
記住我


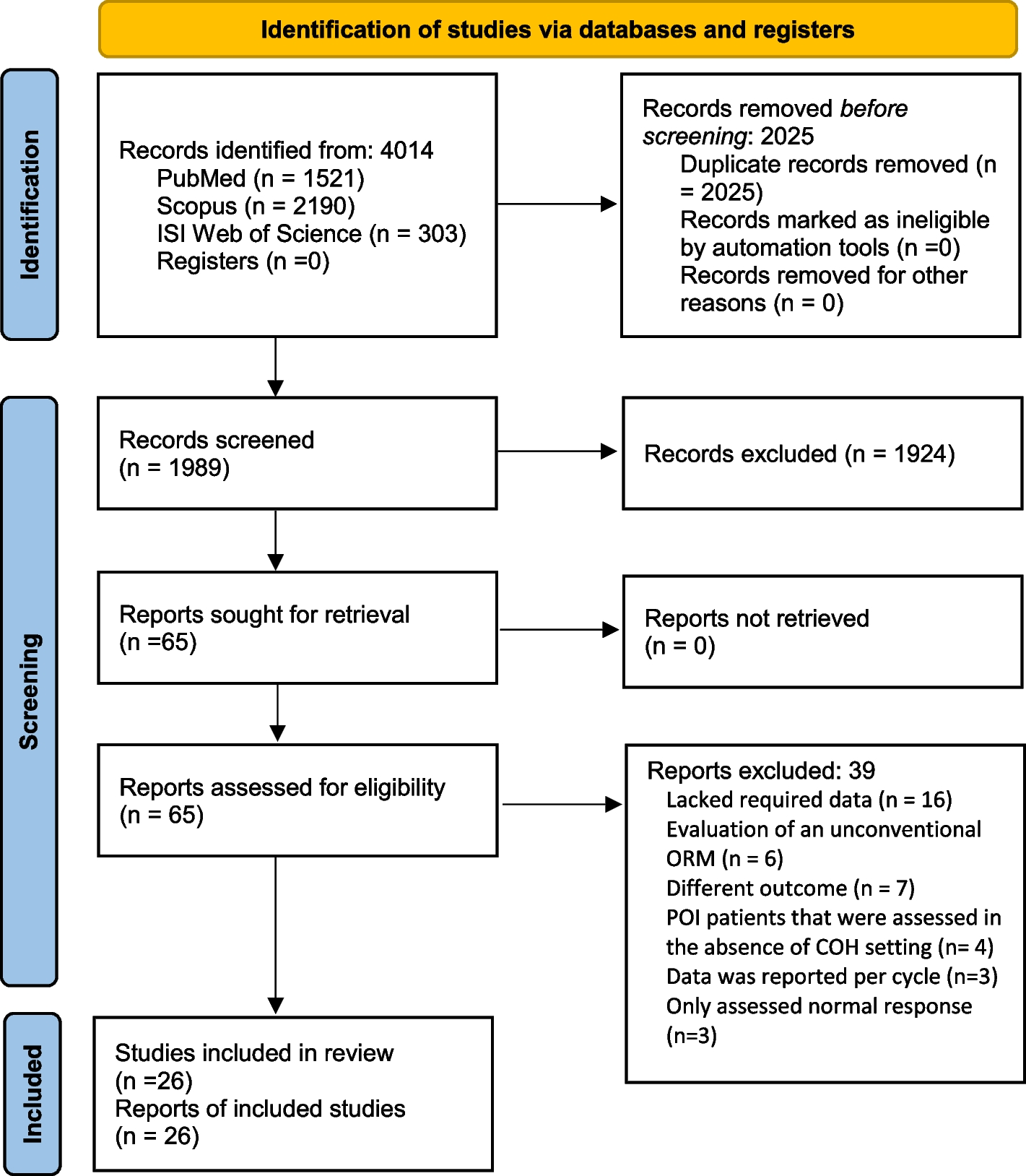


To avoid duplication of effort, we utilized a previous review published in 2017, having a broader scope than ours, for identification of studies (to 2016) related to the benefits and harms and (when suitable) for data extraction and assessments of risk of bias [29]. In line with the previous review [29], and to maximize the utility of available data, we conducted network meta-analyses (NMA) on the benefits [30,31,32]. From searches conducted during our preparation for these reviews, we did not identify an existing review fully answering the questions on outcome valuations or intervention preferences, respectively, and therefore conducted de novo reviews for these questions.
