
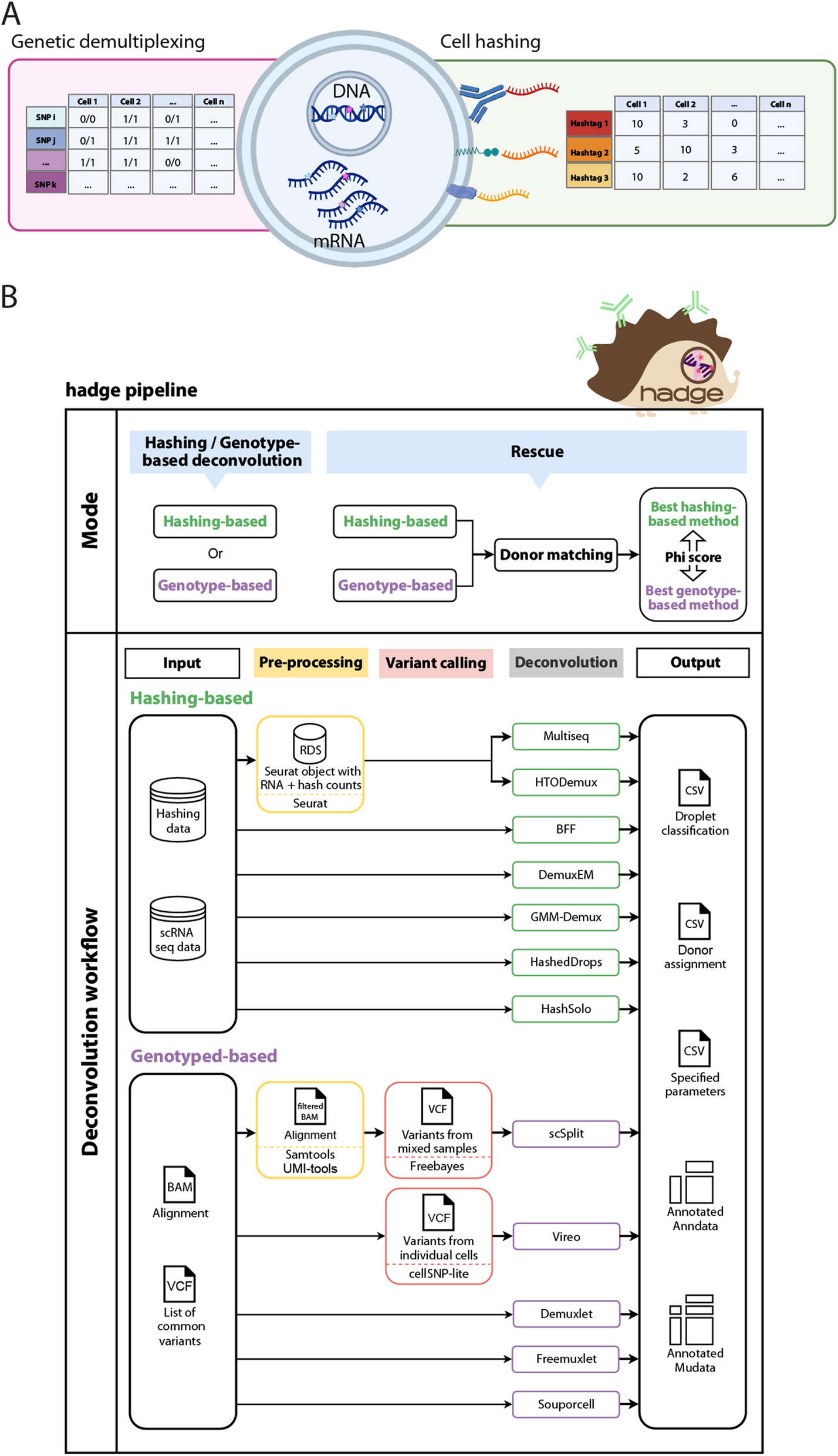
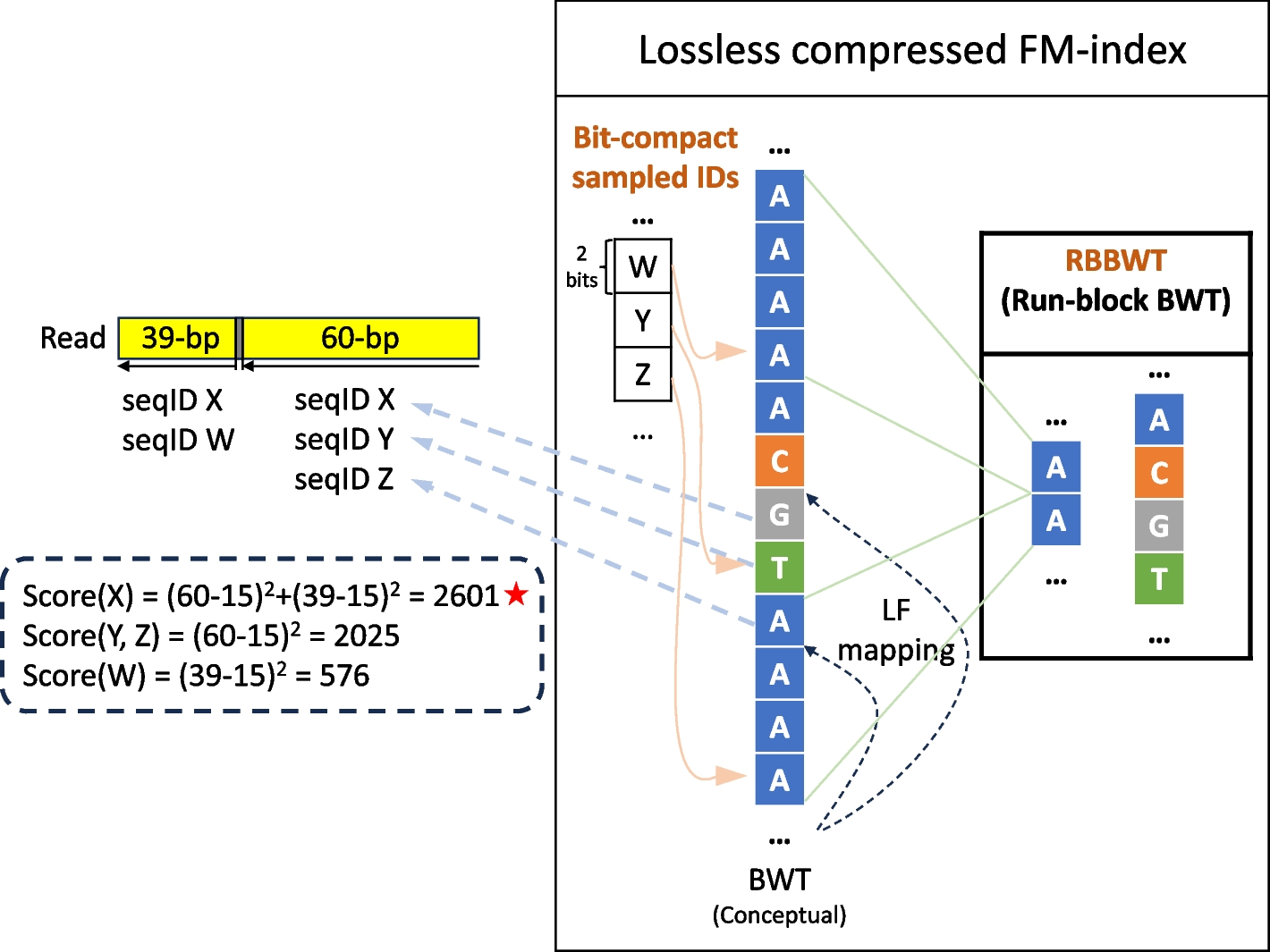
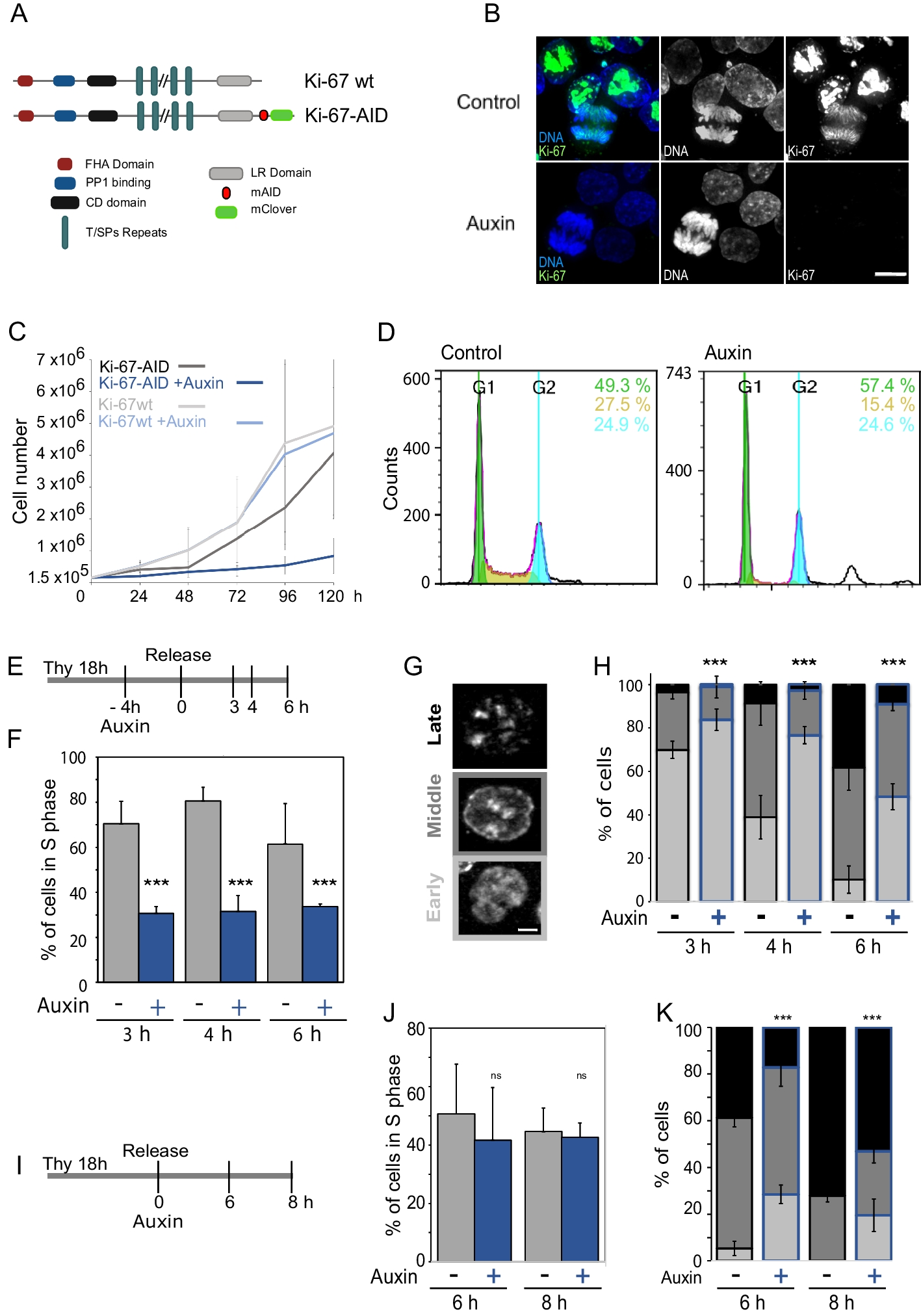
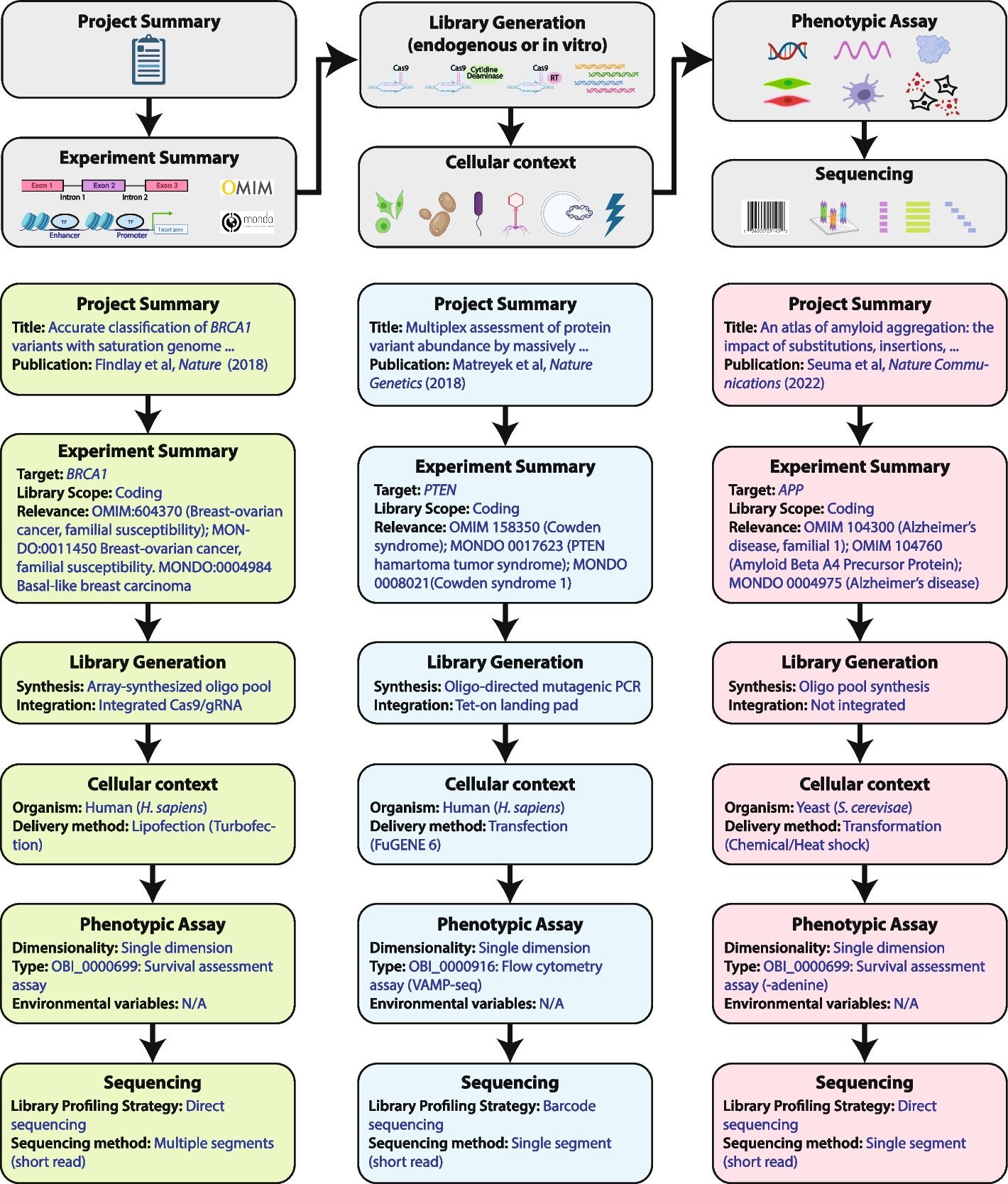
記住我






Scoary2 retains all features that are already familiar to users of original Scoary [14]. As in Scoary, the two basic inputs are (i) a table that describes the genotypes (orthogenes, SNPs, k-mers, unitigs) present in all isolates and (ii) a table containing the trait(s) of the isolates. These function as explanatory and response variables, respectively. Like in original Scoary, for each trait, Scoary2 generates a list of significant genotypes per trait as output.
