
記住我
Breast cancer, which is a prevalent malignant tumor affecting women globally, exhibits considerable heterogeneity in biological characteristics and clinical outcomes.[1,2] Recent cancer epidemiological data indicate a rising trend in the cases of breast cancer, which has surpassed lung cancer as the most diagnosed cancer worldwide and is the leading cause of cancer-related deaths in women.[3] Consequently, breast cancer has emerged as a public health concern on a global scale. Triple-negative breast cancer (TNBC) is a molecular subtype of breast cancer,[4,5] constituting 10–20% of all breast cancer cases and lacking the expression of estrogen receptor, progesterone receptor, and human epidermal growth factor receptor 2.[6] TNBC is highly aggressive and prone to distant metastasis, and patients with TNBC have an average survival time of approximately 1 year after metastasis or postoperative recurrence.[7,8] Traditional surgical and cytotoxic chemotherapy interventions have shown limited efficacy in improving patient prognosis. As biologically targeted therapies have demonstrated success in treating other cancers, identifying potential therapeutic targets for TNBC has been emphasized in recent years.[9-12]
Considerable research has focused on discovering and exploring transcription factors related to cancer treatment and diagnosis. Transcription factors are a class of proteins that bind to DNA and interfere with the transcription process through specific structural sequences. Many transcription factors, particularly when overactivated, are integral to the development of tumor cells.[13] Some transcription factors can serve as markers for tumor diagnosis, treatment, and prognosis. Tong et al.,[14] proposed that the level of Krüppel-like factor 5 is considerably higher in breast cancer tissues than in adjacent normal tissues, associating it with early recurrence and early death and thus confirming its major role in the growth of breast tumor cells. Wang et al.,[15] confirmed the substantially high expression of paired-like homeodomain transcription factor 1 (PITX1) in breast cancer tissues. PITX1 shows a significant negative correlation with prognosis. Davis et al.,[16] reported that the expression level of forkhead box A1 (FOXA1) in patients with TNBC was significantly lower than in patients without TNBC, suggesting that FOXA1 is a diagnostic indicator for TNBC and may even be an important target for TNBC treatment.
Weighted gene co-expression network analysis (WGCNA) is a biological method that analyzes vast amounts of gene expression data, identifies gene clusters with highly correlated expression levels, and associates them with phenotypic traits.[17] In our study, modules related to disease-free survival (DFS) in patients with TNBC were first identified using WGCNA. The biological functions of genes within each module were determined through Gene Ontology (GO) and Kyoto Encyclopedia of Genes and Genomes (KEGG) analyses. The modules were then intersected separately with the Human Transcription Factor Database (HumanTFDB), and overlapping genes in each module were considered potential transcription factors. Through survival analysis, three potential transcription factors were identified as hub transcription factors. Bioinformatic analysis, immunohistochemical staining, quantitative reverse transcription polymerase chain reaction (qRT-PCR), and Western blotting confirmed the reliability of the identified hub transcription factors.
MATERIAL AND METHODS Data sources, selection, and preprocessingWe downloaded data from the Gene Expression Omnibus (GEO) website (http://www.ncbi.nlm.nih.gov/geo/ ). The dataset met the following criteria: (1) samples comprising patients with TNBC, (2) number of samples exceeding 15, and (3) clinical features included prognostic information.[18] On the basis of these criteria, we selected GSE97342 as our dataset for analysis. The matrix file for GSE97342 and its associated clinical information were downloaded. The matrix file was converted to a matrix format. The columns represented genes, and the rows represented the samples. Genes with small standard deviations were filtered out, abnormal or outlier samples were excluded, and clinical characterization data were correlated with gene expression. The flowchart of this study is shown in Figure 1. We utilize the online flowcharting software ProcessOn for flowcharting.
Export to PPT
Network construction and module selectionWe used the WGCNA package in R (Ross Ihaka and Robert Gentleman, Auckland, New Zealand) to construct a co-expression network with a one-step method. First, based on the criterion of approximate scale-free topology, we used the pickSoftThreshold function to determine the soft-threshold power β, which enhanced the network’s connectivity. We then constructed co-expression networks using the blockwiseModules function, dividing genes into different modules by setting minModuleSize at 30. Modules were identified through hierarchical clustering and dynamic tree cut, and similar modules were merged (MEDissThres = 0.25). The module eigengene represented the gene expression profile of the entire module. We correlated these eigengenes with clinical variables to find the most relevant modules. Gene significance (GS) referred to the correlation between gene expression and clinical variables, and high GS values indicated strong correlation. Ultimately, we identified modules relevant to the clinical variable DFS, and genes in these modules were extracted for further analysis.
Functional enrichment analysisWe used the online tool Bioinformatics (https://www.bioinformatics.com.cn/ ) for GO and KEGG pathway analyses. GO analysis provided the biological functions of each module, and KEGG analysis identified the signaling pathways associated with each module.
Identification of potential transcription factors by intersection with HumanTFDBTo identify candidate transcription factors, we intersected the obtained modules with HumanTFDB (http://bioinfo.life.hust.edu.cn/AnimalTFDB/#!/ ).[19] The Draw Venn Diagram tool (http://bioinformatics.psb.ugent.be/webtools/Venn/ ) identified overlapped genes, which were considered potential transcription factors.
Survival analysis of potential transcription factors and identification of hub transcription factorsPotential transcription factors within the modules significantly associated with DFS were included in Cox regression models for univariate analysis. Transcription factors with P < 0.05 were identified as hub transcription factors. The hazard ratios (HRs) for these hub transcription factors determined whether they were protective or risk factors for the DFS of patients with TNBC. The Gene Expression Profiling Interactive Analysis 2 (GEPIA2) online tool (http://gepia2.cancer-pku.cn/#index ) was used in drawing Kaplan–Meier survival curves of hub transcription factors.
Bioinformatic analysisWe used university of california santa cruz xena (UCSC XENA) (https://xenabrowser.net/datapages/ )[20] and The Cancer Genome Atlas (TCGA) database (https://cancergenome.nih.gov ) to explore the expression levels of hub transcription factors in breast cancer and other cancers and to analyze receiver operating characteristic (ROC) curves in breast cancer. Four online databases, namely harmonizome (https://maayanlab.cloud/Harmonizome/), Gene Regulatory Network database (GRNdb) (http://grndb.com/ ), ChIP-Atlas (http://chip-atlas.org/ ), and Cistrome Data Browser (http://cistrome.org/db/#/ ), were used in predicting the downstream target genes of hub transcription factors. Expression levels, ROCs, oncogenic effects, and correlations with hub transcription factors were verified. Kaplan–Meier plotter (http://kmplot.com/analysis/ )[21] was used in plotting survival curves, and Tumor Immune Estimation Resource (TIMER) (https://cistrome.shinyapps.io/timer/ ) was used in analyzing immune cell infiltration in tumor tissues.[22,23]
Acquisition of TNBC samplesWe retrospectively collected samples from 57 women with TNBC who underwent breast surgery from 2015 to 2017. The patients were followed up regularly after the operation, with 30 patients relapsing and 27 not. Formalin-fixed paraffin-embedded (FFPE) tissues from these patients were sliced into 4–6 μm-thick sections. In addition, we collected 20 fresh pairs of TNBC tissues and matched para-carcinoma tissues. The collection of specimens required the consent of the patients and approval from the Fourth Hospital of Hebei Medical University’s ethics committee. In addition, this study adhered to the principles of the Helsinki Declaration.
