
記住我


Neuropsychiatric diseases are currently the leading cause of disability and dependency worldwide. Among them, the neurodegenerative diseases Parkinson’s disease (PD) and Alzheimer’s dementia (AD) are rising the fastest (Dorsey et al., 2018). Aging represents one of the strongest risk factors for both diseases. Predictions indicate that the prevalence will double worldwide in the next 20 years (Ferri et al., 2005). Since there is considerable diversity in the rate at which we age, the identification, and effect size of risk and protective factors that indicate the dynamic processes from aging to neurodegeneration is of high interest. While some factors, such as sex and genetic status, are immutable, a large proportion can be influenced by lifestyle. These factors include cardiometabolic, physical, and educational profiles (Mukadam et al., 2024; Cova et al., 2017; Livingston et al., 2020). This offers the opportunity to focus on these factors for preventive healthcare strategies. However, many of these factors are interdependent. Moreover, the heterogeneity of human subjects and intervals of data collection in longitudinal studies make it difficult to extract suitable data for robust statistical predictions. Conventional statistical methods cannot accommodate these complex relationships. Therefore, we used an unbiased machine learning approach by developing a Bayesian model to simultaneously predict aging-related key functions such as motor and cognitive function from a single composite score that reflects a large set of multi-modal factors, including genetic, biofluid, clinical, demographic, and lifestyle factors.
Similar models have been used in high-dimensional medical settings using imaging or genetic data (Goh et al., 2017) and also to investigate dietary patterns by fat types (Brayner et al., 2021). However, such methods have not been used in multi-modal settings assessing aging- and neurodegeneration-related profiles. Importantly, we primarily focused on factors that were already identified in epidemiological and genetic studies by standard statistical approaches in order to facilitate a proof-of-concept for the Bayesian model.
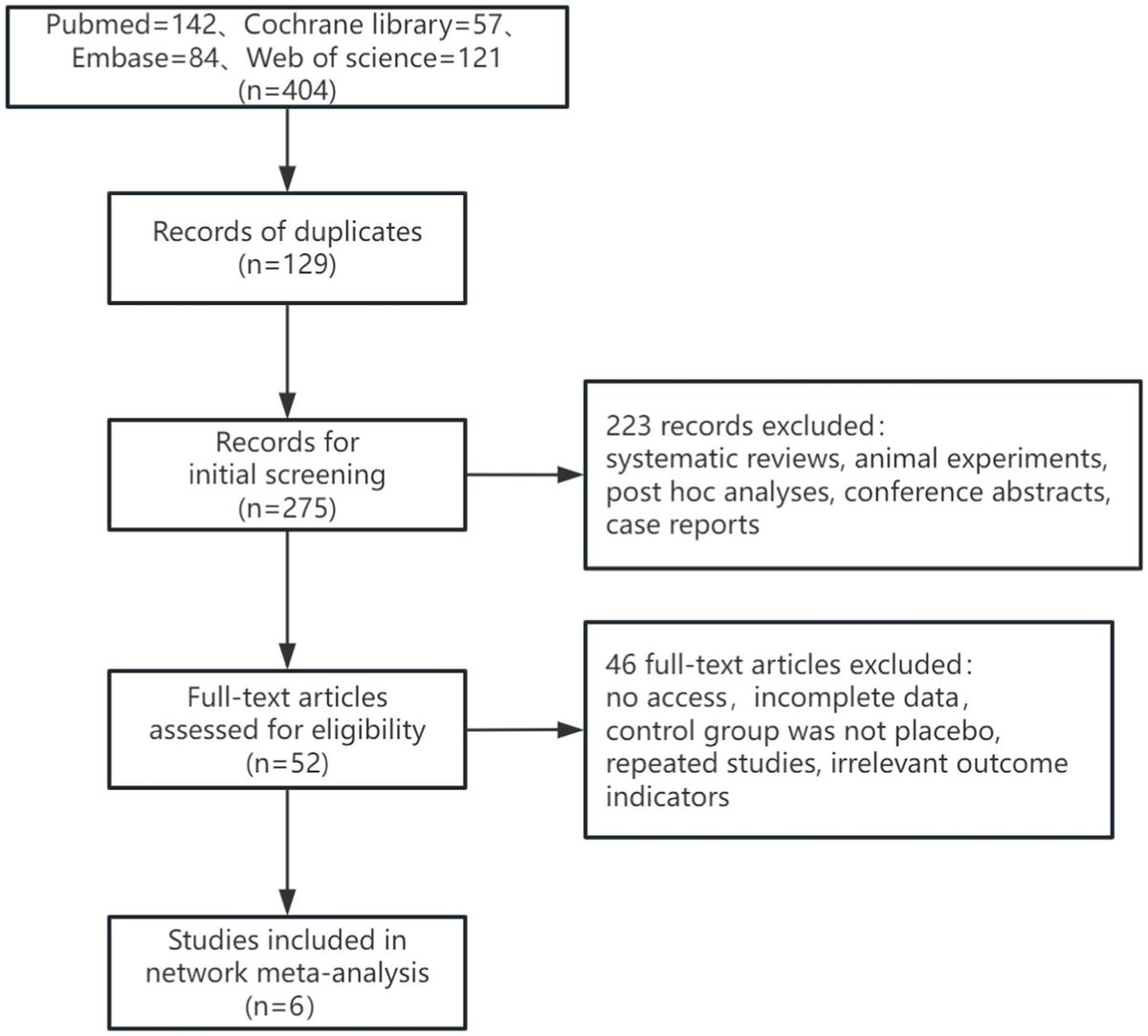
Methods Study populationWe used the data from the TREND study (Gaenslen et al., 2014) which is a prospective longitudinal study initiated in 2009 with biennial assessments of older participants aged between 50 and 80 years without neurodegenerative diseases at study recruitment. Newspaper announcements and public events were used to recruit participants from Tübingen and the surrounding area. Between 2009 and 2012, 1,201 participants underwent baseline assessments. For study inclusion, participants had to be free of a diagnosis of a neurodegenerative disorder, history of stroke, inflammatory disorders affecting the central nervous system (such as multiple sclerosis, encephalitis, meningitis, vasculitis), and inability to walk without aids. The study has been performed at the Department of Neurology and the Department of Psychiatry of the University Hospital Tuebingen, Germany. A large assessment battery with quantitative, unobtrusive measurements for repeated objective application was designed. To avoid bias in data acquisition, all investigators were blinded to the results of all other examinations. For more details about the TREND study please visit https://www.trend-studie.de/. Supplementary Figure S1 summarizes the exclusion criteria and selection of participants for the current analysis.
Clinical investigations Motor function: gaitFor the assessment of motor function, we decided to focus on gait as representative of axial motor performance which is key for maintaining independence in older participants. Gait assessments were performed in an at least 1.5 meters wide corridor allowing obstacle-free 20-meter walking. All subjects performed four single-task conditions: 1. walking with habitual speed, 2. walking with maximum speed, 3. checking boxes with maximum speed while standing, and 4. subtracting serial 7 s with maximum speed while standing. Additionally, two dual-task conditions were performed: 1. walking with maximum speed and checking boxes with maximum speed and 2. walking with maximum speed and subtracting serial 7 s with maximum speed (Hobert et al., 2011).
