

記住我










Amnestic mild cognitive impairment (aMCI) is considered the preceding phase of dementia in Alzheimer’s disease (AD) (Zhu et al., 2013). Approximately 10–15% of patients with aMCI develop AD dementia per year, with an average conversion rate of 60% after 5 years (Farias et al., 2009). However, progression is variable among individuals with aMCI. Due to the heterogeneity in its etiology, different rates of cognitive decline are observed in patients with aMCI. While some patients exhibit rapid conversion to AD dementia, others remain stable or may even return to normal cognitive functioning (Busse et al., 2006). The deposition of amyloid-β (Aβ), a well-known pathological hallmark of AD, is a critical predictor of conversion to AD in aMCI patients. Indeed, it has been found that only 40 to 60% of patients diagnosed with aMCI exhibit Aβ positivity (Landau et al., 2012; Roberts et al., 2018), and the conversion rate for Aβ (+) patients with aMCI is 4 to 9 times higher than that of Aβ negative, Aβ (−) (Okello et al., 2009; Doraiswamy et al., 2014).
Recent treatment strategies for AD focus on the predementia stage encompassing MCI and aim at slowing cognitive deterioration. Identifying the timing when individuals with MCI would benefit from treatment is essential. Hence, recent studies have shifted its emphasis from the follow-up to predicting the time of progression in individuals with MCI (Li et al., 2013, 2018). Promising results have been achieved using clinical and imaging-based parameters at the baseline and employing their longitudinal change pattern to forecast of the progression of MCI to AD dementia in individuals.
Further, advances in technology have made deep learning capable of creating new prediction models. Previous studies have shown the newly developed deep learning methods to detect MCI and AD. These studies have demonstrated the ability to evaluate features of abnormal brain connections or identify discriminative brain regions of AD (Pan et al., 2021; Zuo et al., 2021, 2024). In contrast to conventional machine learning models, deep learning techniques have emerged as powerful tools capable of effectively analyzing high-dimensional data and capturing the intricate and nonlinear relationships between its features (Jung et al., 2021). Building on our previous work (Jung et al., 2021), we demonstrated the feasibility of devising a deep recurrent network to address the four interrelated problems of missing value imputation, phenotypic measurement forecasting, cognitive score trajectory estimation, and clinical status prediction using longitudinal imaging biomarkers (Jung et al., 2021). The proposed method is superior to the existing competing methods for a variety of quantitative metrics (Jung et al., 2021). To our knowledge, no existing research has reported the application of machine or deep learning models for predicting the future outcomes of patients with MCI regarding Aβ (+) and Aβ (−) in the context of AD progression.
The present study aims to extend a predictive model using multimodal biomarkers to forecast cognitive decline and magnetic resonance imaging (MRI) markers in the Aβ (+) and Aβ (−) MCI populations. We hypothesize that clinical, neuropsychological, and neuroimaging features of the characteristics of aMCI exhibit associations with cognitive decline and MRI markers, and a combination of these features could enable accurate individual-level predictions of cognitive decline and MRI markers. Under this assumption, we aim to enhance our understanding of the relationship between these features in aMCI and their respective implications for cognitive decline and MRI markers.
Dataset and preprocessing Study participantsWe recruited 657 patients with aMCI who underwent three-dimensional (3D) MRI and Aβ positron emission tomography (PET) imaging (18F-florbetaben (FBB) PET or 18F-flutemetamol (FMM)) imaging between February 2015 and June 2021 at Samsung Medical Center (SMC). All participants diagnosed with MCI fulfilled the following criteria (Albert et al., 2011): (1) Participants or their caregivers must report subjective cognitive complaints. (2) Participants must exhibit objective cognitive impairment in any cognitive domain, with scores falling below −1.0 standard deviations of age- and education-matched norms in memory and − 1.5 standard deviations in other cognitive domains. (3) Participants must not have significant impairment in activities of daily living. (4) Participants must not have dementia. We excluded laboratory-confirmed secondary causes of cognitive deficits, including thyroid, renal, and hepatic function tests, vitamin B12, and syphilis serology. Individuals who had structural abnormalities on their brain MRI, such as territorial infarctions, intracranial hemorrhages, brain tumors, hydrocephalus, or significant white matter hyperintensities as determined by the modified Fazekas ischemia scale (Noh et al., 2014), were also excluded.
This study was approved by the Institutional Review Board of SMC (IRB No: 2018–10-120). Written informed consent was obtained from the patients and their caregivers.
Neuropsychological testsAll participants underwent the Seoul Neuropsychological Screening Battery second edition (SNSB-II) (Kang et al., 2003, 2019). All of the included tests in SNSB-II have been internationally used for several decades in clinical practice (Wechsler, 1955; Folstein et al., 1975; Golden, 1978; Benton et al., 1983; Kaplan et al., 1983; Morris, 1993; Meyers and Meyers, 1995; Kang et al., 1997, 2003, 2012; Benedict et al., 1998; O'Bryant et al., 2008; Ryu and Yang, 2023). The items used in the tests were altered due to the linguistic and cultural differences between Korean and English speakers (Kim and Na, 1999; Kang et al., 2003, 2012; Ryu and Yang, 2023). We used tests that provided numerical scores, such as the Digit Span Forward (DSF), the Korean version of the Boston Naming (K-BNT), Rey complex figure test (RCFT) (copying and delayed recall), Seoul verbal learning test (SVLT) (delayed recall), semantic controlled oral word association test (COWAT), Stroop Test (color reading), Korean-Mini Mental State Examination (K-MMSE), and Clinical Dementia Rating-Sum of Boxes (CDR-SB). In the analysis, the results with numerically continuous values were used.
The participants’ attention and working memory were assessed using the DSF, and naming ability was evaluated using the K-BNT score. Verbal memory and visual memory were measured using the SVLT (delayed recall) and RCFT (delayed recall) scores, respectively. The visuospatial function was assessed using the RCFT copying test, and the frontal executive function was measured using the semantic COWAT and Stroop test. The global cognition was evaluated with K-MMSE and CDR-SB.
MRI data processing for cortical thickness measurementsAll subjects received 3D T1 turbo field echo images and 3D fluid-attenuated inversion recovery at SMC with a 3.0 T MRI scanner (Philips 3.0 T Achieva; Philips Healthcare, Andover, MA, USA), as previously described. The CIVET anatomical pipeline (v. 2.1.0) was used to process the images (Zijdenbos et al., 2002). The MRI images of the native subjects were aligned with the MNI-152 template using a linear transformation method (Collins et al., 1994). Additionally, the images were adjusted for variations in intensity using the N3 algorithm (Sled et al., 1998). The images that were registered and corrected were segmented into distinct regions, including white matter, gray matter, cerebrospinal fluid, and background. Furthermore, the marching-cubes approach was employed to automatically extract the inner and outer cortex surfaces. This allowed for the calculation of cortical thickness, which is defined as the Euclidean distance between the connected vertices of the inner and outer surfaces (Lerch and Evans, 2005).
Intracranial volume (ICV) was calculated by measuring the total volumes of the voxels within the skull-stripped brain mask. After obtaining cortical surface models using MRI volumes that were converted into stereotaxic space, we evaluated the cortical thickness in the original space by using an inverse transformation matrix to rebuild the cortical surface in the original space (Im et al., 2006).
