
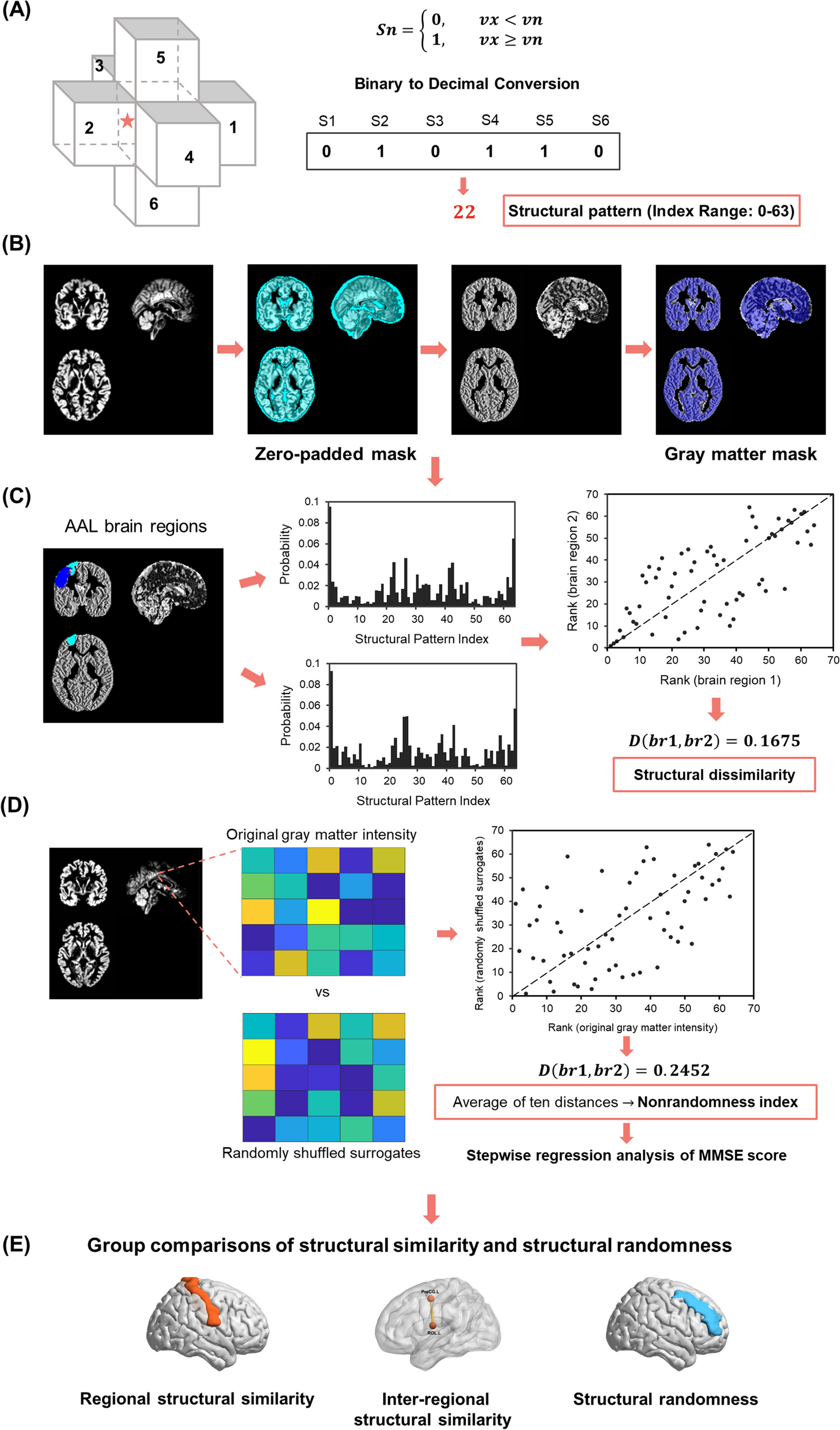
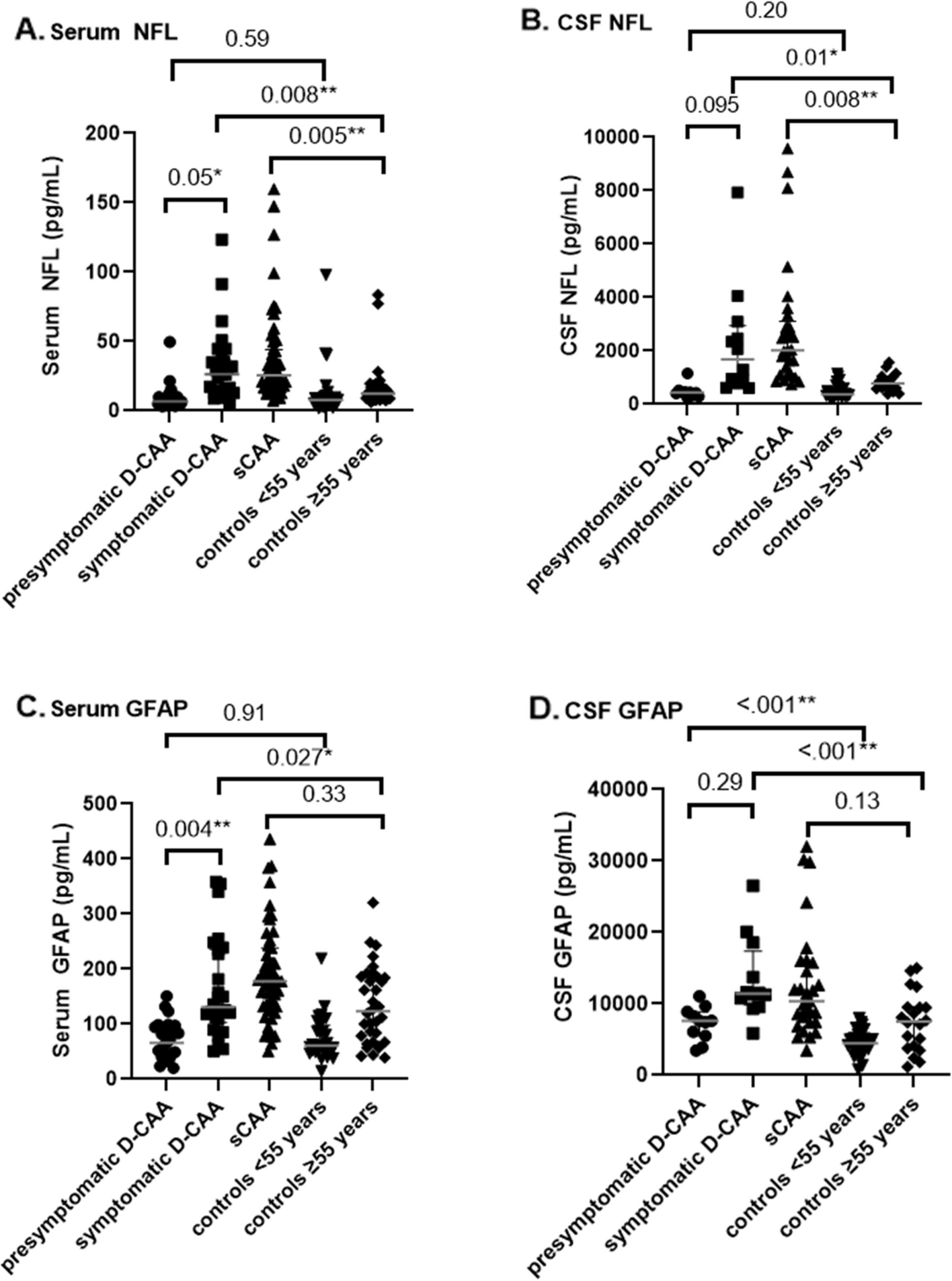
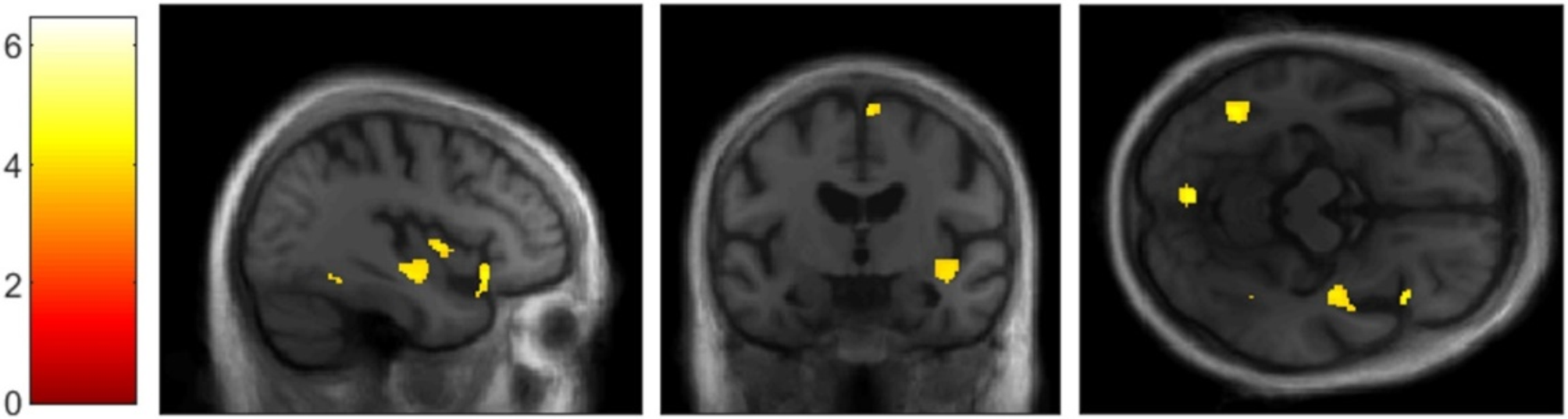
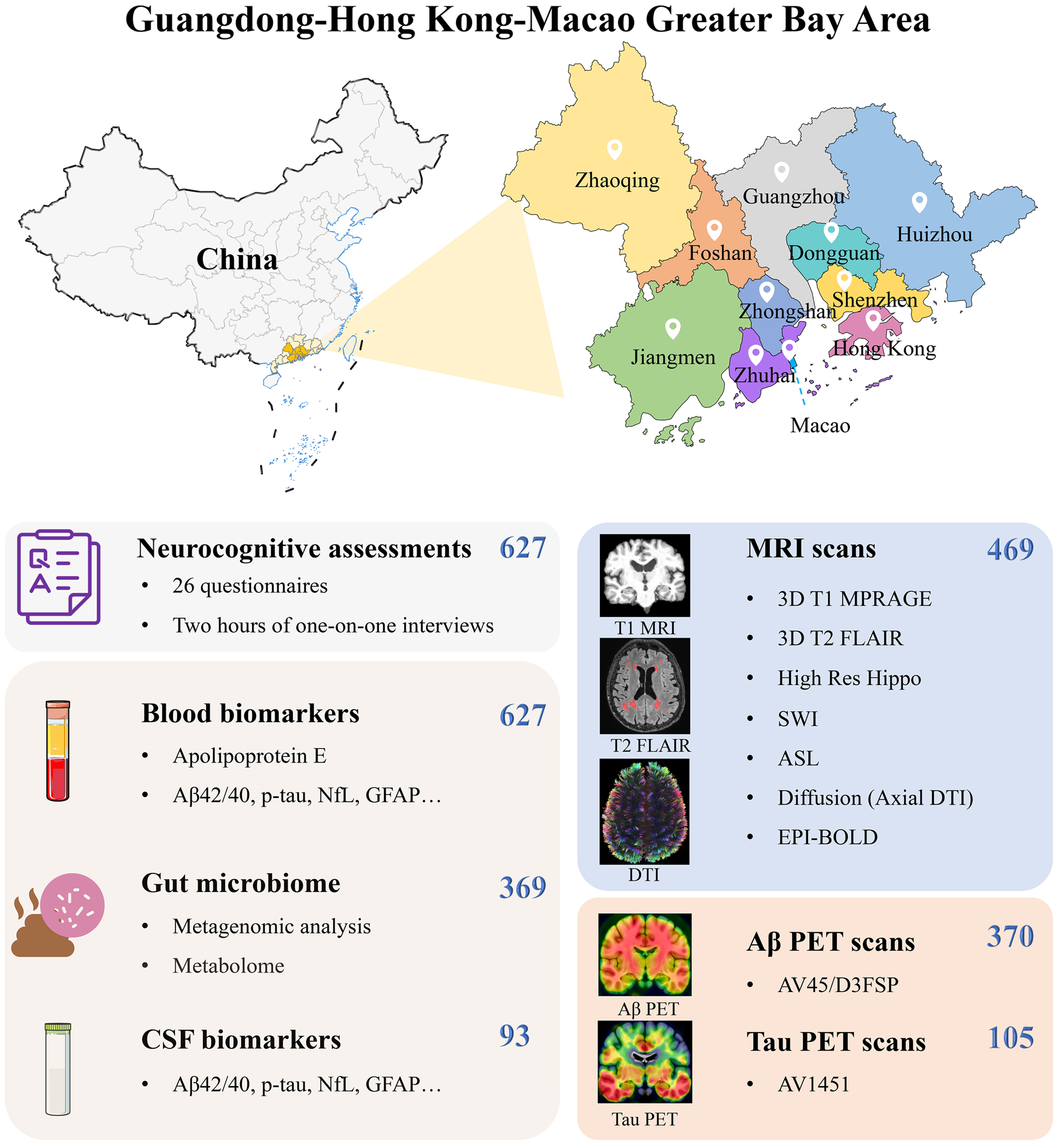
記住我
The study utilized MarketScan Multi-State Medicaid data in the OHDSI Observational Medical Outcomes Partnership (OMOP) model, which was provided by International Business Machines (IBM) Corporation. The IBM MarketScan databases are constructed by collecting data from employers, health plans and state Medicaid agencies. The data encompass service-level claims for