
記住我









The human brain contains approximately 100 billion neurons, making it the most complex organ in the human body. The brain organizes itself through various means such as synaptic connections, forming a complex neural network that dominates our consciousness and behavior (Poo et al., 2016; Sala et al., 2022; Thiebaut de Schotten and Forkel, 2022). Increasing research findings have indicated that the implementation of advanced human functions relies on the connections and communication between different brain regions (Sporns et al., 2005; Yan et al., 2019). In other words, the realization of brain functions primarily depends on highly complex interactions between different areas of the brain in a large-scale network. As a result, the concept of the brain as a network is gaining widespread attention from researchers and clinical practitioners. Currently, the study of interregional relationships in the brain relies heavily on functional connectivity analysis. This method involves analyzing the correlation of neurophysiological activities between brain regions in terms of temporal and frequency domains. It provides objective quantification and interpretable metric information, contributing to the understanding of cognitive function principles and the detection of neurological disorders.
Epilepsy, as a typical neurological disorder, is caused by abnormal neuronal discharges in the brain, leading to a disruption of neural functions. The pathogenesis of epilepsy has been confirmed to be associated with abnormalities in functional connections between relevant brain regions (Shuting et al., 2019; van den Heuvel and Hulshoff Pol, 2010). Neuroscientists are paying attentions to the tools and concepts of network science on a widespread basis, applying them to researches in brain science. These tools and concepts allow for a consistent description and interpretation of interactions among various neural systems within the complex topology of the brain and its networks. This approach has been proven to be successful in systems biology and social network analysis (Michel et al., 2004; Sakkalis, 2011; Fornito et al., 2016; Presigny and De Vico Fallani, 2022).
For the collection of electroencephalographic (EEG) signals, the commonly employed method is electroencephalogram (EEG). EEG is a technique that utilizes electrophysiological metrics to record brain activities. It captures the electrical wave changes during brain activity, serving as a comprehensive reflection of the electrophysiological activity of brain neurons on the cerebral cortex or the surface of the scalp. In recent years, the use of EEG for epileptic seizure detection has drawn widespread attention in the academic circle due to its advantages of easy collection, affordability, and high temporal resolution of data. The installation of EEG collecting channels follows the international 10–20 system, which provides precise positions for channel installation. Each channel’s location corresponds to specific brain regions, facilitating the possibility of analyzing interregional relationships in further analysis (Ein Shoka et al., 2023).
(1) for the first time, proposing the neural network model that is based on hypergraph convolution and suitable for epilepsy detection. The model extracted features from each channel by using Conv-LSTM module and PSD, constructed hypergraphs respectively based on the extracted features, and then realized automatic epilepsy detection by adopting hypergraph convolution.
(2) conducting comprehensive experimental tests on the TUH epilepsy dataset and the CHB-MIT scalp EEG dataset to validate the model’s performance. The result indicates that the model can achieve optimal detection performance in epilepsy detection tasks. This approach provides valuable reference for clinical epilepsy detection.
This study is structured as the following: Part 1 provides an overview. Part 2 introduces relevant technologies in epilepsy detection. Part 3 proposes the epilepsy detection model based on multi-dimensional feature extraction and dual-branch hypergraph convolutional network. Part 4 presents the comparative experiments with relevant literature by adopting benchmark dataset. Part 5 discusses the model’s superiority through ablation experiments and various parameter configurations. Part 6 gives the conclusion.
Regarding the task of neurological disease detection, existing detection methods are often as the following: 1) Artificial feature extraction is adopted, and the extracted features are calculated by filtering and energy evaluation algorithms such as Multi-variable Fast Iterative Filter (MFIF) (Sharma et al., 2023) and dynamic approximate entropy (Zhang et al., 2023). Then the data is classified by machine learning, for example, decision tree classifier (Nithya et al., 2023) and random forest (Sharma et al., 2018). 2) Applying deep learning model to automatically extract features and performing classification.