These reviews were carried out following a protocol [33] and according to the task force methods [34], guided by the Cochrane Handbook and Grading of Recommendations Assessment, Development and Evaluation (GRADE) working group [35,36,37,38]. This report follows the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) reporting guidelines for systematic reviews and the PRISMA extension statement for NMA, as applicable to each question [39, 40]. Any changes to the protocol are described herein; no change was made post hoc, that is, based on the results of any studies or analysis. A working group consisting of task force members and external clinical experts (see the “Acknowledgements”) assisted in developing the eligibility criteria, intervention taxonomy and coding schema, and thresholds for effects, as described herein, but was not involved in the selection and risk of bias assessments of studies, data extraction, or analysis. This manuscript was reviewed by 10 stakeholders (Supplementary file 1 contains the comments and responses), with all comments considered and minor revisions made mainly to enhance clarity of language.
EligibilityDetailed eligibility criteria for all KQs are located in Supplementary file 1 Table S1.1.
Key question 1The population of interest for KQ1 was adults ≥ 65 years old living who were community dwelling, i.e., living in the community/private retirement homes/assisted living with minimal supports. We did not limit eligibility by participant fall history. We included studies where < 20% of participants were < 65 years old or required more than minimal at-home support, including those homebound or living in LTC (people could require homecare); the latter narrows from our original exclusion criteria of studies recruiting based on LTC residency. We excluded studies recruiting participants based on having ≥ 1 specific medical diagnosis that may require different fall prevention and management strategies than the general population (e.g., stroke, Parkinson’s disease, severe dementia, or visual impairment) or that recruited participants on the basis of known vitamin D deficiency [≤ 30 nmol/L]). Studies recruiting inpatients were eligible if the intervention was primarily delivered in an outpatient or community setting (including primary care).
We included studies with at least one intervention aiming to prevent falls in community-dwelling older adults and delivered in, or referable from, primary care. A revision was made to the protocol to require that all studies prospectively collect data and report on at least one of our fall outcomes (falls, fallers, or injurious fallers). The review and our search were not intended to capture all studies (e.g., on vitamin D) aiming to prevent non-fall outcomes and incidentally reported on falls but rather to capture studies of interventions specifically targeting fall prevention. Because the causality of falls is complex, we included studies of interventions targeting known fall risk factors (e.g., balance or gait disturbance, fear of falling) if the authors proposed a mechanism to prevent falls (e.g., improving balance can reduce the likelihood of a fall), and the study reported a falls outcome. We excluded all pharmacologic interventions apart from vitamin D (with or without calcium), protective aids to reduce fractures from falls (e.g., hip protectors), podiatry assessments, alarms to signal a fall, and hearing aids or visual aids unless they were part of a multicomponent intervention. Interventions only providing screening/assessment results to general practitioners, without a protocol for follow-up, or focused on cognitive/executive function or visual attention were also excluded. We included dietary counselling but excluded sole provision of dietary supplements/meal replacements or fluid therapy. We also excluded studies where the only difference between interventions was an “add-on” (e.g., clinician reminders) to improve uptake or implementation of interventions already in place. Supplementary file 1 Table S1.2 has details of intervention eligibility.
The main comparator of interest was usual care (UC), which we defined as typical health or medical care received in a primary care setting without specific intervention to prevent falls. If authors described UC that met one of our intervention descriptions, we classified it as an intervention for our purposes. We also included studies with a non-/minimally active intervention comparator, such as a pamphlet on fall risks, gentle stretching, or social engagement activities. To maximize the utility of available data and generate effect estimates versus UC for interventions not directly compared to UC, we included head-to-head comparisons of different interventions and conducted NMAs [30,31,32]. This form of analysis simultaneously evaluates a suite of comparisons using data from direct comparisons between treatments to inform comparisons for treatments that have not been directly compared (referred to as indirect evidence). We excluded head-to-head studies that only compared interventions that fell within the same category in our intervention taxonomy and coding framework (e.g., different doses of vitamin D, intensities of strength training, different delivery providers) (see the section “Intervention coding and development of NMA nodes” and Table 1).