Immunohistochemical stainingImmunohistochemical staining was performed to validate the expression levels of the hub transcription factors. FFPE tissue slides were sequentially deparaffinized with xylene (1330-20-7, Sigma-Aldrich, Chengdu, China), hydrated with gradient ethanol (64-17-5, Yongda, Tianjin, China), and placed in citric acid antigen repair solution (YMMY812J, Beyotime, Beijing, China) at a high temperature and pressure. The repaired slides were added with an endogenous peroxidase blocker (ZY1028, Zeye, Shanghai, China) and incubated for 25 min, followed by the addition of the primary antibody (goat anti-forkhead box D1 [FOXD1] polyclonal antibody 1:200, Abcam Company, ab129324, Shanghai, China; rabbit anti-aryl hydrocarbon receptor nuclear translocator 2 [ARNT2] polyclonal antibody 1:100, Absin Company, abs118296, Shanghai, China; rabbit anti-zinc finger protein 132 [ZNF132] polyclonal antibody 1:100, ThermoFisher Company, AB-2649961, Waltham, USA) was added, and incubation was continued at 4°C for at least 12 h. A reaction enhancer (MYZH922, DAKO, Copenhagen, Denmark) was added, the slides were incubated for 20 min at room temperature before the secondary antibody (A-11034, ThermoFisher, Waltham, USA) was added, and incubation was continued for 30 min. Evenly applied the prepared DAB coloration solution (DA1016, Solarbio, Beijing, China) onto the spun-dry slides, observed the color development in real-time under the microscope, and adjusted the color development time based on the intensity of staining. The final step involved using hematoxylin (BBP03941, Biobiopha, Yunnan, China) for staining and scoring the slides.
The scores of the slides were determined by the manual quantitative analysis of 10 randomly selected ×40 high-magnification fields. The scoring method was as follows: (1) percentage of positive cells: 1 for ≤25%, 2 for 26–50%, 3 for 51– 75%, and 4 for >75%; (2) staining intensity: 0 for no staining, 1 for light yellow, 2 for brown-yellow, and 3 for tan; (3) total score was the product of the positive cell rate score and staining intensity score: 0 for negative, 1–4 for weak positive, and 4–12 for strong positive. A score below 6 was considered low expression, whereas a score of 6 or above was considered high expression.[24] Each slide was independently evaluated by two experienced pathologists who had no information about the patients.
RNA extraction and qRT-PCR analysisTotal RNA was extracted from TNBC and paired para-carcinoma tissues with an RNA extraction solution (15596018, TRIzol Reagent, ThermoFisher, Waltham, USA). TransScript One-Step gDNA removal and cDNA synthesis SuperMix reverse transcription kit (PC7002, Fermentas, Beijing, China) was used in synthesizing cDNA. qRT-PCR was performed using a SYBR Green polymerase chain reaction (PCR) kit (RR420A, TaKaRa, Dalian, China) according to the manufacturer’s instructions. Glyceraldehyde-3-phosphate dehydrogenase served as an internal reference, and the 2−ΔΔCt method was used in calculating the relative expression of the transcription factors. Table S1 shows the primer sequences for qRT-PCR.
Extraction of breast tissue protein and western blottingSix pairs of TNBC and adjacent normal tissues were selected. Approximately 50 mg of tissue was cut and placed in a 1.5 mL eppendorf (EP) tube with 500 μL of RadioImmunoprecipitationAssay (RIPA) lysate (HC1235, Solarbio, Beijing, China) and protease inhibitor (ab146286, Solarbio, Beijing, China). The tissues were homogenized using a tissue grinder (Sangon Biotech, Shanghai, China) on ice. The homogenate was centrifuged, and the supernatant was collected. Protein concentration was determined using a bicinchoninic acid (BCA) protein assay kit (23225, Solarbio, Beijing, China), and the proteins were denatured at 100°C for 5 min and then used for Western blotting. 30 μg of tissue protein was separated by 10% sodium dodecyl sulfate polyacrylamide gel electropheresis (SDS-PAGE) and transferred to a polyvinylidene fluoride (PVDF) membrane (LC2002, ThermoFisher, Waltham, USA). The membrane was blocked with 5% skim milk at room temperature for 1 h, followed by overnight incubation at 4°C with antibodies against FOXD1, ARNT2, and ZNF132 (1:1000, Abcam Company, Shanghai, China). After another round of incubation with the secondary antibodies, the membrane was infiltrated in a 1:1 ratio of developer solutions A and B (IN0005, ZETA life, USA) on a Bio-Rad ChemiDoc™ XRS+ System (BIO-RAD, California, USA) and imaged through automated exposure with the chemiluminescence instrument.
Statistical analysisCategorical and continuous variables were analyzed using a Chi-square test. Comparisons of data between two groups were made using the Student’s t-test, and comparisons of data between multiple groups were made using analysis of variance. Hazard Ratios for candidate transcription factors were calculated by univariate Cox regression analysis. Kaplan–Meier survival curves were plotted by the “survival” and “survminer” packages in R software. Performed Western blotting band grayscale analysis using Image J software (National Institutes of Health, MD, USA) and then created a bar chart in GraphPad Prism 9.0 (GraphPad Software, CA, USA) software, and P < 0.05 was considered statistically significant.
RESULTS Data download and preprocessingGSE97342 dataset was downloaded from the GEO website. First, raw gene expression data were normalized in R using the Fragments per kilobase of exon model per Million mapped fragments (FPKM) approach. Duplicate genes were removed, and the top 5000 genes with the highest standard deviation were selected for the construction of co-expression networks. The 28 TNBC samples in GSE97342 were clustered for the identification of outliers. A hierarchical clustering tree was constructed with a height cutoff value set at 200, and no abnormal specimens were found [Figure 2a]. Finally, 11 clinical features were correlated with gene expression [Figure 2b].
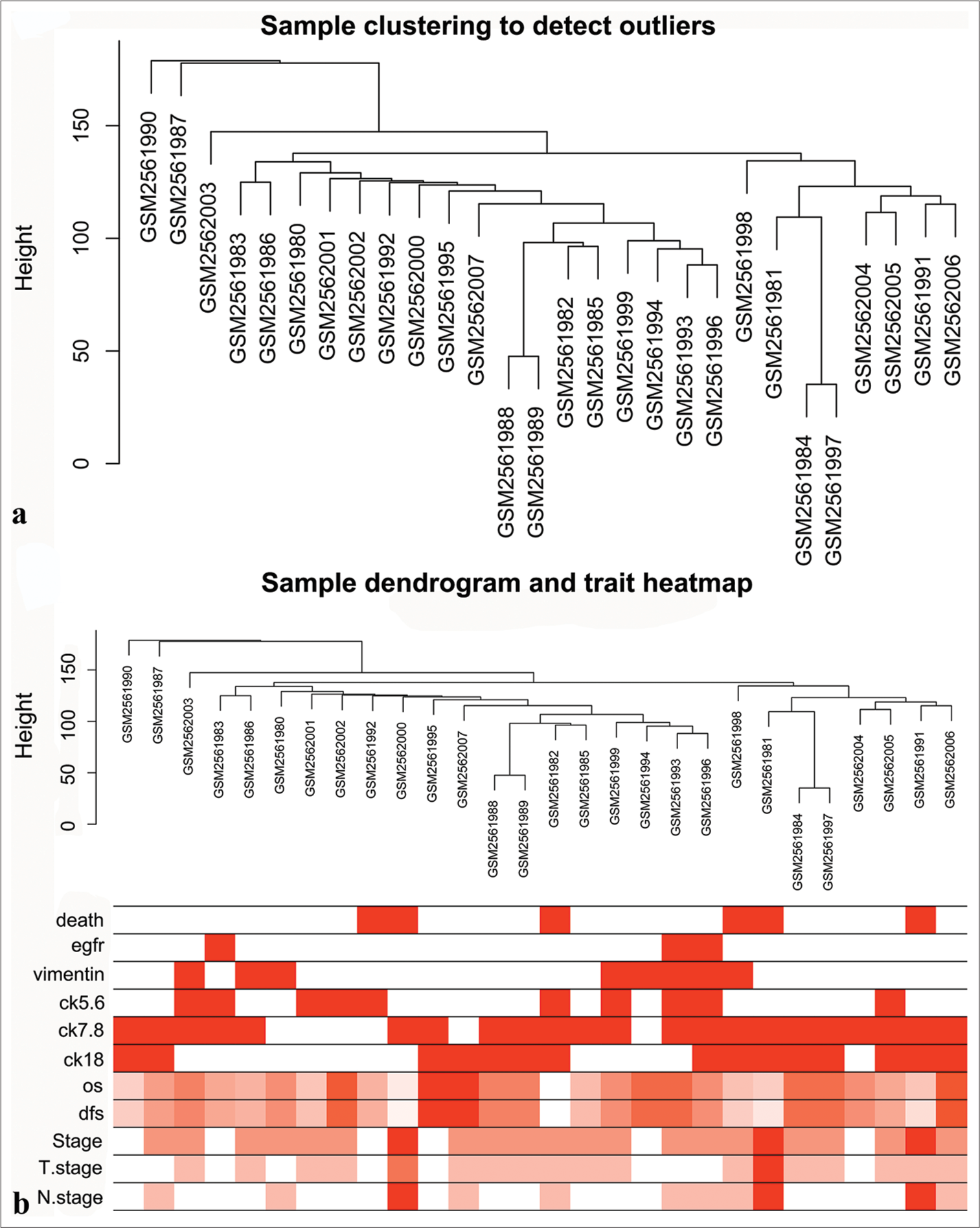
Export to PPT
Network construction and module identificationWe first determined the soft threshold power β to be 6 (scale-free R2 = 0.84) using pickSoftThreshold function, which improved network connectivity [Figure 3a-d]. Using the one-step method, we obtained a total of 15 co-expression modules by setting the module size at 30 and the deepSplit parameter at 2, indicating medium sensitivity. The modules included black, blue, pink, brown, cyan, red, gray, green, purple, yellow, tan, salmon, green-yellow, turquoise, and magenta [Figure 3e and f]. The genes within each module are listed in Table S2.
