
記住我
Coronary artery disease (CAD), the leading cause of death globally, affects around 200 million people worldwide and results in around nine million fatalities annually (1). It remains the most common prevalent heart condition in both the United States and worldwide (2, 3). In 2019, CAD was identified as the single largest contributor to global mortality, highlighting its critical impact on population health (4). Patients with CAD can significantly improve their prognosis through early revascularization, primarily percutaneous coronary intervention (PCI), with drug-eluting stent (DES) implantation as its core part. Following PCI, current guidelines recommend patients receive dual antiplatelet therapy (DAPT), a regimen combining aspirin and a P2Y12 receptor inhibitor, to reduce risks of myocardial infarction (MI) and stent thrombosis. However, the management of DAPT poses a great challenge as shorter durations may fail to prevent the recurrence of ischemic conditions, whereas prolonged usage can heighten the bleeding risk. Hence, DAPT remains one of the most intensively investigated interventions in cardiovascular medicine (5). The decision-making process regarding the treatment duration requires a thoughtful evaluation of the trade-offs between ischemic and bleeding risks (6).
To support clinical decision-making, the cardiovascular community has developed various risk-predictive scores. Notably, the DAPT score (7, 8) and the PRECISE-DAPT score (9, 10) are prominent tools derived from clinical trials, designed to aid in determining the optimal duration of DAPT. The DAPT score focuses on the benefits of extending DAPT beyond 1 year (12–30 months), whereas the PRECISE-DAPT assesses the risks and benefits of long (12–24 months) vs. short (3–6 months) DAPT durations. Both scores utilize a manageable number of predictors, providing convenience in assisting clinical practice. However, their performance is relatively modest, with c-scores around 0.70 for risk stratifications (7, 9). Additionally, the clinical trial-based derivation source poses some restrictions, applicable only to a fixed time window and a predefined medication regimen. As treatment strategies evolve, there has been a shift towards more personalized and flexible DAPT regimens, such as de-escalation or abbreviation (11, 12), facilitated by the adoption of newer-generation stents and more effective antiplatelet medications. Concurrently, the availability of extensive healthcare data has paved the way for AI-based innovations in risk assessment (13, 14). Numerous studies have utilized machine learning techniques, such as XGBoost and Random Forest, to predict the risks of adverse events following PCI or acute coronary syndrome (ACS) (15–18). However, among these studies, very few focused specifically on DAPT management. To address this gap, we previously developed AI-DAPT (19), an approach using the Light Gradient Boosting Machine (LGBM) classifier (20) to dynamically forecast adverse outcomes post-PCI with various DAPT durations. While this model demonstrated strong performance, it represents an earlier generation of machine learning methods that primarily depend on structured decision trees.
In pursuit of further advancement, our current research has turned to the transformative capabilities of transformer-based models, which are revolutionizing various fields with their superior ability to handle complex patterns and data relationships. Transformer, popularized by their application in natural language processing (NLP) through models like the generative pre-trained transformer (GPT), operates on the principle of self-attention mechanisms that process input data in parallel. This allows for significantly improved efficiency and depth in modeling the temporal dynamics and interactions, which are critical for accurate survival analysis in clinical settings. In this study, we introduce a cutting-edge approach by combining transformer architecture with contrastive learning—a technique that enhances learning efficiency by contrasting pairs of similar and dissimilar data points (21). The Contrastive learning process involves minimizing a contrastive loss function that decreases the distance between similar data points while increasing the distance between dissimilar data points (21). It has been explored in biomedical research recently. Chen et al. proposed a deep multi-view contrastive learning model using multi-omics data for cancer subtype identification (22). Park et al. utilized deep contrastive learning for efficient molecular property prediction (23). Kokilepersaud et al. developed a contrastive learning-based model to classify the biomarkers in optical coherence tomography scans (24). The contrastive element allows the model to focus on critical features that differentiate outcomes (25, 26), making it especially adept at handling the complexities of post-PCI risk assessment. By leveraging the advanced AI framework, we aim to substantially enhance the accuracy, reliability, and flexibility of risk prediction after DES implantation, facilitating effective, personalized DAPT duration management in CAD patients.
2 Materials and methods 2.1 Data source and study cohortWe utilized the real-world clinical data from the OneFlorida+ Clinical Research Consortium, an integral part of the national PCORnet effort (27, 28). The dataset encompasses longitudinal EHRs for approximately 16.8 million individuals in Florida dating back to 2012 and provides a broad spectrum of patient information, encapsulating demographics, diagnoses, medications, procedures, and lab tests, among others. Our study was approved by the University of Florida Institutional Review Board (IRB) under IRB202000875 and the Mayo Clinic IRB under ID24-001183.
