
記住我






Simulation-based education is an important part of developing and maintaining healthcare provider competence within complex and dynamic practice environments. Optimal instructional design features of simulation-based training, in particular identifying the most effective and efficient methods of providing simulation training to benefit patients and healthcare professionals, remains an important area of research.1 Just-in-time (JIT) simulation training harnesses a strategy from automobile manufacturing of making products and processes available only at the time they are required2 by providing simulation training in temporal or spatial proximity to performance.3 Just-in-time training is a promising instructional design strategies for improving the impact of simulation training and is supported by cognitivist (improving retrieval, decreasing cognitive load) and situated learning theories (workplace context and experiential participation).4 Although the idea of “warming up” or “rehearsing” before a performance is frequently used in sports and music,5,6 it has not yet been widely adopted in health care.
Currently, most simulation-based training is scheduled based on educator and/or learner time constraints, irrespective of the timing of the actual procedure.7 However, healthcare providers often encounter high risk or rarely performed tasks with little notice and little tolerance for error. Given the potential decay in performance in as little as 6 months after simulation training,8,9 brief, focused interventions that can immediately address knowledge or skill deficits in-the-moment, may offer a more appropriate instructional design strategy to address health care safety, quality, and outcomes.10
Despite a growing volume of research on JIT simulation training,11,12 its effectiveness remains uncertain, in part because of the difficulty in interpreting both the significance and generalizability of research results one study at a time. Several systematic reviews7,13–16 have attempted to provide such syntheses, but each had limitations including inclusion of low-quality observational studies,16 narrow inclusion criteria,7 or focus on only one particular skill or outcome.14 The objective of this systematic review was to determine whether JIT simulation training as compared with no JIT simulation training improves learning and performance outcomes.
METHODSReporting for this systematic review was in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-analyses guidelines.17 The review was commissioned by the Society for Simulation in Healthcare (SSH) and was not registered. A protocol was prepared a priori and submitted to SSH.
Search Strategy and Selection CriteriaA librarian with experience in systematic literature searching (H.G.) developed the search strategy in consultation with the research team (see Table, Supplemental Digital Content 1, Database search strategy Ovid MEDLINE, https://links.lww.com/SIH/A998) (see Table, Supplemental Digital Content 2, Database search strategy Embase, https://links.lww.com/SIH/A999) (see Table, Supplemental Digital Content 3, Database search strategy CINAHL PLUS with Fulltext (Ebsco), https://links.lww.com/SIH/A1000) (see Table, Supplemental Digital Content 4, Database search strategy CAB Abstracts (Ebsco), https://links.lww.com/SIH/B2) (see Table, Supplemental Digital Content 5, Database search strategy ERIC (Ebsco), https://links.lww.com/SIH/B3). Database searches were conducted for controlled vocabulary and keywords related to the following concepts: health professions education, simulation and other training (including resuscitation), and spaced/JIT. The following databases were searched from inception to April 2023: MEDLINE (Ovid), Embase (Ovid), CINAHL (Ebsco), CAB Abstracts (Ebsco), and ERIC (Ebsco). Complete search strategies can be found in the supplementary files.
Reference lists of relevant articles were checked for additional studies. Covidence systematic review software, Veritas Health innovation, Melbourne, Australia (2022), was used to store records and facilitate screening.
Study SelectionStudies were eligible for inclusion if they met the following predefined criteria:
1) Population: Healthcare professionals (trainees or practitioners, a healthcare professional includes any individual who requires a degree qualification to practice in their respective field. This may include but is not limited to medicine, surgery, nursing, veterinary medicine, dentistry, physical therapy, occupational therapy, dietetics, engaged in simulation) 2) Intervention: Training that is conducted in temporal or spatial proximity to performance (“Just-in-time,” “just-in-place,” “refreshers,” and/or “warm-up”) 3) Comparator: Standard training 4) Outcomes: Outcomes were categorized using the translational outcomes framework developed by McGaghie et al.18 Outcomes measured in a classroom or medical simulation laboratory (T1), improved and safer patient care practices (T2), better patient outcomes (T3), and collateral educational effects such as cost savings, skill retention, and systemic educational and patient care improvement (T4). Within each of the translational outcome categories, information was abstracted separately for knowledge, satisfaction, and skills (T1–T4), with skill measures further classified as time, process, and product. 5) Study Designs: Randomized controlled trials (RCTs) and comparative observational studies. Case reports, technical reports, editorials, and commentaries were excluded. 6) Timeframe and language: All years and all languages were included.For the purposes of this study, we used the following definitions:
Simulation based on Gaba's19 concept of simulation: any experiential activity designed to replicate real-world clinical scenarios. This may include, but is not limited to, high-fidelity mannequins, task trainers, standardized patients, screen-based (ie, virtual), mental rehearsal, and situation enactments (ie, table tops, role playing, disaster scenarios). Just-in-time: any training conducted in temporal or spatial proximity to performance3
The titles and abstracts of all potentially eligible studies were independently screened for inclusion by 2 reviewers. Included studies were independently screened in more detail for eligibility based on set inclusion and exclusion criteria. Any disagreements between the reviewers at either stage were resolved by discussion.
