
記住我






Motor imagery (MI) brain-computer interface (BCI) systems (MI-BCIs) are designed to help patients with neurological disorders and physical movement disorders to achieve human-computer interaction by transferring the subject’s MI information to the outside world through the communication medium of electroencephalography (EEG) (Hwang et al., 2009; Yao et al., 2014; Shu et al., 2017; Attallah et al., 2020). Changes in subjects’ physical condition and brain activity occur rapidly and can be detected from EEG (Al-Qazzaz et al., 2018). EEG is a non-invasive, safe neurophysiological tool that allows recording brain activities at low cost (Al-Qazzaz et al., 2015). While MI activities are being performed, the subjects are asked to visualize their limb or muscle movements in their brain but not perform actual movements. These cognitive processes cause the relevant brain regions of the brain to be activated thereby generating EEG signals that can be decoded (King et al., 2013).
The study of classification algorithms for MI-EEG signals is an important part of MI-BCIs, and obtaining the subject’s true motor intention through the recognition algorithms is very important for the realization of human-computer interaction or rehabilitation work (Úbeda et al., 2018; Talukdar et al., 2020). Kumar et al. (2017). used a mutual information-based band selection method to utilize all the information obtained from different channels, the features of each frequency band were analyzed using linear discriminant analysis (Kumar et al., 2017). Imran et al. (2014) proposed a discrete wavelet transform method by using time windows to capture the temporal information from EEG, discrete wavelet transform is applied to the data within each window and features are extracted (Imran et al., 2014). The common spatial pattern (CSP) algorithm extracts the temporal features of EEG signals in space for MI tasks by constructing an optimized spatial filter to maximize the variance between the two types of data. Ang et al. (2012) used the filter bank common spatial pattern (FBCSP) algorithm for air domain feature extraction of motion imagery data in frequency bands with good results (Ang et al., 2012).
In recent years, deep neural networks have largely been applied to achieve state-of-the-art performance. Various deep learning models have been successfully employed to decode EEG signals for good performance (Roth et al., 2016; Dutta, 2019; Jiang et al., 2021; Klepl et al., 2022). EEGNet is a compact convolutional neural network consisting of deep and spatio-temporally separated convolutions. It has been used for MI-EEG recognition, showing excellent performance on the BCI competition dataset (Lawhern et al., 2018). Li et al. (2023) proposed a new dual-attention-based MI classification adversarial network MI-DABAN. This network can reduce the distributional differences between domains by analyzing the output differences between two classifiers and can increase the distance between the samples of confusing target domains and the decision boundary to improve the classification performance (Li et al., 2023). Milanés Hermosilla et al. (2021) used the Shallow Convolutional Network to classify and recognize MI-EEG signals with excellent results (Milanés Hermosilla et al., 2021). Kim et al. (2021) investigated different transfer learning strategies and proposed a sequential transfer learning method based on classifier migration, which utilizes the classifier migration technique to sequentially learn the task to improve the execution of MI task efficiency. Due to the difficulty and high cost of acquiring MI-EEG data from patients with central nervous disorders, there have also been studies related to data enhancement and generation of MI-EEG data (Luo and Lu, 2018).
After being proposed by Google in 2017 and achieving superior results in the field of natural language processing (NLP), Transformer neural networks have been migrated to various popular fields and a large number of variants have emerged (Vaswani et al., 2017). All these studies have proved the reliable performance of self-attention mechanism and Transformer neural network. Sun et al. (2022) proposed a parallel Transformer-based and three-dimensional convolutional neural network (3D-CNN) based multi-channel EEG emotion recognition model. The temporal and spatial features of EEG were retrieved by creating parallel channel EEG data and positional reconstruction of EEG sequence data, then using the Transformer and 3D-CNN models (Sun et al., 2022). Wang et al. (2022) proposed variable Transformer to perform hierarchical feature learning of spatial information from electrodes to brain regions to capture spatial information of EEG signals and improve the accuracy of emotion classification tasks (Wang et al., 2022). However, the research on MI-EEG signal recognition is still insufficient (Lee et al., 2021; Ormerod et al., 2021; Singh and Mahmood, 2021; Zhu et al., 2021). The self-attention mechanism for global feature interactions between feature channels is a very effective method for feature extraction, and it has great potential for processing EEG signals because it can capture the global information of the input data very effectively (Xie et al., 2022). However, none of the above work on EEG signal recognition using the Transformer network has been improved for individual differences in samples. The large individual differences in subjects lead to the difficulty of constructing recognition models with generalization to multi-subject MI-EEG data. Transformer networks have the problem of being easily disturbed and difficult to train, which is exacerbated by large individual differences. Adding sparsity structure to the model has become a reliable method to solve this problem. Sparse neural network models can dynamically allocate different depth parameters and structures for different samples or tasks to perform computations. This design allows for the expansion of model width without increasing computational complexity, leveraging the advantages of model scale to avoid a decrease in accuracy caused by individual differences in samples. The effectiveness of sparse models has been validated in various fields. The Extended Transformer Construction introduces strong sparsity to self-attention through the incorporation of Global-local attention, achieving good results in tasks involving long texts and structured inputs (Ainslie et al., 2020). Mustafa et al. (2022) proposed a sparse expert mixture model for multimodal learning, called Language-Image MoE (LIMoE). LIMoE can simultaneously process images and text, and it is trained using contrastive loss. LIMoE has shown performance improvements compared to other models with similar computational complexity across multiple scales (Mustafa et al., 2022). In this study, we add the Mixture of Experts (MoE) and ProbSparse Self-attention mechanism to the Transformer network to increase the sparsity of the model and thus enhance the model’s classification performance on multi-subject data. The concept of MoE was first introduced by Jacobs et al. (1991) to modularize the transformation of multilayer networks. To achieve the goal of expanding the capacity of the model within a limited computational cost, Shazeer et al. (2017) introduced sparse gating networks to MoE, added strong sparsity to the structure of the model and increased the model size by more than 1,000 times at the expense of a very small amount of computational efficiency (Shazeer et al., 2017). Lepikhin et al. (2020) introduced MoE for the first time into the Transformer neural network model, and achieved very good results on the machine translation task with very good results (Lepikhin et al., 2020). To solve the problem of secondary computational complexity of self-attention mechanism, Zhou et al. (2021) proposed the ProbSparse self-attention mechanism, which reduces the memory usage and time complexity for the Transformer model by introducing sparsity (Zhou et al., 2021).
