
記住我
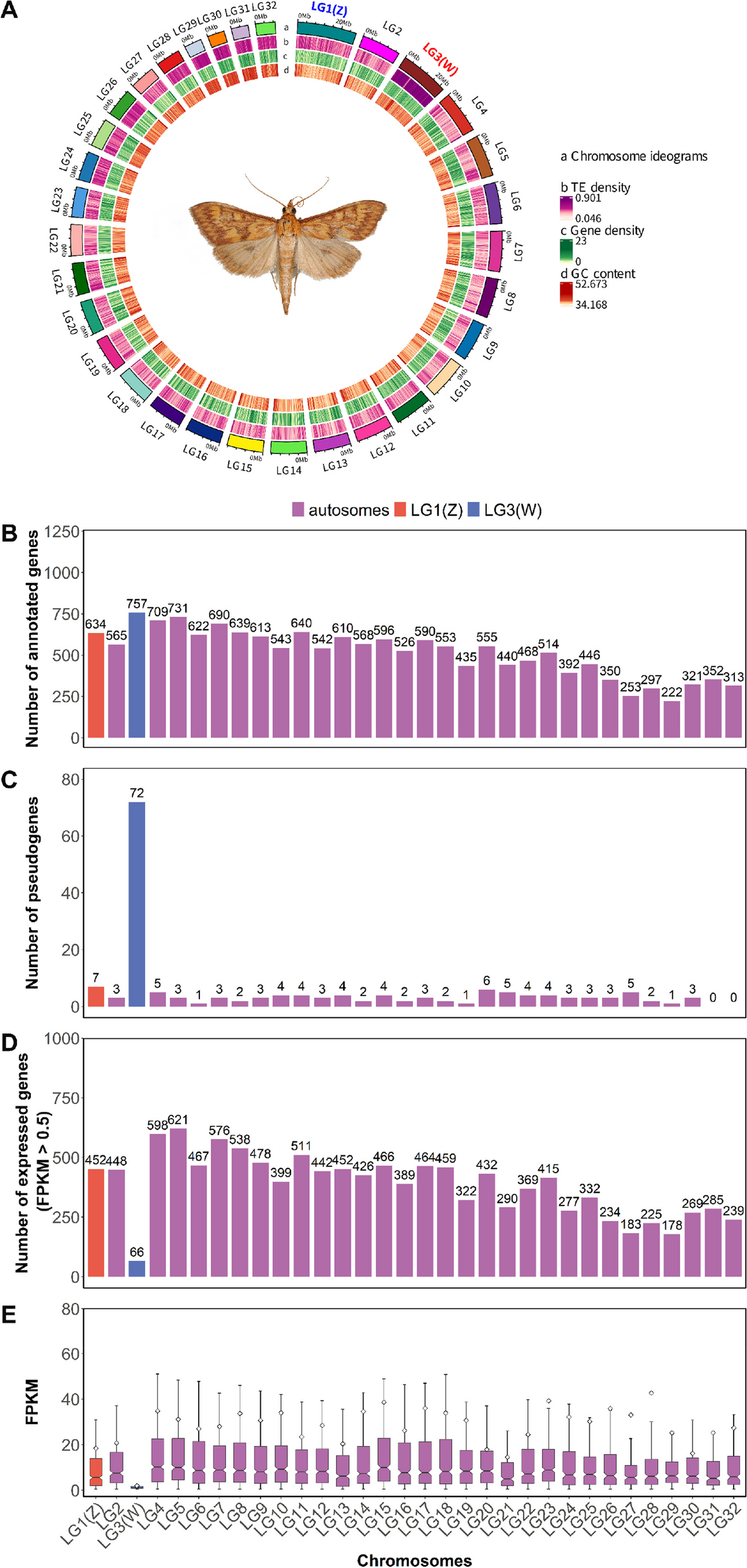

We collected a total of 344 accessions to represent the diploid cotton A-clade, comprising 29 accessions of Gossypium herbaceum (A1) and 315 accessions of Gossypium arboreum (A2), with an average genome sequencing coverage of 24.1 × , which contain all the published diploid A-genome cotton resequencing data. The accessions were obtained from diverse regions, including 222 accessions from China (CHN), 52 from South Asia, 26 from the United States (US), and 15 with undetermined geographic origins (Additional File 2: Table S1). We used the “map-to-pan” approach to construct the diploid A-clade pangenome. For each accession, we performed de novo assembly and retained contigs longer than 500 bp; then, the contigs were aligned to the Shixiya 1 reference genome to identify the NRSs. After excluding redundant and potential contaminating sequences, we finally obtained 511 Mb of NRSs and integrated them with the “Shixiya1” reference genome to yield the diploid A-clade pangenome of 2166 Mb [8].