Data Collection and Quality AssessmentA standardized data extraction form was developed and iteratively tested and revised. Two independent reviewers (C.P. and A.P.) recorded information on study design, participant characteristics, sample size, description of JIT learning, and outcome measures. Any disagreement surrounding the selection of a manuscript or data extraction was resolved either by consensus or arbitration by a third reviewer (A.H.). The risk of bias of individual studies was assessed by 2 reviewers independently (C.P. and A.P.) using the Cochrane Collaboration Risk of Bias 2 (RoB2) tool for RCTs20 and the Newcastle-Ottawa scale for comparative observational studies.21 Disagreements were resolved by discussion between the 2 reviewers. Template data collection forms, data extracted from included studies, data used for all analyses, analytic code, and any other materials used in the review are available upon request.
The certainty of evidence was assessed using the Grading of Recommendations Assessment, Development and Evaluation (GRADE) system in GRADEpro Guideline Development Tool (Evidence Prime, Inc, McMaster University).22,23
Data Analysis and SynthesisWe used both quantitative and narrative syntheses of evidence. Considering the clinical and methodological diversity of included studies, we used a random effects model for meta-analysis where indicated. Data were entered into Review Manager (RevMan5, Version 5.4; The Cochrane Collaboration, Oxford, United Kingdom). For dichotomous outcomes, the odds ratio (OR), 95% confidence intervals (CIs), and statistical heterogeneity were calculated. For continuous outcomes, each mean was converted to a standardized mean difference (the Cohen d effect size).24–26 When this information was unavailable, the effect size was estimated using statistical test results (eg, P values).27 For crossover studies, we used means or exact statistical test results adjusted for repeated measures; if these were not available, we used means pooled across each intervention.28 If articles contained insufficient information to calculate an effect size, we requested this information from authors via e-mail.
Heterogeneity between studies was statistically assessed using the χ2 test. The extent of heterogeneity among studies was expressed with I2,29 with I2 values >50% indicating large inconsistency or heterogeneity. Statistical significance was defined by a 2-sided α value of 0.05. Interpretations of clinical significance emphasized CIs in relation to Cohen ES classifications (>0.8, large; 0.5–0.8, moderate; 0.2–0.5, small; <0.2, negligible).30
Studies that were not conceptually aligned or which seemed to have context-specific drivers were summarized in a narrative synthesis.