inpatient and outpatient services as well as outpatient prescription drugs. The database is designed to provide long-term longitudinal observational data and includes 32.87 million patients.
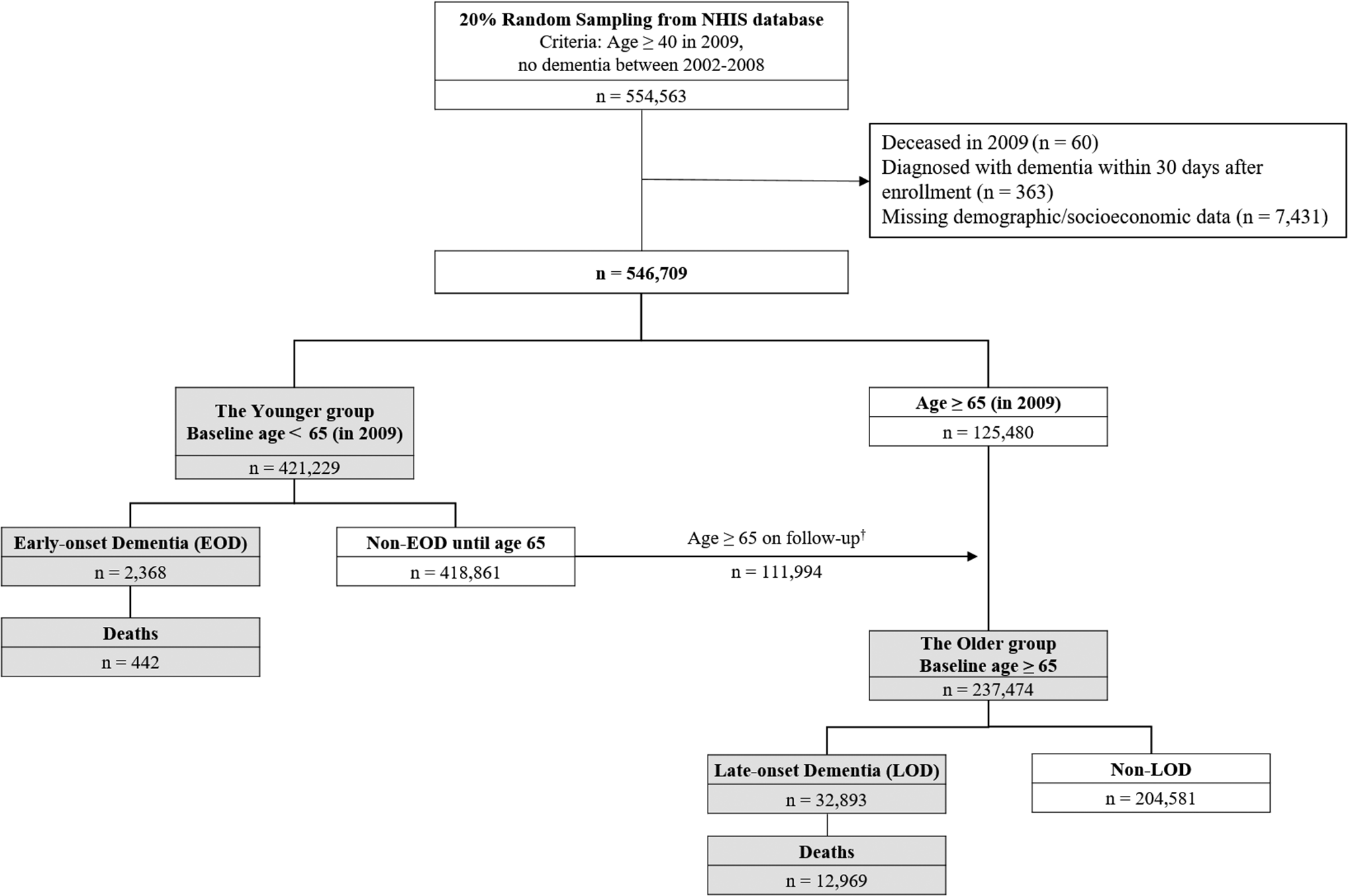
A Cohort study was designed to investigate patients diagnosed with Mild Cognitive Impairment (MCI) in 2006-2016. The aim was to predict their conversion to AD within 3 years after the MCI diagnosis using their administrative claim history during the one-year observation window prior to the MCI diagnosis (Fig. 