This study introduces a Transformer neural network model with the addition of MoE layer and ProbSparse self-attention mechanism for classifying the time-frequency spatial domain features of MI-EEG data of spinal cord injury (SCI) patients, which is named as EEG MoE-Prob-Transformer (EMPT). The model architecture is shown in Figure 1.

Figure 1. EMPT’s network structure.
The main work of this paper is as follows:
1. The effect of the increase of the MoE layer and ProbSparse self-attention mechanism on the performance of the Transformer structure on EEG data is explored through ablation experiments.
2. The optimal network structure of the EMPT is explored and verified to be effective.
3. The effect of the MoE layer and ProbSparse self-attention mechanism in response to individual differences in subjects are visualized and analyzed to enhance the interpretability of the model structure.
Chapter 2 focuses on the experimental dataset and the main algorithm used in this study. Chapter 3 presents the performance of the Transformer structure on EEG data and the optimal structure of the model with the addition of the MoE layer and the ProbSparse self-attention mechanism. Chapter 4 introduces the visual analysis of the improved parts of the model. Chapter 5 summarizes this study.
2 Materials and methods 2.1 DatasetThe dataset was collected from the Department of Physical Medicine and Rehabilitation, Qilu Hospital, Qilu Medical College, Shandong University. All participants provided written informed consent after receiving a detailed description of the purpose and potential risks of the experiment. The study protocol was approved by the Medical Ethics Committee of Qilu Hospital, Qilu Medical College, Shandong University. The experiment was conducted in accordance with relevant guidelines and regulations. The EEG signals were acquired using a 64-electrode acquisition device shown in Figure 2. This dataset was composed of MI-EEG data from 10 subjects (10 SCI patients). During the EEG signal acquisition experiments, the subjects had a complete MI task of 7 s in duration, an imagined movement time of 4 s, and an interval of 3 s between every two imagined movements, and the experimental paradigm is shown in Figure 3. MI tasks are divided into left-handed MI tasks and right-handed MI tasks. The two MI tasks were imagining a left-handed fist clench and a right-handed fist clench. When the MI action cue was over, the subjects started to perform the corresponding MI task. Each experimental group comprised 30 randomly presented MI tasks. Each subject performed 4 groups of experiments with a 90 s rest period between each group of experiments, i.e., each subject performed 4 groups of 120 trials, 60 left-handed MI tasks, and 60 right-handed MI tasks.
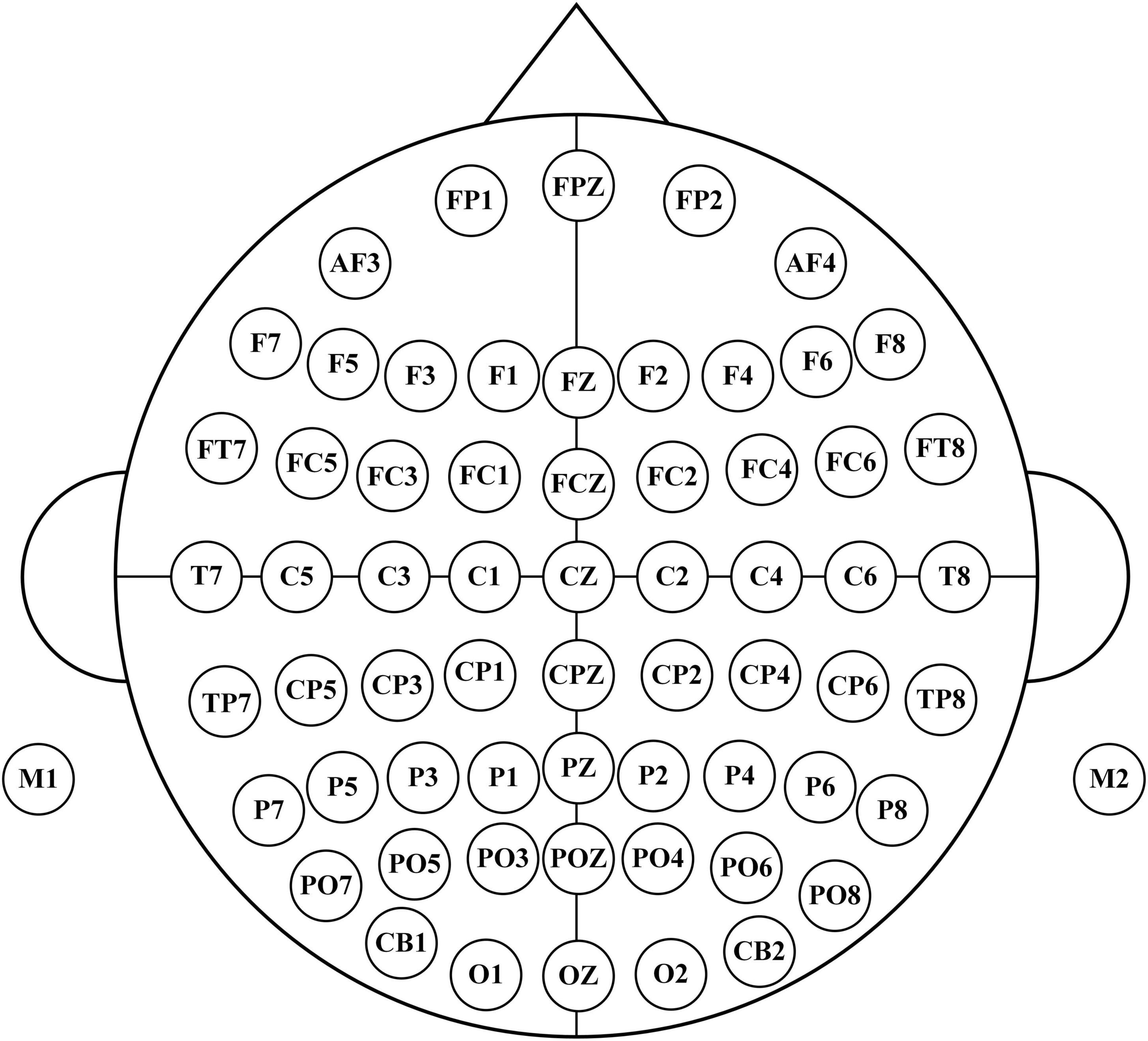
Figure 2. 64 electrodes distribution.