Based on the two dual-task conditions, we extracted the respective four dual-task speeds: 1. checking boxes when walking (number of boxes per second), 2. walking when checking boxes (meters per second), 3. subtracting when walking (number of serial 7 s subtractions per second), 4. walking when subtracting (meters per second). The single and dual-task speed parameters were then used to calculate dual-task costs and overall speed according to the following formulae:
• Overall speed: dual-task speed + single-task speed
• Dual-task cost: dual-task speed – single-task speed
CognitionA detailed assessment of cognitive function was implemented using the standardized German version of the extended Consortium to Establish a Registry for Alzheimer’s Disease (CERAD)-Plus neuropsychological battery (Morris et al., 1989; Rossetti et al., 2010). This comprehensive battery includes the following cognitive subtests: semantic and phonematic verbal fluency tasks, the Boston Naming Test, Mini-Mental Status Examination, word list learning, word list recall, word list recognition, figure drawing, figure recall, and the Trail Making Test (TMT) A and B (Welsh-Bohmer and Mohs, 1997; Ehrensperger et al., 2010). The TMT consists of two parts and evaluates executive function, cognitive flexibility, and working memory (Bowie and Harvey, 2006). In part A, participants connect randomly spread numbers from 1 to 25 in ascending order. In part B, participants are asked to connect randomly spread numbers () and letters (A to L) in alternating numeric and alphabetical order (1-A-2-B-3-C-…-13-L). In case of an error, the examiner draws the attention of the participant to the error, to allow completion of the task without errors at the expense of additional time. The maximum time allowed is 180 s for part A and 300 s for part B. After this time, the investigator discontinues the experiment. Two parameters were calculated from the TMT A and TMT B tests:
• Overall speed: TMT A + TMT B
• Cognitive flexibility: TMT B – TMT A
Next, to the CERAD total score, subscores of the different CERAD domains were included in the analysis. Ordinal variables were measured on a Likert scale and indicated the number of items completed correctly.
Medical condition and lifestyle HypertensionLifetime diagnosis of hypertension (medical history) and/or intake of anti-hypertensive medication was defined as the presence of hypertension.
ObesityBody mass index (BMI) was calculated by: mass [kg]/(height [m])2.
Body composition (fat/skeleton muscle mass)Body composition was assessed by bioelectrical impedance analysis using a body impedance analyzer (BIA 101, Akern, Germany) for two out of four visits. Therefore, ohmic resistance was measured between the dominant hand wrist and dorsum and the dominant foot angle and dorsum in the supine position. Muscle mass in kg was then calculated according to Janssen et al. (1985) and subsequently normalized to subjects’ body height squared (skeletal muscle index: SMIBIA): with body height in centimeters, resistance in Ω, for gender: male = 1 and female = 0, and age in years.
Assessment of physical activityPhysical activity was assessed by a self-administered questionnaire. This questionnaire is part of the Bundes-Gesundheits Survey (national health survey) and allows to rate physical activity between 0 and 4 (0 = no activity, 1 = 0.5–1 h per week, 2 = 1–2 h per week, 3 = 2–4 h per week, 4 = more than 4 h per week) (Mensink, 1999).
Smoking and drinkingPersonal history of smoking and alcohol-drinking behavior was assessed by a self-administered questionnaire. Pack-years were calculated by quantifying the packs (20 cigarettes/pack) smoked per day multiplied by years as a smoker. The frequency of drinking alcohol was assessed on a scale from 0 to 4, which indicates the number of drinks per month.
Genetic risk factors for Parkinson’s disease and Alzheimer’s diseasePathogenic variants in LRRK2 and GBA are the most common PD-associated genes. DNA was isolated from EDTA blood by salting out and stored at 4°C. All participants were analyzed by NeuroChip. Pathogenic variants in LRRK2 and GBA were confirmed by Sanger sequencing. None of the participants carried a LRRK2 mutation. Fifty-seven participants carried a GBA variant. We further grouped those according to known PD-specific mutation severity: wild type (0), low risk (Dorsey et al., 2018), and mild/severe (Ferri et al., 2005). Moreover, the most relevant single-nucleotide polymorphisms in genes for PD (SNCA rs356220 or proxy rs356219) and AD (ApoE, MAPT) were investigated to explore the effect on motor and cognitive function. We grouped the number of risk alleles according to an additive model: SNCA rs356220 (or proxy rs356219) minor allele C (0, 1, 2), ApoE4 allele (0, 1, 2), and MAPT haplotype (H1/H1, H1/H2, H2/H2).
Measurement of neurofilament light chain in bloodNeurofilament light (NFL) chain protein is an unspecific biofluid marker that reflects the extent of neuronal/axonal damage. Blood samples were collected on the day of the study visit, cooled, centrifuged (4°C, 10 min, 2000 g), aliquoted, and stored at −80°C within 4 h after collection. They were analyzed without any previous thaw–freeze cycle. Serum levels of NFL as a marker for neuronal-axonal damage were measured in duplicates using the SIMOA NF-light KIT (Quanterix, Product number: 103186) on the SIMOA HD-1 Analyzer (Quanterix, Lexington, MA) as established previously (Kuhle et al., 2016). Technicians were blinded to all other tests of the participants.
Definition of age-related key functions and model overviewThe aim was to simultaneously predict aging-related key functions of motor and cognitive performance from a large set of multiple multi-modal factors including genetic, biofluid, clinical, demographic, and lifestyle factors (Supplementary Table S1).
As outcome measures for motor function, we defined the different gait conditions:
• Overall speed: dual-task speed + single-task speed
o Walk while subtract serial 7 s dual + single walk
o Subtract serial 7 s while walk dual + single subtract serial 7 s
o Walk while cross boxes dual + single walk
o Cross boxes while walk dual + single cross boxes
• Dual-task cost: dual-task speed – single-task speed
o Walk while subtract serial 7 s dual—single walk
o Subtract serial 7 s while walk dual—single subtract serial 7 s
o Walk while cross boxes dual—single walk
o Cross boxes while walk dual—single cross boxes
As outcome measures for cognitive function, we used the CERAD and defined the different CERAD subdomains:
• Overall cognitive function: Total score
• Memory function: Word list learning and word list recall
• Executive function: TMT A + B and TMT B—A
All scores were transformed such that higher values reflect worse performance by flipping the scale.
Our goal was to develop a Bayesian RRR model that simultaneously predicts all motor and cognitive outcome measures from a single composite score extracted as a linear combination of lifestyle and genetic factors and compare this model to conventional statistical approaches (Supplementary Table S1). This restricts the flexibility of the model but increases its ability to identify a key feature extractor by using several prediction targets. Figure 1 illustrates the rationale for Bayesian RRR compared to classical multivariate linear regressions.