1). AD and MCI were defined using International Classification of Diseases, Ninth/Tenth Revision (ICD9/ICD10) diagnosis codes (Table 1). Since AD is an age-related disease, the focus was on patients 50 years of age or older at the time of their MCI diagnosis. Patients with medical history less than a year prior to the MCI diagnosis were excluded, as were patients with less than 3 years of follow-up after the MCI diagnosis. This leads to 6,847 patients, among whom 312 converted to AD within 3 years. Stratified sampling based on whether being converted to AD within 3 years was used to select 70% of the patients as the training cohort, while the remaining 30% of the patients formed the validation cohort. All variable selection and machine learning model training were done using the training cohort alone, and the validation cohort was only used for evaluation.
Fig. 1 Table 1 ICD9/ICD10 diagnosis codes for MCI and AD
Table 1 ICD9/ICD10 diagnosis codes for MCI and ADMost covariates were binary variables for the ICD codes for the administrative claims. Duplicated features and features with no incidence were removed, resulting in 16,862 remaining rare features. Additionally, 11 baseline variables were included in the study: CHADS2, CHADS2VASc, gender, race (White and Black or African American), ethnicity (Hispanic or Latino), and the linear, quadratic, and cubic terms of age at MCI diagnosis. CHADS2 and CHADS2VASc scores were two scores for atrial fibrillation stroke risk, and we scaled them to a range of 0 to 1. Patient age was normalized by centering it at 65 years old and then dividing it by 20.
