Background
St James’s Hospital, Dublin serves as a secondary care centre for emergency admissions in a catchment area with a population of 270,000 adults. All emergency medical admissions are admitted from ED to an Acute Medical Admission Unit (AMAU), the operation and outcome of which have been described elsewhere [18, 19].
Data collection
An anonymous patient database was employed, assembling core information from each clinical admission including details from the patient administration system, national hospital in-patient enquiry (HIPE) scheme, the patient electronic record, and laboratory data. HIPE is a national database of coded discharge summaries from acute public hospitals in Ireland. For diagnosis and procedure coding, the International Classification of Diseases (9th Revision ICD-9-CM) was employed < 2005 with ICD-10-CM thereafter. Data included parameters such as the unique hospital number, admitting consultant, date of birth, gender, area of residence, principal and up to nine additional secondary diagnoses, principal and up to nine additional secondary procedures, and admission and discharge dates. Additional information cross-linked and automatically uploaded to the database includes physiological, haematological, and biochemical parameters. This study includes all acute medical admissions admitted in the 21 years between 2002 and June 2023, with follow-up on the Irish National Death Register to December 2021. The analysis of weekend vs weekday outcomes utilised two sets of consecutive days—Saturday/Sunday were compared with Tuesday/Wednesday. The representative weekdays chosen were selected as those being at least risk of a weekend effect influence. This study received institutional Ethics Committee approval.
Risk predictors
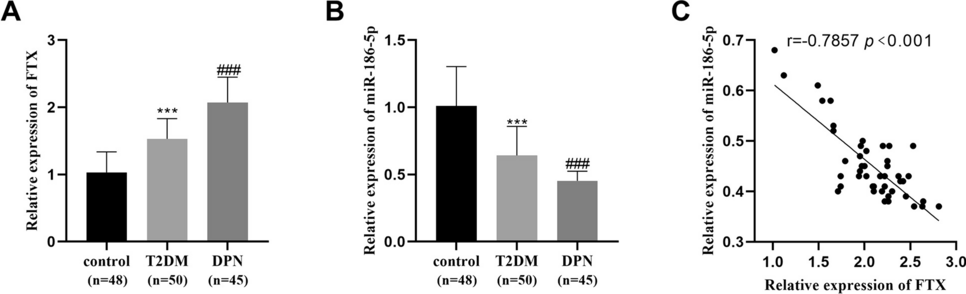
Derangement of admission biochemical parameters may be utilised to predict clinical outcome. We have previously derived and applied an AISS [20], predicting 30-day in-hospital mortality from parameters recorded in the ED. A weighted age adjusted score was derived; six risk groups (I–VI) were identified with initial cut-points for 30-day in-hospital mortality set at 1, 2, 4, 8, and 16%.
Comorbidity was assessed by the previously described comorbidity score [21]. To devise the score, we searched ICD codes that captured chronic physical or mental health disorders that limit people in activities that they generally would be expected to be able to perform were grouped according to the following ten systems: (i) cardiovascular, (ii) respiratory, (iii) neurological, (iv) gastrointestinal, (v) diabetes, (vi) renal, (vii) neoplastic disease, (viii) others (including rheumatological disabilities), (ix) ventilatory assistance required, and (x) transfusion requirement. In addition, we searched our hospital’s other databases for evidence of diabetes (Diamond database) [22], respiratory insufficiency (FEV1 < 2 L), troponin status (high sensitivity troponin ≥ 25 ng/L) [23], low albumin (< 35 G/dL), and anaemia (haemoglobin levels < 10 G/dL) or chronic renal insufficiency, MDRD < 60 mL/min*1.73 m2. Each component of the score was then weighted according to 30-day in-hospital mortality.
Match to Irish National Death Register
Data analysis uses anonymised data, via an instruction set (Stata code) to assemble and analyse data in computer memory from various discrete files, patients in each being identified by a unique hospital admission number or identifier and the series number (case ID, related to the admission date/time). Each patient address was accessed once to derive the Deprivation index [24]. The match to the Irish National Death Register and hospital patient administration record involved cleaning of string data and merge of the databases (matched on date of birth and surname). Gender mismatches were deleted, and string-based fuzzy matching techniques calculated a score of text agreement (both name/surname and address) similarity. The match was confirmed by visual inspection. A small number of residual observations (~ 350) were manually accepted or rejected, using online death notices. The information then, on the database, consist of 0/1 and date of death to preserve the anonymous database nature.
Statistical methods
Descriptive statistics were calculated for background demographic data, including means/standard deviations (SD), medians/inter-quartile ranges (IQR), or percentages. Comparisons between categorical variables and mortality were made using chi-square tests. We adjusted the outcome computation for other known predictor variables including AISS [20, 25], comorbidity score [21], and blood culture status [26]. We employed a logistic model with robust estimates to allow for clustering; the correlation matrix thereby reflected the average discrete risk attributable to each of these predictor variables [20].
Logistic regression analysis identified potential mortality predictors and then tested those that proved to be significant univariate predictors (p < 0.1 by the Wald test) to ensure that the model included all variables with predictive power. We used the margins command in Stata to estimate and interpret adjusted predictions for sub-groups, while controlling for other variables such as time, using computations of average marginal effects. Margins are statistics calculated from predictions of a previously fitted model at fixed values of some covariates and averaging or otherwise over the remaining covariates. In the multivariable logistic regression model, we adjusted univariate estimates of effect, using the previously described outcome predictor variables. Survival regression calculations were undertaken employing the non-parametric Kaplan–Meier model. This non-parametric method does not assume the distribution of the outcome variable, with the Kaplan–Meier curve illustrating the change in survival probabilities over time.
Adjusted odds ratios (OR) and 95% confidence intervals (CI) were calculated for those predictors that significantly entered the model (p < 0.10). Statistical significance at p < 0.05 was assumed throughout. Stata v.17.0 (Stata Corporation, College Station, Texas) statistical software was used for analysis.



留言 (0)