
記住我
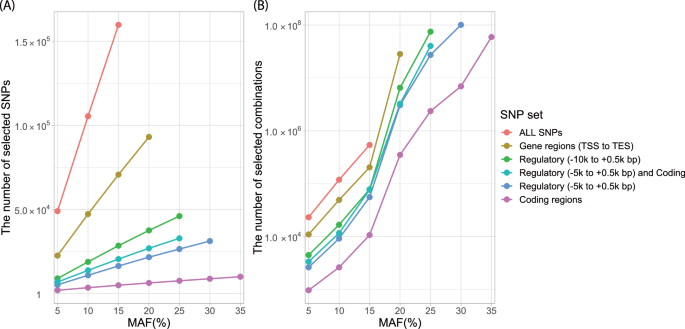
We used phased genotype data from chromosome 22 of 2504 individuals in the phase 3 dataset of the 1000 Genomes Project (1KGP) [26] (https://ftp.1000genomes.ebi.ac.uk/vol1/ftp/release/20130502/ALL.chr22.phase3_shapeit2_mvncall_integrated_v5b.20130502.genotypes.vcf.gz) to prepare the evaluation dataset. For testing, we randomly selected 100 individuals and assessed the imputation performance using the phased genotype data of the remaining 2,404 individuals as the haplotype reference panel. These 100 individuals are listed in Supplementary Table 1. We employed the Infinium Omni2.5-8 BeadChip (Omni2.5-8 v1.4 kit version), hereafter referred to as Omni2.5, as the SNP array platform and extracted genotypes at 31,325 sites designed on Omni2.5 as input data for genotype imputation methods. We evaluated the imputation accuracy for genotypes at the remaining 1,078,043 sites. Note that we directly used phasing information from the reference panel for the input genotypes; therefore, no prephasing process was applied in this experiment. Since RNN-IMP requires substantial computational resources for model training, accommodating all 1,078,043 sites would be computationally intensive, we filtered out rare variants with a minor allele frequency (MAF) of less than 0.005 as the target sites for RNN-IMP. After this filtering, the number of target sites was reduced to 217,428.
Evaluation of imputation accuracy in R2 for input genotypes without missing valuesWe compared the genotype imputation accuracy of RNN-IMP with methods based on the Li and Stephens model, as listed in Table 1, using test input genotypes without missing values.
Table 1 List of genotype imputation methods based on the Li and Stephens model evaluated in this studyFor the RNN-IMP model configuration, we set the number of layers and the size of the hidden vectors to 4 and 40, respectively. We divided chromosome 22 into linkage disequilibrium (LD) blocks using the LD block information in https://github.com/stephenslab/ldshrink/blob/main/inst/test_gdsf/fourier_ls-all.bed. Each block was further divided to ensure that each resulting region contained approximately 200 array markers, resulting in a total of 225 regions. Variant sites located within each subdivided region, except array markers, were designated as outputs for the corresponding RNN model. 50 array markers on both the upstream and downstream sides of each region were also included for the model inputs. We employed a similar approach to that described in [21] for training the model parameters.
