
記住我


For reproducibility and comparability of the results, two public datasets with a total of 100 cases were used in this study. Of these, 60 cases were from the AAPM Lung CT Segmentation Challenge 2017 dataset [22], and 40 cases were from the SegTHOR dataset [23]. Both datasets contain entire 3D thoracic CT images and esophagus delineated by experts. The images are all 512 × 512 pixels for each slice and the in-plane resolution varies between 0.90 mm and 1.37 mm per pixel.
In image preprocessing, the image intensity values were truncated to the range of [-160, 240] to enhance the image contrast, and then the images were normalized to have zero mean and unit variance. All images were resampled to a 0.97 × 0.97 mm in-plane resolution and reformatted into a standard orientation to maintain data consistency.
To avoid potential biases in the model due to small training sample data sets, 5-fold cross-validation was used in this study. For each fold, 68 cases were used to train the model, 12 cases were used to validate the model and adjust the model hyperparameters, and 20 cases, never seen by the model during the training and validation, were used for the final test of the model performance.
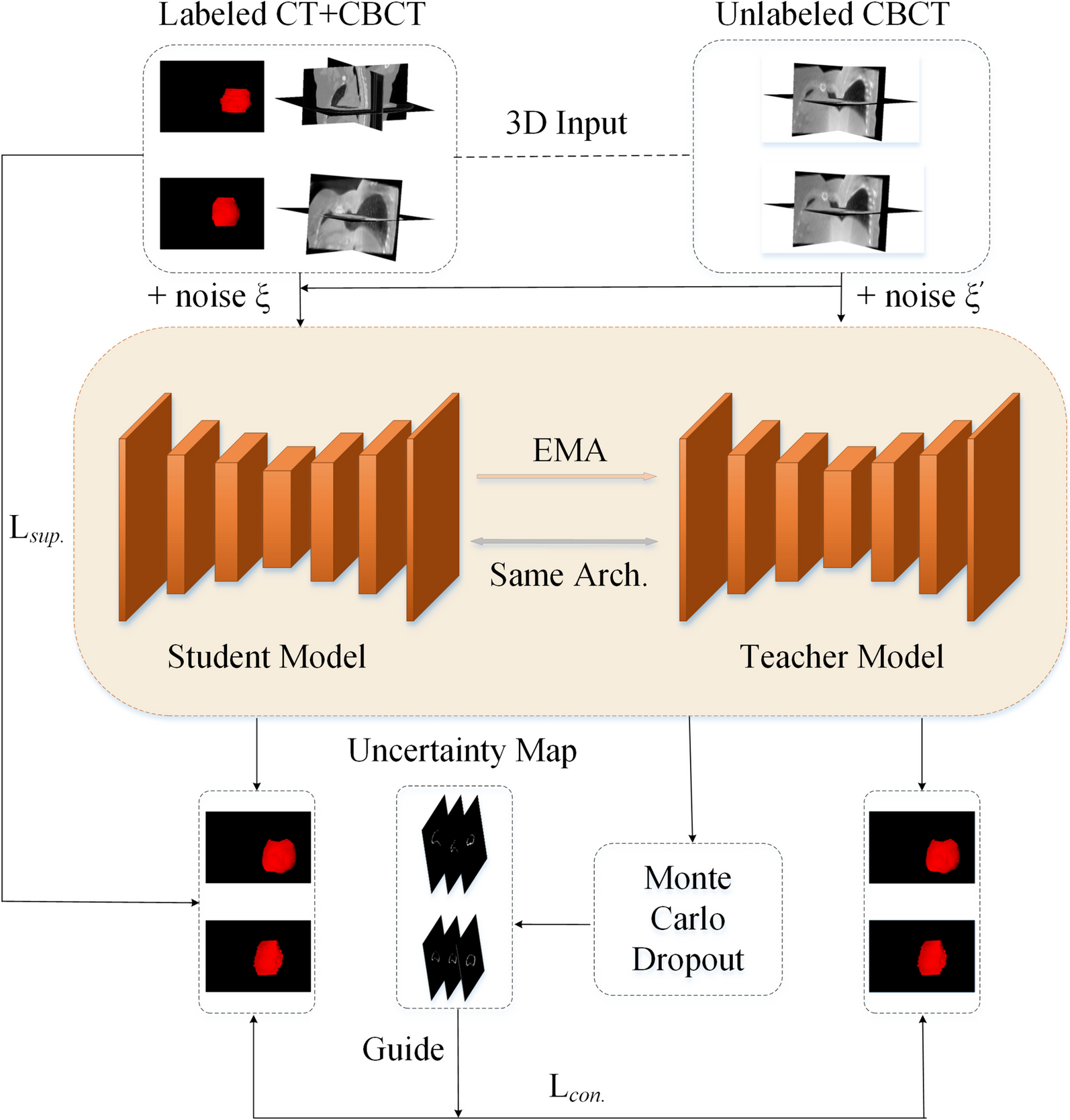
Location and segmentation networkThe entire deep learning framework consists of two parts (Fig. 1). The first part is an object location model, which is a modified CenterNet [24] used to locate the central position of the esophagus first. The second part is a segmentation network used to delineate the esophagus in the cropped image according to the predicted object center.