Table 1 Framework for coding used to develop interventions (nodes) for the network meta-analysesThe outcomes of interest were chosen and rated by the task force for their importance to decision-making, using GRADE guidance [33, 38]. Eight outcomes were considered critical for decision-making (i.e., rated 7 or above on a scale of 1–9): number of fallers, number of falls, number of injurious fallers, number of fractures (any fracture; refined to exclude non-symptomatic vertebral fractures found via x-ray), number of hip fractures, residential status/institutionalization, HRQoL, and functional status. One result was selected for each outcome in each study using a hierarchy developed based on task force input either before (for injurious falls, using the most serious in each study) or after (for HRQoL and functional status) development of the protocol (Table S1.1). Intervention-related adverse effects (AEs) were rated as important (i.e., rated 4–6); we categorized AEs into four categories for extraction: any AE, serious AEs (both proportions), falls, and fractures (both if attributed to the intervention).
We included randomized controlled trials (RCTs) of any design and sample size with at least 3-month follow-up after randomization to adequately capture potential effects on the outcomes. We included studies only reported in conference proceedings or unpublished reports if the results were confirmed by the authors as final.
Key questions 2 and 3Apart from the same main population as KQ1, for KQs 2 and 3, studies recruiting family members or caregivers on behalf of people with cognitive impairment were eligible (Table S1.1). For outcome valuation related to LTC admission in KQ2, studies of LTC residents were eligible if they measured the utility/disutility of admission to LTC within the first 6 months of residence. For KQ2, as per protocol, because we located studies reporting HSUV data for all of the critical outcomes (i.e., health states) in comparison with a “healthy” comparator group (i.e., without the health state being measured), we only included these comparative HSUV studies; retrospective pre-event measurement (i.e., via recall) was an acceptable comparator. This criterion allowed us to calculate a disutility from the outcome (i.e., utility of “healthy” state minus utility of health state from outcome such as fall; range 0 = no disutility to 1.0 = disutility equal to death and approximately ≥ 0.05 considered meaningful), which allows for easier interpretation across populations since it accounts for baseline health status. Participants could have experienced the outcome themselves or been provided with hypothetical scenarios about the experience. Apart from the above eligibility for comparative HSUV studies, we included studies using other utility-based stated and revealed preference methods including contingent valuation studies, such as discrete choice experiments, simple ratings scales, or trade-offs; if we had not found data from these study designs for a particular outcome, we would have included non-utility data from surveys or qualitative studies. For KQ3, we examined preferences between different interventions or between different attributes of interventions within one category. We selected studies after assessing the certainty of the evidence in KQ1 and only included studies measuring preferences among interventions for which we had moderate or high certainty of benefit for at least one critical outcome. Intervention attributes of interest included duration, cost, and format (group vs. individual and virtual vs. in-person delivery). Participants could have either participated in the relevant fall prevention intervention(s) or been provided with information about the interventions. We relied on quantitative studies using utility-based methods but considered data from surveys and, if necessary to fill gaps, qualitative studies.
For all KQs, we included reports in English or French, the official languages of Canada, as per task force methods. Language restrictions in systematic reviews do not appear to bias results from meta-analyses [41, 42]. No restrictions were placed on country or risk of bias. For KQ1, no limit on publication date was placed. However, for KQs 2 and 3, we limited inclusion to studies published on or after 2000 because it is expected that preferences change over time.
Information sources and search strategyFor KQ1 on benefits and harms, we located full texts of all studies included in the previously published review [29]. To identify new evidence, our information specialist updated the previous review’s peer-reviewed searches (Supplementary file 1 contains all search strategies), limited to records after January 1, 2016. The search contains Medical Subject Heading terms and key words combining the concepts of falls/fallers, adults, and randomized controlled trials. We searched Ovid MEDLINE (1946-), Ovid Embase (1996-), Wiley Cochrane Central Register of Controlled Trials (inception-), and AgeLine. Reference lists of all new included trials and recent systematic reviews were hand-searched by one reviewer. We also searched the World Health Organization Clinical Trials Search Portal [43], which searches multiple trial registries. First authors of potentially relevant studies reported in conference abstracts or trial registries were contacted by email (with two reminders over 1 month) to confirm the study’s eligibility or to obtain full study reports and/or additional study or outcome data. Database searches were run November 15–16, 2020, and updated on August 25, 2023 (with the exception of AgeLine which was not a unique source for any of the included studies from the initial search).