Tree-guided lasso for Rare feature selection and aggregationConsider a logistic regression model where Yi~Bernoulli(pi) and logit(pi) = Xiβ for i=1, … ,n. Here Yi is the indicator of whether the patient progressed to AD, Xi is a length p feature vector from the health claim dataset for subject i, β is the length p regression coefficient vector. Let X be the n by p feature matrix that includes all n subjects in the data, where the ith row corresponds to Xi. This feature matrix, derived from Administrative Claim data, primarily consists of an incidence matrix of ICD10 codes, with most entries being 0. In statistical literature, such features are sometimes referred to as “rare features” [10]. Rare features usually lack sufficient variation among samples to effectively measure their association with the outcome. Consequently, these features are intentionally discarded during data preprocessing or implicitly during model selection based on how the algorithm prioritizes the features. The scientific community has recognized this issue, and one approach to mitigate it involves pre-clustering the features and aggregating the rare features within the same group based on previous studies [11]. However, even after aggregation, these features may still be too rare for subsequent variable selection, necessitating further ad hoc feature aggregation. This is partially due to the separation of the feature aggregation step from variable selection, which fails to adapt to the importance of these features. Combining these two steps could potentially enhance variable selection performance and enable identified clusters to better adapt to their importance in the regression model.
In practice, rare features are often related through a tree structure. For instance, the phylogenetic tree among microbiome species can be used to link the microbiome features. In general, this tree can be learned through hierarchical clustering of the data. Based on this tree, the effect of each leaf (elements of β) can be decomposed as the effects of their ancestors plus a leaf-specific effect. Let Γ be a tree with leaves1, … ,p, and the effect of node u ∈ Γ is γu. For j=1, … ,p, βj can be expressed as \(_j=\sum_}_u\) where ancestor(j) denotes the indices of all the ancestor internal nodes of the terminal node j based on the tree. Let q be the number of nodes in the tree Γ, and A be a p-by-q binary matrix such that Aju = 1 if u ∈ ancestor(j) ∪ and 0 otherwise. There is β = Aγ.
We propose transforming the feature matrix to \(\overset= XA\). Consequently, the systematic component of the logistic regression becomes \(logit\left(_i\right)=}_i\gamma\). We adopt the weighted lasso penalty \(\sum__u^\mid _u\mid\) where qu is the number of leaves that are the children of node u. Let \(\hat\) be the estimate, and the estimate of β, the regression coefficients for the effects of the original features, is \(\hat=A\hat\). As this estimate is guided by the tree, we refer to this method as “tree-guided lasso” (TGL). There is only one sparsity penalty parameter, which is selected by 5-fold cross-validation. The output of this model includes the important groups of features and the regression coefficients.
Co-occurrence tree for ICD10 codesTo define the tree of features using the data, we first establish the distance matrix D among the features based on the co-occurrence of rare features. For two features j and k, Let nj and nk denote their frequencies in the sample, respectively. Furthermore, let njk be the number of times they co-occur. We define their distance \(_=1-\frac}_k}}\). Hierarchical clustering with average agglomeration is then applied to this distance matrix to build the tree, which guides the tree-guided lasso algorithm mentioned earlier. To avoid large clusters, we remove internal nodes with a large number of descendants, retaining only the treelets with no more than 50 leaves.
Tight-clustering for extracting important groups of featuresHigh dimensional variable selection and clustering are both notoriously difficult and may be sensitive to the randomness of the data. The rareness of the feature matrix further exacerbates these problems. Averaging the results from repetitive subsamples has been applied to improve the finite sample performance of variable selection [12] and extracting meaningful tight clusters from the data [13]. We employ similar techniques to extract robust clusters of important rare features.
