Study design and patients
DLBCL patients were recruited via the largest lymphoma patient organization in China. As of 2022, there were more than 100,000 registered members (lymphoma patients-50% and their family members-50%) of the organization. The link to the survey was disseminated by the organization staff via its internal network to the members that registered as DLBCL patients, family members of patients, and caregivers of patients. The survey methodology, execution, and data integrity were defined by the survey committee, including rare disease medical experts, leaders of rare disease patient foundations, and our research team.
To uphold the integrity and quality requirements of data collection, the questionnaire was developed in collaboration with medical experts in DLBCL and blood diseases. The final version of questionnaire was refined through two rounds of pilot testing with a small group of patients to ensure clarity and relevance. The survey was distributed digitally via a secure platform, which ensured structured data collection and minimized the chances of manual data entry errors.
To ensure that each entry in our dataset represented a unique individual, the survey committee employed a manual data exclusion process using Microsoft Excel. Specifically, the survey committee cross-referenced the IP addresses from which the surveys were submitted, the respondents' registered domicile at the city level, the hospital where the diagnosis was made, the disease status, treatment regimen, healthcare expenditures, and the total duration taken to complete the survey. By comparing these data points, duplicate responses were identified and excluded. The survey committee conducted periodic data quality reviews and follow-up contact with participants when necessary to ensure that the data collected were reliable and accurate. This study only included those patients who fully completed the questionnaires and there were no missing values in our analysis.
The main inclusion criteria of this study population included: 1. the patients were adults over 18 years old, 2. the respondent had a diagnosis of DLBCL, or was a family member or caregiver of a DLBCL patient, and 3. the respondent can describe the patient's disease status, quality of life and other conditions. Before commencing the survey, participants were advised to prepare specific documents that would aid in accurately responding to questions. This preparation ensured that participants had access to comprehensive information regarding the patient's health condition and treatment history, enabling them to meet the inclusion criteria effectively. The main exclusion criteria included: 1. unwilling to report some crucial questions in the survey, 2. received treatment outside mainland China.
Data collectionDemographic and clinical variables
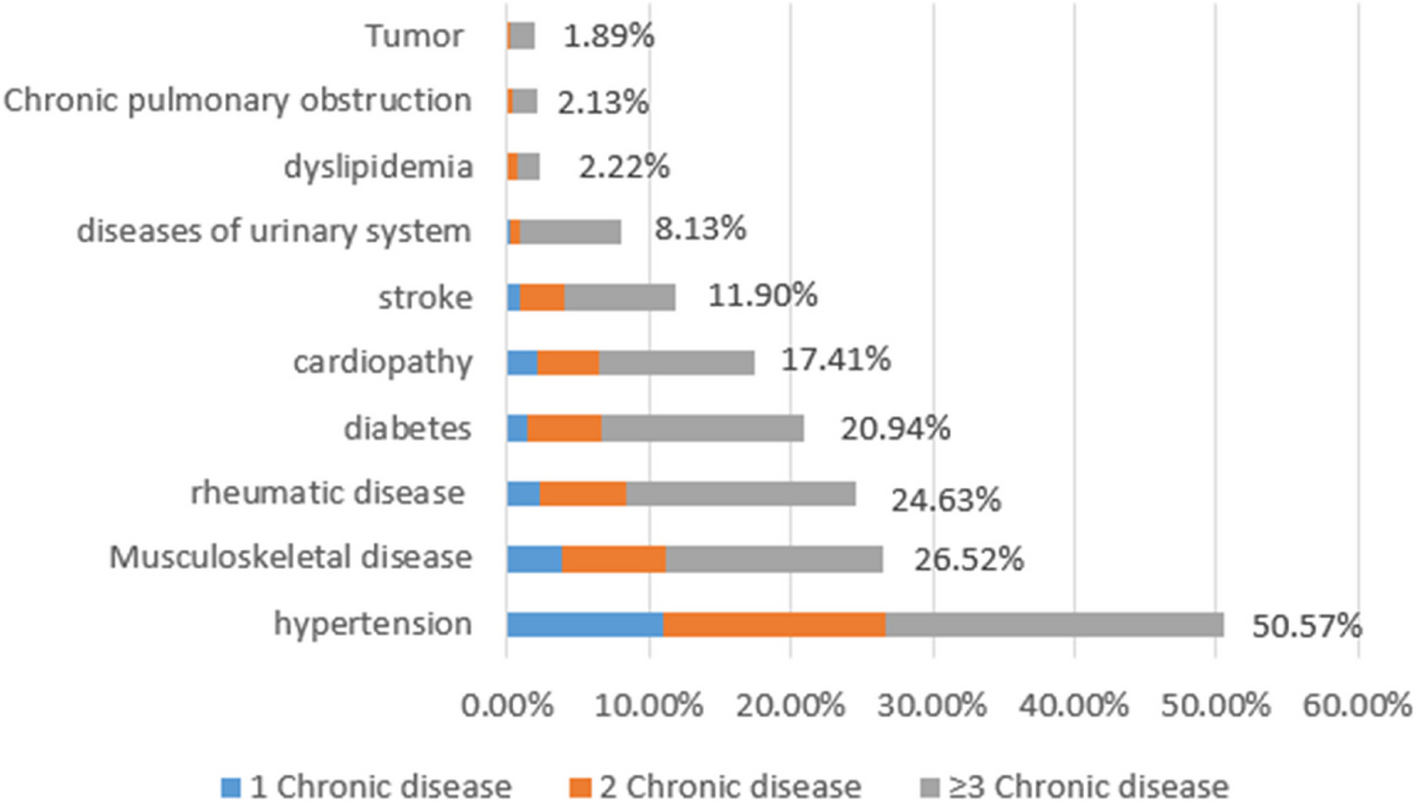
The basic demographic and clinical variables collected were 1) demographic information: sex, age at the time of study, ethnicity, and family registration); 2) SES: marital status, education level, employment status, health insurance coverage, personal income, and household income; and 3) clinical characteristics: treatment lines, whether on treatment, treatment efficacy assessment results, IPI score, double-hit/triple-hit (DHL/THL), double-expressor (DEL), non-GCB subtype, ABC subtype, TP53 mutation, MYD88 mutation and/or CD79b mutation, Ann Arbor staging, and complication.
Treatment stages information