Furthermore, the scope and user-friendliness of Scoary have been significantly improved by enhancements and optimizations in Scoary2. The main improvement of Scoary2 is the addition of an interactive data exploration app which greatly facilitates the exploration of the output. To this end, metadata files describing the genotypes, traits, and isolates can be added as input. Moreover, unlike original Scoary, Scoary2 can perform multiple testing correction for all p-values that are generated using Fisher’s test and not just per phenotype. Finally, Scoary2 is significantly faster than the original Scoary software.
A manual [15] as well as a tutorial [16] detailing how to use Scoary2 are available on GitHub. Below, we describe the improvements over original Scoary in detail.
Performance enhancementsThe original Scoary software only had one software dependency (SciPy [17]) and the entire software was implemented using Python-native data structures (i.e., lists and dictionaries) only. In general, Scoary2 uses the efficient NumPy [18] and pandas [19] libraries to load and process the data. Most importantly, the pairwise comparison algorithm was reimplemented, drastically reducing the number of phylogenetic tree traversals. Gene-presence-absence and trait-presence-absence data are now represented as Boolean NumPy arrays, enabling just-in-time compilation of the pairwise comparison algorithm using Numba [20]. To determine the time complexity of this most time-consuming step and compare the new implementation to the original one, we applied both algorithms to randomly generated datasets with varying numbers of genes and genomes. The results are visualized in Additional file 1: Fig. S1. Using symbolic regression, we determined that the most parsimonious formula for computing the runtime is given by this equation: \(}=\mathrm\times _} \times _}\). The new implementation is around 30x faster than original Scoary. In addition, confidence intervals in the permutation test only depend on the topology of the gene and the number of isolates with the trait. In a dataset with many traits, the same confidence intervals may be used many times. Thus, caching confidence intervals in an SQLite database [21] reduces the number of times this expensive algorithm is executed. The modular software design makes it possible to import the pairwise comparison from the Scoary2 Python module and re-use the algorithm in different programs. Another substantial speed boost comes from enabling true multiprocessing during binarization and analysis of traits using the producer/consumer software architecture pattern. Also, Scoary2 uses a just-in-time-compiled implementation of Fisher’s test (available as a standalone Python library [22, 23]) which is orders of magnitudes faster than the reference implementation in SciPy. Moreover, original Scoary is limited to analyzing datasets with less than 3000 isolates due to Python’s recursion limit. By dynamically adjusting this limit, Scoary2 can now analyze datasets with up to 13,000 isolates.
Using equivalent settings, Scoary2 is about 59 times faster (23 sec vs 22 min) at analyzing 100 randomly selected traits from the dataset described in this paper (44 isolates, 9051 genes). Scoary2 takes only 16 minutes to process our full dataset (3889 traits, 182 isolates, 10,358 hierarchical orthogroups) with the parameters n_cpus = 8, multiple_testing = bonferroni:0.1, n_permut = 1000, max_genes = 50, trait-wise-correction = True. The reduced dataset presented in this paper (3889 traits, 44 isolates, 1466 hierarchical orthogroups) takes only 43 s to process with the parameters n_cpus = 8, multiple_testing = bonferroni:0.999, n_permut = 1000, trait-wise-correction = True. All measurements were performed on a laptop with an Intel i7-1355U CPU (10 cores, 1.70-5 GHz).
Software distributionScoary2 can be installed using the python package manager (pip) or used through an official docker container, where all dependencies are bundled, guaranteeing easy installation far into the future, thus ensuring reproducibility.
