
記住我


ADHD is a common neurodevelopmental disorder that widely affects children and adults worldwide. Its main characteristics include persistent inattention, hyperactivity and impulsive behaviors, which often have a significant impact on an individual's ability to learn, socialize, and work (Tang et al., 2020). The diagnosis of ADHD is complex and varied and often requires a combination of medical, psychological and behavioral evaluations (Loh et al., 2023). Currently, the exact cause of ADHD is not fully understood, and it is widely believed that a combination of genetics, environmental factors, and variations in brain development play a role (Tan et al., 2023). This complexity makes accurate diagnosis and effective treatment of ADHD a challenge (Amado-Caballero et al., 2020). Traditional diagnosis of ADHD relies on behavioral observations and psychological assessments, but these methods carry the potential for subjective judgments that can lead to diagnostic inconsistencies and accuracy issues (Shoeibi et al., 2023). In addition, due to the diversity of ADHD symptoms and their similarity to other disorders, it is often difficult for a single diagnostic approach to fully capture the full picture of the disease (Berrezueta-Guzman et al., 2021a). Therefore, researchers have been seeking more objective and accurate diagnostic tools.
The analysis of motor information plays a pivotal role in ADHD research and treatment, as hyperactive behavior significantly influences a patient's daily functioning and learning capabilities (Enriquez-Geppert et al., 2019). Motor control issues and hyperactivity, essential for diagnosis and treatment planning, offer insights into behavioral and neurophysiological changes in individuals with ADHD (Chen et al., 2020; Slobodin et al., 2020; Berrezueta-Guzman et al., 2021b). Movement tracking technologies and comprehensive analysis of motor behaviors can elucidate ADHD's neurobiological foundations (Amado-Caballero et al., 2023), enhancing diagnostic accuracy and aiding the development of more effective treatments (Berrezueta-Guzman et al., 2022). Additionally, advancements in Artificial Intelligence (AI) have transformed ADHD diagnosis and treatment strategies, with machine learning techniques uncovering complex patterns in data, facilitating preliminary feature selection and analysis (Moghaddari et al., 2020; Zhang et al., 2021a; Tang et al., 2022). This evolving AI landscape necessitates sophisticated, integrative models for a more nuanced understanding of ADHD (Leontyev et al., 2019; Yeh et al., 2020).
However, challenges remain in harnessing AI for ADHD research, notably in data acquisition, processing, and model comprehensiveness and interpretability. High-quality data collection and processing are critical for reliable research outcomes, but standardized, comprehensive datasets are difficult to obtain due to data diversity, complexity, and privacy concerns (Öztekin et al., 2021). Furthermore, the significant individual variability in ADHD symptoms and behaviors requires models that can integrate various data sources and analytical methods to accurately reflect these differences (Chen et al., 2021), highlighting the need for continued innovation in AI methodologies to address these challenges effectively.
In response to the identified gaps in existing research, we have developed an innovative network model that seamlessly integrates Random Forest, Temporal Convolutional Network (TCN), and Adaptive Control of Thought-Rational (ACT-R) to examine the effects of physical exercise on ADHD patients. This integrated framework is designed to transcend the limitations of traditional methodologies by leveraging the distinct strengths of each component (Speiser et al., 2019), thereby enhancing diagnostic accuracy and efficiency in handling complex ADHD-related data. The Random Forest algorithm, recognized for its prowess in managing high-dimensional data, plays a pivotal role in our model by identifying and isolating key features associated with ADHD symptoms. This process not only aids in refining input data for deeper analysis but also capitalizes on its capability to navigate non-linear and intricate data relationships (Dimov et al., 2020). Concurrently, the TCN model, with its specialization in processing time-series data, adeptly captures the dynamic changes in behavior and physiology characteristic of ADHD, thus offering a nuanced reflection of the patients' behavioral patterns and physiological states over time.
The model performs feature extraction and selection of multi-source data through the Random Forest algorithm to effectively identify key features associated with ADHD symptoms. Next, TCN is used to analyze time-series data from these features to capture behavioral and physiological signals over time. The ACT-R model is used to simulate the cognitive processes of ADHD patients to help predict their behavioral responses and symptom performance. Finally, the results of these analyses are synthesized and optimized for diagnosis and treatment prediction of ADHD using deep learning algorithms. By integrating these three models, our network model is able to provide an in-depth understanding of the behavioral and cognitive characteristics of ADHD patients from multiple dimensions and optimize the diagnosis and treatment prediction of ADHD using deep learning algorithms. This multidimensional and multimodal integrated approach is not only more accurate and effective in dealing with complex ADHD data, but also improves the accuracy of diagnosis and personalization of treatment. In addition, this approach helps to reveal the complex pathological mechanisms of ADHD, providing new perspectives and methods for future research and treatment strategies. This fusion model not only deepens the understanding of ADHD, but also provides a new, more precise and comprehensive analytical tool for clinical practice, which has important application value. In the subsequent sections of this thesis, we will detail our model architecture and experimental results to validate its effectiveness in studying the effects of exercise in patients with ADHD.
The contribution points of this paper are as follows:
• We have successfully developed a novel fusion model that integrates Random Forest, TCN, and ACT-R algorithms. This innovative integration approach has demonstrated outstanding performance in processing ADHD data, particularly in enhancing diagnostic accuracy and understanding the pathophysiology.
• Our research is the first to combine deep learning techniques with cognitive psychology models in the analysis of ADHD, providing a new perspective for the diagnosis and treatment of ADHD. This interdisciplinary approach allows us to gain a deeper understanding of the behavioral and cognitive characteristics of ADHD patients, laying the groundwork for developing more effective personalized treatment strategies.
• Our model has been validated on actual clinical data and has shown efficient computational performance and good scalability. This achievement not only proves the practicality of our model but also provides a reliable reference for applying deep learning and cognitive models in future research on similar complex neurological disorders.
2 Related work 2.1 DNN for analyzing ADHD patients' response to exerciseRecent endeavors in the realm of ADHD research have seen the application of Deep Neural Networks (DNN) to parse through complex, multidimensional datasets (Baxi et al., 2022), ranging from biometric readings to comprehensive behavioral assessments (Gupta et al., 2022). By harnessing the power of DNN, researchers aim to uncover the nuanced effects that physical activities exert on the ADHD phenotype, hoping to identify patterns that correlate with symptom alleviation or exacerbation (Wang et al., 2024). The capability of DNN to process vast arrays of input data and to learn from these inputs in an unsupervised or semi-supervised manner has opened up new avenues for predicting the outcomes of various therapeutic interventions, including exercise and movement-based therapies.
