
記住我
Optical Coherence Tomography Angiography (OCTA) is a non-invasive imaging modality (1) that provides high-resolution, three-dimensional images (2). Unlike fundus photography, which lacks detailed microvascular information, and fluorescein angiography (FA) (3), which may have negative effects on human subjects (4), OCTA imaging offers a safer alternative by providing rich retinal microvascular visualizations (5, 6). Consequently, it has been widely accepted and utilized in clinical practice for retinal vascular imaging (7). However, due to the presence of significant independent noise and artifacts in three-dimensional scan data, it is common practice to project 3D image data onto a two-dimensional en face image for analysis (4). The en face images are categorized into three different complexes: the Inner Vascular Complex (IVC), the Superficial Vascular Complex (SVC), and the Deep Vascular Complex (DVC) (8).
Changes in retinal vascular morphology can be used not only for the clinical diagnosis of ocular diseases (9) but also for analyzing the severity of systemic diseases and evaluating the effectiveness of treatments (10). Previous research has revealed a significant correlation between abnormal OCTA retinal morphology and numerous diseases (4), such as early glaucomatous optic neuropathy (11, 12), diabetic retinopathy (13–15), age-related macular degeneration (16, 17), and Alzheimer's disease (18, 19). Consequently, quantifying retinal vascular biomarkers holds paramount clinical importance (20).
With the success of deep learning algorithms, many methods have been developed to address the vascular extraction in OCTA images (21, 22). However, publicly available datasets primarily focus on the segmentation of large blood vessels. Figure 1 illustrates the SVC scans of the OCTA-500 (23), ROSE-O (4), ROSE-Z (8), and ROSE-H (8) datasets, along with their corresponding manual annotations. In the magnified views, we can observe rich microvascular structures in both datasets. However, these microvascular details have not been completely annotated. Thus, the primary goal of our method is to achieve precise segmentation of finer microvascular structures.
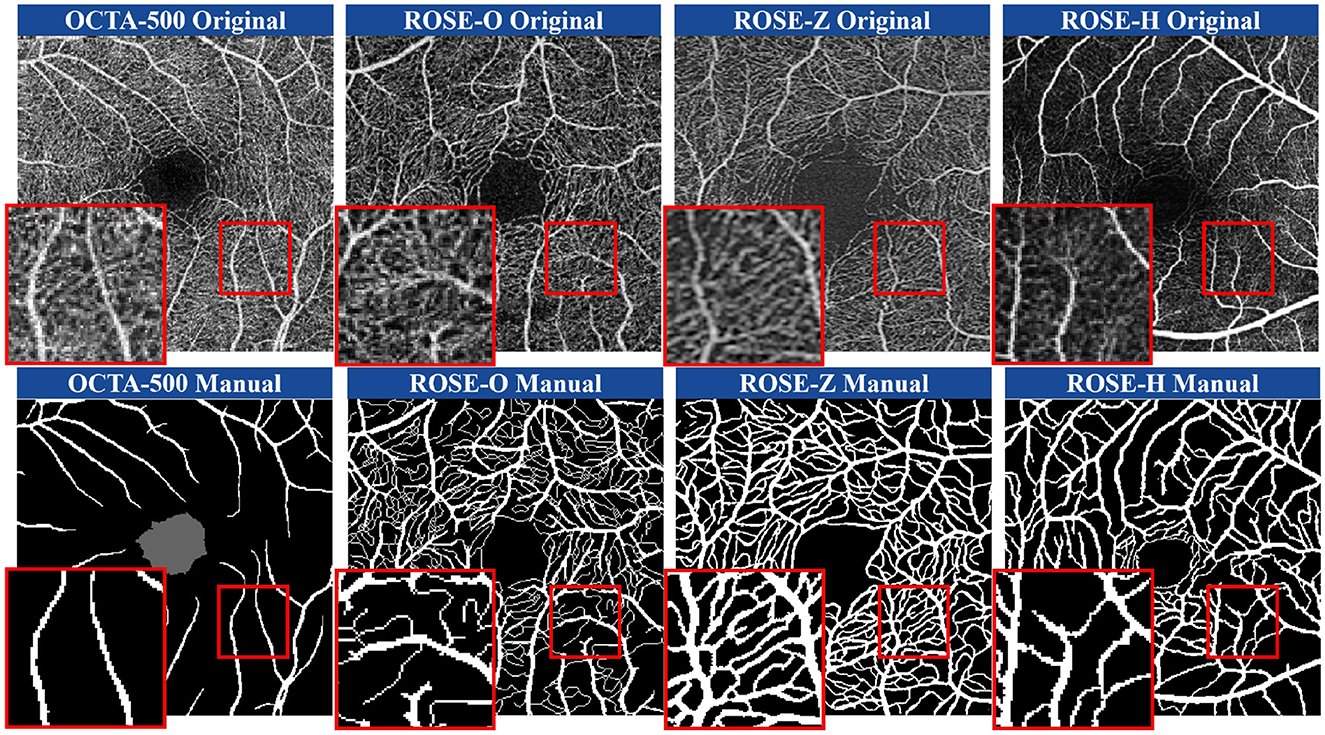
Figure 1. Illustration of SVC layer scans in four different datasets obtained from multiple instruments and the corresponding manual annotations. From left to right: OCTA-500, ROSE-O, ROSE-Z, ROSE-H.
Involuntary eye movements during scanning can cause shifts in the scanning area, leading to linear white noise and artifact streaks (24, 25). Additionally, imaging patterns from different scanning instruments introduce significant noise and artifacts, degrading the quality of retinal vascular imaging (26). As shown in the magnified view in Figure 1, these variations across instruments make it challenging to accurately identify microvascular regions (27, 28). As such, noise and artifacts in the images remain a primary challenge for retinal microvasculature segmentation (29). Additionally, due to the localized nature of convolution operations, deep learning algorithms often struggle to model long-range dependencies, making it hard to capture the detailed retinal microvascular structure (30). Repeated convolution and pooling operations further contribute to semantic information loss (31, 32), resulting in overly large or missing boundaries in microvasculature segmentation (33, 34). Figure 2 illustrates how pixel-level differences lead to oversized segmentation of thicker vascular boundaries, while microvascular structures only 1-2 pixels wide may disappear. Therefore, preserving continuous vascular information is crucial for precise retinal microvasculature segmentation.