Binning of continuous phenotypesThe core algorithm of Scoary is based on binary genotype and phenotype data. Scoary2 is newly capable of automatically pre-processing continuous phenotypes into binary ones. This enhancement is essential for datasets with so many traits that they cannot be curated manually, though this is otherwise recommended. For this purpose, two Scikit-learn [24] methods, k-means and Gaussian mixture model, are available. The former will classify all isolates as having or lacking the trait. The Gaussian mixture model seeks to fit two Gaussian distributions and calculates the probability of each isolate having or not having the trait. By default, isolates that are classified with less than 85% predicted posterior probability are ignored from further analysis. The fitting of Gaussian mixture models can fail, and the user can decide whether to skip such traits or use k-means as a backup instead. In the data exploration app, the original continuous values are used again to calculate a histogram. To assess the power of the automatic binarization, we simulated genomic datasets of varying sizes, see Fig. 1 and the “Methods” section for details.
Fig. 1
Benchmarking of Scoary2’s automatic binarization based on simulated datasets for different effect sizes. Panels on the left show the distributions from which the numeric phenotype was sampled based on the presence or absence of a designated causal gene. Panels on the right indicate the rank of the causal gene in the output of Scoary in relation to the number of genomes in the simulated dataset. The black line indicates the average rank and the grey area indicates 90 % confidence interval based on 20 simulations
OrthoFinder supportThe name Scoary was chosen in homage to the orthology inference software Roary [25], which transformed bacterial comparative genomics in 2015 thanks to its speed and user-friendliness [26]. However, Roary does not seem to be under active development anymore and was not included in recent Quest for Orthologs benchmark studies [27]. Today, OrthoFinder is the most accurate ortholog inference method according to this benchmark [27, 28]. It is under continued development and is among the most used tools in the field. As input, original Scoary uses Roary’s gene-count table, which indicates how many genes per orthogroup each genome has. However, this makes it cumbersome to find the relevant genes of an interesting orthogroup. While Scoary2 is still compatible with the gene-count table, it is highly recommended to use the gene-list table, produced by both Roary and OrthoFinder, where cells contain a list of gene identifiers. This way, the gene names will be shown in the data exploration app.
Output and data exploration appScoary2 produces similar tables as output as original Scoary. As San et al. [5] indicated, the ability to add annotations to orthogroups would “contribute immensely” to the utility of mGWAS tools. For datasets with many phenotypes, this is absolutely essential. Therefore, Scoary2 does not just allow to add metadata to orthogroups but also to traits and isolates. In addition, Scoary2 contains a simple data exploration app for easy inspection of the results. It was built using the JavaScript libraries Bootstrap, Papa Parse, Slim Select, DataTables, Plotly, and Phylocanvas [29,30,31,32,33,34]. The data exploration app was developed to be available as a standalone software library [35] which could be re-used for other mGWAS tools, further extending its usefulness. It consists of two pages (overview.html and trait.html), which are described in next two paragraphs.
The first page, overview.html (Fig. 2), shows a dendrogram of all traits with a significant association to at least one gene. By default, the dendrogram is calculated using the Pearson correlation coefficient for numeric traits and the Jaccard index for binary traits. The distance metrics are made symmetrical to ensure that highly correlated and highly anti-correlated traits end up close to each other in the dendrogram. The negative logarithms of the corrected p-value from Fisher’s test, the p-value from the permutation test, and the product of the two values are presented next to the dendrogram. These plots, created with SciPy and matplotlib [17, 36], can show at least 20,000 traits. When the mouse pointer hovers over a trait, the associated metadata is presented.
