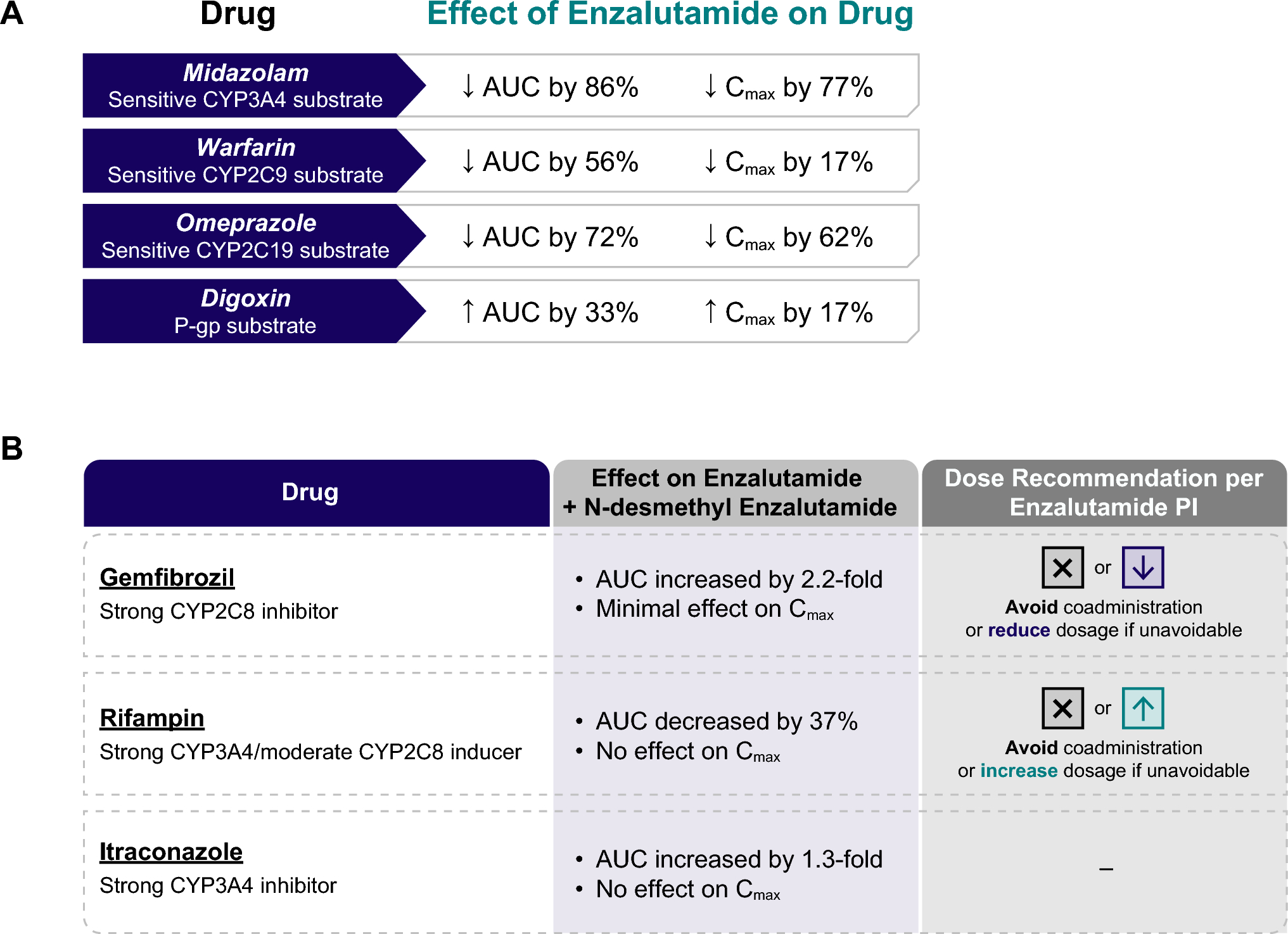
4.1 The DiAna Dictionary
The sensitivity of case retrieval and the relevant disproportionality analysis results may vary depending on the drug cleaning procedures used in SRSs. Disproportionality analysis is mostly performed on public dashboards or other analytical tools with no access to underlying data, ready-to-use databases with partial or non-transparent translation, or individually cured undisclosed databases. While these tools provide easy access to disproportionality analysis, they also pose a risk of inappropriate analyses and interpretation due to users’ unawareness of the nature of data [9]. Common drug translation procedures involve automatic linkage to existing dictionaries (offering only partial translation) and automatic algorithms dealing with misspellings (potentially introducing errors). While the resulting pre-mapped datasets prove highly valuable for signal detection, for effective signal refinement it is recommended a higher control over the definition of the study object already at the drug name-to-ingredient mapping stage.