Figure 2. (A) Original OCTA image and the schematic representations of corresponding segmentation pattern, with the same area highlighted by red boxes and showed in (B). (C) Illustration of the corresponding pixel-level widths for the two modes.
To this end, we propose a novel Dual-stream Disentangled Representation Network(D2Net) based on the encoder-decoder architecture, for OCTA retinal vascular segmentation. To further enhance the modeling of vascular structure and noise and artifacts features, we map the extracted high-dimensional features into a latent space for representation. By introducing vascular structure priors, we strengthen the network's capability to represent latent variables effectively. In addition, we construct auxiliary information to enable the dual-stream encoder to focus on different features separately. The optimization procedure is achieved by integrating an image reconstruction term and a Kullback-Leibler (KL) regularization term. The dual-stream encoders focus respectively on learning the noise and artifacts features for image reconstruction as well as learning the latent features of vascular structures for the KL regularization term. This approach enables the disentanglement of vascular structure information and artifacts in OCTA images, thereby making segmentation of retinal microvasculature possible. Subsequently, we develop a novel module to leverage multi-scale contextual information to enhance the perception of continuous vessels, thereby refining segmentation results with better accuracy.
Finally, we conducted detailed and comprehensive manual annotations on OCTA images collected from two different instruments, constructing an internally annotated dataset (FOCA) at the microvascular level to validate the effectiveness of the proposed segmentation method. Additionally, we conducted experiments on four datasets focusing on segmenting varying degrees of vessels, including two public datasets (OCTA-500, ROSE-O) and two private datasets (ROSE-Z, ROSE-H). The experimental results demonstrate that the proposed D2Net achieves superior performance in microvascular segmentation. The contributions are summarized as follows:
• We propose a Dual-stream Disentangled Network (D2Net) capable of learning the representation of vascular structure information and stylistic information in OCTA images, significantly enhancing the model's robustness against noise and artifacts from different instruments.
• We propose a Distance Correlation Energy (DCE) module that utilizes low-dimensional images to construct auxiliary information, ensuring that disentanglement remains stable even when using a single image as input. This approach also enhances the ability of the network to sense the microvascular structure making the segmentation boundary more accurate.
• We extensively evaluate the proposed method on five datasets acquired from multiple OCTA instruments, confirming its state-of-the-art segmentation performance and generalization capabilities.
2 Related workSeveral works have proposed deep learning methods for OCTA vessel segmentation. To extract more high-level semantic features, Pissas et al. (35) proposed a U-shaped network capable of integrating shallow and deep features. Eladawi et al. (36) introduced an OCT segmentation algorithm based on the Markov Gibbs random field model. Joint-Seg (37) performs joint encoding on OCTA images and utilizes a feature-adaptive filter to provide FAZ and RV-related information for separate decoding branches. These works focus on feature extraction from raw images, which significantly limits the ability to reconstruct and represent microvascular structures. To address the issue of feature degradation caused by convolution and enhance the dependency relationships of contextual features, Chen et al. (30, 38) combined U-Net with Transformer, integrating global attention mechanisms to enhance detailed information and achieve precise localization. Similarly, Wang et al. (39) and Liu et al. (40) propose layer segmentation algorithms specialized for OCT images based on Transformer strategies. Chen et al. (41) combines U-Net and Swin-Uformer to jointly learn global and local information in OCT images, compensating for information loss between layers due to speckle noise.
Despite these advances, attention mechanisms show better performance in compensating for local information, when the focus is on microvascular areas with more refined and complete constraints, the network applies attention enhancement across all regions containing microvessels in OCTA images. This easily leads to boundary overshooting during segmentation of adjacent microvessels, resulting in many false positive predictions, a phenomenon we also observed in our comparative experiments. Recently, Liu et al. (26) proposed a segmentation model that leverages the disentanglement of anatomical and contrast components from paired OCTA images to focus on vascular structure information. However, this method requires a large amount of paired data from different devices for pretraining, increasing the data acquisition threshold. Additionally, it freezes the pre-trained model parameters for supervised learning, which creates limitations in model complexity and portability in the two-stage approach.
OCTANet (4) is a network specifically designed for the segmentation of OCTA vessels with varying thicknesses. It first generates an initial vessel confidence map using a coarse segmentation module based on splitting, and then optimizes the shape of retinal microvessels using a fine segmentation module based on splitting, thereby achieving precise segmentation. VAFF (8) utilizes OCTA images from different layers and incorporates a specialized voting gate mechanism to achieve more accurate vessel localization and segmentation. However, both of these networks tailored for OCTA segmentation tasks are unable to effectively address the artifact and noise interference issues caused by different devices.
The aforementioned methods primarily emphasize combining additional low-level information to improve network segmentation performance, without considering the adverse effects of redundant information reuse and information leakage on network performance. These methods have limitations when learning from the OCTA microvascular regions, as they fail to effectively avoid interference from artifact noise and neglect the utilization of low-dimensional image information from the microvessels.
3 MethodologyIn this section, we introduce the proposed dual-stream disentangled architecture named D2Net, including vessels extractor, dual-stream disentangled network, distance correlation energy module and loss function for its end-to-end training.
3.1 ArchitectureThe overall architecture of the proposed D2Net is shown in Figure 3. D2Net consists of three main components: the vessels extractor, the dual-stream disentangled network, and the distance correlation energy (DCE) module. The model's goal is to differentiate vascular features from noise and artifacts through disentangled representation learning, reducing interference and improving microvascular segmentation.
