
記住我









Robotics has significantly improved industrial productivity in a wide range of tasks. However, the reliance on task-specific fixtures and expert-driven programming limits the broader application of robotic assembly in settings characterized by small-batch, flexible manufacturing processes (Lee et al., 2021). These settings often present semi-structured conditions where components destined for tight-tolerance assembly are randomly oriented within a confined workspace. Such variability complicates the assembly process, demanding sophisticated manipulation skills for precise alignment and force control to ensure successful component integration.
While both model-based and learning-based methodologies have been developed to address these complexities (Suárez-Ruiz and Pham, 2016; Luo et al., 2021; Mandlekar et al., 2023), they often require prior object-specific knowledge or expensive interaction data, limiting their effectiveness and efficiency in skill acquisition. A promising way to overcome these limitations is a hybrid approach that combines the strengths of model-based and learning-based strategies, paving the way for the efficient mastery of novel tasks without necessitating robotic expertise. Recent advancements in Residual Reinforcement Learning (Residual RL) epitomize such hybrid methodologies (Johannink et al., 2019). However, challenges remain, particularly in learning full-state estimation and managing large exploration spaces for long-horizon tasks involving variable target positions and precision assembly (Carvalho et al., 2022; Wang et al., 2022).
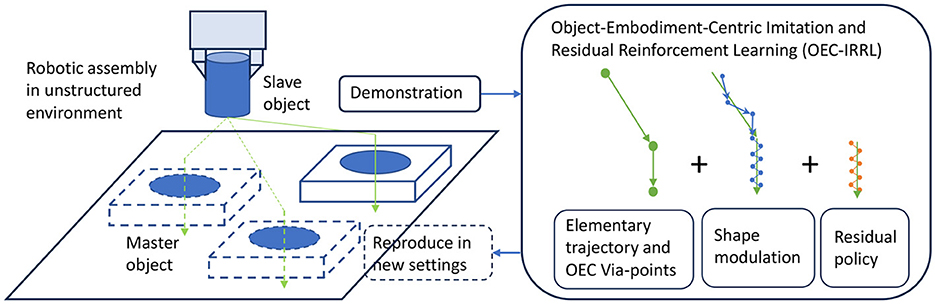
This study aims to bridge the gap in fixture-less robotic assembly by leveraging partial knowledge of transitions to streamline robot learning (Mandlekar et al., 2023). This approach simplifies learning by segmenting it into geometry structure estimation, trajectory planning, and uncertainty handling (refer to Figure 1). It is crucial to recognize that manipulation depends on the geometric constraints of the task, the grasp pose of the slave object, and the master object's location (Li et al., 2023). Assuming the known master object's location, we can represent the motion trajectory and assembly relationship with a low-dimensional framework, facilitating skill adaptation across various poses. With the geometry structure determined, learning can concentrate on robot and task dynamics, emphasizing smooth trajectories and interaction behaviors (Shi et al., 2023). While the initial transfer phase requires only smooth trajectories, the critical assembly phase demands precise localization and intricate contact dynamics. Focused learning allows for a balanced ratio of exploitation to exploration, enhancing sample efficiency. However, integrating object-embodiment-centric partial knowledge, which simplifies the task into subtasks by encoding relevant geometric information, presents challenges: (1) extracting and representing this knowledge without robot experts, (2) incorporating it into imitation learning for efficient adaptation, and (3) balancing sub-policies for effective residual learning.
Figure 1. OEC-IRRL overview. We introduce an efficient and effective hybrid learning system that can perform precise assembly tasks in a semi-structured environment from a single human demonstration and less than 1.2 h of interactions.
