

記住我









Deep learning (LeCun et al., 2015) has achieved great success and has become a practical method in many applications, such as computer vision (Yu et al., 2022; Jiang et al., 2023), speech recognition (Afouras et al., 2018; Zhang et al., 2019), and natural language processing (Shen et al., 2018). However, it heavily relies on a large amount of labeled training data. When the available training data is drastically reduced, traditional deep learning methods are ineffective in training. In contrast, humans can quickly learn novel tasks (i.e., few-shot tasks) through a small amount of supervised information, because people can fully apply their past learning experience to novel tasks and then can quickly adapt and learn them. We hope that artificial intelligence models can quickly learn from novel tasks with few-shot data similar to humans. This fast learning is a challenge because the artificial intelligence models must combine their previous experience with a small amount of new information while avoiding over-fitting novel tasks (Finn et al., 2017). The process of human learning has sparked our interest in the research of few-shot learning (Wang et al., 2020; Lu et al., 2023; Song et al., 2023; Zeng and Xiao, 2024) and how to fully utilize past learning experiences to few-shot tasks.
Meta-learning (Vanschoren, 2018; Elsken et al., 2020; Li et al., 2021; Liu et al., 2022; He et al., 2023; Vettoruzzo et al., 2024) was put forward to solve the problem of few-shot learning. It empowers learning systems with the ability to acquire knowledge from multiple tasks, enabling faster adaptation and generalization to new tasks (Vettoruzzo et al., 2024). Specifically, it is to provide the model, especially the deep neural network, a learning ability that allows the model to learn some meta-knowledge automatically. Meta-knowledge refers to the knowledge that can be learned outside of the model training process, such as the initial parameters of the neural network, the structure and optimizer of the neural network, and the hyperparameter of the model. In few-shot learning, meta-learning specifically refers to learning meta-knowledge from a large number of prior tasks and using them to guide the model to learn faster in novel tasks.
The meta-learning method (Hospedales et al., 2021), based on optimization, is an important branch of few-shot learning. These algorithms attempt to obtain a better initial model or correct gradient descent direction through meta-learning. It optimizes initial parameters by the meta-learner so that the learner can converge faster in novel tasks and achieve fast adaptation and learning with few-shot data.
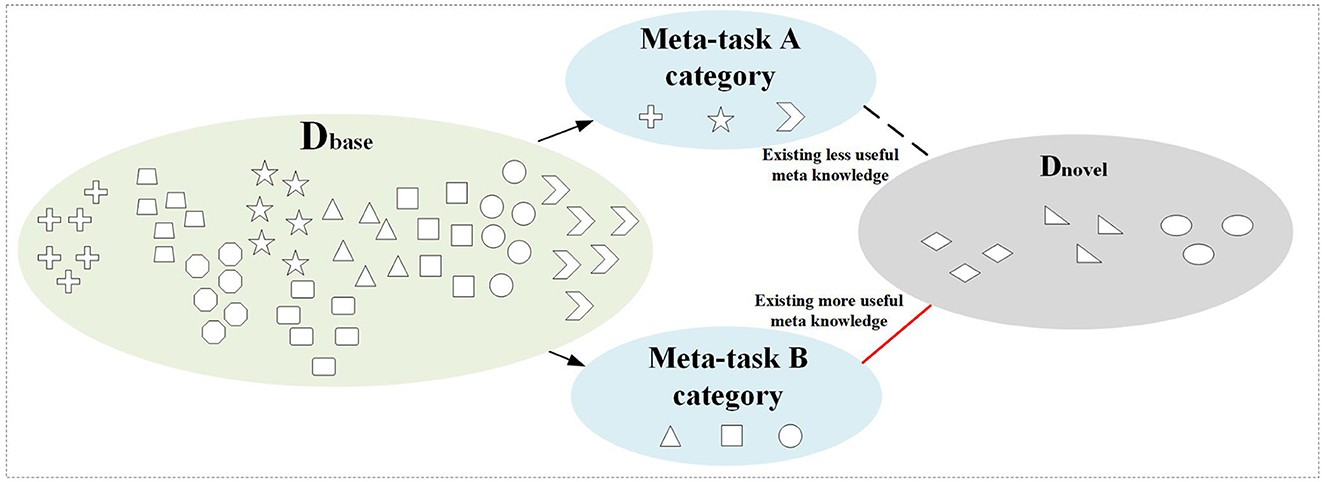
In few-shot learning, the pre-learned base class data before learning few-shot novel tasks is crucial for the generalization ability of the model. Selecting a good base class can often greatly improve the learning efficiency of novel tasks (Zhou et al., 2020). Figure 1 shows the randomly selected meta-tasks A and B from the base class data during the meta-training period. From the perspective of the sample category feature, meta-task B has more meta-knowledge related to the few-shot task. Therefore, it is crucial to select effective meta-knowledge from the base class for few-shot tasks, which can improve the efficiency and effect of few-shot learning.
