
記住我





A retrospective review of the institutional PACS database identified endovascular procedures performed between 2010 and 2020. Inclusion criteria were patient age greater than or equal to 18 years at the time of the endovascular procedure, angiographic studies of the abdominopelvic arterial structures, and a cross-sectional study in the PACS within 150 days of the index angiographic study. Patients with post-surgical vascular anatomy due to visceral organ transplant were excluded.
Individual DSA sequences from each study were selected for inclusion in the experimental dataset. The requirement for cross-sectional imaging was specified to allow direct comparison of the conventional angiography for more accurate anatomic location labeling. These CT and MRI images were not included in the experimental data. Manual labeling of the DSA sequences was performed separately by two interventional radiology attending physicians (A.S., R.G.) with 4 and 5 years of post-fellowship experience. Individual DSA series representing the abdominal aorta, celiac trunk, superior mesenteric artery (SMA), inferior mesenteric artery (IMA), right external iliac artery (EIA), and left EIA were selected and labeled from the identified studies. Unsubtracted angiography sequences and sequences acquired from other anatomic locations were excluded. Individual images in each DSA series were additionally labeled as “key” or non- “key.” “Key” images were defined as the set of sequential images in which the parent vessel and first bifurcation were opacified (Fig. 1). The remainder of the images in the sequence was labeled as non- “key.” Discrepancies between the labels were resolved subsequently by consensus. Interobserver agreement of the labeling was assessed using Cohen’s kappa coefficient for the classification of the angiographic location, and separately for the key images, without weighting either of the domain expert labelers.
Fig. 1
“Key” image labeling. A 9-image sequence with “key” images framed in gold. All images in an angiographic sequence in which the parent vessel and first bifurcation and opacified are labeled “key”
We formed our modeling dataset by randomly selecting and labeling a cohort of 230 procedures from 160 unique patients. Based on a class analysis demonstrating a substantial imbalance in the IMA class, these data were supplemented with an additional 46 procedures from 45 patients curated to balance the label classes. The additional studies were identified for inclusion through a search of the associated procedure report for the text phrase “inferior mesenteric.”