According to a question in our survey, “which of the following is the patient's current status?”, patients were classified into five categories: 1, untreated newly diagnosed patients, 2, newly diagnosed patients on treatment, 3, patients completed the first-line treatment and were being monitored for health, 4, RR patients on treatment, and 5, RR patients completed at least one line of treatment after relapse and were being monitored for health. In our analysis, the first three categories were described as initial treatment patients and the rest were described as RR treatment patients.
According to a question in our survey, “what was the efficacy assessment result of the treatment according to the doctor?”, patients were classified to four categories: 1, complete remission, 2, partial remission, 3, progressive disease, and 4, have not been evaluated. In this analysis, these answers were described as CR, PR, PD and Unknown.
HRQoL measure instruments
Given the complexity of the functional status of DLBCL patients, especially that of those unable to complete the survey on their own due to severe health conditions or poor digital illiteracy, this study allowed the family members or caregivers to answer on behalf of the patients [27,28,29,30,31]. This study used the self-reported versions of both EQ-5D-5L and SF-6Dv2 in the questionnaire and the responses were converted to utility values using Chinese-specific value set [26, 32].
Statistical analysis
To ensure the robustness and validity of the statistical analysis, this study performed a Chow’s test [33, 34] to evaluate the comparability of the data collected from the self-reported and proxy-reported groups and to determine if the responses of the two groups could be pooled in subsequent analyses [35, 36]. The results of the Chow’s test indicated that the null hypothesis could not be rejected, suggesting that pooled analyses of self-reported and proxy-reported data were statistically justified. Detailed results of the Chow’s test are provided in Appendix.
Descriptive statistics
Descriptive analyses were conducted for both initial and RR treatment patients. The EQ-5D-5L and SF-6Dv2 utility scores value scores were reported by both treatment stage information and treatment efficacy assessment results. Categorical variables were reported using frequency and percentage. Continuous variables were described using means and standard deviations.
Chi-squared tests were conducted to statistically evaluate the differences in demographic and SES characteristics across initial (untreated, on treatment, and off treatment) and RR (on treatment and off treatment) patients, whereas a t-test was performed to test the difference in age.
The proportion of patients reporting the best and worst levels of the EQ-5D-5L and SF-6Dv2 dimensions and utility values were examined to assess the ceiling and floor effects. Ceiling and floor effects were reported if the proportions of respondents reporting the highest and lowest utility score were greater than 15% [37].
Agreement between the EQ-5D-5L and SF-6Dv2
The agreement between the utility values of the EQ-5D-5L and SF-6Dv2 can be used to determine whether these utility values can be used interchangeably. The Bland–Altman plot is utilized to visually display the agreement of utility values across different ranges. The agreement of utility scores obtained from EQ-5D-5L and SF-6Dv2 was depicted using the B-A plot. The x-axis of the B-A plot represents the mean of the two utility scores whereas the y-axis represents the difference. The mean difference of the two utility scores is labeled using a red horizontal line in the middle of the plot while the upper and lower limits of the range within which 95% of the differences between the two utility scores are expected to lie are visualized using two black horizontal lines. It is considered “good agreement” if the mean difference is close to zero and more than 95% of the scatters lie within the range [38].