Fig. 2
The first page (overview.html) of the Scoary2 data exploration app. A Dendrogram of traits. A cluster of carnitine-related traits is highlighted in yellow; the highest-scoring trait is selected (blue). B Negative logarithms of the p-values calculated by Scoary2: p-values range from high (left) to low (right); f stands for the p-value from Fisher’s test, e for the p-value from the post hoc test, and * for the product of the two values. C Trait names. D Trait search and navigation tool. E Trait metadata. It is updated when the mouse hovers over the traits in the dendrogram. F Plot legend
The second page, trait.html (Fig. 3), allows users to further investigate each trait. This page includes a phylogenetic tree of the isolates, where color bars indicate which isolates have the trait and which have a selected orthogroup. In addition, a pie chart shows the fraction of isolates that have the trait and how many of these have the gene. If the trait data is continuous, a histogram is also displayed. These plots are updated whenever the user clicks on an orthogroup. Below the phylogenetic tree, there are two tables. The first displays the Scoary statistics and, if present, metadata for each orthogroup. The second table is a coverage matrix, which shows the number of genes each isolate has from each orthogroup. If the isolates have metadata, this information is also displayed in this table. If Scoary2 uses an OrthoFinder-style gene-list table as input, clicks on these numbers reveal the gene identifiers. Moreover, the data exploration app can be configured to generate hyperlinks, such that clicks on gene identifiers forward the user to a certain URL, for example one where more information about the gene is available, such as its sequence and annotations. Clicks on orthogroups can also be configured to redirect to custom URLs, for example to enable a comparison of the genes.
Fig. 3
The second page (trait.html) of the Scoary2 data exploration app. A Trait name. B Phylogenetic tree of the isolates. C Top row: presence (black)/absence (white) of orthogene. Middle row: binarized trait. Bottom row: continuous trait. D List of best candidate orthogenes with associated p-values. E Coverage matrix: The numbers in the cells tell the number of genes in the genome that have the annotation. F Pie chart that shows how the orthogene and the trait intersect in the dataset. G Histogram of the continuous values, colored by whether each isolate has the orthogene (g+/g−) and the trait (t+/t−)
Analysis of yogurt datasetOverview of the full datasetTo illustrate the problem of taxonomy-based clustering of bacterial metabolome data using real data, Fig. 4A/B show 2D embeddings of the full LC-MS and GC-MS volatiles datasets (182 strains) that was generated using uniform manifold approximation and projection (UMAP) [37]. Notably, yogurts made with closely related strains tend to cluster together. Both datasets show one cluster dominated by yogurts made with strains from the order Propionibacteriaceae and another dominated by Lactobacillales. This means that most correlations between genes and traits are simply due to population structure and to find promising links between genes and traits; mGWAS methods are indispensable.
Fig. 4
UMAP projections of mass spectrometry datasets. Each symbol represents one yogurt that was made with a different bacterial strain in addition to the starter culture YC-381. A LC-MS dataset: 2348 metabolites. B GC-MS volatiles dataset: 1541 metabolites. C Legend: each (sub-)species has a unique combination of color and symbol. The number in brackets indicates the number of yogurts made using the respective (sub-)species
However, since the analysis of the full dataset would go beyond the scope of this publication and the results can be replicated by restricting the dataset to the 44 Propionibacterium freudenreichii isolates, only this selection of data is shown.
Scoary2 resultsInitially, Scoary2 was employed on the dataset with multiple testing parameters suited to yield robust results (multiple-testing = fdr_bh:0.1). Because traits without at least one gene with a significant Fisher’s q-value are automatically removed from the output, only 20 metabolites remained [38].
To explore the relationship of these 20 metabolites within a broader context, we applied Scoary2 again with relaxed multiple testing parameters (trait-wise-correction = True, multiple-testing = bonferroni:0.999) [39]. This adjustment yielded an output comprising 707 traits, including many false positives. As illustrated in Fig. 2, the original 20 metabolites persisted in the same dendrogram group, indicating strong correlation or anti-correlation. A few additional metabolites were also grouped with the original metabolites, further enriching the contextual understanding. Because each metabolite’s metadata is available in overview.html (Fig. 2E), we quickly noticed that the MS database putatively labeled 14 out of 26 of the metabolites in this group as compounds with carnitine in their names (Fig. 5D).
