
記住我



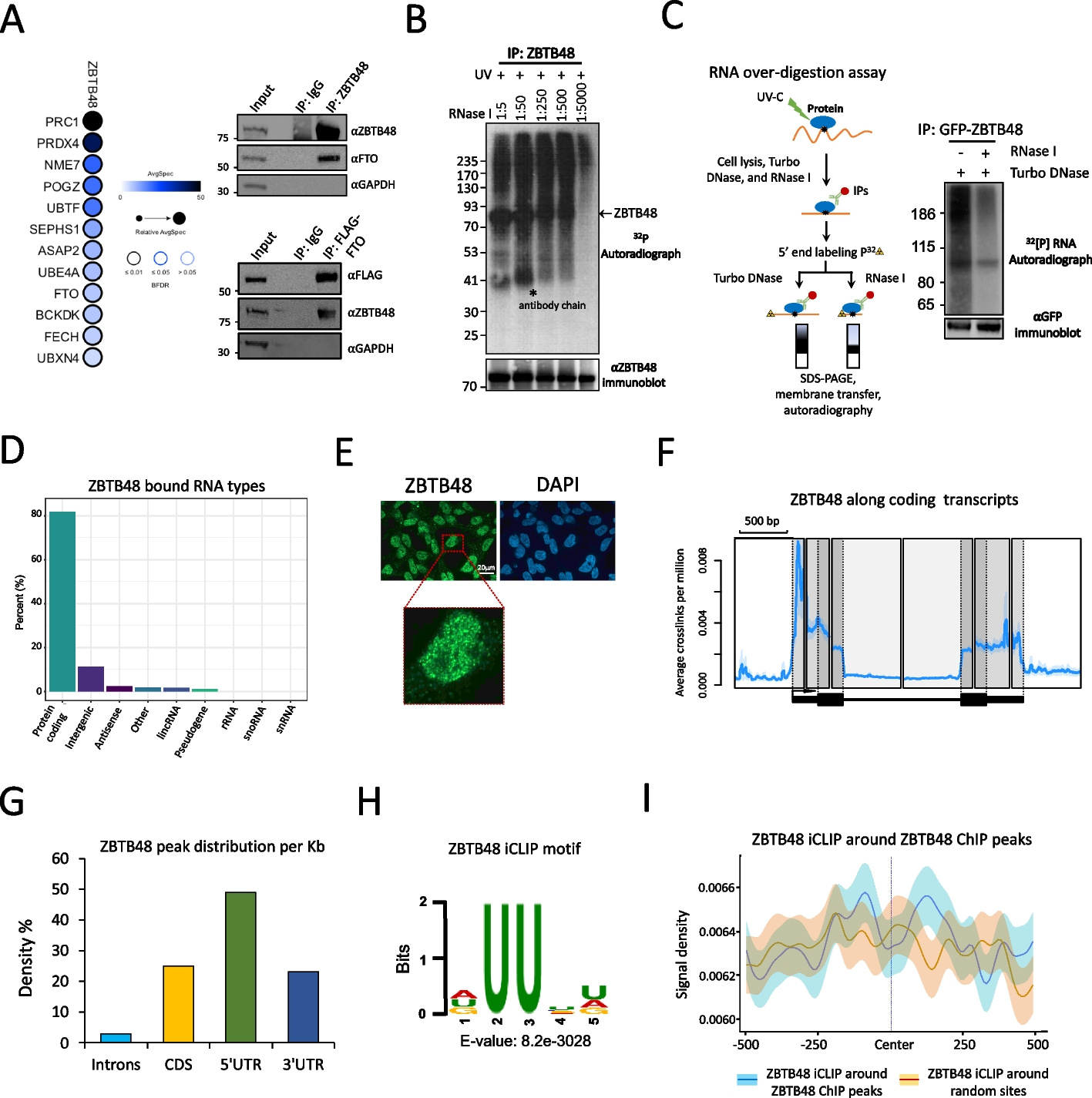

Chromatin modules (CMs) represent genomic regions where CREs display covariable activity for active histone marks such as H3K4me1 and H3K27ac [17] (Fig. 1a). CMs can be mapped using correlation-based approaches that quantify epigenome signal covariability across individuals to group CREs into modules using either graph-based community detection ([18], which we will refer to as VCMtools [22]) or hierarchical clustering (Clomics [19, 20]). A complementary strategy (PHM [21]) uses interindividual variation to infer different modes of associations between peak pairs conditioned on the underlying genetic variant(s) (Fig. 1b). So far, there has been no systematic comparison of existing techniques for CM mapping. To address this, we downloaded available H3K4me1 and H3K27ac ChIP-seq data for 317 lymphoblastoid cell lines (LCLs [19]) together with respective genotype and RNA-seq data [19]. We performed peak calling on all chromosomes for H3K4me1 (218,542 peaks) and H3K27ac (127.060 peaks), and considered H3K4me1 and/or H3K27ac peaks as putative CREs.