Fig. 1
The architecture of the two-stage deep learning framework. It consists of two parts: object location and object segmentation
In the modified CenterNet model, the ResNet18 module [25], a down-sample pathway, was used to extract image features first. The features are gradually recovered through an upsampling pathway to obtain the predicted Gaussian heatmap, and decoding which yields the predicted object center. A supplementary file describes the object location network in more detail [see Additional file 1].
In the segmentation module, the 2D U-net [17] and 3D U-net [10] models were used to perform esophagus segmentation respectively, and we found that the 3D U-net model performed better in terms of miss delineating the object but the 2D U-net model performed better in terms of identifying boundaries. Therefore, the segmentation was performed using the 2D U-net and the updated object center based on the 3D U-net (See Figs. 2, 3, 4).
Fig. 2
The dice coefficient and 95% HD of esophagus delineated by various segmentation models
Fig. 3
Visualization of a case of esophageal delineated based on the coarse and fine object center. From left to right, they represent different slices of the same case. The red line is marked by experts and the green line is delineated by deep learning models
Fig. 4
Dice coefficient and the improvement of dice coefficient for all cases. (a) the dice coefficient of esophagus delineation based on the coarse object center. (b) the improvement in dice coefficient of the model after updating the coarse object center to fine object center. The black arrows indicate exception cases
For the object location network, the input was a set of center-cropped images with a size of 192 × 192 pixels, and the output was the corresponding Gaussian heatmap. Focal loss was used to optimize the model. For the segmentation network, the input was a set of cropped sub-images with 112 × 112 pixels according to the predicted object center. The model was optimized via a combination loss function as follows:
Where dice and focal represent the dice loss and focal loss, respectively, and the \(\alpha\) represents the weight of focal loss, which is adjusted according to the model’s bias. For example, the weight was turned up if the model tended to have fewer predictions.
The deep learning models were implemented based on the Pytorch [26] framework, and all experiments were carried out on a Windows system workstation equipped with the intel core i7-12700 CPU, NVIDIA 4080 GPU, and 32 GB RAM. During training, a set of on-the-fly data augmentation strategies was employed to enhance the model’s generalization ability, including random flip, random rotation within a range of -10 to 10 degrees, random noise, and random crop scaling. The data augmentation and deep learning models training procedures are described in detail in a supplementary file [see Additional file 1].
EvaluationFor quantitative evaluation, the volumetric dice similarity coefficient was used to evaluate the degree of overlap [27] between the automatic segmentation result and expert delineation, and the 95% Hausdorff distance (95% HD) was used to evaluate the farthest distance between the two delineated boundaries [28]. Besides, the volume ratio was used to evaluate the systematic under or over-segmentation. The quantitative metrics were compared using paired two-sided t-tests.
In addition, we also focused on the cases with poor delineation performance, namely the robustness issues in clinical applications. Based on the performance of esophagus automatic segmentation in the current study, cases with dice coefficients lower than 0.75 were defined as poor delineation. Using the expert delineation as the standard, each slice was reviewed and analyzed. The phenomenon that there is an expert delineation but no model delineation in a slice is defined as missing delineation (for example, Fig. 5f). The phenomenon that the expert delineation and model delineation were located in different regions (overlap area less than 25% of model delineation) in a slice is defined as the delineation with wrong objects (for example, Fig. 5b). The incidence of delineating wrong objects and missing objects was counted and compared across models using a paired-sample design chi-square test since it is a comparison of sample rates.
Fig. 5
Visualization of esophagus delineation for typical hard samples. The red line is marked by experts and the green line is delineated by deep learning models
Besides, the slice dice coefficients were interpolated to the same length for all cases and then plotted in a graph to evaluate the esophagus automatic segmentation performance in different regions since the esophagus is very long, spanning the neck, chest, and abdomen.
Finally, the total time of object localization and fine segmentation was calculated, to evaluate the feasibility of the proposed model in clinical practice.
留言 (0)