This study introduces the Object-Embodiment-Centric (OEC) task representation in an Imitation Learning (IL) and Residual RL framework, OEC-IRRL, which is designed for contact-rich tasks at variable locations. This framework eliminates the need for specific fixtures and extensive expert programming and enhances sample efficiency by seamlessly integrating IL and RL with partial knowledge. Our contributions are as follows: (1) Innovative Extraction of Temporal and Spatial Task Information: OEC-IRRL employs a via-point-based task representation to outline temporal and spatial segments of the task, enabling the learning of adaptive operations from a single demonstration and acceptable interactions. We extract via-points from the demonstrated trajectory based on velocity, dividing the task into transfer and assembly phases. The OEC task representation includes the start via-point in the robot base frame, as well as the middle and end via-points in the master object frame, offering essential geometry information without extensive robot calibration or task-specific knowledge. This is particularly useful in dynamic environments where the master object's pose is estimated by a vision model. (2) Guided Hybrid IL and Residual RL for Enhanced Learning Efficiency: This novel approach uses the OEC representation to guide efficient learning through VMP and limits the exploration range of residual RL. Improved VMPs learn the motion trajectory from demonstrations and via-points, where the basic trajectory encodes via-point geometry and shape modulation dictates the trajectory distribution for smooth exploration. This strategy allows for adaptation to various settings while keeping the trajectory profile consistent during assembly. Moreover, residual RL is selectively applied in the assembly phase for precise localization and contact dynamics, minimizing exploration space for efficient learning and reusing policies across locations under the base policy's guidance. The exploration behavior learned from human demonstrations notably increases success rates. (3) Experiment Validation of OEC Task Representation and Framework: Through extensive testing, we have shown that OEC task representations can be effectively derived from a single demonstration, greatly enhancing the sample efficiency of VMP-based IL and multimodal residual RL in extended tasks. Our experiments confirm the learned strategies' applicability to various fixtureless assembly tasks across different locations, significantly advancing robotic assembly.
2 Related workDeep reinforcement learning (DRL) techniques have become increasingly popular for contact-rich activities due to their potential to provide an alternative to the complicated and computationally expensive process of modeling intricate environments. Despite its potential, the application of DRL to complex manipulation tasks has been hampered by issues related to sample efficiency and safety. To mitigate these challenges, previous task-specific knowledge has been exploited, including bootstrapping from demonstrations through a specific teleoperation system in the study by Nair et al. (2018), utilizing high-performance simulators for sim2real in the study by Amaya and Von Arnim (2023), and exploiting knowledge of similar tasks by pre-training on the task family in the study by Hao et al. (2022). Although these strategies have shown the potential to improve sample efficiency and ensure safer DRL applications, extracting and using prior knowledge requires a lot of engineering effort. Therefore, this section discusses methods that extend RL to perform accurate assembly tasks in semi-structured environments via a base policy, which is accessible in manufacturing.
2.1 Model-based base policyResidual RL was originally proposed to integrate conventional controllers with DRL to solve complex manipulation tasks. RL is utilized to handle the unknown aspects of the task, while a hand-designed controller manages the known elements in the study by Silver et al. (2018); Johannink et al. (2019). This integration simplifies controller design and improves sample efficiency. Different controllers and integration techniques have been examined in the current literature. Schoettler et al. (2020) applied Residual RL in real-world industrial tasks using a hand-designed P-controller as the base policy. In contrast, Beltran-Hernandez et al. (2020) concentrated on learning force control for position-controlled robots using a state-based controller gain policy. Additionally, Ranjbar et al. (2021) proposed a hybrid residual RL approach and aimed at modifying both the feedback signals and the output via the RL policy to prevent the low-level controller's internal feedback signals from restricting the RL agent's capacity to optimize its policy, thus hindering learning.
Visual servoing and motion planning have played a crucial role in guiding DRL methods in unstructured environments. Shi et al. (2021a) have introduced a visual RL method that unites a fixed visual-based policy and a parametric contact-based policy, guaranteeing a high success rate in the task and the capacity to adapt to environmental changes. Meanwhile, Lee et al. (2020) quantify uncertainty in pose estimation to determine a binary switching strategy using model-based or RL policies. Additionally, Yamada et al. (2023) implemented an object-centric generative model to identify goals for motion planning and a skill transition network to facilitate the movement of the end-effector from its terminal state in motion planning to viable starting states of a sample-efficient RL policy. However, these methods require the model of the object, in particular, the manual specification of a goal state in the robot's frame and control policy design (Yamada et al., 2023). Additionally, they face difficulties in providing comprehensive guidance in both free space and contact-rich regions due to the limited motion planning in tasks that require environmental interaction and the scarcity of visual servoing in addressing geometric constraints.
