
記住我








Trajectory prediction is an essential research area that has various applications in autonomous driving (Bennewitz et al., 2005; Ma et al., 2019; Chandra et al., 2020), robot navigation (Rasouli et al., 2019), and surveillance systems (Oh et al., 2011; Sultani et al., 2018). For instance, in autonomous driving, vehicles need to estimate the future movements of pedestrians to avoid collisions and plan a safe driving path.
One of the basic challenges for trajectory prediction is to analyze the pedestrian future intention in the changing context, such as whether the pedestrian intends to cross the road before or after a car passes. This analysis can provide a useful information for trajectory prediction. Recently, some works have considered the agent intention prediction in the trajectory prediction task, such as PECNet (Mangalam et al., 2020), TNT (Zhao et al., 2021), DenseTNT (Gu et al., 2021), and so on. However, these methods simplify the problem by assuming that the agent intention endpoint, which reveals the agent movement intention, remains constant during the prediction range.
In fact, predicting the endpoint coordinates of pedestrians is a very challenging task. Pedestrians will dynamically adjust their intent endpoint coordinates in respond to the change of scene information in different regions. As shown in Figure 1, the pedestrian in the red frame is the target pedestrian. In the left image, the vehicle on the right is parked at the upper right of the image and has no tendency to move forward. At this time, the short-term movement target of the pedestrian is the red star below the vehicle. However, during the movement of the pedestrian, the vehicle starts to move forward, blocking the original movement target of the pedestrian. Due to environmental changes, pedestrians must change their original intention and move toward the green star at the upper right. It is important to dynamically analyze the pedestrian's intent coordinate by combining the pedestrian's motion state and scene characteristics.

Figure 1. Dynamic change of the pedestrian intention.
In addition, when modeling the future intention of the pedestrian, existing methods generally use the multi-layer perceptrons (MLPs) to predict a 2-d coordinate as the intention feature. Huang et al. (2021) models the intention with a Mutable Intention Filter to address the drift in long-term pedestrian trajectory prediction, and its experiment demonstrates the goal prediction is changing during the prediction process. But there are limitations in the work. Firstly, this work assumes that all targets are located at the scene edges, which is unrealistic. And it models the intention with specific 2-D locations. The pedestrian's movement intention information should not be modeled as a specific physical coordinate, and the observable coordinate cannot fully represent the pedestrian's intention to help predict the future trajectory as in Figure 1.
In this paper, we model the intention as features that combine both fine-precision destination and coarse-precision region representation, and could be dynamically changed in the prediction process, consider the dynamic changing caused by environment and pedestrian. To extract a feasible dynamic intention feature, we propose a multi-precision pedestrian intention analysis module, which dynamically predicts intent from the scene information and history trajectory. We generate the coarse-precision coordinate from the history trajectory, then we use the scene heatmap and the coarse-precision coordinate to calculate the local dynamic feature. By combining the local dynamic feature and the coarse-precision coordinate, we predict agent intention feature as an assistance to predicting the future trajectory. In addition, three sub-tasks including prediction of coarse-precision endpoint coordinate, fine-precision endpoint coordinate and scene sub-regions scoring are proposed to help training the feasible dynamic agent intent extraction module.
We propose Dynamic Target Driven Network for pedestrian trajectory prediction (DTDNet). First, we use a motion pattern encoding module to extract movement patterns from pedestrian historical trajectories. After that, we use multi-precision pedestrian intention analysis module to extract the feasible intention based on multi-precision feature input. At the same time, multi-precision intention analysis sub-tasks are introduced to aid pedestrian intent information extraction. Finally, a pedestrian trajectory decoding module based on the CVAE generation framework combines pedestrian movement patterns and scene information to predict pedestrian intent coordinates dynamically. The contributions of this paper are as follows:
1. We discuss the dynamic changing attribute of pedestrian intention prediction process, and propose a novel module to extract the dynamic intention feature accordingly. This module encodes the pedestrian future intention at each time steps iteratively with scene information, and we propose a multi-task structure to aid the feature learning process with three related subtasks.
2. We propose a novel multi-precision pedestrian trajectory data representation method to estimate the multi-precision intention, including three aspects: coarse-precision coordinates, fine-precision coordinates, and local scene information.
