
記住我


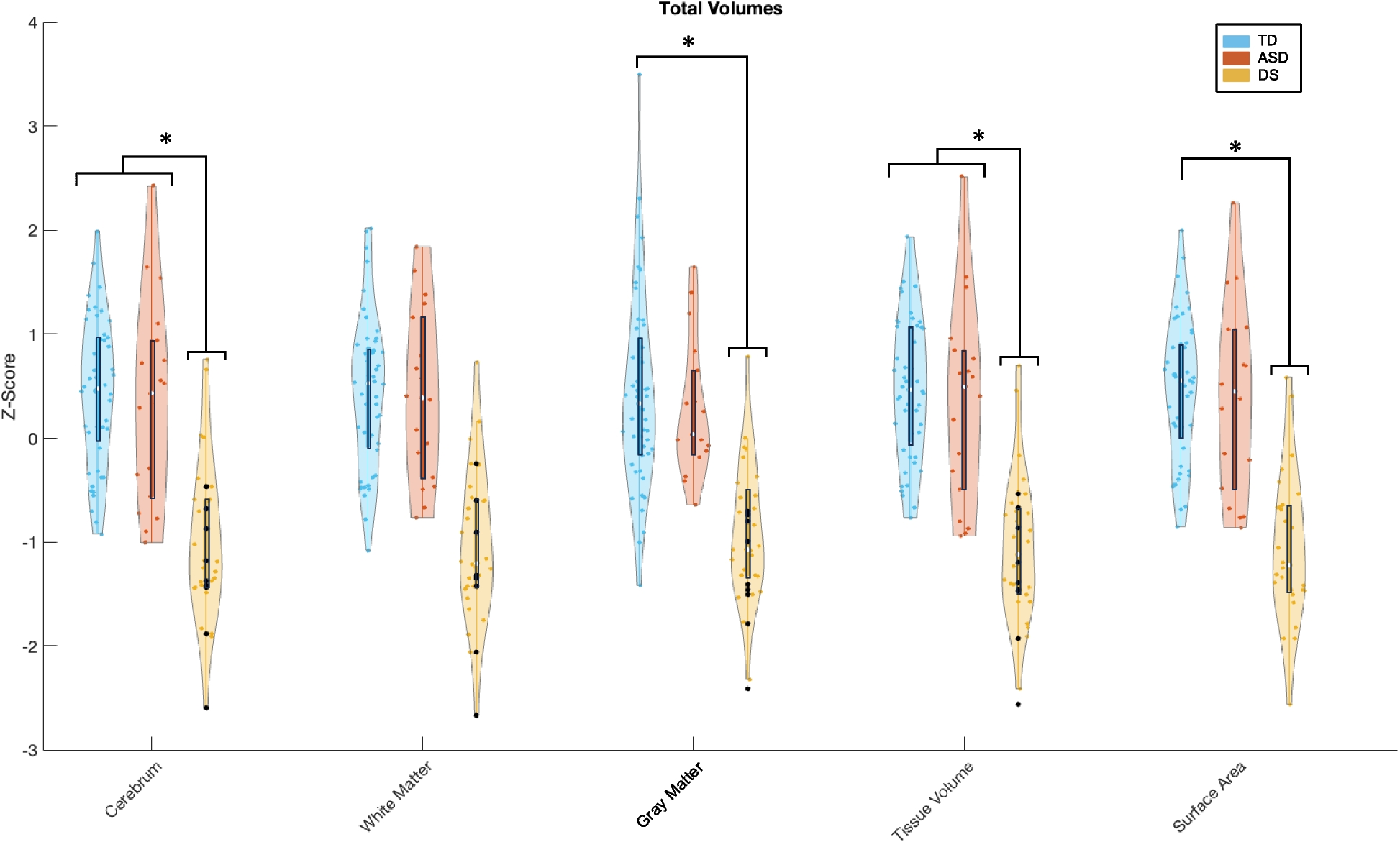






Our search strategy resulted in 1191 records, from which 302 were removed in the first step as these were meeting abstracts or proceedings and 358 as duplicate records (Fig. 1). After removing 683 from the initial list of 1191, we were left with 508. From this, we excluded records that did not use medical records (n = 93), did not use machine learning (n = 142), review articles (n = 29), no NDD (n = 215), records not found (n = 4), and system development/correspondence (n = 2). We further included 9 articles from other sources, 32 of which met the inclusion criteria and were included in this review, as summarized in the PRISMA flow diagram (Fig. 1). The included studies were conducted in 13 different countries. Most studies came from the USA (59%), followed by Denmark (6%). There is a single study each from the UK, Sweden, Germany, Finland, Switzerland, Netherlands, Egypt, Brazil, Israel, Thailand, and Australia (Fig. 2a, Table S6).
