
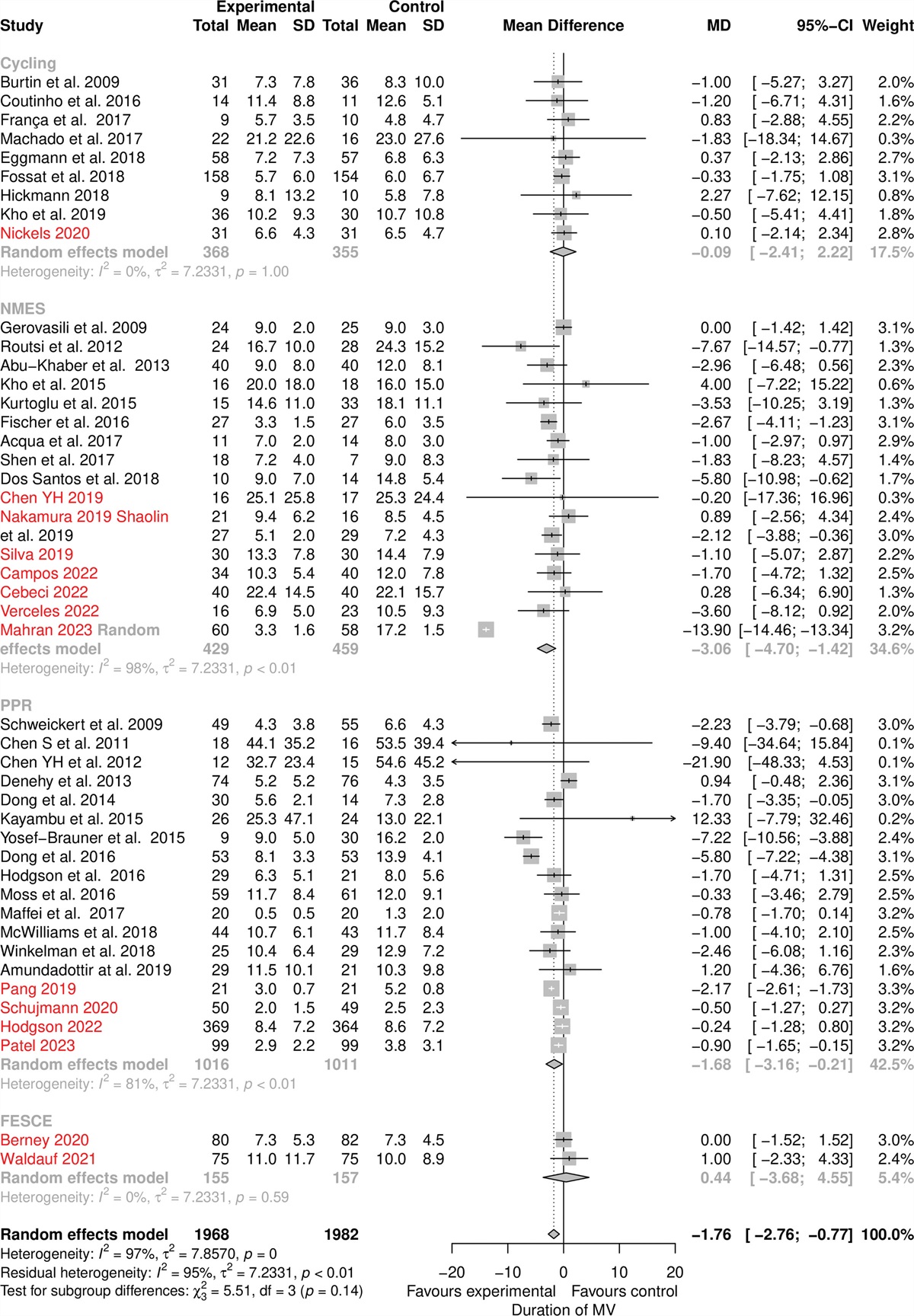
記住我









Robust risk adjustment is one of the cornerstones of outcomes research and quality improvement. Although several severity scores exist to measure ICU performance by adjusting for admission severity of illness (1–5), several issues limit their utility for benchmarking performance across ICUs and over time. Traditionally, risk models such as the Acute Physiology and Chronic Health Evaluation (APACHE) system (Cerner, Kansas City, MO) (1) recommended using dedicated clinical experts trained to capture data through manual curation of electronic health records (EHRs). With the digitization of hospitals and the desire to collect data more efficiently, risk models are increasingly calculated through direct extraction from EHR data. Although this solves many issues of efficiency and interrater reliability, it also introduces new risks of bias through variation in documentation patterns (e.g., measurement error and/or data drift) (6–9). When these variations are nonrandom and correlated with institutions, significant bias can be introduced, artificially improving or worsening measured performance for an institution relative to peers.
