
記住我

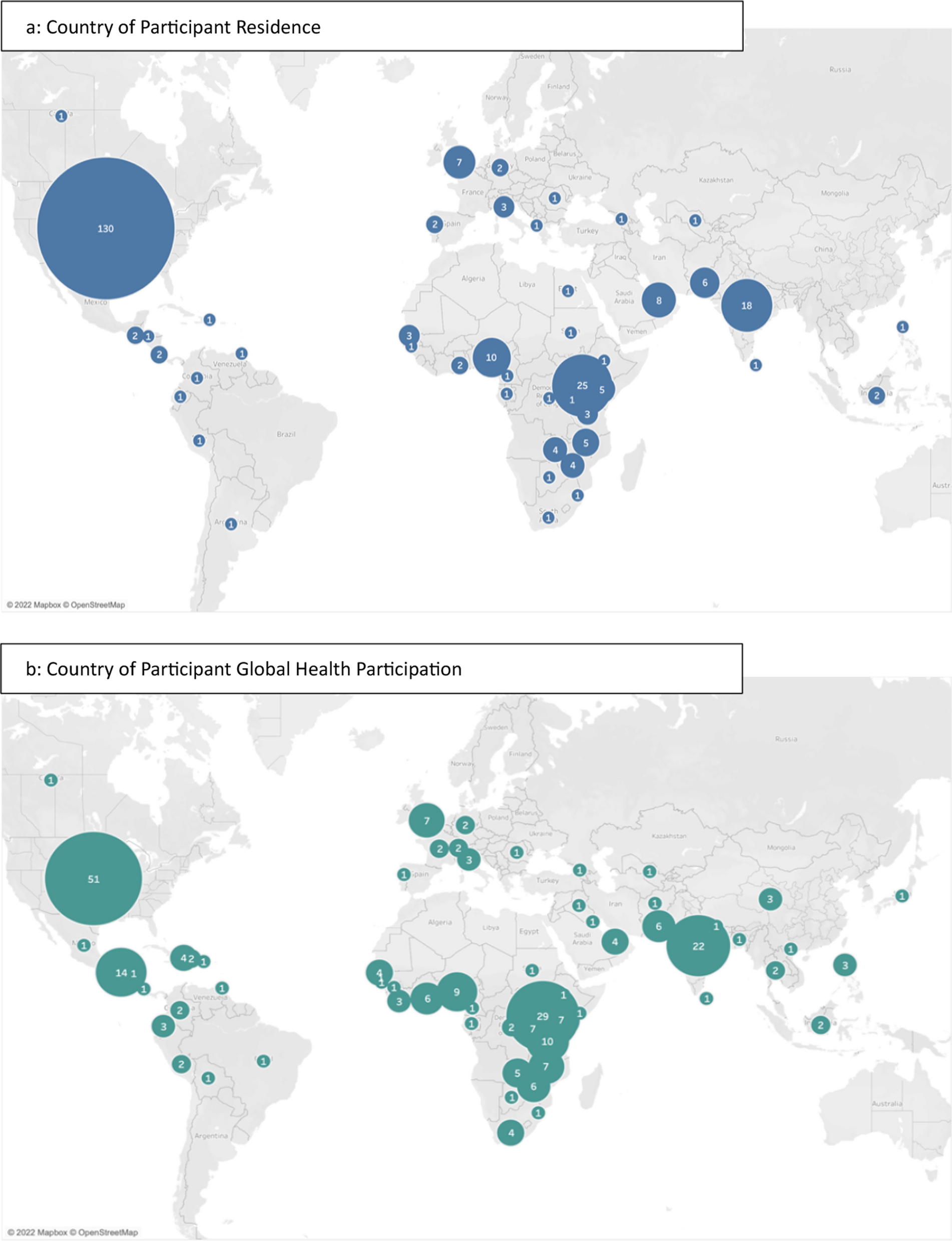
The CHARISMA model used ADL and IADL functional statuses of the late middle-aged and older Chinese population as the outcomes. The present study deferred to the China Health and Retirement Longitudinal Study (CHARLS) questionnaire that defined ADL based on the six activities: dressing, bathing and showering, eating, getting in and out of bed, using the toilet, and controlling urination and defecation [21]. Also, IADL was defined based on the five activities of managing money, taking medications, shopping, preparing meals, and cleaning house. Although the cohort study from which our data was sourced (CHARLS) asked about a sixth IADL activity of making phone calls, this question was not asked in the baseline survey [22]. Therefore, the present study did not include the sixth IADL item. Activity level was categorized into three states. Namely, the states were 1) no difficulty for any activity; 2) for at least one activity, the individual had some difficulty but could still do; and 3) for at least one activity, the individual needed help to do or could not do. Category 2 indicated some activity impairment whereas category 3 indicated disability [21]. By the end of the simulation, the percentages of people aged 50 years and over in each year through 2048 in each category were summarized for ADL and IADL, respectively. In addition to the rates of people with functional loss, the corresponding population size was also estimated by scaling up the sample size of the cohort. In what follows, people in category 2 are referred to as some ADL (IADL) difficulty population, and people in category 3 are referred to as ADL-dependent (IADL-dependent) population. For ADL, we also projected the percentage and size of the population with at least two disabilities, which indicated severe ADL disability [21, 23].