We evaluated the quality of the pangenome by three approaches. First, we observed an improvement in the mapping rate of short reads from 344 accessions, which increased from 98.5 to 99.7% from the reference to the pangenome. Second, we evaluated the completeness of BUSCO hits using the eudicots_odb10 database and found 97.7% and 98.9% completeness in the reference and pangenomes, respectively (Additional File 1: Fig. S1a). Third, we aligned the 511 Mb NRSs to the nucleotide collection (nt) database and found that 95.8% of NRSs had alignments in the Gossypium genus (Additional File 1: Fig. S1b). These results indicate high confidence in the pangenome.
We annotated a total of 5479 non-reference genes on the NRSs, of which 75.2% (4123) were assigned gene functions through the Gene Ontology (GO) (47.5%), Kyoto Encyclopedia of Genes and Genomes (KEGG) (39.2%), and Pfam (49.8%) databases. Finally, the diploid cotton pangenome was 2166 Mb with 47,257 genes (1655 Mb with 41,778 genes for the reference genome) (Additional File 2: Table S2).
Presence and absence variations (PAVs) in genes among the different accessions can reveal genetic changes and the breeding history. After excluding three outgroup accessions, 47,257 pangenes from 341 accessions were used for gene PAV analysis. We identified 41,626 (88.1%) core genes, 1436 (3.0%) soft core genes, 4042 (8.6%) shell genes, and 153 (0.3%) cloud genes, which were present in more than 99% (> 337), 95–99% (324–337), 1–95% (4–323), and less than 1% (< 4) of accessions, respectively (Fig. 1a; Additional File 1: Fig. S2). To verify the accuracy of gene PAVs, a PCR experiment of five dispensable genes in 23 randomly selected accessions matched the results from the bioinformatics analysis (Additional File 1: Fig. S3; Additional File 2: Table S3), further confirming the reliability of the gene PAV data and providing confidence in the pangenome.
Fig. 1
Pangenome of Gossypium arboreum. a The gene number and presence composition of the G. arboreum pangenes. Pie charts correspond to the proportions of the core, soft core, shell, and cloud genes according to gene presence in the population. b The modeling analysis of the number of pangenes and core genes in 341 cotton accessions. The top and bottom edges represent 99% confidence intervals. c The boxplot displays the number of genes in each group. P-values (“***” indicate P < 0.01) were calculated by a two-sided Mann–Whitney U test. d Maximum-likelihood tree of the 326 known geographic accessions was constructed using the 5632 dispensable genes. e Heatmap showing the PAVs of 5632 dispensable genes in 326 accessions. K-means (K = 4) clustering was used to cluster genes. Each cluster is shown with one or two geographical distributions, and enriched GO terms in each cluster are displayed in the right panel
We explored the associations between the gene PAVs and genic features, encompassing Pfam domain annotation, expression level, exon number, gene length, selective constraint, and TE coverage. The result demonstrated a significant association between gene PAVs and the investigated genic features (Additional File 1: Fig. S4). Specifically, dispensable genes were more likely to be evolving under relaxed selective constraint compared to core genes, indicating that the evolution rate of dispensable genes was faster than that of core genes, consistent with previous findings in rice, tomato, and wheat [14, 15, 21]. Our analysis also showed a closed pangenome, and we gradually increased the number of selected samples to estimate the size of the pangenes and core genes (Fig. 1b), indicating that the sampling strategy in this study covered the genetic diversity in diploid A-clade cotton.