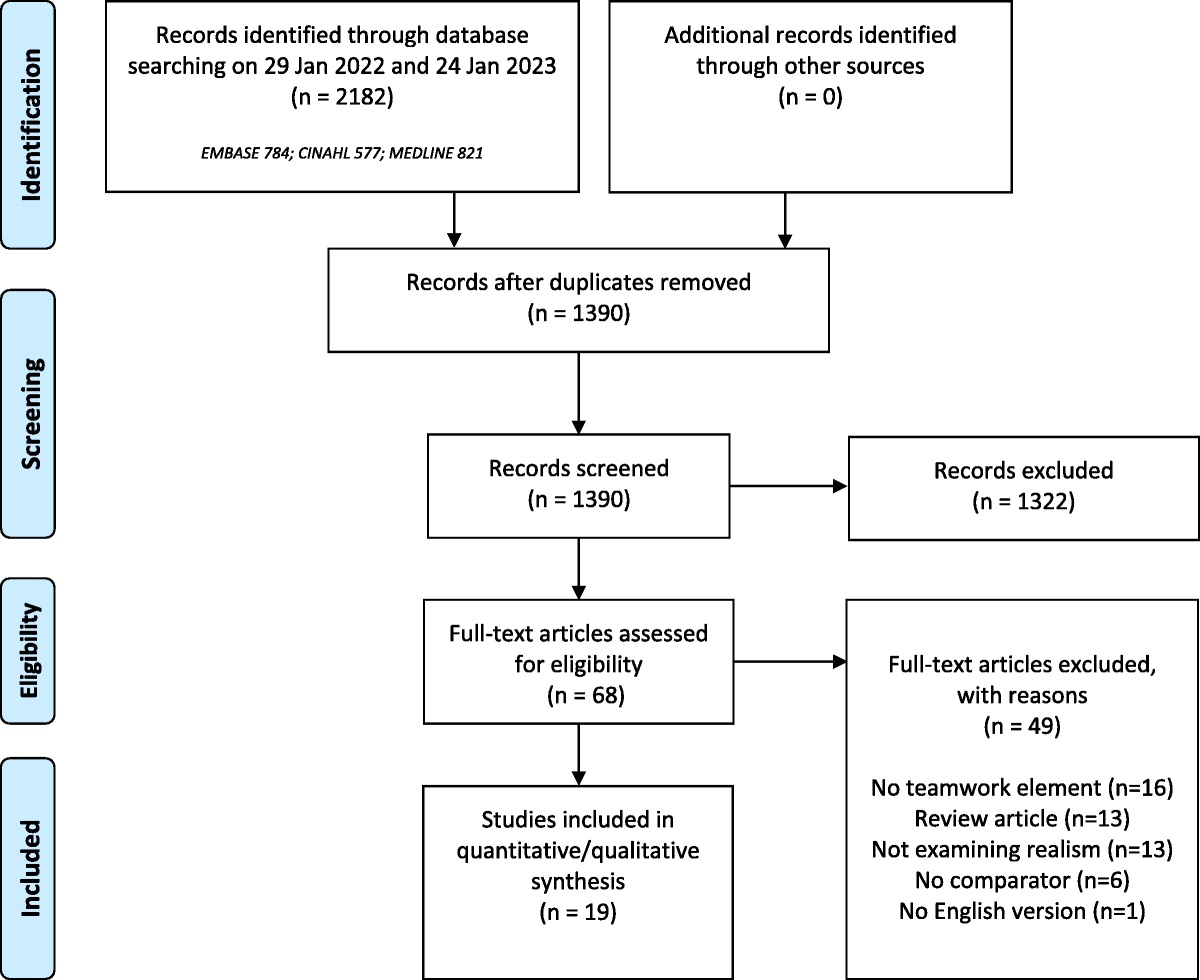
RESULTSAfter removal of duplicates, the literature search yielded 2952 unique references. After screening, 28 studies (14 randomized control trials,31–43 3 randomized crossover trials,44–46 8 before-after trials,11,47–52 and 3 comparative studies53–55) fulfilled eligibility criteria and were included in the synthesis (Fig. 1). Studies were conducted in North America (n = 18),11,31,32,36,43–51,53–57 South America (n = 1),37 Europe (n = 5),32,38,39,42,44 Australia (n = 3),33,40,58 and Asia (n = 1).34 (see Table, Supplemental Digital Content 6, which includes the characteristics of included studies, https://links.lww.com/SIH/B4). Some studies were conducted in multiple sites so the numbers do not add up to 26. Just-in-time training was completed for a variety of procedures: diagnostic/therapeutic procedures (nasopharyngeal swab,47 lumbar puncture,50 central venous catheter (CVC) dressing change51) (n = 3); resuscitation procedures (transvenous pacemaker,31 intraosseous insertion and defibrillation,49 chest compressions,32 neonatal resuscitation skills,36 laryngeal mask airway insertion,40 orotracheal intubation11,52) (n = 8); and various surgical procedures: general laparoscopic simulator tasks (n = 5),33,45,48,53,54 laparoscopic cholecystectomy (n = 5),35,37,42–44 laparoscopic appendectomy (n = 2),35,43 laparoscopic gynecologic surgical cases (n = 1),56 laparoscopic radical and partial nephrectomy (n = 2),46,55 robotic surgery (n = 1),57 mandibular contour surgery (n = 1),34 vitrectomy (n = 1),39 endovascular aortic aneurysm repair (n = 1).38
 FIGURE 1:
FIGURE 1: Preferred Reporting Items for Systematic Reviews and Meta-analyses 2020 flow diagram for new systematic reviews, which included searches of databases and registers only.