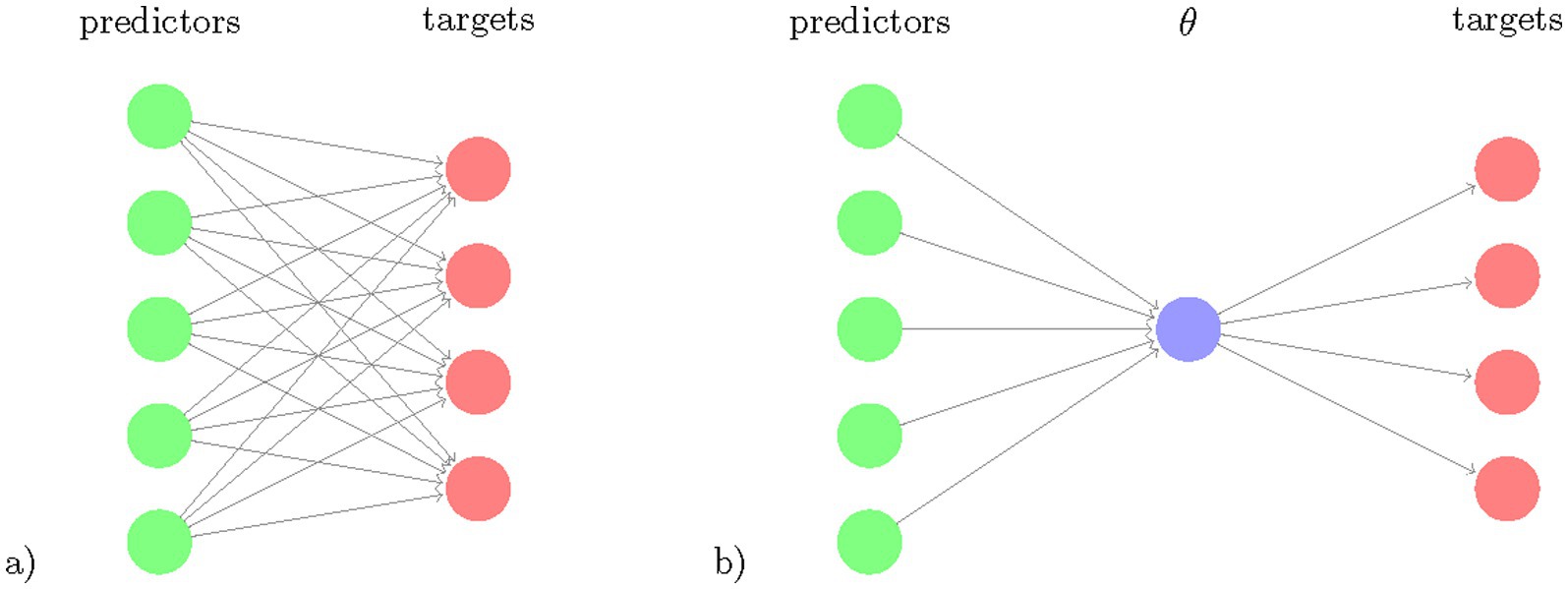
Figure 1. Schematic comparison of multivariate regression and reduced rank regression. The number of coefficients to learn (number of arrows) is illustrated for (a) multivariate regression and (b) reduced rank regression. The latent variable θ , the composite risk is a linear combination of the predictors and is projected via linear multiplications to the targets.
We used python 3 (3.8.2) in combination with the probabilistic modeling library PyMC3 (3.9.3) (Salvatier and Fonnesbeck, 2016) to implement the Bayesian RRR model. The ordinary least squares (OLS) models were implemented with statsmodels (0.11.1) (Seabold, 2010). Model evaluation was performed using scikit-learn (0.23.1) (Pedregosa et al., 2011). We used datajoint (0.12.6) (Yatsenko et al., 2015) to build our data processing pipeline.
Handling missing dataMissing data of predictor variables were handled in the same way for both models. After subject and visit exclusion as detailed in Supplementary Figure S1, we assessed the missingness of the predictors across all remaining visits. The percentage of missingness for time-varying predictor variables can be found in Supplementary Table S1. To increase the amount of available data points, we performed imputation. We did so only for subjects with at least one value available for each predictor. Based on the assumption that predictors only change when a new value is given, we first applied forward filling and then backward filling.
Models Reduced rank regression model and Bayesian reduced rank regressionOur reduced rank regression model is based on the observation that the outcome measures/clinical tests are correlated and thus can be represented through a smaller set of latent variables. Therefore, we used an RRR model that allows us to predict multiple response variables from the same set of predictor variables while reducing the amount of model parameters (Figure 1). RRR can be seen as a multivariate regression model with a coefficient matrix of reduced rank (Velu, 2013). RRR is a computationally efficient method that increases statistical power in settings where the number of dimensions is large compared to the number of examples. In such m ≫ j settings, RRR is nowadays a state-of-the-art method in fields with high-dimensional data, such as genetics and imaging (Zhu et al., 2019; Kobak et al., 2021). Given j observations of m predictors and n outcome measures, standard multivariate regression requires fitting m n coefficients Y = XC + E, with Y being the response matrix of size j × n, X being the j × m predictor matrix, C the m x n coefficient matrix and E being the error term matrix of size j × n. The RRR is obtained by adding a rank constraint rank(C) = k, k ≤ min (n,m). The rank constraint decreases the dimensionality of the model and improves the statistical power. Using the rank constraint, C can be rewritten as C = ABT, with A of size m × k and B having size n × k. Hence, the model can be expressed as Y = (XA) BT + E.
This decomposition allows for interpretations of A and B. A is a mapping from the predictor matrix X to a latent representation of dimension k. B is a mapping from the latent scores to the responses Y. The latent scores XA display the low-dimensional predictor variability that is predictive of the response variability.
We used Bayesian inference for our RRR model to obtain parameter uncertainty and handle missing data. This means that given observations X and Y, we sampled model parameters Ψ from the posterior distribution p(Ψ|X,Y) ∝ p(Y|Ψ,X)·p(Ψ). The variable Ψ generically denotes all parameters of the model. The Bayesian framework requires a prior distribution p(Ψ) that embodies our prior knowledge about these parameters and the behavior that we want the model to exhibit. We are specifying these choices in the following paragraphs.
Least squares regression models can easily be transformed into Bayesian models by rewriting the model as Y ∼ N(XABT,σ2), where N(μ,Σ) denotes the normal distribution with mean μ and covariance Σ. Given a high-dimensional data setting, it is likely that some of the predictors are non-informative for some of the outcome measures. A Laplace prior to A can realize this desired sparsity as it promotes element-wise sparsity: Certain elements in A are set to 0, resulting in a latent composite score depending on certain predictors but not on others.
Suppose we have a predictor matrix X which holds information about m predictors (time-varying and static) for j visits of subjects. Through A those are mapped to the latent space of size k, such that we obtain k composite scores for each visit, θ. For visit i, we thus get for composite score f: θif = ∑l = 1m Xil Alf. A priori, each element of A is sampled from a Laplace distribution Laplace(x,μ,b)= 12bexp−x−μb with b = 1 to enforce element-wise sparsity. The matrix B maps back from the latent space to the response space. A lognormal distribution ln(eμ + σZ) with σ = 0.25 is used prior to enforcing the positivity of the coefficients. By centering the real responses prior to learning, an offset can be omitted. For visit i we get a prediction for the response o via Yio = θ’ioBo for which we assume a Gaussian observation noise with σ = 0.908, which is informed by the MSE on the training data of the multiple OLS models. We trained a model with k = 1, for which we present the results in the main text, but we also trained a model with k = 2 to check how this increase in complexity improves the performance. We further trained a model with k = 1 and a deterministic B = 1 to check whether our Bayesian model with similar complexity to the OLS models performs as well as those. The results can be found in Supplementary Table S3.