A total of 66,870 adult patients who underwent DES implantation between 2012 and 2020 were identified as potential inclusion for this study. The index date was designated as the date when a patient received the first DES implantation, labeled as time 0. Patients were excluded if they met any of the following criteria: (1) age >95 years at the index date; (2) absence of essential data such as gender or race among their whole records, or missing diagnosis or medication record after the index date; (3) absence of P2Y12 inhibitor record after the index date; (4) follow-up less than 1 month after the index date (Figure 1).
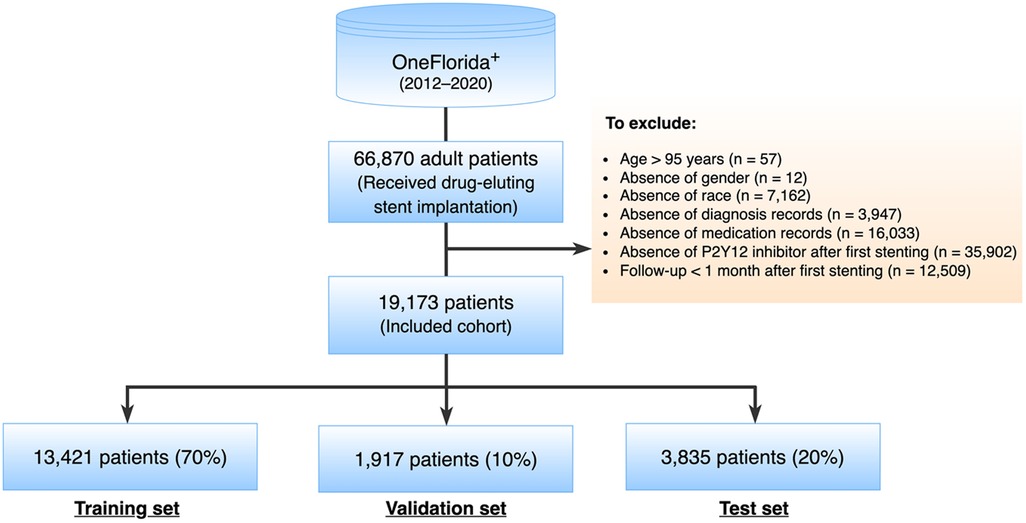
Figure 1. Study cohort selection.
2.2 Endpoints and characteristicsThis study primarily focused on two endpoints: ischemia and bleeding. The primary ischemic endpoint was a composite of acute ischemic heart disease, ischemic stroke, and coronary revascularization. The primary bleeding endpoint consisted of a spectrum from minor to severe spontaneous bleeding as well as blood transfusion. The details of definitions and validation of the phenotyping algorithms could refer to our previous study (19).
Following the approach of the PRECISE-DAPT score, we excluded endpoints occurring during the hospital stay, which were largely related to invasive procedures. Regarding 7 days being the upper limit of current hospitalization trends in patients with ACS, we started event prediction on the 8th day after the initial invasive procedure (the index visit). DAPT exposure was defined as the combinational antiplatelet therapy with aspirin and a P2Y12 receptor inhibitor (clopidogrel, prasugrel, or ticagrelor). Due to the over-the-counter availability, aspirin may not necessarily be included as a prescription in the EHR data. Regarding this, we assumed that all patients were on aspirin regardless of whether the aspirin information was captured in their records or not.
This study examined patient characteristics potentially associated with the development of the adverse endpoints, comprising: (1) sociodemographic information, including the age at the index visit, sex, and race/ethnicity; (2) medical history and risk factors, encompassing a range of factors such as prior incidents (bleeding, myocardial infarction [MI], stroke, coronary artery bypass graft surgery [CABG]), lifestyle factors (alcohol abuse, smoking), health conditions (anemia, atrial fibrillation, cancer, chronic kidney disease [CKD], congestive heart failure [CHF], diabetes mellitus, dyslipidemia, hypertension, liver disease, peripheral vascular disease [PVD], and venous thromboembolism [VTE]); (3) concomitant medications, including angiotensin-converting enzyme inhibitors (ACEIs), angiotensin receptor blockers (ARBs), beta-blockers, calcium antagonists, non-steroidal anti-inflammatory drugs (NSAIDs), and statins. The definitions of the comorbidities and generic name sets of the medications were mainly based on the Elixhauser Comorbidity Index, Epocrates Web Drugs, and related studies. The standard terminologies referenced in this study included the International Classification of Diseases, Ninth and Tenth Revision, Clinical Modification (ICD-9-CM, ICD-10-CM) for diagnoses, the ICD procedure coding system (ICD-9-PCS and ICD-10-PCS), Current Procedural Terminology, 4th Edition (CPT-4), and the Healthcare Common Procedure Coding System (HCPCS) for procedures.