In the application of epilepsy detection, some researchers used individual patients’ historical data to train models and then applied these models to test new data from the same patients. Representative achievements in this area include: Hu et al. (2020) proposed an epileptic seizure detection method based on the deep bidirectional long short-term memory (Bi-LSTM) network, achieving an average sensitivity of 93.61% and an average specificity of 91.85% on the long-term scalp EEG database. To address the challenge of limited data samples in individual patient detection tasks, Yang et al. (2022) introduced a specific patient epilepsy detection and analysis method based on data augmentation and deep learning, this approach achieved an average accuracy of 95.47%, an average sensitivity of 93.89%, and an average specificity of 96.48% respectively on the CHB-MIT dataset. Zhou et al. (2018) proposed an epileptic seizure recognition model based on convolutional neural networks (CNN), achieving an average accuracy of 97.5% on the CHB-MIT dataset. Poorani and Balasubramanie (2023) presented a one-dimensional CNN model and a hybrid CNN-LSTM model, where the one-dimensional CNN model achieved an average accuracy of 91.50%, and the CNN-LSTM model achieved an average accuracy of 92.11% on the CHB-MIT dataset. Similarly, Wang et al. (2023) also used the persistent homology method to calculate the complex filter bar code of virtual reality on the CHB-MIT dataset to extract topological features and input them into GoogLeNet for classification. The average accuracy, sensitivity and specificity were 97.05%, 96.71%, and 97.38%, respectively. However, these methods are limited to training and testing on individual subjects, having poor model generalization.
Another research approach involves designing network models with generalization capabilities and utilizing leave-one-out cross-validation. Specifically, this method involves partitioning epilepsy datasets with data from multiple patients. One patient’s data is selected for testing, while the data from other patients are used for training. This approach enhances the model’s generalization capability. Representative achievements include: Zhang et al. (2020) employed feature separation and adversarial representation learning to decompose data into category (seizure and normal) relevant features and patient-specific features, achieved an average accuracy of 80.5% on the TUH EEG dataset. Dissanayake et al. (2021) utilized CNN network structure and Siamese network structure, achieved an accuracy of 88.81% on the CHB-MIT dataset. Yang et al. (2023) applied feature separation adversarial training, achieved an average accuracy of 85.7% on the TUH EEG dataset.
The two aforementioned approaches involve overall feature extraction from a data segment without capturing information transmitting among channels. However, for epilepsy EEG data, the interregional relationships in the brain are highly relevant to seizure patterns, which includes higher-order information of EEG signals and holds important reference significance for epilepsy detection. In the exploration of advanced network feature information from data, researchers have conducted extensive work. Feng et al. (2019a) were among the pioneers who introduced hypergraph neural networks, while Yadati et al. (2019) proposed hypergraph convolutional networks. Jiang et al. (2019) introduced a dynamic hypergraph convolutional neural network, this network utilizes KNN and K-Means to dynamically update the hypergraph structure, enhancing its ability to capture data relationships, it can extract both partial and overall relationships within the data.
In the field of brain science research, some researchers have proposed using graph models to describe pairwise relationships among multi-channel EEG signals. For instance, Zhang et al. (2019) introduced a graph-based hierarchical model that classifies motor intentions based on the relationships between EEG signals and their spatial information. Li et al. (2023) proposed a spatial-temporal hypergraph convolutional network (STHGCN) to capture higher-order relationships in EEG emotion recognition, achieved leading results on the SEED and SEED-IV datasets. Recently, Wagh and Varatharajah (2020) employed graph convolutional neural networks (GCNN) for the classification of epilepsy and normal data, achieving an AUC of 0.90. Currently, there isn’t related research found regarding the application of hypergraph convolution in the field of epilepsy detection. Therefore, taking use of hypergraph convolution can be considered as an important research approach for exploring higher-order information among brain regions in epilepsy patients.
In the study, we proposed an epilepsy detection model based on hypergraph convolution, as illustrated in Figure 1. The processing flow of the model consisted of three stages: 1) feature extraction stage, 2) hypergraph construction stage, and 3) hypergraph convolution stage. The approach in feature extraction stage was depicted in Figure 2. To thoroughly extract multidimensional features from the data, two parallel extraction methods were employed. PSD was used to extract spectral features, and Conv-LSTM neural network was utilized to capture spatiotemporal features. In the hypergraph construction stage, a hypergraph was generated by combining multidimensional features. Hyperedges were adopted to characterize the vertices connected to them, encoding high-order feature information to represent complex data structures in a more flexible manner. In the hypergraph convolution stage, a hypergraph spectral domain convolution method was applied to thoroughly extract high-order data features from epilepsy data, thereby enhancing the model’s generalization capability and classification performance.