The information specialist developed a search covering both KQs 2 and 3, combining Medical Subject Heading terms and key words for falls, fractures, and transition to residential care with those for patient preferences, quality of life, preference-based instrument/methodology terms (e.g., EQ-5D, conjoint analysis), decision-making, attitudes, and acceptability. This search was peer-reviewed by another librarian using the Peer Review of Electronic Search Strategies 2015 checklist [44]. We searched Ovid MEDLINE (1946-), Ovid PsycINFO (1987-), and CINAHL via EBSCOhost (1937-) databases, screened studies in KQ1 for KQ2 and 3 eligibility, and hand-searched reference lists of included studies and relevant systematic reviews. Database searches were initially run September 23–25, 2021 and updated on June 9, 2023.
Selection of studiesDatabase search results were exported to an EndNote library (version X7, Clarivate Analytics, Philadelphia, USA, 2018) for record-keeping and deduplication. Records identified through hand-searching were manually added to the library. Unique records from the database searches were uploaded to DistillerSR (Evidence Partners Inc., Ottawa, Canada) for screening. Structured eligibility forms for screening and selection were developed and pilot tested by all reviewers involved in screening (J. P., L. A. G., S. S., A. W., A. R. A.) with samples of 100 abstracts and 20 full texts, respectively, until agreement was high (> 95%). Thereafter, all titles and abstracts were screened by two reviewers independently, using broad inclusion criteria. Efforts to retrieve the full texts of all potentially relevant records were made, with the exception of qualitative studies potentially relevant to KQ2 where we had sufficient evidence from other study designs. Two reviewers independently reviewed all full texts (including the studies from the previous review) [29], and disagreements were resolved by consensus or adjudication by a third reviewer (L. A. G. or J. P.). Records identified from reference lists, trial registries, and websites were screened by one experienced reviewer, with two reviewers reviewing full texts. We recorded reasons for all exclusions at full text.
Data extractionKey question 1We planned to utilize data extraction from the previous review [29], but differences in our classification of interventions and definitions of several outcomes (e.g., separating fallers and falls, using a hierarchy for injurious falls, addition of functional status outcome) led to extracting all data anew. All data were extracted by one trained reviewer and verified for accuracy and completeness by a second trained reviewer. Data were extracted into purpose-built forms in Microsoft Excel that were piloted on a sample of 10 studies by all reviewers involved in data extraction (L. A. G., A. W., S. S., A. R. A.).
We collected data on the following: study characteristics (i.e., year and country of conduct, funding source [industry vs. not], enrolled sample size, recruitment setting, trial design); intervention components (including, as applicable, delivery method, location, provider, degree of supervision, details of any assessments made, provision of any modifications, duration in weeks, and number of sessions/hours); description of UC or other control; participant characteristics (sex, age, proportion with previous falls, any enrolment criteria related to a clinical condition); outcome measurement tools and ascertainment; and results data (with sample size) at longest follow-up. Studies with populations requiring contextual or equity considerations (e.g., Indigenous peoples, newcomers, low income, Black Canadians) by the task force were also noted. Data were collected to allow examination of the homogeneity and transitivity assumptions for the NMAs and for assessment of risk of bias.
For binary data, we extracted crude events in each arm, when reported, or risk, rate, or odds ratios if necessary or suitable (i.e., adjusted for clustering). If falls were reported as incident rates (e.g., over person-years), we used the mean follow-up duration of the study to calculate the total number of events. We assumed injurious fall events only occurred once per person during follow-up if the number of injured fallers was not reported; in a few cases where only data on any injurious falls were available, we extracted data for events knowing this may overestimate the risk, but likely not the relative effects. When data for multiple fracture types (e.g., wrist, tibia, distal femur) were reported, we extracted the findings for all. Unless specified, we assumed that a participant had only one fracture, hip fracture, or serious AE during follow-up. If studies only reported serious AEs, we used this data for both the any AE and serious AE outcomes and performed sensitivity analysis. When authors reported zero AEs, we extracted this as zero for any AE and serious AEs outcomes but not for falls or fractures, which we did not assume authors considered to be intervention-related AEs.