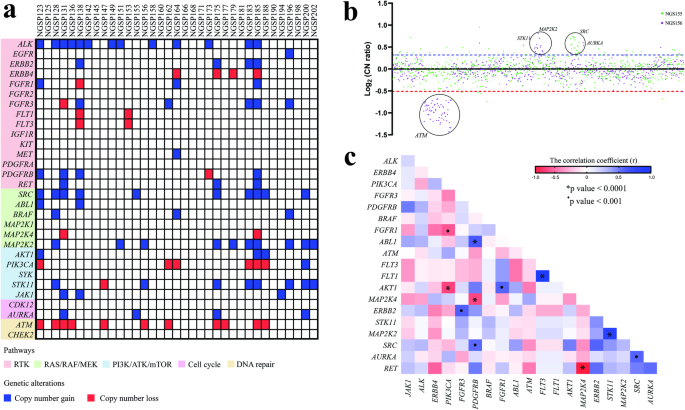
Default options were used for the Li and Stephens model-based methods. Within the evaluation dataset, all variant sites were biallelic; one allele was denoted as the a0 allele, and the other as the a1 allele. To assess genotype imputation accuracy, we used the R2 value, calculated as the square of the Pearson correlation coefficient between the actual genotype counts of the a1 allele and the a1 allele dosages in the imputed genotypes. Figure 1a presents a comparison of R2 values for RNN-IMP and the methods listed in Table 1 across the MAF spectrum. The R2 values on the y-axis represent the average R2 values for variants within small local bins for each MAF value. Figure 1b displays the comparison of the R2 values with a y-axis range limited to values ≥0.7 to focus on this range. Although the differences among the Li and Stephens model-based methods are slight, IMPUTE5 exhibits the highest R2 values across most of the MAF range, except for very rare variants (MAF < 0.001), where Minimac3 presents the highest. From the comparison in R2, RNN-IMP demonstrates competitive accuracy relative to the Li and Stephens model-based methods for input genotypes without missing values.
Fig. 1
a A plot comparing R2 values of genotype imputation methods. b A plot with a y-axis range limited to R2 ≥ 0.7
Comparison of computational timeWe recorded the computational time required for obtaining genotype imputation results with RNN-IMP and the Li and Stephens model-based methods, as summarized in Table 2. Since model training was required for RNN-IMP, the running time on this process was also recorded. IMPUTE5, Minimac3, and Minimac4 require a preprocessing phase to reformat the reference panel data for efficient computation, and the duration of this step was also recorded.
Table 2 Summary of the computational time required for genotype imputation including preprocessing and model training time where applicable for each methodMinimac4 requires the reference panel data to be in msav format. While this format can be directly obtained from vcf format reference panel data, it can also be derived from m3vcf format, which is used by the previous version, Minimac3. Although the direct conversion from vcf to msav takes significantly less time than the conversion from vcf to msav via m3vcf, we observed that the imputation accuracy using msav format data obtained through the direct process was lower than that achieved with data converted via m3vcf. Based on our observations, we here opted to use msav data converted from m3vcf for our evaluation dataset, although this difference in accuracy is expected to diminish for large biobank-scale reference panels. We included the conversion time of m3vcf using Minimac3 in the preprocessing time for Minimac4.
Similar preprocessing, such as the data conversion with the Positional Burrows Wheeler Transform, is required for IMPUTE4 and Beagle 5.4; however, since these steps are integrated within the main genotype imputation process, their computational times were not recorded separately. The trained models or preprocessed data can be reused, and hence in Table 2, we distinguished this initial computational time from the subsequent running time for genotype imputation. The training time for RNN-IMP was assessed on an AMD Epyc 7713 CPU (base clock 2.0 GHz; boost clock up to 3.675 GHz) in a single thread, while other processes were measured on an AMD Ryzen 9 7950X CPU (base clock 4.5 GHz; boost clock up to 5.7 GHz) in a single thread. Python 3.7 and TensorFlow 1.15.0 were used for training the deep learning models for RNN-IMP. The trained models were then converted to the ONNX Runtime format (https://onnxruntime.ai/) to accelerate computations during model inference for genotype imputation. For inference, we used Python 3.11 with the ONNX Runtime. Although RNN-IMP demands a substantial amount of computational time for training, this process can be parallelized, and the entire training was completed within two days using a supercomputing system. RNN-IMP also generally consumed more computational time than methods based on the Li and Stephens model. One reason is that genotype data reading and result writing operations are implemented in Python for RNN-IMP, whereas they are implemented in C, C++, or Java in the Li and Stephens model-based methods. The inference phase by ONNX Runtime took 296.62 seconds for RNN-IMP, suggesting that computational efficiency could be improved by implementing I/O processes in C or C++ rather than Python. In this experiment, only 100 samples were processed for genotype imputation, but it is anticipated that the computational time per sample will decrease significantly for larger datasets, due to reduced overhead in all methods.