2.3 Predictive modeling 2.3.1 Contrastive learning with transformerIn this work, we proposed a unified framework for adverse endpoint prediction for patients on DAPT post-PCI. Our approach began with a lower-level auto-encoder (encoder-decoder) model which extracted compressed features from the embedding matrix to reduce dimensionality, which served as input to the multi-head attentional transformer. We performed contrastive learning on the transformer for the improvement of discriminative power and robustness in the parameter space. Specifically, we performed simultaneous optimization for both the event classification and cumulative risk prediction tasks. Given the inherent variability of patient data from different subjects, leverage of the heterogeneous prediction tasks enhances the model's generalization ability towards the noise and variance in the data. The model parameters are optimized with contrastive triplet loss, which seeks to minimize the distance between pairs of samples with the same label and, at the same time maximize the distance between paired samples of different classes. Optimization of this multi-task contrastive target encourages the model to extract meaningful representations that are versatile across the different prediction tasks. Specifically, our model comprises modules of input, autoencoder, transformer encoder, contrastive learning network, and multi-task learning for output. The architecture overview is depicted in Figure 2.
1. Input Module. We used the one-hot encoding method to create an embedding lookup table for all codes, then converted values of categorical variables (such as gender and disease) to high-dimensional vectors. We performed standardization transformation for numerical variables (such as age) to achieve a mean of 0 and standard deviation of 1 and then initialized them with a random embedding. As a result, each feature will have an embedding vector with the same size. After that, we concatenated both types of embedding vectors to construct a complete embedding matrix. Each patient's embedding is a 2-dimensional array with an M × N shape, where M is the number of features and N is the embedding size. This embedding matrix was the output of this Input Module.
2. Autoencoder Module. Autoencoder is an unsupervised artificial neural network that learns efficient representations of data by compressing input into a lower-dimensional latent space and then reconstructing the original input from this representation. The autoencoder has three parts: an encoder, a bottleneck, and a decoder.
• Encoder: Learns the hidden features of the input data and then compresses it into a smaller dimension.
• Bottleneck: Stores the learned representation. It is usually used for further model training and prediction.
• Decoder: Reconstructs the compressed data to the original dimension. It outputs a synthetic embedding matrix that should be as similar as the input data.
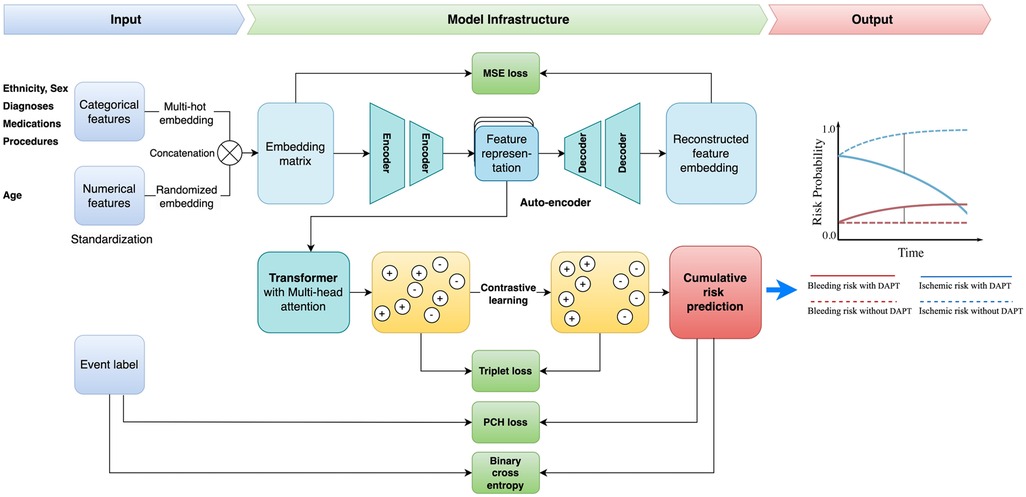
Figure 2. Study framework. DAPT, dual antiplatelet therapy; MSE, mean square error; PCH, piecewise constant hazard.
We used mean squared error (MSE) loss (LMSE) to optimize the loss between the input and the reconstructed data:
Where N is the total number of samples, hi is the ith input and hi′ is the ith reconstructed data. The output of this module is the learned representation from the bottleneck.
3. Transformer Encoder Module. Transformer is a popular deep-learning model introduced by Vaswani et al. in 2017 (29). The encoder from the transformer is the pivotal component within the transformer architecture that has emerged as a cornerstone in various machine-learning tasks. It employs an attention mechanism to let the network focus on relevant parts of the input sequence, enhancing its ability to capture long-range dependencies and contextual information. Therefore, the learned representation from the attentive encoder is calculated by:
Attention(Q,K,V)=softmax(QKTdk)V
Where Q is the matrix of all query vectors, K is the matrix of all key vectors, V is the matrix of all value vectors, and dk is the dimension of the key vectors. All query, key, and value matrices are transformed from the input embedding. The softmax(QKTdk) calculates the normalized attention scores matrix (or relevant scores matrix) between each feature. The higher attention scores imply greater relevance and force the model to focus on certain parts of the input sequence while generating each output element. As a result, the learned representation is obtained by multiplying the attention score matrix with the value matrix.