2.2 Imitation learning-based base policyLeveraging prior knowledge in the form of demonstrations can extend the application of residual RL to scenarios where accurate state estimation and first-principle physical modeling are not feasible (Zhou et al., 2019; Wang et al., 2023). Mathematical model-based movement primitive (MP) with compact representation is a promising method for learning controllers that can solve the non-linear trajectories from a few human demonstrations. For instance, Ma et al. (2020) recently presented a two-phase policy learning process that employs a Gaussian mixture model (GMM) as a base policy to accelerate RL. Davchev et al. (2022) introduced a framework for employing full pose residual learning directly in task space for Dynamic Movement Primitives (DMP) and demonstrated that residual RL outperforms RL-based learning of DMP parameters. Carvalho et al. (2022) investigated the use of variability in demonstration of Probabilistic Movement Primitives (ProMP) as a decision factor to diminish the exploration space for residual RL. They compared this method with a distance-based strategy. Neural networks are also used well for imitation learning methods in residual RL. Wang et al. (2022) have developed a hierarchical architecture for offline trajectory learning policies, which are complemented by a reinforcement learning-based force control scheme for optimal force control policies.
Visual imitation learning is essential to enable residual RL of difficult-to-specify actions under diverse environmental conditions. Alakuijala et al. (2021) suggest learning task-specific state features and control strategies from the robot's visual and proprioceptive inputs using behavioral cloning (BC) and convolutional neural network (CNN) on demonstrated trajectories for residual RL. The resulting policy can be trained solely using data, which is demonstrated for the base controller and with rollouts in the environment for the residual policy. However, achieving generalization through adaptable control strategies and state estimation from high-dimensional vision information requires a significant number of demonstrations. Additionally, to prevent unnecessary exploration in free space regions, the activation decision of the residual policy needs to be closer to the assembling phase and rely on trajectory distributions from numerous demonstrations or task-specific knowledge for geometric constraints.
In response to these challenges, this study proposes a novel OEC task representation within imitation learning (IL) and residual RL frameworks, which are tailored to enable the learning of adaptive operations from minimal demonstrations and interactions. This approach builds upon these foundations of the prior vision model from the model-based methods (Lee et al., 2020; Shi et al., 2021a; Yamada et al., 2023) and the mathematical model from the imitation learning-based methods (Carvalho et al., 2022; Davchev et al., 2022). Our approach distinguishes itself by: (1) streamlining robot programming through extracting via-points from demonstrated end-effector trajectories for task representation, thereby simplifying the reconfiguration costs and improving adaptability. (2) Integrating IL and Residual RL to effectively manage both free space and contact-rich regions, overcoming the limitations of previous approaches in terms of learning efficiency and effectiveness. In contrast to the study by Mandlekar et al. (2023), Zang et al. (2023) using the base policy for data augmentation, this study uses residual RL for further optimization on the base policy.
3 Problem statementIn this study, we formalize contact-rich assembly tasks in a semi-structured environment as a Markov Decision Process (MDP), M = (S, A, P, r, γ, H). For a system with the transition function P and reward function r, we want to determine a policy π, which is a probability distribution over actions a∈A conditioned on a given state s∈S, to maximize the expected return ∑t=0Hγtr in the rollout with a horizon of H.
The assumption employed in this study can be stated as having partial knowledge of the transition function P (Lee et al., 2020), including a two-stage operation process and a coarse estimation of the environmental state. The policy is typically formulated from a combination of sub-policies, which may depend on time and state as Equation (1) (Johannink et al., 2019; Davchev et al., 2022):
π(a|s,t)=α(s,t)πb(s,t)⊕β(s,t)πθ(a|s,t) (1)where πb is a base policy (offline learning or model-based), πθ is an online learning-based policy, and α and β are the adaptation parameters. The operation ⊕ depends on the integration method.