Figure 3. Experimental paradigm.
2.2 Modified S-transform (MST)The MI-related activity information in EEG signals is mainly concentrated in the alpha band (8–13 Hz) and beta band (13–30 Hz) (Al-Qazzaz et al., 2015; Siddharth et al., 2022). Time-frequency domain analysis of EEG signals has been validated as a very effective method.
Modified S-transform (MST) is a time-frequency domain feature extraction method with independent frequency resolution. MST performs multi-resolution time-frequency analysis of the input EEG data by means of a window function with an adjustable width, which better extracts the phase at different frequencies and clearly locates the frequency profile of the noise. The MST algorithm can optimize the window size and better focus the energy in the time-frequency domain by introducing adaptive parameters (Siddharth et al., 2022).
Modified S-transform (MST) can be expressed as follows,
MST(ξ,f)=∫-∞∞t(s)g(ξ-s,f)e(-j2πfs)dt(1)
where g(ξ−s,f) is the Gaussian function of the MST. It is defined as follows,
g(ξ-s,f)=12πσ2(f)e-(ξ-t)22σ22(f)(2)
where the standard deviation σ2(f) is as follows,
σ2(f)=p|f|q(3)
The width of the Gaussian window can be optimized by adjusting these two parameters, P and Q.
The PSD of the MST is calculated as follows,
PSD=E[MST*MST¯](4)
2.3 Common spatial pattern (CSP)The CSP is employed to find an optimal common spatial filter. After the EEG signals are processed by the optimal spatial filter, the variance of one class of MI-EEG signals is maximized while the variance of the other class of MI-EEG signals is minimized. To obtain the feature vectors with the highest discrimination, the covariance matrices of the CSP for the two classes of MI-EEG signals are diagonalized.
Common spatial pattern (CSP) is able to rely on spatial filters to aggregate the spatial distribution characteristics within the EEG data well and extract the relative spatial information in the signals. Due to its reliability and high computational efficiency, CSP has been widely used for the analysis of EEG signals (Cheng et al., 2016; Fu et al., 2019; Li et al., 2019).
Xi is the spatio-temporal EEG signaling matrix for the two types of motion imagery The size of Xi is C × Tc, where C is the number of EEG channels and Tc is the number of time sampling points for each channel.
After normalizing the time-space matrix Xi, the covariance matrix Ri can be obtained as follows,
Ri=XiXiTtrace(XiXiT)(i=1,2)(5)
where XiT denotes the transpose of the matrix Xi, trace(X)trace(X) denotes the sum of the elements on the diagonal of the matrix.
The two-class covariance matrix R of the mixed space can be defined as follows,
R=R¯1+R¯2(6)
where R¯i(i=1,2) are the average covariance matrices for task 1 and task 2, respectively.
Since the mixed space covariance matrix R is a positive definite matrix, the eigen decomposition is defined as follows,
R=UλUT(7)
where U is the eigenvector matrix and λ is the diagonal matrix of the corresponding eigenvalues.
These eigenvalues are be arranged in descending order, the transformation U can be whitened as follows,
P=1λUT(8)
Then S1 and S2 can be obtained by the following transformations. S1 and S2 have the same eigenvectors.
S1=PR1PT,S2=PR2PT(9)
Decompose the principal components of S1 and S2.
S1=Bλ1BT,S2=Bλ2BT(10)
where λ1, λ2 are diagonal matrices and the same eigenvector moment B.
The sum of the diagonal matrices λ1 and λ2 of the two eigenvalues is the unit matrix.
λ1+λ2=I(11)
The eigenvalues of λ1 and λ2 are ordered in descending and ascending order, respectively. Since λ1 and λ2 are the diagonal matrices of S1 and S2, for the eigenvector matrix B,when S1 has the largest eigenvalue, S2 has the smallest eigenvalue. The classification of the two types of MI signals can be achieved by means of the matrix B. The projection matrix W is calculated as follows.
W=BTP(12)
The projection matrix W is the corresponding spatial filter.
2.4 Transformer neural networkIn this study, only the encoder structure of the base Transformer network is used. The structure of the baseline Transformer network is shown in Figure 4A. The feature vectors are sequentially entered into several TransformerBlocks thereby being mapped into deep feature vectors containing information about whole brain activity (Han and Wang, 2021).

Figure 4. (A,B) Transformer and TransformerBlock structure.