3. We design a new trajectory prediction model DTDNet, which conducts the prediction with dynamic intention modeling and multi-precision history data. Qualitative and quantitative experiments show that this model outperforms current methods and predicts endpoint coordinates closer to the future endpoint.
2 Related work 2.1 Trajectory predictionEarly researches on trajectory prediction are based on hand-craft rules and energy potentials. Helbing and Molnar (1995) model the force between pedestrians by attractive force and repulsive force. However, with the limitation of the hand-craft functions, the previous approaches cannot model the complicated interactions in crowded scenarios. Trajectory prediction is a time series prediction task, many data-driven methods (Oliveira et al., 2021; Zhang et al., 2022) have been proposed to solve this problem in recent years. Alahi et al. (2016) propose one of the earliest deep learning models for trajectory prediction, which uses a grid-based “social pooling” layer to aggregate the hidden state of the pedestrians in the neighborhood. Gupta et al. (2018) also use the pooling-based method and propose a “pooling module” to share information of all the pedestrians in the whole scene. Vemula et al. (2018) and Kosaraju et al. (2019) introduce the attention mechanism to assign different importance to different agents. Recent works (Huang et al., 2019; Hu et al., 2020; Mohamed et al., 2020; Tao et al., 2020) are all graph-based methods that use graph neural networks to model the interactions among the pedestrians.
2.2 Human-scene interactionPedestrian motion is not only affected by surrounding pedestrians, but the layout features of the scene also limit the movement space of pedestrians. Therefore, effectively extracting scene information plays a crucial role in trajectory prediction. Some works (Vemula et al., 2018; Huang et al., 2019) use VGGNet to encode a large scene's complete overhead image information. The model can learn any scene information and use the visual attention mechanism to assign important spatial regions to pedestrians. To incorporate scene category information, Yao et al. (2021) use a semantic segmentation model to process scene pictures. Pixel-level scene category information can be obtained by using semantic segmentation information. However, this method still has ambiguous information and does not know whether pedestrians in this category could move forward. Wang et al. (2022) proposed a heat map construction method based on historical trajectory statistics and used the GLU module to model scene information continuity.
2.3 Human intention predictionPedestrians have subjective intentions to guide themselves to reach their expected goals. Recently, some researchers have begun to research the endpoint prediction of pedestrians. Mangalam et al. (2020) used the CVAE module to predict the endpoint information and then predicted the complete trajectory. Different from the previous model, Lerner et al. (2007) used the bidirectional trajectory fitting method to predict the complete trajectory in the stage of generating the complete trajectory. Zhao et al. (2021) propose to set up multiple candidate endpoints in the region where pedestrians are likely to reach and score different candidate endpoints based on pedestrian characteristics. Gu et al. (2021) improved TNT (Zhao et al., 2021) and proposed a trajectory prediction method without pre-defining candidate targets. It dramatically improves the performance of target estimation without relying on heuristic predefined target quality. Unlike previous work that only modeled a single long-term objective, Robicquet et al. (2016) proposed a step-wise objective-driven network for trajectory prediction that evaluates and uses the goal at multiple time scales.
3 MethodIn this section, we introduce structure of our DTDNet model, as shown in Figure 2. At first, we present the construction of multi-precision data. Then we discuss the three sub-networks of DTDNet: the motion pattern encoding module, multi-precision pedestrian intention analysis module and trajectory decoding module.