However, deploying DNN in ADHD research is fraught with challenges. The primary issue revolves around the interpretability of the models. The intrinsic complexity of DNN architectures, while a boon for navigating large data sets, renders the extraction of clear, actionable insights difficult (Ahmadi et al., 2021). Clinicians and therapists seeking to apply these findings are often met with a gap between statistical significance and practical applicability. Moreover, the reliance on extensive computational resources for data processing and model training limits the accessibility of DNN methodologies, particularly in resource-constrained research environments. The demand for vast, meticulously annotated data sets further complicates research efforts (Hernández-Capistran et al., 2023), given the inherent variability in ADHD manifestations across individuals and the ethical considerations tied to patient data privacy.
2.2 SVM in identifying ADHD biomarkers from physical activity dataThe use of Support Vector Machines (SVM) in analyzing behavioral data presents a focused approach to understanding ADHD, especially in the context of physical activity interventions (Mohd et al., 2022). SVM's robust classification capabilities allow for the distinction between ADHD-affected individuals and their neurotypical peers based solely on quantified behavioral metrics derived from physical activity patterns (Wang et al., 2018). Such analyses are instrumental in pinpointing potential behavioral biomarkers for ADHD, facilitating a deeper comprehension of the disorder's external manifestations and the ways in which targeted physical interventions might ameliorate or modify these behaviors.
Despite the strengths of SVM in classification tasks, the model's application in ADHD research is not devoid of limitations. The necessity for labeled data poses a significant bottleneck (Chen et al., 2023), especially in early-stage research where diagnostic ambiguity prevails. Additionally, SVM models, traditionally linear, may struggle with the complex, non-linear behavioral patterns characteristic of ADHD, even though kernel methods can offer some mitigation (Eslami et al., 2021). The focus on behavioral data, to the exclusion of neurophysiological or cognitive data, might also narrow the scope of findings, potentially overlooking multifaceted aspects of ADHD symptomatology.
2.3 CNN for processing EEG data in ADHD exercise studiesConvolutional Neural Networks (CNN) have revolutionized the analysis of neurophysiological data, such as EEG, offering fresh perspectives on the neurological aspects of ADHD (TaghiBeyglou et al., 2022). The application of CNN to EEG data pre- and post-physical activity interventions has shed light on the neurophysiological shifts that might underlie observed behavioral changes in ADHD patients. CNN's adeptness at detecting spatial hierarchies in data makes it uniquely suited to identifying patterns within the complex signals characteristic of EEG recordings (Ribas et al., 2023), providing a conduit for exploring the neurobiological impact of exercise on individuals with ADHD.
The implementation of CNN in the study of ADHD through neurophysiological data is not without challenges. The model's sensitivity to the specificities of the training data raises concerns about overfitting (Delvigne et al., 2021), particularly acute in neurophysiological studies where sample sizes are often limited. The preprocessing required to adapt EEG data for CNN analysis is both intricate and labor-intensive, risking the introduction of bias or the loss of critical information (Sawangjai et al., 2019). Moreover, the complexity of CNN outputs complicates their translation into clinically relevant insights, presenting an ongoing challenge for bridging the divide between advanced AI-driven analyses and actionable treatment strategies for ADHD.
By elaborating on these studies, we gain a nuanced understanding of the current landscape of AI in ADHD research concerning physical activity, acknowledging the progress made and the hurdles that lie ahead. This comprehensive view serves as a critical stepping stone for future investigations aimed at harnessing AI's full potential in this domain.
3 Materials and methods 3.1 Overview of our networkIn this study, we have developed an integrated model combining Random Forest, Temporal Convolutional Network (TCN), and Adaptive Control of Thought-Rational (ACT-R) to investigate the effects of physical activity in patients with ADHD.
We developed a comprehensive model that integrates the strengths of Random Forest, TCN and ACT-R to cope with the complexity of ADHD. Random Forest is crucial for feature selection and extraction. It processes the initial input data, identifying and isolating key features that are most relevant to ADHD symptoms and motor activities. The strength of Random Forest lies in its ability to handle high-dimensional data and uncover complex, non-linear relationships, making it ideal for the initial analysis stage. TCN serves as the core component for analyzing time-series data, particularly motor monitoring and neurophysiological data. Its architecture, designed to handle sequential data, captures temporal dependencies and dynamic changes in ADHD patients' behavior and physiological responses. TCN's effectiveness in our model stems from its deep, dilated convolutional structure, enabling detailed analysis of intricate time-related patterns. ACT-R is utilized to simulate and interpret the cognitive processes of ADHD patients. This model integrates the outputs from the Random Forest and TCN, providing a cognitive perspective to the analysis. It helps in understanding how ADHD affects cognitive functions and how physical activities might influence these cognitive patterns.
The workflow of our integrated model, detailing the collaborative functions of Random Forest, TCN, and ACT-R in the context of ADHD physical activity research, is systematically illustrated in the flowchart presented in Figure 1. In constructing our integrated network model, we began with the data processing of the original dataset, which included Bootstrap resampling to ensure consistency of data across the training and test sets. The Random Forest algorithm was trained on dataset S, selecting key features based on importance rankings. These features were then transformed into time series datasets S' and W' using a moving window function, preparing them for TCN training. This process readied TCNs for training by sliding a fixed-size window along the time axis of the dataset and capturing local data features within each window. The generated time series datasets were then fed into the TCN, which was trained using its residual blocks defined by kernel size k and dilation coefficient d to build the RF-TCN predictive model. Data processed through these residual blocks passed through Flatten and Dense layers to generate the final output.