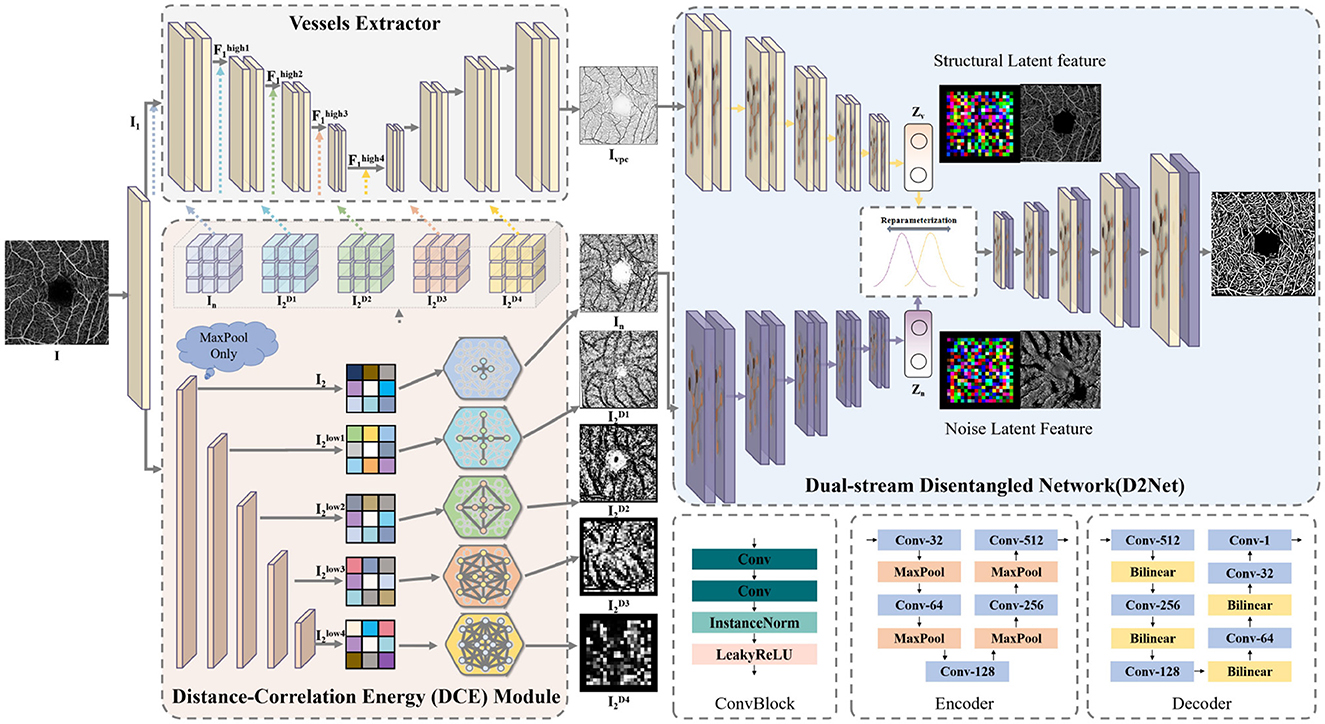
Figure 3. The architecture of our D2Net, consisting of the vessels extractor, dual-stream disentangled network and the distance correlation energy.
The model input is a single-layer en face projection from the SVC layer of the OCTA image. The initial OCTA image I∈ℝH×W×3 is duplicated and processed with a 1 × 1 convolutional layer to adjust the channel number to 64, resulting in I1 and I2. Subsequently, I1 and I2 are sent to the vessels extractor and DCE module, respectively, to obtain a noise-free vascular structure prior Ivpc and a version with noise and artifacts In. The vessels extractor enhances high-dimensional features at each layer using the DCE module's correlation energy, producing Ivpc, which serves as the input for the vascular disentangled stream and provides a clean vascular structure reference. To enable the network to focus on the vascular structure, the second stream must minimize vascular information while highlighting noise and artifacts. Thus, I2 is enhanced with correlation energy, creating In, which retains both vascular and noise information, and is used as input for the noise and artifacts disentangled stream.
The vessels extractor in D2Net can be any end-to-end segmentation network; in this paper, a U-shaped architecture is used as the backbone. Notably, D2Net is designed as a plug-and-play framework, allowing any state-of-the-art segmentation network to replace the vessels extractor. The extractor's convolutional block includes two 3 × 3 convolution layers with Instance Normalization and LeakyReLU activation. Maxpooling and bilinear interpolation are used for feature dimension reduction and resolution restoration, respectively. The extractor performs four rounds of feature extraction on I1, producing feature maps F1high1 (12H×12W×128), F1high2 (14H×14W×256), F1high3 (18H×18W×512), and F1high4 (116H×116W×512). For the noise and artifacts disentangled stream, it's only necessary to provide vascular information comparable to the vascular disentangled branch while differing in noise and artifacts. Thus, instead of dimension reduction, the low-dimensional image data I is directly enhanced with correlation energy by the DCE module and input into the dual-stream disentangled network.
Each layer in the dual-stream encoder extracts high-level information from two distinct feature types. Specifically, each encoder layer consists of two convolutional layers with instance normalization and LeakyReLU activation, followed by maxpooling for feature extraction. The decoder mirrors this structure, using bilinear interpolation for feature restoration. Additionally, we flatten the extracted latent variables, transform the resulting vector into latent space via linear neurons, reparameterize it, and feed it into the upsampling layer to complete the reconstruction of retinal vessels.
3.2 Dual-stream disentangled networkNoise and artifacts can complicate accurate segmentation of microvascular regions. To address this, our dual-stream disentangled network is designed to separate representations of retinal vessel structure from noise and artifact information. This disentanglement, achievable using a single image, facilitates training on more diverse datasets. The dual-stream network includes two encoders with similar structures but independent weights and a shared decoder. Each encoder focuses on specific features: one on the vascular structure and the other on noise and artifacts. With the vascular structure extracted by the vessels extractor as a prior constraint, the network learns to reduce noise interference and achieve more accurate segmentation of microvascular areas. Each encoder maps its input into latent space, where the shared decoder reparameterizes the latent features and adaptively learns feature selection and fusion. The inputs for each stream are tailored: the vascular structure stream uses prior information from the vessels extractor enhanced with multi-scale DCE modules, while the noise and artifacts stream uses OCTA data enhanced with single-scale DCE modules. This setup ensures both streams have consistent vascular structure information during encoding. Given that encoding is a lossy process with a capacity limit (42), the inputs to both streams are designed to maintain identical spatial dimensions.