Fig. 1
Systematic mapping of chromatin modules (CMs) in LCLs. a Schematic representation of ChIP-seq profiles (H3K27ac in green, H3K4me1 in purple) for individuals with differential chromatin activity at the loci. ChIP-seq peaks are shown with purple and green rectangles, where color indicates different histone modifications. Only covariable peaks are used to define a CM, which is depicted with black rectangles at the bottom of the panel. b Schematic representation of the pipeline. We collected available H3K27ac and H3K4me1 ChIP-seq data for LCLs and associated genotypes for 317 individuals. We then used the data to map covariable regions with three approaches: correlation-based approaches (VCMtools, Clomics) that depend only on the epigenome data for CM mapping, and a Bayesian hierarchical method (PHM) that requires genotype information in addition to epigenome data. c The depicted UpSet plot shows the percentage of overlapping CM pairs by at least one base pair across different methods. Left panel: example of the most reproducible CMs across three methods in the MD21D2 gene locus. The top track represents peak-to-peak correlations in the locus. The tracks below show CMs mapped with Clomics (gray), VCMtools (orange), and PHM (green). The bottom tracks show ChIP-seq tracks for two individuals with the most differential CM signal (H3K27ac in dark green, H3K4me1 in dark blue). Right panel: example of the Clomics-specific CM (in gray) in the SPIC gene locus. The top track represents peak-to-peak correlations; the bottom tracks show ChIP-seq tracks for two individuals with the most differential CM signal
We started method performance evaluation by mapping CMs with VCMtools, Clomics, and PHM using the smallest chromosome 22 to evaluate several aspects of computational performance (i.e., elapsed time, memory consumption), and CM-related quantitative outputs (i.e., the number of mapped CMs, median module length, and coefficient of variation of CM length) across various sample sizes (Additional file 1: Fig. S1.1a; “Methods”). Execution-wise, Clomics was the most user-friendly tool (i.e., it required the least input data formatting and was simple to use), the fastest (in terms of elapsed time), and the most efficient in terms of RAM usage, followed by VCMtools and PHM (Additional file 1: Fig. S1.1b, c). Overall, Clomics produced the largest number of CMs yielding two to three times more modules as compared to VCMtools and PHM (Additional file 1: Fig. S1.1d). The number of identified CMs and genetic associations scaled with the number of individuals with the relative gain of CMs reducing after ~175 (Clomics and VCMtools), even though features such as median CM size remained relatively stable from 75 individuals onwards. PHM on another hand showed consistent linear trend with respect to the number of mapped CMs with increasing sample size (Additional file 1: Fig. S1.1d–g). Next, we devised a strategy to quantify the reproducibility of mapped CMs in terms of included CREs, and also quantified how well the methods preserve individual CM peak composition across randomized sample size groups with respect to the number of peaks in CMs (“Methods”). CMs mapped with VCMtools showed the highest average reproducibility across pairwise comparisons of CMs for different sample sizes (Additional file 1: Fig. S1.1h) and exhibited greater consistency in peak composition for smaller CM sizes (2–3 peaks) and lower sample cohorts (Additional file 1: Fig. S1.1i). Clomics and PHM showed a trend toward higher average scores for CMs with a larger number of peaks and larger sample sizes (Additional file 1: Fig. S1.1h, i). All methods revealed higher average reproducibility scores with larger cohort sizes, with the best average reproducibility scores achieved for > 175 (Clomics/VCMtools) or 250 (PHM) samples (Additional file 1: Fig. S1.1h, i). Together, these analyses highlight that CM identification robustness scales with the number of included individuals, only increases marginally when more than 250 individuals are included, and requires a minimum of ~50–75 individuals.
