
記住我
Music, as a mode of emotional expression, profoundly permeates various aspects of human culture and life (Hallam and MacDonald, 2013; Ma, 2022). Its influence extends beyond the auditory senses, touching on emotional and psychological dimensions as well (Darki et al., 2022; Deshmukh and Gupta, 2022). For instance, music composed in major keys tends to be bright and cheerful, evoking a sense of openness and positivity in listeners. Conversely, compositions in minor keys generally appear darker and heavier, eliciting feelings of sadness and melancholy (Suzuki et al., 2008). These emotional expressions are intricately linked to the tonality and timbre of music. Within a musical piece, altering the key and instruments can provide listeners with varying emotional experiences. Moreover, factors such as rhythm and melody also significantly impact the emotional tone of music (Schellenberg et al., 2000). The emotional response music elicits is a result of brain processing, making the study of the relationship between music and the human brain crucial for understanding music’s effects on humans (Putkinen et al., 2021). Music therapy, as a method utilizing the unique properties of music to promote psychological and physiological health, has been widely applied in various medical and rehabilitation settings.
Humans primarily perceive music through the auditory system. Therefore, when the auditory system is functioning normally, listening to music typically induces brain activity (Chan and Han, 2022; Fasano et al., 2023; Fischer et al., 2021). Different types of music can affect listeners’ emotional experiences by triggering cognitive processes like memory and association (Bedoya et al., 2021; Cardona et al., 2020; Talamini et al., 2022). Specific pieces may evoke recollections of particular moments or emotional experiences, leading to corresponding emotional reactions (Baird et al., 2018). Additionally, music can create various emotional atmospheres, spurring listeners’ imagination and immersing them into the musical experience, further deepening their emotional engagement. The processing of musical information in the brain involves multiple areas (Pando-Naude et al., 2021; Samiee et al., 2022; Williams et al., 2022). Damage to the right temporal lobe can impair musical abilities, confirming the involvement of the brain’s right hemisphere in music processing (Särkämö et al., 2010; Sihvonen et al., 2016; Wilson and Saling, 2008). However, damage to the left hemisphere can also cause difficulties in music recognition, indicating the necessity of both hemispheres in understanding music (Schuppert, 2000). The brain’s limbic system plays a vital role in processing musical emotions; the amygdala connects different brain regions to manage music processing, and the anterior cingulate cortex regulates emotions.
The brain processes music and language through some similar mechanisms. For example, the rhythm of music and the grammatical structure of language both stimulate the Broca’s area in the left hemisphere, a region closely associated with language processing (Meister et al., 2004; Özdemir et al., 2006). This suggests an overlap in the neural processing of these two forms of information. Research has shown that musical education can enhance children’s language skills, including vocabulary, grammar comprehension, and verbal expression (Caracci et al., 2022; Lee and Ho, 2023). Musical activities, such as singing and rhythm exercises, can improve motivation and effectiveness in language learning (Good et al., 2015). Therefore, music can enhance the language abilities of groups with language impairments. In music therapy, activities like singing and rhythm exercises can boost the language comprehension and vocabulary usage of children with autism (Chanyanit et al., 2019; Christensen, 2021). The repetitive patterns in music aid in reinforcing memory and language learning, making it easier for children to acquire new vocabulary and language structures (Falk et al., 2014). On the other hand, in receptive music therapy modalities such as Semi directive music imagination and song discussions, therapists facilitate patients’ acquisition of positive emotional experiences through verbal interactions (Gao, 2011).
Thus, there exists a close connection between music and language, and brainwave signals serve as a method for studying brain activity, which can be applied to examine the relationship between musical and linguistic expression at the neural level. In music therapy, especially the receptive music therapy, therapists need to engage in dialog with patients and monitor their emotional changes. Electroencephalography (EEG), with its high temporal resolution, captures the brain activity during music and language processing. It is beneficial for music therapists to continuously monitor changes in patients’ emotions. With the advancement of machine learning, this technology is increasingly used to analyze and model brainwave signals. Besedová et al. achieved accuracies of 82.9 and 82.4%, respectively, by comparing brainwave signals from musically trained individuals and those without musical training while listening to music and foreign languages, using neural networks for classification (Besedová et al., 2019). Bo et al. employed SVM algorithms to analyze brainwave signals from listening to music of different emotions, achieving an accuracy of 66.8% (Bo et al., 2019). The establishment of EEG classification models can be applied in various fields such as the treatment of neurological diseases and brain-computer interfaces. For instance, by analyzing the EEG signals of patients with depression while they listen to music with different emotional tones, doctors can more accurately assess the patients’ emotional states.
To investigate the relationship between music and language, this study recruited 120 subjects and collected their EEG data under two conditions: during quiet and speaking, while exposed to different emotional music stimuli. Regarding EEG acquisition equipment, we developed a customized EEG cap based on OpenBCI to enhance the comfort of the data collection process. For EEG signal analysis, we employed Analysis of Variance (ANOVA) and independent samples t-tests to examine the differences in brain activity under different conditions. Additionally, we utilized neural networks and other machine learning algorithms to construct classification models for EEG signals under various emotional music stimuli, comparing the effects of different algorithms and EEG features on classification performance.
Section 2 of this paper introduces the EEG acquisition equipment developed in this study, the data collection process, and the data processing approach. Section 3 presents the results of EEG signal analysis based on ANOVA and independent samples t-tests, as well as a comparison of the performance of different classification models. Section 4 discusses of the experimental results. The conclusion is provided in section 5.