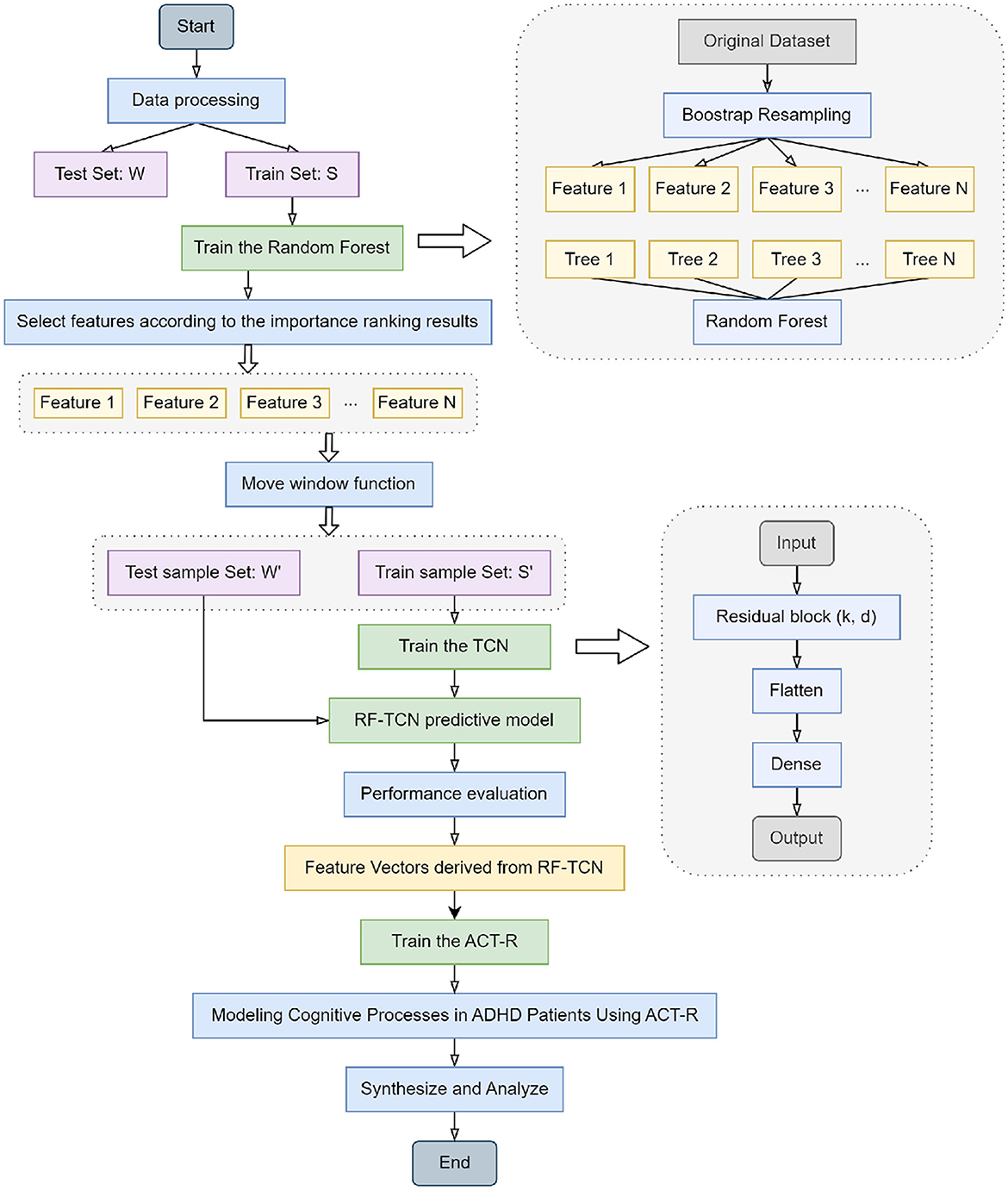
Figure 1. Flowchart of the overall structure of our model.
Upon the training and performance evaluation of the RF-TCN model, we proceeded to integrate the ACT-R model. The input to the ACT-R model consists of feature vectors derived from the Random Forest and Temporal Convolutional Network (RF-TCN) model. These vectors encapsulate the significant features related to ADHD symptoms' behaviors and physiological responses, pinpointed through our initial analyses. Utilizing this input, the ACT-R model was further trained to simulate the cognitive processes of ADHD patients. This process aimed at blending the time series analytical capabilities of the RF-TCN model with the cognitive simulations facilitated by the ACT-R framework. The output of the ACT-R model encompasses predictions on cognitive states and potential behavioral responses of ADHD patients to various exercise regimens. By providing a comprehensive analysis of the behavioral and cognitive patterns of ADHD patients under physical intervention, this output is invaluable for understanding how specific exercises can influence cognitive functions and behavioral patterns in patients with ADHD. This integrated approach not only enhances our ability to understand and evaluate the impact of physical activity on ADHD patients but also lays the groundwork for further personalized treatment approaches, aiming to tailor individualized exercise-based treatment plans based on the predictive insights generated by the ACT-R model.
The significance of our model lies in its multifaceted approach to understanding ADHD. By combining the strengths of Random Forest, TCN, and ACT-R, our model offers a comprehensive analysis of ADHD patients' motor activities and their cognitive implications. This integrated approach allows for a deeper understanding of how physical activity affects ADHD patients, not just in terms of immediate motor responses but also in long-term cognitive and behavioral changes. The model's ability to process complex data and provide insights into the temporal dynamics of ADHD presents a significant advancement in researching effective treatment and management strategies for ADHD, particularly in the realm of physical interventions.
To ensure the trustworthiness and transparency of our AI model, we incorporated an interpretability and reliability analysis into our methodology. For interpretability, we utilized SHapley Additive exPlanations (SHAP) values to quantify the impact of each feature on the model's predictions. This approach helps in identifying the most influential factors contributing to the model's decision-making process. Additionally, to assess the reliability of our model, we employed a rigorous cross-validation technique, along with an external validation on a separate dataset, ensuring the model's robustness and its capability to generalize across different populations.
The interpretability analysis revealed that certain features, such as the duration and intensity of exercise, played a significant role in the model's predictions regarding the effectiveness of exercise in ADHD patients. SHAP value plots highlighted these features' positive influence on the model's confidence in predicting improvement in ADHD symptoms, offering insights into how exercise routines can be optimized for therapeutic purposes.
The reliability analysis, conducted through 10-fold cross-validation and further validated on an external dataset, demonstrated consistent accuracy levels, underscoring the model's robustness. The slight variations observed across different folds were within acceptable limits, indicating the model's capability to generalize and perform reliably in diverse settings.