Figure 1. The relationship between meta-tasks selected from base class dataset and few-shot dataset.
Based on the above motivation, this article argues that existing meta-learning methods do not take into account the relationship between base classes used for meta-learner learning and novel classes in few-shot tasks. During the meta-training period, this can lead to providing more irrelevant meta-knowledge for few-shot tasks, which will affect the efficiency and effect of few-shot learning in the meta-testing. Therefore, it is necessary to consider the feature relationships between base class data and few-shot data in the meta-training.
To improve this problem, first, we should select the most relevant set of candidate meta-tasks for novel tasks from the base class as much as possible to construct situational meta-tasks, which in turn provide optimal initial models for novel tasks. Then, the diversity of features among different meta-tasks can be used to promote better learning of novel tasks by multiple models.
In this article, we attempt to improve the problem of not considering relationships between base class data and few-shot novel class data by means of situational meta-task construction and multiple ensemble models. Starting from the feature relationship between base class data and few-shot data, we provide a new research idea for meta-learning. First of all, a universal feature extractor is trained in the basic learning phase to extract features of base class data and few-shot class data. Then, during the meta-training period, accurate meta-knowledge is provided for novel tasks by constructing situational meta-tasks. Furthermore, it provides good initial model parameters for novel tasks. Finally, during the meta-testing period, few-shot tasks are learned through the cooperation of multiple models. A large number of experiments on popular few-shot datasets demonstrate the effectiveness of the proposed method. Our main contributions are summarized as follows:
• This article puts forward a construction method of situational meta-task. It uses the class centroid of base class data to select the candidate meta-task sets with the stronger correlation for few-shot tasks and then sets up situational meta-tasks similar to few-shot tasks. The situational meta-tasks are the same as the few-shot tasks in form and similar to them in terms of feature. This method provides accurate and available meta-knowledge for novel tasks, which is conducive to rapid adaptation and learning on few-shot tasks.
• An ensemble model method based on meta-optimization is proposed in this article. The meta-model of situational meta-task training during meta-training is used to cooperate to complete the learning of few-shot tasks. The cooperation of multiple models improves the predictive performance and stability of a single model in the full-phase meta-learning process.
• Moreover, we extensively validate the proposed method by applying it to popular few-shot character dataset and image recognition datasets and then implementing and training through CNNs, Vgg16, and ResNet50 networks. The results indicate that the construction method of situational meta-task provides effective and available meta-knowledge for few-shot novel tasks, and the method of ensemble multiple models outperform previous state-of-the-art baselines.
2 Related workThe core idea of the meta-learning method is to use the past prior knowledge to guide the model to learn novel tasks. Meta-learning, as a standard approach to solving the problem of few-shot learning, which attempts to learn (Li et al., 2017). The goal of meta-learning is to enable models, especially deep neural networks, to learn how to undertake novel tasks from few-shot data. Among them, the meta-learning method based on optimization is an important branch of few-shot learning.
2.1 Meta-learning based on optimizationThe idea of this kind of algorithm is to attempt to obtain a better initial model or correct gradient descent direction through meta-learning. Then, the initial parameters are optimized by the meta-learner. This enables the learner to converge faster in novel tasks and learn rapidly in the case of few-shot learning.
Finn et al. (2017) proposed a model agnostic meta-learning (MAML) method. First, the network is trained with the ability to extract universal features, and then further trained to adapt to novel tasks rapidly on this basis. This approach is considered model agnostic since it can be applied directly to any learning model trained by a gradient descent process.