4. Contrastive Learning Module. Contrastive learning is a self-supervised technique that learns representations by contrasting similar and dissimilar samples. Maximizing agreement between positive pairs (samples from the same class) and minimizing agreement between negative pairs (samples from different classes) enhances the model's ability to discriminate samples from different classes. In this project, we used the triplet loss (Ltriplet) to minimize the distance between the embedding of positive pairs while maximizing the distance between the embedding of negative pairs. We modified the Ltriplet below:
Ltriplet=∑max(||f(xit)−f(xi+)||22+β−||f(xit)−f(xi−)||22,0)
Where f(xit) is the embedding of the ith random selected target sample, f(xi+) and f(xi−) represent the averages of embeddings from either the same or different classes of the target sample, respectively.
5. Output Module—Cumulative Risk Prediction. We utilized the shared representation learning network to perform multiple tasks using a shared feature representation. This strategy allows the model to learn new knowledge from different tasks and hence improve model performance. In this project, we designed two distinct tasks: event classification and cumulative risk prediction. The event classification is optimized by the binary cross entropy loss (LBCE) and the risk prediction is updated by the piecewise constant hazard loss function (Lpc) (30).
LBCE=−1N∑i=1Nyilog(p(yi))+(1−yi)log(1−p(yi))
LPC=−1N∑i=1N(dilogλκ(ti)(xi)−λκ(ti)(xi)ρ(ti)−∑j=1κ(ti)−1λj(xi))
The goal of the piecewise constant hazard loss function Lpc is to evaluate and minimize the discrepancy between the predicted hazard rates (the model's estimate of the risk at any given time) and the actual observed data, including both event occurrences and censored observations. By minimizing this hazard loss, the model learns to predict the risk of events over time while appropriately handling censored data for robust and accurate survival predictions. The loss function consists of three key parts: (1) Maximizing the likelihood of actual events: dilogλκ(ti)(xi): This term accounts for the likelihood of observing the event at time ti. If the event is observed (i.e., di = 1), this term contributes positively to the likelihood of the predicted hazard rate; (2) Penalizing for survival time predictions: λκ(ti)(xi)ρ(ti): This term penalizes the model for incorrect predictions of survival times. The duration of the interval ρ(ti) scales the predicted hazard rate, reflecting the fact that the event's timing is influenced by how long an individual survives; (3) Penalizing for cumulative risks from earlier intervals: ∑j=1κ(ti)−1λj(xi)ρj: This sum represents the cumulative hazard over previous intervals, accounting for the risk an individual faces in earlier time periods. It helps to adjust for the fact that hazard rates earlier in the study period influence the probability of survival at later times. In this context, ti is the observed time for the i-th subject; di is event indicator for the i-th subject, specifically, di=1 if the event occurred at time ti, di=0 if the data is censored (i.e., the event didn't happen by time ti); κ(ti) is the index of the time interval containing ti; λκ(ti)(xi) is the predicted hazard rate for the i-th subject in the interval κ(ti), based on the covariates xi and it represents the instantaneous risk at time ti; ρ(ti) is duration of the interval that contains ti; λj(xi) is the predicted hazard rate for earlier intervals (where j<κ(ti)).
As a result, the final loss function Ltotal is defined as:
Ltotal=aLMSE+bLBCE+cLpc
Where a, b, and c are learned coefficients to balance between each loss function.
2.3.2 Baseline modelsWe chose three cutting-edge deep learning-based survival models as our baselines: DeepSurv, DeepHit, and SurvTRACE. The LGBM was selected as the backbone model in our previous research (19). Since it is a classification model and does not align with the regression nature of the survival analysis, it was not included as a baseline in this study.
DeepSurv is a modern implementation of the Cox proportional hazards (CPH) model using a deep neural network architecture (31). It uses a multi-layer perceptron architecture to handle survival data, capturing both linear and nonlinear effects from features, and modeling the relationship between covariates and the hazard function. The model takes baseline data as input, processing it through several hidden layers with weights θ. Each layer consists of fully connected nodes with nonlinear activation functions, followed by dropout for regularization. The final layer is a single node that performs a linear combination of the hidden features. The network's output is the predicted log-risk function ĥθ(x) (31). A limitation of this model is that it is based on the proportional hazards assumption, which means that the ratio of hazards between individuals is constant over time.
DeepHit is another advanced deep-learning survival model that directly learns the distribution of first-hitting times (32, 33). It comprises a single shared sub-network and a family of cause-specific sub-networks enabling the prediction of a joint distribution of survival times and events. This structure allows it to seamlessly handle multiple competing events using the same features. DeepHit does not assume proportional hazards but it is more complex than DeepSurv and may require more computational resources and data.
