
記住我
where T is the time window. And the we adopt the neuron with the largest number of spikes in the time window as the output neuron of the max-pooling layer, shown in Figure 15.
FIGURE 15
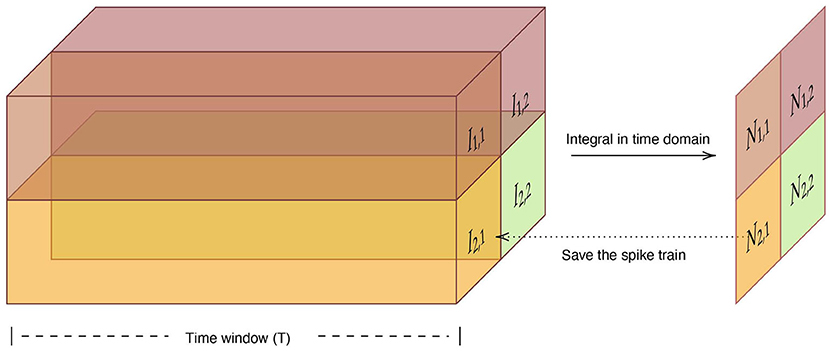
Figure 15. The structure and information flow of spiking max-pooling layer.
5.4.3. Datasets and implementationWe set a group of experiments based on MNIST and CIFAR-10 datasets. We convert the supervised-trained weights of CNN into an SNN with the same structure and verify the gap between CNN and SNN in the test dataset.
A ConvNet with two convolution layers (Conv.12 5 × 5 - Conv.64 5 × 5), ReLU activations, and two max-pooling layers are trained on the MNIST dataset. The structure of networks is the same as architectures used by authors in Diehl et al. (2015) and shown in Table 5. In the experiment, we select the best-performing model after the verification accuracy has converged, and directly transform it into LIF-SNN. The LIF-SNN uses frequency coding and sets the parameters of each Linear LIF neuron to be equivalent to the ReLU-AN model.
TABLE 5

Table 5. CNN baseline model for MNIST dataset (with softmax output layer).
Verified by experiment, a shallow convolutional net can achieve high performance on the MNIST dataset. A more complex model should be performed to evaluate the equivalence in a deep structure. We use the AlexNet architecture (Krizhevsky et al., 2012) and VGG-16 (Simonyan and Zisserman, 2015) architecture for the CIFAR-10 dataset. In the simulation, we did not use image pre-processing and augmentation techniques and kept consistent with the AlexNet and VGG-16 model architecture. And all the CNNs in the experiment did not use bias. Because the conversion between bias and membrane conductance needs to limit the weight of the neural network, see Section 4.3 for details. The equivalence between neuron models with bias has been proved in the previous chapter through formulas and simulation experiments, see Section 5.2.
By verifying the similarity between CNN and LIF-SNN, we proved the equivalence of the Linear LIF model with the ReLU-AN model. However, we are not aiming at the highest performance of CNNs under supervised learning, so we don't use regular operations like image pre-processing, data augmentation, batch normalization, and dropout.
5.4.4. Experiments for ConvNet architecturesThe network used for the MNIST dataset is trained for 100 epochs until the validation accuracy stabilizes, and achieves 98.5% test accuracy. For LIF-SNN, we set the time window of simulation as 2s and normalized values of the MNIST images to values between 0 and 10. Based on the algorithm of information coding, spike trains between 0 and 10 Hz were generated and presented to the LIF-SNN as inputs. The input trains are processed by convolutional layers and max-pooling layers, and finally are vectorized and fully connected to ten Linear LIF node as the output. We counted the number of spikes in output spike trains, used the node with the highest frequency as the output of LIF-SNN.