The risk of bias not only varies by the frequency and magnitude of measurement error but is further magnified when the feature has significant influence on a risk model. The prime example is Glasgow Coma Scale (GCS), as it is the highest weighted feature in the APACHE score (1) and is susceptible to documentation bias for several reasons. APACHE uses a construct where patients who are heavily sedated should be documented as “unable to score due to medication”; however, this concept is not required in traditional GCS documentation. We have observed in the eICU Research Institute (eRI) dataset that some ICUs never document “unable to score due to medication.” Therefore, heavily sedated patients may receive the lowest possible GCS value (3 of 15), which is associated with 48 points out of a possible 299 (in the APACHE score) compared with 0 points for a GCS of 15. In these situations, the ICUs who do not chart “unable to score due to medication” will have systemically higher risk scores than ICUs who do, inflating their outcomes performance.
Other theoretical sources of bias are harder to observe but also likely to influence performance. The primary reason for admission to the ICU can have a significant impact on mortality prediction (10), yet the choice of diagnosis can be highly subjective and vary across institutions and over time. For example, the difference between sepsis and other infections can be nebulous and evolves, along with the definitions of sepsis. We have observed a significantly increased proportion of patients admitted for sepsis coinciding with a decreased severity of illness (11). Behavior change can vary between different institutions, and systematic misclassification of diagnoses could have tangible effects on risk estimates.
Our goal was to develop an accurate in-hospital mortality predictive model and a process for benchmarking ICU performance that is robust to variations in documentation practice. We hypothesize that we can achieve this through careful design of model features that balance accuracy with robustness to documentation bias. We sought to develop and validate this model by leveraging a large, multicenter ICU clinical database with variations in performance and documentation patterns.
MATERIALS AND METHODSThe eRI database, housing all historical data collected from participating telecritical care programs, was used for the development and validation of the proprietary Philips Critical Care Outcome Prediction Model (CCOPM). The eRI database includes patient unit stays admitted to ICUs monitored by the Philips eICU program where physiologic, diagnosis, and treatment information are primarily captured through HL7 integration with bedside monitoring and EHR systems (12). The use of the eRI database has been certified as meeting safe harbor standards by Privacert (Cambridge, MA) (The Health Insurance Portability and Accountability Act of 1996 Certification no. 191202-1) (13).
After a priori exclusion of ICUs without key data interfaces, all patient unit stays discharged from the hospital between January 1, 2017, and December 31, 2018, were included in the analysis. Supplemental Figure 1 (https://links.lww.com/CCM/H252) shows the excluded patient unit stays with: 1) length of stay less than 4 hours or greater than 365 days, 2) ageless than 16 years, and 3) missing required data inputs. Included patients were required to have nonmissing values for data inputs commonly measured for ICU patients within the first day of ICU admission (Table 1). If patients had multiple ICU encounters within a single hospitalization, each ICU stay was treated as an independent observation. Patient unit stays were randomly split into development and validation sets at a ratio of 3:2 after stratification by year of hospital discharge. All results are from the validation cohort. APACHE IVa and IVb predictions had previously been calculated for all patients with complete data. Comparisons were performed in the validation cohort among patients with both scores available.