As shown in Figure 3, in the noise and artifacts stream, I2 is enhanced through the DCE module to obtain In, which increases the distance correlation energy. Subsequently, In is then encoded by the noise and artifacts stream encoder, yielding the probability distribution qϕ(Zn|In) in the latent space. The latent feature Zn has an encoding bottleneck, allowing it to only capture limited information from In. In the vascular structure stream branch, I1 is processed by the vessels extractor and the DCE module, generating Ivpc, which also enhances distance correlation energy. The vascular structure encoder then maps Ivpc to the probability distribution qϕ(Zv|Ivpc) in latent space. Thus, Zv represents only the vascular structure features, free of noise and artifacts, while Zn includes similar vascular features alongside unique noise and artifact information. The decoder reconstructs Zn using the encoding bottleneck to prioritize distinct information while discarding redundancies. Similar to conditional variational autoencoders (43), this process is guided by the evidence lower bound (ELBO):
L(θ,ϕ;In)=Eqϕ(Zn|In)[logpθ(In|Zn)]-KL(qϕ(Zn|In)||p(Zn)), (1)This equation balances the reconstruction likelihood of In given Zn with the KL divergence between the approximate posterior qϕ(Zn|In) and the prior p(Zn), ensuring that the network learns to generate accurate reconstructions while maintaining diversity in the latent space.
The encoder maps the input In to a probability distribution in the latent space, qϕ(Zn|In), assumed to be a Gaussian distribution N(Zn;μ(In),σ(In)). The first term, Eqϕ(Zn|In)[logpθ(In|Zn)], represents the expected log-likelihood of reconstructing the input data In under the latent variable Zn. The decoder samples from the latent variable Zn and reconstructs the input data In, denoted as pθ(In|Zn). The reconstruction error term involves taking the expectation over the variational posterior distribution qϕ(Zn|In). In practice, this expectation can be computed as ∫qϕ(Zn|In)logpθ(In|Zn)dz.
This represents the expected log-likelihood of reconstructing In under the latent variable Zn. The objective of optimizing the reconstruction error term is to maximize Eqϕ(Zn|In)[logpθ(In|Zn)], indicating that we aim for Zn to accurately reconstruct the input data In as closely as possible. This part is akin to minimizing the mean squared error of reconstructing In in implementation. The second term KL(qϕ(Zn|In)||p(Zn)) is the Kullback-Leibler divergence between the variational distribution qϕ(Zn|In) and the prior distribution p(Zn) in the latent space, used to regularize the distribution of latent variables.
The decoder parameters are optimized to maximize reconstruction log-likelihood, aiming to capture only the most critical latent features for reconstruction. Due to the limited dimensionality of the latent space, the decoder must prioritize differential information essential for reconstruction. If Zn were expected to also represent vascular information, it would lead to a significant redundancy between Zn and Zv latent features. Thus, the decoder focuses on preserving features in Zn specific to noise and artifacts, while Zv retains vascular structure details.
3.3 Distance correlation energy moduleIn OCTA images, accurately segmenting fine microvascular structures is challenging due to complex vascular topology and interference from noise. Convolutional operations alone struggle to capture long-range dependencies and maintain low-dimensional image details, leading to information loss. To address this, we introduce a DCE module to capture multi-scale neighborhood correlations, which enhances segmentation accuracy by improving microvascular representation. The DCE method leverages both low-dimensional neighborhood semantics and high-dimensional feature correlations by constructing an energy matrix that measures pixel correlations. Typically, large differences between neighboring pixels indicate noise or artifacts, while small differences signify continuous vascular structures with higher energy. This helps the network retain vascular structure while minimizing the influence of independent noise.
Specifically, we represent the OCTA en face image as an undirected graph G = (V, E), where V represents the set of nodes (vertices) in the graph, and E represents the set of edges connecting these nodes. We calculate the distance between each node and its four-connected neighbors, forming a distance correlation matrix D. Assuming node i has four connected nodes jp (where p = 1, 2, 3, 4), the matrix D is defined as:
Di,jp=Djp,i=||I(i)-I(jp)||2, (2)where I(·) denotes the pixel values from the pre-processed OCTA data I2 obtained after a 1 × 1 convolution. To address the boundary two-neighbor problem, we introduce additional edges that treat head and tail nodes as independent elements with an infinite distance between them. In this undirected graph, the path distance between nodes is computed by summing the weights of the connecting edges. When structural information in the image is similar, indicating close proximity between two nodes, the network assigns higher correlation weights to that region during training to enhance vascular feature learning. Conversely, regions with greater differences, such as isolated noise, are assigned higher distances to neighboring elements. Instead of discarding these noise-related components entirely, we assign them smaller correlation weights. The distance correlation matrix is then converted into energy weights as supplementary information. w can be described as: w=e-Dλ, where λ is a predefined hyperparameter that adjusts the energy magnitude. Since boundary nodes have infinite distances in the second neighborhood, their energy weights approach zero. This setup enables the network to localize features in images of various sizes while maintaining weak connectivity at boundary nodes. Because features extracted at different layers of the autoencoder capture different levels of semantic information, the DCE module needs to provide energy at multiple scales to the vessels extractor. To ensure alignment, a consistent pooling mechanism is used in the DCE module, matching the perceptual field of the vessels extractor. The DCE module then applies the same number of pooling operations to I2 as the vessels extractor, representing corresponding low-dimensional signals across scales: I2low1 (12H×12W×3), I2low2 (14H×14W×3), I2low3 (18H×18W×3), and I2low4 (116H×116W×3). When features are reduced k times, each pixel can represent an energy value within a range of 4·12k(k+1). In summary, this approach enhances the semantic boundaries of vessel regions, helping to mitigate annotation errors and improve segmentation model performance for microvascular regions.