Ordinal predictorsWe further improved our Bayesian RRR model through the way it handles ordinal predictors. Ordinal variables are commonly used in clinical settings. However, in most modeling approaches, they are encoded as either nominal or interval variables. The former disregards the ordering information, and the latter assumes regular spacing, which may not be given. To correctly use ordinal predictors, one can use monotonic effects (Burkner and Charpentier, 2020) (Supplementary Figure S2). This transformation ensures a monotonic increase or decrease, while adjacent categories can be arbitrarily spaced. For an ordinal predictor x taking values xn∈ a monotonic transformation is defined as mo:0…D→0D,xn→moxnζ=D∑i=1xnζi where ζ is the element of a simplex, meaning it satisfies ∑i=1lζi=1 and ζ_i∈[0,1]. It can be interpreted as the normalized distances between adjacent categories. As D can be absorbed into the regression coefficients A and lead to redundancies, we instead encoded ordinal variables in our model with: cmoxnζ=∑i=1xnζi.
This still ensures a monotonic transformation with arbitrary spacing; however, the effect and sign will be inferred through the regression coefficient. In our Bayesian RRR model, we chose a Dirichlet prior for the ζi as it is the natural choice for a prior on simplex parameters. By choosing a constant α = 1, we effectively used a uniform (equal probability) prior to the probability simplex, i.e., all vectors ζ that sum to one are equally likely. The a priori expectation of ζ is given by wi=Eζi=αi∑i=1Dαi . With α = 1, we have wi=1D . This prior centers the category distances, ζ around a linear trend but allows for high variations around this. This transformation was applied to the ordinal predictors in X prior to the RRR.
We decided to model the genetic data as ordinal predictors as well. The monotonic transformation allows us to consider dominant (0 vs. 1), additive (0 vs. 1 vs. 2), as well as recessive (0 vs. 2) effects simultaneously.
Model comparisonTo compare the predictive performance of the Bayesian RRR model against a more flexible and traditional approach, we trained 13 OLS models that each predict a single outcome measure from the set of predictors. To handle the longitudinal data, we decided to include all available visits of each subject, thereby having subjects unequally represented in the dataset. The models thus treat each visit as an independent data point, disregarding the correlation arising from repeated measures of the same subject. As the outcome measures have variable availability (Supplementary Table S2), for each model, the valid visits to include for training were selected separately in order to maximize the number of overall data points. For each outcome measure, we kept all data points where the outcome measure itself was available. We thus trained the OLS models on differently sized datasets. In contrast, the Bayesian RRR model was trained on all targets simultaneously. Due to the nature of the Bayesian framework, we can include data points where parts of the outcome measures are missing. Thereby the entire Bayesian RRR is trained on the union of the datasets for the OLS models but for each outcome measure, only the same visits as for the corresponding OLS model are used for training. For the OLS models, we decided to use dummy encoding for nominal and ordinal predictors and include an intercept term. For a predictor with n categories, we thus included n−1 coefficient in the model. Real-valued predictors were standardized. All models were fit using mean-squared error loss. We performed 5-fold cross-validation using 20% as test and 80% as training data, ensuring that visits of the same subject are grouped into either one. For each fold, the outcome measures and real-valued predictors were standardized on the training set. As no hyperparameters (values that we set to control the learning process) were learned, cross-validation yielded a measure of uncertainty for the prediction performance from the 5-folds. All performance evaluations and comparisons were conducted through this cross-validation. We retrained all 13 OLS models on their respective complete datasets (training and test) to obtain the final coefficients for the predictors.
Sampling from the posteriorWe sampled from the posterior p(Ψ|X,Y) through NUTS sampling (Hoffman and Gelman, 2014) with two chains, each with a burn-in of 2000 samples and 500 retained samples. We thus obtained 1,000 samples from the posterior distributions of each parameter. Subsequently, we obtained the posterior predictive distribution by feeding the samples through the generative model: p(Y|X) = ∫ p(Y|Ψ)p(Ψ|X)dΨ.
These predictions were used for performance evaluation. To assess the generalization of our model, we performed a 5-fold cross-validation where for each split the data were randomly split into a test (20%) and train (80%) set, ensuring that each subject is only in either one. We retrained the model using the whole dataset to obtain the final posterior distributions for the coefficients.
Performance evaluationWe used the coefficient of determination R2 to compare our model performances. Suppose we have n data points with yi being the true value for visit i, y ̂i being our predicted value, and y− being the mean of the true values. R2 is defined as R2=1−∑i=1nyi−ŷi2∑i=1nyi−y−2.
It is 1 for perfect prediction and 0 when the mean is predicted. Note that, R2 can be negative if the prediction is worse than the mean, i.e., the constant predictor. We calculated R2 as the standardized mean-squared error (MSE): R2=1−MSEvary where y are the true values. To make the measure more robust, we decided to normalize the MSE by the variance of the whole dataset, i.e., train and test set. This better captures the true variation regardless of the applied train/test split. We compared the performance over the 5-folds of the OLS models and the Bayesian RRR model for each clinical test with a t-test.
We evaluated the significance of predictors of the multiple linear regression models with t-tests and a type-I error threshold for a p-value of 0.05 that is corrected by the number of tests performed using Bonferroni correction. For our Bayesian RRR model, where we obtained posterior samples for our coefficients, we calculated the highest posterior density (Turkkan, 1993) (95%) and defined significance as this interval not crossing 0.t.
Results Model performanceThe Bayesian RRR composite score model achieved comparable performance to classical linear regressions (OLS) per clinical outcome measure (Figure 2). It showed similar levels of explained variance for all cognitive outcome measures (Supplementary Table S3). Separate linear regressions significantly outperformed the composite score model in the four gait-related outcome measures (walk while cross dual – single, subtract while walk dual – single, walk while subtract dual + single, walk while cross dual + single), Figure 2. Our composite score model performed on par with linear regressions in predicting the gait-related outcome measure “Subtract while Walk Dual + Single” which is the gait measure that has the highest cognitive load as it measures the speed of mathematical calculations while walking. Overall, the composite score model performed well on cognitive outcome measures, on par with the OLS models, and worse on gait-related measures. This indicates that a composite score RRR model with a single explaining factor performs almost equally well as several individual OLS models.