By leveraging a precomputed offline continuous base policy, πb, the task complexity for πθ is significantly reduced (Carvalho et al., 2022). Thereafter, the residual policy is tasked with learning how to deviate from the base policy to overcome model inaccuracies and potential environmental changes during execution. The final policy can mitigate system uncertainties and ensure contact safety through adaptation parameters. To optimize the objective derived from the sampled trajectories, a policy gradient method is implemented to update the πθ.
A key question in this context is how to obtain the πb and adaptation parameters to guide πθ. The proposed methodology entails directly acquiring them in task space from a demonstrated trajectory and a prior vision model, as described in the following section.
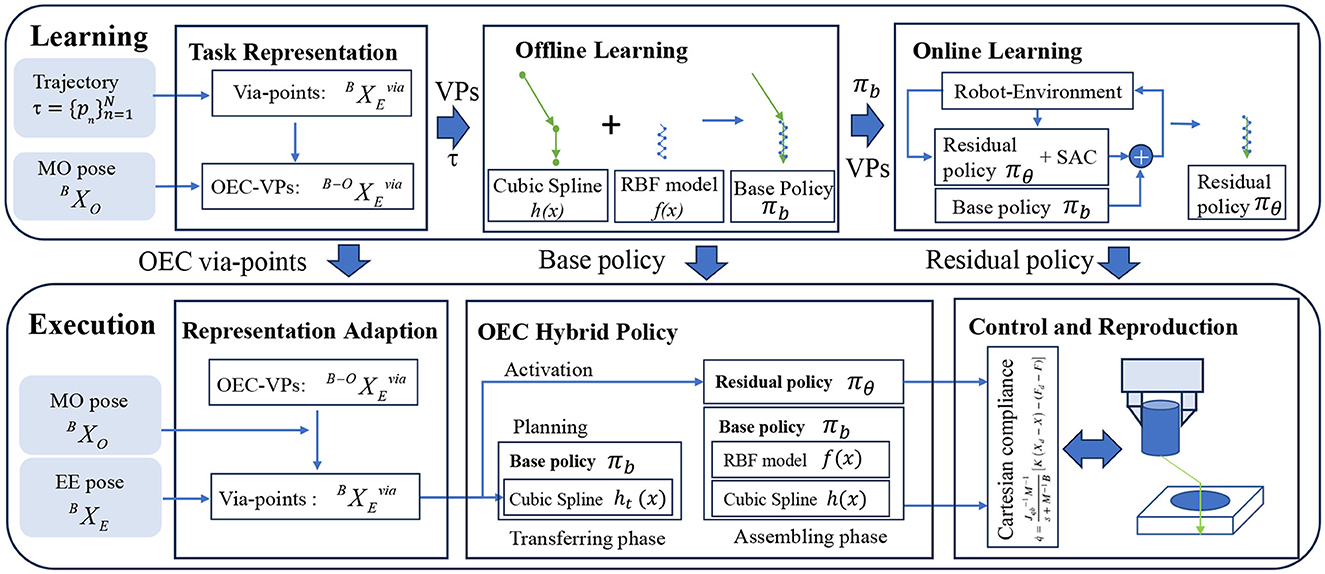
4 MethodThis study introduces an OEC-IRRL framework for precise assembly tasks without specific fixtures (see Figure 2 for an overview). It encompasses a coarse operation for long-horizon exploration and a fine operation for uncertainty compensation. The OEC-IRRL method begins by pre-processing the recorded data from a single demonstration trajectory of the end-effector τ=[Xn]n=1N and the master object pose BXO obtained from an eye-to-hand camera. This pre-processing step involves the generation of the OEC task representation, which enables efficient learning policies that adapt to new settings. Via-points (VPs) are extracted from the trajectory based on the velocity and then converted into OEC-VPs representing task robot-related temporal and spatial information (Section 4.1). Subsequently, a base policy (πb) based on piece-wise VMP is fitted using the VPs and trajectory to facilitate coarse movements, including transferring and assembling (Section 4.2). Leveraging πb and VPs, a multimodal residual policy (πθ) is learned through RL to enable precise localization and variable force control in contact-rich tasks (Section 4.3). Following the learning process, the obtained sub-policies (OEC-VPs, πb, and πθ) and the current state (including master object pose BXO and end-effector pose BXE) are utilized for skill execution. New VPs are obtained from OEC-VPs by representation adaptation. The πb, after shape modulation by VPs, guides the robot in both free space and contact-rich regions. The πθ is selectively activated by the VPs in contact-rich regions, working in conjunction with the parallel position/force controller to effectively reproduce the demonstrated skill (Section 4.4).