Convergent/Divergent validity
Convergent validity is established when two measures that are expected to be related demonstrate a strong correlation. For instance, the mobility dimension in the EQ-5D-5L is expected to exhibit a significant correlation with the physical functioning dimension in the SF-6Dv2 [39, 40]. Pearson’s correlation coefficients were used to assess the association of utility score (continuous data) and Spearman’s rank correlation coefficients were used to assess the associations between EQ-5D-5L and SF-6Dv2 dimensions (categorical data). Correlations were deemed strong, moderate, and weak when the coefficients were > 0.5, between 0.3–0.5, and < 0.3, respectively [41].
Discriminant validity: known-group validity and GRM
The assessment of known-group validity, a measure that elucidates the capacity of the EQ-5D-5L and SF-6Dv2 to discriminate respondents with different clinical severity, was conducted using one-way ANOVA for multiple groups and the t-test across binary variable groups. Specifically, the groups stratified by treatment lines [42,43,44], whether on treatment [45], treatment efficacy assessment results [46], IPI score [47, 48], DHL/THL [49, 50], DEL [51, 52], non-GCB subtype, ABC subtype [49], TP53 mutation [51], MYD88 mutation and/or CD79b mutation [53,54,55], Ann Arbor staging [56, 57], and complication were analyzed [58]. Furthermore, the selection of clinical characteristics defining clinical severity was guided by evidence from previous studies and clinical practice suggesting an association between these characteristics and health status in patients with DLBCL. It was hypothesized that the factors associated with lower utility scores included the RR status, on treatment, PD treatment efficacy assessment results, higher risk IPI score, with DHL/THL, with DEL, non-GCB subtype/ABC subtype, with TP53 mutation, with MYD88 mutation and/or CD79b mutation, higher Ann Arbor staging, and with complications.
Item response theory (IRT) is a statistical model commonly used in psychometric and educational measures. IRT has also been increasingly engaged in quality-of-life research and patient-reported outcomes (PRO) measures in recent years [59,60,61]. IRT relates a person's ability/trait level to their probability of answering a question correctly. Based on the findings from previous studies, data collected from EQ-5D-5L and SF-6Dv2 met the key assumptions for the application of IRT [62,63,64]. The evidence to support the appropriateness of applying IRT to the current data is provided in Appendix. In the PRO analog, the ability/trait refers to health status. In this study, the GRM, which is an extension of IRT to ordinal response variables, was used to evaluate the discrimination power of each item within each instrument [65].
The GRM generates difficulty (in this study, it represents the underlying health) parameters (bn) for n response categories, and a discrimination parameter (a) for each dimension [61]. The dimensions correspond to the items of each instrument and the response categories correspond to the levels of each item. The discrimination parameter of an item indicates the capacity of the corresponding dimension to differentiate between study subjects at different health status [60]. A higher value suggests that the item that can more effectively differentiate respondents across the spectrum of health status [61]. To visualize the discrimination parameter and the relationship between a person's ability and their probability of choosing a less damaged health state, the boundary characteristic curve (BCC) produced from the results of the graded response model GRM can be used. The BCC is a sigmoid shaped curve, typically plotted with ability on the x-axis and the probability of choosing a less damaged health state on the y-axis. On the BCC plot, the discrimination parameter is represented by the slope of the curve. Items with higher discrimination will have steeper slopes. Items with discrimination parameters > 0.50 are typically considered being able to adequately discriminate respondents with different ability [61, 65]. The difficulty parameter, alternatively known as the location parameter, indicates the health status where there is a 50% probability of moving to the next higher response category. It is represented by the location on the ability scale where the curve is steepest such that there is maximum uncertainty in whether a respondent will endorse the item. It is widely accepted that the difficulty parameter of an item should fall within the interval of [-3.00,3.00] to ensure accurate and effective discrimination [59]. To apply GRM to our analysis, the response levels of EQ-5D-5L items and the five-level items of SF-6Dv2 were assigned values of 5 ~ 1, while the options of the 6-level items of SF-6Dv2 were assigned values of 6 ~ 1.
Ordinary least square (OLS) linear regression
A multivariable OLS regression was used to examine the factors that affected the EQ-5D-5L and SF-6Dv2 utility scores. Categorical independent variables were re-organized as dummy variables. The level of each category that was supposedly associated with the highest health utility value was employed as the reference category in our regression model. The reference levels of the categorical explanatory variables were initial treatment, off treatment, CR, IPI = 0 ~ 1 (low risk), no DHL/THL, no DEL, no TP53 mutation, neither MYD88 mutation nor CD79b mutation, Ann Arbor staging: Stage I, and no complication. The variables that demonstrated statistical significance in the one-way ANOVA were considered for inclusion in the OLS model. The significance level was set at 0.05. All statistical analyses were performed using Stata/MP 15.0 (StataCorp LLC, College Station, TX, USA).






留言 (0)