Learners in these studies encompassed a variety of health care professionals, including physicians (n = 25),11,31–39,42–45,47–50,52–57,59,60 nurses (n = 6),11,32,38,47,51,52,60 paramedics (n = 2),40,47 or other (n = 4),32,38,47,52,60 and included trainees and practitioners. Just-in-time training included watching videos (n = 5),31,32,40,47,54 completing a task using an interactive checklist (n = 1),31 training on a video game or virtual reality simulator (n = 8),35,37,38,42,44,46,54,57 laparoscopic simulator (n = 9),33,35,39,43,45,48,53,55,56 and/or task trainer or simulation station practice (n = 10).11,32,34,36,40,47,49–52 Just-in-time training occurred immediately before or up to 24 hours before the actual performance. Just-in-time training ranged from 5 to 30 minutes. Outcomes were assessed either in a simulated setting (n = 13)31–33,36,37,40,45,47–49,53,57,60 or in a patient care setting (n = 15).11,34,35,38,39,42–44,46,50–52,54–56
Risk of Bias for Individual Studies and Certainty of EvidenceThe risk-of-bias assessments are summarized in Tables 1 and 2. The overall certainty of evidence was very low across all outcomes, primarily because of risk of bias and inconsistency (see Table, Supplemental Digital Content 7, which includes GRADE summary tables, https://links.lww.com/SIH/B5).
TABLE 1 - Risk of Bias—Randomized Studies Study ID Domain 1, Randomization Process Domain 2, Deviations From Intended Interventions Domain 3, Missing Outcome Domain 4, Outcome Measurement Domain 5, Selective Reporting Domain S (Only for Crossover Trials) Overall Risk of bias Branzetti31 Low risk Low risk Unclear risk Some concerns Low risk N/A Some concerns Calatayud44 Low risk Low risk Low risk Low risk Low risk Low risk Low risk Chen56 Low risk Low risk Some concerns Low risk Low risk N/A Some concerns Cheng32 Low risk Low risk Low risk Low risk Low risk N/A Curran36 Some concerns Some concerns Low risk High risk Low risk N/A High risk da Cruz37 Low risk Low risk Low risk Low risk Low risk N/A Low risk Desender38 Low risk Low risk Low risk Low risk Low risk N/A Low risk Deuchler39 Low risk Low risk Low risk Low risk Low risk N/A Low risk Hein40 Some concerns Some concerns Low risk High risk Low risk N/A High risk Kroft45 Low risk Some concerns Low risk Low risk Low risk N/A Some concerns Lee46 Some concerns Low risk Low risk Low risk Some concerns Low risk Some concerns Lendvay57 Low risk Low risk Low risk Low risk Some concerns N/A Some concerns Moldovanu42 Some concerns Low risk Low risk Low risk Some concerns N/A Some concerns Moran-Atkin43 Low risk Some concerns Some concerns Low risk Some concerns N/A Some concerns Navaneethan33 Some concerns Low risk Low risk Low risk Some concerns N/A Some concerns Qiao34 Some concerns Low risk Low risk Some concerns Some concerns N/A Some concerns Weston35 Low risk Low risk Low risk Low risk Low risk N/A Low riskThe Newcastle-Ottawa Scale uses predefined criteria and awards stars for each study: 4 for quality of patient selection, 2 for comparability between cases and controls, and 3 stars for the adequate ascertainment of exposure. Asterisks represent stars used in the scale.