Fig. 1
PRISMA flow diagram. After screening 1191 articles, 32 were retained for the review
Fig. 2
Distribution of reviewed articles across multiple factors. (a) number of articles from different countries, (b) usage of categories of predictor variables in studies, (c) ML algorithms used in studies, and (d) multiple co-occurring NDD conditions in studies
The sample sizes in the studies varied significantly between 50 participants and a dataset of 4.5 million subjects (Table 1). Prediction models were developed for a single diagnosis and a combination of NDDs. Approximately 47% of included studies developed ASD prediction models, 28% focused on ADHD models, and the remaining were individual studies for other NDDs (Fig. 2b, Table 1).
Table 1 Main characteristics of the reviewed articlesThere were only three studies [13, 17, 27] that used Swedish and Danish nationwide population-based registers for the model development, and the rest of the studies used EHRs. Of the studies, 82% employed classical ML methods, while the remaining 18% applied DL methods (Fig. 2c, Table S7). The majority of the studies (60%) were published in the last three years.
The comorbid medical conditions, sociodemographics, and parent medical history were the most commonly used predictor variables (Fig. 2d, Table S8). In terms of performance results, the AUC metric was greater than 75% in most studies, while the sensitivity metric was less than 75% (Table 1, Table S9), indicating a need for further advancements. In the studies reviewed here, we did not find clear association between larger sample sizes and higher performance.
Input preprocessing for addressing data quality issuesThe data used in studies were from population-based registers, EHRs or medical records (diseases, medications, lab tests, procedures, clinical notes) of patients and family members, and insurance claim forms which all are characterized by missing values, the high dimensionality of records, heterogeneity, imbalance case–control categories, errors, and systematic biases. Data imputation is one of the commonly employed methods for handling missing data. In the reviewed studies, imputation was done in different ways, including using the random forest-based methods to impute the values [24], populating the missing data with the average value for continuous variables and mode value for discrete variables [36], replacing missing values either with zeros or unknown status values [42] and use chain equations from remaining predictors to fill missing values. Mikolas and colleagues filtered the features and participants with more than 20% of missing values [35], and Garcia-Argibay, et al. [17] included features with less than 10% missing values.
The case–control class/category imbalance problem was addressed using different tools, including downsampling the number of controls [27] or upsampling the number of cases [32] by randomly generating new samples between each positive sample and its nearest neighbors, employing the Synthetic Minority Over-sampling Technique (SMOTE) method to increase the cases [17, 24] or to assign more weights to cases while training a model [34].
There are no standard ways to process multimodal data from population-based registers and EHRs for generating an effective representation. Schuler et al. [50] proposed a generalized low-rank modeling framework to form efficient representations. This low-rank modeling framework was further used for downstream clustering applications. The advent and success of deep neural networks for efficient representation learning have led to the emergence of new studies to form efficient representations for EHRs data. Landi et al. [51] have proposed a representation learning model using word embeddings, convolutional neural networks, and autoencoders to transform patient history in EHRs into a set of low-dimensional vectors. They evaluated the generated representation for patient stratification across various conditions using clustering methods and demonstrated the effectiveness of the representation. Miotto et al. [52] have applied an unsupervised DL method using denoising autoencoders to generate a representation—Deep Patient—for each patient record in EHRs. They demonstrated the effectiveness of this representation by developing risk prediction models for various diseases for patients. Most studies included in this review have used custom methods to convert the input records into a multidimensional numerical vector, while some have grouped certain factors into features and used them as input to the model.
Prediction features and ML methodsThe predictor variables used in included studies were comorbid medical conditions from ICD-9 and ICD-10 codes, health problems, medical screening data, prescribed medications of a child, parental medical histories, medications, extended family history of mental and non-mental health conditions, socio-demographics, hospital admission/discharge, outpatient visit events, clinical notes and medical claims (Fig 2d, Table S8).