TABLE 1. - List of Model Features Data Input Category Data Input Detailed Definition Basic characteristics Body mass indexa kg/m2 Basic characteristics Agea yr Basic characteristics Gender Female, non-Female (or not applicable) Basic characteristics Pre-ICU admission lead timea Hours in the hospital before ICU Basic characteristics ICU admission source i.e., floor, Emergency Dept., etc. Basic characteristics Ventilation statusa Yes vs No, at hour 24 of ICU admission Basic characteristics Admitted with elective surgery statusa Yes vs No Vital signs Mean blood pressurea mmHg, mean, variability Vital signs Systolic blood pressurea mmHg, mean Vital signs Diastolic blood pressurea mmHg, mean Vital signs Heart ratea Rate/min, mean, variability Vital signs Respiratory ratea Rate/min, mean, variability Vital signs Oxygen saturation, Spo 2a %, mean Labs Blood glucosea mg/dL, mean Labs Blood white blood cella Count per mL, mean Labs Blood sodiuma meq/L, mean Labs Blood potassiuma meq/L, mean Labs Blood creatininea mmol/L, mean Labs Blood hemoglobina g/dL, mean Labs Blood albumin g/dL, mean, with missing Labs Blood lactate mmol/L, mean, with missing Labs Arterial blood gas, pH Mean, with missing Labs Arterial blood gas, Paco 2 mmHg, mean, with missing Provider assessment Admission diagnosis Categories allowing unspecified Provider assessment Total Glasgow Coma Scale score Glasgow Coma Scale scores (3–15) with unable to score due to medication, NA; last entry at 24 hr of ICU admissionaRequired data for model development.
Patient baseline risk was defined using data available through the first 24 hours of ICU admission (Table 1). When data were not available within the first 24 hours, data captured up to 6 hours prior to ICU admission were included. Outcomes were patient mortality status at ICU and hospital discharge.
Continuous features commonly measured (e.g., vital signs, chemistry labs, age, and body mass index [BMI]) were used to fit the model with four degrees of freedom to allow nonlinear relationships with outcomes. Other continuous features less commonly measured (e.g., lactate and pH) were included as categorical features with a separate category of missing data (Supplemental Table 1, https://links.lww.com/CCM/H253). Features with many nominal values were collapsed with cut points defined by clinical knowledge and data distribution, to ensure clinically meaningful groups with large enough sample sizes to support stable coefficient estimation. Features were designed to capture a clinically accurate reflection of the patient while minimizing the impact of potentially anomalous outlier values through use of means and measures of variability (Table 1) rather than relying on the most extreme values used in other risk models, such as APACHE. Various approaches to modeling GCS were evaluated, and ultimately, the “last GCS” value of the first 24 hours was used as it was deemed less likely to be influenced by immediate postoperative sedation on admission while still reflecting admission neurological status.
The primary admission diagnosis strings were regrouped based on clinical knowledge to minimize the risk of misclassification. ICU clinicians trained in APACHE methodology annotated admission diagnoses with their assessment of misclassification risk. The diagnoses with high risk of misclassification based on these responses were collapsed with other physiologically similar diagnoses based on the body system and operative status. For example, although many cases are distinct, the difference between pulmonary sepsis and pneumonia may not always be clear, and criteria have evolved (11,14). We opted to sacrifice an increase in accuracy to minimize systemic bias in the documentation by collapsing these into a single diagnosis group, ensuring stability as the pattern of diagnosis shifts across ICUs and over time. ICU stays with an unassigned or rare diagnosis were also collapsed into a separate category. In total, 54 unique ICU admission diagnosis groups were created as features in the model. Supplemental Table 2 (https://links.lww.com/CCM/H254) provides the list of diagnostic categories and how they map to the APACHE admission diagnoses.
Modeling TechniquesThe CCOP models were developed using the generalized additive model (GAM) framework, which is an extension of a standard linear model (with binomial link function). This framework allows the model to use nonlinear functions of continuous features while maintaining the additivity of multivariate linear regression. Interaction terms were included to allow features to have a different association with outcome dependent on another feature with which they interacted.
Random effects (intercepts and slopes) for vital signs over the admission diagnosis groups were added allowing vital signs to have different associations with outcomes across diagnosis groups. The random effects were fitted along with other fixed effects in a generalized linear mixed model. For better efficiencies in model training, we optimized the random effects and fixed effects coefficients in the penalized iteratively reweighted least square step by assigning points per axis for evaluating adaptive Gauss-Hermite approximates to log-likelihood (15).
Model Evaluation MetricsModel discrimination was assessed using the area under the receiver operating characteristic curve (AUROC) (16). Model calibration was assessed by the actual/predicted ratio and calibration-in-the-large statistics in addition to visualizing calibration by plotting the observed and predicted mortality across 50 equal sized risk groups based on predicted mortality. The model discrimination and calibration were also examined in subgroups identified by ICU admission diagnosis (minimum 200 observations) and ICU level characteristics. The distributions of the quantitative performance matrices were compared between APACHE IVa and IVb.
