
記住我

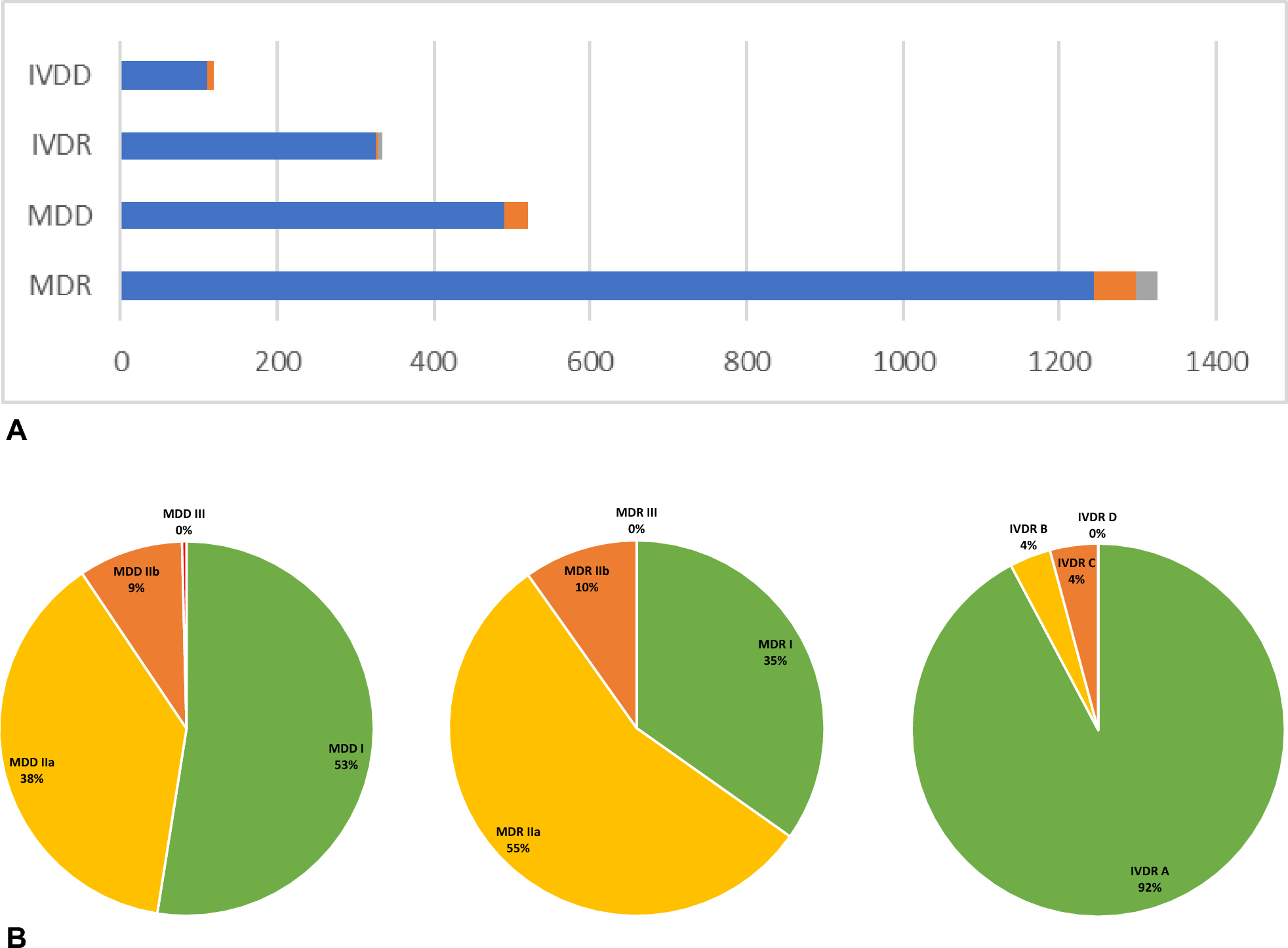






ICH E17 presents seven basic principles for MRCTs, the fourth is on that the use of the pooling strategy may help in sample size allocation and the assessment of consistency across regions. In specific, pooled regions and pooled subpopulations are the two of the most common strategies, with their definitions from E17 guideline described as follows [1]:
Pooled regions: “Pooling some geographical regions, countries or regulatory regions at the planning stage, if subjects in those regions are thought to be similar enough with respect to intrinsic and/or extrinsic factors relevant to the disease and/or drug under study.”
