
記住我
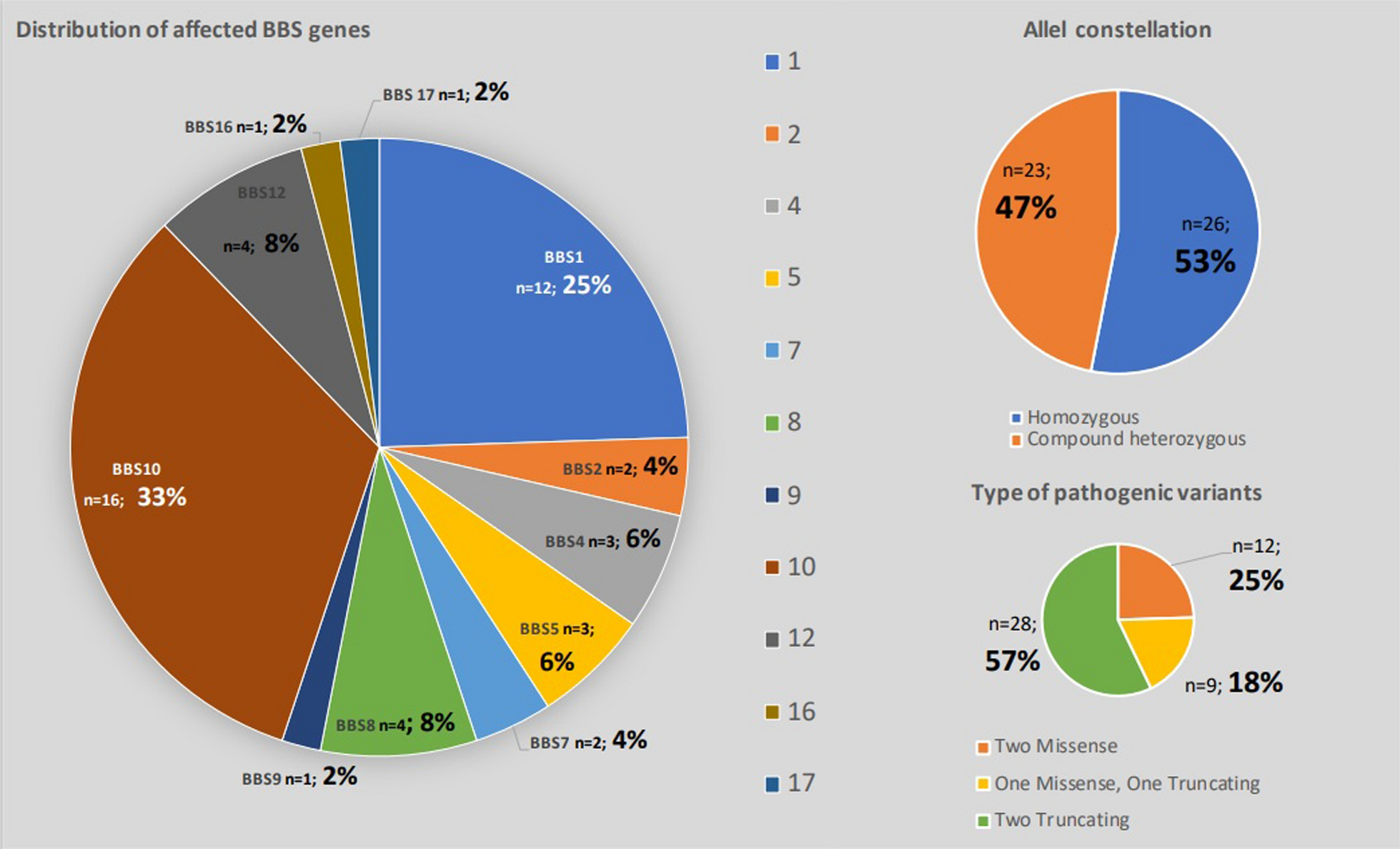
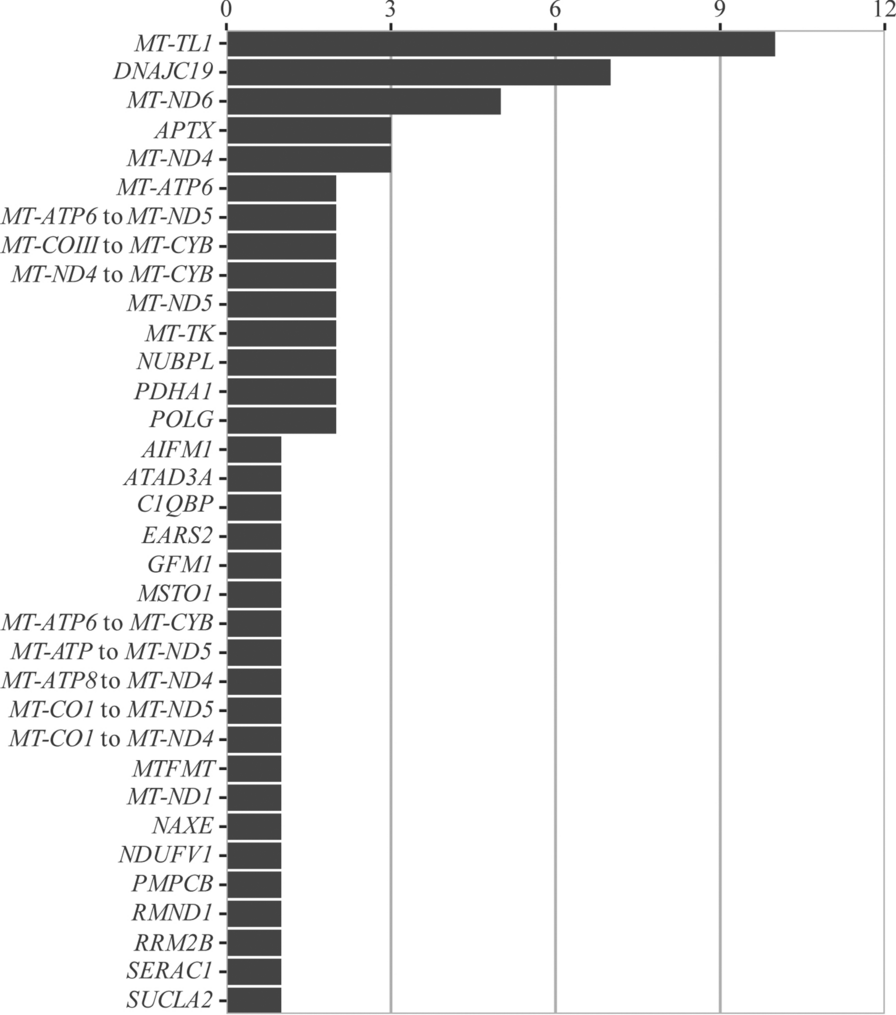


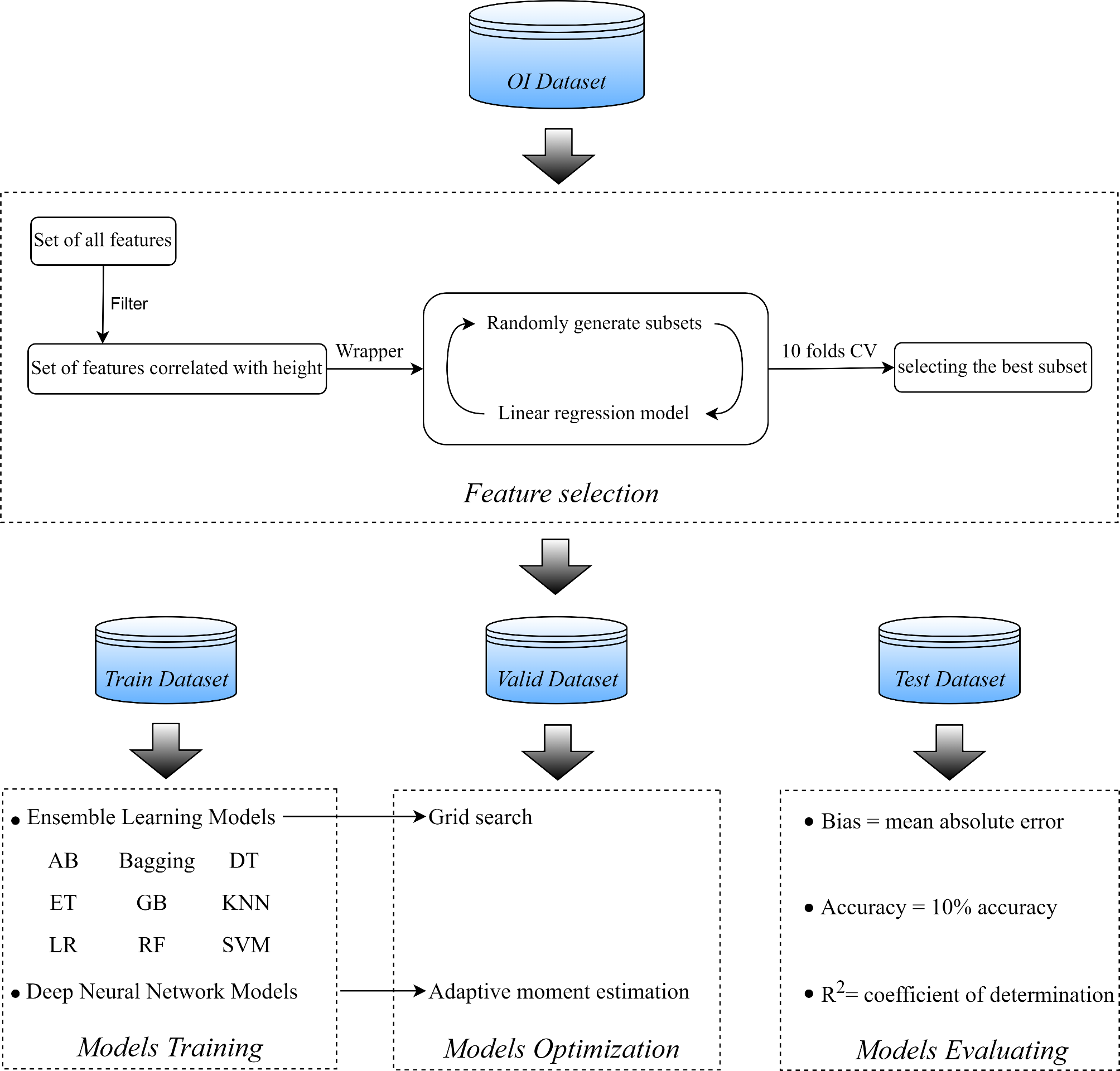

After the initial selection of features using both filter and wrapper methods, we applied ensemble machine-learning (EML) and deep-learning (DL) models to predict the height of children with Osteogenesis Imperfecta (OI). The EML model integrated various algorithms, including the AdaBoost classifier (AB), Bootstrap aggregating (Bagging), Decision Tree (DT), Extra Tree (ET), Gradient Boosting Classifier (GB), K-nearest Neighbor (KNN), Linear Regression (LR), Random Forest (RF), and Support Vector Machine (SVM). This ensemble approach was subsequently optimized using Grid Search (GS), which facilitated the fine-tuning of parameters to enhance model performance. In parallel, we developed a deep-learning model using the Keras framework within TensorFlow. This deep neural network (DNN) was specifically optimized with the Adaptive Moment Estimation (Adam) technique, aiming to refine the learning process and improve predictive accuracy. The comprehensive methodology encompassed feature selection, model construction, training, optimization, and evaluation. These steps were meticulously designed to ensure robustness and reliability in height prediction for children with OI, as depicted in (Fig. 1).
Fig. 1
The main steps of the predictive system. Filter is the method of identifying the features correlated with height. Wrapper is the method of selecting the best subset of features. AB: AdaBoost classifier, Bagging: Bootstrap aggregating, DT: Decision tree, ET: Extra Tree, GB: Gradient boosting classifier, KNN; K-nearest neighbor, LR: Linear Regression, RF: Random forest, SVM: Support vector machine