To address these concerns, a dictionary for drug name-to-ingredient mapping was developed through an automatic procedure that was manually checked and extended. This dictionary, called the DiAna dictionary, has required a time-consuming effort and is made available open source for everyone to use it and propose changes. The use of the DiAna dictionary will allow authors to better define studied drugs, and the pharmacovigilance community to propose more appropriate definitions, contributing to the achievement of an agreement on the best possible drug names-to-ingredient mapping.
The DiAna dictionary is already implemented in a pre-mapped dataset for signal detection accessible through the R DiAna package. The innovative feature and added value of this pre-mapped dataset, compared with previously published attempts of drug name standardizations [7, 16, 17, 17], is its ability to translate almost 99% of drug names reported to the FAERS. The only other dictionary with the same translation percentage was developed by Wong et al. [17], but it was not publicly available. Additionally, the mapping of free text to active ingredient is freely accessible for easy inspection, update, and modification according to the specific research question in signal refinement activities (see Table 2). A greater control on data cleaning and focusing on the definition of the studied drugs, and not only of the studied events, will result in improved replicability and accuracy of signals and more conscious and appropriate interpretation of results, with relevant benefit for the scientific community.
Table 2 Comparison between the standardization steps performed to create DiAna and other published versions of the FAERS.4.2 Better Retrieval for Higher Sensitivity
We were able to translate 98.94% of total drug entries to 6282 unique active ingredients using the DiAna dictionary, compared with 76.32% using only RxNorm. When considering unique drug entries, we translated 346,854 terms over 793,274 (43.72%). We manually checked the first 14,832 terms (up to 174 occurrences), which were responsible for the translation of 96.88% of total drug entries. We believe that this is a good starting point to share our work with the pharmacovigilance community and enable more participative use and development of the DiAna dictionary. In contrast to the previous work by Wong et al. [17], made on the FAERS up to 2012, we made our dictionary (up to 2022) open source. We chose to design the translation so that a new column is produced with only active ingredients while keeping the original verbatim text in a separate column for more in-depth analyses. We have also decided not to translate to salts as this is rarely taken into account in disproportionality analysis and can lead to confusion about whether the same ingredient with unspecified salt should be considered among cases or non-cases. Instead, we have included the linkage to the ATC classification. In some cases, underspecified drug names were translated to higher ATC classes such as ‘antihypertensives, unspecified’, as this information can be important for adjusting the analysis and assessing individual cases. The most frequently observed higher classes to which unspecified drug names were mapped were vitamins, immunoglobulins, and estrogens, appearing in 1.7%, 0.8%, and 0.6% of the FAERS reports, respectively. Retrieving information about estrogen exposure is crucial due to its significance as a risk factor for conditions such as thrombosis. This information, not detected by standardization procedures focusing on active ingredients alone, is essential for conducting a more thorough evaluation of relevant cases.
The DiAna dictionary translates a higher proportion of the database, enabling a higher sensitivity in case retrieval, and a higher number of identified cases. This results in better specificity in the definition of non-cases and higher accuracy in signal detection, leading to earlier and clearer signals, as, in specific products, the number of retrieved reports significantly increased. For example, for rimegepant, the DiAna dictionary identifies 278 times more reports than RxNorm alone.