Figure 16 shows the comparison between ReLU-based ConvNet and LIF-SNN, and the confusion matrix. We use the number of spikes to represent the spike trains. The comparisons of feature maps between ReLU-based ConvNet and LIF-SNN are shown in the left figure in Figure 16. By comparing the upper and lower figures, we can obtain that the original images have undergone convolutional and pooling operations, which are the same as the information represented by spiking convolutional and spiking max-pooling operations after frequency encoding. Ideally, that is, the encoding time is infinite and the sampling frequency is infinite, the image in the bottom row should be the same as the image in the top row. The right figure in Figure 16 shows the confusion matrix of MNIST data, the actual labels are the outputs of CNN, and the predicted labels are the outputs converted LIF-SNN. We selected 2,000 sets of images from the test dataset for testing. Compared with the output of CNN, the accuracy of LIF-SNN reached 100%. Under the structure of the convolutional and pooling layers, the two neuron models can also maintain high behavioral equivalence. The experiments also proved the equivalence of the ReLU-AN model and the CLIF model in the convolutional neural network composed of convolutional and max-pooling layers.
FIGURE 16

Figure 16. Performance of SNN with ConvNet architecture. The left figure shows comparison of feature maps between ReLU-based ConvNet and LIF-SNN. The top figure shows the test image, feature map of convolutional layer, and feature map of max-pooling layer. The images in the bottom rows show the spikes count of output of LIF-SNN. The right figure shows the confusion matrix of LIF-SNN relative to the output of CNN.
5.4.5. Experiments for deep convolutional architecturesIn this subsection, a more thorough evaluation using more complex models (e.g., VGG, AlexNet) and datasets (e.g., CIFAR that includes color images) are given. Since the main contribution of this work is establishing the mapping relationship and not in training a SOTA model. In the training of AlexNet and VGG-16 based on the CIFAR-10 dataset, we did not use data augmentation and any hyper-parameter optimization. Although the classification accuracy based on the existing training mechanism is not the best, it is already competitive.
The AlexNet architectures network with five convolutional layers, ReLU activation, 2 × 2 max-pooling layers after the 1st, 2nd, and 5th convolutional layer, followed by three fully connected layers was trained on the CIFAR-10 dataset. The AlexNet network is created based on PyTorch and trained on 2 GPUs with a batchsize of 128 for 200 epochs. Classification Cross-Entropy loss and SGD with momentum 0.9 and learning rate 0.001 are used for the loss function and optimizer. We selected the best-performance model and convert the weights to the LIF-SNN with same structure. The best validation accuracies (all the test data) of AlexNet for the CIFAR-10 dataset we achieved were about 80.23%. The simulation process is the same as the simulation of the MNIST dataset. Figure 17 shows the comparison of the feature map and the confusion matrix. Based on the equivalence of Linear LIF model and ReLU-AN model, the outputs of LIF-SNN are infinitely close to the outputs of CNN. Besides, in order to quantitatively analyze the equivalence of LIF-SNN and CNN after weight conversion, we compared the classification accuracy of the two models and drew a confusion matrix. We verified all the test samples and used the output of CNN as the label. LIF-SNN achieved 99.46% accuracy on the CIFAR-10 dataset.
FIGURE 17
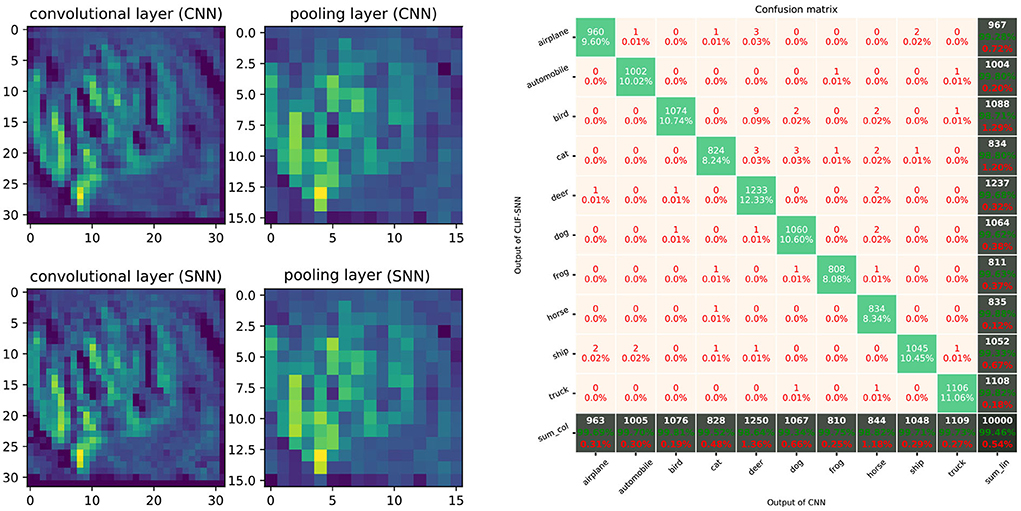
Figure 17. Performance of SNN with AlexNet architecture. The left part of figure shows the comparison of feature maps of convolutional layers and max-pooling layer between ReLU-based CNN and LIF-SNN with same input and connection weights. The right part of figure shows the confusion matrix for CIFAR-10 classification.