The EEG is a bioelectrical signal generated by brain activity, which is characterized by uncertainty and randomness. Therefore, prior to analyzing raw data, preprocessing is necessary to eliminate the negative impact of different units and numerical ranges between features on subsequent data analysis. Additionally, it is helpful to improve data quality by adopting various interference elimination techniques, thus to enhance the accuracy of later analyses. This paper adopted min-max regularization technology (Sola and Sevilla, 1997) to regularize the EEG data. The min-max regularization method was shown as the formula (1):
where, Xi represented the original data, X represented the data after data regularization. Xmin and Xmax represented the minimum and maximum values in the original data.
After regularization of EEG data, in order to extract the features of EEG data, the EEG data were processed in segments. In the study, XM,N,T represented the collected EEG data, where M=1,2,⋯,m denoted the m−th subject, N=1,2,⋯,n denoted the n−th signal channel, and T denoted the length of original data. Additionally, for the purpose of facilitating feature extraction, the original data was segmented with a length of t. Then, the original data consisted of S=T/t EEG data segments, with each signal segment s∈S being represented as xm,s,n,t.
For data feature extraction, we proposed a dual-branch epilepsy feature extraction method in the study. It utilizes PSD to extract spectral features and the Conv-LSTM neural network to capture spatiotemporal features. By extracting data features from multiple dimensions, this approach can provide more information for hypergraph construction, ensuring that the model achieves higher classification accuracy.
PSD is a method for calculating the energy distribution of EEG signals at different frequencies from a frequency domain perspective. It helps reveal the essence of brain activity and function. Currently, the frequency domain features of EEG signals represent the most intuitive and convenient characteristics. They are widely utilized in the diagnosis and treatment of neurological disorders. By implementing this algorithm, it is possible to thoroughly extract the energy information of EEG data at different frequency bands, analyzing subjects’ changes in energy across different stages and frequency bands. Consequently, this provides reliable clues for the diagnosis and treatment of relevant neurological disorders.
For the process of extracting PSD features, the first step involved applying Fast Fourier Transform (FFT) to the input data xm,s,n,t (Yudhana et al., 2020), which was defined as Eq. (2):
where, FFT represented the Fast Fourier Transform operator, Ham denoted the Hamming window, and sft denoted the frequency domain sampling rate.
Then, performed PSD calculation as Eq. (3) on the obtained XFFTf (Alam et al., 2021):
where, L represented the length of signal. To extract the energy distribution features of data in different frequency bands, we extracted features from the following six sub-frequency bands: δ (0–4 Hz), θ (4–8 Hz), α (8–13 Hz), β (13–30 Hz), γ (30–80 Hz) and high-frequency oscillations HFO (80 Hz–120 Hz), obtaining the power spectral features P=pδ,pθ,pα,pβ,pγ,pHFO of the input data xm,n,t.
By integrating, we obtained the PSD features fPSD∈RM×S×N×6 for M subjects, all segments S, channels N, and 6 sub-frequency bands.
EEG signals are temporal signals, and solely capturing PSD features may not sufficiently acquire the spatiotemporal features of the signal. In the study, we employed the Conv-LSTM spatiotemporal convolutional network (Shi et al., 2015) to automatically extract one-dimensional spatial features and temporal features from EEG signals. This approach allows for a more comprehensive and in-depth extraction of EEG signal features, thereby enhancing the detection accuracy of the model.
In the study, we adopted LSTM networks, which are powerful in representing the extracted temporal domain features, and used the states and outputs of the network’s memory cells at each time step, to construct spatial convolutional norms learning and the sequential accumulation of effective signal features. Therefore, between adjacent time steps, parameters are selectively inherited, aiding in the construction of contextual information and ensuring the integrity of feature structures presentation.
In the current time segment S, the state and output of the LSTM memory cell were represented by Cs and fs−1 respectively, while Cs−1 and fs−1 represented the state and output of the cell in the previous time segment s−1. The calculation process for extracting features from a single-channel xm,s,1,t input was defined as Eqs (4)–(7):
where, ∘ and ⊕ represented Hadamard product and dimension concatenation respectively, ψ13×3 and ψ23×3 represented the feature tensor convolution and state tensor convolution for 3×3 respectively. The output of the spatiotemporal convolution branch fConv−LSTM∈RM×S×N×t was obtained by extracting features from all channels.