Fig. 5
Abundance of the metabolites that correlate with the putative carnitine transporter and corresponding gene loci of three yogurts made from starter cultures only and 44 yogurts made with additional Propionibacterium freudenreichii isolates. The figure is divided into two parts, depending on the completeness of the carnitine gene cluster of the isolates: the isolates on a blue background have a complete gene cluster, and the isolates on a red background have an incomplete gene cluster, resulting in varying metabolite compositions. A Heat map of the scaled metabolite abundances. Scale: blue (low) to average (white) to red (high). B Scale factor of each metabolite. C Color bar that indicates whether the mass spectrometry database suggested a match with carnitine in the name (green) or not (grey). The suggested names are shown below. Names highlighted in green were confirmed with standard substances. D Comparison of the associated gene cluster spanning from the MFS transporter (red) to fixX (dark blue). E Annotations of the orthogroups. Genes that belong to the same orthogroup are highlighted in the same color. The caiABC genes are colored in shades of green and the fixABCX genes in shades of blue. The putative carnitine transporter and hydrolase identified using Scoary2 are highlighted in red and violet, respectively
Looking at the results in more detail using trait.html, shown in Fig. 3, we found that two genes correlate strongly with these metabolites: an MFS transporter and an α/β-hydrolase fold domain-containing protein. A closer look at the gene identifiers suggests that the two genes are adjacent. Furthermore, the gene loci (Fig. 5E/F) were compared using OpenGenomeBrowser [40] via custom URLs as mentioned earlier, revealing that the two genes are indeed adjacent and located in a syntenic gene cluster, one gene away from an L-carnitine CoA transferase (caiA). In the isolates which lack the two genes, many of the clusters were seemingly disjoined by transposases and other genes on the cluster were pseudogenized (Fig. 5E/F).
Confirmation of identities for carnitine compoundsThe identities of five metabolites (decanoylcarnitine, octanoylcarnitine, hexanoylcarnitine, carnitine and acetylcarnitine), assigned to the gene cluster detected by Scoary2 (Fig. 5D), were subsequently confirmed by LC-MS analysis of pure analytical standard solutions (Table 1).
Table 1 List of MFS-transporter-associated metabolites that were confirmed by standard injectionCompared to yogurt made from starter cultures only, we found that two thirds of the Propionibacterium freudenreichii isolates did not strongly affect the composition of the carnitine-related metabolites shown in Fig. 5. These yogurts are characterized by high amounts of certain acylcarnitines. In contrast, the presence in isolates of the two genes identified by Scoary2 (MFS transporter and α/β-hydrolase fold domain-containing protein) did influence the abundance of those acylcarnitines. Yogurts prepared using such isolates contain depleted amounts of acylcarnitines, particularly octanoylcarnitine and decanoylcarnitine, and are characterized by higher amounts of carnitine, γ-butyrobetaine (putative), and certain other (putative) acylcarnitines.
Literature completes the pictureInterestingly, the cluster includes the caiABC and fixABCX genes, which are associated with the anaerobic metabolism of carnitine [41]. Homologs of fixABCX were originally characterized in Rhizobium meliloti where they function as a respiratory chain, providing electrons for nitrogen fixation [42]. The genes caiABC were first identified as part of the E. coli caiTABCDE operon, which is close to and co-expressed with the fixABCX operon and together ferment carnitine to γ-butyrobetaine in anaerobic conditions and absence of preferred substrates [41, 43, 44]. This biochemistry is summarized in Additional file 1: Fig. S2. However, the selected Propionibacterium freudenreichii isolates are lacking homologs of the crotonobetainyl-CoA hydratase caiD and the carnitine/γ-butyrobetaine antiporter caiT. Instead, between caiABC and fixABCX, we find an MFS transporter and an enoyl-CoA hydratase, which might fill these gaps in the pathway. On the other hand, the two genes identified by Scoary2 are also an MFS transporter and a hydrolase, and since only the strains with these genes have a strong impact on the carnitine composition of the yogurt (Fig. 5), it appears that the full operon is required to permit efficient import of precursors and fermentation of carnitine in Propionibacterium reichii. This is supported by the apparent degradation of the gene cluster through transposases and pseudogenization in many genomes where the two genes were lost.
留言 (0)