3.2 Random ForestRandom Forest is a machine learning classifier composed of multiple decision trees. It is capable of handling classification, regression, and dimensionality reduction problems (Borup et al., 2023). In a Random Forest, each decision tree operates independently and without correlation to others (Sheykhmousa et al., 2020). For classification tasks, each tree classifies the test sample, and the final category is determined by the mode of the outputs from the forest, essentially using a voting mechanism to decide the category of the test sample. For regression tasks, the final result is the average of the outputs from all trees. Compared to a single decision tree, Random Forest exhibits a stronger tolerance to outliers and noise and shows better performance in both prediction and classification (Cheng et al., 2019).
A decision tree is a commonly used algorithm for classification and regression (Maji and Arora, 2019). It constructs a tree-like structure by dividing the dataset into different subsets, where each node represents a feature, each branch represents a value of that feature, and each leaf node represents a category or a value. In building a decision tree, the optimal feature for splitting must be selected, which necessitates the concept of entropy. Entropy is a measure of the uncertainty of a dataset (Li et al., 2021); the greater the entropy, the higher the uncertainty. In decision trees, we aim to select the optimal feature that minimizes the entropy of the subsets post-split, thereby enhancing the accuracy of the decision tree. Therefore, entropy can be used to measure the information gain of each feature, aiding in the selection of the optimal feature.
The entropy in a decision tree can be calculated using Equation 1:
H(D)=-∑i=1npilog2pi (1)Here, H(D) denotes the entropy of dataset D, n is the number of categories in D, and π represents the proportion of samples of the ith category in D. To calculate entropy, we compute the proportion of each category in the dataset and substitute these into the formula.
In decision trees, it is also necessary to calculate the information gain of each feature for optimal splitting. Information gain can be calculated using Equation 2:
Gain(D,a)=H(D)-∑v=1V|Dv||D|H(Dv) (2)where Gain (D, a) denotes the information gain of dataset D on feature a, H(D) is the entropy of dataset D, V represents the number of values for feature a, Dv is the subset of samples where feature a has the value v, |Dv| is the number of samples in Dv, and |D| is the number of samples in dataset D. When calculating information gain, we compute it for each feature in the dataset and select the feature with the highest information gain for splitting.
The process of Random Forest involves several key steps. Initially, it includes a random sampling process where the model samples both rows and columns from the input data. For row sampling, it employs a bootstrap method, meaning that the sampled dataset may contain duplicate samples. If the input sample size is N, then the sampled dataset will also have N samples. This approach ensures that each tree in the training phase does not use all the samples, reducing the likelihood of over-fitting. For column sampling, out of M features, a subset of m features (where m < < M) is selected. Following this, decision trees are constructed using a complete splitting method, where each leaf node either cannot be further split or contains samples belonging to the same category. Unlike many decision tree algorithms that involve a crucial step of pruning, Random Forest does not require this due to the randomness introduced in the two sampling processes, thereby preventing over-fitting even without pruning.
The procedure then involves drawing a specific number of samples from the training set randomly to form the root node samples for each tree. During the construction of the decision trees, a set number of candidate attributes are randomly selected, and the most suitable one is chosen as the splitting node. Once the Random Forest is built, for a test sample, each decision tree produces either a class output or a regression output. In classification problems, the final category is determined through a voting mechanism among the decision trees, while for regression problems, the final result is the average output of all the trees. As depicted in the Figure 2, suppose a Random Forest consists of three decision trees, with two trees classifying a sample as Category B and one as Category A, the Random Forest would classify the sample as Category B.
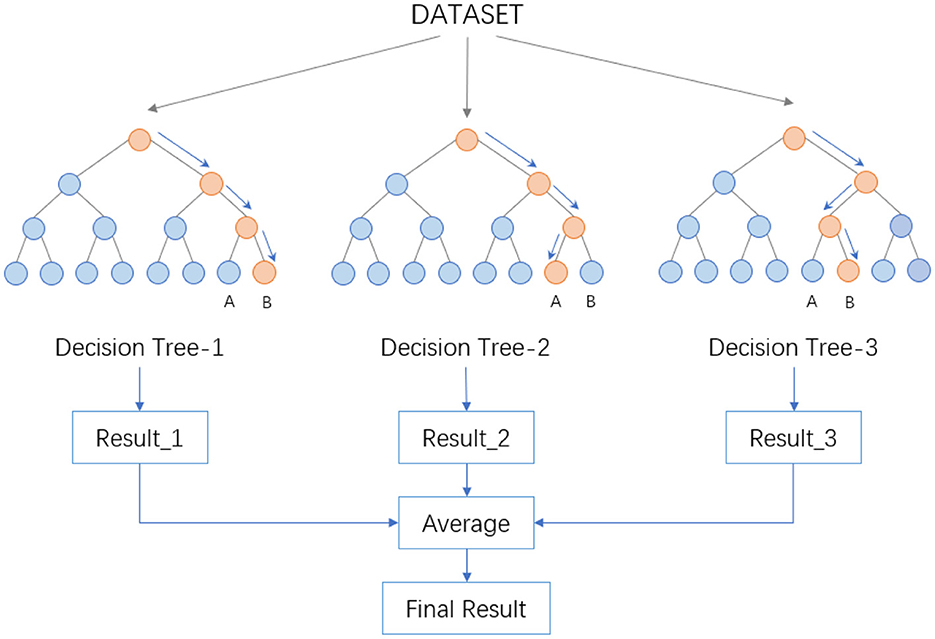
Figure 2. Data processing flow in random forest.
The randomness in Random Forest is reflected in two aspects. Firstly, it's exhibited in the randomness of sample selection, where a certain number of samples are randomly drawn from the training set with replacement to construct sub-datasets. These sub-datasets are of the same size as the original dataset, and elements within them can be repeated. Secondly, the randomness is in the selection of attributes. During the construction of each decision tree, a certain number of candidate attributes are randomly selected, from which the most suitable attribute is chosen for the splitting node. This process ensures diversity among the trees in the Random Forest, thereby enhancing the classification performance.
In our research, Random Forest, as a core tool, works in conjunction with the ACT-R model and the TCN model, playing a vital role. It employs an ensemble learning approach to comprehensively process and analyze data and insights obtained from both the ACT-R and TCN models. The ACT-R model is used to simulate the cognitive processes of ADHD patients, particularly during physical activities, while the TCN model primarily handles time-series data related to movement, such as motion monitoring or neurophysiological data.