The gene PAV-based phylogenetic analysis showed that the PAVs were broadly distributed within different subpopulations. Interestingly, we observed that the Chinese (CHN) group encoded more genes than the South Asian and US groups (Fig. 1c), indicating that G. arboreum migrated to high latitudes and formed distinctive genes after long-term selection. Moreover, we identified a small clade of US accessions that were clustered with accessions from South Asia and CHN in the phylogenetic tree (Fig. 1d), suggesting that some US accessions were genetically mixed with accessions from South Asia and China. We further tabulated the PAV genes in four subpopulations. The k-means algorithm classified the 5632 dispensable genes into four clusters. Each cluster enriched one or two geographic origins, and accessions with different geographic origins had clear divergence. In cluster I, we found that 1128 genes had a lower presence frequency in 326 accessions, which were enriched in the gene functions of ion transport and sodium channel binding and lyase activity. The 385 genes in cluster II were mainly present in G. herbaceum and were involved in terpene synthase activity. The 995 genes in cluster III tended to be of CHN origin, which was involved in hydrolase activity and acyltransferase activity. Cluster IV contained 3124 genes that tended to be of both CHN and US origin, which were involved in basic biological processes (Fig. 1e). To investigate signals of gene frequency changes between the CHN and non-CHN populations, we conducted comparisons based on the dispensable genes. Genes exhibiting a substantial frequency change (fold change > 2 or < 0.5; FDR < 0.001) were categorized as either favorable or unfavorable in the CHN group. Specifically, we identified 645 genes with high frequency and 103 genes with low frequency in the CHN group. GO analysis unveiled that the functions of CHN favorable genes were enriched in cellulose synthase activity and terpene synthase activity. Low-frequency genes were enriched in channel activity, indicating potential implications in maintaining cellular homeostasis, signal transduction, and various physiological processes (Additional File 1: Fig. S5).
The pangenome improves eQTL detectionIt has been suggested that PAVs are more likely than SNPs to alter gene expression [22]. In this study, we identified 725,998 PAVs in NRSs. Then, we integrated the RNA-seq data from 216 accessions at 5 fiber development timepoints and SNP-PAV variations to perform expression quantitative trait locus (eQTL) analysis. We identified an average of 3301 best cis-PAV-gene pairs with significant expression associations with a false discovery rate (FDR) less than 0.05 at each timepoint, compared with an average of 1942 cis-SNP-gene pairs (Fig. 2a), which showed a strong link between PAVs and gene expression regulation during fiber development. For these, we compared the results from previous research and found that an average of 2342 cis-PAV genes were novel in each period [23]. In addition, we observed that PAVs tend to be located farther away than SNPs from the regulated genes (Fig. 2b).
Fig. 2
eQTL analysis based on the pangenome and enhanced discovery of causal variation. a Bar plot showing significant eQTLs identified by PAVs and SNPs at different fiber developmental stages. b Distance of the significant variation from the TSS of the associated genes. c An example of a PAV lead-eQTL for the Garb_10G032080 gene. The y-axis represents the significance of the association. d Boxplot of the gene expression levels of different PAV alleles at different fiber developmental stages
Compared to eQTL analysis with SNPs, analysis with PAVs could improve the power for detecting more significant variations; for instance, many SNPs were found to be associated with the transcript expression of the gene Garb_10G032080 (Fig. 2c). This gene has been reported previously as a candidate gene that is known to bind ubiquitin and is associated with cotton fiber length [23]. The top signal of SNPs was located 28.4 kb downstream of the Garb_10G032080 gene (P = 1.24 × 10 −9). We observed a PAV (NRS_166316), located 1.3 kb downstream of the Garb_10G032080 gene, which was more significant than the top SNP signal (P = 7.26 × 10 −15). The gene expression level of Garb_10G032080 is significantly lower in the presence of NRS compared with that of its absence (Fig. 2d). These findings underscore the importance of considering structural variations in eQTL analyses; nevertheless, more functional gene studies should be carried out in the future.