Based on the idea of MAML, Li et al. (2017) put forward a meta-stochastic gradient descent method called meta-SGD based on LSTM. By meta-learning the initialization parameters, learning rate and updating direction, the trained model can be easily fine-tuned to adapt to novel tasks. This algorithm is significantly less difficult to train compared to LSTM. Compared with the MAML method, it improves the model capacity.
The reptile (Nichol et al., 2018) method was proposed by Nichol et.al., which updates fewer parameters at a time and saves a lot of time and memory costs. However, the algorithm cannot directly adapt to the fast learning performed by MAML.
Rajeswaran et al. (2019) proposed a meta-learning method of implicit gradient. In this method, a new loss function and a corresponding method for computing the gradient are designed, so that the gradient of the parameter can be obtained only by computing the result of the loss function without considering its specific optimization method.
The meta-learning method based on optimization is to find a better initialization model or gradient descent direction for few-shot data. However, existing methods learn directly on the base class dataset and rarely consider relationships between few-shot data and base class data. This will lead to the learning of irrelevant meta-knowledge on the base class, which is not conducive to few-shot learning. Therefore, this article first fully considers the feature relationships between base class data and few-shot data and uses it as prior knowledge to construct strongly relevant situational meta-tasks for meta-learners. Then, meta-learners use situational meta-tasks to carry out meta-learning based on optimization, thereby improving the effect of few-shot learning.
2.2 Ensemble learningTo overcome the problem of unreliable and unstable results from single model, ensemble learning aims to utilize the diversity among multiple models to improve the learning ability of multiple weak learners. It can produce a strong ensemble learner for better prediction performance (Ganaie et al., 2022).
Traditional ensemble learning methods include Bagging, Boosting, Stacking, decision tree-based, and random forest-based. The Bagging algorithm (Breiman, 1996) (such as bootstrap aggregation) is one of the earliest ensemble learning methods. Although it has a simple structure, it has excellent performance. The algorithm generates different training subsets by randomly changing the distribution of the training dataset, then trains individual learners with different training subsets, and finally integrates them as a whole.
The Boosting algorithm (Freund and Schapire, 1996) is an iteration method that transforms weak learners into a strong learner. It generates a strong learner that behaves almost perfectly by increasing the number of iterations. Stacking, also known as Stacked Generalization (Wolpert, 1992), refers to training a model that is used to integrate all individual learners. The model is trained with the output of these individual learners as input to obtain a final output.
Recently, the deep neural network has been integrated into the ensemble strategies. Deep neural decision forest (Kontschieder et al., 2015) is a learning method that combines convolutional neural networks (CNNs) and decision forest techniques. It introduces stochastic backpropagation of decision trees, which is then combined into a decision forest, resulting in a final model with better generalization performance. gcForest (Zhou and Feng, 2017) is a new method that combines the ensemble method with the deep neural network. Unlike the above method, it replaces the neurons with random forest models, using the output vector of each random forest as the input to the next layer.
3 MethodIn this section, first, we explain the relevant definitions and concepts proposed for meta-task construction and meta-model ensemble (Section 3.1). Then, the motivation and idea of our proposed method are generally introduced (Section 3.2). Finally, in order to improve the problem of feature correlation between few-shot and base class, the construction method of situational meta-task (CSMT) proposed in meta-training (Section 3.3) is introduced and the full-phase meta-learning process of multiple initial model cooperation (FMPMIMC) is described, which includes the basic learning phase and the meta-optimization phase (Section 3.4).
3.1 Problem definition and description 3.1.1 Basic class dataset and novel class dataset(few-shot dataset)The base class dataset is Dbase=, and the novel class dataset is Dnovel=, where Dbase∩Dnovel = ∅. Few-shot tasks Tnovel are randomly sampled from Dnovel. Each few-shot task includes support set and query set. The support set is S=, where S⊂Tnovel. The query set is Q=, where Q⊂Tnovel. Especially, S∩Q = ∅ and S⋃Q = Tnovel.