The robustness to changes in GCS documentation practice was validated on historic cohorts (not included in primary model development and validation). For health systems where we had prior knowledge of abrupt changes in GCS documentation, we compared the APACHE IVa and the CCOPM performances in the 1 year before and 1 year after these abrupt changes. Given that APACHE IVb was not designed to populate predictions in the years before 2014, during which the GCS documentation pattern change might have occurred, it was not included in this analysis.
Missing DataA secondary validation on the sample excluded due to missing data was performed using multiple imputation to fill in the missing values of required variables by iteratively using the chained equations with 10 imputations (17). The continuous variables were imputed using a truncated linear regression with a restricted range specified by the acceptable valid range. The average predictions of the 10 imputed copies were used to generate predicted probabilities. Supplemental Figure 1 (https://links.lww.com/CCM/H252) shows the patient cohort selection as well as how many patients remained after accounting for missing data.
RESULTSA total of 572,985 ICU stays discharged from the hospital between January 1, 2017, and December 31, 2018, representing 552 ICU years were included. After applying the sequential exclusion criteria (Supplemental Fig. 1, https://links.lww.com/CCM/H252), 509,586 ICU stays were included in the final cohort and randomly split into 305,590 and 203,996 unit stays for the development and validation sets, respectively. Among 203,996 ICU stays receiving predictions in the validation sample, 161,282 (79.1%) received a valid prediction of ICU and hospital mortality according to APACHE IVa and IVb. Patient baseline characteristics are presented in Table 2.
TABLE 2. - Patient Demographics and Clinical Outcomes Variables Development Set Validation Set p a n 305,590 203,996 Age, mean (sd) 63.37 (16.86) 63.40 (16.84) 0.436 Sex, non-female (%) 165,960 (54.3) 110,711 (54.3) 0.798 ICU type (%) 0.313 Cardiac ICU 23,198 (7.6) 15,449 (7.6) Cardiac/Coronary Care Unit-Cardiothoracic ICU 33,812 (11.1) 22,834 (11.2) Medical-Surgical ICU 168,649 (55.2) 112,450 (55.1) Medical ICU 31,632 (10.4) 21,280 (10.4) Neurological ICU 19,436 (6.4) 12,687 (6.2) Surgical ICU 23,955 (7.8) 16,061 (7.9) Trauma ICU 4,908 (1.6) 3,235 (1.6) ICU admission source (%) 0.585 Unspecified 324 (0.1) 231 (0.1) Direct admit 18,560 (6.1) 12,252 (6.0) Emergency department/observation 162,988 (53.3) 108,657 (53.3) Floor 58,939 (19.3) 39,304 (19.3) Operation room 55,464 (18.1) 37,205 (18.2) Transfer 9,315 (3.0) 6,347 (3.1) Pre-ICU admission lead time, hr, mean (sd) 31.37 (125.66) 32.08 (186.33) 0.106 Elective surgery, yes (%) 49,084 (16.1) 33,063 (16.2) 0.167 Body mass index, kg/m2, mean (sd) 29.21 (8.63) 29.21 (8.59) 0.973 Mean blood pressure, mm Hg, mean (sd) 83.21 (12.99) 83.26 (13.04) 0.222 Heart rate, rpm, mean (sd) 84.57 (16.42) 84.60 (16.39) 0.579 Oxygen saturation, %, mean (sd) 96.70 (2.29) 96.70 (2.26) 0.555 Respiratory rate, rpm, mean (sd) 19.73 (4.60) 19.73 (4.62) 0.74 Glucose, mg/dL, mean (sd) 142.83 (52.57) 142.49 (52.10) 0.024 Lactate, mmol/L, mean (sd) 2.38(2.33) 2.37(2.33) 0.791 pH, mean (sd) 7.36(0.10) 7.36(0.10) 0.92 WBC, count/mL, mean (sd) 12.00 (8.73) 12.00 (8.55) 0.974 Hemoglobin, g/dL, mean (sd) 11.14 (2.33) 11.13 (2.34) 0.229 Sodium, mEq/L, mean (sd) 138.74 (4.95) 138.74 (4.95) 0.859 Potassium, mEq/L, mean (sd) 4.10 (0.59) 4.10 (0.59) 0.314 Creatinine, mmol/L, mean (sd) 1.52 (1.64) 1.52 (1.65) 0.906 Glasgow Coma Scale, total, mean (sd)b 13.54 (2.88) 13.54 (2.87) 0.931 ICU length of stay, hr, mean (sd) 73.78 (99.91) 73.73 (99.98) 0.845 Hospital length of stay, hr, mean (sd) 171.98 (274.70) 172.98 (292.65) 0.218 ICU mortality, mean (sd) 0.06 (0.24) 0.06 (0.24) 0.61 Hospital mortality, mean (sd) 0.09 (0.29) 0.09 (0.29) 0.819ap values were generated by the χ2 (for categorical variables) and the two-sample t test (for continuous variables).