NRSs reduce comparative genomic biasA previous comparative genomic study revealed extensive PAV sequences between diploid and tetraploid cottons [12]. However, the origin of the PAV sequence after polyploidization is difficult to determine. For example, diploid-specific sequences cannot be distinguished from sequences lost in polyploids or nascent in diploids. We addressed the problem of the origin of PAVs through genome-specific kmers and pangenome comparisons (Additional File 1: Fig. S6). First, by comparing the reference genome sequences between A2 and At, we found 202,411 and 99,002 genome-specific kmers, respectively (Fig. 3a), indicating that the A2 genome acquired a very large genome-specific kmers after speciation compared with At. Similarly, we also found 417 and 62,070 genome-specific kmers in D5 and Dt, respectively (Fig. 3b), and genome-specific kmers were rare in D5, suggesting that they might have been conserved after polyploidization. In addition, we found that 43,007 genome-specific kmers were shared between At and Dt, implying that the genome-specific kmers in the two subgenomes coincided.
Fig. 3
Sequence gain and loss after polyploidization. a, b Unsupervised hierarchical clustering was used to identify diploid and tetraploid genome-specific kmers. The heatmap indicates the Z-scaled relative abundance of genome-specific kmers, and the color bar on the top axis indicates the kmer assigned to a given genome. c Schematic illustrating the increase or decrease in PAV sequences in cotton. d Distribution of intraspecific PAV sequences in the At subgenome. Some genes are shown. These sequences are absent in the A2 reference genome but present in NRSs and tetraploid genome sequences. e The FBP and HDH variation in the A2 pangenome and At subgenome. The pie chart represents the gene presence frequency in the 341 accessions. f, g A permutation test was used to assess the distance of lost sequences from genes in the A2 and D5 genomes. The green bars represent the observed lost sequence with gene distances, and the black bars represent the relationship between random sequences and gene distance. h GO enrichment of genes in lost sequences in A2 and D5
Second, we divided the A2 pangenome into 1 kb segments and aligned them to At to identify A2-specific sequences. The A2-specific sequences containing A2-specific kmers were considered nascent in A2 (see the “Methods” section). Otherwise, they represented lost sequences in the At subgenome. In total, we found that 280 Mb of sequences were specific to A2, of which 188.3 Mb were nascent in A2 and 91.8 Mb were lost in the At subgenome (Fig. 3c). For nascent sequences in the At subgenome, a pangenome comparison can reduce bias from reference genomes. We divided the At-genome sequences and aligned them to the A2 reference genome to identify At-specific sequences. This analysis gave rise to 201 Mb of sequences that were not matched. However, by aligning the At-genome sequence to the A2 pangenome, the length of unaligned sequences was reduced to 142.4 Mb, of which 71.2% (101.5 Mb) contained At-specific kmers that were considered nascent sequences in the At subgenome. Furthermore, although the nascent sequences in the At genome amounted to only 101.5 Mb, they comprised 60.9% of the full-length LTR retrotransposons in the At subgenome. We also compared them with the D5 genome to identify nascent sequences in Dt. It was found that 59.6 Mb of nascent sequences contained 73.6% of full-length LTR retrotransposons in the Dt subgenome. In summary, we obtained the numbers of nascent and lost sequences in tetraploid cotton. The genome sizes of the two subgenomes were both expanded, but the At subgenome had fewer nascent sequences than the A2 genome (At ~ 101.5 Mb vs. A2 ~ 188.3 Mb), as well as more lost sequences (At ~ 91.8 Mb vs. A2 ~ 40.9 Mb), causing a decrease in the size of the At subgenome.
To test the accuracy of the use of genome-specific kmers for determining the source of PAV sequences, we checked the coverage of At-specific kmers in a 1310 Mb At shared sequence and revealed that only 116.2 kb sequences contained the At-specific kmer, which suggests the high accuracy of determining tetraploid nascent sequence by genome-specific kmers. Similarly, we examined the A2-specific kmers in 1341 Mb of A2 shared sequences and found that 224.6 Mb of the sequence contained the A2-specific kmers, implying possible underestimation of the content of nascent sequences in A2. Some nascent sequences may be highly similar to the At sequence, so they cannot be identified from genome comparison.