We utilized a surface-based 2D registration technique employing a sphere-to-sphere warping algorithm. Furthermore, we spatially standardized the cortical thickness values to facilitate a comparison between the thickness obtained from the registration algorithm and an unbiased iterative group template with improved anatomical detail (Lyttelton et al., 2007). This transformation allowed us to align the thickness information for the vertices with the unbiased iterative group template. The technique of surface-based diffusion smoothing was employed to blur each cortical thickness map, with a full width at half maximum of 20 mm. This process was done to enhance the signal-to-noise ratio and statistical power of the data, as described by previous studies (Chung et al., 2003; Im et al., 2006). In order to quantify the hippocampal volume (HV), we employed an automated method for segmenting the hippocampus. This method utilized a graph cut algorithm in conjunction with atlas-based segmentation and a morphological opening technique, as detailed in an earlier study.
Amyloid PET imaging acquisition, analysis, and Centiloid valuesAll participants underwent either FBB or FMM PET scans at SMC using a Discovery STe PET/CT scanner (GE Medical Systems, Milwaukee, WI, USA). The scans were performed in 3D mode, examining 47 slices of 3.3 mm thickness that covered the entire brain (Jang et al., 2019). The CT pictures were obtained using a 16-slice helical CT scanner with a section width of 3.75 mm. The scanner was set to 140 keV and 80 mA for attenuation correction. Following the guidelines provided by the makers of the ligands, a dynamic emission PET scan lasting 20 min was conducted. This scan consisted of four frames, each lasting 5 min. The scan was performed 90 min after injecting an average dose of 311.5 MBq of FBB or 185 MBq of FMM. The 3D PET scans were reconstructed using the ordered-subset expectation–maximization algorithm with a voxel size of 2.00 × 2.00 × 3.27 mm. The reconstruction was done in a 128 × 128 × 48 matrix. The algorithm parameters used were FBB iterations = 4 and subsets = 20 for the ordered-subset expectation–maximization algorithm, and FMM iterations = 4 and subsets = 20 for the same algorithm. The PET images were aligned with individual 3D-T1 weighted MRI scans that were standardized to the T1-weighted MNI-152 template using statistical parametric mapping (SPM) 8. The quantification of Aβ uptakes was performed using BeauBrain Morph, a software developed by BeauBrain Healthcare Co., Ltd. This software utilizes fully-automated image processing to measure Aβ uptakes on PET scans. In the previous study, to improve the prediction of prognosis and early detection, we developed an MRI-based regional modified Centiloid (rdcCL) method that harmonizes the overall and regional Aβ uptake among Aβ ligands (Klunk et al., 2015). More details of the analysis method are found in the original Centiloid project paper and previous paper (Kim et al., 2022). The MRI and PET images underwent spatial normalization using the transformation parameters obtained from SPM8. The whole cerebellar (WC) mask for the reference region was obtained from the Global Alzheimer’s Association Interactive Network website. We created a WC mask for rdc-SUVR to calculate global and regional Centiloid using FBB and FMM PET images of Aβ patients. The six regional Volume of interests (VOIs) were named the frontal, lateral temporal, occipital, parietal, posterior cingulate, and striatal areas. rdc-SUVR values were calculated using the global regional VOIs. We divided the groups into two groups using the K-means clustering algorithm, and the cut-off was obtained by using the Centiloid values of patients in the lower group of these two groups. We defined Aβ positivity based on the cutoff value of the FBB or FMM PET global rdcCL, which was previously computed as 27.08 (Jang et al., 2021). This cutoff value is similar to the cutoff of 30 CL which was reported by previously studies (Salvadó et al., 2019; Milà-Alomà et al., 2021, 2022).
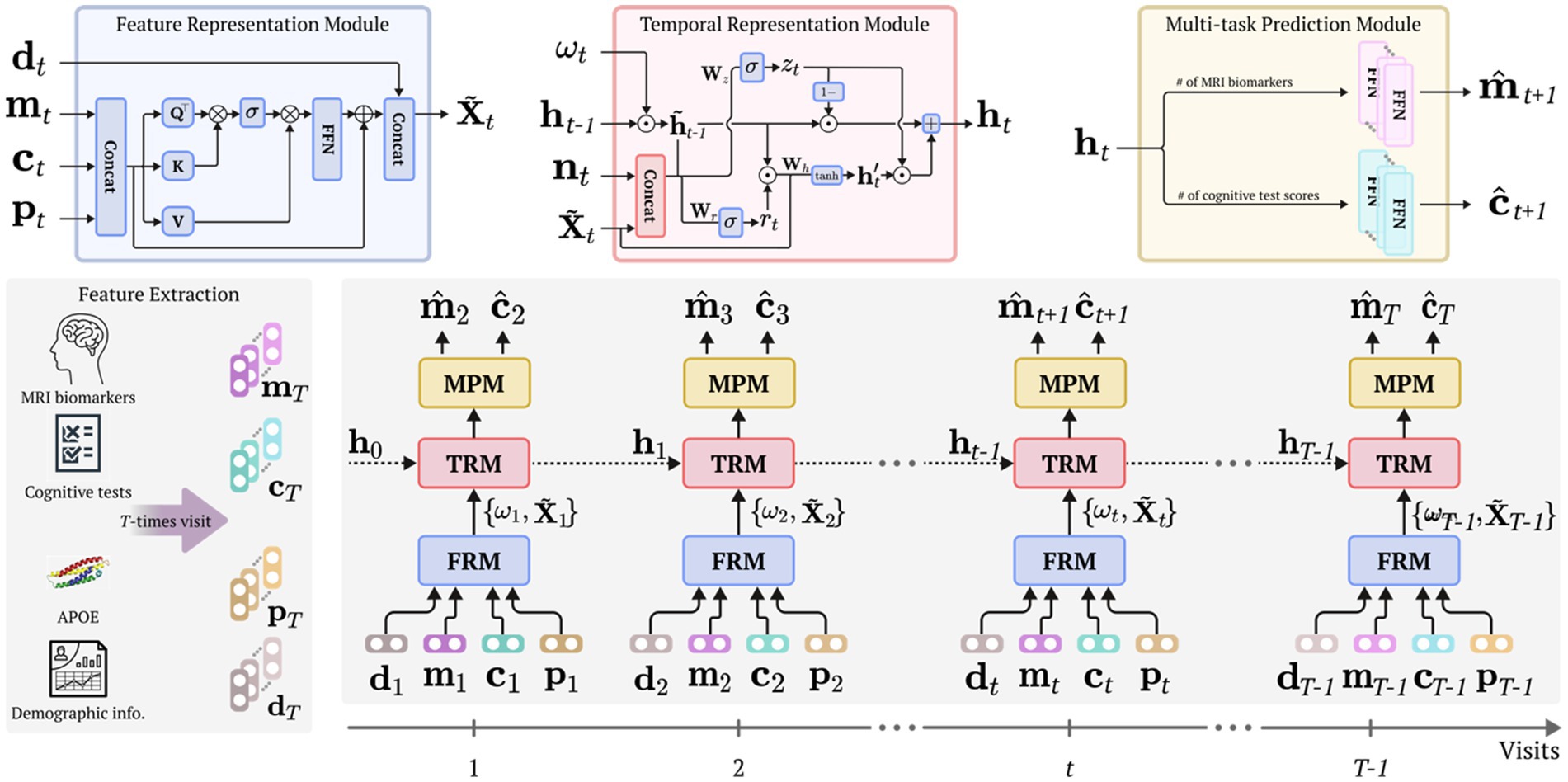
Proposed methodThis work proposes a simple but efficient framework for modeling personalized prognostic trajectories in participants with aMCI. Specifically, the proposed framework consists of three modules: a feature representation module (FRM), temporal representation module (TRM), and multi-task prediction module (MPM) as illustrated in Figure 1. In the FRM, we employ a self-attention mechanism (Vaswani et al., 2017) to fuse diverse clinical information (e.g., MRI markers, cognitive test scores, and the presence of the apolipoprotein E (APOE) carrier) into representative features. This module captures complex relationships of the input data and provides a comprehensive representation. The representative features were input into the TRM. Through this process, the proposed framework embeds and captures the underlying temporal characteristics inherent in the longitudinal data. The temporally embedded features are then fed into the MRM to simultaneously predict the cortical thickness of MRI markers and cognitive test scores for the next time sequence. By integrating these three modules, our proposed framework facilitates modeling individualized prognostic trajectories in participants diagnosed with aMCI.