bGlasgow Coma Scale score was measured as the last entry seen at/before 24 hr of ICU admission, whereas all other variables were measured as the mean of all data entries within the baseline time window.
The CCOPM resulted in higher model discrimination (AUROC) and better calibration (actual/predicted ratios closer to 1; calibration-in-the-large values closer to 0) than APACHE models (Table 3 and Fig. 1, A and B). APACHE IVa and IVb exhibited similar discrimination, although calibration was improved with APACHE IVb. Model performance among the 8.8% (48,909 patients) of the cohort excluded due to missing data is described in the Supplemental Results (https://links.lww.com/CCM/H255). The most common reason for missing data was laboratory values (about 10%), followed by vital signs (about 5%) and BMI (2%). AUROCs were higher in the imputed dataset (0.927 and 0.940 for ICU and hospital mortality, respectively), but the model tended to overpredict mortality (standardized mortality ratio for ICU and hospital mortality were 0.905 and 0.808, respectively).
TABLE 3. - Model Discrimination and Calibration Metrics of Acute Physiology and Chronic Health Evaluation IVa and IVb, and Critical Care Outcome Prediction Model Model Outcome Discrimination: AUROC Calibration: Actual/Predicted Ratio (Slope) Calibration: Calibration-in-the-Large (Intercept) APACHE IVaa ICU mortality 0.879 0.782 –0.360 APACHE IVba ICU mortality 0.881 0.898 –0.163 New modela ICU mortality 0.925 1.037 0.054 New modelb ICU mortality 0.900 1.007 0.010 APACHE IVaa Hospital mortality 0.862 0.756 –0.425 APACHE IVba Hospital mortality 0.863 0.966 –0.054 New modela Hospital mortality 0.905 1.034 0.054 New modelb Hospital mortality 0.922 1.011 0.010APACHE = Acute Physiology and Chronic Health Evaluation.
aMetrics generated among 161,282 ICU stays in the validation set with all prediction values available (APACHE IVa, IVb, and new model).
bMetrics generated from the entire validation set, n = 203,996.
 Figure 1.:
Figure 1.: ICU and hospital mortality model performance. A, ICU mortality performance in the validation cohort with all predictions available presented for Acute Physiology and Chronic Health Evaluation (APACHE) IVa in (i), APACHE IVb in (ii), and the Critical Care Outcome Prediction Model (CCOPM) in (iii). B, Hospital mortality performance in the validation cohort with all predictions available presented for APACHE IVa in (i), APACHE IVb in (ii) and the CCOPM in (iii). A:P = actual-to-predicted ratio of deaths, CITL = calibration in the large, Lowess = locally weighted scatterplot smoothing.
The improved model performance and calibration is also being observed when stratifying analyses by admission diagnosis strings (Column B of Supplemental Table 2, https://links.lww.com/CCM/H254). In addition to the increase in mean and median AUROCs, a narrower dispersion of AUROCs across individual diagnosis strings compared with APACHE IVa and IVb was observed (Supplemental Table 3, https://links.lww.com/CCM/H256; and Supplemental Fig. 2, https://links.lww.com/CCM/H257). There were only three diagnosis strings for which the CCOPM significantly underperformed APACHE IVa (delta of AUROCs < –0.08): fusion-spinal/Harrington rods, asthma, and alcoholic withdrawal, with AUROC deltas of –0.309, –0.166, and –0.091, respectively. These three diagnoses tended to have relatively low mortality rates: 0.3%, 0.7%, and 0.6%, respectively.
Consistently improved discrimination and calibration performance compared with APACHE IVa/IVb are also observed within each ICU and ICU discharge year (e.g., ICU-year). The overwhelming majority of the ICU-years received more accurate predictions with the CCOPM (detailed results in Supplemental Table 4, https://links.lww.com/CCM/H258).
