
記住我

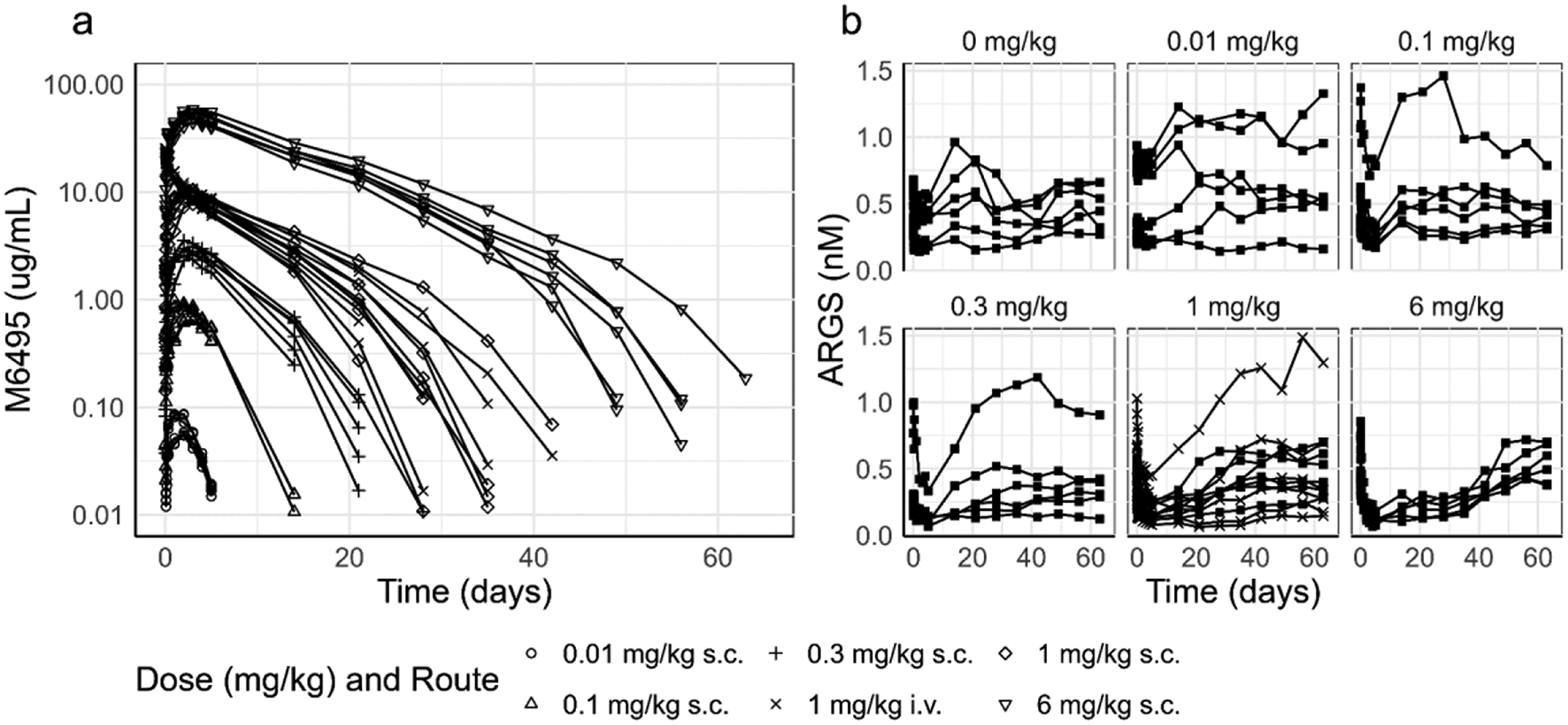




A total of 500 samples of patient age, height, weight, blood group, and von Willebrand factor antigen (VWF:Ag) levels were simulated from a recently proposed generative model for haemophilia A patients [19]. This generative model implements non-linear relationships to represent the joint distribution over these covariates. Covariate relationships were based on a directed acyclic graph (DAG) representing the causal effects of the covariates. The resulting samples are more realistic than samples from multivariate normal or marginal distributions. After generating synthetic covariate data, factor VIII levels were simulated based on a hypothetical population PK model implementing the following covariate effects:
$$\beginCL=0.1\cdot\frac}^\cdot\left(\frac\_\mathrm(\mathrm+100)}+0.9\right)\\V_1=2.0\cdot\frac}\cdot\exp(\eta_)\\Q=0.15\\ V_=0.75\end$$
(5)
where \(\mathrm\_ \mathrm \left(x, \alpha = \frac, \beta= \frac\right)= \alpha \cdot x + (1- \alpha) \cdot \frac(x \cdot \beta)+1)}\).