Figure 1. Overall framework. Our proposed framework comprises a feature representation module (FRM) to learn enriched feature representation and to fuse multimodal input features using a self-attention mechanism; a temporal representation module (TRM) dedicated to accounting for the characteristics of temporal dynamics; and a multi-task prediction module (MPM) aimed at predicting the MRI biomarkers and cognitive test score for subsequent time visits. Before our proposed framework is trained, the data extraction procedure is initially conducted, utilizing MRI, cognitive tests, APOE genotype, and demographic data. Henceforth, each module considers multivariate and temporal traits, thereby using various input features from the current visit to predict the MRI biomarkers and cognitive test scores for the subsequent visit. FRM, feature representation module; TRM, temporal representation module; MPM, multi-task prediction module; APOE, apolipoprotein E.
NotationIn this work, we express matrices with boldface uppercase letters, vectors with boldface lowercase letters, and scalars with italic letters. For a given matrix C , we define its ijth element and the i -th column as Cij and ci , respectively. Thus, the longitudinal neuroimaging dataset is characterized by a multivariate time series consisting of B variables across T time sequences from N number of samples as XnYnn=1NwhereXn=x1n⋯xtn⋯xTn∈ℝB×T,Yn=y1n⋯ytn⋯yTn∈01L×T, and L represents the of classes, number of classes, such as Aβ (+) and Aβ (−) status. Furthermore, each data point integrates demographic information (i.e., age, gender, and education) pertaining to the n -th sample from the first visit (i.e., baseline). To use them as input features, demographic information is duplicated across T time sequences, with the exception of age. For simplicity, the superscript n is omitted. For clarity, the input features are defined as xt=mtctptdt , where mt denotes the cortical thickness features, ct represents the cognitive test scores, pt indicates APOE features, and dt=dtagedtedudtgen represents the demographic information, including age, education, and gender.
Missing value imputationGiven the scarcity of longitudinal data XY , we tackle the problem of missing values by applying an imputation technique. To achieve this, we employ a mask vector alongside a time interval between consecutive data observations. These variables-the mask vector and time interval-are instrumental in informing to the model about the presence or absence of input features and labels. Consequently, this facilitates the model’s capacity to adeptly manage missing values, thereby recuperating essential information both for the imputation of missing values and for the latent feature representation. To incorporate this information, we employed a time delay matrix, indicating the time interval of observation. Harnessing these characteristics, we embraced a data-driven imputation strategy, which proficiently utilizes both temporal and multivariate relationships to impute missing observations. A detailed explanation is provided in our earlier work (Jung et al., 2021).
Feature representation moduleThe proposed framework encompasses an feature representation module (FRM) designed to identify and understand the relationships among multimodal input data, thereby learning an enriched representation of clinical information. In other words, this module leverages a self-attention mechanism, thereby identifying feature-specific relationships and acquiring intricate and comprehensive clinical information.
To adhere to the aforementioned assumption, at time t, we initially concatenate the input features that include MRI markers, cognitive test scores, and the presence of APOE carriers as follows:
x˜t=mt⊚ct⊚pt∈ℝB′×1,where ⊚ represents a concatenation operator. Subsequently, these concatenated features are transformed into three distinct representations through the utilization of three feed-forward networks (FFNs): the query Q , key K , and value V :
Q=x˜tWq,K=x˜tWk,V=x˜tWv,where Wq∈ℝB′×B′,Wk∈ℝB′×B′, and Wv∈ℝB′×B′ are learnable weight matrices. Following this, the similarity between each query in the Q representation and each key in K representation is computed using the elementwise product. A standard self-attention calculation (Vaswani et al., 2017) is then executed as follows:
where dk representing the feature dimension of K and σ denotes a softmax function. After performing the self-attention operation, the outcome is multiplied by the value features. FFN is then applied to further refine the transformed features. These refined features are added back to the original concatenated features (i.e., attentive feature vectors) and concatenated with the demographic features as outlined in Figure 1 (FRM).
Temporal representation moduleFollowing the combining of attentive feature vectors with demographic features ( x˜t∈ℝB′×1 ), we employed a gated recurrent unit (GRU) network (Chung et al., 2014) to capture the temporal representation. We introduce a novel computational strategy via a modified GRU cell incorporating a temporal decaying factor ωt∈ℝH×1 (where H denotes the number of hidden units) and a mask vector nt∈ℝB′×1 to delineate whether each observation was directly observed or imputed. The hidden state ht−1∈ℝH×1 of the recurrent network embodies temporal context information up to the previous time t−1 ; nonetheless, it is crucial to deliberate on the manner of amalgamating this temporal data with the current observation, particularly concerning the term of recent true observation. To address this, we leverage a temporal decaying factor that judiciously apportions the impact of past observations, thereby effectively embedding them with the current observation as follows: h˜t−1=ht−1⊙ωt , where ⊙ denotes an elementwise multiplication operator. In doing so, the TRM captures temporal dependencies and adjusts its representation accordingly. Moreover, the inclusion of the mask vector into the TRM informs the model about the imputed values. Through the using of temporal patterns and mask vectors, our proposed framework adeptly discerns imputation patterns, thereby improving its representational capability.