The predictor variables or features were processed multiple ways to generate a unique numerical representation for each subject before training an ML model. For example, Onishchenko et al. [22] developed digital biomarkers for ASD from past medical conditions. Autism comorbid risk score (ACoR) was estimated in the early years of a child with ASD comorbidities. The score was further conditioned on current screening scores to reduce the false positive rate. A diagnostic history model using time-series patient data across 17 disease categories was developed for each patient. Chen et al. [31] developed an ASD prediction model for young children at 18 mo, 24 mo, and 30 mo using medical claims data. They have examined all diagnosis and procedure codes of a child's medical encounters and used Clinical Classifications Software (CCS) software to form different disease categories. The total number of encounters for each CCS category, sex, and encounters of emergency department visits were used as predictor variables for the model. Ejlskov et al. [27] examined the feasibility of using extended family history of mental and non-mental conditions to predict the ASD risk. A large national Denmark cohort of medical history data of three generations of family members is used for developing ML models. Morbidity indicators across 73 disorders, including mental, cardiometabolic, neurologic, congenital defects, autoimmune, and asthma of family members, were used as predictor variables. Allesøe et al. [13] have employed a DL model for mental disorder prediction, including NDDs using nationwide register data, family and patient medical histories, birth-related measurements, and genetics.
Most studies (82%) trained one or more ASD prediction models using classical ML methods. The most commonly used methods were logistic regression and random forests. Onishchenko et al. [22] used Sequence Likelihood Defect (SLD) to measure the deviations in the observed time-series diagnostic events across positive and control cohorts. It was shown that this approach resulted in better performance than state-of-the-art ML algorithms. The proposed approach has few model parameters to learn, unlike conventional deep neural networks with a large set of parameters. Yuan et al. [32] developed an ASD prediction model from medical claim forms. The medical claim forms are preprocessed to extract textual content, and natural processing techniques were applied to derive text features. These features were used to build a Support Vector Machine (SVM) classifier for ASD prediction. There were nine studies utilizing DL methods. Tran et al. [40] investigated the feasibility of using a short textual description of clinical notes to predict the risk of future multiple mental conditions, including ADHD. The baseline model was developed using the SVM classifier and compared with deep network models, such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks with Hierarchical Attention (ReHAN). The detailed list of ML algorithms used in included studies is presented in Table S7. Many studies have developed an ensemble of models using multiple ML algorithms.
The model evaluation methods used in studies involved k-fold cross-validation techniques and/or train-valid-test split methods. The performance of the algorithms was reported using the commonly used metrics, such as sensitivity, specificity, the area under the curve (AUC), positive predictive value (PPV), and accuracy. Half of the studies have reported AUC performance greater than 75%. While most studies have reported superior performance in some metrics, the sensitivity results were relatively low, as the majority showed a sensitivity of less than 75%. Not all studies have reported performance results across all evaluation metrics in a consistent way. The summary of performance evaluation metrics reported in studies is shown in Table 1, Table S9.
ML model interpretability for feature importances and generalizationModel interpretability is key to healthcare problems as it helps identify influencing variables for decision-making needed by clinicians. It is worth mentioning that most of the studies in this review have addressed the interpretability aspects in sufficient detail. The findings from the included studies and the dominating predictor variables influencing model performance varied across studies. For example, for ASD models, Betts et al. [16] identified gender, maternal age at birth, delivery analgesia, maternal prenatal tobacco disorders, and low 5-min APGAR score as dominant risk factors for ASD. Rahman et al. [24] found that the features derived from predictor variables, such as parental age and parental medications, contributed to a better ML model performance. These predictors agree with prior studies. However, they noted that the performance metrics varied across different ML models, with no one clear model outperforming all metrics. Ejlskov et al. [27] found that the best-performing ML model—extreme gradient boosting (XGB)—identified indicators across mental conditions (ASD, ADHD, neurotic/stress disorders) and non-mental conditions (obesity, hypertension, and asthma) of family members. The study concluded that a comprehensive family history of mental and non-mental conditions could better predict ASD than considering only the immediate family history of ASD. Hassan et al. [25] aim was to identify etiological factors of ASD using subject and family medical histories. Among the 81 family history attributes, six of them—father anxiety, sibling PDD-NOS, father autism disorder, sibling learning disability, father development delay, and mother autism disorder—were highly predictive of ASD. The attributes from the subject medical history that were highly predictive of ASD were atypical language development, age at 3-word sentences, age of first words, disrupted sleep patterns, dietary, gastrointestinal problems, allergies, low birth weight, and ADHD. Gender comparisons highlighted unique and overlapping conditions. One of the significant findings from this study was that parental and sibling developmental delays were strongly associated with ASD. Chen et al. [31] found that for prediction at ages 24 months and 30 months, 30–40 predictor variables were sufficient to achieve stable prediction performance, whereas, for early prediction at 18 months, the model needed 50 predictor variables. For prediction at age 24 months, the identified important variables included sex, developmental and nervous system disorders, psychological and psychiatric services, respiratory system infections and symptoms, gastrointestinal-related diagnosis, ear and eye infections, perinatal conditions, and emergency department visits. Lerthattasilp et al. [33] developed a logistic regression-based ASD prediction model. The experiments identified delayed speech, a history of avoiding eye contact, a history of not showing objects to others, poor response when the clinician draws attention, and low frequency of social interaction as the influencing predictor variables.