Evaluation of method and sequencing parameters for CM mappingTo facilitate the use of each method and provide the rationale behind the method selection, we comprehensively evaluated the robustness of each method by testing a range of critical parameters involved in CM mapping. We first assessed how sequencing depth affects each method by downsampling BAM files for each individual to 25, 20, and 10 million reads and mapping CMs with each method (“Methods”). We observed that a large proportion of the CMs mapped across all chromosomes with the full set of reads can be identified with only 10 million reads (Additional file 1: Fig. S1.2a). However, the reproducibility scores for mapped CMs increase from 20 million reads onward (Additional file 1: Fig. S1.2b). The randomization strategy on chromosome 22 for the downsampled data allowed us to show the effect of varying the total number of individuals on the general CM characteristics. For example, the total number of mapped CMs and median CM length showed better resemblance with the full set of reads for higher sequencing depths, thus reinforcing the observation that sample number is a critical parameter for CM mapping for all methods (Additional file 1: Fig. S1.2c–e). We thus recommend to sequence at least 20 million reads per sample, which aligns with the ENCODE recommendations [23].
Next, we evaluated the effect of the two main parameters that can be varied when mapping CMs: (1) the genomic window size left and right of the tested peaks (tested at ranges from 10 kb to 1 Mb) and (2) the cut-off for significance of peak association (p value threshold, VCMtools; background correlation, Clomics; posterior probability, PHM). We observed that the number of identified CMs and their size scales inversely with the stringency of the significance cut-off for all methods. For VCMtools and PHM, we observed that the number of CMs and their size is proportional to increasing window sizes (Additional file 1: Fig. S1.3a–c). We complemented this analysis by intersecting the CMs for each parameter pair with their localization in or outside TADs or A/B compartments. This revealed that, for example, with small window sizes (< 100 kb) VCMtools maps many CMs in B (inactive) compartments with limited TAD overlap (Additional file 1: Fig. S1.3d–f). We quantified the reproducibility of the mapped CMs within each method across the range of parameters, which indicated the robustness of Clomics outputs (i.e., an F1 score of overall average reproducibility = 0.545), as compared to VCMtools (F1 score = 0.208) and PHM (F1 score = 0.365). PHM showed the highest reproducibility scores for the posterior probability thresholds > 0.7 across all window sizes, indicating that the approach is robust under stringent cutoffs, whereas VCMtools requires more careful selection of both window sizes and p value cutoffs to allow for consistent detection of CMs (Additional file 1: Fig. S1.4). Based on these analyses, and the results summarized in Additional file 1: Figs. S1.2–S1.3, we determined the recommended ranges (indicated with red rectangles in the respective figures) for the significance cutoffs and window sizes yielding reproducible CMs with consistent descriptive statistics (Additional file 3: Table S2).
Functional relevance of CM localization and embedded genesConsidering the recommended parameter ranges, we mapped CMs on all chromosomes with the full set of individuals using VCMtools (n = 9071, window size = 0.5 Mb, p value ≤ 0.001), Clomics (n = 18,633, window size = 0.5 Mb, background correlation ≥ 3), and PHM (n = 5299, window size = 0.5 Mb, posterior probability ≥ 0.8) (Additional file 1: Fig. S1.5a, b; Additional file 2: Table S1; Additional file 3: Table S2). The methods showed high concordance with respect to previously reported CM characteristics [17,18,19,20,21], such as CM length (median 8.6–31.7 kb) and size (median 2–4 peaks) (Additional file 1: Fig. S1.5a), localization (59.4–63.9% CMs fully contained in A (active), compared to 30.5–33.3% for bootstrapped CMs; 25.7–31.9% CMs fully contained in B (inactive) compartments, compared to 50.0–53.9% for bootstrapped CMs; 68.1–73.2% CMs fully contained within TADs, compared to 44.5–49.3% for bootstrapped CMs (Additional file 1: Fig. S1.3d–f, indicated with red rectangles)), enrichment in 3D interactions between CM-embedded CREs (as inferred using either a Hi-C 500 bp or Micro-C 500 bp dataset; Additional file 1: Fig. S1.5d, e), and active chromatin states (Additional file 1: Fig. S1.5f–h) (“Methods”).
Across all overlapping CMs in pairwise method comparisons, 42.4% were at least partially identified using all methods (UpSet plot, Fig. 1c; “Methods”), with the largest overlap between the correlation-based approaches Clomics and VCMtools (Additional file 1: Fig. S1.2b). A representative example of a highly reproducible CM comprises the MB21D2 locus that was previously reported to display high levels of cis-regulatory coordination [21, 24], displaying high or very low ChIP-seq signal in the CM-embedded regions (Fig. 1c, left).