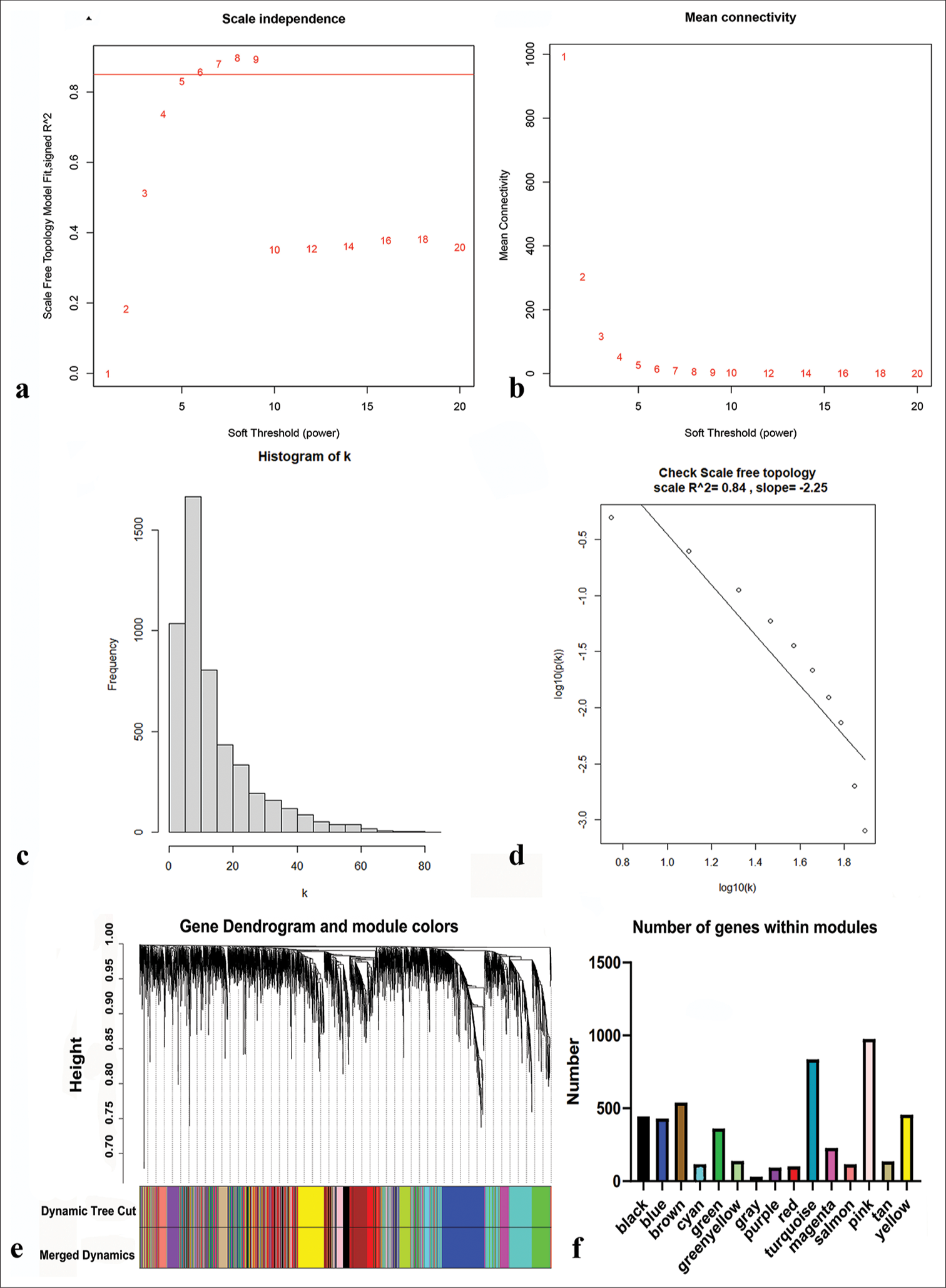
Export to PPT
Selection of DFS-related modulesThe trait-heat map illustrated the correlation between each module and the variables under consideration. From this analysis, three modules stood out as strongly associated with the variable disease-free survival: Green-yellow, magenta, and turquoise modules. Notably, the green-yellow module (correlation = −0.44, P = 0.02) and magenta module (correlation = −0.38, P = 0.05) exhibited negative correlations with DFS, while the turquoise module (correlation = 0.29, P = 0.1) showed a positive correlation [Figure 4]. In addition, these three modules demonstrated high GS for DFS in comparison with the others [Figure 5a]. Subsequently, we constructed a weighted network of genes within each module, visualizing it through a heatmap [Figure 5b] and conducted hierarchical clustering of the modules [Figure 6].