2 Materials and methods 2.1 EEG signal acquisition deviceThis study developed a portable EEG signal acquisition device based on the OpenBCI EEG hardware platform, enabling the acquisition of EEG signals from five frontal positions: F7, Fp1, Fz, Fp2, and F8. The OpenBCI EEG hardware platform, an open-source EEG signal acquisition system, offers low cost and high customizability, supporting up to 16-channel EEG signal acquisition. Therefore, it is suitable for modifications and secondary development.
Instead of using an EEG cap made from PLA material, this study employed a cap made of cotton fabric, as shown in Figure 1 Compared to the PLA material EEG cap from OpenBCI (Figure 1A), the cotton fabric cap (Figure 1B) provides better flexibility, significantly enhancing comfort during prolonged wear. Additionally, the cotton cap ensures a closer fit between the electrodes and the skin, accommodating different head shapes and sizes, thereby improving the quality and stability of signal acquisition.

Figure 1. EEG cap. (A) PLC materials of cap from OpenBCI. (B) Cotton fabric cap this study used. (C) The complete EEG signal acquisition device.
For the power module design, this study selected a 2000mAh, 3.7 V lithium battery and incorporated a Type-C interface-based lithium battery charging module. Considering the power consumption and operational efficiency of the EEG signal acquisition device, this battery model was chosen for its ability to provide stable power over an extended period. The charging module is equipped with four LED indicators to display the battery status: when all four lights are on, the battery is fully charged; when only one light is on and flashing, the battery is low and needs recharging. This design effectively provides users with information about the device’s battery status. In terms of safety, the charging module offers overcharge protection, overvoltage protection, and short-circuit protection, thus preventing overcharging, over-discharging, and short-circuit hazards. Additionally, the charging module can boost the voltage from 3.7 V to 5 V, meeting the power requirements of the hardware device. The complete EEG signal acquisition device is shown in Figure 1C.
2.2 Design of EEG acquisition processTo capture the changes in EEG activity under different emotional musical environments, when the subjects are in quiet and speaking states, we designed a comprehensive EEG data acquisition process. This process facilitates the acquisition of EEG changes under musical stimuli conveying emotions of fear, sadness, anger, calmness, happiness, and tension, with a particular focus on EEG signals during speaking states. This preparation serves as preliminary groundwork for EEG analysis in subsequent language interventions. The EEG electrodes are placed at the frontal locations F7, Fp1, Fz, Fp2, and F8. The preparation phase prior to data acquisition involves the following steps:
(1) Subjects fill out basic information, including age, gender, and experiment number, which helps differentiate subjects in subsequent data analysis.
(2) With the assistance of experiment personnel, subjects wear the EEG cap, ensuring that the electrodes are in the correct positions and that the acquisition software correctly receives data from the five channels.
(3) Before the actual data acquisition, subjects are asked to close their eyes and listen to a 90-s piece of instrumental music. This music aims to stabilize the emotional state of the subjects, equalizing the mood among all subjects as much as possible to minimize its impact on data acquisition.
After the preparation phase, subjects open their eyes and undergo the formal EEG data acquisition process. This process is divided into six stages, each featuring a different emotional music piece. The procedure for each stage, as shown in Figure 2, begins with a prompt played by the acquisition software before the music starts, instructing subjects that they will listen to a piece of music and reminding them to read textual material at the 40-s mark. This reduces the risk of subjects not completing the experiment steps due to unclear objectives, thereby ensuring the quality of the data and the smooth progression of the acquisition process. After the prompt, there is a 3-s period of silence during which no sensory stimulation occurs. At the 40-s mark of the music playback, subjects are required to read the text that appears on the screen, while the music continues to play. After the music ends, there is another 3-s period of silence before moving to the next stage of data acquisition.

Figure 2. The formal acquisition process. Begins with a prompt played by the acquisition software before the music starts, instructing subjects that they will listen to a piece of music and reminding them to read textual material at the 40-s mark. This reduces the risk of subjects not completing the experiment steps due to unclear objectives, thereby ensuring the quality of the data and the smooth progression of the acquisition process. After the prompt, there is a 3-s period of silence during which no sensory stimulation occurs. At the 40-s mark of the music playback, subjects are required to read the text that appears on the screen, while the music continues to play. After the music ends, there is another 3-s period of silence before moving to the next stage of data acquisition.
2.3 EEG data acquisitionIn this study, a total of 120 subjects were recruited, including 38 males and 82 females, all of whom were students aged between 19 and 26 years. The final dataset comprises 720 min of EEG data and 720 min of audio data. The music selected as stimuli comprised classical, pop, and film scores expressing six different emotions. EEG data acquisition took place in a quiet indoor environment, with subjects wearing headphones and an EEG cap throughout to minimize environmental noise disturbances. The acquisition process is as follows:
(1) Experiment personnel assist each subject in wearing the EEG cap and headphones. This ensures good contact between the electrodes and the skin, reducing signal interference. The headphones isolate external noise while playing the selected music.
(2) Experiment personnel operate specialized EEG acquisition software to start the acquisition process. Before starting data acquisition, personnel guide subjects in filling out basic information and adjusting the equipment to ensure the appropriateness and comfort of the EEG cap and headphones.
(3) Subjects begin EEG data acquisition under voice prompts from the software. During this phase, subjects sit quietly, relax, and listen to the music being played. To minimize the interference of physical movements with the EEG signals, subjects are instructed to remain as still as possible. Meanwhile, experiment personnel monitor the entire process to ensure smooth data acquisition.
(4) After hearing the voice prompt that the test has concluded, the entire acquisition process ends. At this point, experiment personnel assist subjects in removing the EEG cap and headphones.
