
記住我




The R software (version 4.2.2) was used for data cleaning and statistical analyses. The rfImpute and randomForest functions from randomForest package were used to impute the missing data and build the models, while the smote function from performanceEstimation package was used to generate synthetic samples.
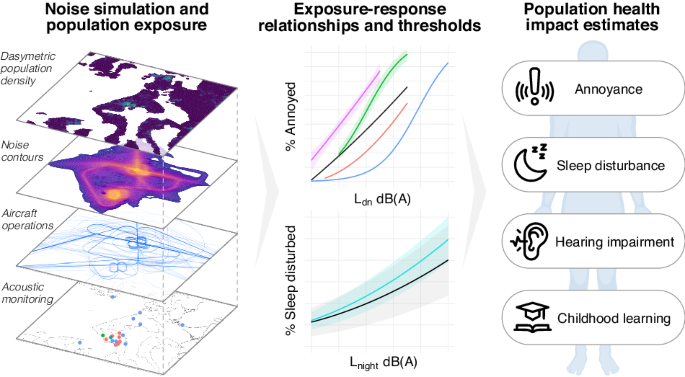
DFR databaseThe dataset used for this project consisted of data from 104 DFR studies on 28 active ingredients with registrations held by Corteva AgriscienceTM. All studies were conducted according to US EPA’s Occupational and Residential Exposure Test Guideline OPPTS 875.2100 [11]. The products containing the a.i. were applied under representative conditions following Good Agricultural Practices (GAPs). Studies recorded DFR values at different times before and after application. Analyses of the dataset indicated that in cases where multiple applications were recommended, the magnitude of DFR values on day 0 after the first application were similar to DFR on day 0 (DFR0) after last application once spray had dried (Fig. 1). The correlation value R2 is 0.747, showing a relatively strong correlation between the first and last application. For DFR0 ≥ 3 µg/cm2/kg a.i./ha, DFR0 values after the last application were slightly greater than after the first application. Therefore, as a conservative approach, DFR0 values after the last application, without any correction for residues carried over from previous applications, were used for model building and analysis presented here.
Fig. 1: DFR values (µg/cm2/kg a.i./ha) at Day 0 after first application (crosses) and last application (circles) after residues have dried.
The x-axis is an index of all the trials with multiple applications and had DFR values for both first and last applications.
Each of the 104 studies had 2–4 trial sites each, and about 3 replicates per site, for a total of 850 DFR0 data entries: 735 of them were from open field studies and 115 were from greenhouse studies. Ten of the trial sites did not have records for specific replicates but had records for average DFR value for that trial site, therefore the corresponding average value was imputed for each missing trial replicate value. Eight entries did not have records of either replicates or average values for DFR0 after last application, and there were no experimental notes explaining the missing values. Since all 8 missing entries had DFR0 values from the first application recorded, these were used in modeling since they were good estimates based on the similarity and strong correlations between the first and last applications as shown in Fig. 1. The 28 active ingredients were categorized into 11 formulation types, with the formulated products applied to 31 crops at 32 different trial locations across the United States (US), Canada, and Europe. Weather conditions for each observation day were available for all field studies, and the mean relative humidity and temperature on the day of last application was used in model building.
The univariate analyses demonstrated that the mean DFR0 on each crop varied from 0.114 to 4.968 µg/cm2/kg a.i./ha. The mean DFR0 at each location showed some variation across the different geographies where the studies were conducted, an indication of the influence of site-specific parameters on the magnitude of DFR0.
Based on an initial hypothesis that DFR0 is related to the active ingredient used, the crop/crop group, and location-specific variables, 14 parameters (Table 1) were considered in model building. These 14 parameters can be divided into three general categories related to the applied PPP, crop on which the PPP was applied, and site-specific properties.
Table 1 Summary of study parameters in DFR database.Imbalanced classificationThe EFSA Guidance assumes a default DFR0 value of 3 µg/cm2/kg a.i./ha in instances where experimentally determined DFR values are not available [1]. In the random forest classification model discussed below, the response variable (DFR0) was classified into two classes based on the EFSA default DFR0 value:
DFR0 < 3 µg/cm2/kg a.i./ha is considered as negative (DFR0 Class = 0), and
DFR0 ≥ 3 µg/cm2/kg a.i./ha is considered positive (DFR0 Class = 1).
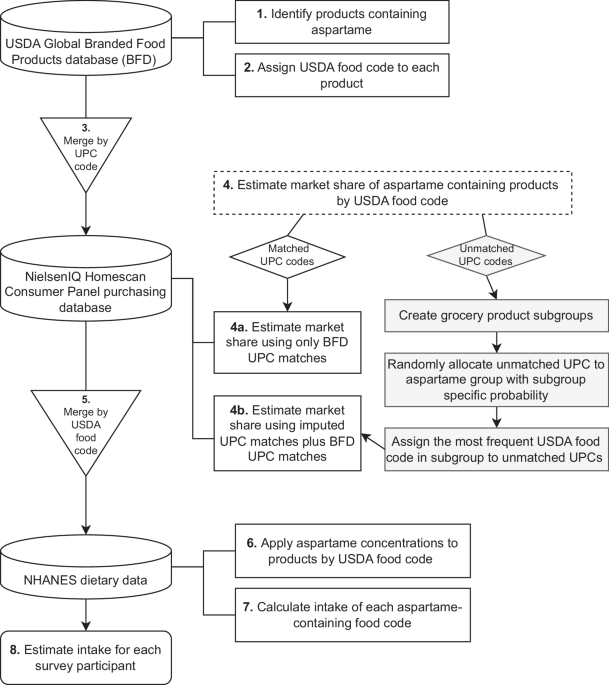
The histogram of DFR0 after last application shown in Fig. 2 indicates that the response is skewed with the imbalance ratio around 11:1, i.e., for every positive DFR0, there are 11 negative DFR0 values. It is expected to be skewed to the right since DFR follows a log normal distribution [12] with the EFSA default DFR0 value ranking in the 92nd percentile of the dataset considered here, consistent with the EUROPOEM II data distribution [4] and reflecting the conservatism of the current regulatory approach. The US EPA value ranks in the 87th percentile of our dataset, also highlighting the conservatism in the US approach.
