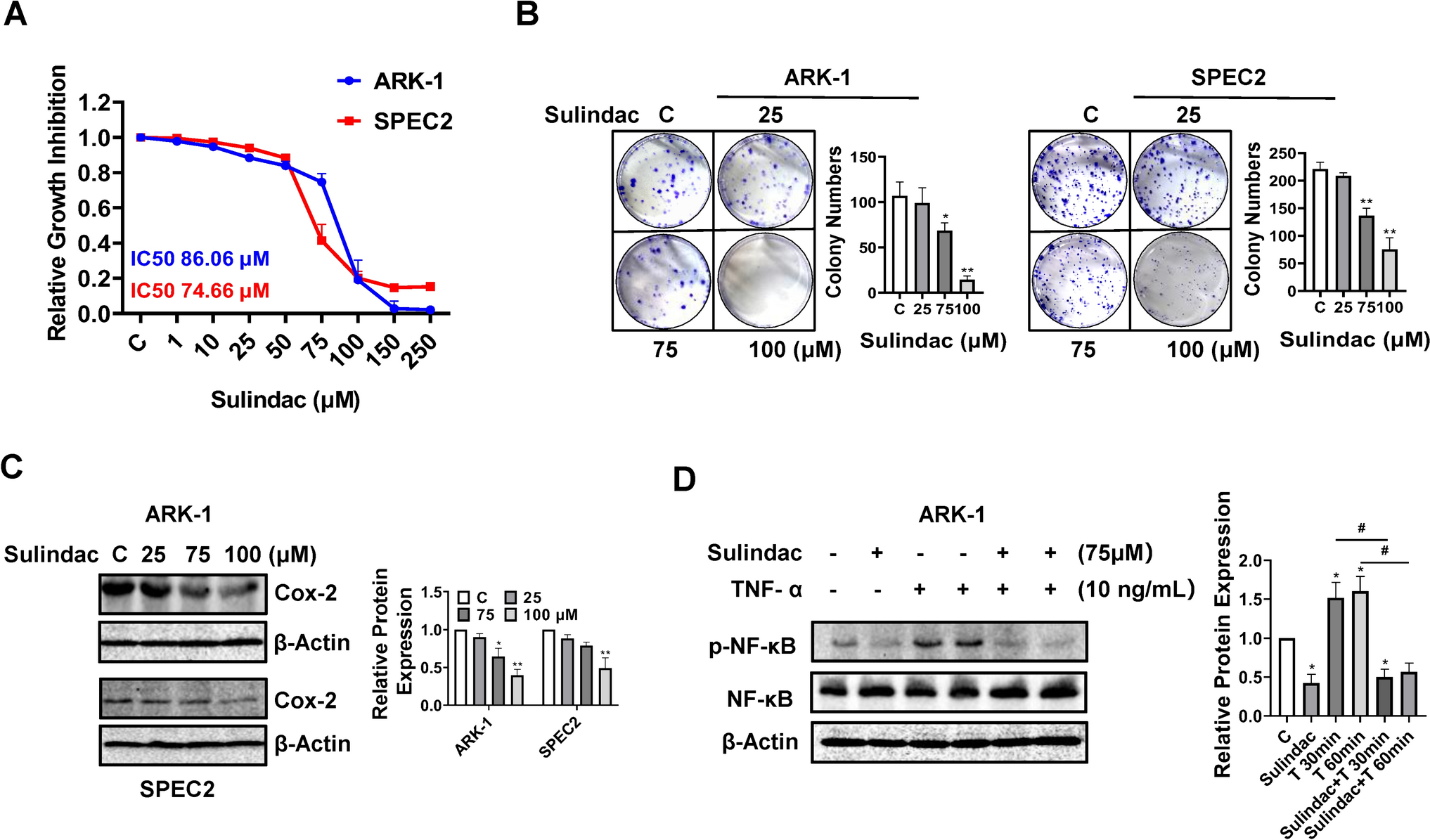
In our study, utilizing the UBC-OCEAN dataset of 725 histopathological images representing five ovarian cancer subtypes, our model showed robust performance. The dataset was thoughtfully split, with 80% for training and 20% for testing, ensuring a thorough evaluation. Our model is implemented on an HP laptop with an 11th generation processor, 16 GB of RAM, and an NVIDIA 3070 GPU and operates efficiently on MATLAB 2022a. With an initial learning rate of 0.001, a mini-batch size of 32, and the ADAM optimizer, our model leverages the fine-KNN approach for nuanced subtype classification. The results revealed high accuracy during testing, confirming the model’s ability to distinguish between HGSC, CC, EC, LGSC, and MC. The individual subtype metrics provide deeper insights. The performances of the models on the validation and test data are shown in Figs. 3 and 4, respectively.