2.4 Data alignment and segmentationThe EEG data collected through the acquisition software are not time-aligned. In the data acquisition for each stimulus, the start time of the data acquisition precedes the start time of the stimulus playback, and the end time of data acquisition is later than the end time of the stimulus playback, with a time difference of approximately 0.3 s. Therefore, recorded data timestamps do not correspond to the stimulus playback times. Data needs to be trimmed to align with the stimulus playback times to prevent out-of-bound data from affecting the analysis. The software records timestamps for each sampling point as well as the start and end timestamps of the stimulus playback. Therefore, time alignment can be based on these timestamps. After alignment, the data are segmented into 5-s slices. Since human emotional changes are dynamic, segmenting the long-duration EEG signals allows for a more detailed analysis of the emotional change process.
2.5 EEG preprocessing workflowCommon EEG frequency bands include delta (δ), theta (θ), alpha (α), beta (β), and gamma (γ), thus, during the preprocessing of EEG data, it is essential to extract EEG waveforms from these five bands and remove waveforms from other frequency bands.
The original EEG signals from five channels had a sampling rate of 1,000 Hz. For EEG research, this sampling rate is excessively high; hence it was downsampled to 256 Hz to reduce the computational load in subsequent analyses. Centering each channel’s EEG signals to have a zero mean value minimizes baseline shifts caused by noise. A notch filter was primarily used to remove the influence of the 50 Hz power line frequency, retaining useful frequency bands. These bands were filtered using Butterworth filters with frequency ranges of 0.5–4, 4–8, 8–14, 14–30, and 30–44 Hz, ultimately yielding five frequency bands of EEG signals for each channel. Figure 3 shows the EEG signals across these five bands for a subject in a sad music setting.
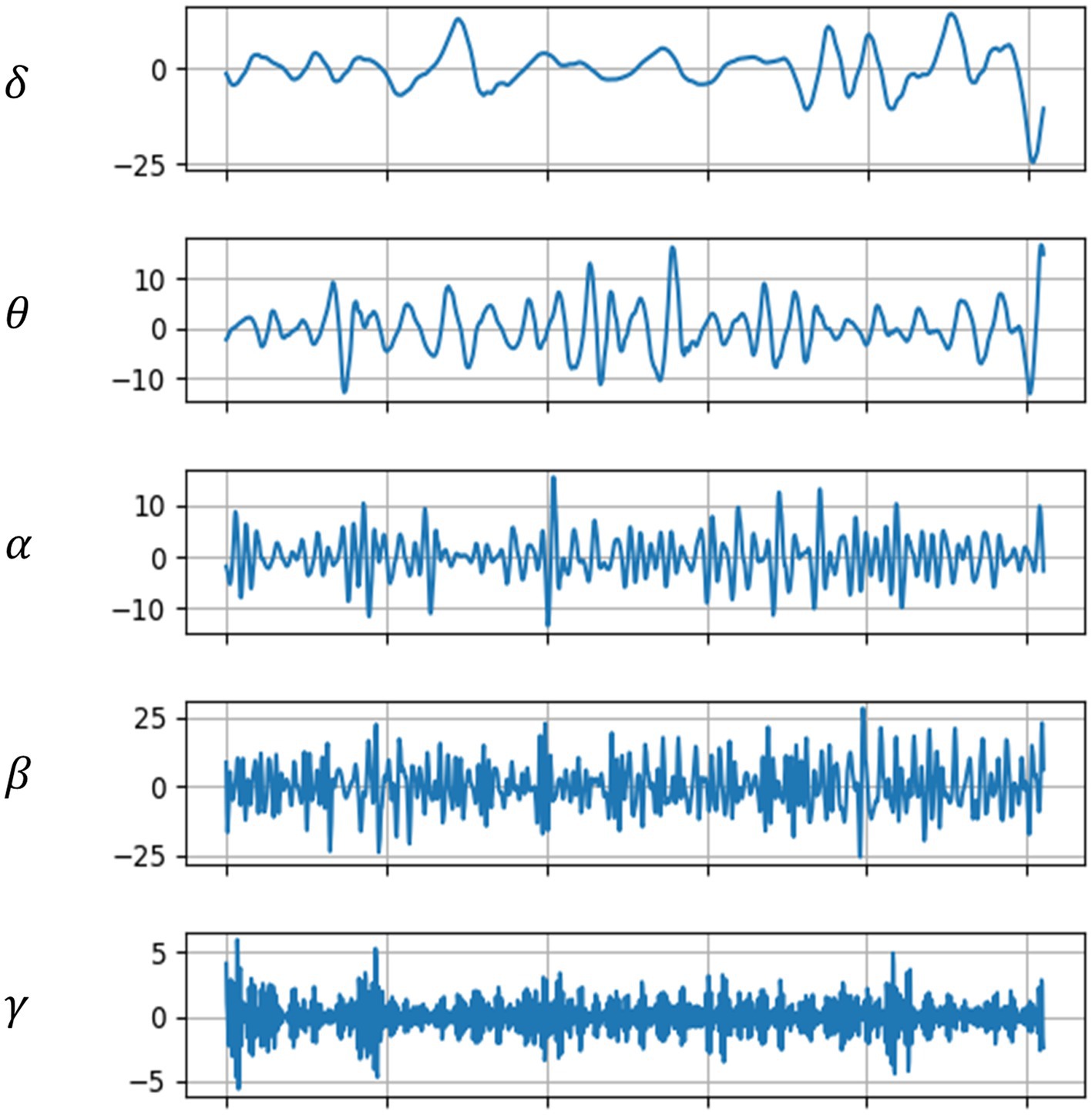
Figure 3. EEG waveforms across five frequency bands.