The experiment of the VGG-16 structure network is based on the proposal outlined by the authors in Sengupta et al. (2019). Sengupta made effort to generate an SNN with deep architecture and applied it to the VGG-16 network. Similarly, we trained a VGG-16 network based on the CIFAR-10 dataset. The best validation accuracy we achieved is about 88.58%. We only replace the ReLU-AN model with the Linear LIF model. For 800 images of the test dataset, LIF-SNN obtained a test accuracy rate of 99.88%, and the accuracy rate is calculated in the same way as Section 5.3.2. Besides, with the Spike-Norm proposed by Sengupta et al. (2019), the algorithm allows conversion of nearly arbitrary CNN architectures. The way to combine it with parameter mapping needs to be explored to minimize the accuracy loss in ANN-SNN conversion.
Table 6 summarizes the performance of converted LIF-SNN on MNIST and CIFAR-10 datasets. We list the results of some ANN-to-SNN works and compare them based on the error increment between CNN and SNN as an indicator. Error increment refers to the gap between the classification accuracies of ANN and SNN. At the same time, we also give the network structure and parameters for reference in Table 6. The transformation based on model equivalence achieved the best performance. For the shallow network, we can achieve error-free transformation, and for the deep network, we can minimize the error to 0.08%.
TABLE 6
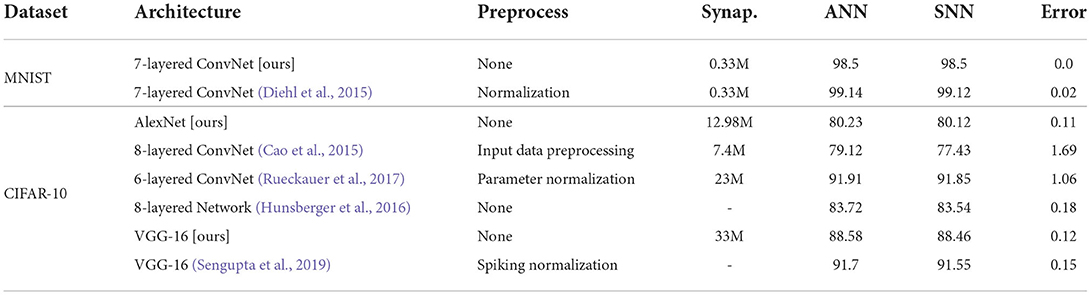
Table 6. Classification error rate on MNIST and CIFAR-10 dataset.
Through the simulation of neural networks with different structures, including shallow and deep networks, we proved the equivalence of the Linear LIF model and the ReLU-AN model. And it is verified that the conversion from CNN to SNN can also be completed in convolutional structures, deep networks, and complex data sets.
5.5. Error analysisThere is still a gap between the LIF/SNN and ReLU/DNN. We believe that the main reason for the error is that the ideal simulation conditions are not achieved. Under ideal conditions, we have infinite encoding time and infinite sampling frequency. However, considering the demand for computing power, our simulations are compromised between accuracy and computing power consumption. Besides, the mapping relationship we proposed is established under the condition that multiple inputs with the same frequency. While in more general conditions, there are still errors.
Here we explore the relationship between coding time and error. We define the output of the Linear LIF model as:
where N is the number of action potentials of spike train within the coding time, and T is the coding time. Then we assume that our expected output frequency is f, then:
Then the error between the expected output frequency and the true output frequency is:
|f-f′|=|f-NT|=|f-[f·T⌉T|<1T (21)We explore the L2 norm as the error under the same frequency input condition. Figure 18 shows the relationship between simulation error and the theoretical error of LIF-AN. We can see that the actual error is consistent with the theoretical error trend, and we can reduce the error by increasing the encoding time. When the coding time is 10s, LIF-SNN achieves an error of less than 1% in the moto/face and MNIST data sets.