Each virtual patient was given a single dose of 25 IU/kg rounded to the nearest 250 IU. Random samples \(\eta \sim N\left(0,\Omega \right)\) with \(\Omega =\left[\begin\begin0.037& 0.0113\end\\ \begin0.0113& 0.017\end\end\right]\) were drawn to produce individual estimates of the PK parameters. Next, simulated FVIII concentration–time curves were generated based on a two compartment model. FVIII measurements were collected at 4, 24, and 48 h after dose.
Evaluating the accuracy of variational approximationsThe accuracy of variational posterior approximations was determined by comparing learned random effect posteriors obtained from VI to those obtained from MCMC sampling when using the true model from the simulation. Posteriors were compared in two settings: (1) using the true typical PK and population parameters (i.e. Ω and Σ), and (2) when only using the true typical PK parameters (also approximating the posterior over Ω and Σ). Covariance matrices M were decomposed in terms of marginal standard deviations S and correlation matrix C such that M = S · C · S’. More information on prior and hyper-prior selection for the MCMC model can be found in supplementary data 2.5.
For the MCMC model in scenario 1, a single chain was run to generate 10000 posterior samples using the NUTS algorithm. In scenario 2, 5000 samples were taken. Models were fit to the first data fold of the simulated data set, and 20 replicates of the VI algorithm were fit to compare to results from MCMC. The same prior distributions were used in the VI model. Posterior similarity was determined based on visualizations and quantified using the Wasserstein distance. The ADAM optimizer using a learning rate of 0.1 was used.
Comparison of methods for estimating random variablesGiven our computational budget, we decided on fitting 100 models for each of the methods. The complete data set was divided into 20 random subsets of 60 subjects drawn with replacement for model training with the remaining samples for determining model accuracy. Previous results indicated that data from 60 subjects was sufficient to fit accurate models [5, 20]. On each data fold, five replicates of model training were performed which we deemed to be a minimal requirement to represent variability induced by random initialization of model parameters. We chose to run a larger number of training replicates over data folds rather than within a single data fold (i.e. 20 vs. 5) as we assumed that the specific training data had a larger effect on parameter variability compared to random initialization following previous findings [21].
A multi-branch network based architecture of the DCM [21] was fit to each training fold of the simulated data set. In a multi-branch network, covariates are linked to specific ODE parameters such that each covariate effect is learnt in isolation. This contrasts standard fully-connected networks where all covariates are linked to all ODE parameters, potentially making the model susceptible to learning spurious covariate effects. In addition, the approach enables the direct visualization of learned functions for each of the covariates, making the model inherently interpretable without the need for post-hoc ML explanation methods. Subject weight and VWF:Ag were used as covariates. Global parameters were estimated for Q and V2. In the multi-branch network, weight was connected to CL and V1, and VWF:Ag was connected to CL. The same model was optimized using each of the objective functions. For each training replicate, random initial parameters were drawn from initial distributions. More information on model architecture and initial parameter settings can be found in supplementary data 2.
Again, covariance matrices M were decomposed in marginal standard deviations and correlation matrices. All variance estimates were constrained to be positive using the softplus function. Models were compared based on the root mean squared error (RMSE) of typical predictions, accuracy of the estimated population parameters (represented by the KL divergence of Ω and mean absolute error (MAE) of σ), and the similarity of the learned functions with respect to the true covariate effects. Models were fit based on the MSE (no estimation of population parameters), FO, FOCE, and VI objective functions. When using the VI objective, random effect posteriors were approximated using full-rank multivariate normal distributions. The expectation in the ELBO was approximated using Monte Carlo simulation, taking three random samples and using the reparametrization trick [8] to generate samples from q. For the models trained using FOCE, MAP estimates of the random effects were obtained by minimization of the negative joint likelihood for each subject using the BFGS method at the start of each epoch of training. Estimates were constrained between [-3, 3] to improve stability during optimization.