For continuous outcomes measures, we extracted (by arm) the mean baseline and endpoint or change scores, standard deviations (SDs) or other measure of variability, and number analyzed. Means were approximated from medians, when necessary. When SDs were not provided, they were computed or estimated using established imputation methods [35]. Results were extracted from figures using WebPlotDigitizer version 4.6 [45] when no numerical values were provided. For crossover trials, we limited data extraction to the first period of the study to eliminate the possibility of carry-over effects. When two or more interventions in a multi-arm trial were classified as the same intervention in our taxonomy (e.g., different intensities/difficulty levels of a balance/resistance training intervention), we combined the results from those groups to avoid loss of information [35].
Key questions 2 and 3For these questions, we collected data on the population as in KQ1, as well as exposure to any of the related outcomes and/or to fall prevention interventions. We collected details about instruments used, including development and composition of scenarios of health states; choice tasks, including definitions of all attributes; and survey questions. For KQ2 data on HSUVs, we extracted sample sizes, means, and 95% CIs, or medians and interquartile ranges (IQRs), when necessary; when other (e.g., standard deviations) measures of variance were reported, we extracted this information to later calculate or impute 95% CIs for analysis [35]. When HSUVs for multiple fracture types (e.g., wrist, tibia, distal femur) were reported, we extracted findings for all. When multiple HSUV measurement tools were used by a study for a single health state, we preferentially extracted EQ-5D over other utility measures as this is the most commonly used tool. If a study without EQ-5D used more than one utility tool, we extracted data from each tool, standardized them and pooled them. Our protocol did not specify a specific timepoint for measurement; rather, specifying that time since event (≤ 12 vs. > 12 months) would be a subgroup variable of interest. Few studies reported on fracture outcomes in the long term (> 12 months; although many at 12 months), and this variable was judged as a major potential confounder; therefore, we defined two measurement time points for utilities for our primary synthesis: time closest to the event (if ≤ 3 months) and time closest to 12 months (but > 3 and < 24 months). All relevant results data from studies not employing HSUV methods in KQ2 (e.g., rankings of outcomes by importance, coefficients from discrete choice experiments) and reported in quantitative studies for KQ3 were extracted. Qualitative findings for KQ3 were copied and pasted from the relevant findings or results sections of the report into a Microsoft Excel table for analysis. All data were extracted by one trained reviewer and verified for accuracy and completeness by a second trained reviewer. Data were extracted into purpose-built forms in Microsoft Excel that were piloted by all reviewers involved in data extraction (L. A. G., A. W., S. S.).
Within-study risk-of-bias assessmentsTo align with the previous review [29], we used the Cochrane Effective Practice and Organisation of Care Group’s risk-of-bias tool for KQ1 [46]. Briefly, studies were evaluated on the following domains: random sequence generation, allocation concealment, contamination, similarity of baseline characteristics, similarity of outcome measures at baseline, incomplete outcome data, blinding of outcome assessors, and selective outcome reporting. In each study, each outcome was rated as being at low, unclear, or high risk of bias in each domain. Studies with an active comparator but no blinding were not considered at high risk of bias for contamination. Outcomes with no ratings of high risk in any domain were considered at overall low risk of bias. Outcomes with a ≥ 1 ratings of high risk in any domain other than incomplete outcome data were considered at moderate risk of bias. Outcomes rated at high risk of bias for incomplete outcome data and ≥ 1 other domain were considered at overall high risk of bias.
For the KQ1 outcomes of AEs attributed to the intervention, we revised the protocol to assess risk of bias using an adapted McMaster Quality Assessment Scale of Harms (McHarms) tool (Supplementary file 1) [47]. McHarms was developed to compare AEs between intervention and control groups in trials of pharmacologic interventions. Because we were not interested in the AEs in UC/control groups, we removed some questions and focused on whether ascertainment of AEs was active (rather than passive/spontaneous), used a valid measure (e.g., events that could vary in severity were classified as such), and if attrition was acceptable. If there were serious concerns for ≥ 1 of the seven questions in our form, the study was rated as high risk of bias.