FIGURE 18
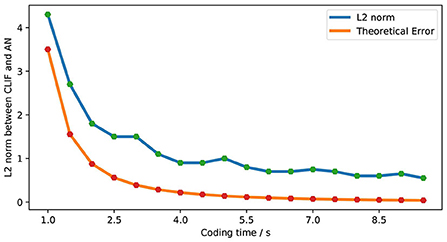
Figure 18. Comparison of theoretical error and actual error.
6. Conclusion and discussion 6.1. Brief summaryDespite the great successes of DNN in many practical applications, there are still shortcomings to be overcome. One way to overcome them is to look for inspiration from neuroscience, where SNNs have been proposed as a biologically more plausible alternative.
This paper aims to find an equivalence between LIF/SNN and ReLU/DNN. Based on a dynamic analysis of the Linear LIF model, a parameter mapping between the biological neuron model and the artificial neuron model was established. We analyzed the equivalence of the two models from the aspects of weight, bias, and slop of activation function, and verified it both theoretically and experimentally, from a single neuron simulation to a neural network simulation. It shows that such an equivalence can be established, both the structural equivalence and behavioral equivalence, and the Linear LIF model can complete the information integration and the information processing of the linear rectification.
This mapping is helpful for the combination of an SNN with an artificial neural network and increasing the biological interpretability of an artificial neural network. It is the first step toward answering the question of how to design more causal neuron models for future neural networks. Many scholars believe that interpretability is the key to a new artificial intelligence revolution.
At the same time, the equivalence relationship is the bridge between machine intelligence and brain intelligence. Exploring new neuron models is still of great importance in areas such as unsupervised learning. As brain scientists and cognitive neuroscientists unravel the mysteries of the brain, the field of machine learning will surely benefit from it. Modern deep learning takes its inspiration from many areas, and it makes sense to understand the structure of the brain and how it works at an algorithmic level.
6.2. Future opportunitiesThe architecture of SNN is still limited to the structure of DNN. Compared with DNN, SNN only has the synaptic connection weights which can be trained, while the weights, bias and activation function (dynamic ReLU, Microsoft Chen et al., 2020) can be trained in DNN. Therefore, we expect Linear LIF model and the parameter mapping relationship can bring innovation to SNN fromthose aspects.
6.2.1. A new way to convert ANN to SNNWith the new approach of converting pre-trained ANN to SNN, we will have a better expression of bias in SNN. Most conversion methods restrict the structure of ANN and directly map the weight. However, bias is also an important parameter in the deep learning network, and we can convert bias into membrane conductance gl based on parameter mapping relationship. In this way, SNN and ANN can maintain high consistency and improve the effect of some tasks. Especially in the convolutional neural network, the connectable region of neurons is small, which is more conducive to the conversion of bias into the parameters in the Linear LIF model.
6.2.2. Parameters training of linear LIF modelAll the parameters of LIF model can be trained or transformed, which is the fundamental difference from other SNN. Based on the parameters mapping relationship, we can map the trained parameters of DNN to the biological parameters of LIF model, to ensure that each node in SNN has its own unique dynamic properties. At the same time, we know the meaning of each parameter, and we can also carry out the direct training of parameters. In biology, it is also worth investigating whether other parameters of neurons, besides weights, will change.
6.2.3. Dynamic activation functionAs the number of layers in the network increases, the number of spikes decreases. We generally adjust the spiking threshold to solve this problem. But we know that the shape of the action potential is essentially fixed, and the spiking threshold of neurons does not change. The membrane capacitance represents the ability to store ions, that is, the opening and closing of ion channels. So, when the number of spikes is low, we can reduce the membrane capacitance and increase the membrane capacitance instead. In parameter mapping, it is similar to dynamic ReLU.
Data availability statementThe original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author.
Author contributionsFX conceived the original idea. SL and FX conducted the theoretical derivation and algorithmic development, contributed to the development of the concepts, the analysis of the data, and the writing of the manuscript. Both authors contributed to the article and approved the submitted version.