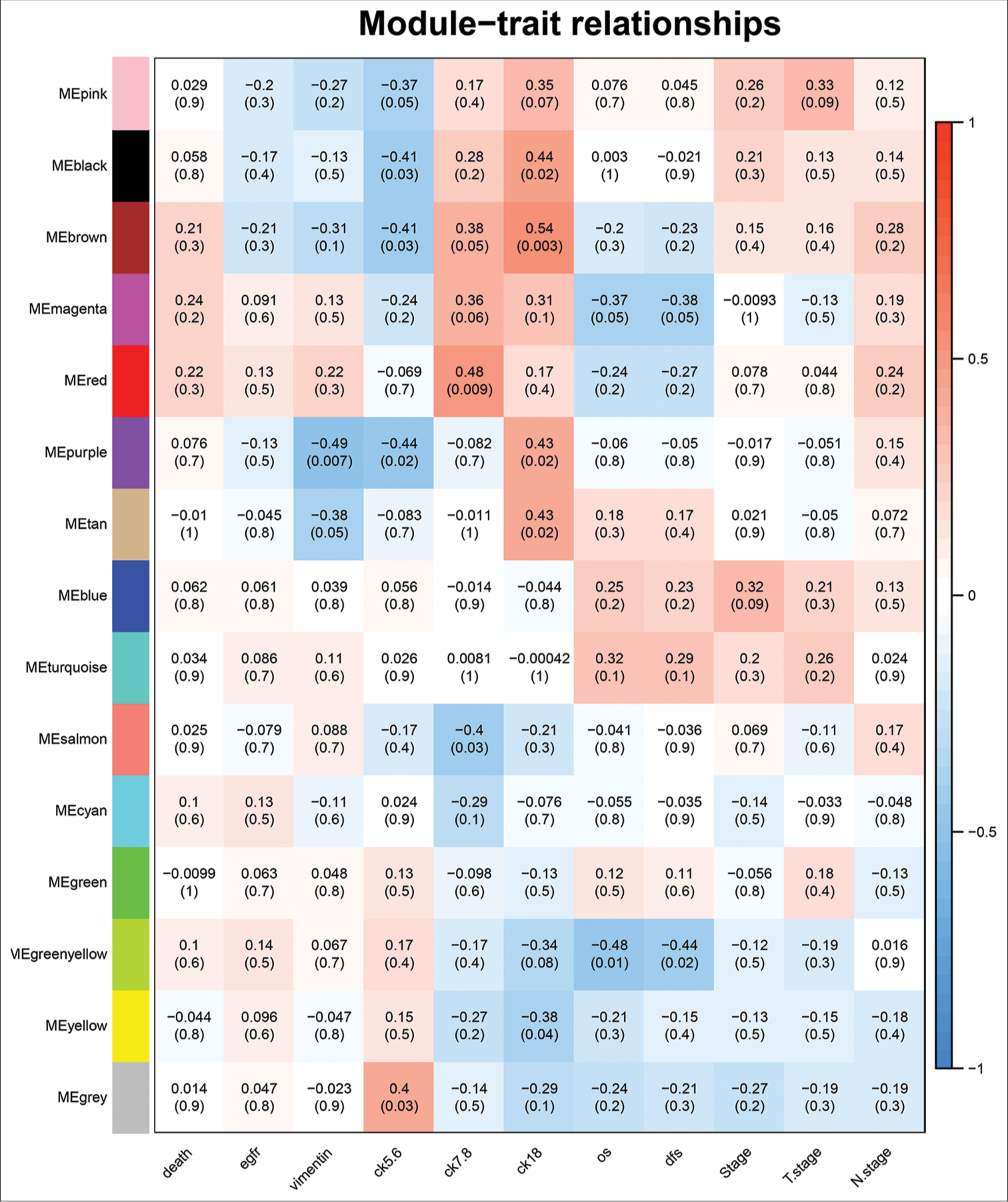
Export to PPT
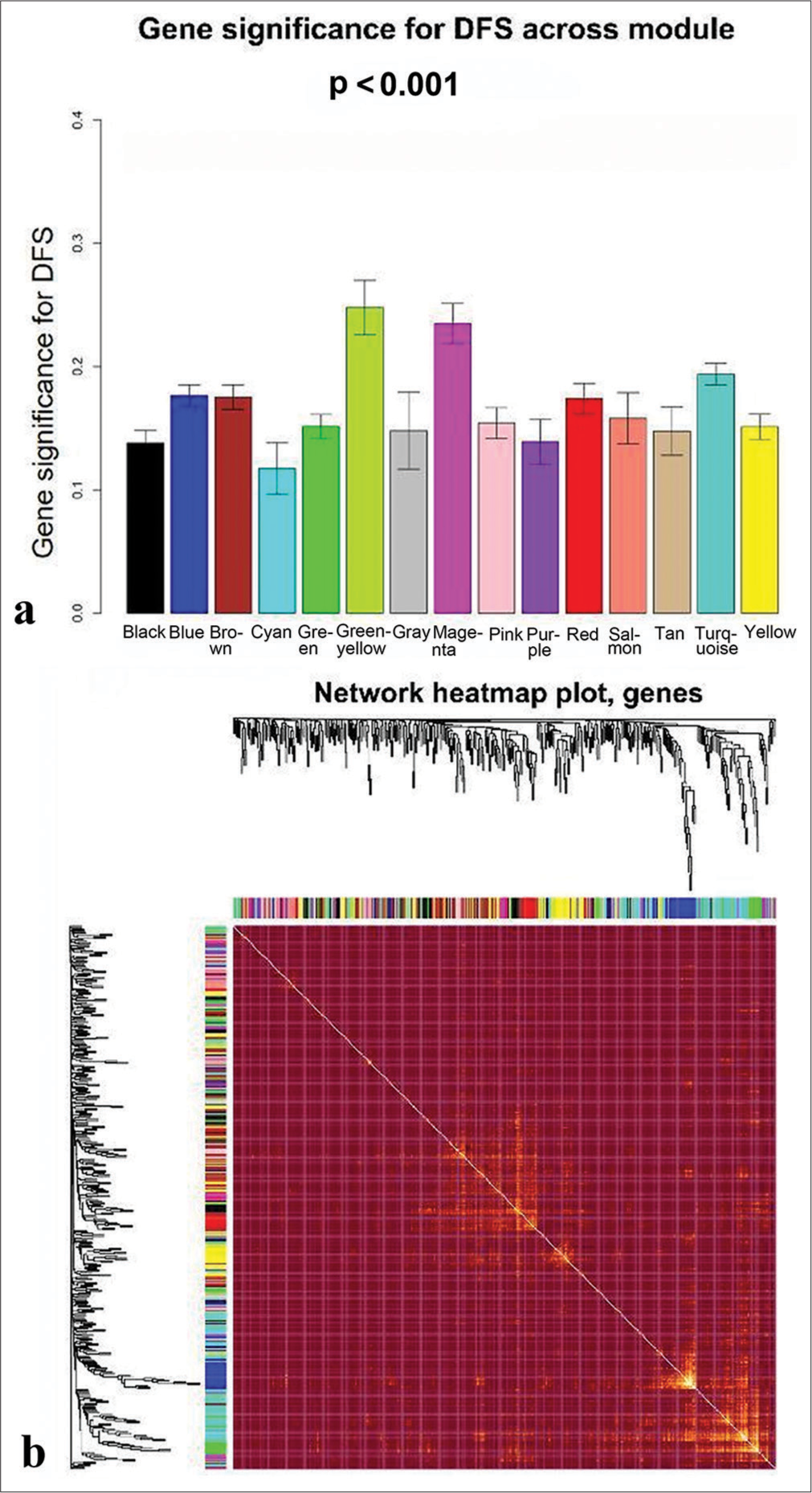
Export to PPT
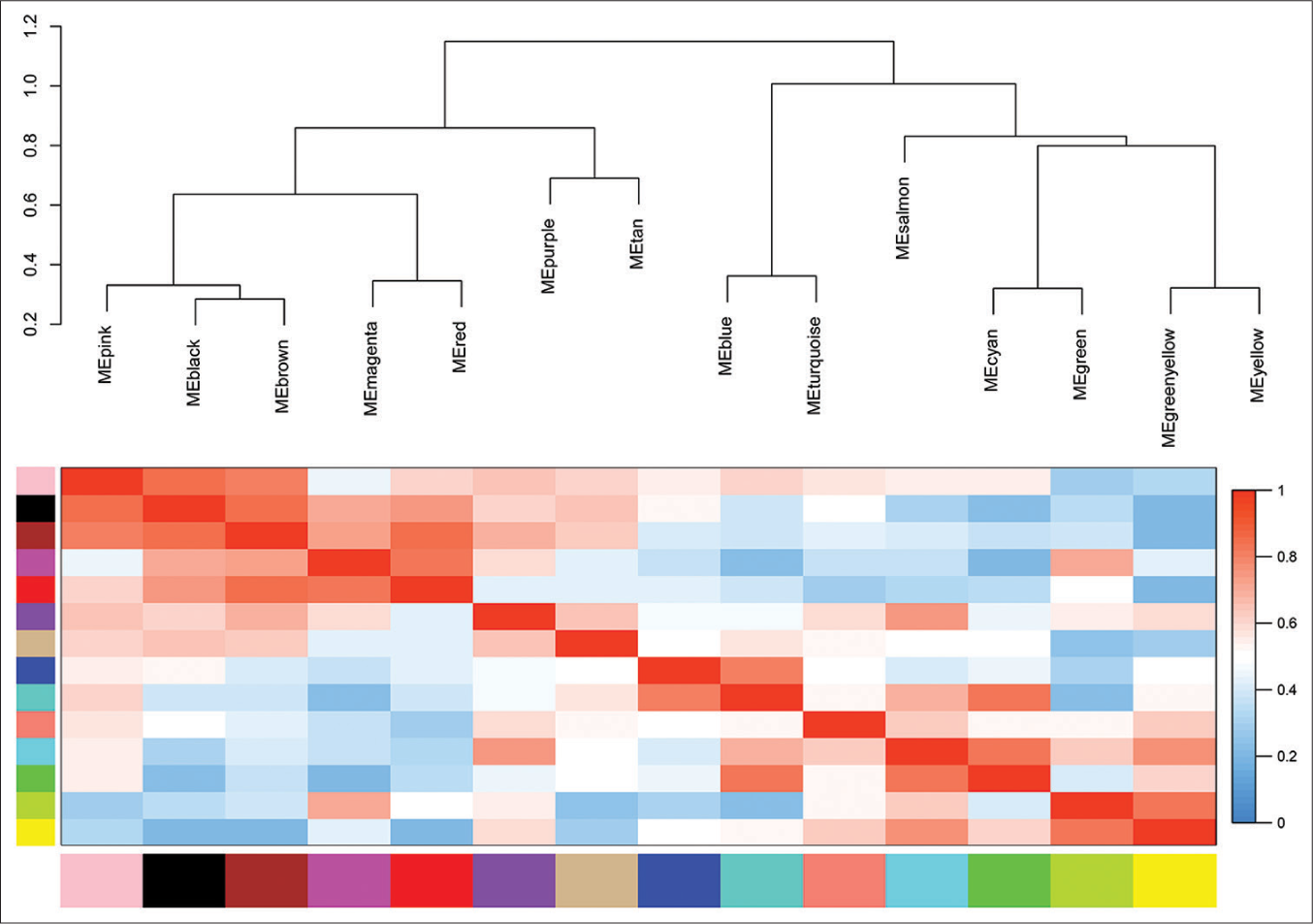
Export to PPT
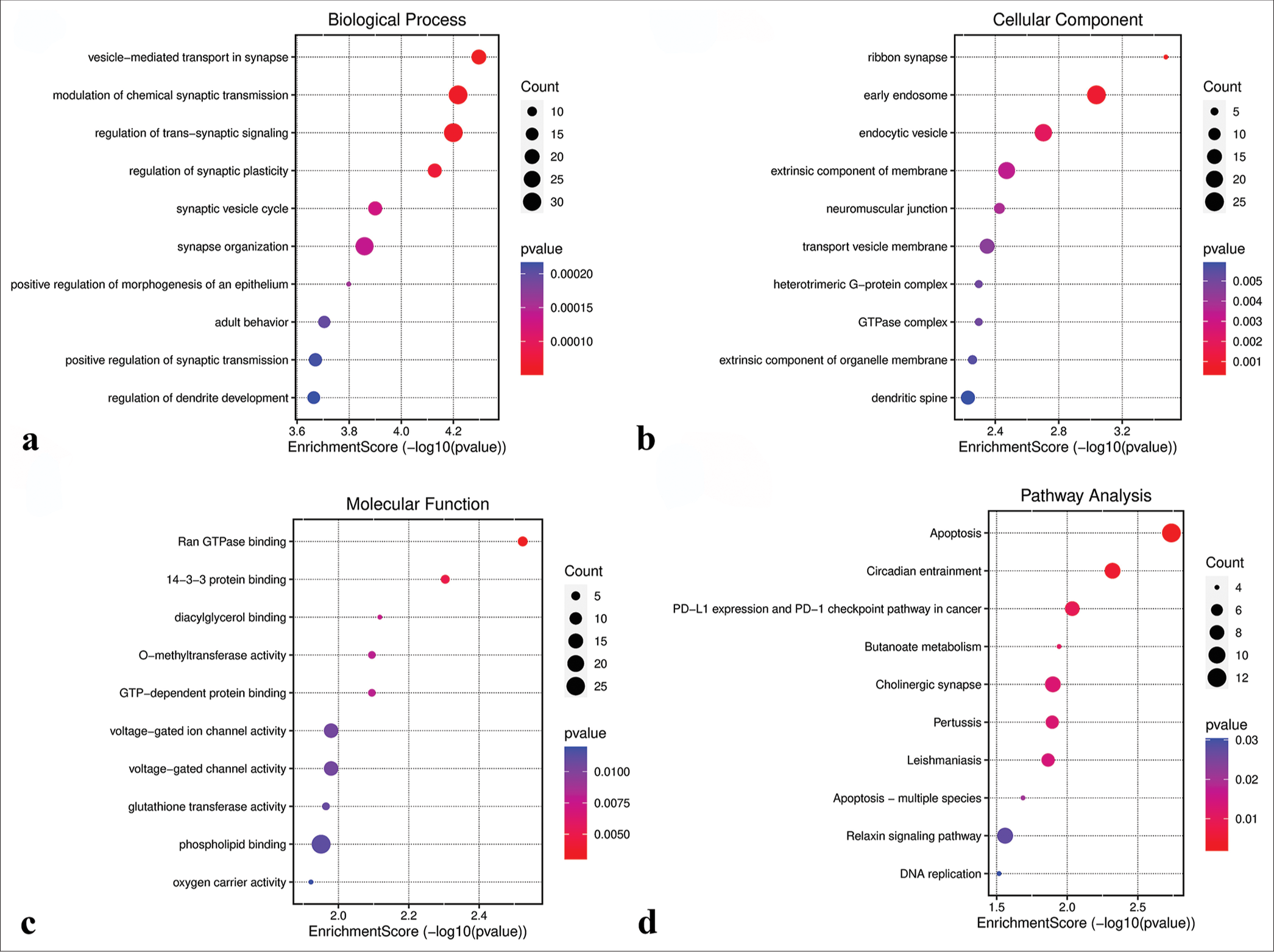
GO and KEGG functional analysesGO analysis revealed that genes in the green-yellow module were primarily implicated in B-cell proliferation [Figure 7a], located on the external side of the plasma membrane [Figure 7b], and exhibited receptor ligand activity and signaling receptor activator activity [Figure 7c]. KEGG pathway analysis further highlighted the significant enrichment of the green-yellow module in the B-cell receptor signaling pathway [Figure 7d]. Conversely, genes in the magenta module were predominantly associated with dicarboxylic acid transport [Figure 8a], localized to the cytoplasmic side of the plasma membrane [Figure 8b], and exhibited metallopeptidase activity [Figure 8c] and were involved in the calcium signaling pathway [Figure 8d]. The genes within the turquoise module were linked to chemical synaptic transmission and regulation of trans-synaptic signaling [Figure 9a], were located in early endosomes [Figure 9b], had phospholipid binding activity [Figure 9c], and were involved in apoptosis [Figure 9d].