Figure 2. System overview. The first step is to extract structured information from the demonstration using the OEC task representation. Then, the OEC task representation is used to plan the elementary trajectory in the offline IL, with the dynamic behavior in the demonstration encoded by shape modulation. Finally, the residual policy is selectively activated by the OEC task representation to concentrate on the uncertainty during assembly. To adapt to different poses, the base trajectory is revised using an adaptive OEC task representation which directs invariant dynamic behavior and handles uncertainty, enabling the reproduction of assembly skills.
4.1 Task representationDemonstration-based programming has been proposed to handle variations in geometry with less engineering effort in robot calibration and task-specific reconfiguration (Shi et al., 2021b). The goal of this section is to extract and define an OEC task representation with a single demonstration and a prior vision model, which provides the task and robot-related information for efficient learning in long-horizon tasks and adaptability to variable positions in a semi-structured environment.
This study equips an eye-to-hand camera to provide a global view of the workspace, capturing a 2D image denoted Ieth. The relative pose of the master object in the robot's base frame BXO can be obtained from extrinsic and intrinsic camera parameters by hand-eye calibration and YOLO-based detectors fine-tuned to the domain. The YOLO algorithm is widely used to detect objects in the image or video streams (Mou et al., 2022). For each object in the image Ieth, the algorithm makes multiple predictions of bounding boxes that contain information concerning the object's position (x, y), size (w, h), confidence ccon, and category ccate, as shown in Equation (2). The algorithm selects the most effective predicted bounding box for the object based on a predefined confidence level.
[ccate,x,y,w,h,ccon]=YOLO(Ieth) (2)A perception system based on object detection generates a bounding box around the master object to obtain the location (x0, y0), and two additional bounding boxes are generated around the predefined feature structures to obtain the locations (x1, y1) and (x2, y2). Using the eye-to-hand transformation BTC, the estimated points (xi′,yi′) are converted to the robot frame, as shown in Equation (3). The partial pose information of the master object, including its orientation in Rx and Ry and translation in z dimensions zcon, is taken into account to determine the pose BXO, as shown in Equation (4). The calculated position is accompanied by an error Er.
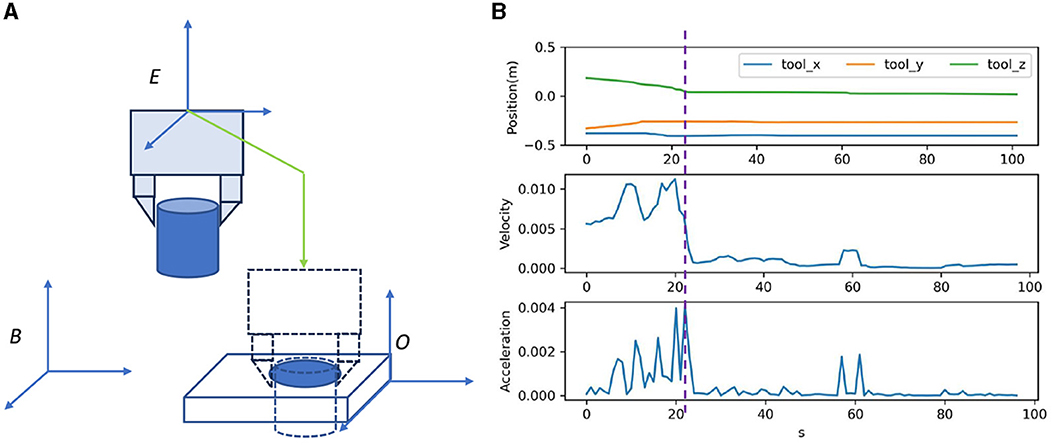
(xi′,yi′)=BTC(xi,yi),i=0,1,2 (3) BXO=[x0′,y0′,zcon,0,0,arctan(y2′−y1′x2′−x1′)]+Er (4)The demonstration is performed by a tele-operation system, which first moves the slave object to the master object and then assembles them, as shown in Figure 3. In the demonstration, BXO0 observed at the start and the trajectory of the end-effect BXEi at each step Ti is recorded τ=[(Ti,BXEi,BXO0)]n=1N.