FundingThis work has been supported by National Natural Science Foundation of China (Grant No. 61991422 to FX).
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary materialThe Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2022.857513/full#supplementary-material
ReferencesBear, M. F., Connors, B. W., and Paradiso, M. A. (2007). Neuroscience - Exploring the Brain. 3rd Edn. Baltimore, MD: Lippincott Williams & Wilkins.
Burkitt, A. N. (2006). A review of the integrate-and-fire neuron model: Ii. inhomogeneous synaptic input and network properties. Biol. Cybern. 95, 97–112. doi: 10.1007/s00422-006-0082-8
PubMed Abstract | CrossRef Full Text | Google Scholar
Cao, J., Anwer, R. M., Cholakkal, H., Khan, F. S., Pang, Y., and Shao, L. (2020). “Sipmask: spatial information preservation for fast image and video instance segmentation,” in Computer Vision-ECCV 2020. ECCV 2020. Lecture Notes in Computer Science, Vol. 12359, eds A. Vedaldi, H. Bischof, T. Brox, and J. M. Frahm (Cham: Springer).
Cao, Y., Chen, Y., and Khosla, D. (2015). Spiking deep convolutional neural networks for energy-efficient object recognition. Int. J. Comput. Vis. 113, 54–66. doi: 10.1007/s11263-014-0788-3
CrossRef Full Text | Google Scholar
Chen, Y., Dai, X., Liu, M., Chen, D., Yuan, L., and Liu, Z. (2020). “Dynamic relu,” in 16th European Conference Computer Vision (ECCV 2020) (Glasgow: Springer), 351–367. Available online at: https://www.microsoft.com/en-us/research/publication/dynamic-relu/
Choromanska, A., Henaff, M., Mathieu, M., Arous, G. B., and Lecun, Y. (2014). The loss surface of multilayer networks. Eprint Arxiv, 192–204. doi: 10.48550/arXiv.1412.0233
CrossRef Full Text | Google Scholar
Denham, M. J. (2001). “The dynamics of learning and memory: lessons from neuroscience,” in Emergent Neural Computational Architectures Based on Neuroscience: Towards Neuroscience-Inspired Computing, ed S. Wermter (Berlin; Heidelberg: Springer), 333–347.
PubMed Abstract | Google Scholar
Diehl, P. U., Neil, D., Binas, J., Cook, M., Liu, S.-C., and Pfeiffer, M. (2015). “Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing,” in 2015 International Joint Conference on Neural Networks (IJCNN) (Killarney), 1–8.
Diehl, P. U., Zarrella, G., Cassidy, A., Pedroni, B. U., and Neftci, E. (2016). “Conversion of artificial recurrent neural networks to spiking neural networks for low-power neuromorphic hardware,” in 2016 IEEE International Conference on Rebooting Computing (ICRC) (San Diego, CA: IEEE), 1–8.
Falez, P., Tirilly, P., Bilasco, I. M., Devienne, P., and Boulet, P. (2019). Unsupervised visual feature learning with spike-timing-dependent plasticity: how far are we from traditional feature learning approaches? Pattern Recognit. 93, 418–429. doi: 10.1016/j.patcog.2019.04.016
CrossRef Full Text | Google Scholar
Gerstner, W., and Kistler, W. M. (2002). Spiking Neuron Models: Single Neurons, Populations. Plasticity. Cambridge: Cambridge University Press.
Ghahramani, Z. (2003). “Unsupervised learning,” in Advanced Lectures on Machine Learning: ML Summer Schools 2003, Canberra, Australia, February 2–14, 2003, Tübingen, Germany, August 4–16, 2003, Revised Lectures, eds O. Bousquet, U. von Luxburg, and G. Rätsch (Berlin; Heidelberg Springer), 72–112.
Glorot, X., Bordes, A., and Bengio, Y. (2011). “Deep sparse rectifier neural networks,” in Proceedings of the 14th International Conference on Artificial Intelligence and Statisitics (AISTATS) 2011, Vol. 15 (Fort Lauderdale, FL: PMLR), 315–323.