To illustrate the effect of changes in GCS documentation pattern, two health systems (representing over 25 ICUs and over 120,000 patients) that previously experienced a substantial change in APACHE-adjusted mortality performance after changes in GCS documentation practice were identified: one health system had an inadvertent change in GCS documentation, whereas the other went through a deliberate change to better align with APACHE criteria (Fig. 2, A and B).
 Figure 2.:
Figure 2.: A, Change in predicted mortality after an inadvertent change in Glasgow Coma Scale (GCS) documentation practice in consecutive years. Health system (A) inadvertently changed their process for capturing GCS to align more closely with Acute Physiology and Chronic Health Evaluation (APACHE) methodology resulting in a smaller percentage of patients with a total GCS score of 3, reducing from 8% to 5% of the population. Represents 48,552 ICU stays in the year prior and 56,373 ICU stays in the year after change that were not part of the primary study cohort. B, Change in predicted mortality after a deliberate change in GCS documentation practice in consecutive years. Health system (B) deliberately changed its process for capturing GCS to align more closely with APACHE methodology by no longer using GCS values charted at the bedside during routine care and instead using only GCS values specifically documented for APACHE scoring. This resulted in the proportion of patients with a total GCS score of 3, reducing from 23.7% to 5.1% of the population. Represents 9,531 ICU stays in the year prior and 10,120 ICU stays in the year after change that were not part of the primary study cohort.
For both health systems, there was a significant change in the proportion of GCS scores equal to 3 before and after the GCS documentation pattern change, confirming the impact of the documentation change on GCS scores (Fig. 2, A and B). In both health systems, APACHE IVa hospital mortality predictions fluctuated dramatically along with GCS scores in contrast to the CCOPM showing relatively stable predictions across time periods (Fig. 2, A and B). Importantly, the CCOPM exhibited improved model discrimination compared with APACHE IVa across the 2 years examined: AUROCs: 0.916 versus 0.869 for health system A, and 0.897 versus 0.866 for health system B. This was also observed individually before/after transition for health system A (AUROCs for the CCOPM 0.920/0.913 vs APACHE IVa 0.877/0.864) and health system B (AUROCs for the CCOPM 0.900/0.895 vs APACHE IVa 0.865/0.873).
DISCUSSIONRisk models have been frequently used to adjust for ICU admission disease severity while benchmarking ICU performance. The performance of the risk models is dependent on including accurate information relevant to the outcome of interest. However, the accurate extraction of clinical data requires specialized training, reflects subjective assessment, and relies on complete documentation from the provider. Not surprisingly, commonly used ICU risk models such as Simplified Acute Physiology Score (SAPS) (4), APACHE (10), and mortality probability model (5) were all initially developed with manually collected/curated data to ensure data input validity.
Use of ICU risk models has historically been hampered by tedious, manual data collection. The transition from paper-based documentation to the EHR has alleviated but not completely solved the problem (7,18). With the broader penetration of EHRs, developing an automated system to collect data reliably and cost-effectively with high inter-rater reliability is important. The automatic interfaces with bedside monitors, laboratory measurements, and other intervention devices have facilitated standardized data collection, mostly for vital signs, lab measures, and ventilator settings. However, reliable collection of data elements that require human subjective judgment, intervention, or complete documentation remains challenging.
An example is the GCS score, which requires providers to follow the scoring instructions in a precise manner, and measurement reliability could suffer from inadequate training and education of the assessment methods (19,20). We have witnessed an example from the health system in Figure 2B, where heavily sedated patients (often during mechanical ventilation) can be systematically assigned the lowest score instead of “unable to score due to medication.” This led to 23.7% of admissions having a lowest value of 3 based on bedside nursing documentation compared with only 5.1% the following year after only GCS values input explicitly for APACHE scoring were used. When this occurs, the bias introduced by GCS score would have a significant impact on the predictive model and jeopardize its validity as a severity adjustment as illustrated in Fig. 2, A and B. Another example of a parameter relying on subjective assessment that could suffer from variability is the ICU admission diagnosis. It is challenging to enforce a single stable standard across multiple institutions with different EHR systems or even over time for the same institution. Overreliance on automation for those data could instead introduce new biases for risk score models, driven by variations in documentation patterns or data drift.