As depicted in Fig. 2, for each replication, we randomly subset 80% of the training data, discard the extremely rare features (frequency <n0.2,e.g., at least 7 incidences out of 10,000 samples), build the tree, and employ the tree-guided lasso. We create a co-selection matrix among the features to summarize the results across B=100 replications. Each element in the ith row and jth column of this matrix represents the number of replicates in which the ith and jth features are both selected and grouped together (with a common ancestor node with nonzero effect). We further filter the features, excluding those with a selection proportion less than πimp . Additionally, elements in the co-selection matrix below πco are set to zero. Both πimp and πco are user-defined tuning parameters for interpretation purpose. We use 0.5 for both in our analysis. The remaining features are clustered into disjoint groups based on this co-selection map. The output of this TGL workflow in Fig. 2 includes robust groups of important features for predicting the conversion from MCI to AD.
Fig. 2
The tree-guided lasso (TGL) workflow: it aggregates the tree-guided lasso outputs from repetitive sub-samples and outputs important feature groups
Predictive modeling using the extracted featuresWe train various predictive models on the training cohort data using the extracted features from the proposed feature selection workflow described in Section 2.4. The selected features within the same group are aggregated using three strategies. The first strategy involves using them as individual features. The second strategy sums up the features in the same group. The third approach leverages the binary nature of the original features, which represent the incidence of ICD10 codes, and defines the aggregated feature for the group as 1 if any of the original features in the group is 1, and 0 otherwise. The predictive models used include logistic regression (LR), generalized random forest (GRF) [14], and artificial neural network (ANN) [15]. We train these models on the training data using [1] all features, [2] Lasso selected features, [3] GRF selected features, [4] TGL selected features, [5] group sums of the TGL selected features, and [6] group unions of the TGL selected features. GRF ranks the variables by importance, and a cutoff is chosen so that it selects the same number of features as TGL. When training logistic regression on all features, we apply the lasso penalty with the tuning parameter lambda selected via 5-fold cross-validation. For GRF, we train it on the training data with the default settings, except that we average 10,000 trees and assign re-sampling weights for the cases proportional to the inverse of the events' prevalence. The ANN architecture consists of two hidden dense layers with 64 nodes and ReLu activation function. The output layer has one node and Sigmoid activation function. We determine the number of epochs via 5-fold cross-validation. All feature selection procedures and the predictive models are trained using the training cohort, and their performance is evaluated on the validation cohort.
Model evaluationThe proportion of conversion to AD from MCI is lower than 6%, making it an imbalanced classification problem. The Precision-Recall Curve (PRC) is a better measure of performance than the ROC curve in such cases [16]. We can also calculate the Area Under the PRC (AUPRC). While the Area Under the ROC (AUROC) for a useless random classifier is 0.5, its corresponding AUPRC is equal to the proportion of true cases in the data (AD conversion rate in our context). Extremely unbalanced classification problems like ours often yield small AUPRC values, such as 0.1.
For the cross-validation step in tree-guided lasso, AUPRC is maximized. For the evaluation of the predicted models based on all or the selected features, the models are trained using the training cohort, and both AUPRC and AUROC are calculated on the validation cohort. R package pROC is used to calculate AUROC and its confidence interval is based on the “delong” method. AUPRC is calculated using R package PRROC, and the confidence interval is based on the Logit interval proposed in Boyd et al (2013) [17].
Relative risk for the important feature groupsThe relative risks and the associated 95% confidence intervals for the important feature groups identified by TGL are calculated for the validation cohort. The features in each group are aggregated as one feature using the group sum as described in Section 2.5. The exposure and the non-exposure groups are defined based on whether the aggregated feature exceeds its median value. Due to the strong association between age and the other variables, the relative risks for features other than age are stratified by age group (50-59,60-69,70-79, and above 80). For each aggregated feature, a point estimate and a confidence interval are calculated by inverting a score test statistics for its average stratified relative risk (equation 6 of Tang 2020 [18]).
留言 (0)