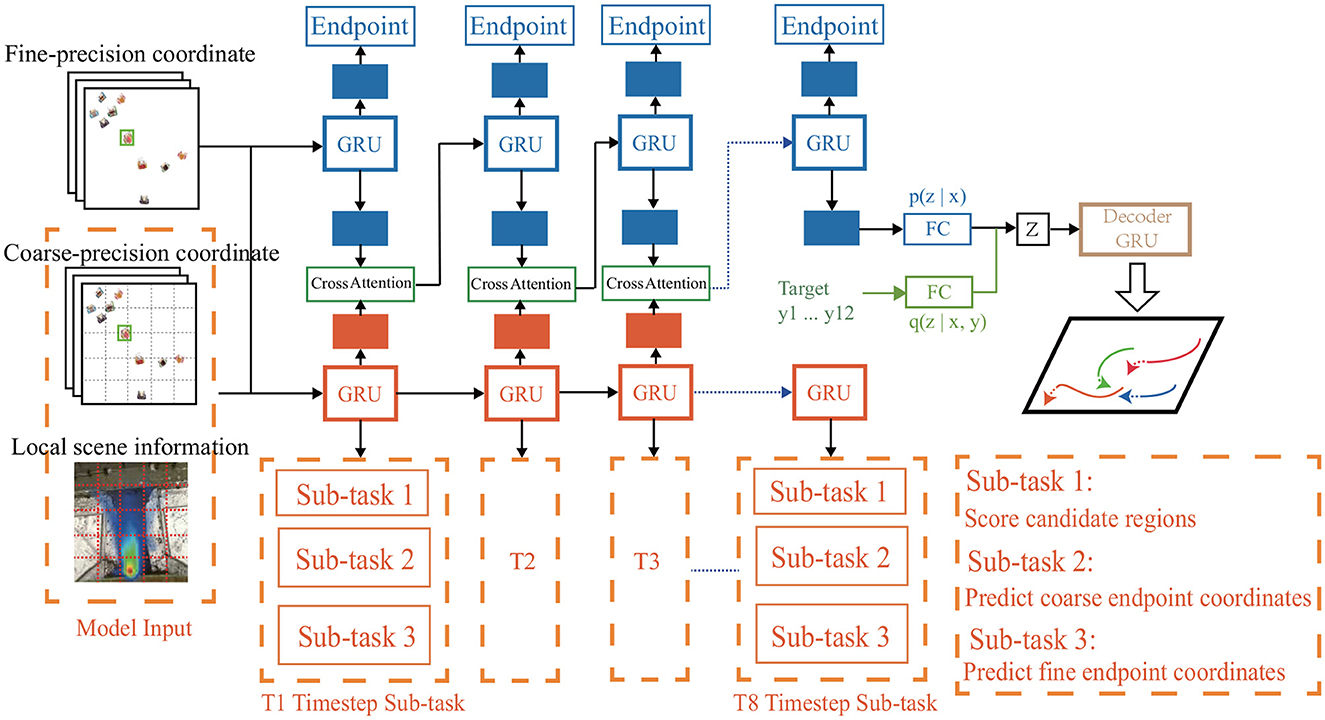
Figure 2. Overview of our proposed DTDNet. Take fine-precision, coarse-percision pedestrian coordinate and local scene information as input, the DTDNet is consisted of three parts: a motion pattern encoding module based on pedestrian historical trajectories (blue), a dynamic multi-task intent analysis module based on multi-precision feature input (orange), a multi-modal trajectory decoding module based on the CVAE freamwork (green and brown). Green part in the CVAE module is used only in the training stage.
3.1 FormulationsWe assume that there are N pedestrians in the scene I, the position coordinates of pedestrian i at time step t is denoted as Pit=(xit,yit). Our model uses historical trajectories Pi_h={Pit,t∈[1,Tobs]} to predict the future locations P^i_f= and minimize the distance between prediction and future trajectory ∑t=Tobs+1Tpre∑i=1N∥P^it-Pit∥2.
3.2 Multi-precision data constructionWe get three kinds of data for the model to perform the multi-precision modeling, namely fine-precision coordinates, coarse-precision coordinates, and dynamic local scene information.
3.2.1 Coarse precision coordinate generationA schematic diagram of coarse-precision coordinates is shown on the left in Figure 2, the model divides the global scene into multiple sub-regions. The region coordinates are the input coarse-precision coordinates, which retain the physical information of the scene location and are easy to combine with the scene information.
First, we collect coordinate ranges (xmin, xmax, ymin, ymax) of different scenes based on the training data. Following the principle of equal spacing, we get the segmentation space of each region according to the set division resolution R = m×n. Furthermore, we could use the pedestrian's current position Pi, the coordinate range of the scene (xmin, xmax, ymin, ymax), and the length of the region to calculate the coarse precision coordinates. By using Algorithm 1, we could get the pedestrians' coarse precision coordinates PR as shown in Algorithm 1.

Algorithm 1. Strategy of coarse-precision coordinate generation.