In addition, we found that ~ 60 Mb of the PAV sequences from the diploid A-genome comparison were intraspecific variations, which appeared in only a few accessions. The intraspecific PAVs were unevenly distributed across the genome (Fig. 3d). The longest PAV sequence was 124 kb and contained 21 genes (from 122.86 Mb to 122.98 Mb on chromosome 11). In Fig. 3e, two non-reference genes are highlighted as intraspecific variations. The fructose-1,6-bisphosphatase (FBP) gene plays a key role in sucrose synthesis and metabolism [24], participating in sugar regulation during cotton fiber development. We observed that FBP was lost on chromosome 11 of the “Shixiya 1” reference genome; nevertheless, this nonreference gene was present in 306 (89.7%) G. arboreum accessions. Similarly, histidinol dehydrogenase (HDH), associated with root growth [25], was missing on the A2 reference genome but present in 98.2% (335) of G. arboreum accessions. In total, 1324 nonreference genes were included in the intraspecific PAVs, which were considered to be lost in previous reference genome studies.
We also found that the sequence loss in tetraploid cotton was unbalanced between the two subgenomes. Analysis of the relationship between lost sequences and genes in diploids showed that the lost sequences were closer to genes than were random sequences in A2, but the opposite pattern was observed for D5. Meanwhile, the missing sequences in D5 were farther away from the genes than those in A2 (Figs. 3f, g). Further analysis showed that the lost sequences in gene regions and their flanking 2 kb regions were related to 4088 and 2920 genes in A2 and D5, respectively. In the At, lost genes were involved in multiple lyase activities, including pectate lyase activity, carbon–oxygen lyase activity, and aldehyde lyase activity (Fig. 3h), which might shape the adaptability of cotton to diverse environmental conditions. In the Dt, lost genes were involved in protein self-association, tubulin binding, and channel activity, which were associated with cotton fiber properties and response to external stimuli.
The evolutionary features of G. arboreum pangenesAccording to the phylogenetic tree, we assigned the 47,257 pangenes to five age catalogs (Fig. 4a). The oldest gene group was orthologous to genes in the monocot plant O. sativa, which included 51% of the genes. A total of 15.6% of the youngest genes were only present in pangenes (Fig. 4b), which could be considered species-specific genes that diverged from G. raimondii approximately 5.1–5.4 MYA. After linking gene age to conservation, we found that older genes had a higher presence frequency in the population; in contrast, new genes had a higher evolution rate. The gene length, expression level, and exon number were correlated with gene age, with an increase in the median number from the youngest to the oldest group (Additional File 1: Fig. S7), consistent with previous findings in O. sativa, A. thaliana, and H. sapiens [26,27,28,29].
Fig. 4
Gene age in the Gossypium arboreum pangenome. a Gene age distribution in the pangenome. The number indicates the number of gene clusters in each category. b The number of genes per gene catalog. c The proportion of nascent sequences overlapping with different ages of genes. d The boxplot shows the distance between nascent sequences and genes of different ages. e The Gypsy and Copia transposon insertions in G. arboreum pangenes near 2 kb regions. The pie charts represent the number of genes in which the coding regions contain LTR domains
We explored the relationship between nascent sequences and gene age in the pangenome and found that species-specific genes were more likely to be near nascent sequences and thus likely to reside closer to LTR retrotransposons (Fig. 4c). A total of 7.1% of species-specific genes in Age5 overlapped with nascent sequences, but in Age1, only 0.8% of genes overlapped with nascent sequences. With increasing gene age, the average distance to the nascent sequence increased (Fig. 4d).
In tomato and Arabidopsis, Copia retrotransposons were found to be located preferentially within or near genes, in contrast to Gypsy retrotransposons [30]. However, we found that the Gypsy superfamily existed more frequently than Copia in G. arboreum, especially in younger (Age5) genes (Fig. 4e, f). This opposite trend may be related to the ultrahigh Gypsy content in G. arboreum. We found that the coding sequences of 6217 genes contained TE domains (Additional File 2: Table S4), of which 3938 (63.3%) were caused by Gypsy insertion and were mostly concentrated in species-specific genes (2206 genes). This observation indicates that Gypsy may play a key role in the evolution of new genes in G. arboreum.