3.4 Loss functionDuring network training, standard cross-entropy (CE) loss is computed between the vessel extractor's predictions Yextract and their corresponding ground truth Ygt is computed and updated through backpropagation to optimize the network parameters. The CE loss is represented as LCE(Yextract, Ygt). In the dual-stream disentangled network, our aim is to filter out redundant vascular structure information in the noise and artifacts stream. For this purpose, the mean squared error (MSE) loss is used between the reconstructed outputs and the original OCTA image to capture noise and artifacts more effectively. Given the reconstructed output Yrec and the image with domain-specific information YI2, the MSE loss is defined as LMSE(Yrec, YI2). To further optimize, KL divergence is employed to measure information loss by comparing the posterior distribution of latent features to a standard normal prior. This approach minimizes information loss in the approximate distribution, prevents distribution shift, and helps maintain the model's generalization capability. This process can be expressed as follows:
Lkl=KL(qϕ(Zn|In)||p(Zn))=−12∑i=1n(1+logσ2−μ2−eσ), (3)where μ and σ represent the mean and variance of the distribution, respectively.
4 Experimental setup 4.1 DatasetsIn this work, we constructed a new dataset, FOCA, to validate the effectiveness of our proposed method for microvascular segmentation. This dataset specifically focuses on microvascular regions. To further assess the method's robustness across diverse large-vessel segmentation standards, we also conducted experiments on two publicly available datasets (OCTA-500, ROSE-O) and two private datasets (ROSE-Z, ROSE-H).
FOCA contains 88 OCTA images from 3 mm × 3 mm SVC scans acquired using the Angiovue (RTVue XR Avanti, Optovue) and Zeiss Cirrus 5000-HD-OCT Angioplex (Carl Zeiss Meditec) instruments. We selected 40 image pairs with optimal imaging quality and aligned them at the pixel level. Each image underwent detailed pixel-level annotation, completed meticulously by a specialist and reviewed independently by another to ensure precision. Referencing OCTA-500 and ROSE-O, we randomized the data, using 32 scans for training and 8 for testing. Additionally, our dataset includes 44 paired, non-annotated images (with completed registration) to facilitate further research into retinal vascular structure using paired OCTA images.
ROSE-O includes 39 OCTA images from 3mm×3mm SVC scans obtained using the RTVue XR Avanti SD-OCT (Optovue, USA). We followed the same train-test split used in (4) (30 scans for training, 9 for testing), utilizing both the scans and their manual delineations.
ROSE-Z consists of 126 OCTA images from the Zeiss Cirrus 5000-HD-OCT Angioplex (Carl Zeiss Meditec) instrument. This dataset includes enface SVC, DVC, and IVC layer images from 42 subjects, encompassing 15 cases of diabetic retinopathy, 2 of Alzheimer's disease, and 25 healthy controls. We selected the 3mm×3mm SVC layer scans and their manual annotations for our experiments.
ROSE-H includes 60 OCTA images obtained using the Heidelberg Spectralis OCT2 (Heidelberg Engineering, Germany) instrument, with 3mm×3mm SVC layer scans and corresponding manual annotations. This dataset comprises 8 images with choroidal neovascularization and 12 from healthy controls. Following the training strategy in (8), we trained using the ROSE-O dataset's training subset and reserved ROSE-H solely for testing to evaluate generalizability across OCTA images from different instruments.
OCTA-500 contains 200 OCTA images (No. 10301−No. 10500), collected with a 70 kHz SD-OCT (RTVue-XR, Optovue, CA). The scans, centered on the macula with a 3mm×3mm range, include manual annotations. We adhered to the train-validation-test split in (44): images No. 10301−10440 for training, No. 10441−10450 for validation, and No. 10451−10500 for testing.
4.2 Implementation detailsThe proposed D2Net was implemented using the PyTorch framework and trained on a single NVIDIA GeForce GTX 3090Ti with 24GB of memory. We used the Adam optimizer with an initial learning rate of 0.0005 and a batch size of 4. The model was trained for 200 epochs, with all images resized to 512 × 512 pixels. No learning rate decay was applied. All experiments were independently validated, and metrics were not directly referenced. To ensure a fair comparison, the same parameter settings and training strategies were applied to all comparison methods. During training, all models underwent the same augmentation techniques, including random horizontal and vertical flips, random rotations, and random cropping.
4.3 Evaluation metricsTo comprehensively and objectively evaluate the segmentation performance of the proposed methods, the following metrics were calculated between the segmentation results and manual delineations for each model:
• Area Under the ROC Curve (AUC);
• Accuracy (ACC) = (TP + TN)/(TP + TN + FP + FN);
• Dice coefficient (Dice) = 2 × TP/(FP + FN + 2 × TP);
• G-mean score(GMEAN) = sensitivity×specificity;
where TP, TN, FP, and FN represent True Positives, True Negatives, False Positives, and False Negatives, respectively. Sensitivity (also known as recall or true positive rate) is the proportion of actual positives correctly identified by the model, calculated as TP/(TP + FN). Specificity is the proportion of actual negatives correctly identified, calculated as TN/(TN + FP). The GMEAN score balances sensitivity and specificity, offering a more holistic measure of a model's performance in binary classification tasks.
5 Experimental resultsSince retinal vascular region segmentation is a dense prediction task, we evaluated the performance of our model by comparing it with several recent methods in medical image segmentation, including UNet (35), UNet++ (45), CENet (33), CSNet (10), OCTANet (4), VAFF (8), SwinUNet (46), TransUNet (30), and UTNet (38). To ensure a fair comparison, all methods used the same training approach and optimization strategy, as described in Section 4.2.