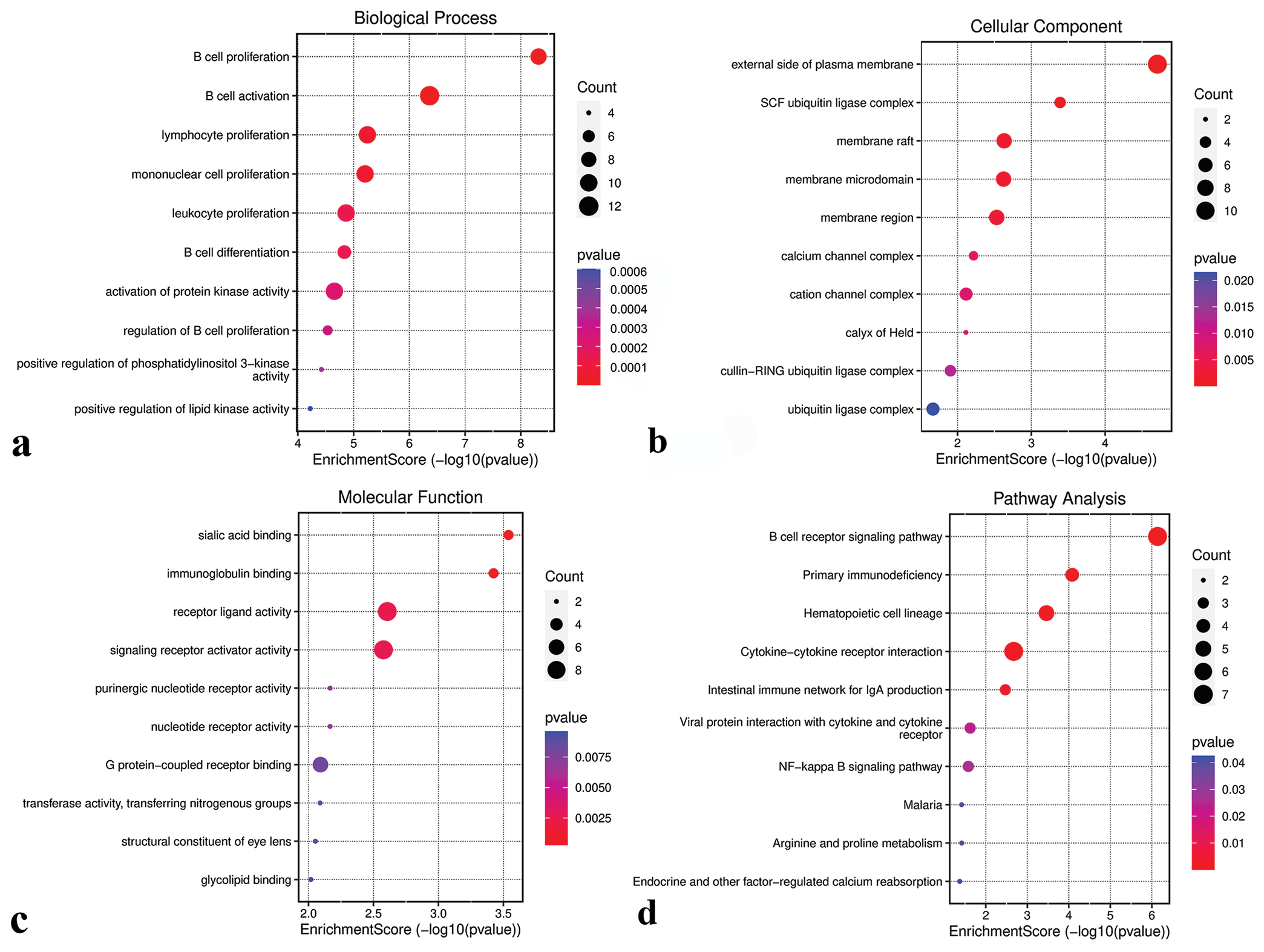
Export to PPT
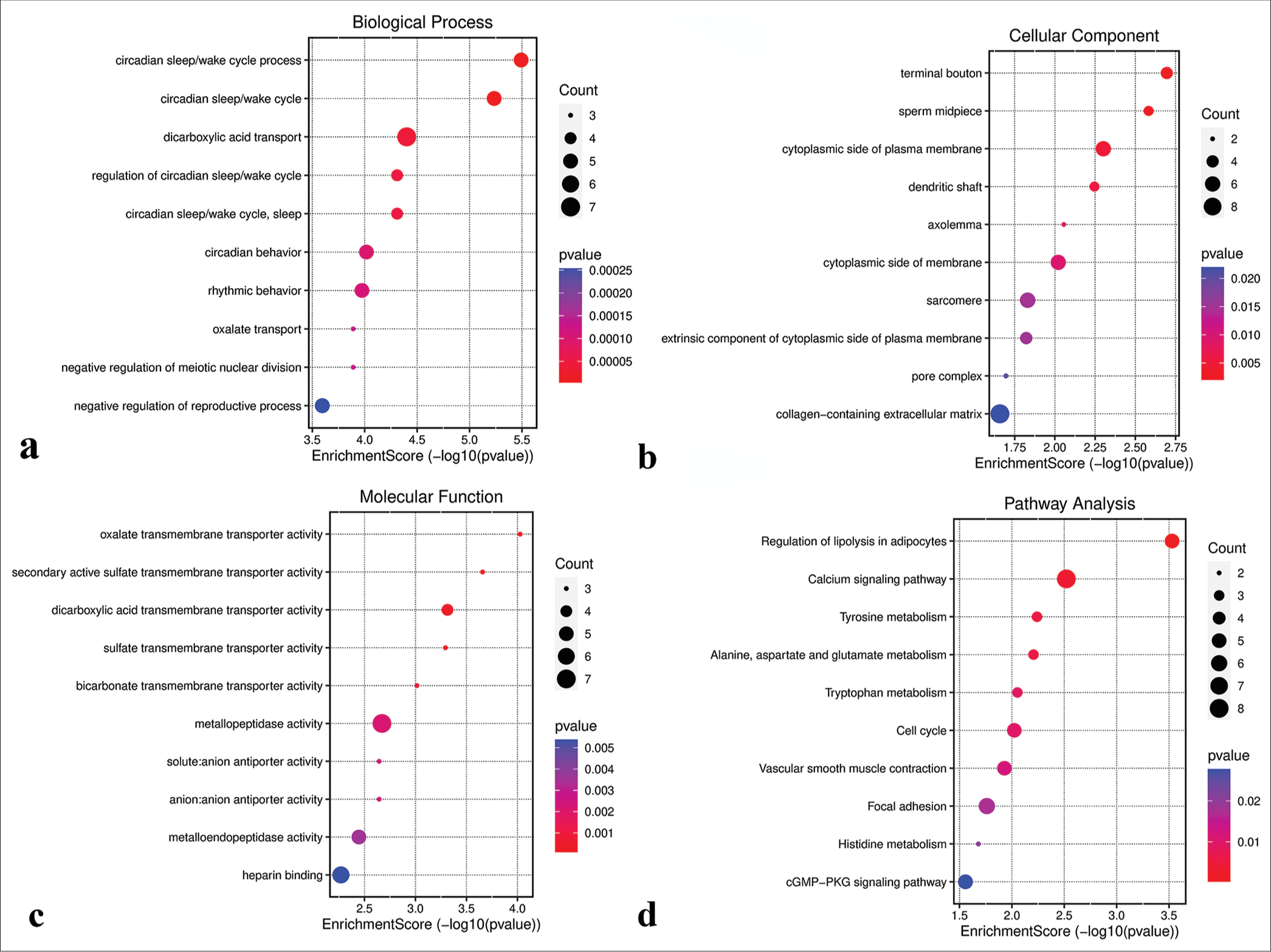
Export to PPT
Export to PPT
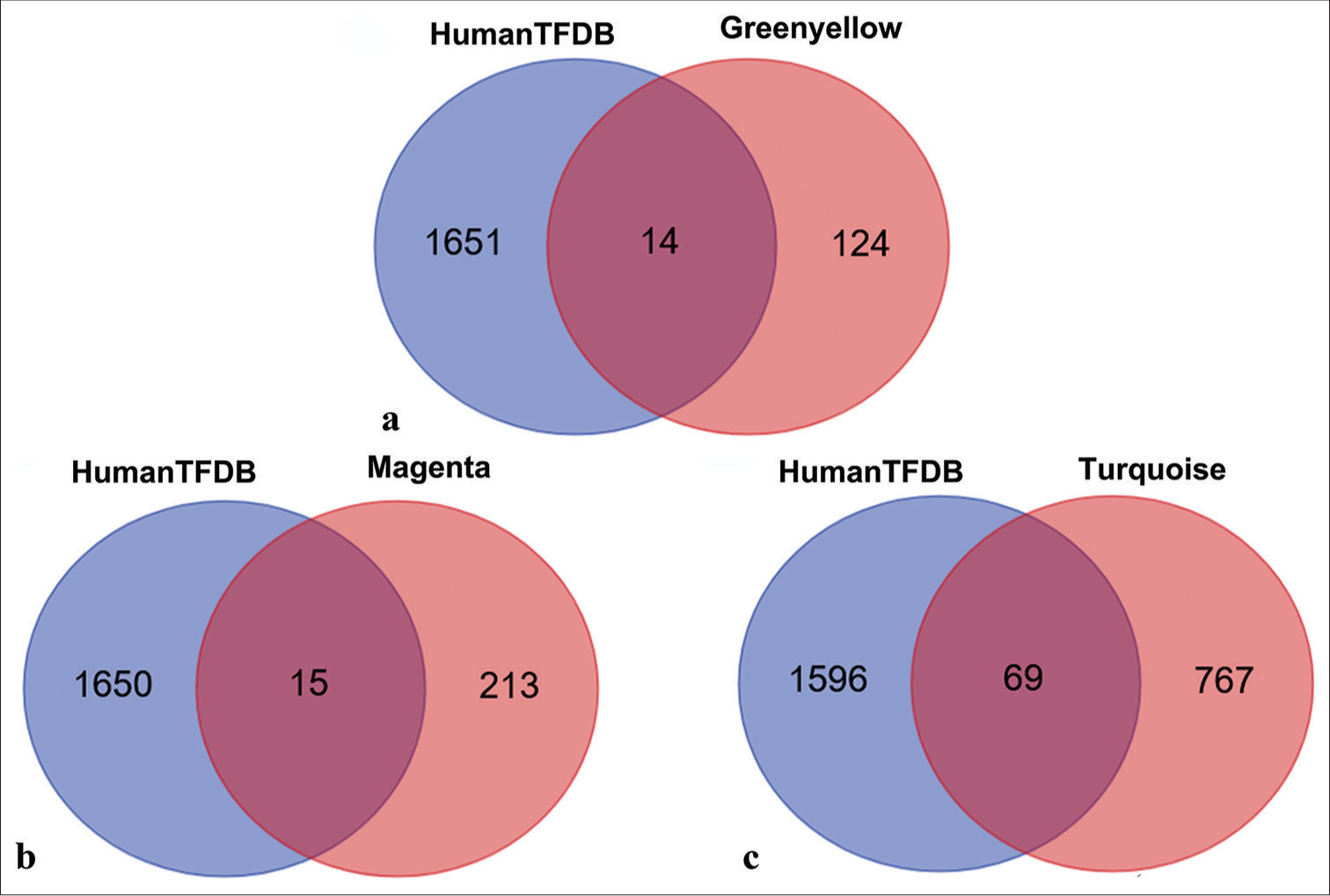
Identification of potential transcription factorsTo identify potential transcription factors within the three modules, each module was intersected with the Human Transcription Factor Database. The green-yellow module yielded 14 overlapping genes [Figure 10a], the magenta module had 15 overlapping genes [Figure 10b], and the turquoise module exhibited 69 overlapping genes [Figure 10c]. These overlapping genes, identified as potential transcription factors, are listed in Table S3.
Export to PPT
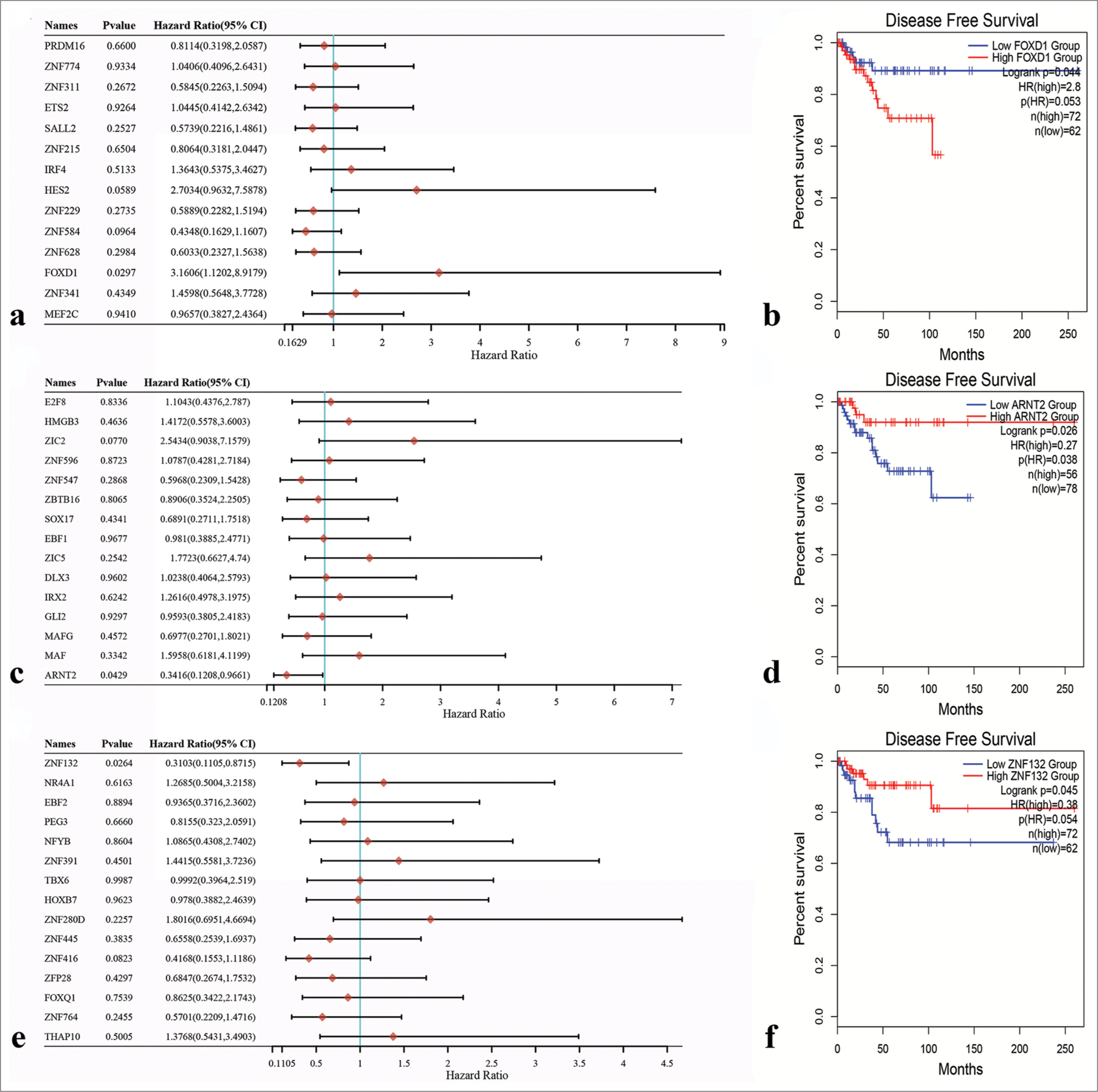
Survival analysis of potential transcription factorsPotential transcription factors were subjected to univariate Cox regression analyses for the identification of hub transcription factors. The results revealed that FOXD1 (HR = 3.1606, 95% Confidence interval [CI] 1.1202–8.09179; P = 0.0297; [Figure 11a]), ARNT2 (HR = 0.3416, 95% CI 0.1208–0.9661; P = 0.0429; [Figure 11b]), and ZNF132 (HR = 0.3103, 95% CI 0.1105–0.8715; P = 0.0264; [Figure 11c]) emerged as hub transcription factors. Subsequently, Kaplan–Meier survival analysis results demonstrated the correlation between the expression levels of these hub transcription factors and DFS. Notably, prognosis was better when FOXD1 had low expression than when it had high expression, suggesting that FOXD1 is an activating oncogene [Figure 11d]. Similarly, prognosis was better when the expression levels of ARNT2 and ZNF132 were high than when the expression levels were low, indicating that these genes act as tumor suppressor genes [Figure 11e and f].