The primary task of the Random Forest is to integrate and analyze these diverse data sources. Through its multitude of decision trees, Random Forest is capable of effectively handling high-dimensional and complex datasets, which is crucial for our research. It aids in identifying key factors affecting ADHD patients from multiple dimensions and enables precise predictions. Through the analysis conducted by Random Forest, we gain a deeper understanding of the potential cognitive and behavioral impacts of physical interventions on ADHD patients and predict the potential effects of different types of physical interventions on various patient groups. These insights are invaluable for designing more effective treatment plans and intervention measures, providing us with data-driven decision support.
Especially in the context of studying the impact of physical activities on ADHD patients, the application of Random Forest is particularly significant. It integrates various data sources, such as neuroimaging data and behavioral observation data, offering a comprehensive analytical perspective for our research. By analyzing different feature combinations, Random Forest helps to reveal the effects of physical interventions on the cognitive and behavioral patterns of ADHD patients. Its high-accuracy predictive and classification capabilities can also be used to assess the effectiveness of physical interventions for different types of ADHD patients and identify which patients may benefit most from specific types of physical activities. Thus, Random Forest becomes a powerful tool in addressing this complex issue.
3.3 Temporal convolutional networksThe Temporal Convolutional Network (TCN) is a neural network architecture specifically designed for processing time series data, with its core feature being the utilization of one-dimensional convolutional layers for handling such sequential data. A key characteristic of the TCN is causal convolution, ensuring that the model uses only the current and previous data points for predictions, effectively preventing the leakage of future information. This attribute is crucial for ensuring the accuracy and reliability of the model's predictions. Additionally, TCN incorporates a design with residual connections, similar to those used in ResNet. These residual connections help address the issue of vanishing gradients common in training deep networks (Gao et al., 2023), thereby enhancing the efficiency and stability of model training. This is particularly significant when dealing with complex time series data. Through its unique structure and functions, the TCN provides an effective method for understanding and analyzing time series data, making it particularly suitable for applications involving long-term data dependencies and complex dynamic patterns.
TCN, built upon the principles of CNN, features a dilated causal convolution architecture that maintains equal lengths for both input and output. The specific structure of this dilated causal convolution is depicted in Figure 3. This design choice in TCN, emphasizing dilated convolutions, enables the model to efficiently handle sequential data while preserving the temporal sequence length from input to output.
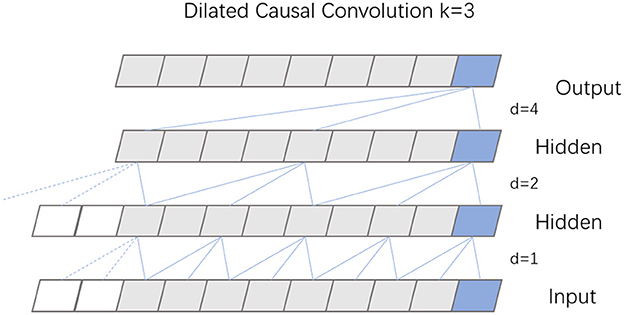
Figure 3. Structure diagram of dilation causal convolution.
Causal convolution is designed to exclusively consider present and past data points, disregarding any future information. This approach means that for any given time t in the output sequence, the result is influenced solely by the input sequence's elements at time t and earlier, thus preserving the integrity of historical data. Expanding on this concept, dilated convolution incorporates a dilation coefficient d, which dictates the interval at which the input is sampled, thereby enlarging the receptive field of each convolutional layer. The extent of this dilation, and consequently the sampling rate, hinges on the value of d. Typically, as a network deepens, the dilation coefficient d increases exponentially, often doubling with each added layer. To maintain uniformity in the size of the data through the network layers, and to ensure the output layer matches the width of the input layer, zero padding is employed within each layer of the dilated causal convolution.
To mitigate the problems of vanishing and exploding gradients that often arise in overly deep network structures, TCN incorporates a specifically designed residual block. This block consists of two layers of dilated causal convolution, complemented by a non-linear mapping arrangement that incorporates both a WeightNorm and a Dropout layer. A detailed illustration of this residual block structure is presented in Figure 4. The WeightNorm layer functions to standardize the weights within the network layer, thereby streamlining the training process, while the Dropout layer plays a crucial role in preventing overfitting. This configuration equips the TCN with the combined attributes of CNNs and RNNs. Its uncomplicated yet adaptable structure allows for parallel processing of input sequences, which significantly cuts down on both the memory usage and time required for network training. In medical and health research applications, TCN's capability to forecast long-step outputs from complex feature sets demonstrates a notable advantage over traditional models like LSTM and GRU.
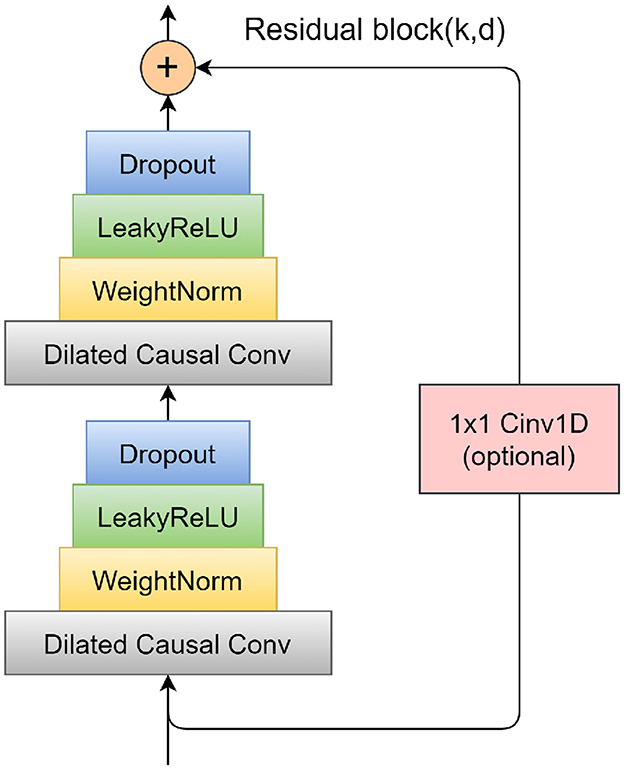
Figure 4. Schematic diagram of residual block.