Figure 3. OEC task representation. The trajectory is demonstrated as shown in (A) and analyzed as shown in (B) for OEC task representation.
To reduce the exploration horizon, this study analyzes the assembly process and extracts the bottleneck pose for task segments. Although various techniques, such as dynamic programming algorithm (Shi et al., 2023) or stochastic-based method (Lee et al., 2019), have been used for automatic waypoint extraction, this study uses a simpler method of velocity-based motion mode switch detection (VMMSD), which is motivated by the instinctive switching between fast arrival and safe fine-grained operation behavior modes, as shown in Figure 3. First, we define P as the 3-d translation of BXE for the bottleneck position estimation. Second, we estimate the nominal velocity v=[(Ti,vi)]n=1N and smooth it using a moving average, as shown in Equation (5). The pose with the highest velocity change serves as the bottleneck poses BXEm, as shown in Equation (6), which divides the skill into transferring in the free space and assembling in the contact-rich region.
v^=convolve(v,w),vi=Pi-Pi-1Ti-Ti-1 (5) m=argmax(a),ai=v^i-v^i-1Ti-Ti-1 (6)where w is the moving average window, a is the nominal acceleration, and m is the bottleneck position index.
For temporal and spatial adaptation, we have established an OEC task representation for learning. We first define the via-points BXEvia to represent structured information. Together with the extracted bottleneck pose BXEm, the start pose BXEs and the goal pose BXEg are specified as the first and last poses of the trajectory, as shown in Equation (7). A canonical variable t serves as a virtual timer, linearly increasing from 0 to 1 in this study. We then transform the bottleneck and goal pose in via-points from the robot base frame into the task frame using the master object pose estimated by the object detection model, as shown in Equation (8). This allows the task robot-related information to be scaled to scenes with different robot and master object poses.
BXEvia=[(0,BXEs),(tm,BXEm),(1,BXEg)],tm=mH (7) B−OXEvia=[BXEs,OXEm,OXEg]=[BXEs,(BXO)−1(BXEm,BXEg)] (8) 4.2 Offline learningIn semi-structured environments, a concise trajectory representation is required to encode geometry constraints and motion dynamics related to the task and robot while being adaptable to various target positions. Therefore, this section presents OEC piece-wise VMP and demonstrates the importance of the bottleneck pose in via-points.
Motion primitives are commonly employed to model movements in few-shot imitation learning. In this study, VMP is used due to the enhanced capability of via-point modulation compared with DMP and ProMP (Zhou et al., 2019). The VMP method combines a linear elementary trajectory h(t) with a non-linear shape modulation f(t), as shown in Equation (9).
y(t)=h(t)+f(t) (9)where t is the canonical variable increasing linearly from 0 to 1, and y is the generated current pose.
It is assumed that the elementary trajectory h(t) serves as the fundamental framework alongside the extracted via-points. The cubic spline is a commonly used interpolation technique which ensures that the position and velocity curves remain continuous, which is equivalent to the goal-directed damped spring system of DMP. The elementary trajectory can be obtained as Equation (10).
h(t)=∑k=03aktk (10)The parameters ak results from the four constraints, as shown in Equation (11).
h(t0)=y0,h˙(t0)=y˙0,h(t1)=y1,h˙(t1)=y˙1 (11)where (t0, y0) and (t1, y1) are two adjacent via-points.