Garcia-Argibay et al. [17] developed an ADHD prediction model from population-based Swedish national registers. They found that parents' criminal history, male sex, relative with ADHD, number of academic subjects failed, and speech/learning disabilities were the top features contributing to the model performance. Shi et al. [34] developed ADHD and LD prediction models. The main findings from the study were that complex ML models using ICD-9 codes perform well in ADHD identification. However, they did not offer significant differences compared to using a simple model with a single family of ICD9 codes for ADHD. For LD identification, the utility of clinical diagnostic codes was limited. Mikolas et al. [35] developed a predictive model to detect individuals with ADHD comorbid with psychiatric conditions in a population. The findings from the study were: (a) age, gender, and accuracy/reaction time were more critical than other features, and (b) The ADHD core symptoms reported by parents/teachers did not carry the degree of importance as commonly assumed. Instead, combining symptoms across different domains had strong predictive power for ADHD diagnosis. Elujide et al. [38] developed an ADHD prediction model and found that the factors influencing the model were sex, age, occupation, and marital status. van Dokkum et al. [49] developed a prediction model of development delay at age 4. The perinatal, parental, and child growth milestones of 1st two years were used as predictor variables. They found that sex, maternal educational level, pre-existing maternal obesity, smiling, speaking 2 to 3-word sentences, standing, and BMI z score at one year were features of high importance for the prediction model. Allesøe et al. [13] developed a cross-diagnostic mental disorder diagnosis prediction model and found that previous mental disorders and age were the most important predictors for multi-diagnostic prediction. In summary, the most common predictor categories of NDDs across studies were patient and familial medical history and sociodemographic factors. The specific predictor variables in these categories vary across studies, making it harder to draw more detailed conclusions.
Most studies have used cross-validation and train-validation-test techniques to report model performance. While these methods provide sufficient information about the model performance in a single dataset, model generalizability can be validated using multiple independent datasets across sites and populations. For example, Onishchenko et al. [22] have used data from the Truven dataset for training models and an independent UCM database for validation. Lingren et al. [29] have used cohorts from Boston Children's Hospital, Cincinnati Children's Hospital and Medical Center, The Children's Hospital of Philadelphia, and the Vanderbilt University Medical Center in their model validation. The ADHD prediction model developed by Caye et al. [37] was validated using three external birth cohorts. Koivu et al. [42] developed a Down Syndrome prediction model using datasets from Canada and the UK for training a model and validating the model using an independent dataset from Canada. In summary, studies utilizing cohorts from distinct populations and sites for model validation for generalizability are emerging. The results of individual studies are summarized in Table 1.
Limitations in the included studiesWhile all studies reported superior performance of proposed individual models, there were not many performance comparisons across studies. There is some overlap of influencing predictive variables across studies; however, the variations in experimental conditions and target sample populations make it harder to form conclusive evidence. For instance, the sample set size varies from fifty participants to millions across studies. The risk of bias, either due to sex, gender, the proportion of cases vs. controls, target site, and populations, was not sufficiently discussed in most studies. More studies following standardized protocols and using common data are critical for reproducible research and moving toward the clinical utility of such models [53].
留言 (0)