
記住我





We conducted a prospective longitudinal study of secondary data using information from the National Household Survey (ENAHO) panel 2015–2019. We chose this time period in order to not include the effect that the pandemic may have had on the association between insurance and access to OHS. The databases used were obtained from the National Institute of Statistics and Informatics (INEI) webpage [22] and were the following: SUMARIA-2015-2019-PANEL, Enaho01-2015-2019-100-PANEL, Enaho01A-2015-2019-200-PANEL, Enaho01A-2015-2019-300-PANEL, Enaho01A-2015-2019-400-PANEL, Enaho01A-2015-2019-500-PANEL. The ENAHO panel survey collects information from urban and rural areas in the 24 departments of Peru and the Constitutional Province of Callao. Data was collected by interviews performed by trained field personnel and the same households were visited each year. The sample was selected in a probabilistic, area-based, stratified, multistage and independent manner in each department [21]. The questions are divided into several topics, including household characteristics, characteristics of household members, health, employment and income, ethnicity, among others [23]. The STROBE guide was used to report the results of this study [24].
Population and sample sizeThe 2015–2019 ENAHO panel sample included 10,950 households for 2015, the 2016 sample included 12,164, the 2017 sample included 12,038, the 2018 sample included 12,234 and the 2019 sample included 12,637 households. We only included households that responded each year during this 5-year period and who had complete data for all the variables. Therefore, considering the number of households lost in follow-up, the common panel sample in the 2015–2019 period included 1866 comparable households that completed the 5-year follow-up [21].
We calculated the sample size, even though the follow-up sample had losses and may not be highly important. For the present study, the minimum sample size of participants was calculated using the outcome values reported in the study by Teusner et al. in 2012 [14], which explored associations between health insurance affiliation and OHS visits. They found that 71% of the insured participants regularly attended OHS, while 41.5% of the uninsured regularly attended OHS. The sample size calculation was performed in the Online calculator “OpenEpi” for cohort studies using the Fleiss formula with continuity correction and considering a 95% confidence interval (95% CI), a power of 80%, and an exposed/unexposed ratio of 1, which resulted in a minimum sample size of 100 participants (50 exposed and 50 unexposed). In addition, a sensitivity analysis was performed in the statistical package Stata version 17.0, which estimated different sample size scenarios (the ratio in group 1 was 0.415 in all cases and the ratio in group 2 varied between 0.5 and 0.71) taking into account a 1:1 ratio of the outcome in exposed and unexposed. This resulted in sample sizes ranging from 88 to 1078 participants, respectively (Table S1, Supplementary Material). The final sample included in this study exceeded the required estimate.
The household members were considered as the research unit by the ENAHO, as well as household workers living at home, members of a family pension with up to 9 pensioners and persons who were not part of the household but who were in the household during the 30 days prior to the survey. Likewise, the ENAHO excluded members of family pensions with more than 10 pensioners and household workers who resided outside the home [21]. We included 4064 participants, from 1847 households, who responded to the survey during the five years.
For this study we included participants who had complete data for all the variables during all five years.
Dependent variableThe dependent variable was dental health care in the last three months prior to the survey each year, which was evaluated by means of question 414.6 of the survey: “Did you receive dental and related services in the last three months?”, which had a dichotomous answer (yes/no).
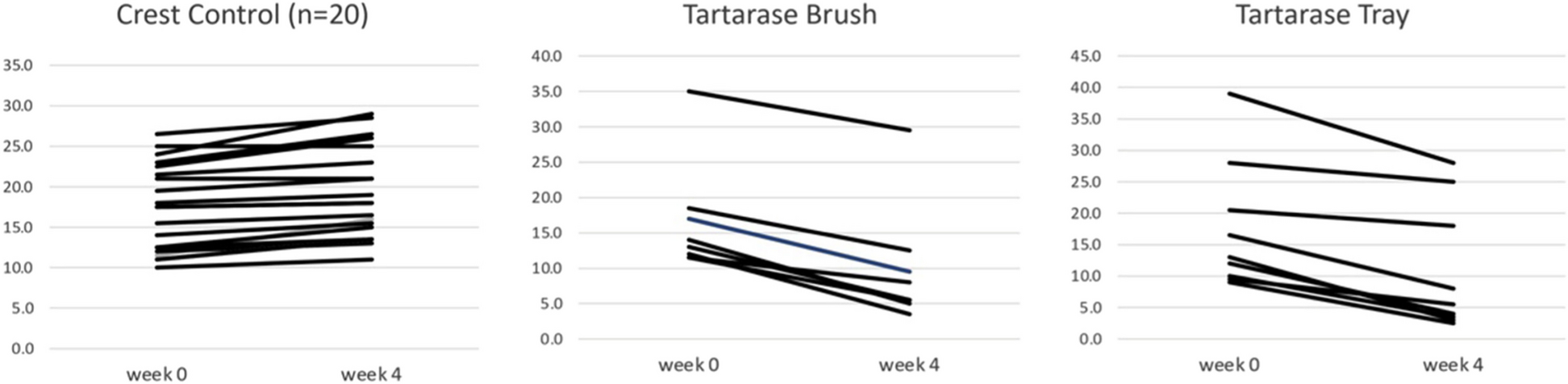
Independent variableInsurance status was evaluated by question 419, which states: “The health insurance system to which you are currently enrolled is:”, which had multiple alternatives (types of insurance). A participant was considered as “has health insurance” when they answered “yes” to any of the following 8 options: EsSalud, Private health insurance, Health provider entity, Military/Police insurance, Comprehensive health insurance (SIS), University insurance, Private school insurance, other. Those who answered “no” to all of these 8 options were considered as “does not have health insurance”. Then, the main independent variable was constructed by distributing this information into two categories: “four years or less”, when a participant had health insurance for four or less years, and “all five years”, when a participant had insurance for all five years continuously. Three main entities provide most of the health insurance services in Peru. The Comprehensive Health Insurance (SIS) is mostly aimed at the poor population, is tax-funded and covered 61% of the population as of 2022, EsSalud depends on the Ministry of Labour and provides care through payroll discounts of formal workers, and the Armed and Police Forces insurance depends on the Ministry of Defense and is aimed at military and police personnel, as well as their families; besides, private insurance covers around 10% of the population [26]. We presented the percentage of the population with insurance per year (Fig. 1).