3.2.2 Fine precision coordinate generationAfter obtaining the coarse-precision coordinates of pedestrians, we perform data pre-processing on both fine-precision coordinates and coarse-precision coordinates. To increase the generation capability of the model, we set the position (xTobs, yTobs) of the target pedestrian at the last observation time step as the origin, and convert the absolute position into relative position according to the position of origin.
We adopt the same data pre-processing method as Trajectron++ (Salzmann et al., 2020). In addition to the position coordinates, the input data also uses the first-order derivation and second-order derivation of position to calculate the speed information and acceleration information in both x and y direction. And we augment the training dataset by rotating all trajectories every 15 degrees around the origin point.
3.2.3 Dynamic scene informationMost existing methods use semantic segmentation of the scene image to model scene information. Although semantic segmentation information has proved useful in 3D stereo reconstruction and other fields, this information is ambiguous and lacks the interaction semantics between scenes and pedestrians. For example, the lawn beside the road is defined the same as the lawn in the park. However, the lawn in the park is allowed for pedestrians to walk, and the roadside lawn is generally prohibited for pedestrians. The two have the same semantic information, but different social rules.
To solve the ambiguity of pedestrian interaction with semantic segmentation and make the scene information guide pedestrian future movement more accurately, DTDNet uses the method of STHGLU (Wang et al., 2022) to get the probability heatmap of each scene generated from historical trajectory collections. This method could provide the distribution of pedestrian movable area and the corresponding probability information. Coarse-precision coordinates keeps the spatial location information of the scene, combined with the regional information to get the local scene information.
Assuming that the coarse precision of the scene is R = m×n, we divide each sub-region with the precision of 9 × 9, and obtain the global scene information with the precision of R = 81 × m×n. At each moment, the model dynamically models the local scene s based on the pedestrian coarse-precision coordinate, provides information to guide the pedestrian future movement and avoid the pedestrian moving into the unreasonable area.
3.3 Motion pattern encoding sub-networkAs shown in the upper blue part of Figure 2, the backbone of motion pattern encoding module is GRU, which inputs the fine-precision coordinates of pedestrians to model the motion pattern feature of pedestrians.
In Equation 1, we encode three input trajectory data including the position xt, yt, velocity Δxt, Δyt and acceleration axt, ayt to the pedestrian motion hidden representation et. In addition to the pedestrian motion state et, as shown in Equation 2, the model includes the pedestrian target intent vector gt. At each moment, the endpoint decoding module uses the MLP as fgoal to map the output of GRU to the endpoint coordinates p^gt of pedestrian, as shown in Equation 3. The goal prediction is trained with Lossdes, as shown in Equation 4. The goal prediction is trained with Lossdes, which is the distance between the real and the predict goal. Generation of the target intention vector gt from ht will be introduced in detail in Section 3.4.2.
et=fe(xt,yt,Δxt,Δyt,axt,ayt;We) (1) ht=GRU(ht-1,eit,gt;WGRU) (2) p^gt=fgoal(ht;Wgoal) (3) Lossdes=MSE(p^gt,pg) (4) 3.4 Dynamic pedestrian target prediction 3.4.1 Multi-precision pedestrian intention analysis sub-networkIn the model, the output ht is used to predict the pedestrian target coordinates at each time step, using the mean square error as loss can not guarantee complete converge at. In order to model the pedestrian's target intention and achieve a better convergence effect, we design a pedestrian dynamic intent prediction sub-network to update the pedestrian's intent dynamically.
The model input of the sub-network consists of three parts: the fine-precision coordinate pf, the coarse-precision coordinate pc, the scene information s. It is the same as Equation 1, the multi-layer perceptron encodes the fine-precision pf and coarse-precision pc coordinate and obtains embeddings ef and ec, respectively. As shown in Equation 5, the model uses the convolutional neural network (CNN) to encode the local scene information st to obtain hst.
hst=CNN(st;Wcnn) (5)In order to model the time series features and fuse them with the modeling information of the main network, we also use GRU to model the sequence of three kinds of information input by the sub-network. As shown in Equation 6, the input of the GRU model of the sub-network contains eft, ect, hst three dimensions of information, the output hsubt is the intent embedding predicted by the sub-network at time t, and WGRUsub is the training parameters.
hsubt=GRUsub(hsubt-1,eft,ect,hst;WGRUsub) (6) 3.4.2 Multi-precision pedestrian intention analysis sub-tasksTo extract the pedestrian intention feature, in addition to predicting the fine-precision coordinates of the target coordinate, DTDNet proposes two additional sub-tasks to model the pedestrian intent information, namely predicting the coarse-precision endpoint region and score the pedestrian intent destination region.