Export to PPT
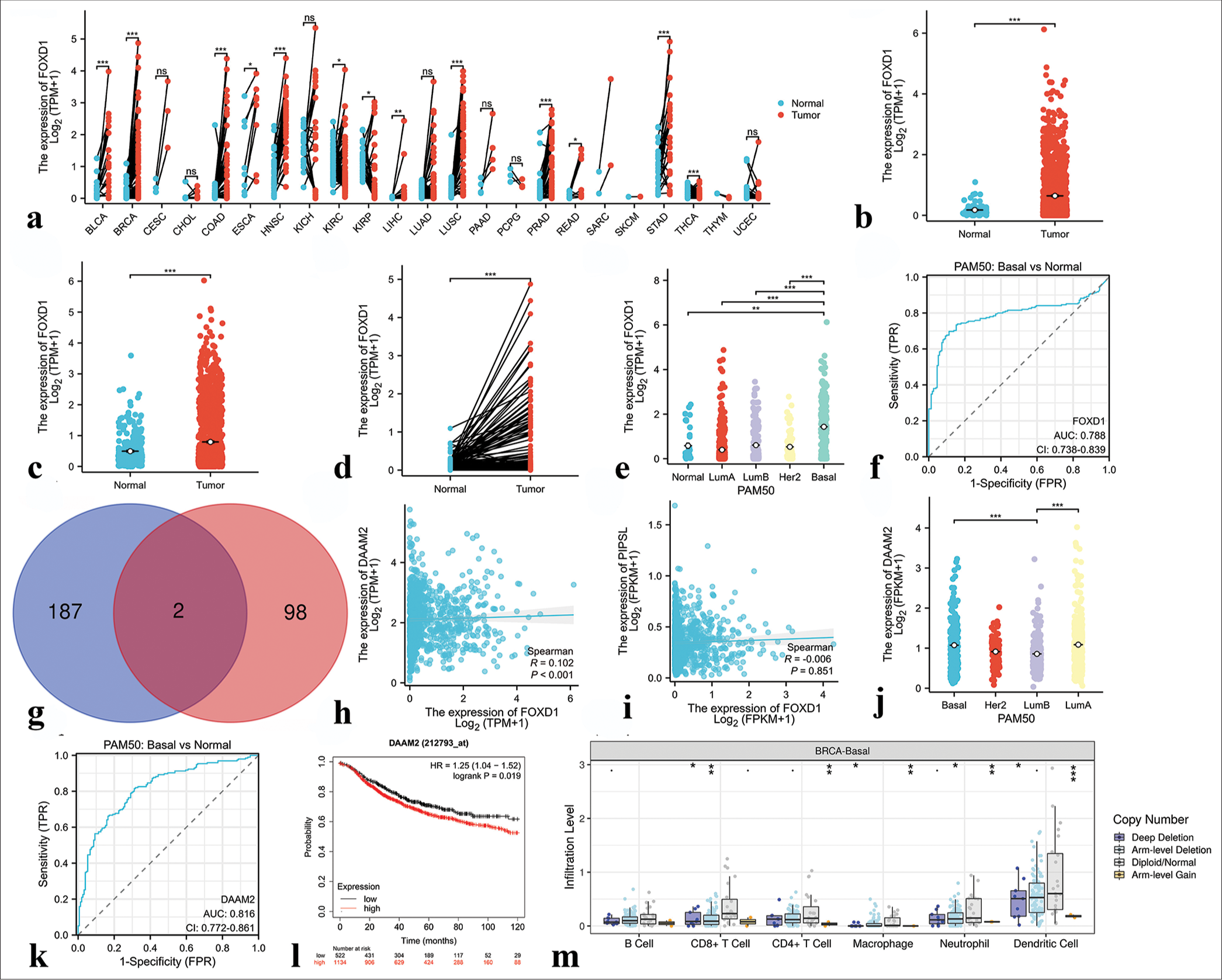
Hub transcription factors: expression level, clinical significance, downstream target genes, and correlation with tumor-infiltrating immune cellsWe initiated an analysis of FOXD1 expression across various cancers using the TCGA database. The results showed that its expression level was significantly elevated in Bladder urothelial carcinoma (BLCA), Breast invasive carcinoma (BRCA), Colon adenocarcinoma (COAD), Esophageal carcinoma (ESCA), Head and Neck squamous cell carcinoma (HNSC), Liver hepatocellular carcinoma (LIHC), Lung squamous cell carcinoma (LUSC), Prostate adenocarcinoma (PRAD), Rectum adenocarcinoma (READ), and Stomach adenocarcinoma (STAD), but was low in Kidney renal clear cell carcinoma (KIRC), Kidney renal papillary cell carcinoma (KIRP), and Thyroid carcinoma (THCA). FOXD1 expression remained unchanged in Cervical squamous cell carcinoma and endocervical adenocarcinoma (CESC), Cholangiocarcinoma (CHOL), Kidney Chromophobe (KICH), Lung adenocarcinoma (LUAD), Pancreatic adenocarcinoma (PAAD), Pheochromocytoma and Paraganglioma (PCPG), or Uterine Corpus Endometrial Carcinoma (UCEC) [Figure 12a]. In the TCGA-BRCA data, FOXD1 was markedly upregulated in breast cancer samples[23] [Figure 12b and c]. It expression was significantly higher in breast cancer tissues within the TCGA paired sample dataset [Figure 12d]. Moreover, FOXD1 expression was particularly elevated in the basal subtype of breast cancer [Figure 12e], and its expression level served as a moderately accurate predictor of prognosis in patients with Figure 12f. The predicted downstream target genes of FOXD1 included dishevelled associated activator of morphogenesis 2 (DAAM2) and Putative PIP5K1A and PSMD4-like protein (PIPSL) [Figure 12g], and significant correlation was observed between FOXD1 and DAAM2 expression levels [Figure 12h and i]. In addition, DAAM2 expression was higher in the TNBC samples than in other subtypes and was a highly accurate prognostic indicator [Figure 12j-l]. The copy number variation (CNV) of FOXD1 correlated significantly with the infiltration levels of various immune cells in TNBC, as revealed by the Tumor Immune Estimation Resource (TIMER) database [Figure 12m].
Export to PPT
Similarly, ARNT2 and ZNF132 expression and clinical significance were analyzed across cancers. ARNT2 exhibited higher expression in BRCA and CHOL but lower expression in COAD, KIRC, KIRP, LUAD, and LUSC than in normal tissues [Figure 13a]. ZNF132 displayed higher expression in CHOL and LIHC but lower expression in several cancers than in normal tissues [Figure 14a]. In the TCGA-BRCA data, ARNT2 expression was significantly higher in breast cancer samples than in normal tissues [Figure 13b-d], whereas ZNF132 expression was higher in the normal tissues [Figure 14b-d]. ARNT2 and ZNF132 expression levels showed subtype-specific patterns in breast cancer, and ARNT2 had low expression in basal subtypes [Figure 13e] and ZNF132 had low expression in basal and other subtypes [Figure 14e]. The expression levels of ARNT2 and ZNF132 served as moderately accurate and highly accurate prognostic indicators, respectively, for TNBC [Figures 13f and 14f]. The predicted downstream target genes of ARNT2 included Autophagy-related 3 (ATG3), V-type Proton ATPa
留言 (0)