A large proportion of CMs was identified only using Clomics (29.2%). Peaks of Clomics-specific CMs had comparable median statistics of average peak heights to peaks from CMs captured with at least two methods. Yet, peaks of Clomics-specific CMs showed a broader range of average peak heights and their standard deviation across individuals compared to VCMtools- or PHM-specific CM peaks. Together, this suggests that Clomics-specific modules may have a slightly higher power to detect overall smaller covariable peaks compared to VCMtools or PHM (Additional file 1: Fig. S1.5i). A representative example of such a Clomics-specific CM is the SPIC locus. Although CM peaks in the SPIC locus showed lower average interindividual correlation (cor = 0.18) compared to the CM peaks around MB21D2 (cor = 0.58), the normalized ChIP-seq signal clearly indicated co-presence or co-absence of CM-embedded peaks (Fig. 1c, right).
Clomics-specific CMs comprised the largest group of method-specific CMs (Fig. 1c, center; Additional file 1: Fig. S1.5c). To assess whether CMs, including method-specific CMs, can aid in advancing our understanding of gene regulation, we assessed the genes that were overlapped by CMs (20–50% among 26,362 protein-coding genes and lincRNAs; 75–80% of CMs overlapped a gene, Additional file 1: Fig. S1.5j, k). We observed that Clomics CMs overlapped in total more gene promoters and gene bodies, also when accounting for the relatively higher number of mapped CMs. Clomics as well captured a higher percentage of significant CM activity (captured as the first principal component of the PCA performed on the CM peak count matrix (aCM [18])) to gene expression correlations compared to VCMtools and PHM (Additional file 1: Fig. S1.6a), which also extends to the Clomics-specific CMs (Additional file 1: Fig. S1.6b). We noted that genes embedded within CMs showed higher coefficient of variation in gene expression with increasing CM size, higher standard deviation, average, and median expression as compared to genes that did not overlap with CMs (Additional file 1: Fig. S1.6c, d). Genes embedded within CMs as well as showed enrichment in B cell and immunity-related terms (Additional file 1: Fig. S1.6e), which was consistent across all approaches. Intersection of the gene categories embedded in CMs (shared or specific to a particular method) revealed that cell type-specific genes are mainly captured in the “shared between methods” groups, and that only Clomics-specific CMs are associated with additional GO terms, which may also be partly related to B cell biology, such as “chronic myeloid leukemia” (Additional file 1: Figs. S1.6e and S1.7a–c). Together, this indicates that Clomics has higher power in detecting more subtle variation in covariable chromatin activity that is associated with changes in gene expression as compared VCMtools and PHM. This is likely due to the adaptive background-aware thresholding used in Clomics that allows to account for subtle yet important differences in local correlation changes compared to the chromosomal background [19, 20], as opposed to universal p value thresholding implemented in VCMtools [18].
We have benchmarked a range of thresholds for all CM mapping methods and provide recommended parameter values and ranges (Additional file 3: Table S2). We observed that Clomics was more robust compared to VCMtools for the parameter changes tested. Clomics further stands out by its ease of use and higher sensitivity toward identifying subtle yet putatively relevant chromatin covariation related to changes in gene expression. Together with high reproducibility scores between VCMtools and Clomics, similarity in annotations of the captured genes, and enrichment of Clomics-specific genes in cell type relevant terms, we opt for Clomics over VCMtools among correlation-based approaches. PHM provides directional insights into CRE communication yet requires large sample cohorts and significant computational resources. Therefore, we suggest using PHM as an auxiliary approach for the interpretation of CMs mapped with Clomics, which we will hereafter use for all downstream analyses.
Cell type specificity of interindividual variationUnderstanding regulatory variation among individuals in different cell types and states is crucial both from a fundamental and translational perspective [25,26,27]. To explore cell type specificity of chromatin activity variation among individuals, we extended the LCL dataset with downloaded ChIP-seq (H3K27ac, H3K4me1), genotype (derived from SNP arrays or whole genome sequencing; “Methods”), and RNA-seq data for hundreds of individuals in five cell types: LCLs (n = 317), fibroblasts (FIB, n = 78), monocytes (n = 172), neutrophils (n = 164), and T cells (n = 93) [19, 28]. To facilitate downstream interpretation and ensure consistency in our analyses, we remapped ChIP-seq peaks to obtain a universal set of peaks for H3K27ac and H3K4me1 in all cell types (Fig. 2a, Additional file 1: Fig. S2.1a; Additional file 4: Table S3; “Methods”) and used this peak set to map CMs with all methods for the data completeness and availability (Additional file 1: Fig. S2.1b; see Availability of data and materials). Based on the preceding analyses, in this and following sections, we specifically focus on CMs mapped with Clomics in LCL (n = 18,633), FIB (n = 10,158), monocytes (n = 9002), neutrophils (n = 6604), and T cells (n = 4841) (Additional file 1: Fig. S2.1c; Additional file 5: Table S4).