3.1.2 Situational meta-taskSituational meta-task is a collection of tasks that have the same form (N-way K-shot) and related features to few-shot tasks. It is constructed from the data in the base class and is used in the meta-training. From the perspective of feature, it has a strong correlation with few-shot tasks. In form, it is the same as Nway-Kshot for few-shot tasks. Suppose that the base class dataset is represented as Dbase = by category, and a 5way-1shot support set denotes S = . By using the situational meta-task construction method, the most relevant candidate meta-task set (such as the candidate meta-task set for few-shot x1 is Dx1meta_task=, where Dc, Dk, Dp, Dq, and Dm∈Dbase) is selected from the base class dataset for each category of few-shot dataset (taking few-shot x1 as an example), and then the situational meta-tasks are constructed by extracting a sample from each category of few-shot own related candidate meta-task set (such as Dx1meta_task,Dx2meta_task,Dx3meta_task,Dx4meta_task, and Dx5meta_task, where Dximeta_task⋂i≠jDxjmeta_task=∅).
3.1.3 Multiple initial modelsDuring the meta-training period, the set of different meta-models is trained using different situational meta-tasks, which can be described as M = . They are used as the basis for cooperative learning in the meta-testing.
3.1.4 Full-phase meta-learning processIt includes the basic learning phase and the meta-optimization phase. The basic learning phase provides a universal feature extractor for the meta-optimization phase, which is used for constructing situational meta-tasks. The meta-optimization phase includes meta-training and meta-testing. During the meta-training period, the multiple initial models are trained using situational meta-tasks. They are used to adapt and learn few-shot tasks cooperatively in the meta-testing period.
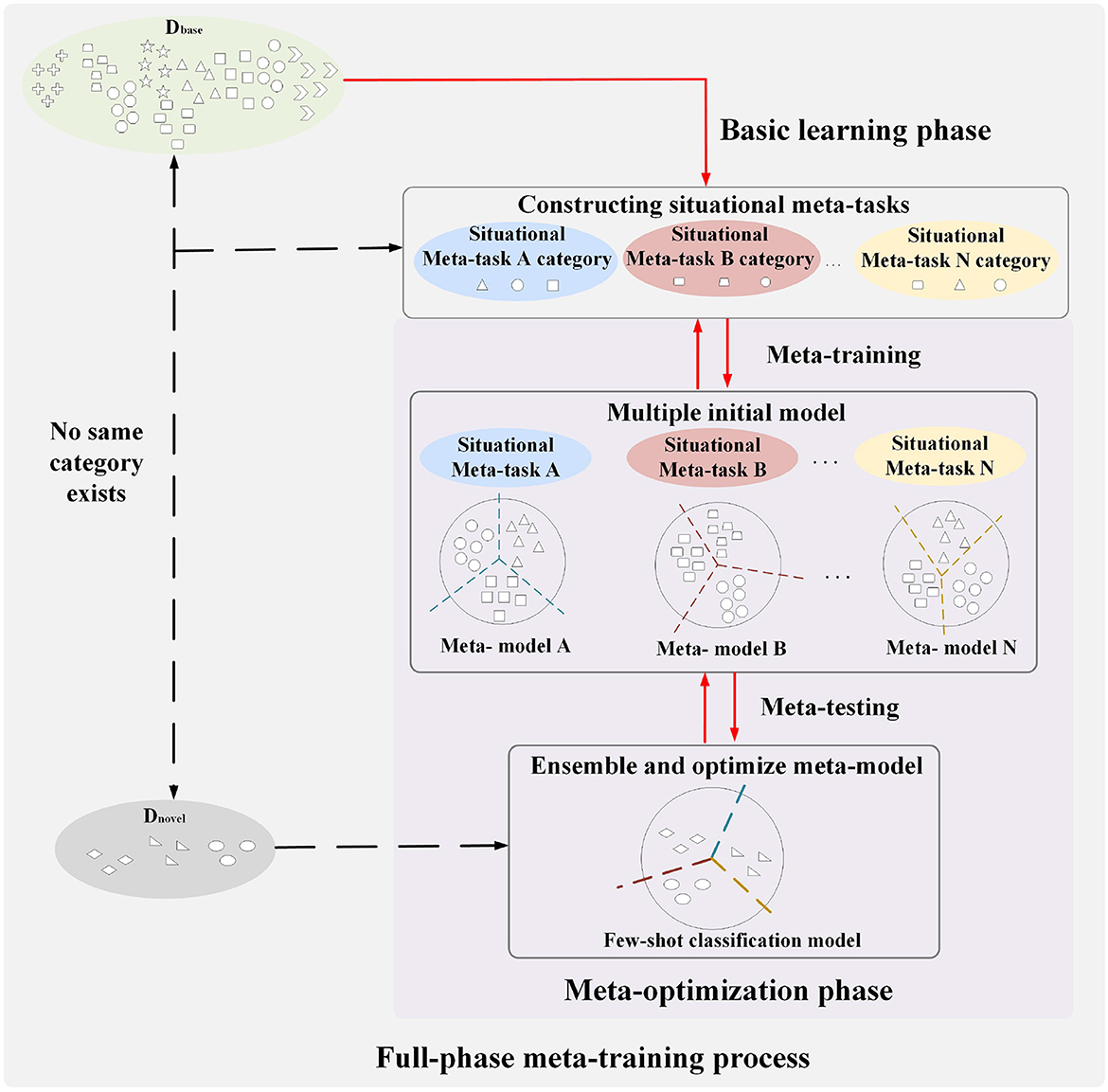
3.2 OverviewThe full-phase meta-learning method based on situational meta-task construction and multiple initial model cooperation is shown in Figure 2. It consists of the basic learning phase and the meta-optimization phase. The base class data and few-shot data do not have the same category, which means that few-shot data are novel tasks for models. The general idea of our proposed method is introduced below from the process of the full-phase meta-learning.
Figure 2. Schematic diagram of a full-phase meta-learning method based on construction of situational meta-task and cooperation with multiple initial models.