Hahnloser, R. H. R., Seung, H. S., and Slotine, J. J. (2003). Permitted and forbidden sets in symmetric threshold-linear networks. Neural Comput. 15, 621–638. doi: 10.1162/089976603321192103
PubMed Abstract | CrossRef Full Text | Google Scholar
Han, B., Srinivasan, G., and Roy, K. (2020). “Rmp-snn: residual membrane potential neuron for enabling deeper high-accuracy and low-latency spiking neural network,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Seattle, WA: IEEE).
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Las Vegas, NV: IEEE), 770–778.
PubMed Abstract | Google Scholar
Hebb, D. O. (1949). The Organization of Behavior: A Neuropsychological Theory. New York, NY: J. Wiley; Chapman & Hall.
Hinton, G., Deng, L., Yu, D., Dahl, G. E., Mohamed, A.-,r., Jaitly, N., et al. (2012). Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Process. Mag. 29, 82–97. doi: 10.1109/MSP.2012.2205597
CrossRef Full Text | Google Scholar
Hodgkin, A. L., and Huxley, A. F. (1952). A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 117, 500–544. doi: 10.1113/jphysiol.1952.sp004764
PubMed Abstract | CrossRef Full Text | Google Scholar
Hunsberger, E., Eliasmith, C., and Eliasmith, C. (2016). Training spiking deep networks for neuromorphic hardware. Salon des Refusés 1, 6566. doi: 10.13140/RG.2.2.10967.06566
CrossRef Full Text | Google Scholar
Illing, B., Gerstner, W., and Brea, J. (2019). Biologically plausible deep learning – but how far can we go with shallow networks? Neural Networks 118, 90–101. doi: 10.1016/j.neunet.2019.06.001
PubMed Abstract | CrossRef Full Text | Google Scholar
Ivakhnenko, A. (1971). Polynomial theory of complex systems. IEEE Trans. Syst. Man Cybern. Syst. 1, 364–378. doi: 10.1109/TSMC.1971.4308320
CrossRef Full Text | Google Scholar
Ivakhnenko, A., and Lapa, V. (1965). Cybernetic Predicting Devices. New York, NY: CCM Information Corporation, 250.
Jarrett, K., Kavukcuoglu, K., Ranzato, M., and LeCun, Y. (2009). “What is the best multi-stage architecture for object recognition?” in 2009 IEEE 12th International Conference on Computer Vision (Kyoto: IEEE), 2146–2153.
Jeong, D. S., Kim, K. M., Kim, S., Choi, B. J., and Hwang, C. (2016). Memristors for energy-efficient new computing paradigms. Adv. Electron. Mater. 2, 1600090. doi: 10.1002/aelm.201600090
CrossRef Full Text | Google Scholar
Jiang, X., Pang, Y., Sun, M., and Li, X. (2018). Cascaded subpatch networks for effective cnns. IEEE Trans. Neural Networks Learn. Syst. 29, 2684–2694. doi: 10.1109/TNNLS.2017.2689098
PubMed Abstract | CrossRef Full Text | Google Scholar
Kheradpisheh, S. R., Ganjtabesh, M., Thorpe, S. J., and Masquelier, T. (2018). Stdp-based spiking deep convolutional neural networks for object recognition. Neural Networks 99, 56–67. doi: 10.1016/j.neunet.2017.12.005
PubMed Abstract | CrossRef Full Text | Google Scholar
Kim, S., Park, S., Na, B., and Yoon, S. (2020). “Spiking-yolo: spiking neural network for energy-efficient object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34, 11270–11277.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems, eds F. Pereira, C. J. Burges, L. Bottou, and K. Q. Weinberger (Lake Tahoe: Curran Associates, Inc), 1097–1105.
Kulkarni, S. R., and Rajendran, B. (2018). Spiking neural networks for handwritten digit recognition–supervised learning and network optimization. Neural Networks 103, 118–127. doi: 10.1016/j.neunet.2018.03.019
PubMed Abstract | CrossRef Full Text | Google Scholar
Lapicque, L. (1907). Recherches quantitatives sur l'excitation electrique des nerfs traitee comme une polarization. Journal de Physiologie et de Pathologie Generalej. 9, 620–635.