Building on the foundation of feature extraction, we constructed a hypergraph GF=V,E,W based on the distance relationships between features, with F∈fConv−LSTM,fPSD being the extracted feature set. Each EEG data channel serving as a vertex ν∈V in the hypergraph and each hyperedge e∈E being formed by connecting a vertex ν with its k-nearest neighboring vertices at the minimum Euclidean distance. Among which k∈2,3,4,5,6, five hypergraph adjacency matrices were formed. Each hyperedge e∈E contained two or more vertices and was assigned a positive weight We, forming a diagonal matrix WN×N from integrating all the weights. A hypergraph GF=V,E,W can be equivalently represented by V×E to be an adjacency matrix H∈RV×E, with entries defined as Eq. (8) (Feng et al., 2019b):
hν,e=yConv−LSTMqq=1Q and YPSD=yPSDqq=1Q.Through the dual-branch hypergraph convolution, we obtained the frequency domain features and spatiotemporal features representations of the data respectively. These two representations were then connected in a cascaded manner. Finally, label prediction was achieved through two convolutional layers ψ1×1 for 1×1 and the softmax function was defined as Eq. (14):
PX=softmaxψ1×1ψ1×1YConv−LSTM⊕YPSD(14)To complete the model training, we introduced the cross-entropy loss function in the study. The cross-entropy loss function measured the difference between the predicted probability distribution of the proposed model and the true probability distribution. During backpropagation, gradients were used to constrain the hyperparameters and convolutional parameters in the model, aiming to improve the model’s predictive accuracy. It was specifically represented by Eq. (15):
L=−P∗logylabel−1−P∗log1−ylabel(15)where, P∈0,1 represented the predicted probability of the network, and ylabel denoted the data label.
4 Experiments4.1 Datasets and evaluation metricsThe proposed model in the study was extensively evaluated on the publicly available dataset, TUH epilepsy dataset (Obeid and Picone, 2016), to thoroughly assess and validate the effectiveness of the model and its components. The dataset included 2,993 records of at least 15 min duration obtained from 2,329 unique patients and consisted of a developed and separate final assessment set. It contains records of male and female patients from a variety of age ranges (7 days −96 years), and therefore includes infants, children, adolescents, adults, and elderly patients. Pathologies diagnosed in patients in the dataset include (but are not limited to) epilepsy, stroke, depression, and Alzheimer’s disease, however, only binary labels are provided. The dataset includes physician reports that provide additional information about each EEG record, such as major EEG findings, the patient’s ongoing medication, and medical history. In the description of the dataset, TUH reported an inter-rater confidence of 97%–100%. In the literature, the reported scores are usually much lower. The nearly perfect rating may be the result of a review of the survey results by medical students who were aware of the diagnosis in advance. The dataset followed the international 10–20 system to perform channel installation and data collection, with 21 channels and a sampling rate of 250 Hz. We randomly selected subjects with seizure duration being more than 250 s, forming 14 TUH subsets as the experimental datasets. For each subject, we used 500 s of EEG signals (half normal data and half seizure data), with each EEG segment having 250 sampling points (lasting for 1 s), i.e., t = 250, and adjacent segments overlapping by 50%. For each EEG segment, the seizure state ones being categorized as positive were assigned a label of 1, while the normal state ones being categorized as negative were assigned a label of 0. Then, the 14 TUH subsets were divided into training set and testing set according to leave-one-out cross-validation.
The leave-one-out cross-validation method used in this paper is a special cross-validation method. Specifically, the TUH dataset contains 14 patient data subsets, and through 14 experimental trainings, only 1 patient sample is retained as the validation set each time, and the remaining 13 patients are used as the training set. Because each sample is independently verified, the model is not affected by the division of training set and verification set, and the validity and robustness of experimental data are guaranteed. To be more specific, the designed diagnosis model with robustness must handle both intra-patient factors and inter-patient noise to embrace clinical and more complex situations needs such as patient-independent: the testing patient is unseen in the training stage (Zhang et al., 2020). Therefore, the leave-one-out cross-validation method provides a patient-independent validation of the differences in data structures among patients during training and testing. The high average accuracy obtained by leave-one-out cross-validation method can reflect the anti-noise interference ability and robustness of the proposed model. At the same time, we evaluated the training time and test delay of our method. The results showed that the test required only 0.03 s (0.01 s for EEG decomposition and 0.02 s for attentional epilepsy diagnosis), while a single training session required 1,852.7 s. In conclusion, in a potential online seizure diagnosis system, the diagnostic delay of our approach is acceptable.