SurvTRACE is a state-of-the-art deep learning survival model that leverages a transformer-based architecture to handle complex relationships in the data better to improve model performance (34). Transformer architecture's attention mechanism helps engineer automatic feature learning and increase interpretability. It can handle competing events and multi-task learning through a shared representation network.
2.3.3 Evaluation metricsWe utilized the time-dependent concordance (Ctd) index (34, 35) to measure the performance of cumulative bleeding risk prediction. The traditional concordance index (C-index) evaluates a model's capability to rank the survival times of different individuals accurately. It is determined by the proportion of all possible pairs of individuals for which the model's predictions and the actual outcomes are concordant. The Ctd-index extends this concept by considering survival status at various time points. More specifically, the Ctd-index assesses the model's ability to predict the order of survival times over time by accounting for the censored nature of survival data. In addition to ignoring the bias introduced by the distribution of censoring times, we adapt the inverse probability of censoring weights to obtain a more reliable and robust measure of a model's predictive performance in the presence of censored data. As a result, a meaningful Ctd-index typically ranges from 0.5 to 1.0. A higher value indicates better model performance in ranking survival time or time-to-event outcomes.
We also applied the bootstrapping method to generate a new sampling distribution for model performance evaluation. Specifically, we performed 500 trials to select samples with replacements from the testing set randomly. In each trial, the sample size matched the original testing set size, and the Ctd-index was calculated. The 95% confidence interval (CI) for the Ctd-index was determined using the 2.5th and 97.5th percentiles of the 500 Ctd-index values. To evaluate the significance of the differences between our proposed model and the baselines, we employed Welch's t-test (assuming unequal variance) to compare the Ctd-index values derived from the bootstrap samples between our model and baselines.
2.3.4 Model calibrationTo assess the predictive reliability of our model, we plotted calibration curves and calculated the Brier scores. A well-calibrated model demonstrates that its predicted probability closely aligns with the actual likelihood of the event happening. The Brier score is a metric commonly used to evaluate the calibration of probabilistic forecasts, by calculating the mean squared difference between the predicted probabilities of an event and the actual outcomes. A lower Brier score indicates better accuracy, with 0 being a perfect score.
2.4 Statistical analysisFor descriptive analysis of demographic and clinical characteristics, categorical variables are reported as count (%) and continuous variables as mean (standard deviation, SD). We used the chi-square test for categorical variables and the Kruskal-Wallis test for continuous variables to assess the differences between patients who experienced events and those who did not within 1–24 months. A two-sided p ≤ 0.05 was considered statistically significant. Welch's t-test was applied to compare model performance, as detailed in the Evaluation metrics section.
3 Results 3.1 Baseline characteristicsA total of 19,713 adult patients, who underwent DES implantation with more than 1-month records after coronary stenting, were identified as the final cohort from OneFlorida+. Of them, 5,088 (26.5%) experienced ischemic events and 3,150 (16.4%) encountered bleeding events within the first year post-DES implantation. The average age of the cohort was 60.4 years with a standard deviation of 11.8. Among them, 12,036 (61.6%) were males.
Regarding the ischemic event, as shown in Table 1, patients with the event were younger than those without the event (59.4 vs. 63.0, p < 0.0001). Most clinical characteristics were significantly more prevalent in patients with ischemic events than the non-event group. Notably, 66.4% of patients in the ischemic event group presented with acute ischemic heart disease, compared to only 27.9% in the non-event group (p < 0.0001). In terms of medical history, prior conditions like bleeding, ischemic heart disease, and stroke, were more prevalent in the ischemic event group, all showing statistical significance (p < 0.05). For comorbidities and risk factors, there was higher prevalence in the ischemic group for conditions like hypertension (92.5% vs. 87.6%), diabetes (62.4% vs. 51.1%), dyslipidemia (93.3% vs. 86.4%), chronic heart failure (CHF) (57.4% vs. 35.6%), anemia (46.1% vs. 29.5%), atrial fibrillation (20.5% vs. 16.2%), smoking (46.4% vs. 34.1%), and alcohol use (10.7% vs. 7.0%) than the non-ischemic group. Interestingly, the prevalence of cancer did not differ significantly (14.4% vs. 14.3%, p = 0.83) between the two groups. For medication use, only beta-blockers and statins showed no significant difference while other medications, including the use of ACEI, ARB, calcium antagonists, NSAIDs, and PPIs demonstrated significant differences.