2.4.1 TransformerBlock structureA complete TransformerBlock consists of a multi-head attention module, a feed-forward neural network, and an Add&Norm module with corresponding residual connections. The structure of the TransformerBlock is shown in Figure 4B.
The feed-forward neural network in the base Transformer network consists of fully connected layers that rely on a high-dimensional hidden layer transform to map the input vectors and then map the high-dimensional vectors to fixed low-dimensional vectors. This transformation accomplishes deep feature extraction and relies on activation functions to add more nonlinear computation to the network.
The Add&Norm module consists of residual links and layer normalization modules. Its main purpose is to ensure the stability of network training and reduce the occurrence of overfitting phenomenon and network degradation.
2.4.2 Multi-head self-attentionThe multi-head attention mechanism consists of multiple mutually independent self-attention heads, each of which can capture different whole-brain activities for reconstructing depth feature vectors. The multi-head attention mechanism expands the sensory field of the attention mechanism for brain activities capture and improves the performance of the attention mechanism.
On the input feature vectorF, the self-attention module can map three vectors Q, K and V of dimension L for computing the attention coefficients of self-attention through the three trainable weight matrices WQ, WV and WK. Where Q and K are the query vector and key vector, respectively, in the attention mechanism, Q and K are used to compute the attention dot product, while V yields the output vector by weighting with the attention dot product. The formula for Q, V and K calculation is as follows,
Q=WQF,K=WKF,V=WVF(13)
The attention factor for Xi pointing to Xj is calculated as follows,
Ai,j=QiKjdk(14)
dk=L(15)
After obtaining the attention factor matrix Ai,j for the eigenvector Fi, Vi is weighted according to the attention coefficient Ai,j. The weighted vector Zi is obtained by the following equation.
Zi=∑j=1NSoftmax(Ai,j)VH=j(16)
The self-attention mechanism is used to map the feature vectors of all channels, the original feature vector F becomes a new vector containing the attention relations of all feature vectors Z. The output vectors of multiple attention heads are spliced together and processed by the feed-forward neural network to be provided to the downstream task.
2.5 Sparsity improvement in Transformer networksBecause of the large individual variability of subjects’ EEG signals, when a dataset containing multi-subject data is used to construct a model, a large model width is required to ensure the performance and stability of the model (Suhail et al., 2022). The training samples become larger and each sample needs to go through all the computations of the model, which leads to a large increase in the training cost. In this paper, the MoE layer is introduced to increase the sparsity of the model to save the computational cost. Sparsity means that the model has a large capacity, but only some parts of the model are activated for a single sample. An increase in model sparsity can significantly improve the capacity and performance of a model, but does not proportionately increase the computational effort.
2.5.1 MoEThe MoE layer has different expert submodels, each specialized for a different input. The experts in each layer are controlled by a gating network that activates certain expert submodels based on the input data. For each input, the gating network selects the most appropriate expert submodel to process the data. The structure of the MoE layer is shown in Figure 5:
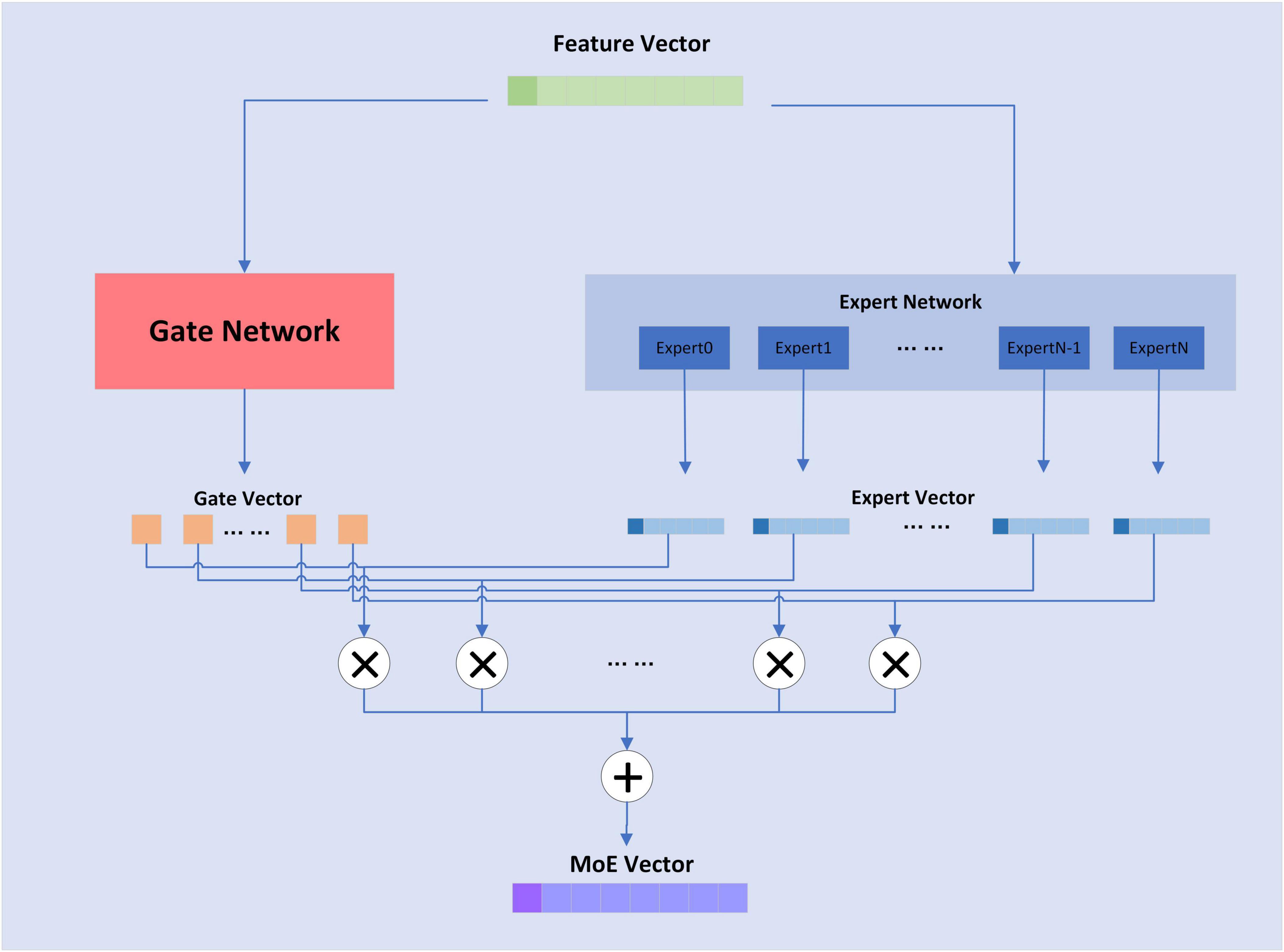
Figure 5. Structure of MoE layer.
