In this study, we used a novel method [4] to acquire data and train a deep learning network with two sets of configurations for the classification of surgical actions and skills assessment. Both networks demonstrated good performance in a surgically diverse dataset. We used the same network architecture (CNN-LSTM) for both problems, demonstrating the flexibility of the model.
Interest in machine learning-based action recognition or surgical skill assessment of RAS has been increasingly investigated in recent years [2, 3, 18]. Most studies use accuracy to evaluate model performance, as it measures the ratio of correct predictions to total predictions, unlike precision, which focuses specifically on the accuracy of positive predictions [2, 3, 9, 19, 20] or image-level binary classification tasks, such as in this study, the Metrics Reloaded framework supports using accuracy as a primary metric [21]. In addition to accuracy, we also include precision, recall, and F1-score for a more comprehensive evaluation of the results. Regarding action recognition, prior studies have achieved accuracies ranging from 68 to 90% [2, 3, 8]. Similarly, in the context of skill assessment, accuracies range from 76 to 100% when only video data are used [2, 3, 8]. Among state-of-the-art for surgical video assessment is SAIS, which leverages a pre-trained ViT model with a temporal component to identify surgical gestures and evaluate surgical skills [9]. This approach was tested across three hospitals and two surgical procedures (robot-assisted nephrectomy and radical prostatectomy), achieving AUC values exceeding 0.90 for gesture recognition and over 0.80 for both skills assessment and cross-procedure gesture recognition [8]. However, SAIS primarily evaluated on experienced surgeons and also had a more detailed discrimination of surgical gestures [8]. Another notable study utilized a temporal segment network for surgical assessment, combining a CNN with temporal aspect, like our network, to achieve 95% accuracy [10]. This research was conducted using the JIGSAWS dataset for training and testing [9].
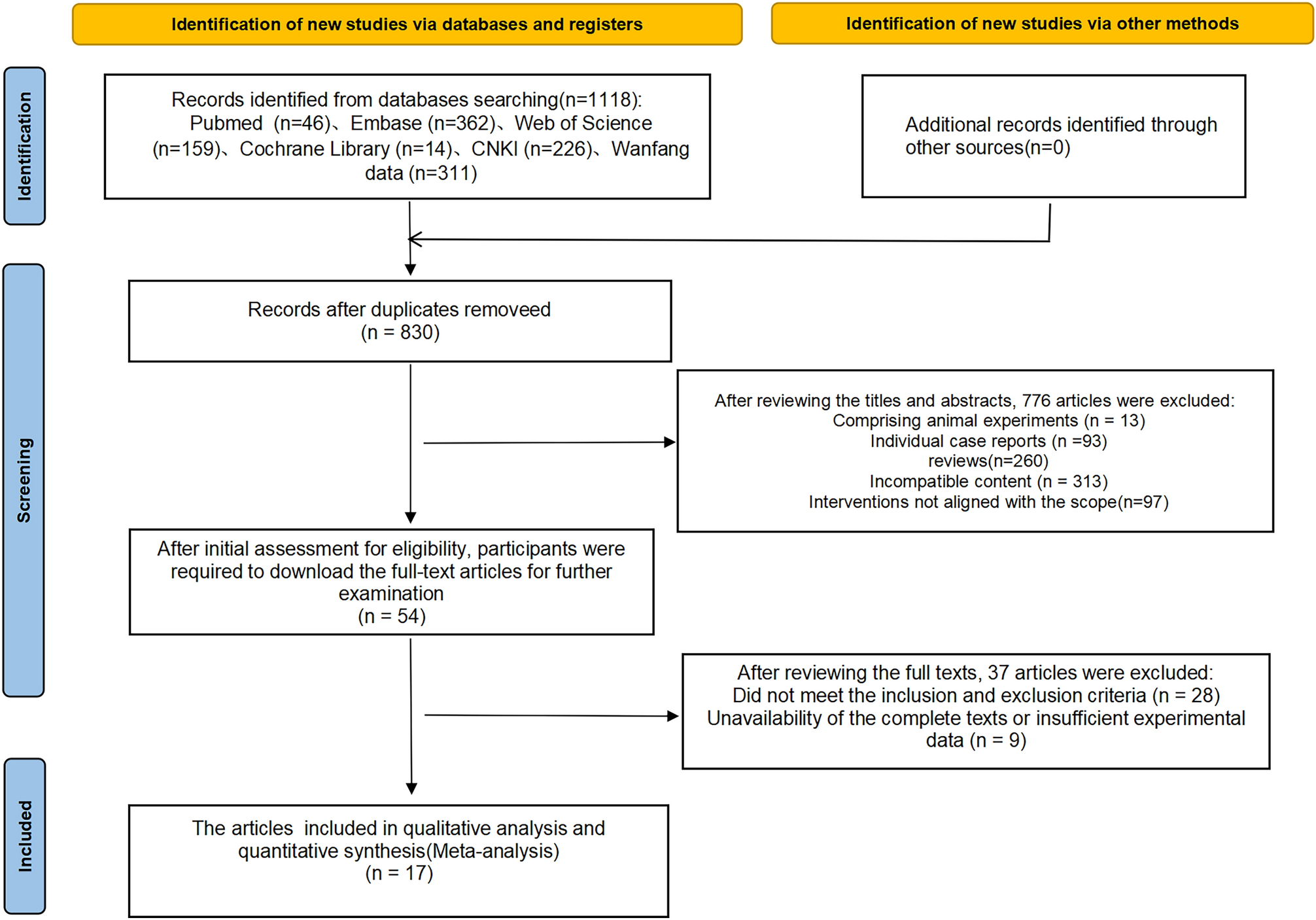
Most prior studies have tested their models on the JIGSAWS dataset, which is a public dataset of video and kinematic data made in a highly standardized, controlled dry lab environment [22]. The main limitation of using a small dataset in a controlled environment is overfitting, which occurs when an algorithm is not generalizable to new data from other environments or procedures [2, 3, 22]. The small size of the JIGSAWS dataset makes it difficult to allocate each participant exclusively to training, validation, or test sets, as we have done in the current study, due to the limited number of experts in the JIGSAWS dataset (only two). This raises questions regarding the results of prior studies in this field, as many studies do not explicitly address how they avoid leakage from training to validation and test data [2, 3].
Another problem when training and developing machine learning models based on dry lab data is that they do not generalize to clinical settings. However, data acquisition from clinical settings is difficult and expensive [23]. More importantly, it may be impossible to collect data for training machine learning models that include examples of poor or erroneous performance in the clinical setting, which are needed to train a good model to assess different levels of clinical skills. In recent years, public datasets like CholecTriplet, HeiChole, SAR-RARP50, ESAD, and PSI-AVA have emerged, alongside non-public datasets, such as SAIS and Theator, which is a surgical video database platform [3, 8, 24,25,26,27,28]. These datasets all use endoscopic footage, similar to our dataset. However, CholecTriplet and HeiChole are specific to human laparoscopic cholecystectomy, excluding robotic surgery, while SAR-RARP50, ESAD, PSI-AVA, and SAIS datasets focus on human robot-assisted radical prostatectomy (RARP) procedures [3, 8, 