There was no validated or commonly accepted tool to assess risk of bias in studies measuring patient values or preferences. Therefore, for KQs 2 and 3, we developed a critical appraisal tool adapted from the within-study risk-of-bias domains in the GRADE guidance for preference-based studies (Supplementary file 1) [36]. Our assessment is comprised of signalling questions addressing four main concepts: (1) selection of representative participants into the study, (2) completeness of data, (3) properties of the measurement instrument, and (4) data analysis. If there were serious concerns in ≥ 1 domain, the study was rated at high risk of bias. Qualitative studies in KQ3 were assessed using the qualitative critical appraisal tool from the Critical Appraisal Skills Programme [48] and rated as having few, some, or significant concerns.
For trials from the prior review included in KQ1, we relied on assessments by the previous review team for use for the benefit outcomes [29]; we assessed harms anew using our modified tool. For newly identified studies and all harm outcomes, two reviewers independently assessed the risk of bias by using the previous team’s reviewer instructions and came to consensus on the final rating for each question/domain, with adjudication by a third reviewer when necessary. In KQs 2 and 3, we obtained approval from the task force for a methods deviation for one reviewer to assess risk of bias with a verification by a second reviewer (instead of using two independent reviewers), and disagreements were resolved by consensus or a review lead. Each risk of bias tool was piloted with a sample of at least five studies until agreement on all elements was high; each tool went through two rounds of pilot testing. The risk of bias/quality evaluations were incorporated into our assessment of the certainty of the evidence for each outcome (see section on “Assessing the certainty of evidence”).
Intervention coding and development of NMA nodes (KQ 1)In consultation with the working group, we adapted the ProFANE taxonomy [20] (to align with the most relevant primary care interventions) and developed a coding framework to create meaningful delineations between interventions (“nodes” when referring to the NMA). Interventions were first categorized as follows: single component (e.g., one or more interventions from a single category), multicomponent (more than one intervention from different categories offered to all people), multifactorial (one or more interventions from different categories offered based on individual risk assessment, not all patients receive all interventions), or mixed (multifactorial intervention combined with ≥ 1 intervention provided for all independent of needs assessment). For control groups, it was decided to separate UC from information controls (e.g., pamphlet) and attention controls (e.g., social engagement, sessions on healthy living, gentle stretching). After data extraction had begun, but before analysis, we decided on various intervention components (e.g., four main types of exercise) and attributes, with their relative importance for implementation (e.g., supervision, delivery [individual vs. group /mixed], duration, comprehensiveness of assessment, varying by type of intervention) (Table 1). For some single-component interventions, we did not code additional attributes because there were usually very few studies examining these types of interventions. The working group decided against comparing different doses or means of administering vitamin D. Multicomponent, multifactorial, and mixed interventions were coded based on the broad types of interventions within them. For example, multicomponent interventions were coded primarily based on whether they included exercise (defined as walking vs. other and by level of supervision) and then by whether the other component(s) were limited to education and, if not, included HHA or a mobility device.
Intervention coding was conducted for each arm in every study and followed a similar process to data extraction. A form based on the coding schema was piloted between two project leads (L. A. G., J. P.). Once sufficient agreement was reached, one reviewer coded all intervention arms in a study, and the other reviewer verified the coding (SS and ARA assisted for studies from our search update). Trials in which all arms coded into the same node (n = 20, see Supplementary file 1 excluded studies list) were excluded, since at least one valid comparison is required to include a study in an NMA. Only one RCT was required to create a node for the NMA.
Data synthesis for KQ1 (benefits and harms)For all critical (benefit) dichotomous outcomes, an odds ratio (OR) was the measure of effect, with the exception of falls for which we used a rate ratio (RR). For studies reporting multiple types of fractures, we calculated an average effect across fracture types. Studies reporting zero events in all arms were not analyzed. For continuous outcomes (e.g., HRQoL), we scaled all study findings to 0–100 (most measurement tools used this or similar ranges) and then used a mean difference (MD) as the effect measure [49]. A total of 95% confidence intervals (CIs) were used for measuring variance. We employed random-effects NMA in Stata (version 17.0) using a frequentist approach, which accounts for correlations between effect sizes from multi-arm studies [50]. In an NMA, a web (network) of different comparisons is constructed to incorporate both direct evidence from comparisons of interest and indirect evidence from comparisons with only one intervention in common. For example, comparisons between treatments A vs. C and treatments B vs. C will contribute to the effect estimate for treatments A vs. B.