The formula for the MoE layer is shown as follows,
y=∑i-1nGi(x)Ei(x)(17)
where n is the attribute of the expert sub-model, G(x) is the output value of the gating network, and E(x) is the output of the expert sub-model. The composition of the gating network is relatively simple and consists of a linear layer and a softmax activation function, whose formula is shown as follows,
G(x)=Softmax(KeepTopK(x⋅W),k)(18)
KeepTopK(⋅) is a discrete function that forces values outside of top-k to negative infinity, resulting in an output value of 0 for softmax. For the MoE layer, the expert sub-model is a fully connected layer.
2.5.2 MoE-TransformerBlockIn this study, the feedforward neural network in TransformerBlock is replaced with a MoE layer, which adds sparsity and network width to the model without increasing the computational effort. The MoE-TransformerBlock is shown in Figure 6.
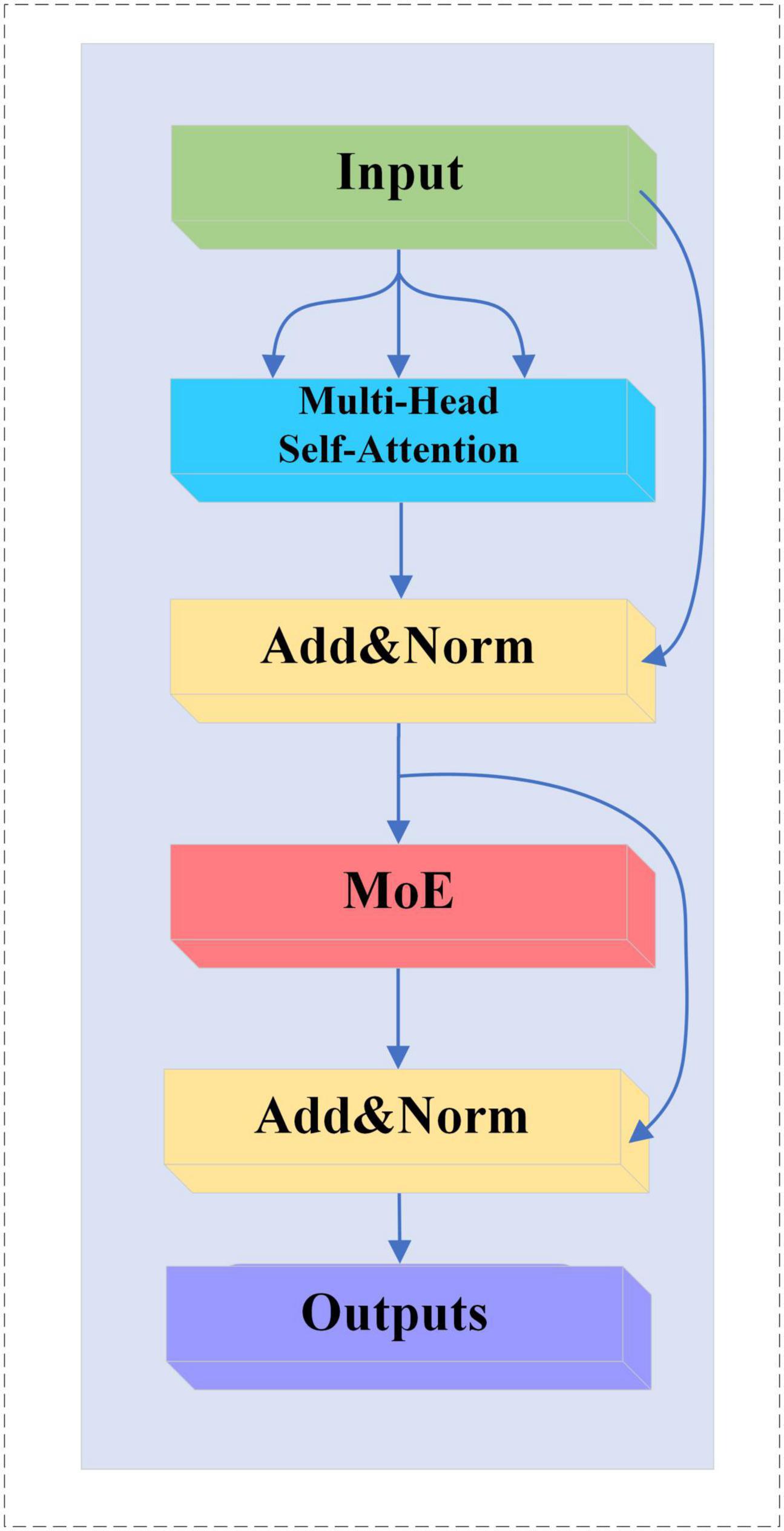
Figure 6. MoE-TransformerBlock structure.