Before demonstrating the modified gating operation of the GRU cell, we introduce the role of its two gates (i.e., reset gate and update gate). These gates control the flow of information. Specifically, the reset gate determines how much of the previous hidden state should be forgotten or reset before considering the current input, while the update gate controls how much of the new hidden state should be updated with the current input. By dynamically adjusting the reset and update gates, the GRU cell can selectively remember or forget information from the past, allowing it to capture long-term dependencies in sequential data. The operation of TRM within the proposed framework is as follows:
rt=σWr⊙h˜t−1,x˜t⊚nt+br, zt=σWz⊙h˜t−1,x˜t⊚nt+bz, h′t=tanhWh⊙rt⊙h˜t−1,x˜t, ht=1−zt⊙h˜t−1+zt⊙h′t,where WzWrWhbzbr represent learnable parameters of the modified GRU cell. The outputs of the update and reset gates are denoted by rt and zt , respectively, while h′t represents the candidate’s hidden state, and σ denotes the sigmoid function. Each weight vector (i.e., Wz,Wr,Wh ) comprises two internal vectors: Wgatei∈ℝH×2B′ and Wgateh∈ℝH×H , where gate∈zrh . Likewise, each bias vector has the same conditions, where the subscript i represents the connection between the weight vector and an input x˜t⊚nt , and the subscript h represents the connection between the weight vector and temporal context information h˜t−1 . The computation process is summarized as follows:
rt=σWr⊙h˜t−1,x˜t⊚nt+br, rt=σWri⊙x˜t⊚nt+bri+Wrh⊙h˜t−1+brh. Multi-task prediction moduleBased on the hidden representation ht from the TRM, the multi-task prediction module (MPM) generates two predictions for the next time point: the predicted MRI biomarker m̂t+1 and the predicted cognitive test scores ĉt+1 . For each outcome, we employ simple linear regression models, defined as follows:
where Wm,Wc,bm , and bc denote the learnable parameters of the linear regression models. The MPM is connected with FRM and TRM, allowing for the joint optimization of the parameters across all three modules.
Optimization and algorithmWe formulated a composite objective function to simultaneously train the proposed framework. Specifically, for the prediction of the MRI biomarker (i.e., cortical thickness), denoted as Lm , we computed the mean squared error (MSE) between the model output m̂t+1 from the MPM and the corresponding true observations mt+1 :
Lm=∑t=1T−1mt+1−m̂t+12.Similarly, for the prediction of cognitive test scores, denoted as Lc , we measured the congruity between the model output ĉt+1 from the MPM and the actual cognitive test score ct+1 :
Lc=∑t=1T−1ct+1−ĉt+12.Finally, the overall loss function Ltotal was defined as a weighted combination of the MRI biomarker loss Lm and the cognitive test score loss Lc :
where α and γ are hyperparameters to balance the influence of the respective losses. The optimization of this objective function enables the training of all learnable parameters in the proposed framework using the stochastic gradient descent method in an end-to-end manner. We performed the objective functions in various settings, including the MSE and mean absolute error (MAE). However, based on the experimental results, we selected MSE as the preferred metric.
Experiments and results Participant characteristics and demographicsA total of 657 aMCI participants were included in the study. Table 1 presents the demographic characteristics of the participants. The mean age of the study participants was 71.5 ± 8.2 years, and 56.0% (n = 368) were females. Among participants, 312 (41.5%) were Aβ (−), and 345 (52.5%) were Aβ (+). No statistical differences were found in the mean age (p = 0.933), the proportion of females (p = 0.329), or years of education (p = 0.902) between the participants with Aβ (−) and Aβ (+) aMCI. Participants with Aβ (+) aMCI had a higher frequency of the APOE ε4 genotype (p < 0.001) than participants with Aβ (−) aMCI. Furthermore, statistically significant disparities were observed in most cognitive scores, with the exceptions of DSF, COWAT, and K-BNT. Among these assessments, CDR-SB and K-MMSE are known as pivotal tools for assessing the severity of dementia and cognitive impairment (Morris, 1993; Kang et al., 1997; O'Bryant et al., 2008). Based on these cognitive scores, it was observed that participants with Aβ (+) aMCI exhibited notably higher levels of cognitive impairment severity compared to those with Aβ (−) aMCI. Consequently, a higher score on the CDR-SB indicates greater dementia severity, while a lower score on the K-MMSE signifies more severe cognitive deficits. Based on the outcomes presented in Table 1, we validated the hypothesis that categorizing aMCI patients into Aβ (+) and Aβ (−) groups through quantitative criteria is plausible and provides a theoretical basis for developing treatment strategies for dementia and cognitive impairment. Furthermore, this approach reaffirmed the utility of CDR-SB and K-MMSE in assessing cognitive impairment.
Table 1. Baseline demographic characteristics of Aβ (−) and Aβ (+) aMCI.
Experimental settingsWe validated the effectiveness of the proposed framework, which employs a systematic data-driven approach for multitask learning to model personalized prognostic trajectories in patients with MCI. Specifically, the proposed framework focuses on forecasting MRI markers and cognitive test scores, which are crucial indicators in assessing disease progression. We made predictions for each time point, with a one-year interval covering four consecutive time sequences, corresponding to forecasting the outcomes for the subsequent 3 years following the baseline. In the prediction process, we applied all available historical data, including observed measurements and imputed values for any missing or unobserved data. By incorporating this comprehensive information, the framework provides accurate and reliable predictions for each time sequence, enabling a thorough assessment of the future progression of the disease.
To ensure the reliability of the experimental results, we conducted a rigorous evaluation using five-fold cross-validation with five repetitions. In addition, the dataset was randomly partitioned into three mutually exclusive subsets: training, validation, and testing. Specifically, we randomly sampled 10% of the subjects from each class as the validation set, whereas another 10% were selected as the testing set from the baseline time point. This approach allowed the framework to validate the performance of the proposed model on unseen data and mitigate the influence of any specific subset of subjects. Regarding training settings, we performed a grid search for hyperparameter selection, including 5×10−510−410−310−2 for the learning rate, 123 for the number of hidden layers, 163248648096 for the size of the hidden units, and 10−610−510−410−3 for the l2 -regularization.
Subsequently, we leveraged an early stopping strategy to identify the optimal hyperparameters by minimizing the MSE on the validation set. In terms of the proposed framework, we used FFNs in the FRM and MPM. In particular, the FRM consisted of 17 input nodes ( B′ ) and 17 output nodes for the query, key, value, and gating layer. In MPM, we employed 21 input nodes ( B ) and six (number of MRI markers) and nine (number of cognitive test scores) output nodes for regression layers. Furthermore, we exploited a GRU cell in the TRM, consisting of 21 input nodes and 48 hidden states. To ensure a balanced optimization process, we introduced loss balance control by setting α and γ to 0.75 and 1.0, respectively. We implemented our proposed framework with PyTorch, and we trained them with Titan RTX GPU on Ubuntu 18.04.
For the quantitative evaluation, we used the MAE, mean absolute percentage error (MAPE), and coefficient of determination ( R2 ) for the MRI biomarker prediction and cognitive test scores prediction tasks. We also conducted statistical significance tests, including Pearson’s correlation coefficient for downstream tasks. For comparison with the other methods, we utilized the paired, two-sided Wilcoxon signed-rank test (Wilcoxon, 1992).
We compared our proposed method against the following approaches, which address tasks related to imputing missing values and forecasting:
• Mean imputation combined with GRU (GRU-M): missing observations were imputed using the mean values of the respective variables from the training data. Subsequently, a GRU cell was employed for forecasting tasks, such as cognitive test scores and MRI markers.
• Multi-directional recurrent neural network (M-RNN) (Yoon et al., 2018): This model, a variant of the traditional RNN, is designed to process data across multiple directions. Specifically, M-RNN leverages the concept of a bidirectional RNN to interpolate missing information within individual data streams, allowing it to analyze data in a more interconnected stream than in isolation. This makes it valuable for handling complex, multi-stream datasets where understanding the context and correlation between data points is key to accurate forecasting and imputations. However, M-RNN does not consider correlations among features.