24,25,26,27,28]. Also, procedures were done by experienced surgeons, creating a small variance in both procedures and group of participants [3, 8, 24,25,26,27,28]. Annotation methods also varied, with SAR-RARP50 using only visual annotations, boundary boxes, while the other datasets include both visual and temporal annotations, such as instrument segmentation and time labels [3, 8, 24,25,26,27,28]. We used an in vivo porcine wet-lab setting to allow for the collection of data from multiple procedures across a large variety of surgeons with different skill levels, both novice and experienced [29]. This enabled us to develop a model that was indifferent to the 16 different surgical procedures on which it was trained. We also chose to use temporal annotations of the videos, where each surgical action was defined in the time they occurred, because it represents the most basic and simple way of annotating surgical procedures, especially when aiming to collect greater datasets and streamlining the data processing [30, 31]. Other methods such as spatial annotation using boundary boxes or segmenting instruments or anatomic structures are usually technically harder and require more defined criteria [2, 31]. We chose the two main categories of tasks; suturing and dissection and left out subcategories to avoid unbalancing the classes and because of the skewed frequency the subcategories were used throughout the surgical procedures [4]. We also left the ‘Other’ category, which was described in our previous study as a category for tasks, such as suction and holding [4]. We excluded the “Other” group because it overlapped with the “Suturing” and “Dissection” classes, creating a multilabel issue with skewed balance and technical complexity in this proof-of-concept study. Secondly, the “Other” class was inconsistent, containing varied actions that sometimes resembled “Suturing” or “Dissection” due to shared elements. Thus, the “Other” class was excluded from training and testing. Although previous research has identified subcategories within suturing and dissection, a widely accepted classification system and consensus has not yet been established [1, 2, 7, 16]. Therefore, we adopted broader definitions of suturing and dissection that encompass finer subcategories [1, 2, 7, 16]. Both the suturing and dissection labels were annotated as segments of time using timestamps, which is a function of BORIS [7, 16]. We based our subcategories on previous research which defines various subcategories of both suturing and dissection [1, 2, 7, 16]. For example, our subcategory of general dissection label included sharp dissection (which have previously been defined as spread, hook, push, and peel with any instrument), sharp dissection (hot and cold cut, burn and cut), and combinations (multiple peels either blunt or sharp and dissection with both instruments) [1]. Because of the size of our dataset, a subcategorization of the surgical actions would lead to non-generalizable results [2, 8]. The use of generic tasks is supported by the SAGES framework for annotation of surgical videos [32]. All labels were annotated by a medical doctor who is a clinical trainee in urology. Our use of temporal annotations aligns with the SAGES framework; however, because we did not annotate surgical phases or steps, defining relationships between different parts of the procedures is challenging [32]. Additionally, we did not label segments were nothing of surgical relevance happened (such as cleaning of camera and change of instruments); instead, we removed it during pre-processing, which aligns with the reason of why they should be labeled according to the SAGES framework [32]. We suggest that developing machine learning models in a wet-lab setting will allow easier generalization to the clinical setting, potentially using much smaller amounts of data for transfer learning, as demonstrated in other areas of data science [33,34,35,36,37]. This will be the subject of future research.