OI data setThe cross-sectional data of this study encompassed 323 participants with diagnosis of OI, date extracted for analysis including age at enrollment, gender, Sillence classification, height and weight at enrollment, area bone mineral density (aBMD) at enrollment, history of femoral rodding (yes or no) and history of tibial rodding (yes or no). The data were measured in accordance with a uniform method by a trained orthopedist. Age at enrollment was set at a minimum of 3 years old and a maximum of 24 years old. This study majored in exploring the most common children with only collagen genes mutation, children with other genes related to OI were excluded. Participants were classified into OI types I, III and IV according to clinical features, with genotypic information utilized for further verification when available. Height was measured as vertical distance from vertex to sole of the foot, which was performed by height measuring scale to the nearest 0.1 cm. The supine length was measured for subjects without ability of standing. Weight was measured using digital scale to the nearest 0.1 cm. aBMD was measured at the lumbar spine (L1-L4) using a DPX Bravo device (3030 Ohmeda Dr Madison, Wisconosin USA). Results for height, weight and aBMD at enrollment were transformed into age and gender-matched Z-scores according to national growth reference data [17]. The characteristics of participants included in the study were detailed in (Table 1). All data collected from Children’s Hospital of Soochow University were sorted and managed by Tianjin Medical University General Hospital from 2010 to 2021. The study was respectively approved by Medical Ethical Committee of participating hospital.
Table 1 Characteristics of the study populationFeatures selection: a critical step in predictive modelsFeatures selection is a prerequisite process of building an effective predictive model. After features extraction, our dataset comprised 3 continuous variables (including age, aBMD Z-score, weight Z-score) and 4 discrete variables (including gender, Sillence types, history of femoral rodding and history of tibial rodding). According to previous studies, there is no single feature selection algorithm is universally optimalis universally optimal. We firstly used the filter to remove features significantly uncorrelated with height. Then the wrapper was applied to explore the best subset of features that remained after filtering.
(i) The filtering process: The filter is usually applied as a preprocessing step, with the aim of selecting the features correlative with dependent variable. In this study, the correlation analysis was examined by Pearson’s coefficient and spearman’s coefficient for continuous variable and discrete variable respectively. This analysis resulted in the retention of five features, while two were eliminated due to their weak correlation with height (Table 2).