2.6 Attention pooling improvements for Transformer networksFor the traditional attention mechanism, the dot product of Q and K is sparse, and the feature map of the self-attention coefficients shows a long-tailed distribution. Long-tailed distribution is a type of uneven data distribution. In a long-tailed distribution, the categories of samples are divided into head and tail categories. The head category means that a few categories contain a large number of samples, and the tail category includes most of all the categories but has only a small number of samples. For a single attention head, fewer dot products contribute the majority of the attention score, and the rest of the paired dot products can be ignored. This sparsity distribution has a practical implication: an element in a sequence will generally only have a high degree of similarity and correlation with a few elements (Zhou et al., 2021). On the EEG dataset, our team similarly confirmed this phenomenon when training the Transformer model, as shown in Figure 7. The head class representation in Figure 7 is boxed in red for easier viewing. For the deeper multi-head self-attention module, the individual attention heads tend to focus more on some specific channels thus showing a long-tailed distribution. This may be because these selected channels already contain the activity of a certain brain region, and the deeper multi-head self-attention module reconstructs the high-level feature vectors that contain the activity of the whole brain by focusing more on these specific channels to capture the global brain activities.

Figure 7. Long-tailed distribution in the dot product of multi-attribute attention.
The long-tailed distribution of each set of self-attention coefficients in the traditional self-attention head is similar, and weighting using similar attention coefficients is very wasteful of computational cost. To deepen the stability of the computation and reduce the computational cost, we should find the Q that can dominate the distribution of attention coefficients for self-attention computation. To accomplish this, we introduce the ProbSparse self-attention mechanism.
2.6.1 Measuring query sparsityThe long-tailed distribution of the coefficients for traditional self-attention on the EEG dataset is shown in Figure 7. The attention factor of the ith query on all keys is defined as the probability P(KH,Qi), where H is the number of channels of input EEG features. The probability distribution of the dominant dot product on the attention of the corresponding query is far from the uniform distribution. If P(KH,Qi) is close to the uniform distribution, P(KH,Qi) = 1/LK, then the query is lazy and fails to pick out important keys, and vice versa, the query is active. If the query is completely lazy, the self-attention becomes a sum of values, which results in some information in the output being redundant.
Since active queries contribute a lot to self-attention and lazy queries contribute little, the active queries are selected as much as possible. The gap between the distribution P(KH,Qi) and the uniform distribution can be used to distinguish the importance of a query. ProbSparse self-attention measures similarity by Kullback–Leibler sparsity, the sparsity measurement of the ith query is defined as follows,
M(Qi,K)=ln∑j=1LKeqikjTd-1LK∑j=1LKQiKjTd(19)
For the sparsity measurement of the ith query, the larger the value, the larger the difference between the dot product probability distribution and the uniform distribution, which means the more active the query is.
2.6.2 ProbSparse self-attentionBased on the proposed metric, ProbSparse self-attention is derived by allowing each key to focus on only u main queries.
A(Q,K,V)=Softmax(Q¯KTd)V(20)
where Q¯ is a sparse matrix of the same size as Q, which contains only the Top-u queries under the sparsity metric M(Q,K). For those queries that are not selected, their outputs may be taken as the means of Vto ensure that both the input and output sequence lengths are Q.
Traversing the sparsity measurement M(Q,K) of all queries requires computing each dot-product pair, increasing the quadratic computational complexity O(LQLK), and the log-sum-exp operation has potential numerical stability issues. ProbSparse self-attention uses an empirical approximation that efficiently obtains the query sparsity metric. The improved formula is as follows,
M(Qi,K)=maxj(QiKjTd)-1LK∑j=1LKQiKjTd(21)
ProbSparse Attention randomly samples key for each query, the sampling result of each head is the same. However, since each layer of self-attention can do a linear transformation of Q, K, and V, which makes the query and key vectors corresponding to different heads at the same position in the sequence different, so the sparsity measurement of the same query of each head is different, which makes the Top-u query with the highest measurement are different for each head. This is also equivalent to the fact that each head adopts a different optimization strategy.
2.6.3 MoE-Prob-TransformerBlockWe replace the multi-head self-attention mechanism in MoE-TransformerBlock with ProbSparse self-attention, the structure of which is shown in Figure 8.