First, in the basic learning phase, a universal feature extractor is trained for constructing situational meta-tasks in the meta-optimization phase. The purpose of constructing situational meta-tasks is to provide more effective meta-knowledge for few-shot tasks, enabling the model to rapidly adapt to few-shot tasks. Then, situational meta-tasks are used to train multiple initial models in the meta-training of the meta-optimization phase. Finally, in the meta-testing of the meta-optimization phase, the few-shot dataset is used to optimize multiple initial models, promoting cooperation among models, and more fully utilizing meta-knowledge to learn few-shot classification model.
3.3 A construction method of situational meta-taskThe meta-learning methods based on optimization find better initial models or gradient descent directions for few-shot tasks through base class dataset. This allows models to adapt and learn quickly for few-shot tasks. However, existing methods directly learn on the base class dataset, rarely considering the feature relationships between few-shot data and base class data. This will result in learning more irrelevant meta-knowledge on the base class, which is not conducive to few-shot learning. Therefore, our research motivation is to provide relevant and effective meta-knowledge for few-shot tasks from the base class. Furthermore, it provides better initial model parameters for few-shot learning, which enables fast learning and adaptation on few-shot data.
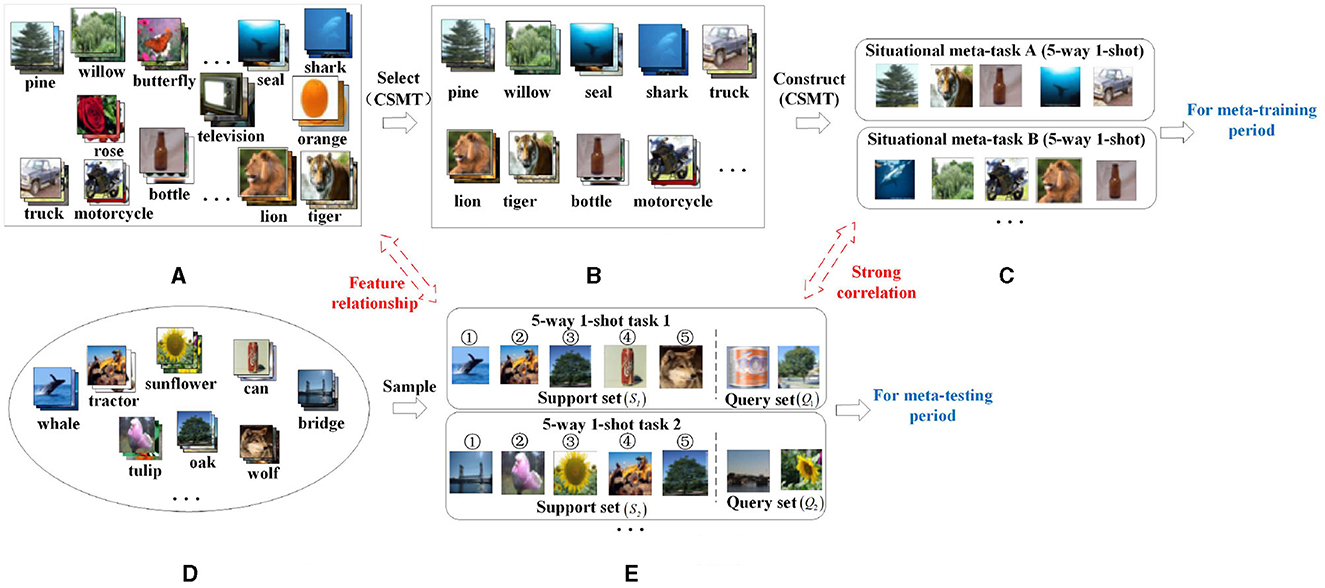
In order to solve the above problem, this article proposes a construction method of situational meta-task (CSMT), which is shown in Figure 3. The main idea of this method is to select the categories related to few-shot tasks from the base class dataset as candidate meta-task sets, and then use candidate meta-task sets to construct situational meta-tasks. Specifically, first, few-shot tasks Tnovel (Figure 3E) are randomly sampled from the few-shot dataset Dnovel (Figure 3D). Each few-shot task consists of a support set (S1, S2, ...) and a query set (Q1, Q2, ...). Then, the support set S1 (shown in the above Figure 3E) of 5-way 1-shot task 1 is used as an example to construct its situational meta-tasks. The relevant categories from the base class dataset Dbase (Figure 3A) is selected as a candidate meta-task set using the feature relationships between the centroid Cbasei of each category of the base class dataset and the centroid Cnovelj of each category of the support set S1. The relevant categories from the base class dataset are selected as the candidate meta-task set Meta_taskS1 (Figure 3B). Finally, the candidate meta-task set is used to construct some situational meta-tasks DS1meta_task (Figure 3C) for the 5-way 1-shot task 1. The situational meta-task A has the same form(5-way 1-shot) and related features to the support set S1 of the 5-way 1-shot task 1. The situational meta-tasks are used during meta-training and the few-shot tasks are used during meta-testing.