In our experiments, the TCN works in conjunction with the Random Forest and ACT-R models, providing support for research into the impact of physical activity on patients with ADHD (Tian et al., 2023). The primary role of the TCN in this model combination is to process and analyze time series data, such as movement monitoring and neurophysiological data. These data are key to understanding the dynamic changes in the behavior and physiological responses of ADHD patients, and the TCN, with its deep and dilated convolutional structure, effectively captures these complex temporal dependencies. The results of the TCN analysis provide a rich feature input for the Random Forest and, when combined with the output from the ACT-R model, offer us a comprehensive perspective for understanding the cognitive and behavioral patterns of ADHD patients under physical activity interventions.
The application of TCN has demonstrated its significance in analyzing the impact of physical activity on patients with ADHD. It not only provides a deep understanding of the immediate effects of physical interventions on the behavior of ADHD patients but also plays a crucial role in capturing the long-term effects of such interventions. Through in-depth analysis by TCN, we can uncover how physical interventions affect the daily behavior and cognitive patterns of ADHD patients, which is essential for accurately assessing the effectiveness of physical activity as a therapeutic approach. The analysis by TCN reveals both the immediate and long-term effects of physical activity on patients' cognition and behavior, and provides crucial data support for designing more personalized and effective treatment plans. This profound analysis and understanding of time series data offer a new perspective and approach for exploring the role of physical activity in treating ADHD, providing significant scientific evidence for enhancing treatment effectiveness and improving patients' quality of life. It also offers valuable data and insights for future research.
3.4 ACT-RThe ACT-R (Adaptive Control of Thought—Rational) model is a cognitive architecture specifically designed to simulate human cognitive processes (Fisher et al., 2020). This model is predicated on the assumption that human cognition is comprised of multiple interacting subsystems, each responsible for processing different types of information, such as visual and motor information. The core of the ACT-R model lies in decomposing the cognitive process into a series of modular components, each dedicated to processing specific types of information. This includes modules for storing long-term memory (Zhang et al., 2021b), buffers for processing short-term memory, and a decision center that guides behavior based on information from various modules. Additionally, ACT-R incorporates several distinct modules, each simulating specific human cognitive functions, such as thinking and decision-making processes, thereby facilitating the study and understanding of cognitive psychology phenomena.
The ACT-R system is a hybrid cognitive architecture consisting of both symbolic and sub-symbolic systems. As can be seen in Figure 5, the symbolic system is composed of several modules, with a procedural module at its core. This procedural module connects the various modules into a cohesive whole, functioning similarly to a model driven by a production system, where procedural rules in the module manipulate the buffers of different modules. The sub-symbolic system, although not explicitly represented in visualizations, controls the internal operations of modules in the symbolic system through mathematical methods. This structure allows the ACT-R model to simulate human cognitive processes with greater precision and comprehensiveness.
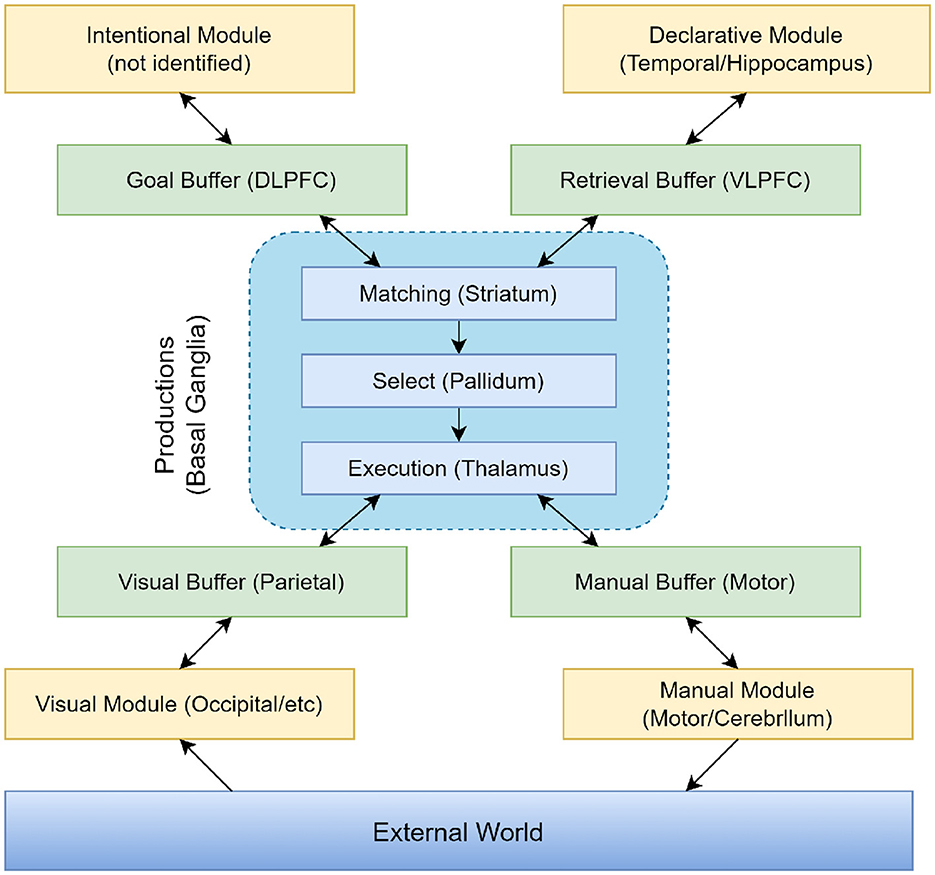
Figure 5. Information organization in ACT-R 5.0.
In the ACT-R model, different modules assume various functions and tasks. The Intentional Module (also known as the Goal Module) serves as the executive control center, responsible for planning and controlling behavior. It determines the goals of the current task and coordinates the activities of other modules to achieve these goals. The Declarative Module acts as a repository for storing facts, rules, and conceptual knowledge, supporting the model in accessing and retrieving information from long-term memory during decision-making and problem-solving processes. The Visual Module processes sensory input, simulating the human visual processing system. This module is responsible for perceiving and understanding visual information, such as objects, scenes, and symbols. The Manual Module enables the model to perform manual actions, such as moving and grasping objects. It controls the model's movements and interactions, simulating the execution of physical actions. The Production Module (also referred to as the Procedural System) is one of the core components of ACT-R, representing knowledge and decision-making. It includes production rules that describe condition-action pairs. When specific conditions are met, these production rules are triggered, executing corresponding actions and simulating the decision-making process in cognitive tasks.