Models were trained for 2000 epochs and parameters were saved every 25 epochs to determine model convergence and stability during training. Most models converged within 250 – 500 epochs, so additional training iterations allowed insights into parameter stability after convergence and risks of overfitting when overextending training time. The ADAM optimizer using a learning rate of 0.1 or 0.01 was used depending on training stability. Results at the end of optimization were compared based on the mean of saved parameter estimates from the last 500 epochs of training. Uncertainty estimates over model parameters were obtained by taking the standard deviation of final parameter estimates for each of the training replicates.An overview of the approach is shown in Fig. 1.
Fig. 1
Comparison of the different methods in the simulation study
First, a data set was simulated containing 500 virtual subjects based on a previously published generative model p(X). The data set was divided in 20 random data subsets with replacement to create the training (n = 60) and testing (n ≈ 440) data sets. On each data fold, models were fit using based on the different methods (FO, FOCE, and VI). In the FOCE method, a Gaussian approximation \(\widetilde\) of the random effect posterior p(Z|y) centered at its maximum a posteriori estimate (white circle) is obtained. In the FO method, the mode is fixed at zero, resulting in lower accuracy due to a potential mismatch with the true posterior. In VI, the divergence between a variational approximation q(Z) and the true posterior is minimized. After fitting the models, the methods were compared based on the accuracy of parameter estimates, their stability during training, and the similarity of learned covariate effects to true effects.
Evaluation on real world dataThe performance of the algorithms was also evaluated on two real world data sets of haemophilia A patients receiving SHL FVIII concentrates during prophylaxis (data set one) and following surgery (data set two). The data originates from the OPTI-CLOT clinical trial [20], were FVIII consumption was compared between standard weight-based dosing regiments and PK-guided dosing in moderate and severe haemophilia A patients undergoing surgery. The first data set contains a total of 69 subjects who received a PK profile following a 25–50 IU/kg test dose of one of five SHL FVIII concentrates. Three FVIII measurements were collected roughly 4, 24, and 48 h after administration. Available covariates were haemophilia severity, body weight, height, age, and VWF:Ag levels. A large proportion of VWF:Ag levels were missing (65.2%), with some subjects missing body weight or height data (1.4% and 4.3%, respectively). Missing values were imputed based on the mode of prior distributions produced by the generative model (i.e. the same model used for generation of the synthetic data) [19].
The second data set contained data on 66 subjects from data set one who underwent a minor or moderate risk surgical procedure within 12 months after their PK assessment. FVIII levels were measured before and after surgery and FVIII peak and trough levels were collected during follow-up. Compared to the first data set, follow-up time was longer (median of 144 vs 44 h) and subjects received a more complex combination of bolus doses and continuous infusions. Available covariates were haemophilia severity, body weight, height, VWF:Ag and VWF activity (VWF:act) levels, pre-assessed surgical risk scores, blood loss, and NaCL administration during surgery. In this data set, most subjects had multiple VWF measurements. Missing VWF:Ag values were imputed based on the mode of the prior distributions from the generative model multiplied by a factor of 1.3 (VWF:Ag levels are higher following surgery [22]). This factor was calculated from the mean difference between imputed VWF levels in data set one and average VWF levels per subject in data set two. The mean VWF:Ag value was used for each individual.
We fitted a multi-branch DCM with either an additive or combined residual error model to both data sets. Subject CL and V1 was predicted based on fat-free mass (FFM) calculated from body weight, BMI, and age using Al Sallami’s equation [23], with an additional effect of VWF:Ag on CL. Random effects were estimated for CL and V1 and global parameters were estimated for Q and V2. These choices match the results from a recent study on the PK of FVIII [19]. The goal of our analysis was to compare results from the different algorithms rather than to produce optimal models for these two data sets. For this reason, no additional covariate selection was performed. Models were trained until convergence (roughly 1000 epochs for MSE, FO, and VI; 2000 for FOCE) and parameters were saved every 25 epochs. Mean parameters from the last 250 epochs were presented. The ADAM optimizer with a learning rate of 0.1 was used. A larger number of epochs (2000 instead of 1000) were required for the FOCE model to converge when using a lower learning rate (0.01 instead of 0.1). Models were again compared based on the accuracy of typical predictions, final parameter estimates and their stability during training, and the learned functions.
Model codeModel code and the simulated data set are available at https://github.com/Janssena/ME-DCM.jl.
留言 (0)