5.1 Subjective comparisons 5.1.1 Qualitative comparisons of annotation and segmentationFigure 1 shows examples of manual annotations from the OCTA-500, ROSE-O, ROSE-Z, and ROSE-H datasets. In many cases, the manual annotations do not accurately match the actual microvascular regions, and these regions are often overlooked during annotation. In Figure 4, we use the microvascular region annotations from the FOCA dataset to guide segmentation, leading to more accurate and refined results across the four datasets. For example, in the OCTA-500 segmentation results, the large vessels in the original image and the predictions are mostly consistent, but the manual annotations for large vessels near the FAZ region are incomplete. Additionally, the segmentation of microvascular regions is much more accurate compared to the manual annotations, which often fail to capture these regions. In the ROSE-O and ROSE-Z datasets, the predictions are more refined and accurate.
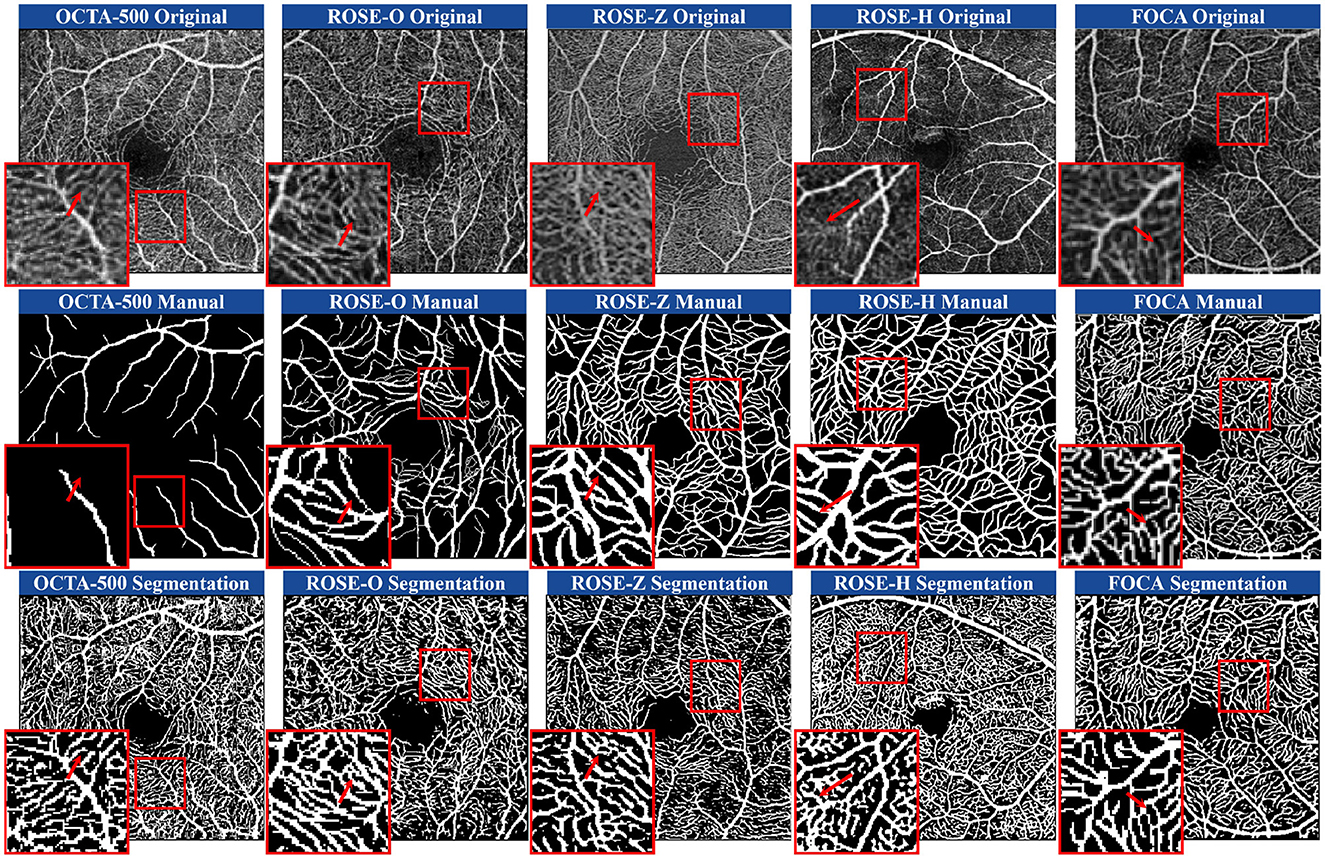
Figure 4. Comparison of manual annotations and microvascular region prediction results across four heterogeneous datasets and one homogeneous dataset. The prediction model was trained using D2Net on the FOCA dataset.
In the generalization experiments on the ROSE-H dataset, while the continuity of capillaries was not as well-preserved as in the other domains, the predictions for large vessels remained accurate. In areas with noise and artifact stripes, manual annotations mistakenly identify them as vessels, while our model correctly classifies them as non-vessel structures. Our method shows a stronger ability to predict low-contrast regions, generating visually richer and usually accurate microvascular predictions. We also conducted tests on the same-domain FOCA dataset. In these examples, we selected lower-contrast original images for demonstration. Our method outperforms in boundary handling, accurately matching the boundary width of professional manual annotations. Furthermore, in blurry microvascular regions, the predicted results are generally complete and accurate.
5.1.2 Qualitative comparisons with state-of-the-art methodsFigure 5 shows the segmentation results of OCTA images from the FOCA dataset using different methods. D2Net outperforms Unet, Unet++, CE-Net, and CS-Net in boundary segmentation. For example, in the red-highlighted areas, these methods over-segment large vessels and microvasculature, extending beyond the vessel boundaries. Due to fine annotations and the strong memory capabilities of these networks, continuous microvascular regions are often over-segmented and identified as block-like areas, losing their microvascular shape. TransUNet and UTNet focus more on local microvascular regions, showing better performance in these areas, but they still exhibit the issue of segmentation extending beyond vessel boundaries. While the over-segmentation problem has improved compared to the other methods, it remains notable. VAFF's voting mechanism helps prevent the network from forcibly memorizing and stacking results, providing better boundary handling. However, it struggles with learning microvascular regions. For example, in the FAZ region, microvascular predictions are inaccurate, with many breakages and incorrect segmentations. In contrast, our approach shows a trend of reduced over-segmentation and under-segmentation. This improvement is due to the DCE module, which effectively uses the correlation energy information of neighboring pixels to assign higher weights to continuous vessels and capture long-distance information.