Table 2 Correlation between height and features(ii) The wrapper method: The wrapper uses machine learning model to choose best subset of features. Initially, we generated 26 potential subsets (excluding those composed solely of one feature) through random permutations of the five retained features. Subsequently, a linear regression model, enhanced by 10-fold cross-validation (CV), was employed to determine the subset that demonstrated the best performance (Table 3).
Table 3 Correlation between height and features$$\:CV(k)=\frac\sum\:_^MAEi$$
(1)
$$MA} = 1/n\sum\nolimits_^n }i - yi|}$$
(2)
Data divisionThe OI data set was divided into a training set, a validating set and a test set with a ratio of 3:1:2. The training set and validating set were mainly used for models training and optimization, and models evaluation was conducted in testing set.
Models training and optimizationMachine learning modelA single machine learning model might not reach the expected performance without theoretical data. Typically, ensemble machine learning (EML) achieved better capacity of prediction, as the combination of heterogeneous machine learning algorithms could alleviate the overall deviations of single model in different vector directions. In this study, we proposed an EML model by averaging the results of the nine single models, including AdaBoost classifier (AB), Bootstrap aggregating (Bagging), Decision tree (DT), Extra Tree (ET), Gradient boosting classifier (GB), K-nearest neighbor (KNN), Linear Regression (LR), Random forest (RF) and Support vector machine (SVM). Then, the grid search (GS) was employed to explore the optimum hyperparameter through testing each value of parameters.
Deep learning modelThe optimized DNN model consists of three layers, including input layer, one hidden layer and one output layer (Fig. 2). The input layer, equipped with 5 neurons, was responsible for reading the features in the OI data set, and Standard Scaler method was used for standardization of the data. The hidden layer, containing of 570 neurons, served as classifier that maps samples to each corresponding neuron. This layer utilized a random uniform kernel initializer and relu activation function. The output layer consists of one neuron, formulated as follows:
Fig. 2
The architecture of the optimized DNN model. χi is the input features, αi is the neuron in hidden layer, y is the output of the model
$$ = 1} \right)\alpha i}}_1} + 2} \right)\alpha i}}_2} + \ldots + j} \right)\alpha i}}_j} + }b$$
(3)
In which yi is the output of the i-th node of the hidden layer, ω(Χj)αi represents the weight of j-th input feature to the i-th neuron of the hidden layer, andΧj is the j-th input feature, b is the bias.
The Model.fit facilitated the training of the DNN by adjusting the weights of the neurons based on the input data. The adaptive moment estimation (Adam) was employed to optimize the DNN model. It is an easy implementation and efficient computing optimization method based on adaptive lower-order moment estimates. Different from the Stochastic Gradient Descent (SGD), Adam can easily search the optimum hyperparameters for our DNN models by iteratively updating the network weights, in addition, the learning rate of parameters in each iteration is within a certain range, and the overall parameter value is relatively stable. To prevent overfitting, early stopping was implemented to halt training once a predefined performance threshold was achieved.
Parameters in DNNHidden Layer. Since single large hidden layer was adequate for a continuous mapping from one finite space to another, one fully connected layer was selected in this study with relatively small samples.
Number of hidden layer neurons. There was no recognized method to determine the number of neurons in the hidden layer. Inappropriate less neurons will reduce the accuracy of the model, nevertheless too many neurons in hidden layer will exhaust computing resource. The number of neurons has adapted from 50 neurons to 700 neurons, and the optimal number of neurons was finally set at 570 with the lowest mean absolute error (MAE) (Table 4).
Table 4 The number of neurons for DNNThe Number of Iterations. The DNN model converges when the number of iterations reaches 200 times with the error reaching the goal at 0.001.
Evaluating modelsThe performance of the models were assessed using three primary metrics: bias, accuracy, and R2. Bias refers to the Mean Absolute Error (MAE), which quantifies the average magnitude of the errors in predictions, irrespective of their direction. Accuracy is defined as the proportion of predictions where the predicted height deviates by no more than 10% from the actual measured height. R2, or the coefficient of determination, measures the proportion of variance in the observed data that is predictable from the model inputs, thus indicating the fitting degree of the predictive models.
Statistical methodsStatistical results were analyzed by using the software SPSS 25 (IBM Corporation, Armonk, New York). Normality of distribution was evaluated using the Shapiro-Wilk tests. Continuous variables were described as median and interquartile ranges, and were compared among the groups using the Kruskal-Wallis test with Bonferroni’s post hoc comparisons for more than two groups because of the asymmetric distribution of data after the normality test. In order to compare the growth patterns in different gender and OI types, data were divided into one-year intervals, with the lowest bin at 3 years and the highest bin at 24 years, to acquire the age at which the curves of each category begin to show statistical differences.
留言 (0)