T1 outcomes (outcomes measured in a classroom or medical simulation laboratory) included knowledge (n = 2)36,49,51 or comfort (n = 3),47,49,60 expert rated checklists,31,36 expert rated global performance,31,37 procedure-specific outcomes,32,45,48,51 haptic scores,33,53,57 cognitive scores,53,57 interval time,37 or total time.31,33,37,40,53,54,57
KnowledgeOverall, 4 studies (1 RCT and 3 before-and-after studies) reported outcomes related to knowledge after JIT simulation training. These demonstrated a trend toward improved knowledge with JIT simulation training.36,47,49,51 The RCT examined knowledge of participants after a booster neonatal resuscitation program (NRP) session on a manikin simulator with integrated assessment and videoconferencing-based instruction using a 27-item multiple choice questionnaire. There was no significant difference in knowledge in the JIT training group (mean ± SD examination score JIT 21.43 ± 2.1 vs control 20 ± 2.53, P = 0.06). All 3 before-and-after studies demonstrated statistically significant improvements on knowledge-related questions for CVC dressing changes, IO needle placement, defibrillator use, and nasopharyngeal swab collection after the intervention as compared with before.
ComfortThree before-and-after studies47,49,60 reported outcomes related to comfort with a procedure after JIT training. Overall, JIT training seemed to improve learner comfort with procedures. One study evaluated a JIT training curriculum for intraosseous needle placement and defibrillator use designed for medical students and residents who rotated through a pediatric emergency department.49 Participants' comfort level to perform these procedures independently increased from 0% pre-JIT training to 48% post-JIT training for IO needle placement (P < 0.001) and 3% pre-JIT training to 32% post-JIT training (P = 0.002) for defibrillator use.49 The second study reported increased comfort of participants after a just-in-time nasopharyngeal specimen collection module as measured on a 5-point comfort scale (JIT 4.51/5 vs control 2.89/5, P < 0.01).47 The third study examined providers' comfort with workflow changes related to the coronavirus (COVID-19) pandemic, which demonstrated significant positive shifts along the Likert scale on perceived knowledge of new workflow processes, comfort in adopting them in practice, and probability would have an impact on future practice (P < 0.001).60
Expert-Rated ChecklistsThere were 2 RCTs31,36 and 1 before-and-after study51 that examined the impact of JIT training on expert rated checklists. After JIT simulation training for transvenous pacemaker placement in a simulated patient, there was a statistically significant increase in mean technical skills checklist score (JIT 23.44 ± 1.44 vs control 11.99 ± 3.36, P < 0.001).31 Participants in a booster NRP manikin simulation with integrated assessment showed no difference in performance on a NRP checklist (JIT 210.98 ± 22.5 vs control 199.89 ± 13.8, P = 0.11).36 Finally, participants in a just-in-place booster training session on CVC dressing changes had statistically significant increases in their ability to complete the CVC dressing change checklist without any prompts (38% before just-in-place simulation training vs 82% after just-in-place simulation training, P < 0.001).51
Expert-Rated Global PerformanceTwo RCTs demonstrated statistically significant impacts of JIT simulation training on expert rated global performance in the education laboratory setting.31,37 In a study of JIT simulation training for transvenous pacemaker placement, there was a significant difference in overall performance on the Behaviorally Anchored Rating Scale (JIT 4.54 ± 0.46 vs control 2.27 ± 0.75, P < 0.001).31 Among final year medical students performing laparoscopic cholecystectomy in a porcine model, students who engaged in preoperative warm-up in a virtual reality surgical simulator had better mean performance on the Global Operative Assessment of Laparoscopic Skills assessment tool61 intervention score (JIT 21.8 ± 1.15 vs control 17.4 ± 1.65, P < 0.0001).