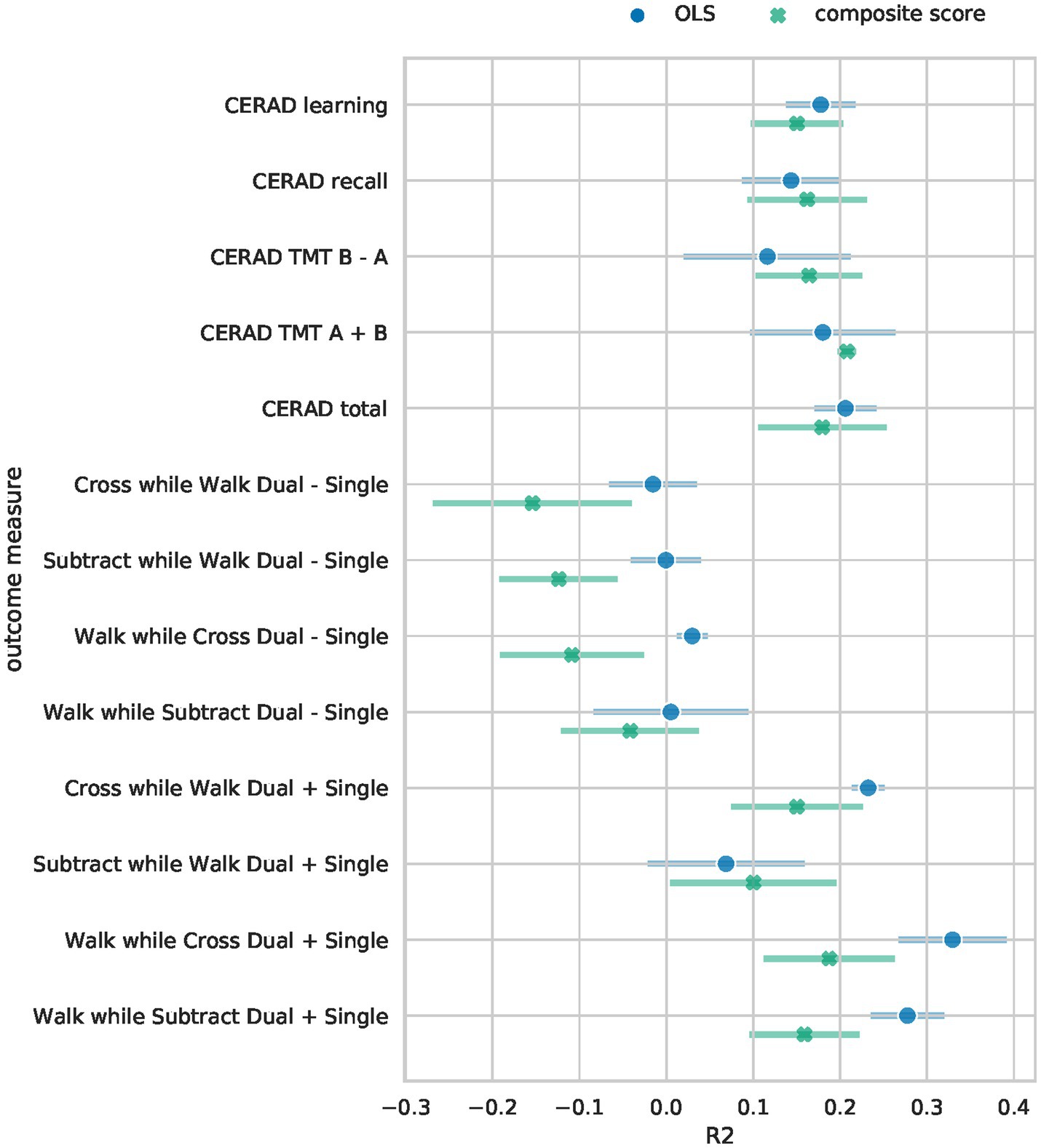
Figure 2. Performance comparison of Bayesian RRR and multiple OLS. The mean 5-fold CV R2 on the test sets is shown for each of the outcome measures. Error bars denote the 95% confidence interval across 5-folds. For the Bayesian RRR, we show the mean across 5-folds of the mean R2 over 1,000 samples and the corresponding 95% confidence interval across 5-folds.
To assess whether the worse performance in the four gait-related measures is due to the reduced complexity of our model or due to other model specifications, we trained a separate Bayesian RRR for each outcome measure. These performed as well as the OLS models on all tasks (see A6).
All models recover known protective and risk factors Multiple linear regressionsThe multiple linear regressions showed an overall agreement for the effect direction, i.e., whether a factor is a risk or a protective factor (Figure 3). Factors identified as protective are female sex, longer time in education, and a higher level of physical fitness (hours of exercise per week, higher skeleton muscle mass). Only for some movement speed-related outcome measures (walk while subtract/cross dual—single) female sex negatively impact the outcome measure (i.e., decreased performance). Risk factors that were in agreement between the majority of the OLS models are older age, a higher number of cigarette pack-years, and a higher BMI.
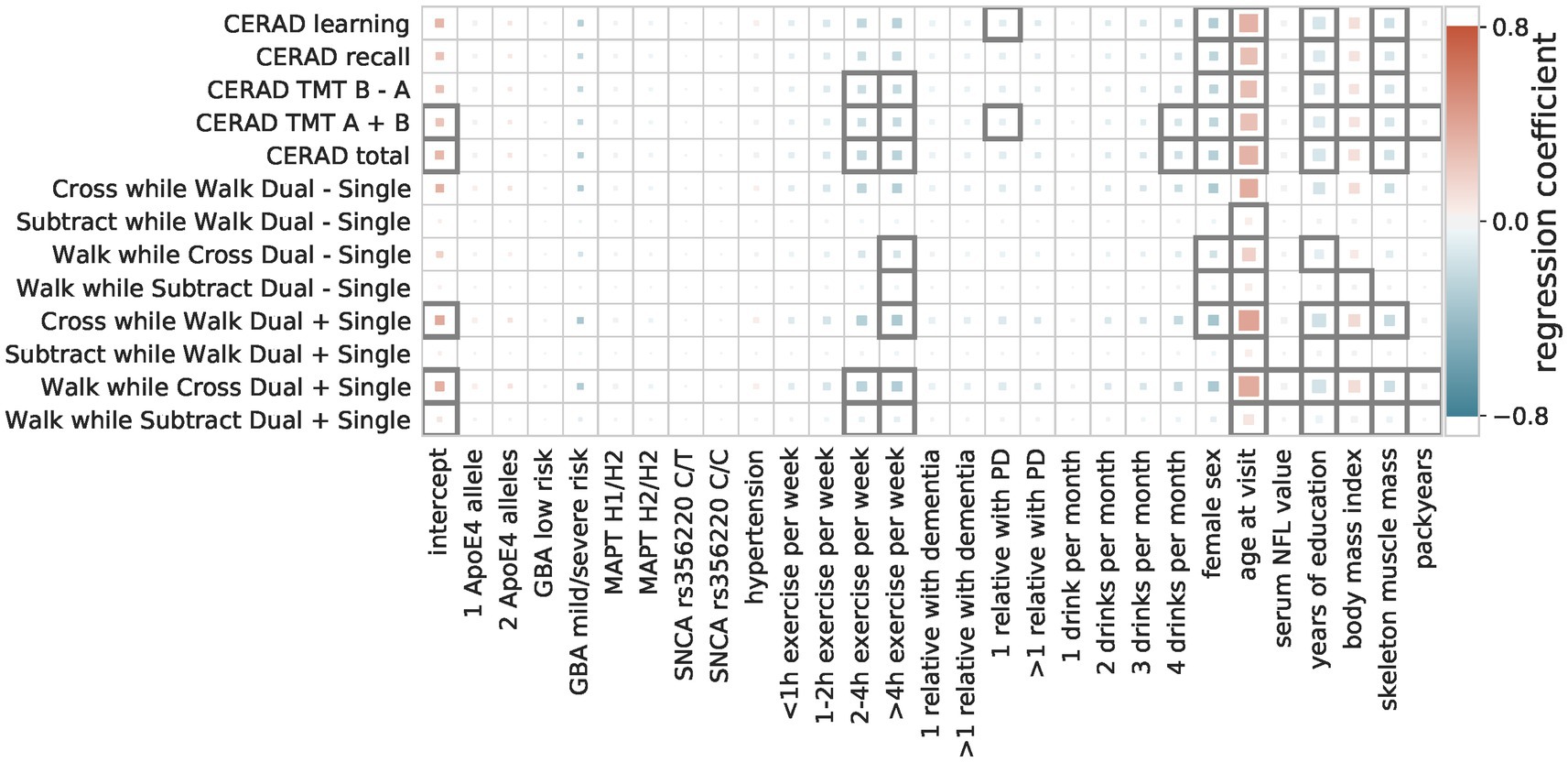
Figure 3. Regression coefficients of multiple linear models. The influence of the predictive factors (x-axis) on the outcome measures (y-axis) is shown. The color indicates the size and direction of the effect (protective = blue, risk = red), with the size showing the importance (abs(coefficient)/standard error) and a black outline indicating significance (Bonferroni-corrected p-threshold 0.05).