2.6 Feature extractionFor the extraction of statistical features, the study identified the following characteristics from the collected EEG signals, where X represents the EEG signals:
Mean: The mean is used to measure the average potential of EEG signals over a period, as shown in Equation 1.
EX=1N∑i=1NXi (1)Variance and Standard Deviation: These two features are used to assess the stability and variability of the amplitude of EEG signals, as shown in Equations 2, 3.
VarX=1N−1∑i=1NXi−EX2 (2) DX=1N−1∑i=1NXi−EX2 (3)Skewness: Skewness measures the symmetry of the distribution of EEG signal amplitudes, as indicated in Equation 4.
S=NN−1N−2∑i−1NXi−EXDX3 (4)Kurtosis: Indicates the fluctuation of outliers in EEG signals, as shown in Equation 5.
KX=NN+1N−1N−2N−3∑i−1NXi−EXDX−3N−12N−2N−3 (5)This study also extracted features from the frequency domain, specifically the power spectral density and average power of the EEG signals. The calculation of the power spectrum involves Fourier transforming the EEG signal as shown in Equation 6:
Xk=∑n=0Nxne−2iπknN (6)where N is the total number of EEG signal sampling points.
From Equation 6, the formula for calculating the power spectral density is given by Equation 7:
where |Xk| is the modulus of Xk (i.e., the absolute value of the complex number), representing the amplitude of the frequency component.
In EEG signal processing, Wavelet Transform is widely used for feature extraction, denoising, and signal classification (Rioul and Vetterli, 1991). Since EEG signals are non-stationary with features that vary over time, traditional Fourier Transform may not effectively capture all time-frequency information when processing EEG data. The introduction of Wavelet Transform allows researchers to more precisely analyze the time-frequency characteristics of EEG signals. For instance, in denoising, Wavelet Transform can effectively separate noise from useful signal components (Alyasseri et al., 2020). By selecting appropriate wavelet bases and decomposition levels, EEG signals can be decomposed into sub-bands of different frequencies. Noise typically appears in specific frequency sub-bands, and by thresholding and reconstructing, noise can be effectively removed while retaining key signal information.
In terms of feature extraction, Wavelet Transform can extract time and frequency-related features from EEG signals, which are crucial for the classification and analysis of EEG signals. For example, in the analysis of sleep stages, detection of epileptic seizures, and recognition of brain activity patterns, Wavelet Transform plays a significant role. Additionally, Wavelet Transform is used to study the dynamic properties of brain functional connectivity and neural networks. By analyzing the time-frequency relationships between different brain regions, researchers can gain deeper insights into brain mechanisms and the characteristics of various neurological disorders.
Wavelet Transform extracts both approximate and detailed coefficients from EEG signals, representing the low-frequency and high-frequency characteristics of the signal, respectively. In this study, db4 wavelets are used to process EEG signals. Assuming low-pass filter hn and high-pass filter gn filter the EEG signal x , the formulas for calculating approximate and detailed coefficients are shown in Equation 8 and Equation 9:
a1n=∑khk⋅x2n−k (8) d1n=∑kgk⋅x2n−k (9)In practical applications, hn and gn are pre-computed sequences, and a1 and d1 can be iteratively decomposed further using the Equation 10 and Equation 11:
ai+1n=∑khk⋅ai2n−k (10) di+1n=∑kgk⋅di2n−k (11)where i is the iteration level of wavelet packets. In this study, EEG signals are decomposed using wavelet packets, resulting in wavelet packet coefficients corresponding to five types of waveforms, with the decomposition level set to eight layers.
2.7 Dimensionality reduction using linear discriminant analysisPrior to constructing the classification models, it was necessary to perform dimensionality reduction on the extracted features to minimize redundancy, thereby facilitating the establishment of subsequent classification models. Linear Discriminant Analysis (LDA) was employed for this purpose. LDA is a classical linear learning method aimed at reducing dimensions while preserving the distinction between categories. It is a supervised learning technique for dimensionality reduction that maintains maximum separability among the classes.
The concept of LDA involves projecting data into a lower-dimensional space to maximize the aggregation of data within the same class and maximize the dispersion among different classes. Suppose there is an EEG dataset X , the within-class scatter matrix Sw for X measures the dispersion of data points within a class relative to its class center (mean). The within-class scatter matrix for each class can be defined by Equation 12:
Si=∑x∈Xix−mix−miT (12)where Xi is the sample set of class i and mi is the mean of class i . The total within-class scatter matrix Sw is the sum of the scatter matrices of all classes which can be defined by the Equation 13:
The between-class scatter matrix Sb , which measures the dispersion between the centers (means) of different classes, is calculated using Equation 14:
Sb=∑i=1cNimi−mmi−mT (14)where Ni is the number of samples in class i and m is the mean of all samples. The goal of LDA is to find the optimal projection direction w that maximizes the between-class scatter while minimizing the within-class scatter. This is achieved by maximizing the Fisher criterion function in Equation 15:
Jw=wTSbwwTSww (15)Maximizing Jw allows the projected data points to be as separate as possible between different classes (high between-class scatter) and as close as possible within the same class (low within-class scatter). The LDA algorithm’s effectiveness was demonstrated in Figure 4, where the dimensionality reduction effects of EEG statistical measures, power spectrum, and wavelet coefficients are shown. Figure 4A shows that most data points are not well-separated, clustering together. Thus, LDA’s dimensionality reduction for statistical measures was not very effective. Figure 4B shows a more dispersed data cluster, suggesting a better outcome, while Figure 4C shows that EEG data were roughly divided into six clusters, corresponding to six emotional categories.