Fig. 2
Cell type specificity of regulatory variation and TF binding in CMs. a Schematic representation of the pipeline. ChIP-seq and genotype data were collected for hundreds of individuals for five cell types, namely, LCLs, monocytes, neutrophils, T cells, and fibroblasts (FIBs) [19, 28]. The collected ChIP-seq data was processed in a standardized way to obtain a count matrix for a universal peak set (see “Methods” for details), which was used for CM mapping. The downstream analysis included evaluation of cell type specificity of regulatory variation captured in the form of CMs and quantification of TFBS enrichment in specific CM peak types. b From left to right: 1. Example of a “universal” CM, here in the RHD gene locus where covariable peaks are present in all cell types. 2. Example of a lineage-specific CM in LCLs (blue) and T cells (light green), spanning the MB21D2 gene. 3. Example of an LCL-specific CM in the REL locus. Tracks depicting the ChIP-seq signal at these loci can be found in Additional file 1: Fig. S2.2. c TF classification according to TFBS enrichments in distinct categories stratified into anchor versus non-anchor CM CREs and cell type-restricted (CT-restricted) versus common CM CREs based on all pair-wise comparisons together (see “Methods” for details). Bottom: schematic representation of TFBS for different categories of TFs across partially overlapping CMs. d Example of an LCL-specific CM (in blue) in the TCL1A locus. Tracks below indicate TFBSs (vertical lines) for cell type-enriched TFs per cell type (from top to bottom: LCL: ATF2 (n = 1), EBF1 (n = 11), KLF1 (n = 1), PAX5 (n = 5), monocytes: KLF4 (n = 1), neutrophils: KLF5 (n = 2), FIB: ERG (n = 2), NR2F2 (n = 1), TFEB (n = 1)). No T cell-specific TFBS were found in the locus. The bottom tracks show ENCODE ChIP-seq profiles for PAX5 and EBF1 binding in LCLs, CTCF and BHLHE40 tracks for LCLs (blue) and FIB (orange)
To assess if read count differences were contributing to the differences in total number of identified CMs across cell types, we mapped CMs with the downsampled data of 10, 20, and 25 million reads. We observed that more CMs were mapped in LCLs and FIB than in other cell types, even when we used downsampled BAM files with 10 million reads per sample (Additional file 1: Fig. S2.1d). This might be related to the fact that LCLs and FIB are culture-adapted and more homogeneous, while the primary blood cells (monocytes, neutrophils, and T cells) were taken directly from human donors and may thus be subject to more variability. With the complete set of reads, the highest average similarity was observed for CMs mapped in monocytes and neutrophils, while fibroblasts tended to be the most distant cell type from the other ones, as expected based on its cell lineage (Additional file 1: Fig. S2.1e). We used pairwise cell type comparisons to coarsely categorize CMs into (1) universal CMs (similarity score > 0.7), (2) partially overlapping CMs (0 < similarity score ≤ 0.7), and (3) cell type-specific CMs (similarity score = 0). This showed that the majority of CMs are cell type-specific while some cell types, such as monocytes and neutrophils, have a relatively higher proportion of overlapping CMs (Additional file 1: Fig. S2.1f–j). Together, this demonstrates the prevalent lineage and cell type specificity of the regulatory landscapes captured in form of CMs. Representative loci for each category are shown in Fig. 2b and Additional file 1: Fig. S2.2a, where cell type specificity is also reflected in the association between CM activity and gene expression (Additional file 1: Fig. S2.3a–c).