Gene loss and gain after polyploidizationWe explored single-copy gene variation patterns in both diploid (A2 and D5) and tetraploid (AD1) cotton. We divided the 9081 single-copy genes from the A-clade pangenes and D5 genes into four groups (Fig. 5a). The first group (two copies completely lost in the tetraploid) contained 413 genes, and 72.1% of lost genes were only present in the Gossypium genus at age 4 (Additional File 1: Fig. S8). The second group had genes reverted to a single copy from two copies, of which 1342 were lost with certain functional implications. Genes involved in DNA repair and targeted to the organelles tended to have a single copy after polyploidization. In addition, the frequency of gene loss was not equal between subgenomes, with higher rates of gene loss in the At subgenome (777 genes in At and 565 genes in Dt), consistent with findings in previous studies [31]. In the third group (balance), both copies were retained in the tetraploid, involving 7049 genes. The last group (277 genes) showed the lowest proportion, including the single-copy genes with copy numbers that increased after polyploidization.
Fig. 5
Single-copy gene states after polyploidization. a A proposed model of the status of single-copy genes after polyploidization. All genes belong to single copies in both diploid progenitor genomes, and the status 0 or 1 represents gene loss or retention in tetraploid subgenomes. b Pie charts showing single-copy gene loss in different situations. c The phylogenetic tree shows the relationship in the four genomes. The figure shows that the gene on chromosome A07 of the At subgenome was lost, accompanied by Copia LTR retrotransposon insertion. This gene was present in the other three genomes. The colored boxes indicate coding regions and protein domain information from the Pfam database. d–g Gene characterization with different status. Mean and SE values are indicated
To investigate the effect of TE activity on gene copy number loss, we analyzed TE insertions in gene body regions. We found that 145 (12.2%) and 185 (18.9%) single-copy genes were lost in At and Dt following LTR retrotransposon insertion, respectively (Fig. 5b), suggesting that TEs played an important role in single-copy gene loss, especially for Dt. An example of gene loss in tetraploid associated with Copia insertion is shown in Fig. 5c. The gene Garb_07G024840 (located in the At genome from 5.54 Mb to 5.78 Mb on chromosome A07) has a legume lectin domain related to plant defense against predators and was lost in the At genome but retained in the other three genomes (Fig. 5c). We examined the gene features of single-copy genes in different states. Genes with copy number loss had shorter coding length, lower expression levels, and higher Ka/Ks values and TE coverage (P < 2.2 × 10 −6, Wilcox test). The genes with copy number gain were more conserved than those with copy number loss (Fig. 5d–f).
TE drives genome size variation after polyploidizationThe most striking genome feature of polyploid cotton is the distinction of genome size compared with that of diploid progenitors. The Dt subgenome expanded from 750 Mb of D5 to 796 Mb, and the At subgenome (1437 Mb) was significantly reduced compared with A2 (1620 Mb). Comparison of genome components showed that Gypsy retrotransposons predominantly contributed to expansion of the A2 genome. The major types of TEs in Dt were more abundant than those in D5 (Fig. 6a), which might be responsible for the genome size evolution between the A and D genomes. The majority of fl-LTR (full-length LTR) retrotransposon copies from ancient bursts were usually truncated. However, some truncated fl-LTRs might have an intact structure in other Gossypium genomes, suggesting that the pangenome can help identify more full-length LTRs (see the “Methods” section). By using the four genome sequences, we constructed a pan-TE library and identified 13,865, 9991, 5661, and 2841 fl-LTR retrotransposons in the A2, At, Dt, and D5 reference genomes, respectively.