The angiographic sequences were split randomly into training (70%), validation (15%), and testing (15%) partitions, each containing non-overlapping patients. A split with the most even class balance across the training, validation, and testing partitions was chosen through an automated search of 9e6 random permutations of the patients and procedures (see Supplemental Materials for details).
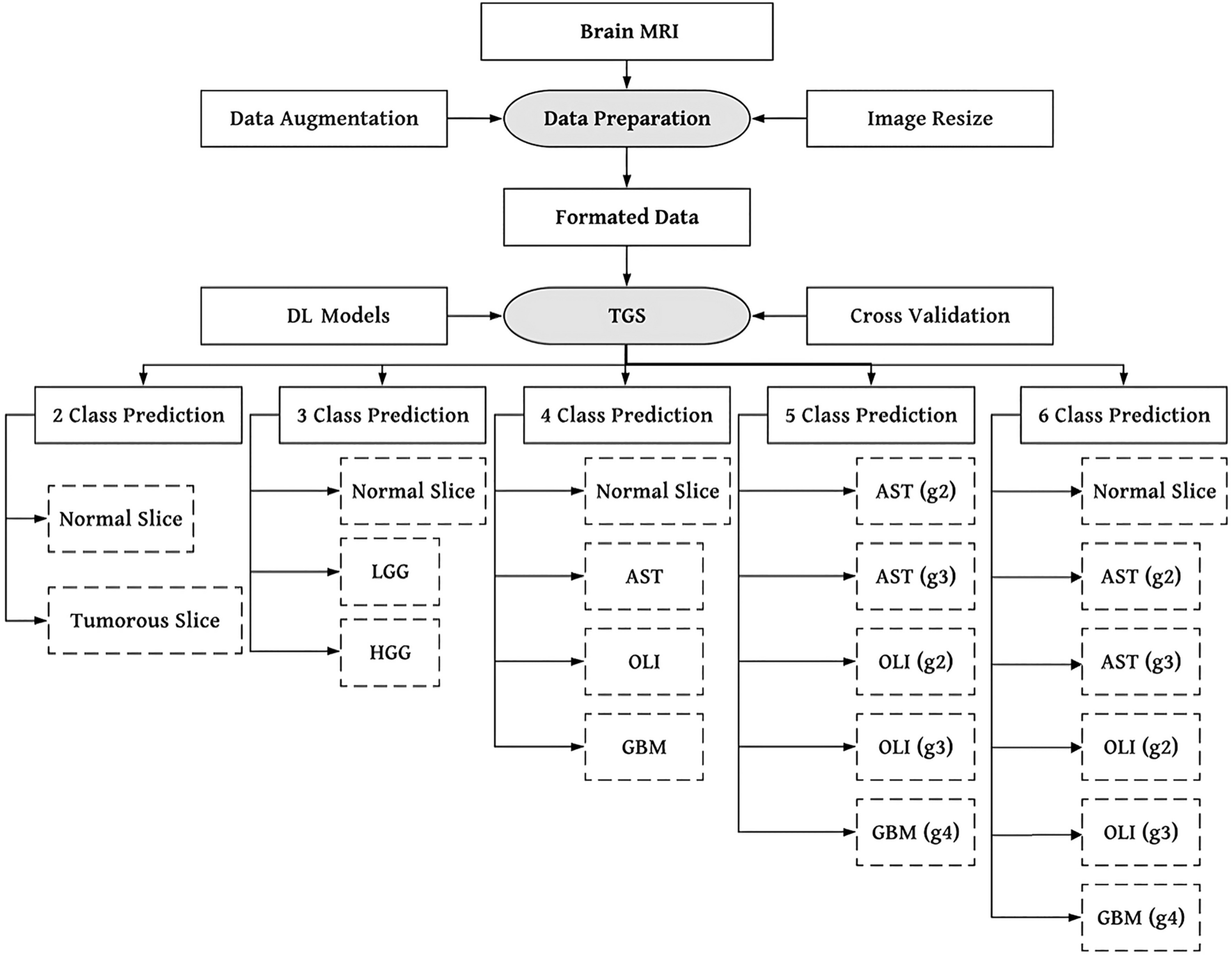
Two related datasets were constructed to develop and evaluate deep learning models for location classification (Fig. 2). Dataset DFull contains all images from each angiographic sequence, including both “key” and non- “key” labeled images. Dataset DKey, a subset of DFull, contains only the images labeled as “key.” All images from a given sequence contain the same anatomic location label.
Fig. 2
Datasets for training, validation, and testing. The angiographic sequences were split randomly into training (70%), validation (15%), and test (15%) sets, each containing non-overlapping patients. Sequences with more than 50 images were truncated at 50 images. Dataset DFull is comprised of all individual images from the 205 unique patients and 276 procedures after splitting into training, validation, and test sets and sequence truncation. Dataset DKey is a subset of DFull comprised of the “key” images only for each sequence
Technical DetailsAll image processing, model development, training, and testing were performed on a machine with an Ubuntu 20.04.5 operating system, an Intel Xeon Gold 6226R CPU, and an NVIDIA A100 graphical processing unit with CUDA 11.2 and cuDNN 8.4. Code was written in Python 3.9.12, leveraging the MONAI 1.2.0, Pandas 1.4.3, and PyTorch 2.0.1 packages.
Image and Sequence Pre-processingImage pre-processing was performed using the Matplotlib 3.5.2 and Open CV 4.7.0.72 packages. To reduce GPU memory requirements and match the input specification in the downstream deep learning analyses, the DICOM image data, originally with a 16-bit pixel depth and 1024 × 1024 matrix size, were resized to a 256 × 256 matrix size for each individual image in a DSA sequence and saved in the default JPEG format with an 8-bit pixel depth. Sequences exceeding 50 images were capped at 50 for computational efficiency and consistency across deep learning models. The absence of patient identifying information was confirmed through manual review.
Model Architectures and DevelopmentTwo distinct classification architectures were developed to localize the angiographic anatomy of DSA sequences. The first architecture aggregates individual image predictions, and models utilizing this architecture will be henceforth referred to as Mode models. The second architecture utilizes a multiple instance learning (MIL) framework and will be referred through the remainder of the text as a MIL model. Schematic representations of two model architectures are provided in Fig. 3.