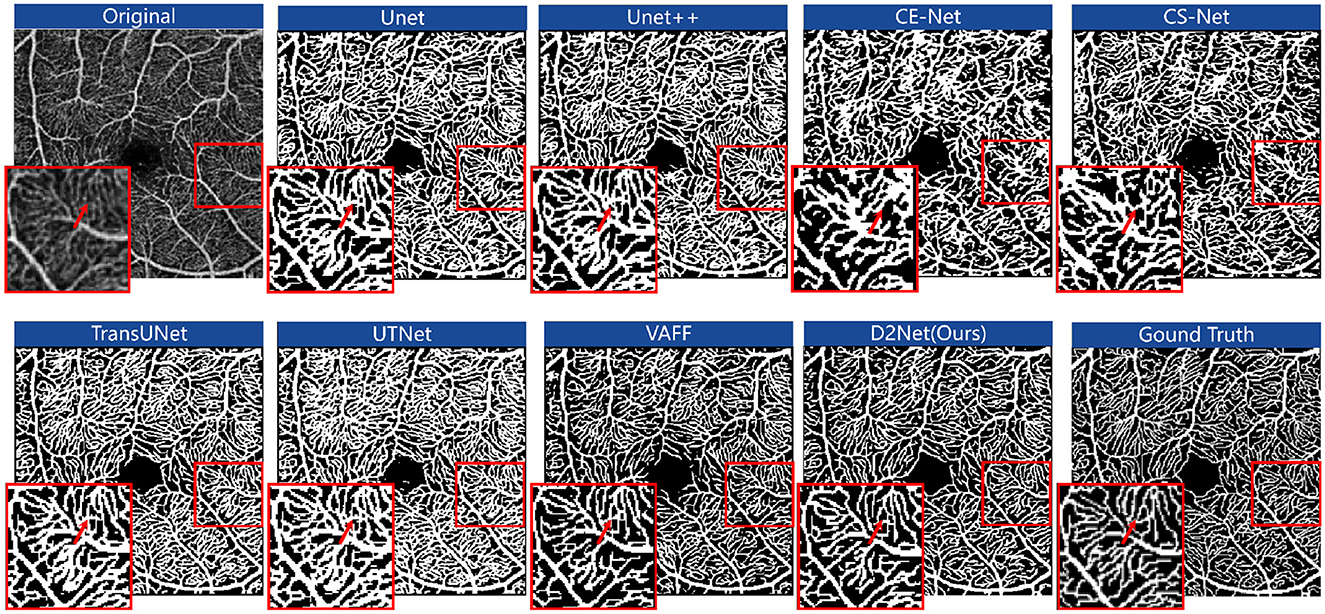
Figure 5. The segmentation results of OCTA images for different methods on the FOCA dataset. The results are shown in red boxes as zoomed-in examples of the segmentation details.
5.2 Quantitative comparisons 5.2.1 Quantitative comparison of microvascular datasetsTo evaluate the effectiveness of our method for retinal microvascular segmentation, we conducted quantitative experiments using the FOCA dataset, which focuses on microvascular regions. The results, shown in Table 1, demonstrate that our method, D2Net, outperforms existing state-of-the-art approaches. Specifically, D2Net achieved the best segmentation performance across multiple key metrics, including AUC, ACC, GMEAN, and DICE. As indicated in the table, D2Net leads in all metrics, with a Dice score 2.01 percentage points higher than the second-best method. This highlights the effectiveness of our dual-stream disentangled network, which reduces noise and artifact interference by separately learning vascular structures and image noise, leading to more accurate and complete segmentation results.
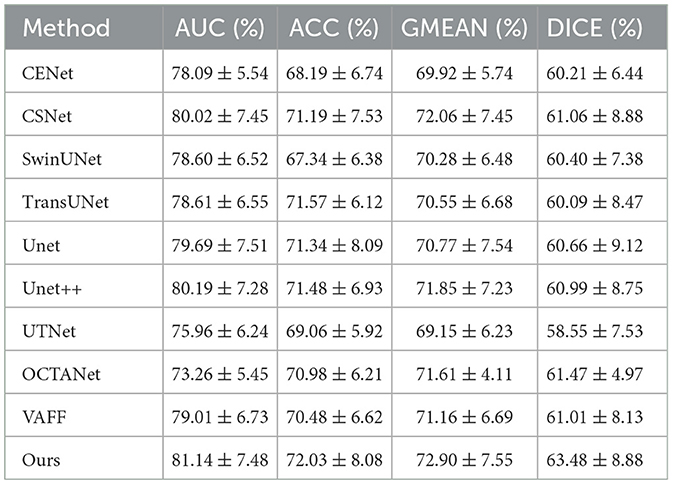
Table 1. Comparison of microvascular segmentation performance of different segmentation methods on the dataset FOCA.
5.2.2 Quantitative comparison of large vascular datasetsWe conducted quantitative comparisons across four large vessel datasets to demonstrate the the superior performance of our proposed method. All comparison methods were independently validated in our experimental environment. Table 2 presents the segmentation results of D2Net on the public datasets OCTA-500 and ROSE-O, while Table 3 shows results on the private datasets ROSE-Z and ROSE-H. As seen in both tables, D2Net outperforms other methods in all metrics. It accurately captures large vessels with high precision and consistency, and performs excellently in both DICE and GMEAN, showing its ability to identify large vessel regions while avoiding under-segmentation. These results highlight D2Net's superior performance in large vessel segmentation tasks. Furthermore, we assessed the model's generalization performance, with results from the cross-domain dataset ROSE-H (not used in training) shown in Table 3. The results demonstrate that D2Net not only generalizes well but also achieves the best performance compared to other methods.