Pooled subpopulations: “Pooling a subset of the subjects from a particular region with similarly defined subsets from other regions whose members share one or more intrinsic or extrinsic factors important for the drug development programme at the planning stage. Pooled subpopulations are assumed as ethnicity-related subgroup particular important in the MRCT setting.”
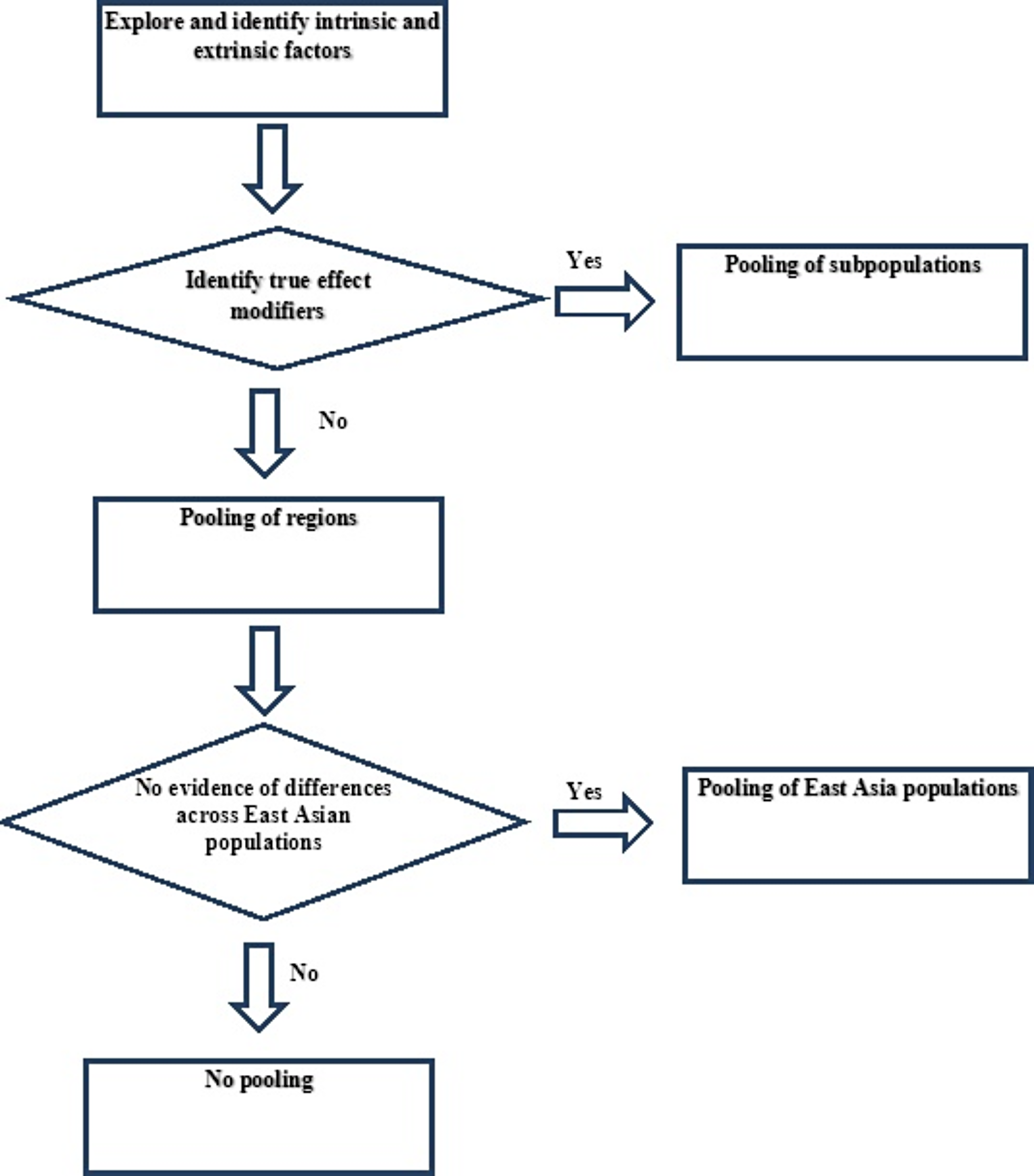
The procedures to determine the pooling strategy in MRCTs are described in Fig. 1. First, we want to explore and identify the intrinsic and extrinsic factors that affect the therapeutic effects of drug or disease characteristics, which we define as the EMs. That is to say, the EMs should present differential treatment effect which has biological implications. Once the EMs are identified, we are able to define and pool different subpopulations according to the EMs. If the EMs cannot be clearly identified, a flexible pooling strategy on regions can be specified based on scientific arguments and practicability. If there are significant differences across regions, then no pooling should be conducted.
Fig. 1
Process of determining the pooling strategy
As mentioned above, we conduct data collection and data evaluation steps to determine the true EMs from the intrinsic and extrinsic factors. By identifying the true EMs, we are able to define pooled subpopulation by different levels of the EMs without discriminating on regions. In other words, stratification could be performed based on the level of EMs that impact the drug efficacy [4]. For example, in the PREVENT study, countries with similar distributions of effect modifiers were grouped into five pooled regions, and the clinical relevance and results were evaluated to identify potential effect modifiers [5, 6]. When more than one EM is taken consideration, the pooling strategies might be more complicated. In this case, cluster analysis can be used when there are multiple EMs [2]. The correlation between these EMs and endpoints can be used to define the distances between different populations. The populations can be pooled by using unsupervised learning methods such as hierarchical clustering and k-means clustering. However, it should be noted that the number of categories for clustering is generally no more than four [7, 8].