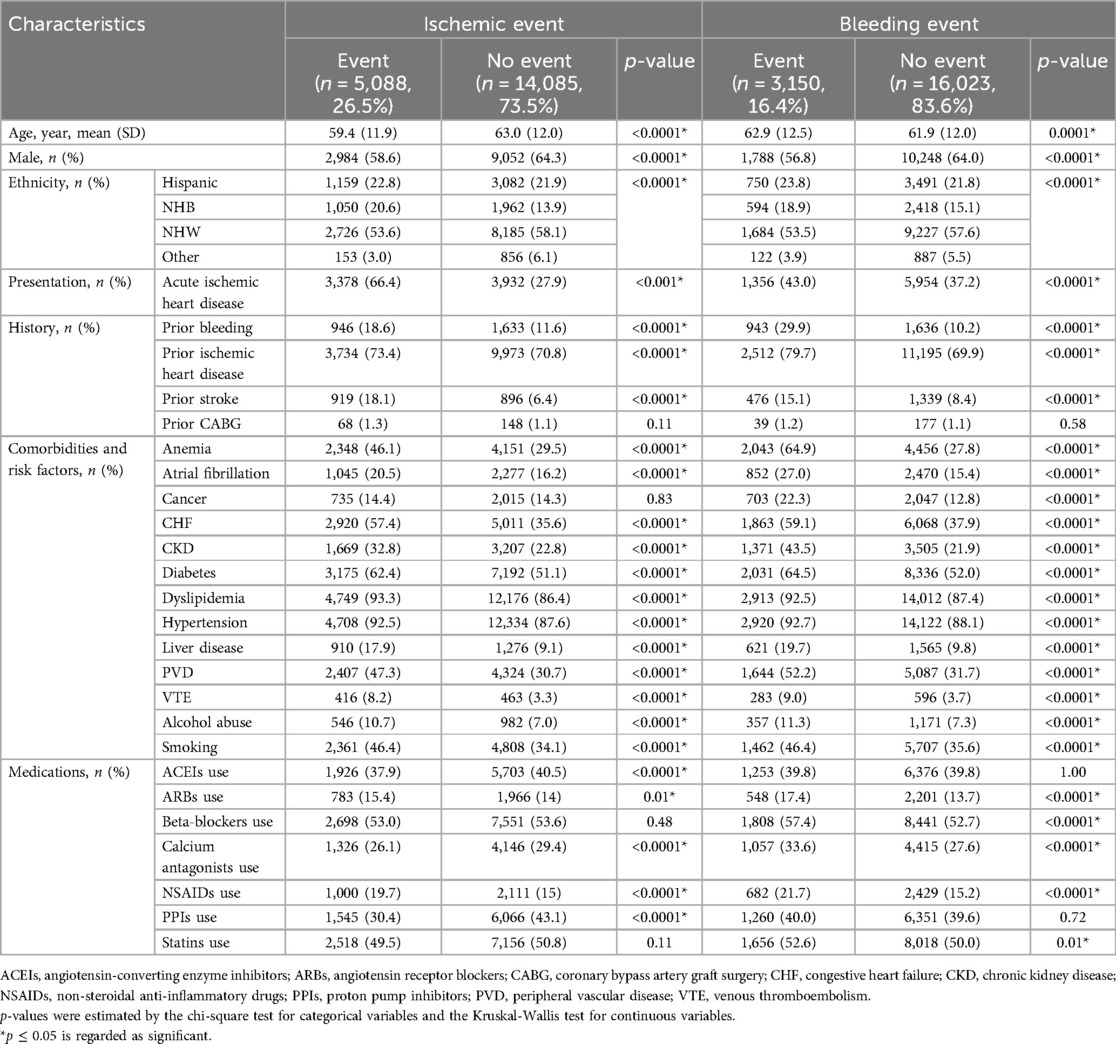
Table 1. Baseline characteristics for patients with vs without events (ischemic and bleeding) from 0 to 12 months in the selected cohort of oneFlorida dataset (N = 19,713).
Regarding bleeding events, patients who experienced a bleeding event were older than those who did not (62.9 vs. 61.9, p = 0.0001). Similar to the ischemic event findings, most diagnostic characteristics were more prevalent in patients with bleeding events, except for prior CABG, which showed no significant difference. For medication use in the context of bleeding events, except for ACEIs and PPIs, which showed no significant difference between the event and non-event groups, there is a significantly higher usage of ACEIs, beta-blockers, calcium antagonists, NSAID, and statin drugs in the event group vs. non-event group.
3.2 Model performanceWe assessed the performance of our proposed model against several baselines using the Ctd-index at multiple time intervals post-PCI, specifically in 1, 2, 3, 6, and 12 months.
For the ischemic event prediction, our model consistently outperformed the baseline models (DeepSurv, DeepHit, and SurvTRACE) (as shown in Table 2). Initially, in the first month, the Ctd-index for our model was 0.88, higher than DeepSurv (0.84), DeepHit (0.87), and SurvTRACE (0.87). This trend continued with Ctd-index scores in the second month (0.85), third month (0.84), sixth month (0.83), and 12th month (0.80), consistently surpassing the corresponding baseline values. Notably, the performance advantage was more pronounced in shorter prediction windows.