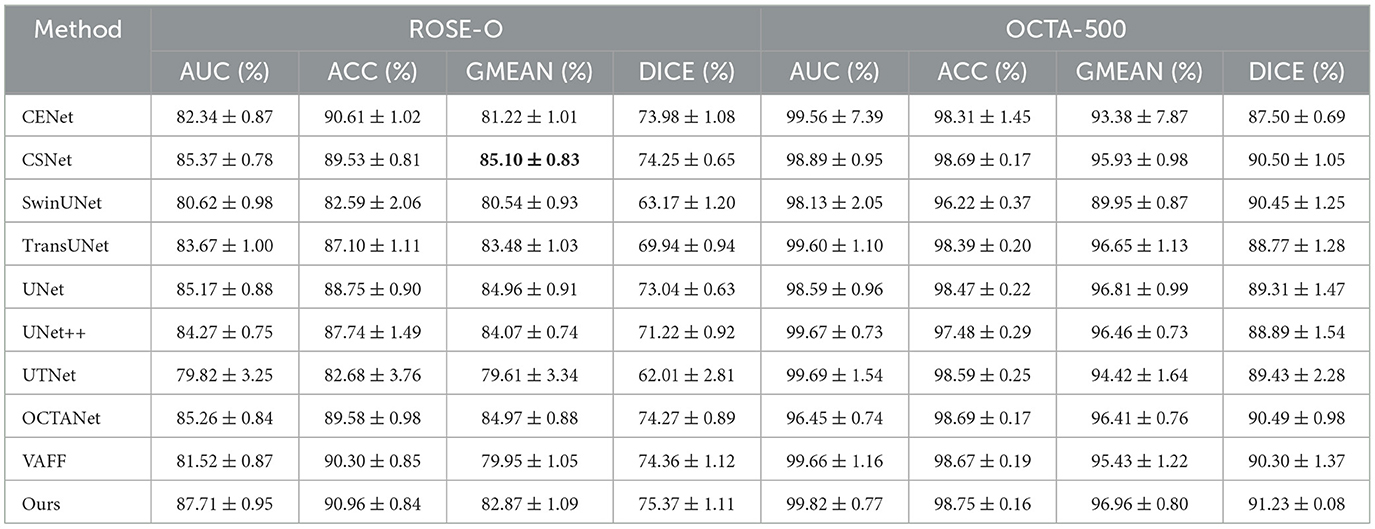
Table 2. Comparison of large vessel segmentation results between different methods on the public datasets ROSE-O and OCTA-500.
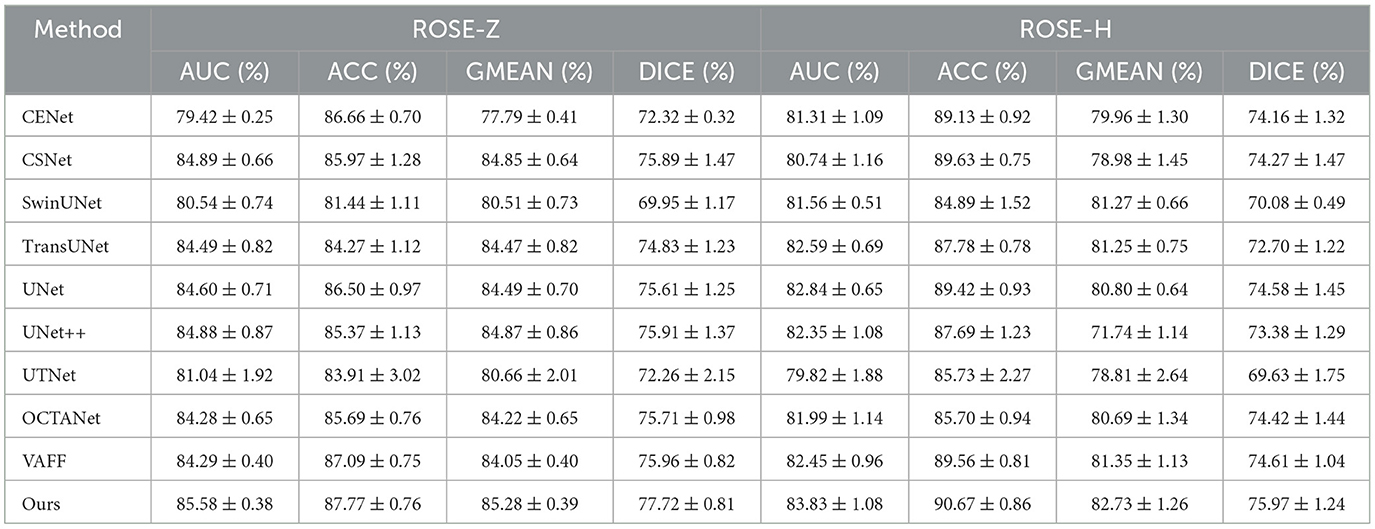
Table 3. Comparison of large vessel segmentation results between different methods on the private dataset ROSE-Z and ROSE-H.
6 Discussion 6.1 Ablation studiesTo validate the effectiveness of the dual-stream disentangled network and the DCE module in accurately segmenting retinal microvascular structures, we used a U-shaped architecture as the backbone for the retinal vessel extractor on the OCTA-500 dataset. We performed ablation experiments with two versions: D2Net without the DCE module and D2Net with the DCE module. The results are summarized in Table 4, and the visual effects are shown in Figure 6. Specifically, Original, Segmentation, and Reconstruction show the original OCTA image, segmentation, and reconstruction results, respectively. EnergyAddition demonstrates the intensity patterns after adding the DCE module, while VesselOnly and NoiseOnly display the disentangled outputs focusing on vascular structures and noise, respectively.
留言 (0)