The first sub-tasks is shown in Equation 7. The model uses the MLP ff to map the pedestrian motion intention embedding hsubt to predict the fine-precision coordinates of the pedestrian intention, where Wf are trainable parameters.
p^f=ff(hsubt;Wf) (7)The second sub-tasks is shown in Equation 8. The model uses the MLP fc to map the pedestrian motion intention vector hsubt to predict the coarse-precision coordinates of the pedestrian's endpoint, where Wc are the model update parameters.
p^c=fc(hsubt;Wc) (8)The third sub-task is to estimate the likelihood of all sub-regions. First, the model uses the MLP fscore to map hsubt, where Wscore are the model update parameters. Then uses the Softmax function to score R = m×n sub-regions in the scene, as shown in Equation 9. Because there is only one ground truth region, we set the score of the true region to 1 and the scores of other regions to 0.
score=Softmax(fscore(hsubt;Wscore)) (9)Through the above introduction, the loss function of the sub-network consists of three parts as shown in Equation 10. Where p^ is the endpoint coordinate predicted by the model, p is the actual endpoint coordinate, score is the region scoring result, the label is the actual region scoring label, and LCE is the cross-entropy function.
Losssub=RMSE(p^f,pf)+RMSE(p^c,pc)+LCE(score,label) (10)However, since the current sub-network and the main network are decoupled, the main network cannot use the sub-networks loss function to assist in the model update. In order to use the back-propagation of the model to update the two networks synchronously, we design two network fusion schemes to couple the two parts of the network.
The first method is to fuse the motion state of the main network with the important scene information selected by the sub-network. The sub-network of the model scores the importance of m×n sub-regions at each moment and selects the Top K with the highest scores. The target sub-region is used as the key region, and the CNN shown in Equation 5 encodes the selected K regions, respectively.
hst=∑j=1Kscorej×hsj (11)After encoding K regions, the model uses Equation 11 to fuse K scene information to obtain the crucial regional information that pedestrians need to consider. Finally, the multi-attention mechanism and residual connection are used to combine the two networks to get the target intention vector gt.
sr=Softmax(<WQhrt,WKhs,rt>D) (12) gt=∑r∈sr·(WVhs,rt)+ht (13)Where < ·, ·> is the inner product operator, and r∈, WQ, WK and WV are trainable parameters, ht is the output of the motion encoding network GRU of time step t, D is the embedding dimension of ht, p is the number of heads in the multi-head attention mechanism, sr is the attention score, and gt is the target intent embedding.
The fusion method introduced in Algorithm 1 directly combines K important scene information, which may introduce excessively artificially set rule information. It is difficult to determine the optimal value of parameter K. Therefore, we attempt to directly fuse the output hsubt of the sub-network with the GRU output ht of the main network using the attention mechanism introduced in Equations 12, 13.
3.5 Trajectory decoding sub-networkThis sub-network utilizes CVAE based framework to generate multi-modal trajectories. CVAE framework is composed by an encoding module and a decoding module. The encoding network is further divided into a recognition distribution network qψ(z|Ph, Pf) and a prior distribution network pθ(z|Ph) given future ground truth trajectory as Pf={Pt,t∈[Tobs+1,Tpre]}.
As shown in Equation 14, the model encodes the pedestrian historical and future motion feature, and generates the mean μ and variance σ corresponding to a Gaussian distribution, and samples high-dimensional latent variable z from Gaussian distribution N(μ, σ). Then combines the sampled high-dimensional latent variable z with the GRU output ht to obtain the hidden state hdect, and iterate the hidden state at each time step, as shown in Equations 15, 16. Finally use the decoding module Equation 17 to predict the complete future trajectory.
μ,σ=qψ(z|Ph,Pf),z~N(μ,σ) (14) hdecTobs=fmlp(hTobs⊕z;Wmlp) (15) hdect+1=D-GRU(hdect,fpred(x^t,ŷt;Wpred)) (16) x^t+1,ŷt+1=fdecoder(
留言 (0)