
記住我








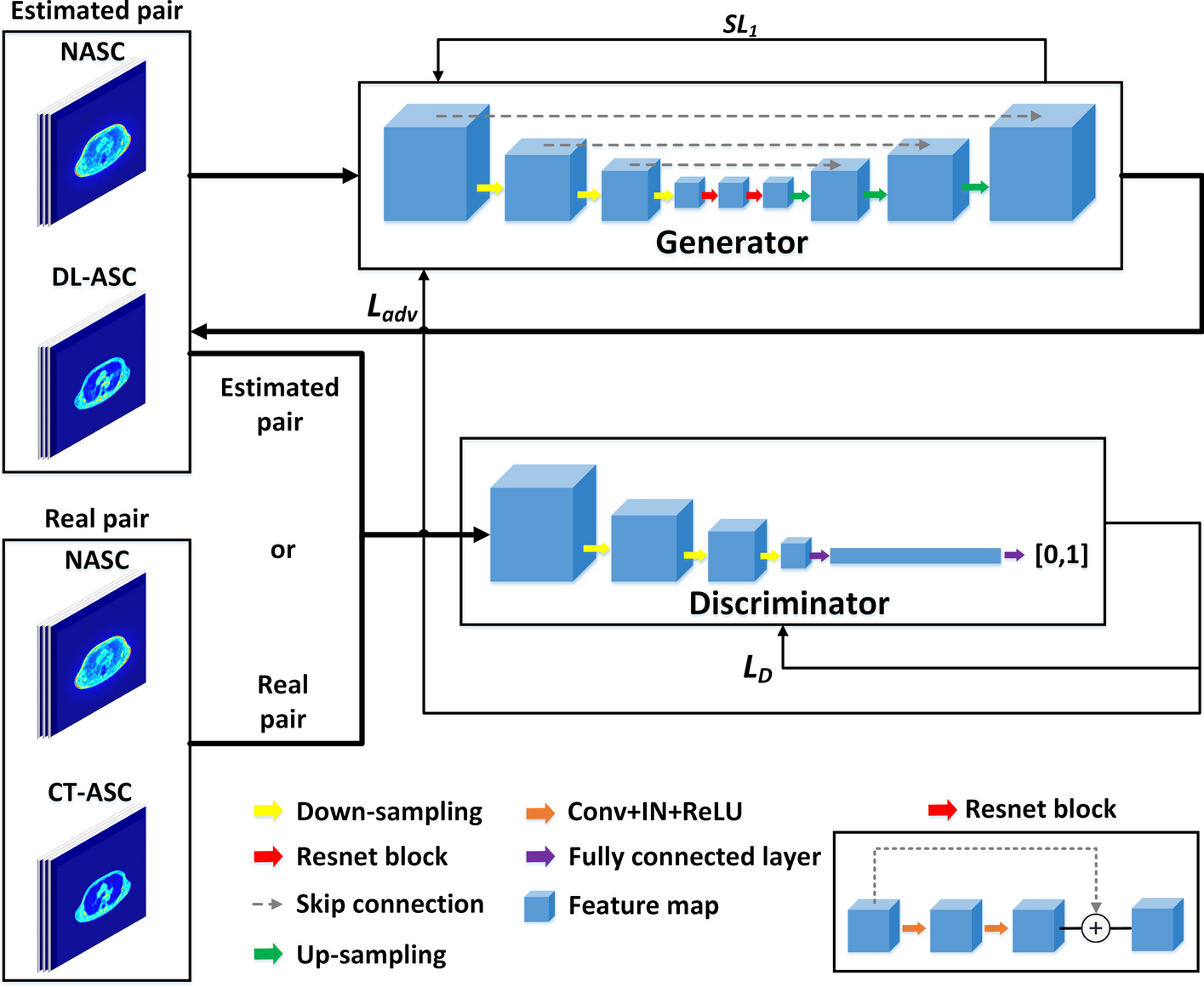
In this study, we conducted four experiments to verify the capability of the proposed method by multiple simulated datasets. The experimental settings and tracer combinations are listed in Table 1 and Table 2.