Fig. 3
Validation results of Efficientnetb0 with Fine KNN a confusion matrix b AUC
Fig. 4
Test results of Efficientnetb0 with Fine KNN a confusion matrix b AUC
Based on the insights gleaned from Figs. 3 and 4, our proposed methodology achieves remarkable results. Both the validation and test accuracies reached 100%, confirming the effectiveness of our approach. Furthermore, the area under the curve (AUC) is a crucial metric for assessing a model’s discriminative ability, which reinforces its high performance. Notably, during testing, the AUC values were noteworthy for various subtypes, with values of 0.94 for CC, 0.78 for EC, 0.69 for HGSC, 0.92 for LGSC, and 0.94 for MC. It notices that, discrepancy between the original sample sizes and predictive performances for EC and HGSC subtypes even if make balanced using augmentation. While EC and HGSC indeed had the highest sample sizes, several factors could explain the lower predictive performance. Firstly, the inherent biological heterogeneity and overlapping histopathological features of these subtypes might have contributed to the classification challenges, causing the model to struggle in distinguishing them from other subtypes. Additionally, the variability within the EC and HGSC subtypes themselves, which can exhibit a broad spectrum of morphological patterns, may have led to a reduced ability of the model to generalize well to the test data. Furthermore, despite the large sample sizes, there may still be an imbalance in the representation of certain histopathological characteristics within these subtypes, impacting the model’s training process. To address these issues, future work could focus on incorporating advanced data augmentation techniques and exploring additional features or integrating multimodal data to enhance the model’s ability to capture the distinctive characteristics of EC and HGSC subtypes. This will help improve the overall predictive performance and robustness of the model.
Furthermore, the model was evaluated for each class of ovarian cancer, as shown in Tables 3, 4, and 5.
Table 3 TPR, FNR, PPV, and FDR of each subtype of Ovarian Cancer in ValidationTable 4 TPR, FNR, PPV, and FDR of each subtype of Ovarian Cancer in TestTable 5 Calculation of LR+ values based on TPR and FPR values for the test caseAs shown in Table 3, the validation dataset demonstrated outstanding performance across all subtypes, with a perfect true positive rate (TPR) of 100% for clear cell (CC), endometrioid (EC), high-grade serous (HGSC), low-grade serous (LGSC), and mucinous (MC) ovarian cancers. The false negative rate (FNR) was also consistently zero, highlighting the ability of the model to correctly identify instances of each subtype. Furthermore, the positive predictive value (PPV) and false discovery rate (FDR) both reached 100%, underscoring the precision and reliability of the classification.
From Table 4, it can be observed that while the performance in the test dataset remained strong, some variations were observed. Notably, the sensitivity (TPR) for the EC, HGSC, and LGSC subtypes decreased, with the lowest value observed in HGSC at 42.9%. The corresponding increase in the FNR suggests potential challenges in correctly identifying these subtypes. Despite this, the overall performance remained robust, with TPR values exceeding 90% for CC, LGSC, and MC. The PPV and FDR values provide insights into the precision of the model in the test dataset. The PPVs for EC and HGSC indicated the potential for false positives, with values of 69.2 and 75.0%, respectively. However, the FDR is generally low across all subtypes, demonstrating reliable control over false positives. Table 5 shows the values of the likelihood ratio positive (LR +), which reinforce the overall diagnostic performance. A higher LR + indicates a more reliable positive test result. Notably, the CC, LGSC, and MC subtypes exhibited particularly high LR + values, suggesting their strong ability to correctly identify these ovarian cancer subtypes.
The validation dataset shows the exemplary performance of the classification model, indicating its ability to accurately identify ovarian cancer subtypes. The minor discrepancies observed in the test dataset may be attributed to variations in the data distribution, emphasizing the importance of robust model validation. The LR + values provide additional context, indicating the strength of the model in providing reliable positive results. The higher LR + values for the CC, LGSC, and MC subtypes suggested that the model accurately identified these specific ovarian cancer subtypes.
Our model, which leverages the UBC-OCEAN dataset and combines EfficientNet-B0 with the fine-KNN approach, demonstrated robust performance with a 100% accuracy rate during both validation and testing phases, indicating its efficacy in accurately classifying ovarian cancer subtypes. The AUC values, a critical metric for assessing the model’s discriminative ability, were particularly high for CC, LGSC, and MC subtypes, underscoring the model’s strong performance. The validation dataset showed a perfect true positive rate (TPR) across all subtypes, while the test dataset revealed some variability, especially for EC and HGSC, highlighting areas for further refinement. Despite these variations, the overall performance remained robust, with high PPV and low FDR values. The likelihood ratio positive (LR +) values further confirmed the model’s reliability in providing accurate positive results, particularly for CC, LGSC, and MC subtypes. These findings collectively demonstrate the model’s potential as a highly accurate and reliable diagnostic tool, contributing significantly to the advancement of precision medicine in ovarian cancer diagnosis.
留言 (0)