Fig. 3
Schematic representations of the deep learning model architectures. A Mode Model. The angiographic location of individual images is predicted using a ResNet50 convolutional neural network (CNN) and fully connected linear classifier. The model accepts a DSA sequence of an arbitrary number of k images. The prediction for the DSA sequence is calculated by the mode of the individual predictions. B MIL Model. The extracted features of images from ResNet50 CNN are supplied to a transformer encoder and subsequently an attention mechanism. The model accepts a sequence of n images, where for sequences < n, the sequence is padded with blank images. The model predicts the anatomic location of the sequence and the “key” diagnostic images within the sequence based upon the attention weights
Mode ModelsClassification models to predict the anatomic location of individual angiographic images were constructed. To generate a prediction of the anatomic location of the entire DSA sequence, a mode operation was performed across the combined individual image predictions [7]. Two distinct mode models were developed. Mode ModelFull utilized training and validation partitions of the entire data, DFull. Similarly, Mode ModelKey utilized only “key” images contained in Dataset DKey.
The base models for individual image classification, Fig. 3A, utilize the ResNet50 convolutional neural network (CNN) [8] which has demonstrated favorable performance in medical image classification applications. Experimentation was performed with alternate model architectures including VGG-16 [9], Inception-V3 [10], Swin-Transformer [11], and EfficientNet-B7 [12] and demonstrated no substantial performance improvement over ResNet50. The training approach, data augmentation strategies, and hyperparameters are included in the Supplemental Materials.
Multiple Instance Learning ModelA deep multiclass MIL model was developed to identify the anatomic location and provide a weighted score of the contribution of each individual image to the classification based on an attention mechanism [13]. The challenges of angiographic sequence classification resembles multiple weakly supervised tasks solved with MIL architectures and closely parallels whole slide image (WSI) pathology classification [14,15,16]. As the size of WSI limits computation on the entire image, algorithmic approaches frequently divide the image into smaller computationally manageable image patches. Noting the pathologic diagnosis may depend on patterns in spatially separated patches, algorithms must account for patch dependencies. In DSA sequences, a single image is often insufficient to infer the anatomic location. WSI patch dependencies are, therefore, analogous to the anatomic information contained across individual images in an angiographic sequence. Thus, our MIL model leverages a deep learning architecture demonstrating state-of-the-art performance on WSI pathology classification [17].
Paralleling the mode model approach, the ResNet50 CNN, pre-trained on ImageNet, serves as the classification backbone for feature extraction. A transformer encoder is attached to the end of that backbone after average pooling to account for dependencies in features identified in individual images within a sequence. The output of the transformer is fed into an attention mechanism that computes weights using a multilayer perceptron network. These aggregated features are subsequently passed to a linear classifier function to perform multiclass classification (Fig. 3B).
The MIL model architecture implemented is permutation-invariant by design. The temporal relationship between images within the sequence is not captured in this architecture as the inputs to both the transformer encoder and attention mechanism do not contain information on the sequential position of the image. This study’s focus on accurate sequence-level classification, rather than modeling temporal dependencies across images, aligns with the capabilities of the MIL architecture.
The training approach, data augmentation strategies, and hyperparameters are described in the Supplemental Materials.
Model Evaluation and Statistical AnalysisDiagnostic performance for each model was evaluated on held-out test data. Statistical analyses were conducted using the scikit-learn 1.3.2 [18] and statsmodels 0.14.1 [19] python packages.
The primary performance endpoint of the study is the overall multiclass classification accuracy of the Mode models, trained with the full (DFull) or “key” image only (DKey) datasets, and the MIL model, trained with the full dataset. To assess the impact of excluding non- “key” images during training and testing, each Mode model is evaluated using both DFull and DKey datasets. The multiclass classification accuracies are compared for statistically significant differences using McNemar’s test [20]. P-values less than 0.05 were considered statistically significant. Frequency-weighted precision, recall, and F1 measures for the overall test data and precision, recall, and F1 measures per class are additionally studied. Confidence intervals (CI) for the multi-class measures were computed by bootstrapping the test data over 1000 iterations.
For evaluation of the MIL algorithm attention weights, images corresponding to the algorithmically generated top-5 attention weights were compared with manually labeled “key” images for overlap. The percent overlap was quantified as the number of images in common between the top-5 weighted images of the MIL algorithm and the “key” images divided by the minimum of 5 or the total number of key images.
留言 (0)