Figure 3. A schematic diagram of the situational meta-task construction process. (A) Base class dataset (Dbase). (B) Candidate meta-task set (Meta_taskS1). (C) Situational meta-task (DS1meta_task). (D) Few-shot database (Dnovel). (E) Few-shot task (Tnovel).
The construction process of situational meta-task is given as follows:
Step 1: Computing the central support point (centroid) of each class
The mean vector is computed for all feature vectors of each class in the base class dataset as the central support point Cbasei for that class. It can be represented as Equation (1):
Cbasei=1|Dbasei|∑(xbases,ybases)∈Dbaseifφ(xbases), (1)where Dbasei is the sample set of the ith class in the base class dataset and xbases is the feature vector that belongs to Dbasei. fφ(·) is an embedding function.
Similarly, when the form of the few-shot dataset is N-way K-shot, the mean vector of all feature vectors in each category in the few-shot data set is calculated as the central support point Cnovelj of the class. When the form of the few-shot dataset is N-way 1-shot, the central support point Cnovelj of each category is the sample feature. It can be represented as Equation (2):
Cnovelj=1|K|∑(xnovels,ynovels)∈Dnovelifφ(xnovels). (2)Step 2: Selecting few-shot candidate meta-task sets from the base class dataset
The feature distance (Disj_i) between the central support point Cnovelj of each category in the few-shot dataset and the central support point Cbasei of each category in the base class dataset are calculated, and the distance using cosine similarity is calculated. It can be represented as Equation (3):
Disj-i=cos(Cnovelj,Cbasei). (3)The calculated data are sorted in the descending order, and the top K class is selected as the candidate meta-task set for each few-shot class and is denoted as Meta_taskj. It can be represented as Equation (4):
Meta_taskj←sort(Disj_i ,K). (4)Step 3: Handling the conflict of candidate meta-task sets
When two or more candidate meta-task sets contain the same category in the base class (assuming that the candidate meta-task sets corresponding to classes p and q of the few-shot dataset both contain class m of the base class dataset), select the few-shot class with the minimum centroid error as the optimal construction method to ensure that different few-shot classes select different candidate meta-task sets. The centroid error is the sum of the distance between all samples of a certain class in the few-shot dataset and the centroid of that class in the base class dataset. It can be represented as Equation (5):
Lc=∑i=1xnoveli∈Dnovelpkfφ(xnoveli)-Cbasem. (5)Among them, Lc represents the centroid error between the samples Dnovelp of the class p in the few-shot dataset and the class m in the base class dataset. xnoveli represents the sample in the few-shot dataset Dnovelp and Cbasem is the centroid of the class m in the base class dataset.