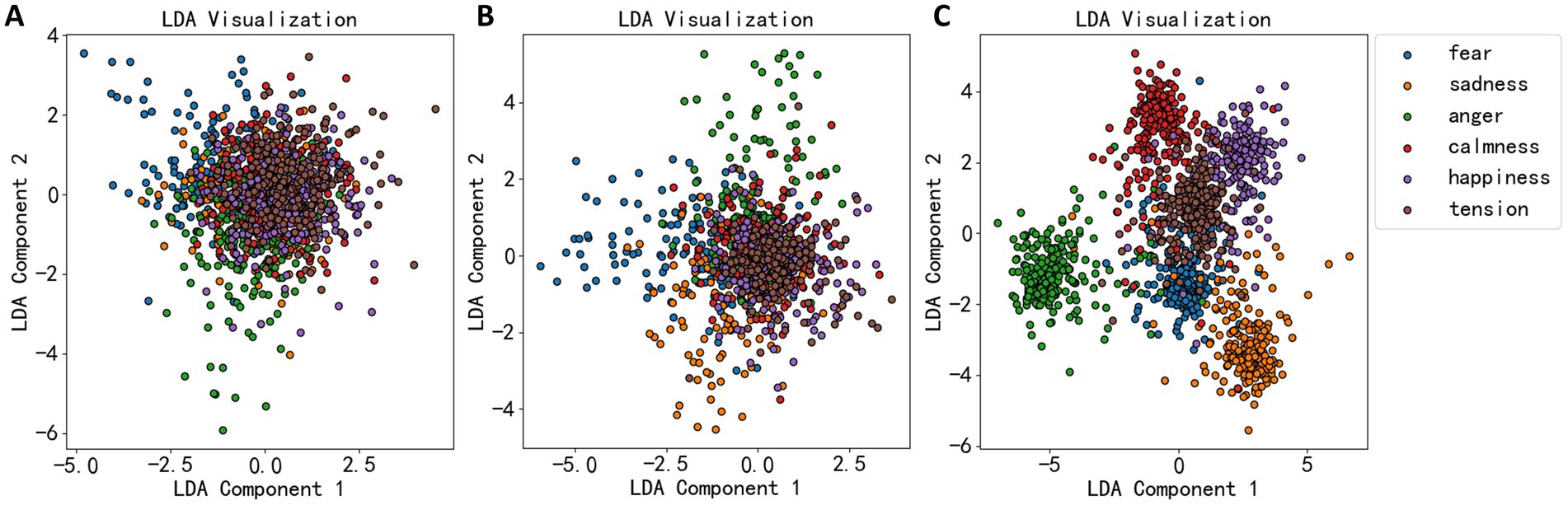
Figure 4. LDA dimension reduction effect diagram of three types of EEG features. (A) The dimension reduction of statistical measures. (B) The dimension reduction of power spectral density. (C) The dimension reduction of wavelet decomposition coefficient.
2.8 Construction of fully connected neural networkThis study primarily establishes a classification model for EEG data using fully connected neural network (FCNN) and compares its performance with other machine learning algorithms. A FCNN, also known as a Multilayer Perceptron (MLP), is a type of deep learning model that is commonly employed to address a variety of machine learning challenges, including both classification and regression tasks. It consists of multiple layers including an input layer, several hidden layers, and an output layer.
The input layer x primarily serves to receive data, with each input feature corresponding to a neuron in the input layer. The hidden layer z acts as the network’s intermediate layer, responsible for learning abstract representations of the data. A typical multilayer perceptron may have multiple hidden layers, each containing several neurons. Every neuron is connected to all neurons in the preceding layer, hence termed “fully connected.”
In the FCNN, each connection is assigned a weight that adjusts the strength of the input signal, and the weights between each pair of layers can be represented by a matrix W . Each neuron also has a bias, represented by a vector b, which helps control the neuron’s activation threshold. Weights and biases are parameters that the network learns to adjust during training, allowing the network to better fit the data.
Activation functions are used at each neuron in the hidden and output layers. These functions introduce non-linearity, enabling the neural network to learn complex function mappings. Common activation functions include the Sigmoid and ReLU (Rectified Linear Unit).
Prediction of data in neural networks is carried out through forward propagation. Starting with the input layer x , the inputs to the hidden layer z are computed using weights W and biases b , as shown in Equation 16, where j represents the j-th element of hidden layer z , and n is the number of elements in hidden layer z .
zj=∑i=1nwjixi+bj (16)Equation 16 can be represented in matrix form to simplify expression:
Assuming the activation function for the hidden layer z is σ , the output a of the hidden layer z is given by:
The computation from hidden layer z to the output layer o also utilizes Equations 17, 18. The neural network depicted in Figure 6 has two outputs, representing two classification categories. During the training of the model, loss functions are used to assess the discrepancy between model predictions and actual values, including mean squared error as shown in Equation 19 and cross-entropy as in Equation 20. Here, ti represents the true values, and yi represents the predicted values by the neural network.
L=1n∑i=1nti−yi2 (19) L=−∑i=0ntilogyi (20)The architecture of the EEG emotion classification network constructed in this study is shown in Figure 5. This neural network consists of 7 layers: one input layer, five hidden layers, and one output layer. The neuron counts for each hidden layer are 512, 1,024, 512, 512, and 256, respectively. The dimension of the input layer is 5, representing the number of dimensions of EEG features reduced by the LDA algorithm. The dimension of the output layer is 6, corresponding to 6 emotions.