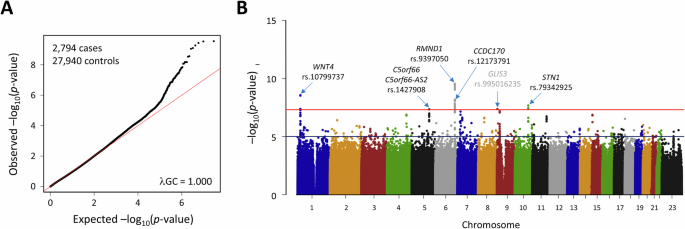
Evaluation of imputation accuracy in R2 for input genotypes with missing valuesIn SNP array genotype analysis, certain markers are removed during quality control, for instance, due to deviations from the Hardy-Weinberg equilibrium or low call rates. Since methods based on the Li and Stephens model use hidden Markov models or state space models, missing values in the input genotypes are simply skipped, and there is no need to fill in alternative values for the removed markers. On the other hand, RNN-IMP treats input genotypes as model inputs and does not account for missing values in input genotypes during the training process. Thus, some value must be supplied for the removed markers. The input value of RNN-IMP for each marker is represented by a one-hot vectors indicating the presence of a0 and a1 alleles, and the vector [1 − fa1, fa1], where fa1 denotes the frequency of the a1 allele, is used for missing values. To assess the impact of missing values in input genotypes on each method, we simulated the removal of genotype data for some markers in the test input data. Since the rate of removal due to quality control is typically at most 0.2, we considered the following removal rates: 0.01, 0.05, 0.1, and 0.2. Figure 2a, b, and c illustrate the impact of missing inputs on the performance of IMPUTE5, Minimac3, and RNN-IMP, respectively. In this comparison, we selected IMPUTE5 and Minimac3 as representative methods of those based on the Li and Stephens model and omitted other methods from this evaluation. As expected, the impact of missing input genotypes was negligible for the Li and Stephens model-based methods, while a clear reduction in R2 values was observed for RNN-IMP as missing rates increased.
Fig. 2
Comparison of R2 values for input genotypes without missing values and for those with missing values at rates of 0.01, 0.05, 0.1, and 0.2, across each imputation method: a IMPUTE5, b Minimac3, and c RNN-IMP
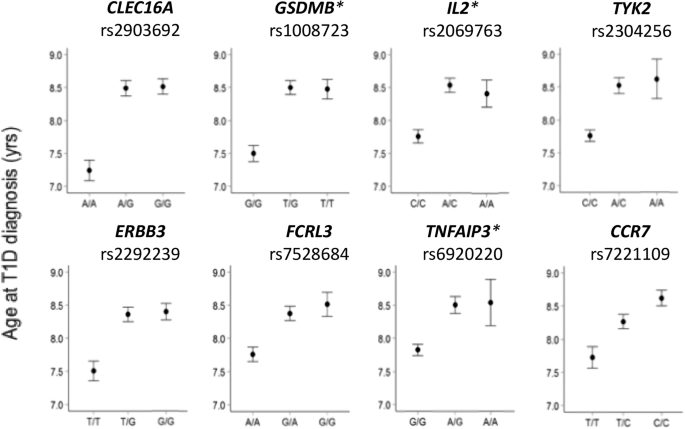
Two-stage strategy for robust genotype imputation to missing valuesIn order to impute missing values in the input genotypes, we considered a modified version of the DAE model used in [19]. Table 3a shows the original DAE model architecture, which uses a kernel size of 5 in its 1-D convolution layers and incorporates L1 regularization to encourage sparsity in the kernel parameters. In our modification, we replaced the 1D-convolution layers with residual 1D-convolution blocks as illustrated in Fig. 3. Residual connections, also known as skip connections, are the key feature of residual blocks and are effective for the efficient training of deep learning models by preventing the vanishing and exploding gradients during the backpropagation process [27]. We anticipated that the use of residual blocks would enhance the performance in the DAE-based methods. Since batch normalization within residual blocks helps prevent