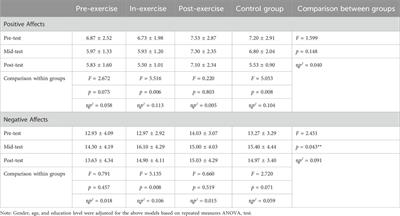
At the same time, we used the epilepsy scalp EEG dataset from Boston Children’s Hospital, United States (Goldberger et al., 2000), which is named as CHB-MIT scalp EEG, to further verify the validity of the proposed model. This dataset contains 24 consecutive scalp EEG recordings from 23 patients. The first and 21st records were from the same patient, and the 24th record did not provide personal information. The dataset followed the international 10–20 system to perform channel installation and data collection with a signal sampling frequency of 256 Hz and a resolution of 16 bits per second. In the dataset, 23 channels were used for most records. For the convenience of research, only EEG data containing 23 channels were retained in this paper, and records with channel number less than or greater than 23 would be discarded. The number of channels recorded in the 12th and 15th sections was not sufficient for the requirements of this experiment, so the data recorded in the 12th and 15th sections were discarded. Table 1 shows the personal information and the number of seizures recorded in the CHB-MIT scalp EEG dataset.
F1=2Pre⋅RePre+Re(19)
Table 1. CHB-MIT scalp EEG dataset information.
In the above equations from (16) to (19), TP (True Positive) denoted the samples judged as positive that are actually positive, TN (True Negative) denoted the samples judged as negative that are actually negative, FP (False Positive) denoted the samples judged as positive that are actually negative, FN (False Negative) denoted the samples judged as negative that are actually positive.
4.2 BenchmarkOn the TUH dataset, using the same data segment length and employing leave-one-out cross-validation, we compared our approach with seven other methods. The comparative results of ACC are presented in Table 2 and Heatmap in Figure 3. Meanwhile, the comparison results of multiple indicators are shown in Table 3.
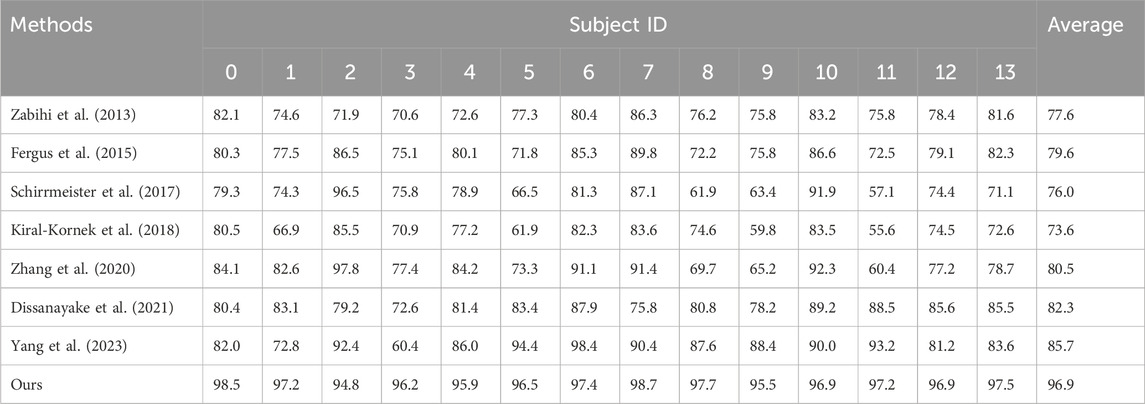
Table 2. Comparative results.
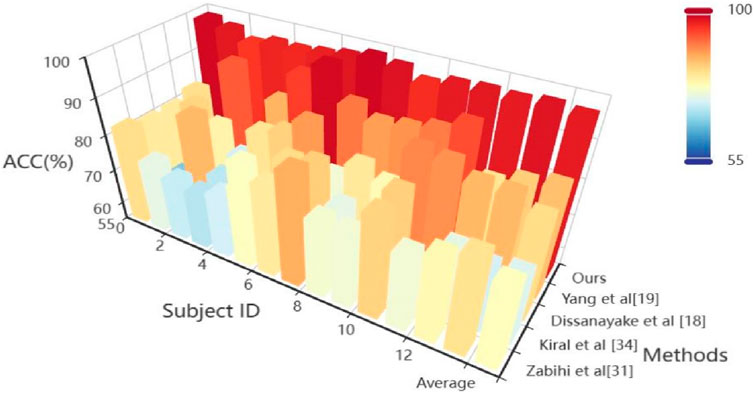
Figure 3. Heatmap visualization results from the comparative experiment.