In our proposed integrated model, the ACT-R model plays a crucial role in providing a deep understanding of the cognitive processes in ADHD patients. This encompasses how they process information, make decisions, and respond behaviorally to various stimuli, such as physical interventions. By leveraging the feature vectors derived from the RF-TCN model, the ACT-R model utilizes its comprehensive cognitive architecture to simulate these cognitive processes accurately. This architecture is adept at mirroring various cognitive functions, including memory processes, attention, and decision-making, thereby laying the groundwork for understanding the complex behavioral patterns that ADHD patients may exhibit in response to physical intervention.
The integration of the ACT-R model with the TCN's capability in processing time-series data, like motion monitoring data, alongside the advantages of Random Forest in analyzing and integrating multi-dimensional data, culminates in a multi-faceted and multi-layered analytical framework. Through this simulation, the ACT-R model not only learns to associate specific patterns of physical activity with cognitive outcomes in ADHD patients but is also designed to simulate and understand the cognitive decision-making processes. It achieves this by mapping the input features—processed information from the RF-TCN model—to cognitive states that represent ADHD characteristics. This dynamic process enables the ACT-R model to learn the underlying cognitive patterns associated with ADHD, offering valuable insights into how various factors might influence cognitive processes in patients.
Combined, these elements highlight the integrative approach of our research, demonstrating how the ACT-R model's simulation capabilities, when enriched with data from the RF-TCN model, form a comprehensive analytical tool. This tool not only deciphers the intricate cognitive underpinnings of ADHD but also facilitates a nuanced understanding of how physical interventions can be optimized for therapeutic efficacy, based on individual cognitive responses.
The ACT-R model is vital in our experiments because it enables us to comprehend the impact of physical activities on ADHD patients from a cognitive perspective. By simulating the cognitive processes of ADHD patients, we gain a deeper understanding of their responses to physical interventions, including changes at cognitive, emotional, and behavioral levels. This in-depth understanding is crucial for assessing the effectiveness of physical interventions, especially when designing targeted treatment plans and intervention measures. Overall, the ACT-R model provides a unique perspective in our research, complementing the capabilities of TCN and Random Forest in data processing and analysis, and offers a key cognitive dimension to understand the overall impact of physical activities on ADHD patients.
ACT-R is not only a tool for simulating human cognitive processes but also a bridge linking the inner cognitive processes and external behavioral manifestations of ADHD patients. By precisely simulating the cognitive activities of ADHD patients under physical intervention, ACT-R provides insights into how they process information, make decisions, and how their attention and memory are affected by physical activities. The details of these cognitive processes are critical in evaluating the specific effects of physical interventions in areas such as improving attention, reducing impulsive behaviors, and enhancing emotional regulation. For instance, by simulating specific cognitive tasks, we can assess how physical activities influence the working memory, attention allocation, and task-switching abilities of ADHD patients. These details offer direct evidence of how physical interventions alter the brain's information processing methods in ADHD patients, aiding in a better understanding of the potential mechanisms by which physical activities improve ADHD symptoms. Through this deep cognitive-level analysis, the ACT-R model significantly enhances our ability to design more effective treatment and intervention strategies, providing robust scientific support for improving the quality of life of ADHD patients.
4 Experiment 4.1 DatasetsTo comprehensively explore the complexities of how physical activity impacts patients with ADHD, this study employs multiple datasets, aiming to provide an integrated analysis of the effects of exercise on individuals with ADHD from various perspectives. We have selected four key datasets, each with its unique value and applicability, aiding us in an in-depth understanding of the influence of physical activity on cognitive, physiological, and social behaviors in ADHD patients. These datasets include: the ADHD Dataset, the ADHD TIDAL Dataset, the ADHD-200 Dataset, and the EEG Dataset. The combined use of these datasets not only strengthens the foundation of our research but also offers robust support for subsequent data analysis and model development.
Attention-Deficit Hyperactivity Disorder Distribution (ADHD) Dataset (Cao et al., 2023): The ADHD Dataset offers a comprehensive exploration into ADHD, encompassing an extensive cohort of over 7,400 subjects. This dataset extends beyond simple ADHD symptomatology to include biosamples critical for genetic and biological research, shedding light on ADHD's hereditary aspects through family studies and enhancing our understanding of its genetic underpinnings. It incorporates detailed clinical tools, such as the Diagnostic Interview Schedule for Children, facilitating a thorough assessment of participants' conditions. With its access to genetic repositories, the dataset provides invaluable demographic, diagnostic, and genealogical data, serving as a pivotal resource for studies targeting the clinical and genetic aspects of ADHD. This aids in analyzing genetics and biological markers associated with the disorder. The dataset's vast size not only enables an in-depth analysis of ADHD's hereditary factors but also aids in identifying potential biomarkers, thereby enriching our comprehension of this complex condition.
To further prepare this rich dataset for our study, we undertook standardization processes to normalize scores across various scales and employed median imputation for missing values, drawing from similar patient profiles. This preprocessing step was crucial for ensuring data consistency and reliability. We extracted key features, such as symptom severity scores, diagnostic criteria, and patient demographics, enabling us to effectively correlate behavioral patterns with the impacts of physical activity. These steps ensured that the ADHD Dataset was meticulously prepared for our analysis, allowing for a nuanced examination of the interactions between genetic predispositions, clinical symptoms, and the benefits of physical interventions in ADHD patients.
The ADHD Teen Integrative Data Analysis Longitudinal (ADHD TIDAL) Dataset (Sibley and Coxe, 2020): Integrating data from four pivotal longitudinal studies conducted between 2010 and 2019, this dataset offers an expansive insight into the long-term effects of psychosocial treatments on 1,500 adolescent subjects diagnosed with ADHD. It provides a multifaceted view of treatment outcomes, encapsulating detailed information on academic performance, diagnostic criteria, and symptom ratings as reported by both parents and teachers. This dataset is instrumental in shedding light on various treatment modalities, including medication and special education interventions, thus delivering invaluable insights into ADHD's impact on educational outcomes and adolescents' daily lives. Such comprehensive information makes this dataset an essential tool for researchers aiming to assess the effectiveness and sustainability of ADHD treatments, offering a deep understanding of how different interventions influence the long-term wellbeing and academic success of affected adolescents.