The shape modulation term f(t) encodes the dynamic behavior of the demonstrated trajectory. It is explained as a regression model consisting of Nk squared exponential kernels, as shown in Equation (12).
f(t)=Ψ(t)Tω,ψi=exp(-hi(t-ci)2),i∈[1,Nk] (12)where hi and ci are predefined constants. Similar to ProMP, VMP assumes that the weight parameter ω~N(μ, σ) follows a Gaussian distribution. The parameter ω can be learned via maximum likelihood estimation (MLE) from the trajectory between t0 and t1.
To handle intermediate via-point, we divide the trajectory into segments to create piece-wise VMP, as shown in Equation (13). In particular, we only use h(t) during the transfer phase, which leads the robot through free space and disregards the suboptimal curved trajectory.
y(t)={ht(t),t0=0,t1=tmt≤tmha(t)+fa(t),t0=tm,t1=1t>tm (13)This study implements via-point modulation to adapt to different positions by manipulating the elementary trajectory, h(t), using the OEC task representation.
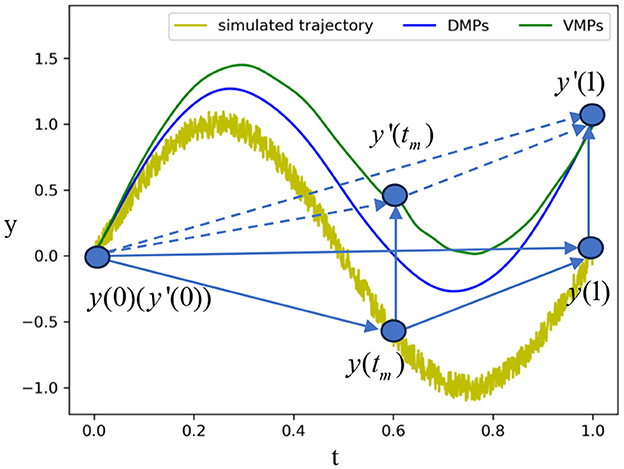
To investigate the effect of via-points on the reproduction results (Wang et al., 2022), we introduce a translation to the goal pose in the VMP formulation of a sine wave, as depicted in Figure 4. The yellow line represents a sine wave trajectory with Gaussian noise. We spatially scale the sine wave to match a new goal y′(1) using one-dimensional VMP. The blue curve represents the scaled trajectory using vanilla VMP (DMP), i.e., no mid-point is considered. With such a baseline, we then add a bottleneck pose to the VMP formulation and show the scaled trajectory as the green curve. The results indicate that the bottleneck pose can maintain the invariant trajectory of assembling in scaling. As the relative position of the start and goal points varies, the trajectory profile of the blue curve is changed, while the middle via-point maintains the unchanged part between itself and the goal.
Figure 4. Comparison of VMP and DMP in scaling to a new goal position. The yellow line is a simulated demonstration using a sine wave trajectory and Gaussian noise. The blue curve is the scaled trajectory using DMP without a middle via-point. The green curve is the scaled trajectory with the middle via-point.
4.3 Online learningThe residual policy is learned from interaction under exploration guidance to compensate for uncertainties in position and contact dynamics. Together with the OEC task representation, the learned VMP guides the RL in two ways, exploration range and distribution in the contact-rich region. Different from Jin et al. (2023), this study jointly trains vision-force fusion and policy by an error curriculum learning for robust residual policy in the insertion task.
Compliance enables a trade-off between tracking accuracy and safety requirements, especially active compliance is particularly useful in making system dynamics more easily adjustable (Schumacher et al., 2019). Based on the mass-spring-damper model, a basic parallel position/force controller is utilized as the low-level controller to integrate the two components of the assembly policy, thereby generating a velocity command. The absence of integral and differential terms ensures that both the force and trajectory strategies have equal importance, rat
留言 (0)