Figure 5. EEG emotion classification network structure. The dimension of the input layer is 5, representing the number of dimensions of EEG features reduced by the LDA algorithm. The dimension of the output layer is 6, corresponding to 6 emotions.
3 Results and discussion 3.1 Speech duration analysisThis study initially set a 20-s speech duration, but in practice, subjects did not require the full 20 s to read the text, necessitating an analysis of the actual speech duration. The EEG segments selected corresponded to the duration of the material read aloud by the subjects. The designated speaking interval was between the 40th and 60th seconds of a music piece being played, thus, a dual-threshold method was employed to detect speech endpoints during this interval, and to calculate the speech duration, yielding results as shown in Figure 6. In Figure 6A, the duration of speech primarily ranged between 6 and 14 s. In Figures 6B,C, the starting time of speech mainly occurred between the 2nd and 4th seconds of the recorded speech, and the end times were primarily between the 6th and 14th seconds. Therefore, the EEG segments used in this study were taken from the 40th to 45th seconds and the 45th to 50th seconds post-music stimulus, ensuring that the selected EEG signals corresponded to when the subjects were speaking.
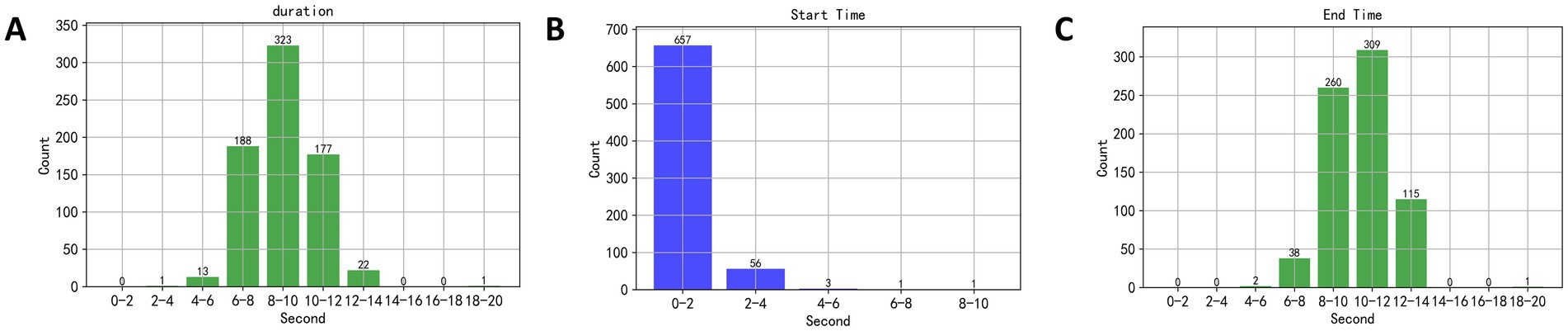
Figure 6. (A) The duration of speech primarily ranged between 6 and 14 s. (B,C) The starting time of speech mainly occurred between the 2nd and 4th seconds of the recorded speech, and the end times were primarily between the 6th and 14th seconds.
3.2 Analysis of significant differencesThis study employed ANOVA and independent samples t-test to analyze the significant differences in EEG signals. These statistical methods were used to examine the differences in EEG signals under the stimulation of different emotional music, as well as the distinctions between the speaking and quiet states. ANOVA was used to assess the overall differences in EEG signals across the different emotional music stimuli, while the independent samples t-test was employed to compare the differences between the groups.
3.2.1 ANOVA of EEGAn ANOVA was performed on the standard deviations of δ, α, β, θ, and γ brainwaves, collected from five channels of 120 subjects while they listened to six types of emotional music. This analysis reflects the overall differences in the data during time intervals between the 30th to 40th seconds and 40th to 50th seconds, corresponding to quiet and speaking conditions, respectively. As indicated in Table 1, significant differences during the speaking condition were primarily observed in the EEG acquisition regions of Fp1, Fz, and Fp2, especially within the α, β, and γ bands. This suggests that these areas and frequency bands are more sensitive to identifying responses to music under different emotional states. The regions F7 and F8 showed no significant statistical differences across most bands, which may imply that these areas are less sensitive to emotional musical stimuli or that the differences are not pronounced enough. The standard deviation is a statistical measure used to assess the variability or dispersion of data, and changes in EEG standard deviations indicate fluctuations in brain electrical activity.