To enhance the dataset's utility for our analysis, we undertook a meticulous preprocessing regimen. This involved aligning time-series data from multiple assessment points to ensure consistency across the longitudinal study and encoding categorical variables into a format conducive to machine learning analysis. Our preprocessing efforts concentrated on extracting pivotal features such as variations in symptom severity over time, adherence levels to prescribed treatments, and key indicators of academic performance.
ADHD-200 Dataset (Bellec et al., 2017): The ADHD-200 Dataset as a fundamental resource in neuroimaging research, shedding light on the profound impact of ADHD on brain function. Comprising 776 resting-state fMRI and anatomical datasets from eight independent imaging sites, it includes data from 285 children and adolescents with ADHD (ages 7–21) and 491 typically developing individuals. This amalgamation not only supports a wide-ranging comparative analysis but also deepens our investigation into the neurological underpinnings of ADHD and its developmental trajectory. The dataset is rich with detailed diagnostic statuses, ADHD symptom measures, and extensive demographic information, including age, sex, IQ, and medication history, making it an invaluable tool for probing into the neural basis and developmental aspects of ADHD. Furthermore, its unrestricted public access greatly enhances its utility, fostering diverse research endeavors aimed at decoding ADHD's neural correlates.
To cater to the unique requirements of MRI image analysis within this dataset, we undertook specific preprocessing steps, including skull stripping, spatial normalization, and smoothing, to refine the images for subsequent investigation. Our focal points during the analysis were on brain volume measurements in ADHD-impacted regions, connectivity patterns among these areas, and textural analysis of neural tissue for pinpointing structural differences. This meticulous approach allows for an in-depth exploration of how ADHD affects brain structure and function, laying a solid foundation for advancements in understanding, diagnosing, and treating ADHD.
EEG Data for ADHD/Control Children Dataset (Motie Nasrabadi et al., 2020): The EEG Dataset is distinguished by its focus on neurophysiological data through EEG recordings from a cohort of 61 children diagnosed with ADHD and 60 healthy controls, aged between 7 and 12 years. This dataset is enriched by comprehensive psychiatric evaluations and detailed medication histories, presenting an extensive neurological profile of ADHD in children. Such a compilation of data is invaluable for pinpointing potential EEG biomarkers and dissecting the complex neural mechanisms underlying ADHD. These insights are crucial for developing more refined diagnostic and therapeutic strategies, particularly through AI-based research methodologies. By integrating clinical assessments with medication data, the EEG Dataset lays a robust groundwork for exploring the neurological aspects of ADHD in young patients, establishing it as a key resource in the field.
In preparing this dataset for analysis, we undertook meticulous preprocessing steps that included filtering to eliminate electrical noise and artifacts, segmenting the recordings into epochs guided by event markers, and applying baseline correction. We focused on extracting neurophysiological features such as spectral power in critical frequency bands, coherence between electrode pairs, and characteristics of event-related potentials. These selected features are designed to elucidate the neurophysiological foundations of ADHD and assess the impact of physical activities on brain function, thereby offering profound insights into the disorder and potential avenues for intervention.
These datasets offer a comprehensive perspective on ADHD, covering genetic, clinical, educational, neurological, and treatment-related aspects. For our research on the effects of exercise on ADHD patients using AI methods, this multifaceted data is crucial. It allows for a holistic analysis, integrating physical activity's impact on various dimensions of ADHD. By leveraging these diverse datasets, we could more accurately assess how exercise influences genetic predispositions, clinical symptoms, educational performance, and neurological functioning in ADHD patients. This approach is invaluable for developing a nuanced understanding of exercise's role in managing ADHD and its broader implications for patient care and family dynamics.
4.2 Experimental details 4.2.1 Experimental environmentHardware Environment: The hardware environment used in the experiments consists of a high-performance computing server equipped with an AMD Ryzen Threadripper 3990X @ 3.70 GHz CPU and 1TB RAM, along with 6 Nvidia GeForce RTX 3090 24 GB GPUs. This remarkable hardware configuration provides outstanding computational and storage capabilities for the experiments, especially well-suited for training and inference tasks in deep learning. It effectively accelerates the model training process, ensuring efficient experimentation and rapid convergence.
Software Environment: In our research, we employed Python as the core programming language and PyTorch for deep learning tasks. Python's versatility facilitated a dynamic development process. Meanwhile, PyTorch played a crucial role as our primary deep learning platform, providing robust resources for building and training models. With PyTorch's advanced computational abilities and its auto-differentiation feature, we efficiently developed, fine-tuned, and trained our models, leading to enhanced outcomes in our experimental work.
4.2.2 Data preprocessingThe data preprocessing stage is crucial for preparing the dataset for effective model training and evaluation. This stage involves several key steps to ensure the data's suitability and reliability:
1. Data cleaning: This step involves identifying and handling missing or inconsistent data entries. We will scan the dataset for any missing values and decide on an appropriate strategy (like imputation or removal) based on the extent and nature of these missing values. Additionally, we will handle outliers by either correcting them if they are due to errors or removing them if they are true anomalies that could skew our analysis.
2. Data standardization: To ensure that our models are not biased toward variables with higher magnitude, we will standardize our data. This involves scaling the features so they have a mean of 0 and a standard deviation of 1. Standardization is crucial, especially for models that are sensitive to the scale of input data, such as neural networks.
3. Feature selection: We will identify and select the most relevant features for our models. This will be done through techniques such as correlation analysis and importance ranking, ensuring that only variables that significantly contribute to our model's predictive power are used. This step helps in enhancing model performance and reducing computational complexity.
4. Data splitting: The dataset will be split into training, validation, and testing sets. A typical split ratio we will employ is 70% for training, 15% for validation, and 15% for testing. The training set is used to train the model, the validation set to tune model parameters, and the testing set to evaluate the model's performance. This separation is crucial to assess the model's ability to generalize to new, unseen data.
4.2.3 Model trainingThe model training phase is crucial, and it involves carefully setting network parameters, designing the model architecture, and outlining the training strategy.
1. Network parameter settings: We will calibrate the network's hyperparameters to optimize performance. The learning rate, a key parameter in model training, will be set to 0.005, providing a balance between rapid convergence and stability. Our model will employ a batch size of 32, allowing for efficient training without overloading the memory. We'll use an A
留言 (0)