Procedure Specific OutcomesThree studies (1 RCT32 and 2 randomized crossover studies45,48) examined the impact of JIT simulation training on procedure-specific outcomes. An RCT of JIT CPR training (5-minute video and 2-minute CPR training with or without visual feedback) improved the proportion of chest compressions with depth exceeding 50 mm (JIT 43% vs control 23%, P < 0.001).32 In a randomized crossover study where obstetrics and gynecology residents or third-year medical students completed a 10-minute warm-up on a laparoscopic simulator, the mean laparoscopic proficiency scores (where a lower score indicates better performance) on a trainer were significantly better in the intervention (JIT 16.6 ± 6.17 vs control 22.8 ± 7.39, P < 0.0001).48 Finally, a randomized crossover study of obstetrics and gynecology residents who performed a 15-minute intracorporeal suturing warm-up on a laparoscopic trainer found no statistically significant difference in mean laparoscopic proficiency scores (where a higher score indicates better performance) on a trainer intervention group (311 ± 166 vs 259 ± 210, P > 0.05).45
Haptic ScoresTwo RCTs33,57 and 1 comparative study53 reported objective proficiency evaluation scores. An RCT of faculty and postgraduate trainees in general surgery, urology and gynecology who completed a warm-up pegboard task on a virtual reality robotic surgery simulator found statistically significant increases in total peg touches (intervention group 19.38 ± 9.01 vs control group 21.68 ± 10.06, P = 0.001) and path length (intervention group 1069.37 ± 133 vs control 1149.23 ± 189, P = 0.014), but no difference in economy of motion scores (intervention group 4.42 ± 0.66 vs control group 4.63 ± 0.66, P = 0.13) or cognitive error (intervention 0.06 ± 0.3 vs control group 0.12 ± 0.4, P = 0.34).57 Another RCT of surgeons, surgical trainees, and medical students completing a 10-minute warm-up on a laparoscopic trainer found no statistically significant difference in acceleration, smoothness or working area scores.33 A comparative study of surgical trainees or attendings in obstetrics and gynecology and surgery where the intervention group performed 3 warm-up exercises on a laparoscopic trainer found statistically significant improvements in gesture proficiency (intervention 3.25 ± 0.25, control 1.25 ± 0.05, P < 0.0001), tool movement smoothness (intervention 0.32 ± 0.025, control 0.24 ± 0.025, P < 0.001), hand movement smoothness (intervention 0.57 ± 0.04, control 0.22 ± 0.03, P < 0.001), and cognitive errors (intervention 1.1 ± 0.085, control 1.56 ± 0.03, P < 0.001) in the intervention group.53
TimeFive RCTs31,33,37,40,57 and 2 before-and-after studies53,54 reported the impact of JIT simulation training on total procedure time measured in the education laboratory and showed a trend toward decrease in procedure time with JIT simulation training (Fig. 2). A meta-analysis of these studies showed a nonsignificant decrease in procedure time with JIT simulation training (ES = −0.25; 95% CI, −0.51 to 0.01, P = 0.06). Statistical heterogeneity was moderate (I2 = 31%, P = 0.20) in this comparison, reflecting the different procedures and contexts within which JIT simulation training was applied (transvenous pacemaker insertion, laparoscopic cholecystectomy in a porcine model, LMA insertion, robotic surgery on a simulator, and tasks in a laparoscopic simulator).
 FIGURE 2:
FIGURE 2: Total procedure time T1 outcome.
T2 OutcomesT2 outcomes (improved and safer patient care practices) (n = 13) included expert rated global performance (n = 5),35,42–44,56 error (n = 3),34,38,51 haptic and cognitive scores (n = 1),59 expert rated specific scores (n = 2),42,59 procedure-specific outcomes (n = 2),50,52 procedure success (n = 2),11,50 interval time (n = 1),59 and total time (n = 3),34,35,55 and self-efficacy (n = 3).34,36,51
Expert-Rated Global PerformanceFive RCTs42–44,56,58 examined the impact of JIT simulation training on expert rated global performance in the patient setting. In a randomized crossover study of general surgery residents performing laparoscopic cholecystectomies, where the intervention group completed a 15-minute warm-up on a laparoscopic simulator, the mean objective structured assessment of technical skill score62 was significantly greater in the intervention group (JIT 28.5 vs 19.3, P = 0.042).44 In an RCT of obstetrics and gynecology residents performing nonemergency laparoscopic benign gynecologic surgical cases, where the intervention group completed a warm-up of 3 preassigned tasks on a virtual laparoscopic trainer, there was a statistically significant improvement in their mean modified objective structured assessment of technical skills score (JIT 22.5 vs control 19.5, P < 0.001).56 An RCT of a single surgical team completing laparoscopic cholecystectomies on 20 consecutive patients done with or without a 15-minute warm-up of virtual reality training tasks showed no difference in the global rating scale scores between the intervention and control groups (JIT 4.86 ± 0.13 vs control 4 ± 0.19, P > 0.05).42 In an RCT of general surgery trainees and minimally invasive surgical fellows performing a range of laparoscopic procedures where the intervention group completed warm-up on a laparoscopic trainer, there was no difference in the Reznick et
留言 (0)