• Self-Attention-based Imputation for Time Series (SAITS) (Du et al., 2023): This model is trained with a joint optimization approach that utilizes two diagonal-masked self-attention blocks (DMSA) to effectively capture both the temporal dependencies and feature correlations between time steps, thereby improving imputation accuracy and training speed. In addition, a weighted-combination block dynamically assigns weights to the representations learned from two DMSA blocks, guided by attention weights and missingness information, to further refine imputation precision.
For all comparative methods, the range of initial hyperparameters was set based on their original papers, and the optimal hyperparameters were selected based on the results of the validation set. All of the experiments were conducted using the same experimental settings as that of the proposed method.
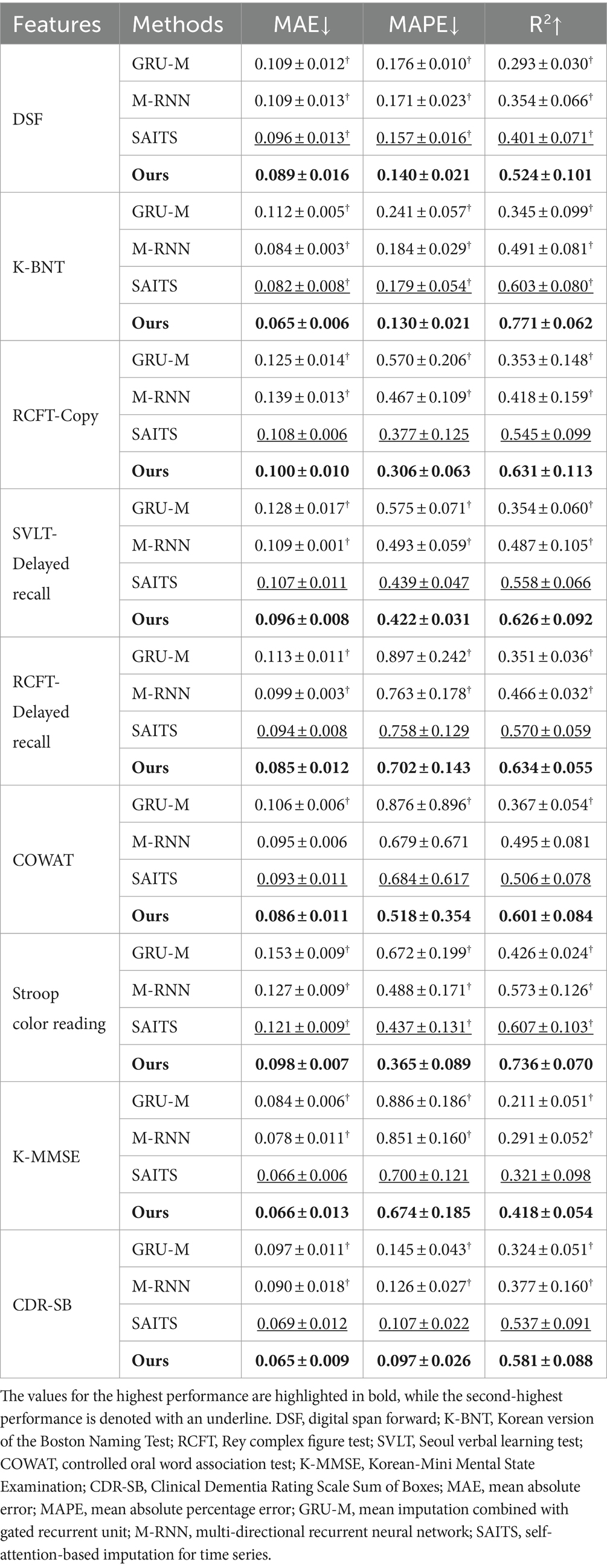
Prediction of cognitive test scoresTable 2 summarizes the prediction errors for the longitudinal changes in neuropsychological test scores. Between the proposed framework and comparative methods. Namely, we evaluated the prediction errors using MAE, MAPE, and R2 metrics. Note that the values for the highest performance are highlighted in bold, while the second-highest performance is denoted with an underline. First, it is noteworthy to highlight that our proposed method outperformed all the competing methods under our consideration, achieving the lowest MAE, MAPE, and R2 scores, with a statistical significance of p<0.05 for most of the competing methods. Overall, M-RNN and SAITS demonstrated better performance than GRU-M across all cognitive test scores in terms of MAPE and R2 metrics. However, in terms of MAE, M-RNN showed lower performance than GRU-M specifically in the RCFT-Copy score, though it still outperformed GRU-M in terms of MAPE and R2. This underscores the importance of utilizing a variety of evaluation metrics rather than relying on a single one to ensure a fair comparison. Additionally, we observed that among M-RNN and SAITS, the SAITS approach generally yielded better performance than M-RNN across all metrics, except for the COWAT score.
Table 2. Performance predicting normalized cognitive test scores for MAE, MAPE, and R2 (†p<0.05).
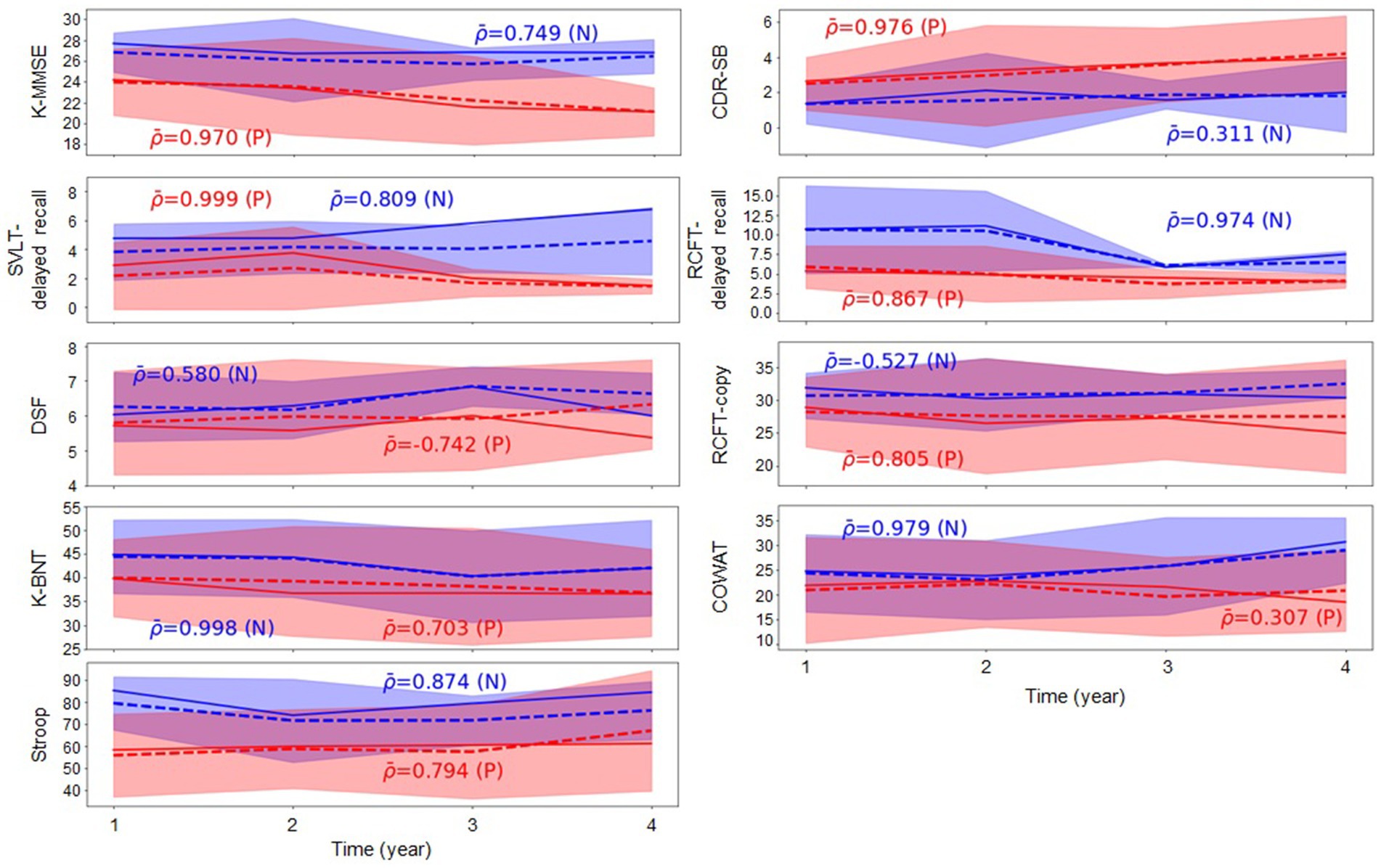
Table 2 indicates that, generally, all methodologies demonstrated high R2 values in the task of predicting cognitive test scores. Specifically, based on the R2 values resulting from our proposed method, the ranking of cognitive test scores was revealed as follows: K-BNT, Stroop Color Reading, RCFT-Delayed Recall, RCFT-Copy, SVLT-Delayed Recall, COWAT, CDR-SB, DSF, and K-MMSE. Furthermore, we conducted a group analysis of the groups with Aβ (+) and Aβ (−) aMCI to observe changes in the trajectory of the cognitive test scores over time and the intergroup differences in their values. Figure 2 presents the comparative