Fig. 6
LTR retrotransposon dynamics after polyploidization. a TE components in diploid and tetraploid cotton. b Comparison of LTR retrotransposon abundance in a different cluster. “A2” only has members in the A2 genome. “At_Dt” represents only the tetraploid genome, and “common” has members in all four genomes. c Amplification time of different classification clusters. d The LTR retrotransposon retention rate in four genomes. The X-axis indicates the CV (coefficient of variation) threshold of the truncated LTR length in four genomes, and the right indicates the LTR retention length with high variability in the homologous regions. e, f Linear regression analysis of insertion distances and insertion times for Gypsy and Copia
The analysis of fl-LTR retrotransposon insertion time showed that Gypsy elements underwent a burst in the A genome after speciation divergence (~ 0.6 MYA). Copia elements were relatively conserved among species, except for a small expansion in At and Dt (Additional File 1: Fig. S9). To elucidate the effect of polyploidization on LTR retrotransposon activity, we categorized the LTRs in the four genomes into different clusters based on sequence identity (Fig. 6b). We found extensive genome-specific LTR retrotransposons amplified in the A2 genome and only a few clusters with low copy numbers amplified in the other three genomes. The A2_At cluster had more copy numbers than D5_Dt, consistent with the fact that the A genome was larger than the D genome. Interestingly, the At_Dt shared cluster was massively amplified, representing concerted proliferation in tetraploids. The A2_At_Dt cluster included the LTR retrotransposon that might be transferred from At to Dt. These results suggested that LTR retrotransposons were subject to exchange between the two subgenomes in tetraploid cotton. The LTR retrotransposons conserved in all four genomes belonged to the oldest copies that might have already existed before polyploidization.
We calculated the burst time of different clusters (Fig. 6c). The LTR retrotransposon specific to either the A or D genome amplified approximately 2 MYA, consistent with the time of allopolyploidization, suggesting that the two subgenomes were subject to independent evolution in the diploid lineages. Notably, in the Gypsy superfamily of the tetraploid-specific cluster, At_Dt dominated the new sequence after polyploidy, and LTR retrotransposon amplification was coincident between the two subgenomes (Additional File 1: Fig. S10).
We clustered the reverse transcriptase (RT) domains from the fl-LTR retrotransposon and found parallel subgenome evolution of copy number variation in different families (Additional File 2: Table S5). For example, the Tekay family was abundant in the cotton clade with the A genome, but the copy number increased significantly in Dt compared with D5 and decreased in At compared with A2. This was similar to a previous finding of CRG (Centromere Retroelement Gossypium), which was detected in the centromere regions of D5, At and Dt, while none existed in all diploid A-clade species, indicating that CRG in Dt might invade the centromere regions of the At subgenome [32].
The TE content was affected by both amplification and elimination. Accordingly, rapid LTR retrotransposon elimination can reduce TE diversity and decrease genome size. We analyzed the consequences of TE elimination events in each genome. The 32,059 homologous truncated LTR retrotransposon regions were used to analyze the retention rates in the four genomes. Most of the homologous regions had a similar retention rate in the four genomes. However, we found that in some homologous regions with highly variable retention lengths, the average retention rate in tetraploid cotton was lower than that in diploid cotton (Fig. 6d), and that in Dt was slightly lower than that in the At subgenome, which suggests a faster LTR retrotransposon elimination rate in tetraploid cotton. This was consistent with the above genome PAV results (Fig. 2c). In addition, we found no difference in the LTR retrotransposon retention rate across different TE superfamilies in the whole genome (P > 0.05, t test), which suggests that the key factor affecting the LTR retrotransposon component is insertions and that the deletion rate is stable in the cotton genome.
In terms of the relationship between LTR retrotransposons and genes, we explored the relationship between burst time and insertion distances in four genomes (Fig. 6e, f). For the Gypsy superfamily, the recent insertion was predominantly located far from genes, and the magnitudes of the slopes of the regression lines were −6.82, −5.92, − 9.02, and −1.12 for A2, At, Dt, and D5, respectively. However, Copia insertions tended to occur around genes, and the magnitudes of the slopes were positive at 1.24, 1.73, 0.669, and 0.554, respectively. This suggested that these two LTR retrotransposon families have different effects on the genome.
Despite the LTR retrotransposon burst after polyploidization, the distance of neighboring homologous genes tended to be conserved, and the ratio of diploid and tetraploid homologous distances had a strong peak at 1 (0 on a log scale) (Additional File 1: Fig. S11). These results indicated that the cotton genome might have responded to selection to regulate the relative positional stabilization of homologous genes.
留言 (0)