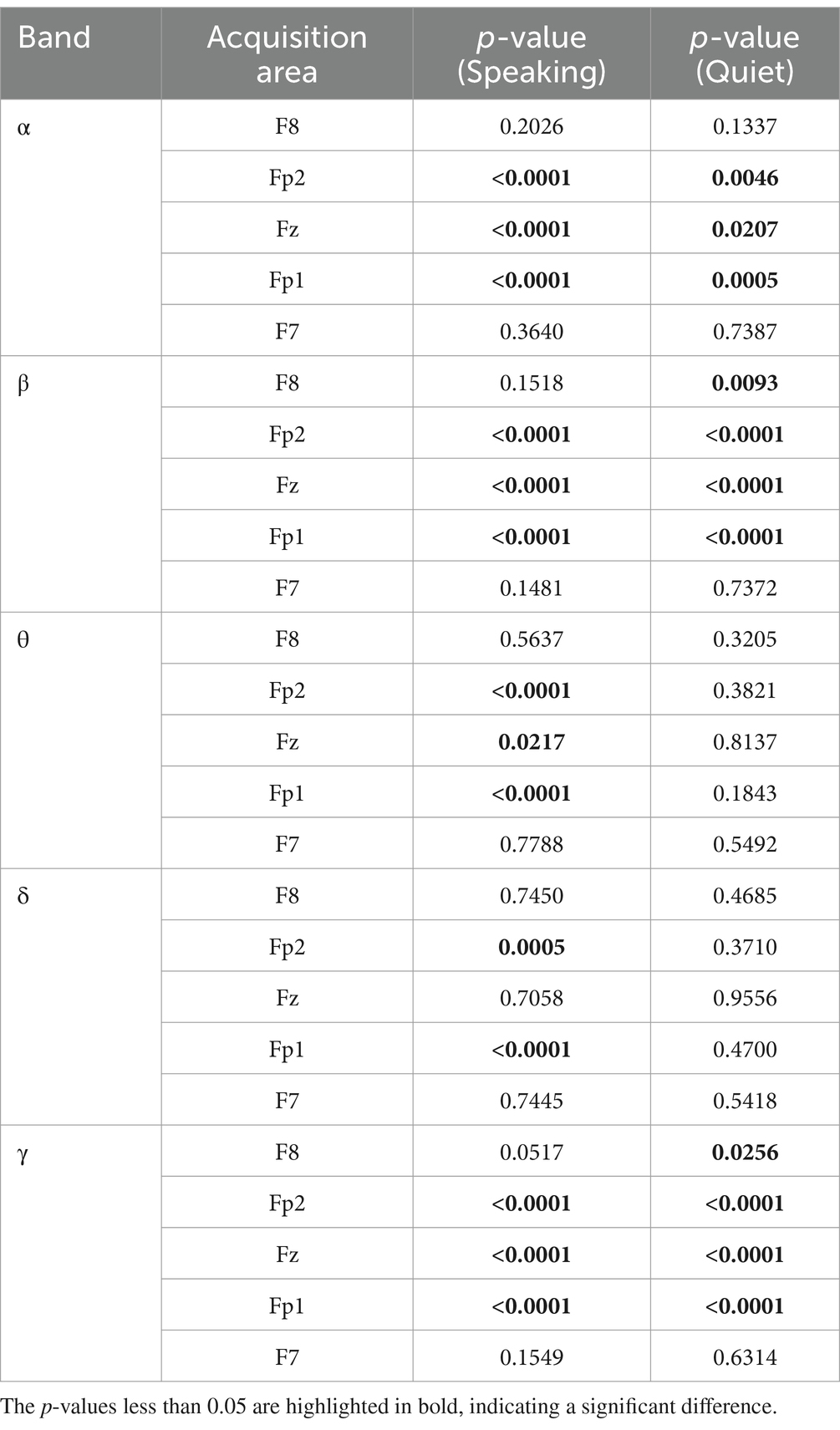
Table 1. ANOVA results of δ, α, β, θ, and γ brainwaves, collected from five channels of 120 subjects.
In contrast, the quiet condition’s ANOVA results differed markedly. Under quiet conditions, the δ and θ bands showed no significant differences in response to the various emotional music stimuli. However, significant differences were observed in the β and γ bands within the F8 acquisition region.
Table 2 presents the results after applying Bonferroni correction to the data from Table 1. In the α frequency band, although no significant differences were observed in the Fp2 and Fz regions during the quiet state, significant changes were still evident in the Fp1, Fp2, and Fz regions during the speaking state. The p-values for these regions during speaking were significantly lower than 0.05, and after Bonferroni correction, they remained below 0.05. This suggests that the impact of emotional music stimuli on α waves is more pronounced during speech, whereas its effect diminishes in the quiet state.
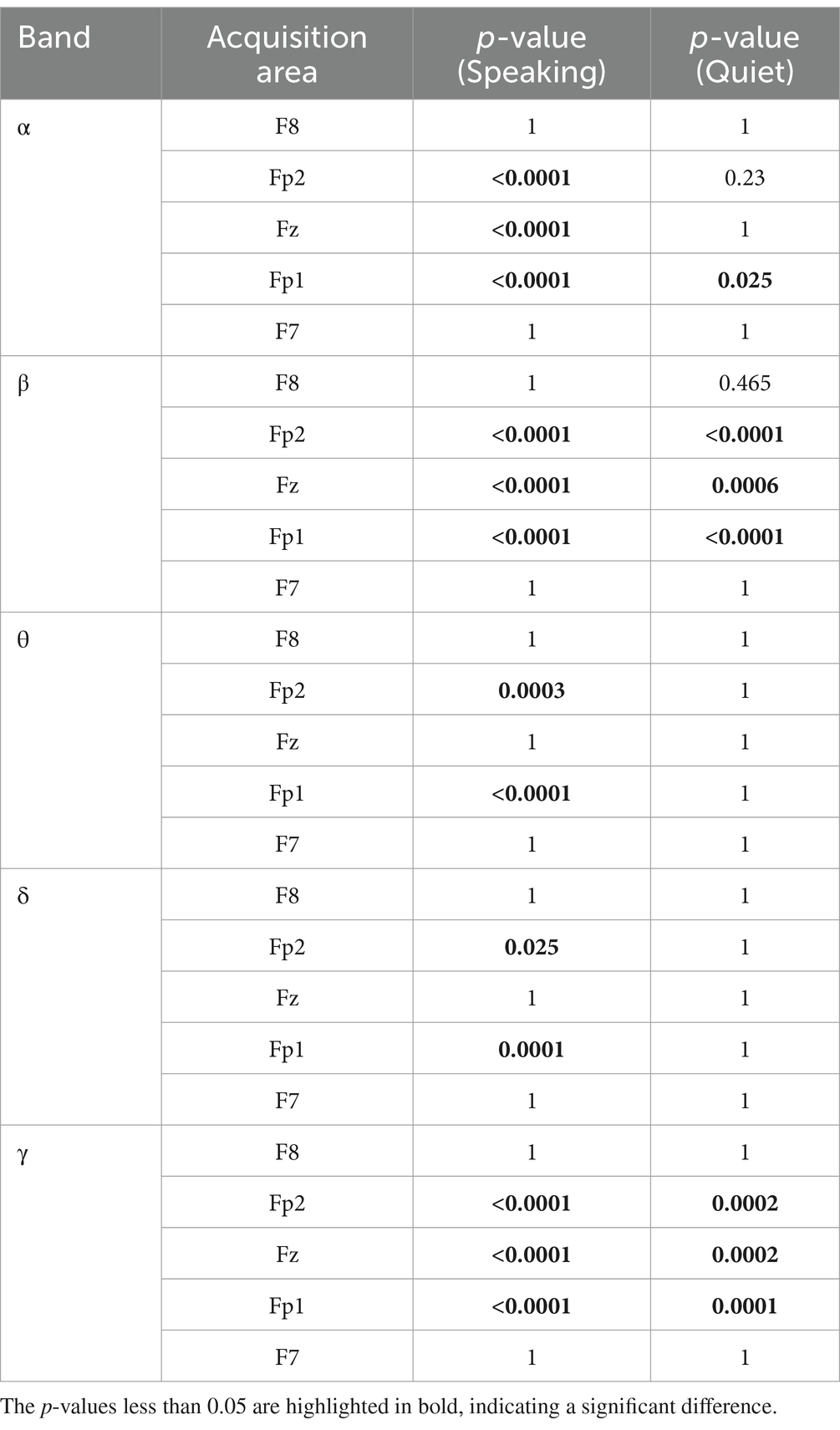
Table 2. Bonferroni corrected of the ANOVA results.
In the β frequency band, similar significant differences were found in the speaking state. The p-values for the Fp1, Fp2, and Fz regions in the speaking state demonstrated significant differences, and after Bonferroni correction, the p-values remained <0.05. In contrast, these regions showed weaker significant differences during the quiet state, with the corrected p-values significantly increased. Notably, the F7 and F8 regions did not exhibit significant differences. This indicates that the influence of emotional music stimuli on β waves is more prominent during speech.
In the θ and δ frequency bands, although significant differences were observed in the Fp2 and Fp1 regions during the speaking state, these effects almost disappeared during the quiet state. In the analysis of θ waves, significant differences were found in the Fp2 and Fp1 regions during speaking, and these differences remained significant after Bonferroni correction, while they were no longer significant in the quiet state, indicating that the effect of speaking on θ waves is more pronounced. Similarly, δ waves showed significant differences in the Fp1 and Fp2 regions during speech, with the influence greatly diminished in the quiet state.
In the γ frequency band, significant differences were observed in both the speaking and quiet states, particularly in the Fp2, Fz, and Fp1 regions. This suggests that the impact of different emotional music stimuli on γ waves in the Fp2, Fz, and Fp1 regions demonstrates significant differences in both speaking and quiet states.