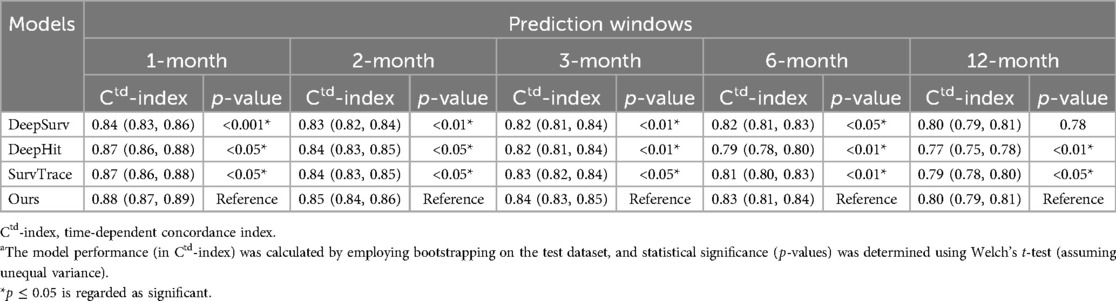
Table 2. Model performance (with 95% CI) across different prediction intervals for the ischemic eventa.
For the bleeding event prediction, similarly, our model demonstrated superior performance (as shown in Table 3). In 1 month, our model achieved a Ctd-index of 0.82, surpassing DeepSurv (0.79), DeepHit (0.81), and SurvTRACE (0.80). This superiority persisted through the 2nd-month (0.81), 3rd-month (0.82), 6th-month (0.82), and 12th-month (0.77) evaluations, generally outperforming all baselines. For both ischemic and bleeding event predictions, the superiority of our model was statistically significant with most p-values less than 0.001.
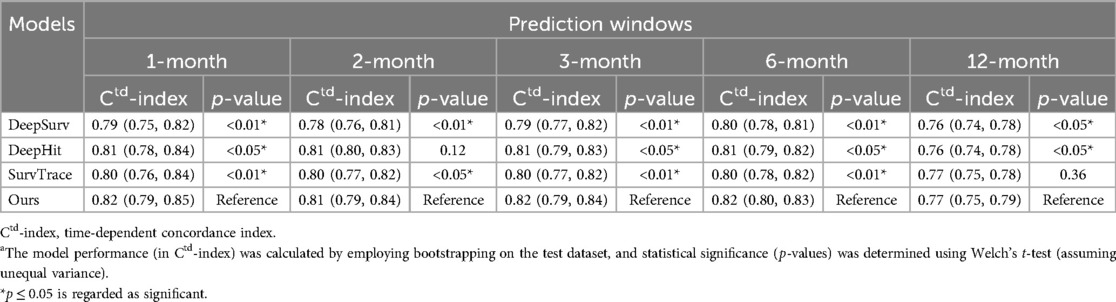
Table 3. Model performance (with 95% CI) across different prediction intervals for the bleeding eventa.
The weights assigned to the loss function are as follows: For ischemic event prediction, the weights are 0.3 for LMSE, 0.14 for LBCE, and 0.95 for LPC; For bleeding event prediction, the weights are 0.9 for LMSE, 0.14 for LBCE, and 0.89 for LPC. More hyper-parameters of the model are detailed in Supplementary Table S1.
3.3 Calibration curvesWe plotted the model calibration curve to assess how well the predicted probabilities of the endpoints align with the actual observed frequencies at the end of 12 months. In Figure 3, the line chart (top) shows the ratio of actual positives in each interval of predicted probabilities, while the histogram (bottom) depicts the relative frequency of predicted probabilities. Figure 3A demonstrates that the predicted probability of ischemic events accurately reflects the actual likelihood, as the predicted probability (red solid line) closely follows the actual likelihood (blue dashed line). The predicted probability for ischemic events ranges from 0 to 1, with a descending frequency. Figure 3B shows the calibration curve for bleeding events, with predicted probabilities mostly between 0.1 and 0.5.