Bayesian reduced rank regression composite score modelThe composite score Bayesian RRR model merged this overall agreement of the OLS models into one composite score (Figures 4, 5). In addition to the identified factors from the OLS models, the Bayesian model identified hypertension, ApoE4 genotype, and higher NFL values as significant risk factors. The number of relatives with PD or dementia was not significant in any OLS model but was identified as a significant protective factor in our composite risk model. The Bayesian RRR further identified genetic variants in GBA and MAPT (H2 haplotype) as protective factors.
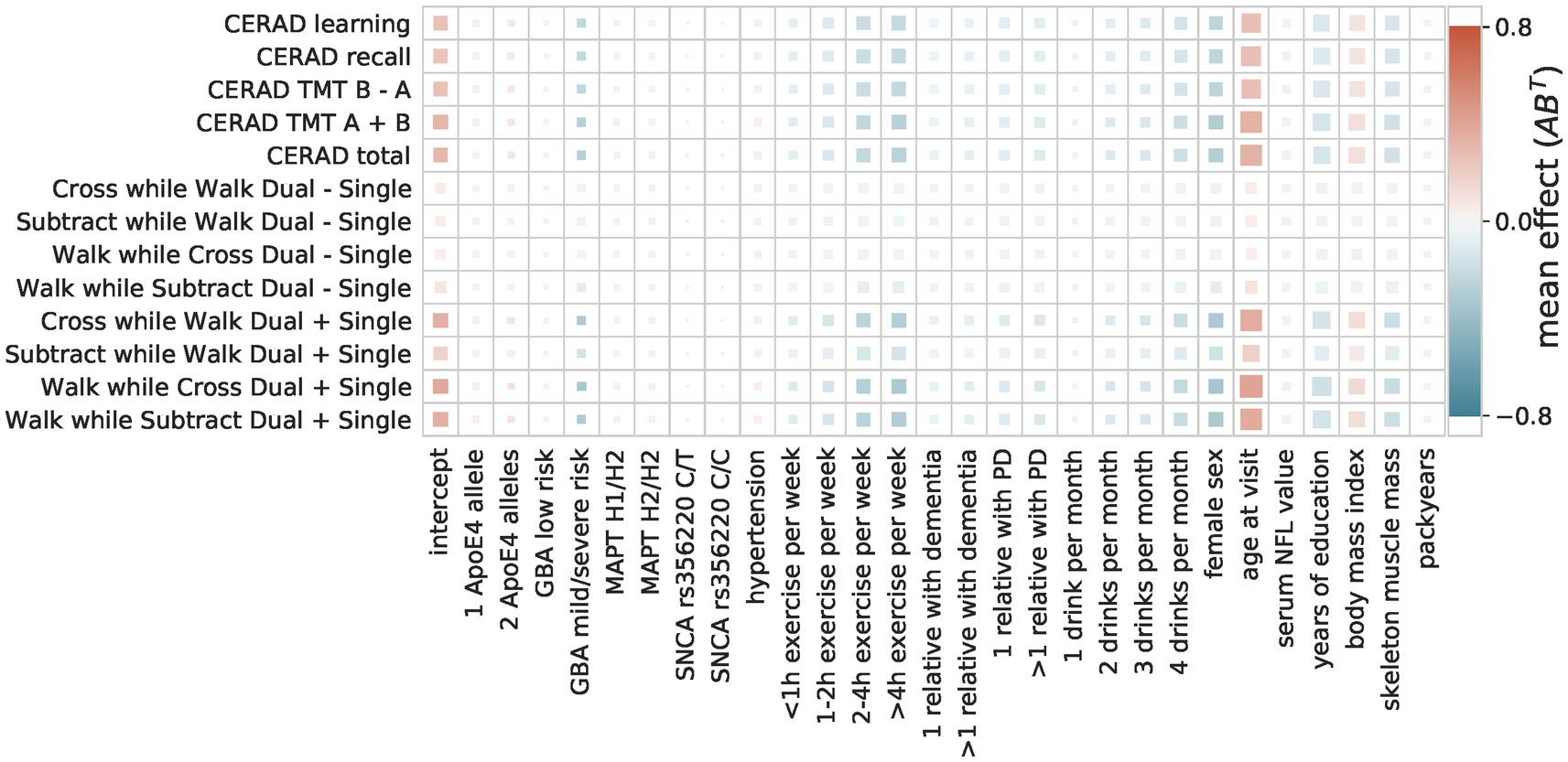
Figure 4. Composite score model The composite score model recovers the overall agreement of the coefficients across the multiple OLS models. The color indicates the direction and size of the effect of a predictor (x-axis) on a target (y-axis). The size of the square indicates its importance as the absolute ratio of mean and standard deviation (the larger the further away from 0).
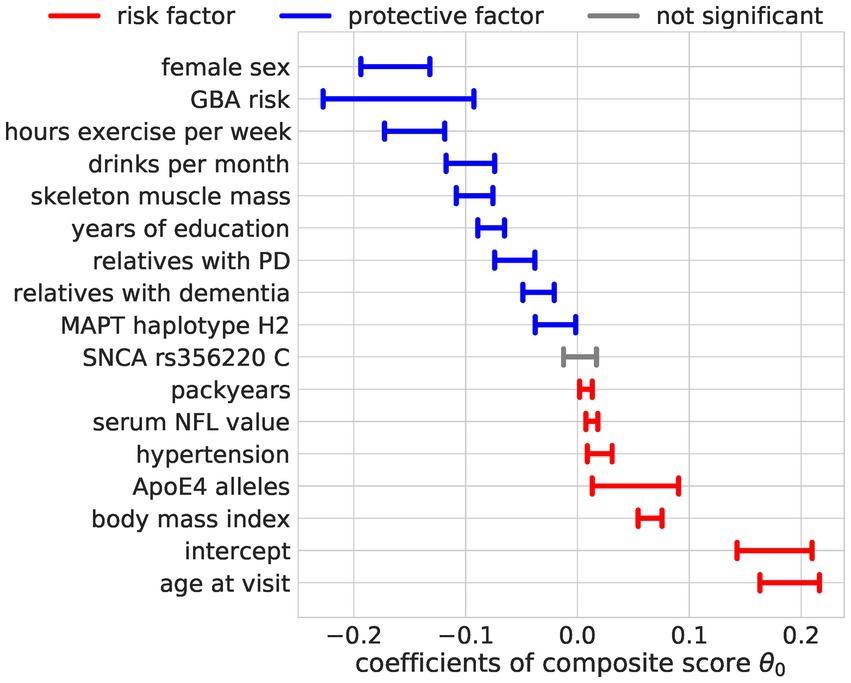
Figure 5. Regression coefficients for the composite score model. The estimated effect sizes of the predictors on the composite score are displayed. The highest posterior density is plotted. The coloring indicates significance (95% highest posterior density contains 0, not significant = gray) and direction of the effect (blue = protective, red = risk).