Step 4: Constructing situational meta-tasks
The tasks from candidate meta-task sets for each class of few-shot data are extracted and combined into situational meta-tasks in the form of Nway-Kshot which is the same as few-shot tasks. They are the training dataset in the meta-training period.
The construction method of situational meta-task is shown in Algorithm 1.
Algorithm 1. The CSMT method.
Through the situational meta-task construction method, the training dataset related to the feature of few-shot is provided for the meta-model in the meta-training. First, for each few-shot class, strongly related candidate meta-task sets are selected from the base class dataset in order to better provide useful meta-knowledge for few-shot data. Then, the candidate meta-task sets are used to construct situational meta-tasks, whose form and features are more similar to few-shot tasks, which is beneficial for the model to adapt quickly and learn novel tasks.
In this subsection, different situational meta-tasks provide models containing different meta-knowledge for few-shot tasks. Overall, this process also makes full preparation for the efficient learning of few-shot tasks in the next subsection.
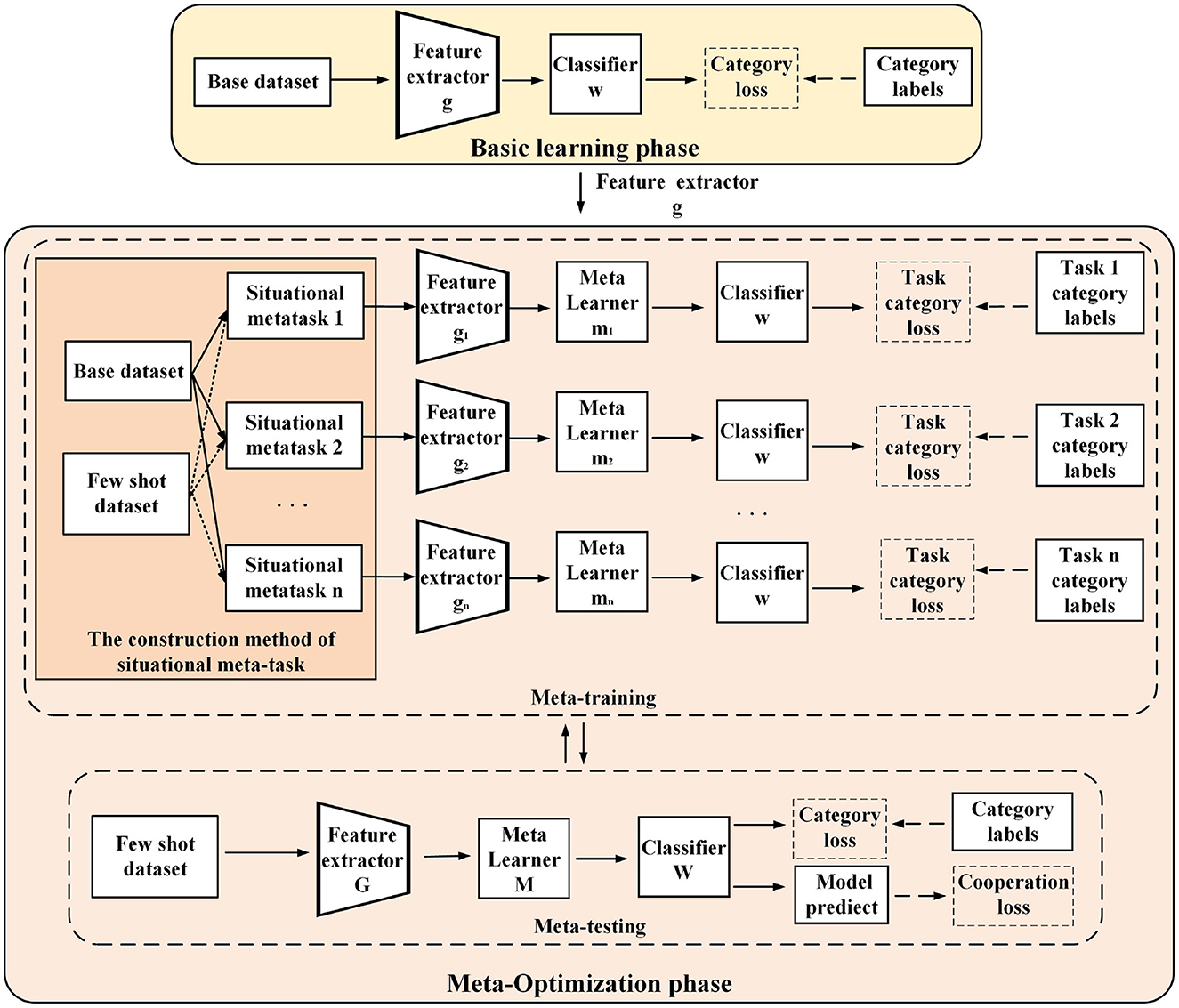
3.4 Full-phase meta-learning process based on multiple initial model cooperationAs shown in Figure 4, the full-phase meta-learning process based on multiple initial model cooperation (FMPMIMC) includes two phases: basic learning and meta-optimization. The basic learning phase provides a universal feature extractor for constructing situational meta-tasks in the meta-optimization phase.
Figure 4. A schematic diagram of the learning process of a full-phase meta-learning method based on situational meta-task construction and cooperation with multiple initial models. In the basic training phase (above), the model learns a universal feature extractor from the base class data for situational meta-task construction. In the meta-optimization phase (below), multiple independent models are trained by situational meta-tasks in the meta-training. Then, multiple models utilize classification loss and cooperative loss to learn few-shot novel tasks in the meta-testing.