analysis of the cognitive test scores between the groups with Aβ (+) aMCI and Aβ (−) aMCI. The findings indicate that the group with Aβ (+) exhibited a more rapid decline in cognitive tests, including the K-MMSE and CDR-SB, compared to the group with Aβ (−). When examining the trajectories of longitudinal cognitive scores in the group comparison, we observed that the cognitive scores of the Aβ (+) group tended to be lower than those of the Aβ (−) group, except for the CDR-SB score. However, higher values on CDR-SB indicate worse conditions; thus, this observation is meaningful. Based on this trend, the possibility of disease progression is expected to be higher in the group with Aβ (+) than that with Aβ (−) (Figure 2). Therefore, more attention should be focused on subjects with Aβ (+) MCI who are likely to exhibit rapid cognitive decline.
Figure 2. Group comparison of changes in the cognitive test scores over time. ρ¯ represents the average Pearson correlation coefficient calculated within each group, where (N) and (P) denote groups with Aβ (−) and Aβ (+), respectively. Blue and red indicate the groups with Aβ (−) and Aβ (+), respectively. The solid line corresponds to the actual observations, whereas the dotted line depicts the predicted values. Aβ, amyloid-β; K-MMSE, Korean-Mini Mental State Examination; CDR-SB, Clinical Dementia Rating Scale Sum of Boxes; SVLT, Seoul verbal learning test; RCFT, Rey complex figure test; DSF, digital span forward; K-BNT, Korean version of the Boston Naming Test; COWAT, controlled oral word association test.
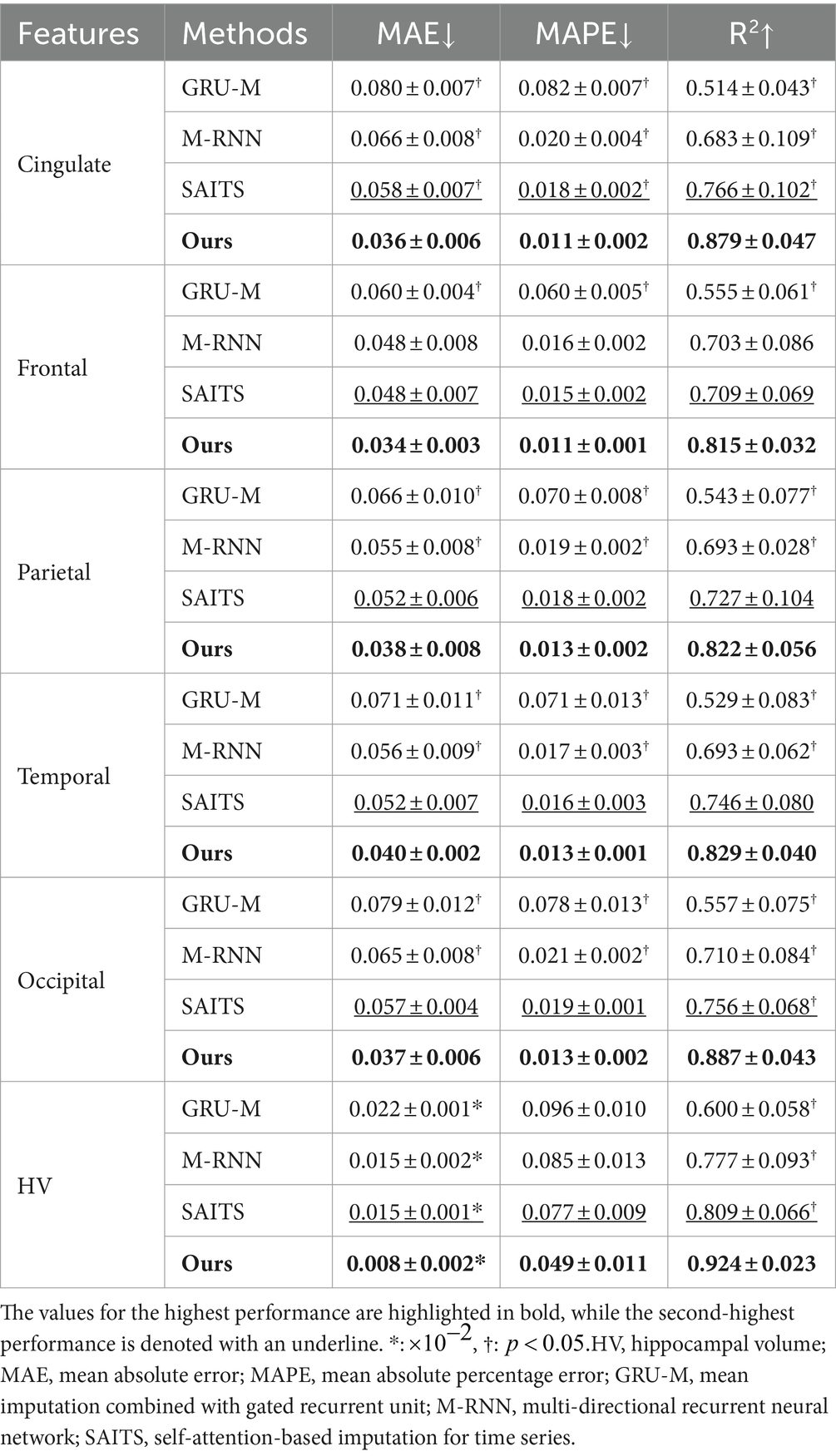
Prediction of MRI markersSimilarly to Tables 2, 3 describes the prediction errors for longitudinal changes in MRI markers, assessed using three metrics: MAE, MAPE, and R2. Note that the values for the highest performance are highlighted in bold, while the second-highest performance is denoted with an underline. Just as with the cognitive test score predictions, our proposed method outperformed all considered competing methods, achieving the lowest MAE, MAPE, and R2 scores with statistical significance of p<0.05 for most competing methods. Furthermore, for this task, we observed a performance improvement in the order of GRU-M, M-RNN, SAITS, and our proposed method with the R2 values indicating much stronger performance in predicting MRI markers compared to the cognitive test score prediction task. Significantly, the MRI markers, including HV and cortical thicknesses in the occipital, cingulate, temporal, parietal, and frontal regions, yielded favorable predictive results, ranked in descending order. Several studies (Singh et al., 2006; Verfaillie et al., 2016; Lee et al., 2018) have reported consistent patterns of volume atrophy in various brain regions, particularly the prefrontal cortex, temporal lobe, and parietal lobe, in relation to cognitive decline. The extent of brain atrophy is predictive of cognitive decline over time.