3.2.2 Independent sample t-tests of EEGIndependent sample t-tests were conducted on the standard deviations of δ, α, β, θ, and γ waves collected from five channels of 120 subjects while they spoke under different emotional music environments. The results, depicted in Figure 7A, consist of 25 matrices representing the five channels across five frequency bands. Each matrix contains 36 cells, corresponding to pairwise comparisons between the six emotions: fear, sadness, anger, calmness, happiness, and tension. Black cells indicate significant differences (p-value <0.05), while white cells indicate no significant differences (p-value ≥0.05).

Figure 7. (A) Differences in EEG frequency bands during speaking. (B) Differences in EEG frequency bands under quiet conditions.
From Figure 7A, it is evident that fear significantly differs from the other five emotions across all EEG acquisition areas and frequency bands. Sadness primarily shows significant differences with calmness, happiness, and tension, particularly in the regions of Fp1, Fz, and Fp2. In contrast, calmness, happiness, and tension show no significant differences, suggesting similar EEG activity under these emotional stimuli during the experimental music exposure. Additionally, α waves exhibit greater variability between emotions compared to other EEG waveforms.
The analysis results of EEG differences under different emotional music stimuli in a quiet state are shown in Figure 7B. Fear shows significant differences with calmness, happiness, and tension, mainly in the β and γ frequency bands. Similarly, tension exhibits significant differences in the β and γ frequency bands compared to fear, sadness, and anger. Among them, the δ and θ frequency bands of the EEG do not show significant differences under different emotional music stimuli, which is also reflected in the ANOVA analysis of the EEG signals. The differences in other frequency bands are also less pronounced compared to the differences observed during speaking. This may indicate that EEG activity is more active during speaking than in a quiet state.
3.3 Pattern recognition of EEGPattern recognition in EEG mainly involves classifying EEG signals to construct classification models. Based on the differential analysis of EEG signals in Session 3.2, there are certain differences in brain activity between quiet states and speaking states. By comparing the data in Table 2, significant differences in the θ and δ frequency bands were observed between the Fz1 and Fz2 regions during speech, whereas no significant differences were found between these two channels in the quiet state. In the α band, significant differences were found between the Fz2 and Fz regions during speech, but no significant differences were observed in the quiet state. According to Figure 7, there are more significant differences in EEG under different musical stimuli during speech than in the quiet state, with these differences being more pronounced in the δ, θ, and α bands. Consequently, this study separately modeled EEG classification for quiet and speaking states. Additional
留言 (0)