In addition to identifying active ingredients, the drug name information enabled us to identify reports derived from clinical trials (0.28% of total reports), as they recorded placebo, blinding, or drug codes. This information can help researchers exclude evidence already taken into account in other steps of drug safety characterization from the disproportionality analysis.
Finally, the linkage between the DiAna dictionary and the ATC classification can help in the retrieval of drug classes and visualization. The information on the distribution of drug classes in the database is particularly useful for the design of future disproportionality analyses, as it provides insight into the representativeness of the population chosen for comparison. Over one-third of the database consists of reports with anticancer and immunomodulating drugs. The large contribution from these agents is in line with recent global reporting patterns observed for serious and fatal events [23, 24]. Moreover, the remarkable number of reported cases for paracetamol and acetylsalicylic acid underscores once more the relationship between drug consumption and adverse event reporting [25]. Recent observations, specifically in the context of the extensive rollout of COVID-19 vaccines, have reignited attention to the possibility that this uneven distribution of drugs in the SRS should be considered during study design since it may lead to masking/cloaking bias, thus potentially hiding disproportionality signals [26].
The DiAna dictionary and its linkage to the ATC classification are freely available online for everyone to use (https://osf.io/zqu89/) and can be corrected and expanded by experts in the field. Changes can be proposed in the GitHub repository (https://github.com/fusarolimichele/DiAna) under the issue DiAna dictionary, and will be periodically validated and integrated into the existing dictionary. This collaborative effort will improve the quality and reproducibility of pharmacovigilance research. The dictionary can be downloaded in Microsoft Excel (Microsoft Corporation, Redmond, WA, USA) and csv formats and can be imported into any data management software, such as R, to automatically translate drug names to active ingredients before conducting analyses. Users can also easily modify the translation of specific terms for their analyses, which is not possible with ready-to-use FAERS databases.
4.3 Higher Control on the Mapping for Signal Refinement
The DiAna dictionary has also already been implemented in the DiAna open-source R package [22], which, together with other functions for disproportionality analysis, allows to import a cleaned and documented version of the FAERS preserving the possibility of adjusting drug-names translation. In particular, the drug names coded to a specific active ingredient of interest can be retrieved with the function ‘get_drugnames()’ (see ESM Table S2 for an example), and, if deemed necessary, they can be modified.
For example, when investigating systemic reactions to ingredients that can be administered topically or systemically, we may want to exclude the topical formulations from the drug definition. One approach is to consider the variable storing information about route of administration, but these data are often unavailable. For instance, gentamicin might be treated differently depending on whether it is administered systemically, topically as a cream (e.g., rinderon-vg), or in eye/ear drops (e.g., garasone). Similarly, when studying aripiprazole, the long-acting injectable form (e.g., Aristada) might be handled differently. This flexibility is lost in databases that have already mapped ingredients without preserving drug name information.
4.4 Identification of Medicinal Products, Towards Higher Standardization in the Collection and Management of Drug Information
In the future, a higher standardization of drug information could already be achieved in the collection, management, and storage of spontaneous reports, following E2B-R3 recommendations to use the Identification of Medicinal Products (IDMP) system developed by the International Organization for Standardization (ISO)—a set of codes unambiguously identifying not only the active ingredients but also the strength and the route of administration of the product. Nonetheless, the E2B-R3 still allows for a free text field for the name of drugs as reported.
The WHO Vigibase, following E2B-R3 recommendations, is embedded with a tool for drug name standardization, i.e., the WHODrug Dictionary. This dictionary compiles extensive drug information, including information about herbal medicines, links drug names to the Anatomical Therapeutic Chemical (ATC) classification, and automatically deals with misspellings and new entries [15]. Nonetheless, this dictionary is only available upon subscription and therefore it cannot be used for, and linked to, an open-source database aiming for complete transparency. Additionally, even if employing a database where drug names are pre-standardized to active ingredients simplifies the process of defining the object of study, as it only requires grouping the active ingredients of interest, it makes it challenging to recognize that different raw drug names translated to the same active ingredient might vary in their suitability for inclusion in the definition.