overfitting, we also omitted the dropout layers and L1 regularization previously applied to the 1D-convolution kernels. The output vector for each variant site in the original model was a one-hot vector representing three states: missing, a0 allele, and a1 allele. Since the missing state in output is not required for our purpose, we modified the output vector to only represent the a0 and a1 alleles. We have named this residual convolution denoising autoencoder-based method as RCDA. Table 3b shows the model architecture of RCDA. Similar to the approach used for RNN-IMP, chromosome 22 was divided into LD blocks. Each region was then further segmented to contain approximately 500 array markers. In total, 75 regions were obtained. For training RCDA, we employed the Adam optimizer [28] configured for 1,000 epochs, a learning rate of 0.001, and a batch size of 32. We selected the parameters that produced the best loss for a randomly selected set of 100 validation samples as the trained parameters for the model for each region. Table 4 summarizes the computational times for genotype imputation and model training using RCDA. Training time as well as genotype imputation time were evaluated on an AMD Ryzen 9 7950X CPU in a single thread. We also evaluated the training time using GPU computation with a GeForce RTX 4090 along with an AMD Ryzen 9 7950X CPU in a single thread. Training with the GPU was approximately three times faster than using only the CPU in a single thread. However, since models for different regions can be trained independently, parallel training across multiple CPU cores is a promising option for accelerating computation. Due to the overhead associated with GPU computation, using the GPU for this dataset resulted in greater overall computational time compared to using only the CPU in the inference for genotype imputation. Genotype imputation time also can be reduced by using multiple CPU cores to independently process models for different regions.
Table 3 The model architectures of a DAE used in [19] and b RCDAFig. 3
The structure of residual 1D-convolution block in RCDA
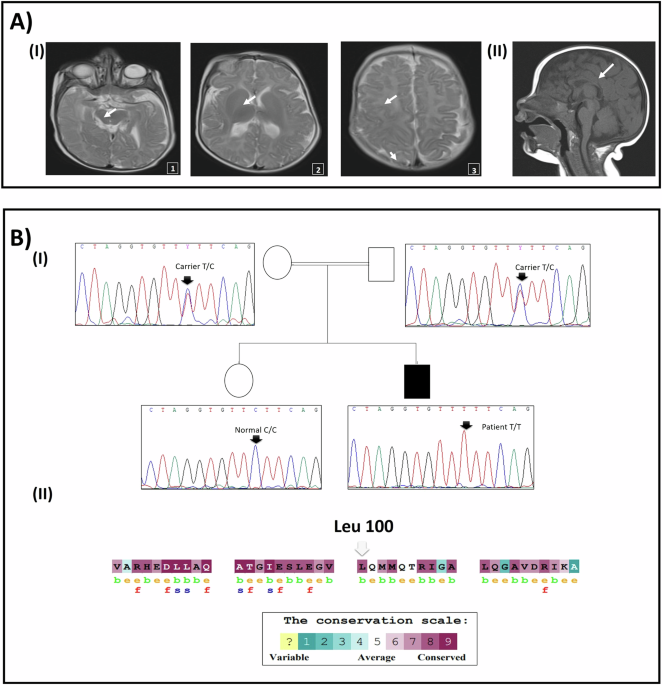
Table 4 Computational time for genotype imputation and model training in RCDAFigure 4 shows a comparison of R2 values for genotype imputations among original input genotypes without missing values, those with missing values, and those with missing values imputed by RCDA across missing rates of 0.01, 0.05, 0.1, and 0.5. The R2 values demonstrate substantial recovery following the imputation of missing genotypes by RCDA, while this recovery is less pronounced for variants with lower MAF, which may be attributed to the reduced imputation accuracy of RCDA for such markers in SNP arrays.
Fig. 4
R2 values for RNN-IMP for input genotypes without missing values, those with missing values, and those with missing values imputed with RCDA, across missing rates of a 0.01, b 0.05, c 0.1, and d 0.2
留言 (0)