Fig. 2: Histogram of DFR (µg/cm2/kg a.i./ha) at Day 0 of last application.
The x-axis represents the DFR value (µg/cm2/kg a.i./ha), while the y-axis represents the frequency of that observed DFR0 in the database.
Most of the algorithms used for classification assume balance. Imbalance in the data lowers the prediction accuracy, especially for the minority class due to a lower sample size. Typically, the minority class is also of interest and requires a robust prediction accuracy. For the current dataset with the ratio of 11:1, the imbalance was remedied before modeling using the synthetic minority over-sampling technique (SMOTE).
SMOTE is one approach generally used to handle imbalanced classification problems by over-sampling the minority class “to create ‘synthetic’ examples based on the nearest k minority class neighbors instead of random sampling with replacement” [13]. The attractive feature of SMOTE is that the synthetic examples balance the original dataset, allowing the classifier to create larger and less specific decision regions which in turn can make the decision trees more generalizable and increase prediction accuracy of the minority class. For our analysis, SMOTE was used to generate a more balanced dataset for learning the predictor versus response relationship which was then compared with the model built on the original imbalanced dataset. There was a similar pattern of distribution in the original and SMOTE training set, with active ingredients which possessed low or high DFR0 values in the original set being reflected in the SMOTE set.
Random forest imputation and modelRandom forest is an ensemble learning method for both regression and classification that operates by constructing a multitude of decision trees at training time [14].
ImputationIn this study, random forest was used to impute any missingness based on similarity between each observation, rather than using any parametric model. There were 10 missing relative humidity values which were not recorded during the study and could not be determined from any official local weather logs for some of the greenhouse studies. After reviewing the study reports the missing values were predicted using other location variables since the missingness for these values was assumed to be missing at random (MAR) because the missing humidity values were related to other observations in the data [15].
ModelThe complete dataset was randomly sampled into training and test sets stratified by the classes of DFR0. The training set contained 546 negative cases (DFR0 < 3 µg/cm2/kg a.i./ha) and 49 positive cases (DFR0 ≥ 3 µg/cm2/kg a.i./ha), accounting for 70% of the original dataset. The testing set had 234 negative cases and 21 positive cases, accounting for 30% of the original data. Both training set and testing set preserved the original imbalance ratio of classes (i.e., 11:1). A second training set was generated with a more balanced ratio of around 1.7:1 by using SMOTE on the original training set. A parameter of k = 5 was chosen to synthesize new examples based on the closest 5 neighbors. The new SMOTE training set had 588 negative cases and 343 positive cases.
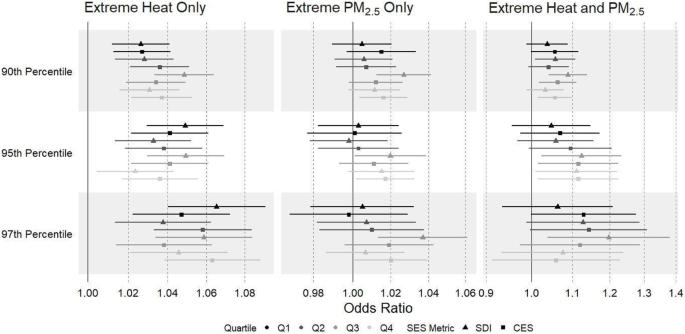
Two methods were considered in developing the random forest classification and regression models; one based on the original imbalanced training set (Method A), and the other based on the SMOTE training set (Method B). The random forest model hyperparameters for each method were optimized by utilizing 10-fold and 30 repeated cross validation methods. All training samples were used to fit the random forest model and applied to the test set data based on the selected optimal hyperparameters. This whole process was repeated 200 times by randomly splitting the dataset into training (70%) and testing (30%) sets so that the training and testing samples represented different data structures, i.e., each of the 200 repetitions is essentially a different model as it contains a different set of training and testing datasets (Fig. 3A).
Fig. 3: Random Forest Workflow for DFR prediction model development.
Panel A is a schematic of the process followed for data processing and the machine learning workflow for development of methods A & B while Panel B is the multidimensional scaling (MDS) plots for the classification models based on the two methods. The axes for the MDS plot represent the first and second principal coordinates where these two principal coordinates explain 69.1% and 7.4% of the total variations of the factors.
These 200 random forest models were used to build a final ensemble model based on majority voting for classification model, and average prediction for the regression model as detailed in Section “Results and Discussions”.
留言 (0)