Table 3. Performance of predicting MRI markers in terms of MAE, MAPE, and R2.
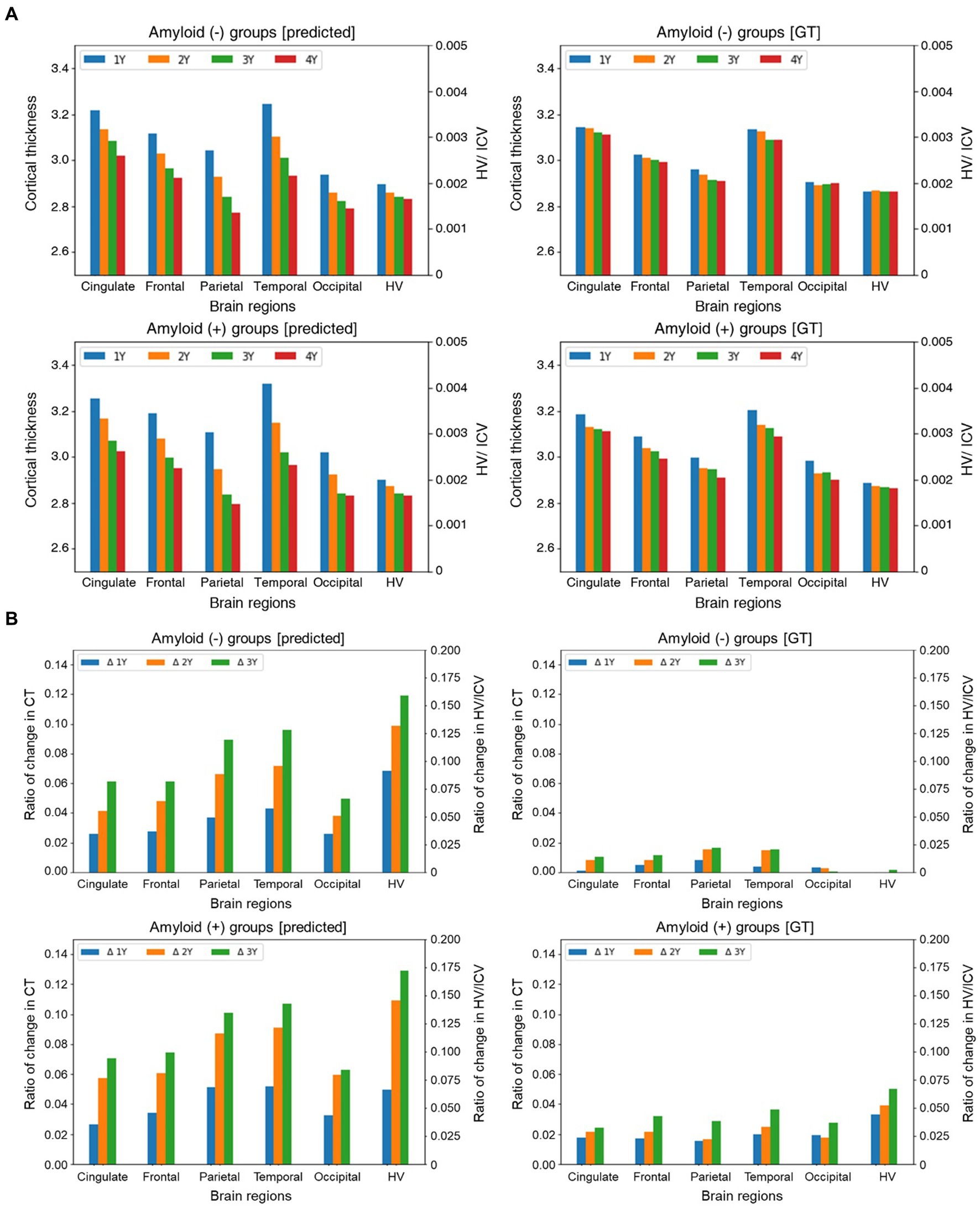
Furthermore, we separately conducted a multifaceted analysis of the longitudinal cortical thinning in the groups with Aβ (+) and Aβ (−) to investigate the influence of the time interval from the baseline MRI scans. Initially, we examined the interaction effect between Aβ (+) and time, revealing that the group with Aβ (+) aMCI exhibited a significantly accelerated rate of cortical thinning than the group with Aβ (−) aMCI in specific brain regions, such as the cingulate, frontal, parietal, temporal, occipital, and hippocampal regions, as depicted in Figure 3A. Compared to the group with Aβ (−), those with Aβ (+) demonstrated a higher progression of brain region atrophy over time based on the ground truth (GT) in Figure 3A (right). Similarly, the predicted values also indicate that the group with Aβ (+) observed more significant brain region atrophy over time than the group with Aβ (−) in Figure 3A (left).
Figure 3. Group comparison of the trajectories for longitudinal MRI markers (A) and the ratio of relative changes in longitudinal MRI markers over time (B). In figure (A), the x- and y-axes represent different brain regions and cortical thickness and HV values are divided by ICV, respectively. In figure (B), The x-axis represents different brain regions. The y-axis indicates the ratio of changes in cortical thickness and HV/ICV values relative to the baseline. The plots in each panel represent a specific time. Abbreviations: GT, ground truth; HV, hippocampal volume; ICV, intracranial volume; CT, cortical thickness.
To delve deeper into the analysis, we further derived the following formula to quantify the relative changes in brain regions over time:
sg,ti=yti−y0iy0i,sp,ti=ŷti−y0iy0i,where p,g,i, and t indicate the prediction, GT, indices of MRI markers, and time points, respectively. The calculated relative changes were subsequently normalized by the minimum and maximum values so that the resulting values were in the range of [−1,1], with positive and negative values representing increasing and decreasing, respectively. While there were some variations between the predictions and actual observations, we observed discernible differences between the groups. Specifically, the findings based on the GT demonstrated a greater progression of brain region atrophy in the group with Aβ (+) than that with Aβ (−). Regarding the predicted values, although a relatively minimal intergroup difference exists in brain region atrophy during the first year, starting from the second year, the group with Aβ (+) exhibits a more rapid progression of brain region atrophy than the group with Aβ (−) (Figure 3B).