Monotonic transformation reveals a proportional effect on exerciseThe encoding of ordinal factors in our model allowed for fine-grained information on their effect on the composite score not addressed by a nominal encoding as used in the OLS models. By learning the distance between the categories of ordinal predictors through monotonic transformation, we obtained flexible spacing of the different levels with additional meaning (Figure 6). We saw a steep reduction of risk for people who drink at least two drinks per month but increasing the number of drinks did not further reduce the risk substantially. In contrast, for physical exercise, we observed no such saturation and can conclude that more exercise is more protective. We also note a steep increase in risk for carriers of 2 ApoE4 alleles compared to carriers of one allele. Contradictorily, heterozygous carriers of mild and severe GBA variants seem to be more protected than those with GBA wildtype.
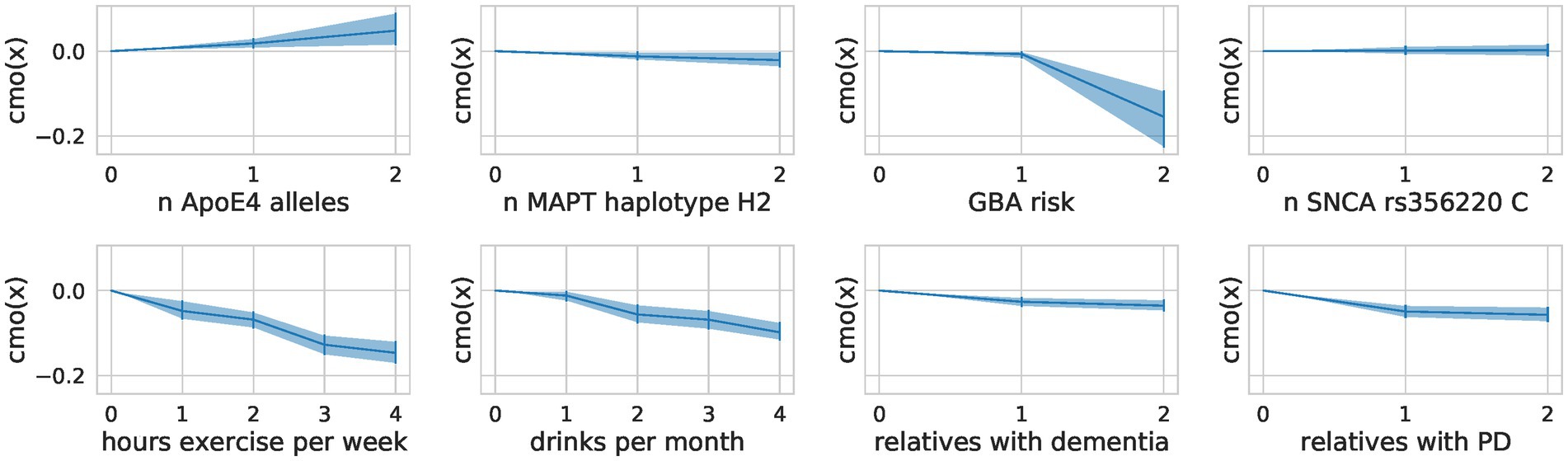
Figure 6. Flexible spacing of ordinal predictors. For each ordinal predictor, we show the distance between the categories modeled through a monotonic transformation in the composite score model. We plot the learned distances multiplied by the predictor’s effect size (A). The mean of the samples alongside the highest posterior density interval (95%) is shown.
DiscussionWe analyzed the combined influence of a large set of multi-modal factors, including environmental, lifestyle, biofluid, and genetic data, on aging-related key functions, cognitive, and gait performance, measured by multiple clinical tests. To this end, we compared two approaches: independent prediction of each outcome measure with a linear regression model (OLS) and joint prediction of all outcome measures from one composite score learned by a Bayesian RRR model. We could show that the predictive performance of the Bayesian RRR model with one single composite score was comparable to classical multiple OLS models. The most relevant factors that showed a protective effect on complex gait and cognitive abilities in older participants included female sex, a higher degree of physical activity, more skeletal muscle mass, and more years of education. Contrary, higher age, body mass index and more smoking pack-years, the presence of hypertension, having two ApoE4 alleles, and higher serum levels of NFL were predictors for impaired gait and reduced cognitive performance.
We primarily included well-known risk and protective factors to check the validity of the composite modeling. However, some factors showed an influence in an unexpected direction. For example, the number of relatives with dementia or PD should serve as a proxy of the genetic risk and thus be a risk factor. Our model as well as the OLS models instead revealed a protective effect. This could be due to the high motivation of individuals with a family member affected by a neurodegenerative disease, as they have an increased personal interest in performing well and taking care of one’s health. However, we did not directly measure motivation. Such motivational influences were not measured directly within the TREND study, but the literature supports this assumption (Soule et al., 2016). Carriers of mild and severe variants in the GBA gene had a reduced risk according to our model, which could be a reflection of these carriers being significantly younger than the other groups (mild and severe GBA variant carriers (N = 30) vs. wildtype (N = 4,294): t-statistic = −3.12, p-value = 1.8e-3; mild and severe GBA variant carriers (N = 30) vs. low-risk GBA variant carriers (N = 166): t-statistic = −2.54, p-value = 1.2e-2).
Our modeling of the ordinal predictors allowed for interpretations of the effect sizes of each category. For example, ApoE4 is a well-known genetic risk factor for cognitive decline, with carriers of one allele having an odds ratio of approximately 3 for developing AD and carriers of two alleles having an odds ratio of approximately 15 (Farrer et al., 1997). This steep increase in risk for carriers of two alleles was replicated in our model despite the small sample size (11 persons with two ApoE4 alleles and 193 with one ApoE4 allele). We investigated how much complexity is needed to achieve similar performance to the OLS models in all outcome measures by training a model with two composite scores and by training separate Bayesian models for each outcome measure. Increasing the latent space and allowing for two composite scores slightly improved the performance for a subset of the clinical tests, albeit not significantly. This mainly affected gait outcome measures and revealed distinct effects of factors for different clinical tests (Supplementary Table S3). For example, female sex was identified as a risk factor for walking speed in general but a protective factor across all cognitive tests (Figure 3). This effect was found in the OLS models and the two composite scores models (Supplementary Figures S3, S4) alike and could reflect the height difference and thus step size differences between males and females. This was not measured within the TREND study and can thus not be corrected for. The single composite score model thus prioritized the cognitive measures over the gait-related measures, leading to a composite score that performs well on cognitive measures and worse than the OLS models on the gait measures. The good performance of the single composite score model to predict the gait measure “Subtract while Walk Dual + Single” might be explained by the high cognitive load of this task. It might thus be better represented by a cognitive composite score.
Our approach of a joint prediction of all outcome measures from one composite score learned by a Bayesian RRR model performed comparably well to the more classical flexible individually fitted regression models. This suggests that already one composite score can capture a substantial part of the complex effects on cognitive and motor function in an aging cohort. This finding is in line with recent studies. Data-driven techniques applied in archival clinical datasets may outperform classical models and could enhance diagnostic procedures in regions with limited resources (Maito et al., 2023; Javeed et al., 2023). Our model unbiasedly identified known risk and protective factors of aging.