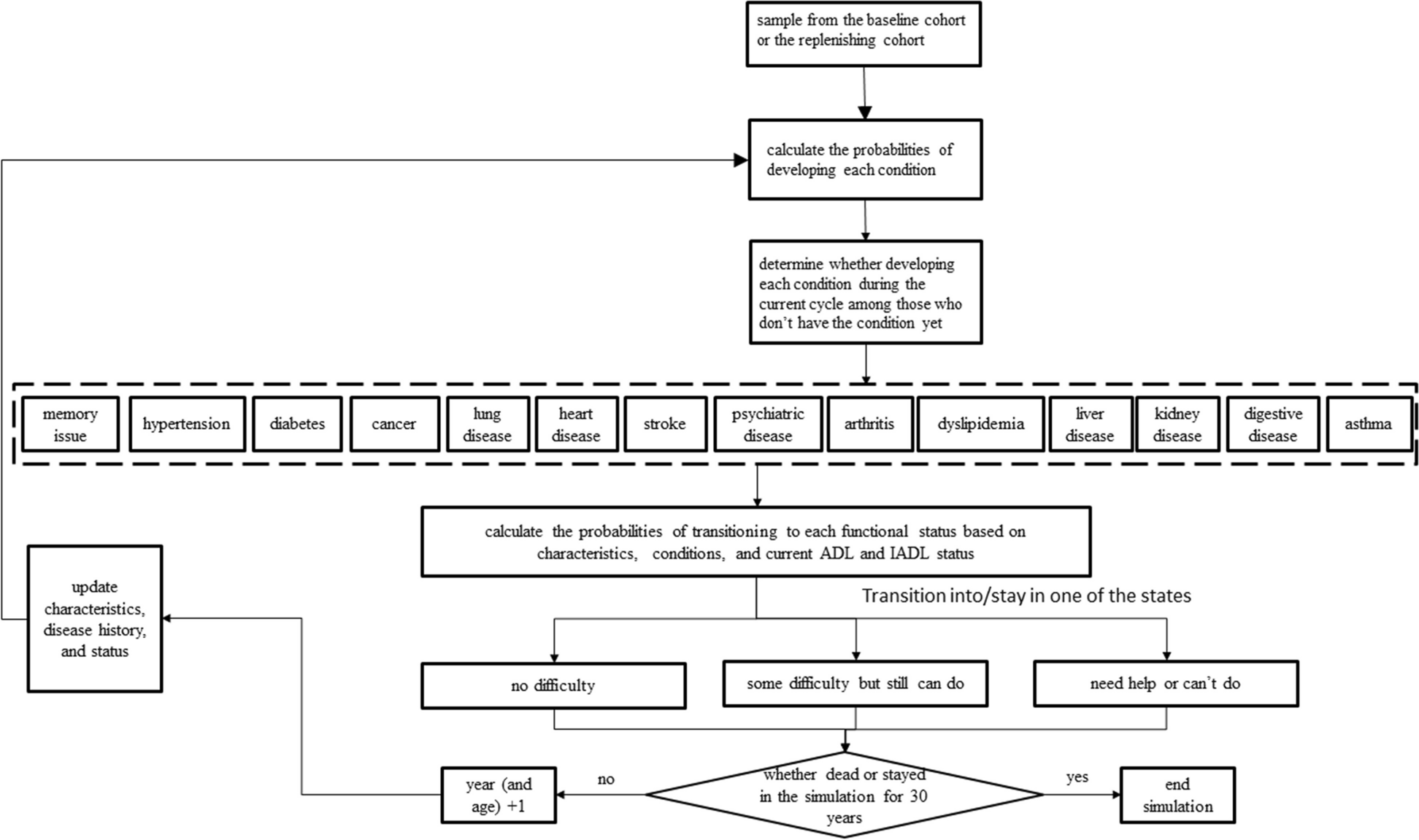
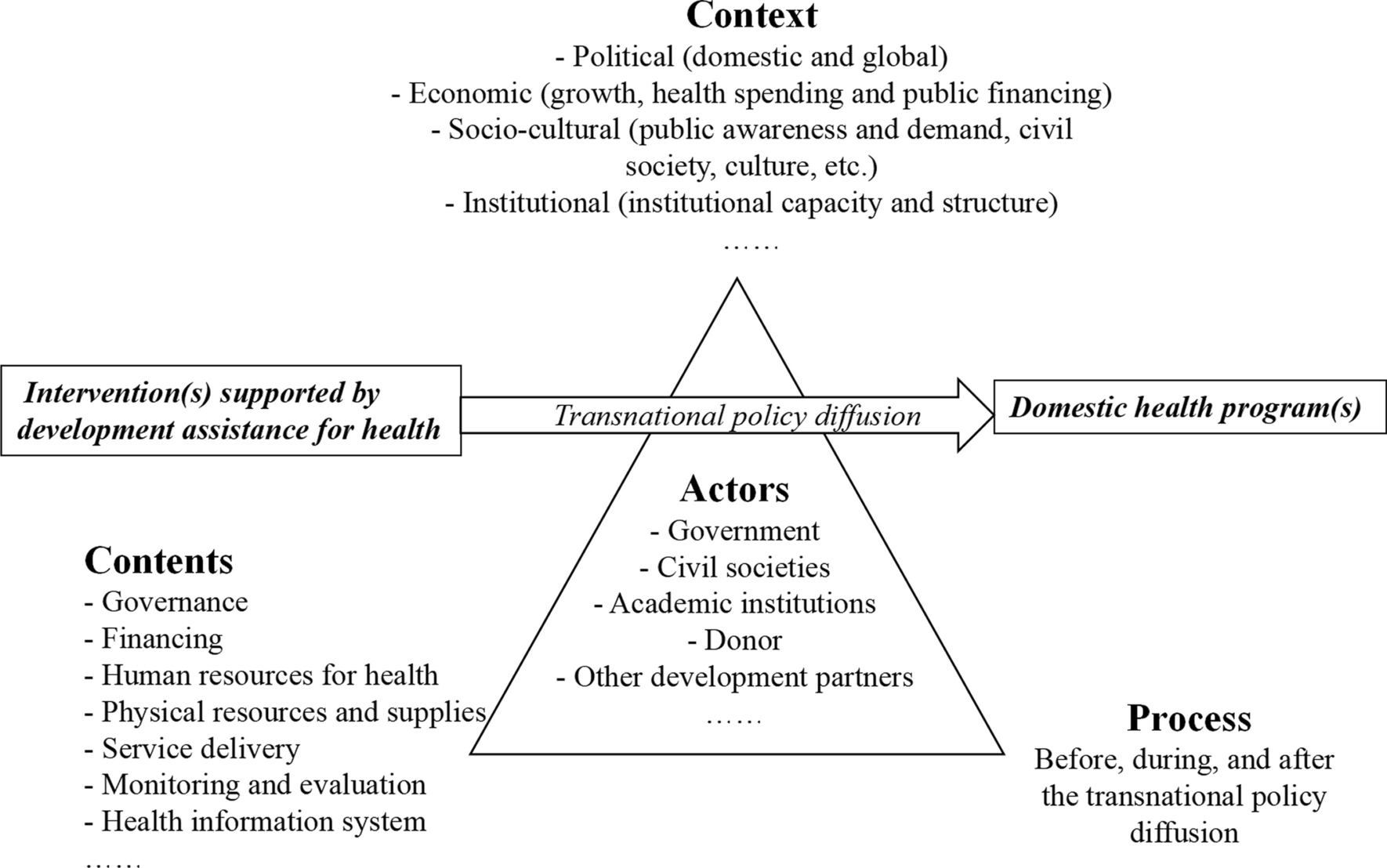
Model design and structureAt the baseline, the CHARISMA model was populated with a sample of over 10,000 individuals representing the population aged 50 years and older in China. For every person in the model, information on socio-demographic characteristics and prevalent health conditions was used as input. Specifically, such information was used to calculate the annual probabilities of developing 14 chronic diseases if the person did not have the conditions already. On top of the simulated medical event history, the probabilities of transitioning into each of the three ADL states were calculated. The probability calculation of transitioning into each of the three IADL states followed the same approach. Against each created probability, a random variable between 0 and 1 was drawn from a uniform distribution and compared. If the random variable was greater than the probability, the development of the corresponding condition was assigned to the individual starting from the current cycle. Consistent with the nature of chronic diseases, the simulated conditions were irreversible for the rest of the life once developed [24]. The simulated status quo of health conditions was used jointly with demographic information to predict further the ordinal probabilities of ADL and IADL categories in the current cycle. The random variable technique was then used again to determine the transitioning of ADL and IADL states. Unlike chronic conditions, ADL and IADL states were not absorbing states such that individuals could move into and out of the states at each cycle. The physical conditions up to and the functional status in the current cycle subsequently entered the risk equations for the next cycle, thereby rendering a dynamic modeling process. Individuals were looped through cycles until either becoming deceased or reaching the year 2048. The structure of the model is depicted in Fig. 1. A diagram of the modeling process is shown in Fig. 2. The model was programmed using Python 3.9 and the analysis of output data was conducted using Stata 15 (StataCorp LLC, College Station, Texas, the US).