Table 1 Experimental settingsTable 2 Tracer combinationsIn Experiment 1, we compared the FBPnet-Sep model which separated in the image domain with two contrast methods. One was the Sep-FBPnet model that separated in the sinogram domain, and the other was our previously proposed Multi-task CNN, which directly mapped the dual-tracer sinogram to two single-tracer images. The FBPnet-Sep model, Sep-FBPnet model and Multi-task CNN contain 0.64 M, 0.66 M and 1.31 M parameters respectively. All three models were trained and tested by simulated \(^\)F-FDG/\(^\)C-FMZ dynamic PET data. As shown in Table 2, \(^\)F-FDG and \(^\)C-FMZ have different half-lives and different types of kinetic characteristics [44]. Single-tracer images inferenced by these three methods were also compared to those reconstructed from noisy single-tracer sinograms by maximum likelihood expectation maximization (MLEM) with 50 iterations.
In Experiment 2, we conducted the ablation study of FBPnet-Sep model by the same \(^\)F-FDG/\(^\)C-FMZ dataset. The proposed FBPnet-Sep model included basic convolution modules (Conv), the Inception module (Inc) and the channel attention module (CA) in its separation part. To investigate the contribution of the Inception and channel attention modules, we compared the original FBPnet-Sep(Conv+Inc+CA) model with the FBPnet-Sep(Conv), FBPnet-Sep(Conv+Inc) and FBPnet-Sep(Conv+CA) models. In addition, to confirm the superiority of deep learning-based reconstruction over traditional iterative reconstruction, we further compared the FBPnet-Sep(Conv+Inc+CA) model with the OSEM-Sep(Conv+Inc+CA) approach, which reconstructed the dual-tracer image by ordered-subset expectation maximization (OSEM) algorithm [45] with 6 iterations and 5 subsets.
In Experiment 3, we investigated the generalization of the FBPnet-Sep model to several dose levels. The model trained in Experiment 1 was tested by \(^\)F-FDG/\(^\)C-FMZ data of 1/2, 1/3 and 1/5 standard dose. The low-dose PET data were obtained by event reduction of test data used in Experiment 1.
In Experiment 4, data of four tracer combinations were together used to train the models, which represented different relationships between two tracers. As listed in Table 2, \(^\)C-FMZ has different half-life and kinetic type from \(^\)F-FDG. \(^\)C-MET differs in half-life from \(^\)F-FDG while \(^\)F-AV45 differs in kinetic type. And \(^\)F-FLT has the same half-life and kinetic type with \(^\)F-FDG. To deal with multiple tracer combinations, we improved the original FBPnet-Sep model by taking the decay correction into account, getting the FBPnet-DC-Sep model. The two models were tested and compared.
Data simulationPhantomsThe two-dimensional brain phantoms used for data simulation were modified from the 3D Zubal brain phantom [46]. We chose 40 slices having different structures. The 40 phantoms are sized 128 pixels \(\times\) 128 pixels, and each contains up to five regions of interest (ROIs). The average size of ROI 1 to ROI 5 are 1393, 1427, 78, 110 and 130 pixels. Representative phantoms are shown in Fig. 2.
Fig. 2
Representative brain phantoms from different slices
Generation of dynamic activity imagesThe dynamic PET images were generated based on the two-tissue compartment model [44], which is a widely used kinetic model of PET tracers. It is described as:
$$\begin \dfrac =&K_1 C_P(t) - (k_2+k_3)C_1(t) + k_4 C_2(t), \end$$
(9)
$$\begin \dfrac =&k_3 C_1(t) - k_4 C_2(t), \end$$
(10)
$$\begin C_T(t) =&C_1(t) + C_2(t). \end$$
(11)
\(C_P(t)\) is the plasma TAC, i.e., the plasma input function. \(C_T(t)\) is the tissue TAC, which is the summation of TACs of two compartments, \(C_1(t)\) and \(C_2(t)\). The two compartments represent different metabolic states in tissue of the tracer. The rates of exchanges between different compartments (including the blood vessel) depend on the rate constants \(K_1\), \(k_2\), \(k_3\) and \(k_4\), which are also known as kinetic parameters. The values of these parameters are related to the pharmacokinetics of the tracer and physiological characteristics of its molecular target. When \(k_3\gg k_4\), the transfer from Compartment 1 to Compartment 2 is regarded irreversible, the tracer is therefore considered having irreversible kinetics. Otherwise, the bound between the tracer and its target is reversible.