Pooling on the subpopulation by a specific attribute would yield the data that resembles a particular region, if this region also enriched with that attribute. This allows the pooled subpopulation to serve as a surrogate for evaluating the efficacy and safety within a specific region. For example, if a regional population has lower weight, a subpopulation that pools all low weight subjects from all regions can provide a good representation of the regional population. The subpopulation will support the assessment of drug efficacy in the regional population under the context of large sample size. Another practical example is if two populations share positive biomarker that solicit similar drug responses, then we could pool them together in the final analysis. If Chinese population makes up a high proportion of the biomarker positive group, then the other biomarker positive populations can be pooled with Chinese population together to help evaluate the drug efficacy in Chinese population.
However, it is extremely challenging to identify the true EMs. When the true EMs cannot be identified, we choose instead the region pooling strategy to assess the drug efficacy. We define the region pooling strategy using geographical location, country or regulatory region without discriminating on EMs. Often times, there are commonalities in terms of potential impact on efficacy and factor distribution in a specific region in for one or several specific EMs. When considering pooling of the entire Asian region versus the East Asian region, China has an inclination on pooling the East Asian population instead of the entire region Asian, due to similarity in EMs among east Asian countries.
Region pooling strategy allows adequate account of the potential etiology and eases on the operational practicability in trial conduct. Relevant data should be obtained from epidemiological and early clinical studies. In specific, ethnic sensitivity information may imply intrinsic factors such as pharmacokinetics and pharmacodynamics, genetic data, biomarkers, etc. Ethnicity is one of the most important information to identify the etiological differences in population by regions. In China, if no significant differences across different ethnicities are shown, the East Asian population can be pooled together. Or else, the region pooling strategy will no longer be considered, and we only focus on the Chinese population.
留言 (0)