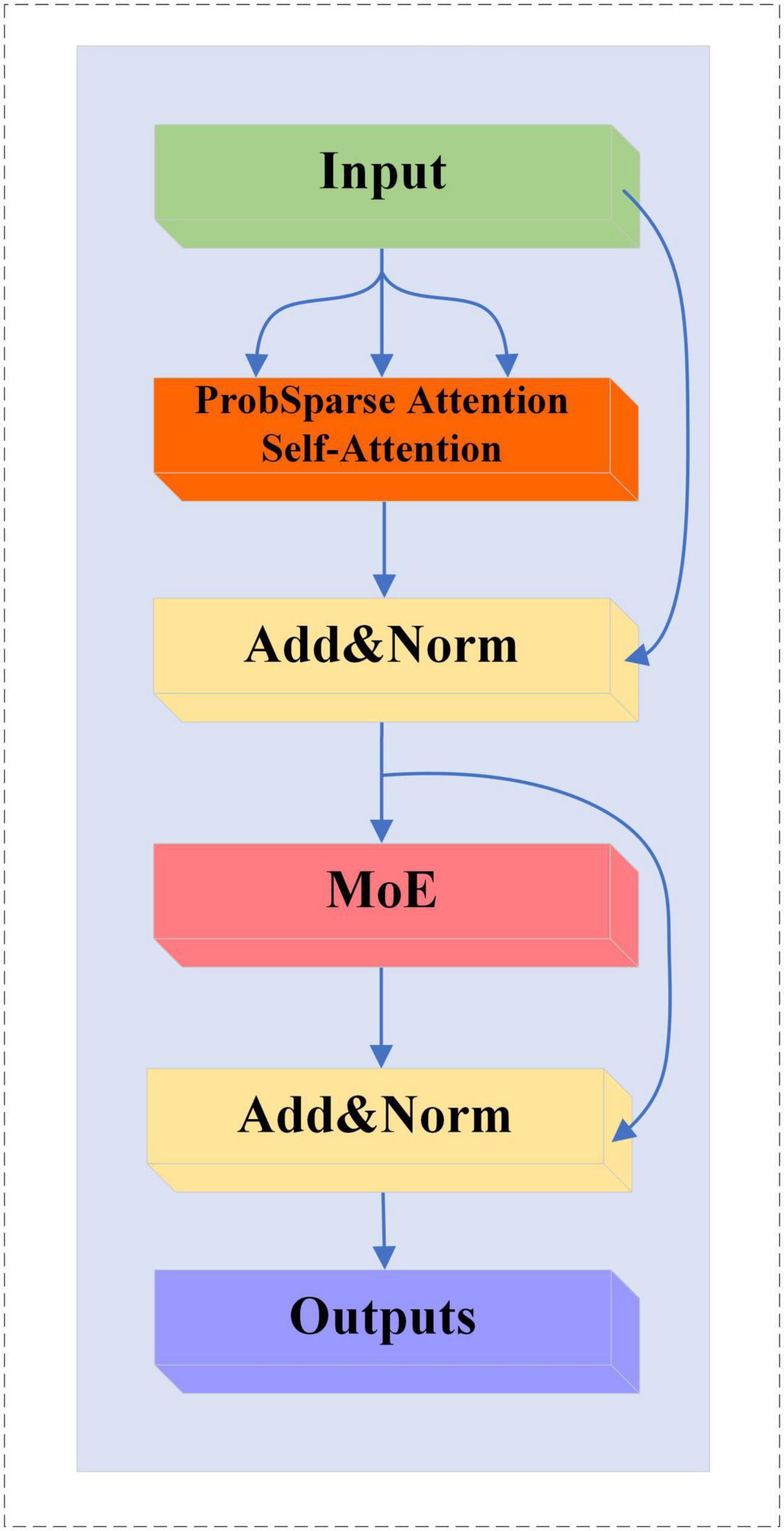
Figure 8. MoE-Prob-TransformerBlock structure.
3 Results 3.1 Implementation details 3.1.1 Pre-processing and feature extractionFor the two different feature extraction methods, this paper uses different preprocessing schemes to MST and CSP on the data.
The shape of the raw EEG data is T × CH × ES, where T is the number of experiments, CH is the number of channels, and ES is the number of sampling points of the EEG signal.
The pre-processing scheme for MST involved passing the raw EEG signals through a Butterworth filter at 8–30 Hz, followed by downsampling. This downsampling step reduced the sampling rate from 1,000 Hz to 100 Hz. After feature extraction by the MST method, the shape of the feature is T × CH × Fmst, where Fmst is the number of MST features. The parameters and of the Gaussian window for MST are 0.98 and 0.49.
In the application of the CSP method, the current study utilizes a multi-band dataset from a single channel for CSP feature extraction. Specifically, the data from multiple frequency bands of each channel is treated as a new channel, and CSP is applied to extract features from these multi-band channels. The pre-processing scheme for the CSP method is as follows, the original EEG signal is decomposed into 55 different frequency bands using a Butterworth filter in windows of band widths of 2, 4, and 8 Hz, all with a step size of 1 Hz (Huang et al., 2009). The signal bands are shown in Figure 9. The shape of the EEG signal data after band decomposition is T × CH × FN × ES, where FN is the number of frequency bands. After completing the filter decomposition and then downsampling, the sampling rate is reduced from 1,000 to 100 Hz. The EEG signals of each channel are sequentially fed into the CSP method for feature extraction, and the shape of the CSP features is T × CH × Fcsp, whereFcsp is the number of CSP features.

Figure 9. Separation of EEG signals by frequency bands.
3.1.2 Neural network trainingThe hyperparameters used to train the neural network are shown in Table 1. Where Dropout Rate (FC Layer), Dropout Rate (MoE-TransformerBlock) and Dropout Rate (MoE-Prob-TransformerBlock) are the neuron inactivation probabilities of the fully connected layer, MoE-TransformerBlock and MoE-Prob-TransformerBlock’s neuron inactivation probability. The lower loss rate of MoE-TransformerBlock and MoE-Prob-TransformerBlock is to ensure proper convergence of the model loss. In training, it was found that setting a higher Dropout rate in self-attention leads to too slow convergence of the model loss function. The loss curve for EMPT training is shown in Figure 10.

Table 1. EMPT model training parameters.