The fact that our less flexible model performed comparably well to individual OLS models indicates that the explored factors either share similar mechanistic pathways and/or are interrelated to each other. This further highlights a global underlying risk for aging processes where motor and cognitive abilities are affected alike.
Our Bayesian RRR has several strengths compared to traditional approaches, such as its handling of missing data, its reduced complexity and thus its interpretability, and its handling of ordinal predictors. In Bayesian models, missing values in the outcome measures can be imputed through the model’s parameter estimates. As we can include incomplete data in the model, we increased the total amount of data the model uses but did not alter the data distribution artificially by learning from imputed outcome measures (covariates were imputed). Through our assumption of a composite risk, we decreased the complexity of the model and thus made it more scalable and better suited for medical data, which are scarce and high-dimensional. This assumption of a low rank further increased the model’s interpretability, as the single composite score can be interpreted as an estimate of the true underlying risk. The modeling of the ordinal predictors better captured the true scale level of the data, indicating that physical exercise has an additive effect.
We acknowledge the following limitations: (1) Our Bayesian RRR model does not test for causality but merely identifies associations between the included predictors and outcome measures. (2) Our Bayesian RRR model currently assumes a linear relation between the predictors and outcomes, although this is not necessarily true. For example, it would be reasonable to assume that drinking a small amount of alcohol could have a protective effect, but excessive drinking could be a risk factor for cognitive performance. Such reverse effects cannot be captured through our linear models. Using a quadratic link function could better account for such scenarios, other non-linearities could be further explored through neural networks. Drinking two drinks might be a confounding fitness factor, as many seniors avoid drinking if they are multimorbid or take multiple medications. (3) Another limitation is the handling of longitudinal data, where we treat visits from the same individual as independent. This disregards the correlation within a subject. A potential improvement of our model could be the adaptation of a mixed model where visits are grouped by individuals and identified through a subject-specific identifier, i.e., random effects. This would further allow us to make statements about a subject’s temporal slope. A different approach to modeling the longitudinal data would be a stacked model where a linear mixed model first learns the trajectory over time for each subject, and this estimated change over time is then used as the outcome measure in our Bayesian RRR. (4) While our Bayesian RRR model reduces complexity, it may not capture all nuances and interactions between predictors as effectively as more flexible models. Additionally, there is a trade-off between interpretability and performance, which might lead to overlooking some significant interactions and non-linear relationships between variables. (5) While the model is designed to be generalizable, its performance and findings are based on this single cohort. Therefore, a validation in further worldwide cohorts is necessary (Santamaria-Garcia et al., 2023; Ibanez et al., 2024). (6) While the overall number of genetic risk carriers (GBA, SNCA, and MAPT) was in the expectant range of the known prevalence, this sample size is too small to robustly recover their effect on age-related functions.
Currently, our model achieved similar performance to multiple OLS models, however, several adaptations could be explored to improve our model’s performance. As our model requires fewer parameters, we could increase the number of predictors and targets without the need to increase the sample size. Especially exploring the effect of various aging-related genetic markers and their interaction could be a promising future project. A similar model has been used before for modeling genotype–phenotype associations (Goh et al., 2017); however, they did not use monotonic transformations but instead assumed additive effects for the SNPs.
We conclude that our low parametric modeling approach successfully recovered known risk and protective factors of healthy aging on a personalized level while providing an interpretable composite score. An extension of this model using more predictors and clinical tests could further identify unknown factors and distinct aging-related processes. To this end, more sensitive tests are needed to better capture the variation with a healthy cohort. Digital sensors such as wrist-worn acceleration devices could provide such sensitive data. The modeling approach is generalizable and could also be applied to other cohorts to investigate the complex interplay of risk and protective factors along with effect sizes from different dimensions such as lifestyle, medical, genetic, and biochemical data.
Data availability statementThe raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statementThe study was approved by the Ethics Committee of the Faculty of Medicine at the University of Tübingen (TREND: 90/2009BO2). The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributionsA-KS: Formal analysis, Software, Writing – original draft, Writing – review & editing. SL: Data curation, Investigation, Writing – original draft, Writing – review & editing. IW: Investigation, Writing – review & editing. BR: Investigation, Writing – review & editing. MZ: Investigation, Writing – review & editing. FF: Investigation, Writing – review & editing. A-KT: Data curation, Investigation, Writing – review & editing. GE: Conceptualization, Supervision, Writing – review & editing. WM: Conceptualization, Investigation, Supervision, Writing – review & editing. DB: Conceptualization, Supervision, Writing – review & editing. FS: Methodology, Software, Writing – original draft, Writing – review & editing. KB: Conceptualization, Investigation, Supervision, Writing – original draft, Writing – review & editing.
FundingThe author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the BMBF-funded de.NBI Cloud within the German Network for Bioinformatics Infrastructure (de.NBI) (031A532B, 031A533A, 031A533B, 031A534A, 031A535A, 031A537A, 031A537B, 031A537C, 031A537D, 031A538A). This work was further partially supported from the Else Kröner-Fresenius-Stiftung within the Project “ClinBrAIn: Künstliche Intelligenz für Klinische Hirnforschung” (KB and FS). FS was supported by the Carl-Zeiss-Stiftung and acknowledges the support of the DFG Cluster of Excellence “Machine Learning – New Perspectives for Science”, EXC 2064/1, project number 390727645. KB received support by the DFG for "Psychosoziale und gesundheitsbezogene Auswirkungen der SARS-CoV-2 Pandemie, Antikörper und Impfung bei älteren Menschen (CORO-TREND)”. We acknowledge support from the Open Access Publishing Fund of the University of Tübingen.
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary materialThe Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnagi.2024.1447944/full#supplementary-material
ReferencesBowie, C. R., and Harvey, P. D. (2006). Administration and interpretation of the trail making test. Nat. Protoc. 1, 2277–2281. doi: 10.1038/nprot.2006.390
Crossref Full Text | Google Scholar
Brayner, B., Kaur, G., Keske, M. A., Perez-Cornago, A., Piernas, C., and Livingstone, K. M. (2021). Dietary patterns characterized by fat type in association with obesity and type 2 diabetes: a longitudinal study of UK biobank participants. J. Nutr. 151, 3570–3578. doi: 10.1093/jn/nxab275
PubMed Abstract | Crossref Full Text | Google Scholar
Burkner, P. C., and Charpentier, E. (2020). Modelling monotonic effects of ordinal predictors in Bayesian regression models. Br. J. Math. Stat. Psychol. 73, 420–451. doi: 10.1111/bmsp.12195
PubMed Abstract | Crossref Full Text | Google Scholar
Cova, I., Markova, A., Campini, I., Grande, G., Mariani, C., and Pomati, S. (2017). Worldwide trends in the prevalence of dementia. J. Neurol. Sci. 379, 259–260. doi: 10.1016/j.jns.2017.06.030
PubMed Abstract | Crossref Full Text | Google Scholar
Ehrensperger, M. M., Berres, M., Taylor, K. I., and Monsch, A. U. (2010). Early detection of Alzheimer's disease with a total score of the German CERAD. J. Int. Neuropsychol. Soc. 16, 910–920. doi: 10.1017/S1355617710000822
留言 (0)