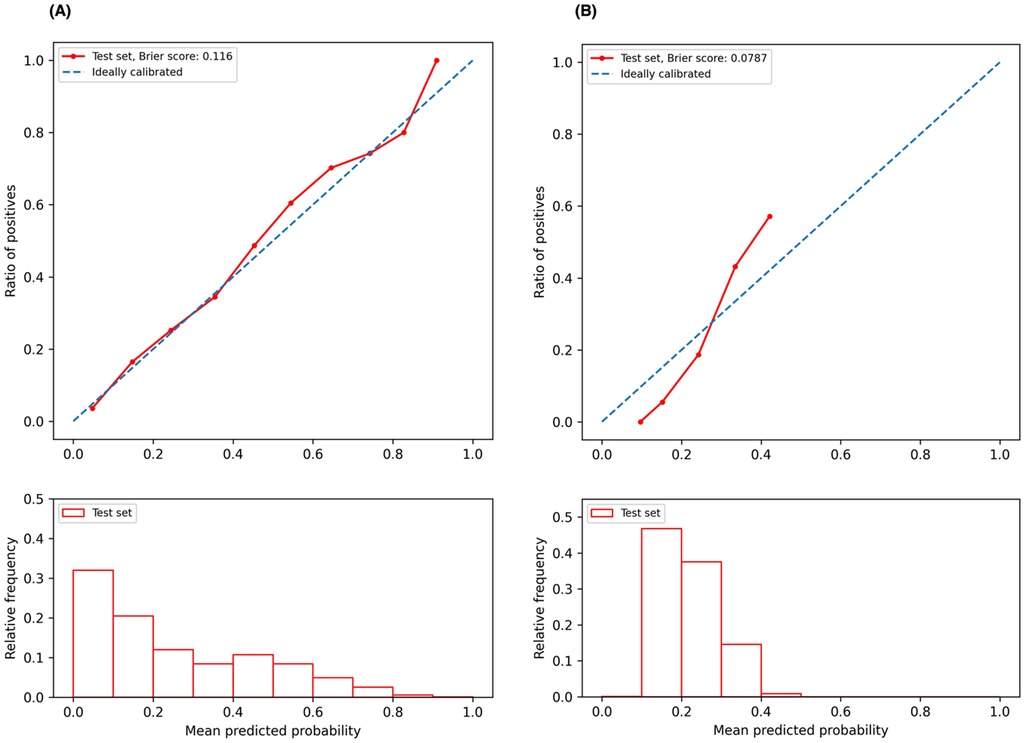
Figure 3. Calibration curves. (A) Calibration curve for ischemic event prediction at the end of 12 months; (B) calibration curve for bleeding event prediction at the end of 12 months.
4 DiscussionOur study demonstrates significant advancements in the field of post-PCI risk assessment for DAPT duration management. The transformer-based architecture coupled with auto-encoder and contrastive learning is adept at processing complex, large-scale datasets while capturing intricate patterns that are often missed by traditional machine learning models. This capability is crucial for understanding the complex dynamics of patient data post-PCI, allowing for a more accurate analysis of adverse endpoint risks. Moreover, our model performance is bolstered by the use of multiple loss functions that concurrently optimize different aspects of the prediction task. This multi-objective approach allows for a more balanced model that does not overly prioritize one predictive goal over another, thus maintaining a holistic view of the patient's risk profile.
By integrating the survival analysis mechanism, our model allows flexibility in risk assessment at any specific time point within the first year after PCI. This feature is particularly beneficial as it supports dynamic risk evaluation, adapting to the evolving clinical status of patients over time. Our model not only forecasts the probability of adverse events on the index date but also adjusts these predictions as new data becomes available, offering a robust tool for continuous patient monitoring.
The practicality of our model in clinical environments is facilitated by its requirement for a limited number of input features. These features, encompassing patients' demographics, clinical presentations, medical history, and concurrent medications, have been carefully chosen to balance comprehensiveness with easy data collection. This selectivity ensures that the model remains both user-friendly and efficient, minimizing the burden on healthcare providers while still capturing the necessary data to assess patient risk accurately. The ability of our model to provide timely and tailored risk assessments holds promise to enhance personalized treatment strategies. For instance, by identifying patients at higher risk of complications at any point within the year post-PCI, clinicians can tailor the duration of DAPT and other therapeutic interventions. This approach not only aims to optimize patient outcomes by preventing over or under-treatment but also contributes to the broader goals of personalized medicine, where treatment plans are customized to individual patient needs.
The strengths of our predictive model are multifaceted: (1) Excellent Predictive Accuracy. Our model consistently outperforms the state-of-art deep learning-based survival models, as demonstrated in Tables 2, 3, where most p-values are <0.05. Specifically, the model achieves C-index ranging from 0.88 to 0.80 for ischemic prediction and 0.82–0.77 for bleeding prediction across different prediction intervals. In comparison, the DAPT score achieves a C-index of 0.70 for ischemia and 0.68 for bleeding (7), indicating our model improves predictive accuracy by over 10%. (2) Enhanced Flexibility and Dynamic Prediction Capability: Unlike clinical trial-derived scores which often lack adaptability, our model is built on real-world data, enabling it to accommodate patients' evolving clinical status over time. Leveraging a deep survival infrastructure supported by the piecewise constant hazard loss, the model allows for dynamic risk evaluation at any specific time point within the prediction window following PCI. As new evidence emerges and clinical guidelines evolve, encompassing considerations for shorter DAPT duration, treatment de-escalation, and monotherapy (11, 36–39), there is an increasing need for more granular and personalized predictions. Our AI-driven approach, trained on large-scale data, captures the subtle nuances and delivers precise, individualized risk assessments, making it well-suited for addressing these emerging clinical demands.
The calibration curve serves as an e
留言 (0)