Pooled proportions were calculated for AE outcomes reported by two or more studies per node, with 95% CIs calculated using an exact method. One exception was for vitamin D where there are several possible AEs/serious AEs and attribution becomes difficult; for these outcomes, we undertook random-effects pairwise meta-analysis in Review Manager (version 5.4.1) to generate the average effect (relative risk for any AE and risk difference for serious AEs where there were zero-event studies) for vitamin D versus UC/information controls. For these analyses, we performed sensitivity analysis removing the studies only reporting on serious AEs (but used for the any AE analysis) or only reporting on a single serious AE.
Assessment of transitivityThe validity of indirect evidence in an NMA relies on the principle of transitivity, which assumes that covariates that act as relative treatment effect modifiers are similar across different interventions, or adjusted for in the analysis, so the effects of all treatments included in the model are generalizable across all included studies [51]. We assumed that there would be transitivity based on our restrictions in eligibility to community-dwelling older adults living independently. To further evaluate whether the transitivity assumption was valid, we first investigated the distribution of clinical and methodological covariates across the studies in each node. Potential effect modifiers investigated were as follows: age of study population (mean age ≥ 80 vs. < 80 years), fall history (100% vs. 30–99% vs. < 30% participants with previous falls), recruitment setting (primary care/community vs. emergency department vs. in-patient), health context (country similar to Canada [high-income Organisation for Economic Co-operation and Development member [52] or United States] vs. otherwise), and duration of follow-up after randomization (< 12 vs. ≥ 12 months). For the health context, with working group input, we considered the USA as having a similar health context to Canada, as older adult in the USA are eligible for government-sponsored healthcare insurance (Medicare). Further, within the context of research studies that usually provide interventions without cost to participants, and many delivered in community settings, results from studies in countries where healthcare access for older adults may be inferior to Canada likely apply well to Canada. Studies were coded for these variables, and we assessed for each node the proportion of the total sample size that came from studies having each level of the variable (e.g., 30% of node sample came from studies with a mean age > 80 years). Graphs were created, and we visually inspected the distributions to see if there were large variations across nodes.
Transitivity was further checked through network meta-regressions for the falls, fallers, and injurious falls networks (other networks were too sparse). Due to concerns that meta-regressions in the full network may be underpowered, we also carried out meta-regressions on a simplified network, in which interventions of the same type or with similar characteristics were collapsed in order to increase statistical power to detect potential effect modifiers (Table 1 footnotes). A meta-regression was carried out for each effect modifier and for each network (full and simplified) for the three outcomes, in comparison with UC. The effect modifiers included age, falls history, recruitment setting, and health context. Though not used for transitivity, we also ran meta-regressions for risk of bias (high vs. moderate/low) to inform our certainty assessments. Our protocol specified we would examine fall history in three categories (0–30% vs > 30–99% vs. 100%), but this was revised (0–99% vs. 100% [usually over the past year]) because the findings of categorical regressions are difficult to interpret and a substantial proportion (32%) of studies did not report fall history in this manner (e.g., recruited instead on presence of falls risk factors) but could be assumed to enrol a sample with fewer than 100% having previous falls. We did not examine duration of follow-up because of our limit to a minimum of 3 months and a subgroup analysis in the previous review [29] did not find any evidence of an impact. Results of the meta-regressions (relying mostly on the full network regressions) were also used in our assessments of evidence certainty for the domains of indirectness and within-study risk of bias, together with data on the contribution of the relevant variables across studies.
Assessment of coherenceCoherence (often termed consistency) refers to the agreement between direct and indirect effect estimates contributing to the overall network estimate for each comparison. We assessed incoherence within comparisons using the Separate Indirect from Direct Evidence (SIDE or node splitting) approach [53] and globally across the entire network using the design-by-treatment interaction model [50]. These methods provide p-values, and p < 0.10 and p < 0.01 indicate some or major incoherence, respectively [54]. We also imported our data into the Confidence in Network Meta-analysis (CINeMA) web application [55] to generate contribution matrices of the proportion of participants in each comparison that came from direct (UC/control) and indirect comparisons. All results were used when assessing our NMA model and certainty of the evidence.
Assessment of heterogeneityThe concordance between CIs, which do not capture heterogeneity, and prediction intervals (PrI)—showing where the true effect of a new study similar to the existing studies is expected to lie—can be used to assess the importance of heterogeneity. We calculated PrIs for all network estimates (for comparisons with UC) and used these findings in our assessments of the certainty of evidence.