4.5 Limitations, Strengths, and Further Goals
The DiAna dictionary is not designed as a static dictionary but as a living one—it will require ongoing efforts to keep up with new drugs and terms. We are recursively extending our translation to reach and maintain a fully checked translation of any entry with over 100 co-occurrences. Users of the DiAna dictionary should be aware of this limitation (which is even more impairing in other pre-mapped datasets), especially with less frequent terms that may not be included in the dictionary. It is recommended that before any signal refinement activity concerning a specific drug, inherent terms are checked in the dictionary and any new translations are shared to integrate into the DiAna dictionary for everyone to benefit in their signal detection and refinement activities. The translation will plausibly never be complete, since some terms are not easily translated (e.g., ‘chinese food’) and many choices are partly subjective. However, these choices can be defined in agreement with the entire pharmacovigilance community.
The translation of ambiguous terms was also noted as a challenge, especially with over-the-counter cold, cough, and flu agents (multiple ingredients changing over the years). When we were not certain, we used the higher-level term (e.g., ‘cough preparations, unspecified’). The lack of expertise in supplements and phytotherapies may have resulted in the dictionary being excessively generic (for example, referring to Plantago spp instead of individual species, and COVID 19 vaccines instead of specific types), and it could benefit from refinement by experts for higher specificity and coverage of entries provided to other spontaneous report databases (CAERS and VAERS are more appropriate to investigate the safety profile of these medicinal products). For example, mapping herbals using the Medicinal Plant Names Service would significantly improve their standardization (cfr. Medicinal Plant Names Services Portal, Royal Botanic Gardens, Kew; https://mpns.science.kew.org/mpns-portal/).
Since lack of completeness is a known problem in spontaneous reports, and other information is not always available, we implemented sharp-cut operative choices to retrieve active ingredients based only on the drug name. The use of additional columns such as country, year of occurrence, dose, indication, and route of administration could help discriminate between mistranslations when the same drug name may be translated to multiple active ingredients. Moreover, information from the drug name column could be used to impute information into other columns. For example, ‘nizoral a-d’ is translated to ketoconazole and refers specifically to an anti-dandruff shampoo (i.e., the indication, formulation, and route of administration could be imputed if missing), while ‘hypersal’ refers to a sodium chloride nebulizer solution, and ‘jinarc’ refers to a formulation of tolvaptan specifically indicated for autosomal-dominant polycystic kidney disease. By incorporating a drug name-to-product translation feature, for example, referring to the WHO Drug Global or to the IDMP, we could streamline the process of the imputation of structured fields using free text, thereby enhancing the value of the DiAna dictionary.
Highlighting the importance of transparency in drug standardization and drug definition and increasing the sensitivity of case retrieval were our two main goals. Nonetheless, it would be interesting to compare accuracy of disproportionality analysis using different drug name standardization strategies.
Linking INN names to ATC codes was a complex task due to the existence of combination products (e.g., glecaprevir and pibrentasvir), medicinal products with ingredients that do not have an ATC code yet, and experimental substances that are missing even the INN. The linkage will be annually updated according to changes in the ATC classification to preserve its utility.
With the recent advent of Natural Language Processing (NLP) techniques, tailored tools have also been implemented to extract information from free text sources such as medical records, as exemplified by Apache cTAKES [27]. Nonetheless, named entity recognition techniques’ accuracy decreases in the lack of context and when having to deal with many possible entities. Given that the FAERS drug name fields often do not provide more than one word and given the high number of active ingredients (i.e., entities), we have chosen to employ existing drug name dictionaries and manual revision as a more sensitive method for translation. Nevertheless, the use of NLP techniques, particularly taking into account multiple variables of the FAERS (e.g., route of administration, dose, indication, country) is a promising endeavor to further improve drug names standardization, particularly for instances in which the ambiguity of a drug name may be solved taking into account additional fields, and to extend the automatic translation to drug names with few occurrences. The subscription based UMC WHODrug Koda service (https://www.who-umc.org/whodrug/whodrug-portfolio/whodrug-koda/), for example, is an AI tool that takes into account multiple information and helps drug mapping, even if requiring a manual validation.


留言 (0)