Fig. 1
The structure of the dynamic microsimulation model
Fig. 2
The process of simulating the baseline and replenishing cohorts
Data sourcesIndividual characteristics of the simulated population and event risk equations were necessary inputs to the model. The current study primarily drew upon four waves of data from CHARLS [22]. CHARLS is a nationally representative aging survey of Chinese aged 45 years and older [22, 25, 26]. The spouses of the eligible participants were also surveyed regardless of age. The nationwide survey started in 2011, after which three follow-up surveys have already been conducted in 2013, 2015, and 2018. Data from the wave of 2018 were released in late 2020. While allowing previously non-participating family members to join follow-up surveys, CHARLS did not replenish household samples. We extracted information on age, sex, marriage status, body mass index (BMI), education, smoking, and drinking from the four waves of CHARLS data. In addition, CHARLS asked about whether the respondent has been diagnosed with fourteen types of conditions, including memory issues, hypertension, diabetes, cancer, lung disease, heart disease, stroke, psychiatric disease, arthritis, dyslipidemia, liver disease, kidney disease, digestive disease, and asthma, the information on which was also used for our analysis. We used Stata 15 (Stata Corporation, College Station, Texas, the United States) for data analysis.
Event probability estimationData from the 2011-2015 waves of CHARLS were used to estimate regression equations of event risks. The reasons for using the initial three waves for probability estimation were twofold. First, it allowed extrapolation validation using 2018 observations. Second, the time step between the 2015 and 2018 waves was three years, whereas the time step was two years for the 2011-2015 waves. When estimating the event risks of the 14 chronic diseases, sociodemographic characteristics, conditions in the previous wave, and functional status in the last wave were used as predictors, all of which were relatively common predictors in microsimulation studies on population aging [8, 9, 13]. In our analysis, sociodemographic characteristics included age, sex, marriage status, BMI, education, smoking, and drinking. Age was defined as linear splines with knots at 45, 60, and 75. Similarly, BMI was defined using linear splines with a knot at 24. Also, sex was indicated using a dummy variable of male while education was grouped into below-high school, high school, and above high school. More, an indicator of whether drinking at least once a day or more often was created. Among these variables, only BMI was considered time-varying. To allow the aging effect on BMI, we regressed the latter on the linear splines of age, the indicator of sex, and the lag value of BMI. Stepwise logistic regressions with backward selection using a significance level of 0.1 for variable removal were conducted to identify the model specification for each disease’s prediction. Each logistic regression equation predicted a two-year event probability, the latter of which was then transformed into an annual probability using the declining exponential approximation of life expectancy method [27]. By contrast, ordinal logit models were used to regress ADL and IADL categories using sociodemographic characteristics, the lag values of ADL and IADL categories, and current conditions as regressors. The predicted probabilities of falling into the ordinal ADL and IADL categories were used for simulation without transformation.