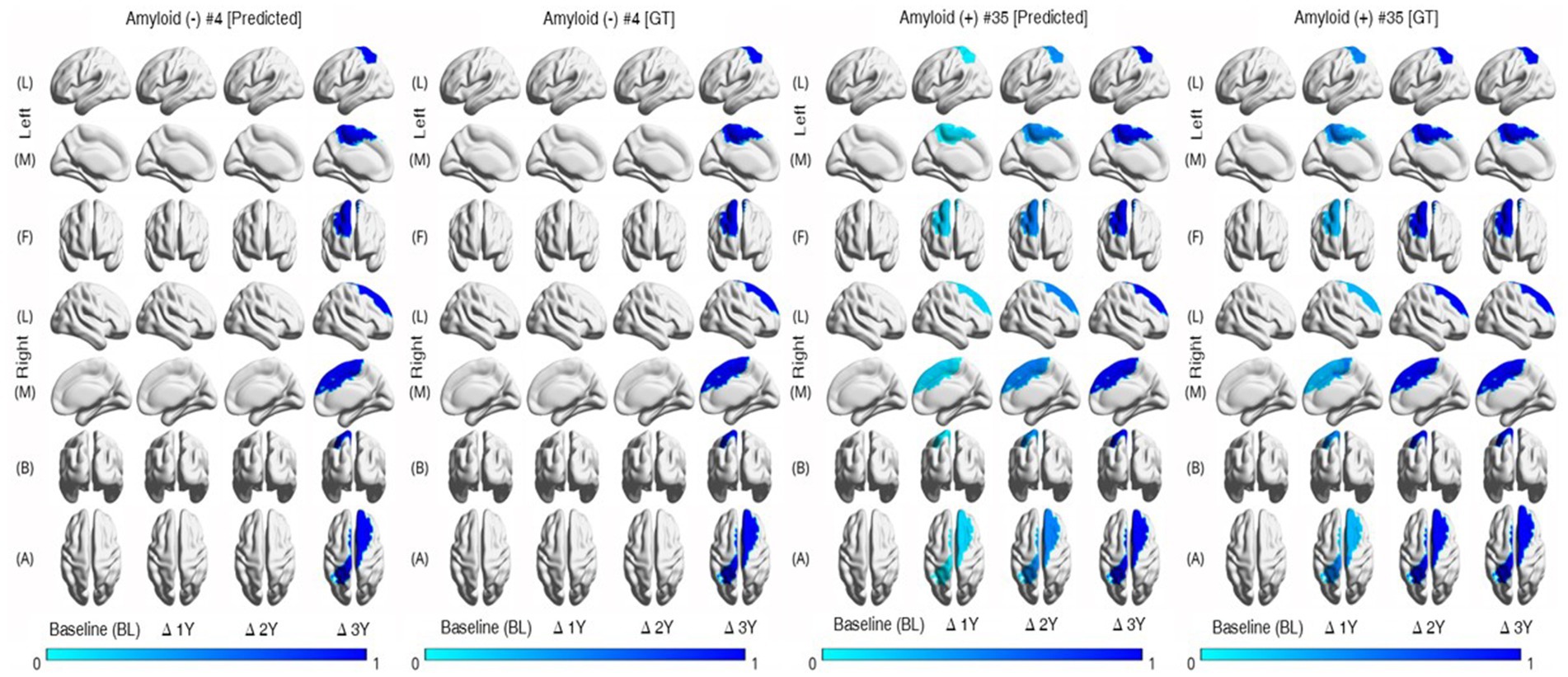
Last, we conducted the individual-level changes in brain regions over time, as illustrated in Figure 4. In this study, we utilized the mean values for brain areas corresponding to each hemisphere. Consequently, as seen in Figure 4 [row (A)], there are overlapping areas when visualizing the results for specific regions. To enhance the clarity of these visualizations, we categorized the areas and separated them into left and right hemispheres. Following the calculations described in Figure 3B, we applied a threshold of 0.25 for the visualization process. The figure reveals that the degree of brain region atrophy is less prominent in the Aβ (−) samples until the second year. In contrast, the Aβ (+) samples exhibit substantial brain region atrophy from the first year onwards.
Figure 4. Individual trajectories of MRI markers representing relative changes over time. The color-coded values represent the normalized changes relative to the baseline values of the corresponding regions. The thickness of the brain region becomes thinner in Aβ (+) faster than Aβ (−). Aβ, amyloid-β; GT, ground truth.
The group with Aβ (+) had a greater magnitude of cortical thinning and volumetric changes in specific brain regions over time than the group with Aβ (−) (Figures 3A,B). Further, similar patterns of analysis by group occurred, with variations in individual levels (Figure 4). Based on these findings, we concluded that the group with Aβ (+) is more likely to progress toward dementia or exhibit cognitive decline.
Performance of the proposed framework (amyloid positivity prediction)Although not the primary study focus, we conducted an analysis to indirectly assess the performance of the downstream task. We defined three scenarios for comparison: (1) comparing the diagnostic outcomes for first-time visiting patients and comparing the predictive results (2) with and (3) without missing values.
First, regarding the diagnostic outcomes of the first-time visiting patients, we employed the same input features as used in the proposed method, with the distinction that the time interval of observation was limited to 1 year. To evaluate the performance, we employed the support vector machine (SVM), which is widely used for classification tasks. We applied various metrics to assess the predictive performance, including accuracy, sensitivity, specificity, and the area under the receiver operating characteristic curve (AUC). The performance of this scenario is presented as follows: accuracy (0.731 ± 0.035), sensitivity (0.692 ± 0.057), specificity (0.765 ± 0.025), and AUC (0.779 ± 0.033).
The subsequent scenario encompassed predicting outcomes in the presence and absence of missing values. For the case of missing values (i.e., without applying an imputation task), the following procedure was employed to derive the results. As described in the experimental setting section, in the process of estimating missing values using the data-driven imputation approach, we evaluated the performance of the prediction of the MCI progression in patients by considering the imputation and classification loss values. The performance of longitudinal prediction for the case when values were missing is as follows: accuracy (0.706 ± 0.058), sensitivity (0.735 ± 0.088), specificity (0.735 ± 0.088), and AUC (0.779 ± 0.044). Based on these results, we replaced missing observations with imputed features at specific points in time.
When input observations were missing (i.e., applying an imputation task), missing observations were imputed through a previous step. Then, the final outputs (i.e., predicted MRI markers and cognitive scores) were estimated from the data in this study and the trained model. These final outputs were applied as input features and input into the SVM for the prediction task. The performance of longitudinal prediction when no values were missing is as follows: accuracy (0.756 ± 0.039), sensitivity (0.763 ± 0.046), specificity (0.819 ± 0.055), and AUC (0.814 ± 0.035). The results are higher than two cases, i.e., comparing the diagnostic outcomes for first-time visiting patients and the predictive resu
留言 (0)