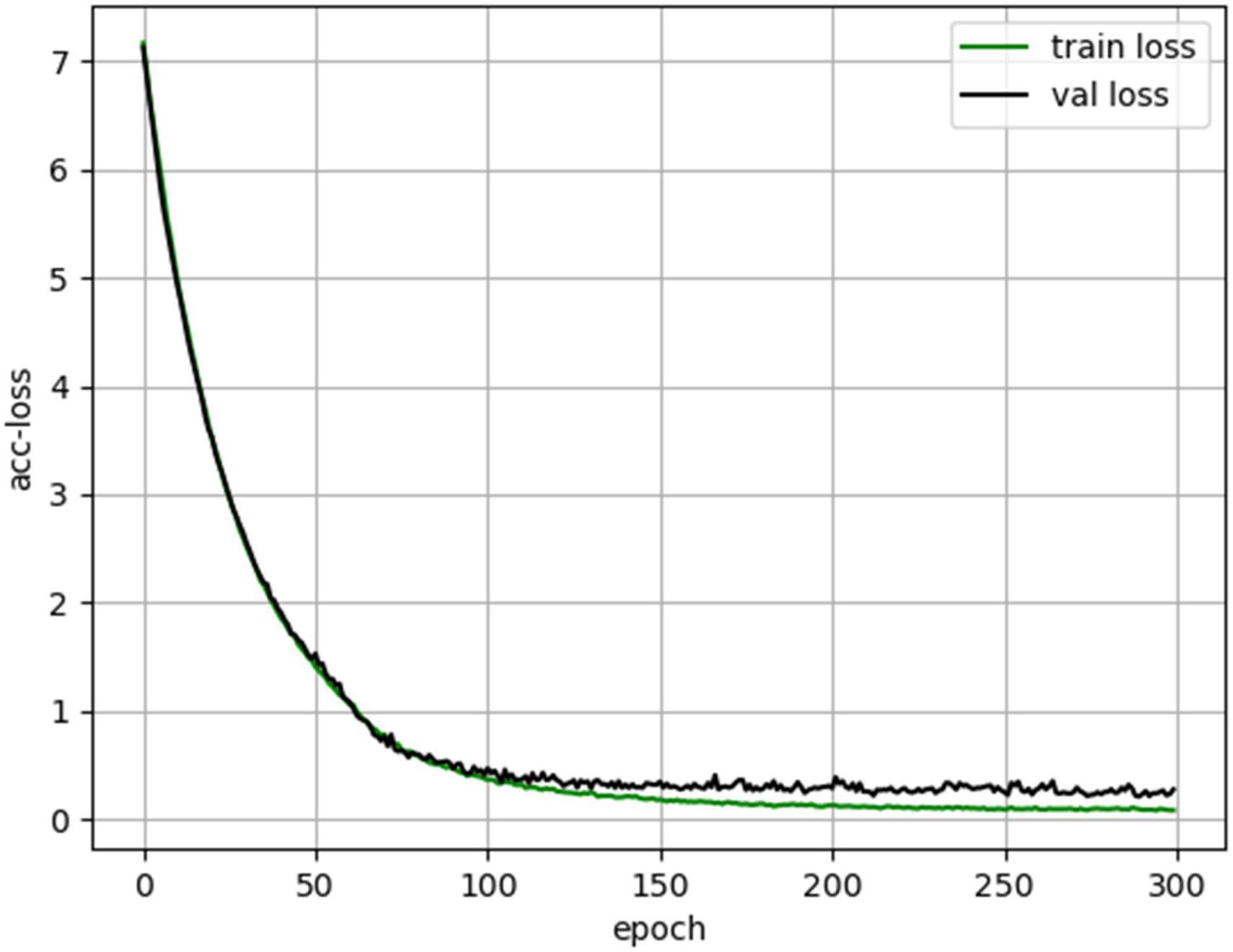
Figure 10. EMPT training loss curves.
3.2 Experimental resultsThis section conducts performance experiments and analysis on the EMPT and related structures. Cross-individual model training was performed on the MI-EEG dataset of SCI patients and ten times 10-fold cross validation was performed to obtain experimental results.
3.2.1 Selection of K value for MoE layerIn MoE, the KeepTopK(⋅) operation selects the larger value G(x)K among the gated network outputs G(x), with K being the number of larger values. expert models corresponding to G(x)K are retained for subsequent weighting operations. expert models with smaller values of G(x)G(x) imply that they are not sufficiently important for the current samples. the choice of the value of K may be of great significance for the final performance of the model. In order to determine the optimal K value for the dataset used in this study, we conducted an experiment to determine the choice of K value by looking at the performance of the MoE-Transformer with a layer number of 1 when different K values are chosen.
By observing the data within Table 2 we can find that there is little difference in MoE-Transformer performance when K≥4. To save unnecessary computational expenses, 4 is chosen as the value of K in this study to enable the model to obtain good classification performance.

Table 2. Performance of single-layer MoE-Transformer at different values of K.
3.2.2 Ablation experimentTo verify that the improvements of the MoE layer and ProbSparse self-attention are effective on the SCI EEG dataset, ablation studies are conducted on them separately to explore their effectiveness. The results are shown in Table 3. The MoE-Transformer and Prob-Transformer models are derived by replacing the TransformerBlock with MoE-TransformerBlock and Prob-TransformerBlock based on the Transformer base model. It should be noted that Prob-TransformerBlock is not the MoE-Prob-TransformerBlock described in section “2.6.3 MoE-Prob-TransformerBlock”. Prob-TransformerBlock is obtained by replacing the self-attention in TransformerBlock with ProbSparse self-attention. The experimental results show that the addition of both MoE-TransformerBlock and Prob-TransformerBlock have made improvements to the performance of the Transformer-Base model. From the Table 3, it can be observed that MoE-Transformer and Prob-Transformer still show the best performance at 2 stacked layers for the dataset used compared to Transformer-Base. This may be due to the fact that although both improvements attach strong sparsity to the model to improve performance, both structures do not make the network deeper. The failure of the network to perform better as it gets deeper may also be related to the fact that the dataset used in this paper is not large enough. Although we added sparsity improvements in this chapter to reduce noise interference in the model, due to the noise-sensitive nature of the attention mechanism, smaller datasets still make it difficult to train the model to exclude all noise interference.
留言 (0)