CM formation appears to be driven by functionally distinct groups of TFsTo identify candidate TFs associated with CREs embedded within CMs, we first performed differential peak-based TF binding site (TFBSs, which represent the genomic locations of TF motifs matching TF binding sites as determined using ChIP-seq [29]) enrichment analysis between CREs embedded within CMs and non-CM CREs for each cell type (Additional file 1: Fig. S2.3d). We created a set of “simulated” CMs from the non-CM CREs that were size-, distance-, ChIP signal strength-, and GC-matched to the mapped CMs (“Methods”). The TFBS analyses revealed that CREs in CMs are significantly enriched for TFBSs of known cell type-specific TFs, e.g., EBF1 in LCLs [30] and CEBPA/B in monocytes and neutrophils [31] (Additional file 1: Fig. S2.3e–i; “Methods”), with larger similarity between myeloid (monocytes and neutrophils) or lymphoid (LCLs and T cells) cell types (Additional file 1: Fig. S2.3j). Since CMs were mapped based on a universal peak set across cell types, this indicates that CM CREs are enriched for cell type-specific TFBSs.
To further characterize the cell type specificity of the CM-embedded CREs, we assessed the episomal regulatory activity of the CREs using available STARR-seq data from the GM12878 LCL cell line [32]. We performed pairwise comparisons between LCLs and every other cell type to stratify the CM-embedded CREs into those shared between the compared pair of cell types (i.e., CREs that we will refer to as “anchors”) and those specific to one of the cell types (i.e., CREs that we will refer to as “non-anchors”) (Additional file 1: Fig. S2.4a). For all pairwise comparisons of LCLs to other cell types, we observed significantly higher activity at anchor CREs, with the lowest average activity at non-anchors of non-LCL cell types (Additional file 1: Fig. S2.4b). This could indicate that CM CREs that are shared between cell types (anchor CREs) may have higher regulatory potential than non-anchor CREs, which themselves may have more secondary support functions as driven by cell type-specific TFs [33,34,35]. To test this hypothesis, we first assessed which TFBSs are enriched in non-anchor CREs in a cell type-dependent manner, which revealed the enrichment of TFs with well-known functions in the respective cell types, such as KLF4 in monocytes [36], KLF5 in neutrophils [37], the pioneer B-cell TF EBF1 in LCLs [30], and TWIST1 in FIBs [38] (Additional file 1: Fig. S2.4c–d). These findings suggest that the TFBS enrichment that we observed when comparing the set of reference versus simulated CMs (Additional file 1: Fig. S2.3e–i; “Methods”) is driven by cell type-specific TFs that bind to non-anchor elements.
As a next step, we used all cell types in our pairwise TFBS enrichment analyses to define if non-anchor CRE-enriched TFBSs can also be detected in anchor CREs and if this depends on the assayed cell types. To do so, we specifically focused on the anchor CM CREs and contrasted these with a collection of non-anchor CREs between each cell type pair. Together with the comparison of non-anchor CREs, this allowed us to broadly categorize TFs into several groups based on (1) whether enrichment of their respective binding sites in CMs is specific to either anchors, non-anchors, or whether their binding sites can be found in both (with the latter representing “general” CM TFs), and (2) if this TFBS enrichment is specific to one or few cell types (i.e., “cell type-restricted” (CT-restricted)), or if this enrichment is present in all pairwise cell type comparisons (“common”) (Fig. 2c, Additional file 1: Fig. S2.4e). We identified a total of 165 TFs that are enriched in anchor and/or non-anchor CREs (Fig. 2c; Additional file 6: Table S5). The TFBSs for a total of 23 TFs were always enriched at anchors (indicated with green and brown colors). These TFs include more universally expressed regulators such as USF1/2 and SP1/2, as well as proteins involved in regulating 3D chromatin organization such as CTCF and YY1 [3, 39, 40]. However, we found that the large majority of these 165 TFs (n = 130, dark gray, blue, and light blue colors) are enriched in a cell type-restricted fashion in non-anchor or all CM CREs.
Altogether, these analyses suggest that CMs consist of both common regions (anchors) with higher regulatory activity that are preferentially bound by universally expressed TFs as well as CREs that are more cell type-specific and that are bound by TFs relevant to the respective cell type(s) (Additional file 1: Fig. S2.5a, b). A notable example that illustrates how CM formation may be driven by distinct classes of TFs is the B-cell-relevant TCL1A locus [41] where the respective gene is specifically expressed in B cells (Additional file 1: Fig. S2.5c). The TCL1A gene locus is enriched for binding sites of LCL-enriched TFs in the CM body, especially at the CM peaks, as compared to other cell types. This is exemplified by binding of cell type-specific TFs such as EBF1 and PAX5, as well as LCL-specific binding of CTCF and BHLHE40, at the locus (Fig. 2d, Additional file
留言 (0)