Skill assessment annotations were based on a binary classification (experienced vs. novice), defined by operative volume alone. Each procedure was labeled as either ‘experienced’ or ‘novice.’ While this quantitative approach is common, it may not accurately reflect individual technical skill levels, it lacks flexibility, and studies have shown considerable variability in determining the skill levels [33, 34]. We chose a value of 100 cases to distinguish between novice and experienced surgeons. Still, previous studies have used a wide range, from 30 to over 1,000 cases, with thresholds differing by procedure type and medical specialty [2, 3, 8, 11, 12, 33, 38]. A way of generating more flexibility could be to use more degrees of experience and actual ratings of clinical performance. However, our proof-of-concept model demonstrates continuous evaluation on shorter segments during the procedures, unlike assessments such as GEARS, which only gives endpoint evaluation. Continuous evaluation provides surgeons and trainees with identifiable segments of less surgical quality during a procedure, allowing for targeted improvement in future procedures [8, 33]. Another limitation in the skills assessment tasks was our access to experienced robotic surgeons. Future research could benefit from a multicenter approach to gathering more data, addressing the challenge of having few experienced robotic surgeons at a single center [3, 8].
When models fail to deliver results accuracy despite the best possible set of features, there are two main avenues for improvement: using techniques to prevent overfitting and underfitting or gathering more data [39]. A clear limitation of the current study was the number of experienced participants and the overall size of the dataset. The dataset was reduced to comply with the criteria of participant exclusivity in the training, validation, and testing sets and also to balance both novice and experienced groups. Because of the limited skills assessment data, we used different machine learning techniques such as dropout, regularization, batch normalization, and an extra dense layer to make the network more robust and avoid overfitting. All machine learning models, including those used in surgical video analysis, are inherently limited by the quality of the datasets on which they are trained [31]. Biases introduced during the collection of training data can result in models that are less generalizable [31]. A pitfall is the use of datasets with limited variability, which fail to account for differences in surgical approaches, differences in anatomy, or even institutional practices [31]. However, because of the black-box nature of deep learning algorithms, we cannot be sure of which features truly influence a models predictions [40]. The lack of explainability and interpretability has been one of the reasons hindering its implementation [40]. GradCAM has been described as a way to make increase the interpretability of deep learning algorithms, especially CNN [40]. As shown in Fig. 2, the visual representation provides an interpretation of the decisions leading to the algorithm’s choices. Figure 2 shows the individual frames from longer sequences that are input to the LSTM layer. In addition, GradCAM has other limitations, such as problems with localizing multiple occurrences in an image, possible loss of signal because of the up- and down-sampling processes, and problems with the gradients of deep layers of a neural network [40]. It is important to note that our model analyzes not only the spatial features highlighted by GradCAM but also the temporal changes in these regions using the LSTM layer, making decisions based on the entire sequence rather than isolated frames. The use of the LSTM layer allows the model to recognize sequences and patterns over time, which is crucial for distinguishing similar actions with different outcomes [41]. Features that increase both interpretability and explainability are important for gaining the trust of clinicians and helping with the implementation of AI in clinical settings [8, 40, 42]. Future research could focus on methods that incorporate transparency as part of the network architecture or include multiple features simultaneously to increase both interpretability and explainability [40]. Moreover, studies are needed to determine how real-time machine learning feedback impacts the surgical workflow, surgeon attention, performance, and long-term learning.




留言 (0)