Reporting (across-study) bias assessmentsTo inform our certainty assessments, we assessed potential across-study bias in our effect estimates (i.e., network estimates, pooled AE estimates) from outcome data unable to contribute to our analyses because they were not reported even though the study should have collected them (i.e., missing outcome data) or because of publication bias (assessed via small study bias). To identify missing outcome data, we looked for trial registrations or protocols for all included studies. For falls or fallers, when it was clear that participants were asked to record all falls during follow-up (e.g., in diaries), we expected the study to report both falls and fallers despite what was reported in their protocol and considered this data missing at bias when they did not. For other outcomes, we considered outcome data to be missing at bias if a protocol, methods, or registration reported intention to collect it but we were unable to locate the results data for that outcome in any trial publication. For intervention-related AEs, clinical input suggested that all harm outcomes as defined for this review should have been measured. Therefore, we assessed data as missing at bias for all AEs outcomes not reported in each study. We analyzed small study effects visually and quantitatively using Egger’s test [56] when ≥ 8 RCTs compared an intervention with UC using random-effects pair-wise meta-analysis in Stata. Other available methods for investigating small study effect in NMAs (e.g., comparison-adjusted funnel plots) [32] were not considered suitable as interventions could not be ordered in a meaningful way.
Presentation of NMA results and consideration of absolute effectsWe generated network plots for each outcome, with the size of the nodes corresponding to the number of participants randomized to each treatment and the thickness of the edges (lines between nodes) weighted by the number of trials evaluating the comparison. Although we originally planned to present results for all pairwise comparisons in league tables, the large number of nodes included in our networks makes this format impractical; therefore, we present the network estimates of ORs or RRs and 95% CIs for all nodes compared to UC in forest plots (ranked by effect size).
With input from the working group, decision thresholds around effect size were created to delineate small (or greater) and moderate (or greater) benefit or harmful effect (i.e., unintended direction of effect for benefit outcomes). For fallers, these were set at OR = 0.8 and OR = 0.7 or OR = 1.25 and OR = 1.4, respectively, corresponding to approximately 5 and 8 fewer/more fallers per 100 people than the control event rates (i.e., the average rate for the UC group) in the studies. For each outcome, the control event rate across all nodes was calculated using the variance-stabilizing Freeman-Tukey double arcsine approach. To determine the thresholds for the other dichotomous outcomes, we used the pooled control event rate for fallers (41%) to convert the OR thresholds above into corresponding RRs (i.e., RR = 0.88 or 1.13 for small and RR = 0.80 or 1.20 for small and moderate benefit or harmful effect, respectively) which were then used as the thresholds across outcomes (with back-conversion to the corresponding OR using the respective control event rates) (Supplementary file 1 Table S1.5 contains the thresholds across outcomes). For harm outcomes, the thresholds of effect for any AE and falls (attributed to the intervention) were similar to those for the benefit outcome falls during follow-up (5 and 8 per 100 for small and moderate effects), while those used for fractures (attributed to the intervention) and serious AEs were 0.5 and 0.8 per 100 for small and moderate effects, respectively. For patient-reported outcome measures (i.e., functional status and HRQoL), which were all scaled to 0–100, we considered a 5-point difference to be at least a small effect and a 7-point difference to be at least a moderate effect, based on previous evaluations of meaningful change in patient-reported outcomes [57, 58]. Though the applicable relative effects of each network estimate were used for our certainty assessments, we present these together with calculated absolute effects for each network estimate.
Data synthesis for KQ 2 (outcome valuation)A large majority (39/44; 89%) of the included studies measured HSUVs, and our synthesis focused on these findings. In each study, we estimated the disutility for each evaluated health state by subtracting the reported utility of the health state (e.g., fracture) from the utility without (when a control group was used) or before (if pre-event utilities were measured, including by recall, among those with the event) the heath state. When a study reported utilities for multiple types of fracture, we took a mean across types weighted by number of individuals reporting on each fracture type; this differed from our protocol that specified we would use ranges of values but allowed us to conduct a quantitative pooled analysis.
Disutilities for each health state, separated by utility measurement tool, were pooled in Review Manager version 5.4.1 by the inverse variance method using a random-effects model. For each analysis, pre-planned subgroup analyses were conducted based on stud
留言 (0)