This work has illustrated an accurate benchmark model that appears to have resiliency to a known source of bias can be developed using automated data collection. Unlike existing models, the CCOPM does not require manual curation of model features. This, along with other key design features, is summarized in Supplemental Table 5 (https://links.lww.com/CCM/H259). Using APACHE IVa and IVb as the reference, the CCOPM demonstrated better discrimination and calibration across the overwhelming majority of ICU admission diagnoses, ICU types, hospitals, and years.
Biases in the data are the main factor for the reproducibility dilemma of machine learning models in health care (21). This work focused on the meticulous design of model features and data extraction while balancing model accuracy and potential bias through collaboration between clinical and data science teams. Most features that would require an onerous level of manual oversight to obtain accurate documentation were purposely excluded. Examples include patient treatments that may reflect the subjective assessment and decision of the provider. For example, the timing and use of vasopressors may vary over time and across institutions as evidence evolves. Excluding these treatment features would remove a source of bias while reducing the data required to generate risk scores.
To mitigate the impact of a single erroneous GCS assessment, the last GCS value within the first day of admission was used instead of the lowest GCS score. Similarly, the primary admission diagnosis was regrouped based on clinical knowledge to mitigate possible drift in diagnosis documentation across institutions and over time. Subgroup analyses of model performance within the diagnosis groups and diagnosis strings demonstrated better results from the CCOPM.
Specific accommodations for missing data were made depending on the underlying mechanisms. Missing data may reflect the clinician’s judgment of the patient’s underlying condition, a data-capture problem (e.g., when an EMR laboratory interface is not complete.), or other unknown reasons. Although we must accept the fact that data captured in an EMR can only be an indirect measure of a patient’s true state (22), we balanced the need to include critical patient characteristics and the risk of directly modeling the “missing values” in the regression model by requiring commonly measured features to be present and allowing a “missing value category” for informative laboratory measurements that are less commonly ordered by clinicians.
Last, by leveraging a collaboration of a telecritical care network, variation in practice across space and time can be detected. Much of the potential biases in data features would probably not have been visible with smaller data samples from either a single institution or over a shorter period of time. Models built on such limited data are prone to overfit the local data, thereby reducing generalizability. The heterogeneous, multicenter data used in this research facilitated the recognition and adaptation of varying data patterns, ultimately improving the generalizability of the model. The large sample size also allowed use of techniques that improve accuracy for small subgroups. These techniques include the use of random effects across diagnoses, which enabled model features to have distinct relationships with the outcome across diagnostic groups.
This work is not without limitations. Although it provided evidence to support the bias mitigation related to GCS documentation, direct mitigation evidence of other biases could not be obtained. Quantifying some of these biases would require setting up field studies to evaluate. Furthermore, other, more insidious forms of bias may have gone unrecognized. Continued data drift is expected in the ICU cohort, as the standard of care, practice pattern, workflows, and data interfaces vary across institutions and over time. However, with automated data collection and processing, the CCOPM models can be evaluated and recalibrated on a routine basis to expose and manage potential bias within algorithms and to influence future changes in care and documentation. Last, the CCOPM was developed as part of a proprietary system for a cohort of ICUs with active telecritical care systems, which may have some inherent differences from the institutions without the telecritical care systems, and much of the observed improvements in calibration may be attributed to developing on a new cohort. This model’s performance against other ICU populations merits further research, and routine recalibration is recommended (23).
CONCLUSIONSIn conclusion, this work proposes a generalizable and accurate model that can be used for benchmarking mortality performance of ICUs. Importantly, the automated capture of GCS and vital signs and labs obviates the need for specialized training and dedicated personnel to capture these data. Although direct proof of bias mitigation is challenging, the model showed resilience to an abrupt change in GCS practice from two health systems (over 120,000 patients) not part of the primary development or validation cohorts. The CCOPM was developed using a large, heterogeneous sample of hospitals with automated electronic data collection of critically ill patients, with careful consideration of clinical workflow and documentation practices. A good collaboration between data science, epidemiology, and clinicians, while leveraging a data science architecture, is essential to further research of severity of illness and outcomes.
ACKNOWLEDGMENTSWe thank Donna Decker for her support in managing this collaboration and requirements. We also thank Ashley Vernon, Colin McKenna, and Russ Rayner for their data engineering support.
REFERENCES 1. Zimmerman JE, Kramer AA, McNair DS, et al.: Acute physiology and chronic health evaluation (APACHE)
留言 (0)