Fig. 1
People with health insurance by year according to the 2015–2019 ENAHO panel survey
CovariablesCovariables were selected by literature review [25] and by epidemiological criteria. These variables were then used to design a causal diagram to define the relationships between the variables (Fig. 2). The selected covariates were: age group (children: <18 years, young adults: 18–29 years, adults: 30–59 years, older adults > 59 years), ethnicity (native/non-native), household poverty level (poor/non-poor), sex (male/female), educational level (up to primary school/secondary school/higher education), presence of disability (yes/no), area of residence (rural/urban) and natural region where the household is located (coast/highlands/jungle). The level of poverty question in the ENAHO has three options: poor, extremely poor and not poor, this information is calculated from household expenditure and presented as such in the ENAHO database. The data related to this question were dichotomized into poor and non-poor. We considered the poor and extremely poor as poor and the second category was non-poor. The ethnicity variable was categorized as follows: those who identified themselves as Amazonian indigenous, Quechua or Aymara were considered native; and those who considered themselves black/mulatto/zambo/Afro-Peruvian, white, mestizo, other, or doesn’t know were considered non-native.
Fig. 2
Directed acyclic graph of the relationships between the study variables
With the aim of evaluating disability, during the application of the ENAHO, each participant answered a question about whether they had any permanent limitation or difficulty that prevented or hindered them from carrying out their daily activities normally. The response options for this question included: difficulty moving or walking, difficulty using arms or legs, difficulty seeing, even when wearing glasses, difficulty speaking or communicating, even when using sign language or other, difficulty hearing, even when using hearing aids, difficulty understanding or learning (concentrating and remembering) and difficulty relating to others, because of their thoughts, feelings, emotions or behaviors.
Peru has three natural regions, the coast, the highlands and the jungle. The coast is a desert region that extends over a strip of approximately 2250 km in length in which Lima (capital of Peru) and other cities of important economic activity are located. The highlands are a mountainous region located at high altitude (average altitude: 3000 m.a.s.l.) in which the Andes, one of the largest mountain ranges in the world, are located. Agriculture and cattle raising are among the main economic activities in this region. The jungle region is located east of the Andes and contains the Amazon River basin; and is a region with a great variety of flora and fauna whose climate is mostly tropical [26].
Statistical analysisThe information (database in .dta format) corresponding to the 2015–2019 ENAHO panel survey was downloaded from the microdata repository of the INEI [22].
The databases were then merged and the variables were categorized as previously described. Subsequently, we performed the statistical analysis.
Descriptive analysis was carried out for the first year of the panel survey (2015) (Tables 1 and 2). Qualitative variables were summarized using weighted frequencies including sampling weights, which were added from the ENAHO database. Generalized estimating equation (GEE) Poisson regression models with robust standard errors were used to estimate the relative risk (RR) associated with the use of OHS. RRs and 95% confidence intervals (95% CI) were obtained from the estimated robust standard errors of the model using the xtgee command in Stata 17 software (StataCorp LLC, USA). An unstructured correlation structure was used to account for repeated measures at the subject level. The following levels were considered during the analysis: cluster, household, home and individual, as well as the years. A cluster is a grouping of 120 households, which is part of the multistage sampling design of the ENAHO panel survey [23]. First, the crude RR was calculated using the GEE model taking into account the four levels. Then, the adjusted relative risk (aRR) was calculated adjusting for covariates. A p-value less than 0.05 was considered statistically significant. The ENAHO sample weights were taken into account during the calculations. Stata SE 17 software was used to perform the analysis.
Table 1 Sociodemographic characteristics of the population in 2015 (n = 4064)Table 2 Sociodemographic characteristics of the population in 2015 according to the use of oral health services (n = 4064)In addition to the main analysis, we carried out a sensitivity analysis in order to validate our results. For this, we recategorized the independent variable into three categories; “never”, “some year/s”, and “all five years”. Then, similar to the main analysis, we used Poisson GEE regression models with robust standard errors to estimate the RR using the xtgee command in Stata 17 software (StataCorp LLC, USA). Similarly, crude and aRR were calculated.
Ethical aspectsThe protocol of this study was approved by the Ethics Committee of the Universidad Científica del Sur with registration code POS-50-2022-00284. The study used a free and open access database from a national anonymous survey conducted by the INEI [21]. The databases we used do not contain personal identifiers. All participants gave consent to participate in the survey.
留言 (0)