The Compartment Model Kinetic Analysis Tool (COMKAT) [47] provides numerical solutions of compartment models. Before solving Eqs. (9)–(11), the scanning protocol, input function and kinetic parameters of each pixel were determined. As an example, the \(^\)F-FDG dynamic scan was designed with a duration of 60 min and divided into 26 frames (15 s \(\times\) 8, 60 s \(\times\) 8, 300 s \(\times\) 10). The input function of \(^\)F-FDG is modeled as:
$$\begin C_P(t) = (A_1 t-A_2-A_3)e^ + A_2 e^ + A_3 e^. \end$$
(12)
According to experimental data of human subjects [48], \(A_1=851.1 \mu Ci/mL\), \(A_2=21.88 \mu Ci/mL\), \(A_3=20.81 \mu Ci/mL\), \(\lambda _1=-4.134 min^\), \(\lambda _2=-0.1191 min^\), \(\lambda _3=-0.01043 min^\). In order to mimic the individual difference in physiological states, the Gaussian randomization was applied to the parameters of input function as well as the kinetic parameters of each ROI. Mean values of the parameters were referred to those reported in previous studies [18, 48], and the standard deviations were set to 10% of the mean values. Totally, 22 groups of physiological parameters were simulated. The output of compartment model was computed by COMKAT for each pixel to form the dynamic activity image of \(^\)F-FDG.
Images of \(^\)C-FMZ, \(^\)C-MET, \(^\)F-AV45 and \(^\)F-FLT were generated in the same way, following the same 60-min-26-frame protocol. The input functions and the empirical values of kinetic parameters were different among tracers, which were determined according to corresponding researches [18, 48,49,50,51,52]. The dual-tracer activity images were obtained by adding two single-tracer images. All images were sized 128 pixels \(\times\) 128 pixels \(\times\) 26 frames.
Generation of dynamic sinogramsThe dynamic single-tracer sinograms were obtained by projecting the single-tracer activity images using the Michigan Image Reconstruction Toolbox [53]. The geometry of Inveon PET/CT scanner (Siemens) was simulated. Subsequently, 20% random coincidence events were added to the projections, and the Poisson noises were simulated. The dual-tracer sinograms were the summation of two single-tracer sinograms. All sinograms were sized 128 bins \(\times\) 160 angles \(\times\) 26 frames.
Data preprocessingFor each tracer combination, a total of 880 groups (22 sets of physiological parameters \(\times\) 40 phantoms) of dynamic PET data were generated. Each group of matched dynamic data consisted of the noisy dual-tracer sinogram (\(S_\)), two noisy single-tracer sinograms (\(S_1\), \(S_2\)), noise-free dual-tracer activity image (\(I_\)) and two noise-free single-tracer activity images (\(I_1\), \(I_2\)). In each group, sinograms were scaled by dividing max(\(S_\))/3, and images were scaled by dividing max(\(S_\))/150.
Training detailsThe 880 groups of data were randomly split into training and test datasets by 10:1 according to parameter sets. In other words, all the 40 phantom slices were included in three datasets, while the physiological parameters were not repeated. The sample sizes are listed in Table 1. Note that in the training of FBPnet-DC-Sep model in Experiment 4, data was augmented by including \(^\)C-FMZ/\(^\)F-FDG and \(^\)C-MET/\(^\)F-FDG combinations, which were obtained by switching two tracers of \(^\)F-FDG/\(^\)C-FMZ and \(^\)F-FDG/\(^\)C-MET combinations.
Network training was performed on PyTorch 1.11 by a NVIDIA TITAN RTX graphics card. In the training session of each experiment, the FBP-Net and separation network were separately pretrained for 300 epochs and 100 epochs respectively, using the training dataset listed in Table 1, and both with a batch size of 4 and a learning rate of 0.0001. The entire models were trained for 100 epochs based on pre-trained network parameters and by the same dataset, with a batch size of 16 and a learning rate of 0.0001. No early stopping or regularization was used during training.
Evaluative metricsThe performance of different methods was quantitatively evaluated by MSE, SSIM and peak signal-to-noise ratio (PSNR) between the predictions and labels. In Experiment 1, bias and standard deviation of ROI TACs and images were also evaluated.
In Experiment 4, we also estimated the macro-parameters from the predicted ROI TACs, and compared them to those derived from the label TACs. For irreversible tracers (\(^\)F-FDG, \(^\)C-MET, \(^\)F-FLT), the net uptake rate \(K_i\) was estimated by Patlak plot [54]. For reversible tracers (\(^\)C-FMZ, \(^\)F-AV45), the total distribution volume \(V_T\) was estimated by Logan plot [54]. The parameters were computed in COMKAT using data of the last 10 frames. And the relative errors of the estimated macro-parameters were calculated.
留言 (0)