Maass, W. (1997). Networks of spiking neurons: the third generation of neural network models. Neural Networks 10, 1659–1671. doi: 10.1016/S0893-6080(97)00011-7
CrossRef Full Text | Google Scholar
Maday, Y., Patera, A. T., and Rønquist, E. M. (1990). An operator-integration-factor splitting method for time-dependent problems: application to incompressible fluid flow. J. Sci. Comput. 5, 263–292. doi: 10.1007/BF01063118
CrossRef Full Text | Google Scholar
Meng, X.-L., Rosenthal, R., and Rubin, D. B. (1992). Comparing correlated correlation coefficients. Psychol. Bull. 111, 172. doi: 10.1037/0033-2909.111.1.172
CrossRef Full Text | Google Scholar
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., et al. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602. doi: 10.48550/arXiv.1312.5602
CrossRef Full Text | Google Scholar
Mozafari, M., Kheradpisheh, S. R., Masquelier, T., Nowzari-Dalini, A., and Ganjtabesh, M. (2018). First-spike-based visual categorization using reward-modulated stdp. IEEE Trans. Neural Networks Learn. Syst. 29, 6178–6190. doi: 10.1109/TNNLS.2018.2826721
PubMed Abstract | CrossRef Full Text | Google Scholar
Nair, V., and Hinton, G. E. (2010). “Rectified linear units improve restricted boltzmann machines,” in Proceedings of the 27th International Conference on Machine Learning (ICML-10) (Madison, WI: Omnipress), 807–814.
Nazari, S., and Faez, K. (2018). Spiking pattern recognition using informative signal of image and unsupervised biologically plausible learning. Neurocomputing 330, 196–211. doi: 10.1016/j.neucom.2018.10.066
CrossRef Full Text | Google Scholar
Rathi, N., Srinivasan, G., Panda, P., and Roy, K. (2020). Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation. International Conference on Learning Representations. Available online at: https://openreview.net/forum?id=B1xSperKvH
Richmond, B. (2009). “Information coding,” in Encyclopedia of Neuroscience, ed L. R. Squire (Oxford: Academic Press), 137–144.
Rueckauer, B., Lungu, I.-A., Hu, Y., Pfeiffer, M., and Liu, S.-C. (2017). Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 11, 682. doi: 10.3389/fnins.2017.00682
PubMed Abstract | CrossRef Full Text | Google Scholar
Sengupta, A., Ye, Y., Wang, R., Liu, C., and Roy, K. (2019). Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 13, 95–95. doi: 10.3389/fnins.2019.00095
PubMed Abstract | CrossRef Full Text | Google Scholar
Simonyan, K., and Zisserman, A. (2015). “Very deep convolutional networks for large-scale image recognition,” in ICLR 2015: International Conference on Learning Representations 2015 (San Diego, CA).
Tan, C., Šarlija, M., and Kasabov, N. (2020). Spiking neural networks: background, recent development and the neucube architecture. Neural Process. Lett. 52, 1675–1701. doi: 10.1007/s11063-020-10322-8
CrossRef Full Text | Google Scholar
Tavanaei, A., Ghodrati, M., Kheradpisheh, S. R., Masquelier, T., and Maida, A. (2019). Deep learning in spiking neural networks. Neur. Netw. 111, 47–63. doi: 10.1016/j.neunet.2018.12.002
PubMed Abstract | CrossRef Full Text | Google Scholar
Tavanaei, A., and Maida, A. S. (2016). Bio-inspired spiking convolutional neural network using layer-wise sparse coding and stdp learning. arXiv preprint arXiv:1611.03000.
Tuckwell, H. (1988). Introduction to Theoretical Neurobiology, Volume 2: Nonlinear and Stochastic Theories. Cambridge Studies in Mathematical Biology; Cambridge University Press.
Wang, X., Lin, X., and Dang, X. (2020). Supervised learning in spiking neural networks: a review of algorithms and evaluations. Neural Networks 125, 258–280. doi: 10.1016/j.neunet.2020.02.011
PubMed Abstract | CrossRef Full Text | Google Scholar
Zhao, Z., Zheng, P., Xu, S., and Wu, X. (2019). Object detection with deep learning: a review. IEEE Trans. Neural Netwo. Learn. Syst. 30, 3212–3232. doi: 10.1109/TNNLS.2018.2876865
留言 (0)