3.4.1 The basic learning phaseThe model is trained by the base class data, and it can be described as Equation (6):
Lbase_cls(f°w,xbase,ybase)=E[l(w(f(xbase)),ybase)], (6)where Lbase_cls is the classification loss, f(·) is a feature extractor of the model, w(·) is a classifier, and l(·, ·) is a cross entropy loss function.
The basic learning phase can be analogized to the extensive human learning process, and the model gets a universal feature extractor through extensive learning. It is better to extract features in the meta-optimization phase.
3.4.2 The meta-optimization phaseThe meta-optimization phase includes two interactive processes: meta-training and meta-testing. First, during the meta-training period, some situational meta-tasks are constructed for few-shot tasks using the feature extractor from the base learning process (each situational meta-task contains the corresponding support set and query set).
Then, they are used to train several independent networks (each network includes components such as feature extractor, meta-learner, and classifier). The loss of each network utilizes the classified cross entropy loss of situational meta-tasks, which can be represented as Equation (7):
Lmeta_train(f°m°w,xmeta_task,ymeta_task)=E[l(w(m(f(xmeta_task))),ymeta_task)], (7)where Lmeta_train is the meta-training loss of situational meta-tasks and f(·) is the feature extractor of the network. m(·) is the meta-learner and w(·) is the classifier. l(·, ·) is the cross entropy loss function of situational meta-task.
During the meta-training period, models containing diverse meta-knowledge are trained and learned on some different situational meta-tasks. During the meta-testing period, multiple initial model cooperation is used to learn novel few-shot tasks. The single model utilizes traditional cross entropy function to calculate the classification loss of the support sets in novel tasks. It can be represented as Equation (8):
Lmeta_testcls_i(fi°mi°wi,xnovel_tasksupport,ynovel_tasksupport)(xnovel_tasksupport,ynovel_tasksupport)∈Dnovel_tasksupport =E[l(wi(mi(fi(xnovel_tasksupport))),ynovel_tasksupport)], (8)where Lmeta_testcls_i is the classification loss of a single model learning novel few-shot tasks, xnovel_tasksupport is the support set sample of few-shot task, and ynovel_
留言 (0)