CHARLS only followed up on death in 2013. Accordingly, we only relied on 2011 regressors and mortality information between 2011 and 2013 to develop the risk equation of death, the implementation of which followed that of chronic conditions.
Baseline populationTo assemble a cohort whose trajectories were to be simulated from 2018, we only sampled individuals from the 2018 wave for the baseline cohort of the CHARISMA model. To that end, we created a cohort of 13,194 people aged 50 years and older in 2018, such that each person in our sample represented 33,334 people on average if scaled up to the entire population 50 years and older in China. Further increases in the sample size might result in too many replications of the same individuals in our data source. Decreasing the sample size might result in a lack of heterogeneity and representativeness. We split the observations in 2018 with non-missing values of all required variables into age-by-sex grids, each with a pre-specified sample size based on the population pyramid [28]. Each grid was then populated by resampling from the observations in the corresponding age-sex grid of CHARLS data.
Replenishing cohortsTo the extent that the model aimed to project the functional status of future late middle-aged and older people over a span of 30 years, it was necessary to account for the health of those newly becoming 50 years old. Therefore, a replenishing cohort of 50 years older people was introduced to the model each year. The size of the replenishing cohort was determined based on predictions of the population pyramid by age and sex in each year [28]. Since CHARLS included people aged 45 years and older, the replenishing cohorts during 2019-2023 could be sampled from those aged 45-49 years in 2018 and simulated along with the baseline cohort. However, the number of people aged 44 years and younger was limited in CHARLS and represented the spouses of the main population of interest. As such, the samples aged 44-46 years old in 2018 were re-used to create the replenishing cohort of 45 years old for each subsequent year. The sampling was not limited to those 45 years old but expanded to a 3-year bin because the sample size of people who were exactly 45 years old was relatively small. Taking 2019 as an example, a 45-year-old replenishing cohort using 2018 samples who were 44-46 years old was created based on the corresponding population size in 2019 and simulated onward, then formally became part of the simulation population in 2024 after turning 50 years old.
Subgroup analysesTo gain insights into the future functional status of underserved populations, we also conducted subgroup analyses by sex, education level (with and without high school education), and residence area (urban and rural residents). In addition to the socioeconomic factors, we also projected the prevalence rates of ADL- and IADL-dependence for the subgroups younger than 60 years and at least 60 years old, respectively.
Validation and sensitivity analysisValidation is a critical step in the process of model-based simulation analysis, serving to ensure the accuracy and reliability of the model's results [29]. It involves comparing the model's predictions with observation [29]. This comparison helps to confirm that the model is functioning as expected and producing results that reflect the phenomena it is designed to simulate [29, 30]. The process of validation is typically conducted using a variety of techniques, such as regression and visualization [30]. To validate the CHARISMA model, we created another cohort using 2011 as the baseline, the process of which followed that of the 2018 cohort. The 2011 cohort was replenished and simulated onward until 2018. The equations and simulation methods remained the same as the main analysis otherwise. To conduct internal validation, we used a linear regression model to compare simulated 2013 and 2015 prevalence rates of all chronic conditions and functional status with the corresponding rates from actual CHARLS observations. R2 was used to quantify internal validity. An extrapolation validation was also performed, in which the simulated and observed 2018 prevalence rates of all chronic conditions and functional status were compared. The concordance between the simulated and observed outcomes for the year 2018 provides evidence to support the validity of the model, given that neither the generation of the 2011 cohort nor the formulation of the risk equations relied on 2018 data. Lacking universally agreed cutoffs of good validity, R2 values >0.9 were considered good fits [31, 32].
In order to address the uncertainty associated with the parameter estimates of our risk prediction equations, a probabilistic sensitivity analysis (PSA) was conducted. This technique involves the simultaneous resampling of all parameters from their respective distributions in each repetition [33]. For our study, we conducted 1,000 repetitions by resampling the parameters from the regression results distributions.
留言 (0)