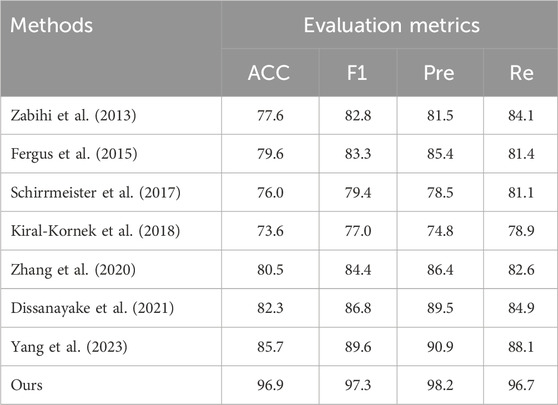
Table 3. Comparison results of multiple indexes.
Zabihi et al. (2013) used discrete wavelet transform (DWT) to calculate indicators such as relative scale energy and Shannon entropy as features. Support vector machines are used for data classification.
Fergus et al. (2015) used PSD and calculated metrics such as peak frequency and maximum frequency as features; KNN is used for data classification.
Schirrmeister et al. (2017) used convolutional neural networks to decode task-related information from EEG signals to distinguish epileptic fragments.
Kiral-Kornek et al. (2018) designed deep neural networks for epilepsy diagnosis and further developed predictive systems for wearable devices.
Zhang et al. (2020) propose an adversarial representation learning strategy to achieve robust and interpretable seizure detection.
Dissanayake et al. (2021) used CNN network structure and Siamese network structure to improve the generalization ability of the model.
Yang et al. (2023) used multistage time-spectrum feature extraction network, feature separation network and invariant feature extraction network to extract the essence of features in depth to avoid differences in data distribution between patients.
Through comparative analysis, Schirrmeister (Schirrmeister et al., 2017) and Kiral (Kiral-Kornek et al., 2018) initially applied deep neural networks to epilepsy detection but failed to consider the diversity in patient data. This lack of extracting consistent features from the data negatively impacted the model training, reducing the detection accuracy for new patients. In this context, Zabihi (Zabihi et al., 2013) used relative scale energy and Shannon entropy, etc. as features, and Fergus (Fergus et al., 2015) used peak frequency and maximum frequency, etc. as features, to capture common features in the data. However, these approaches were unable to identify common features at higher-dimensional levels. Therefore, the proposed method in the study demonstrated better detection accuracy comparing to Schirrmeister’s (Schirrmeister et al., 2017) and Kiral’s (Kiral-Kornek et al., 2018). Additionally, shallow feature commonality extraction cannot thoroughly explore the essence of features, resulting in test results lower than those achieved by Zhang (Zhang et al., 2020), Dissanayake (Dissanayake et al., 2021), and Yang (Yang et al., 2023). Zhang (Zhang et al., 2020) and Dissanayake (Dissanayake et al., 2021) employed deep learning methods such as adversarial training and contrastive training, etc., reducing the negative impact of differences in data distribution between patients. Their results were superior to those not considering removing the negative impact of data distribution shift between patients. Furthermore, Yang (Yang et al., 2023) first used a multi-level time-spectrum feature extraction network to capture common features and then input it into a feature separation network and an invariant feature extraction network, achieving more excellent accuracy performance by deeply extracting the essence of features and avoiding differences in data distribution between patients. We introduced in the study, for the first time, a hypergraph convolutional neural network model suitable for epilepsy detection. It captures multidimensional features through parallel dual branches while constructing hypergraph convolution. This exploration of high-order common information between brain regions of epilepsy patients can project essential features of data structure from a higher dimension, thereby reducing the impact of skewed distribution.
Through comprehensive analysis of several evaluation indicators, the proposed model reached 96.9% (ACC), 97.3% (F1), 98.2% (Pre) and 96.7% (Re) on the TUH dataset. Compared with the epilepsy detection study in the preface, Yang’s method has an 11.2% improvement in ACC, 7.7% improvement in F1, 7.1% improvement in Pre and 8.6% improvement in Re (Yang et al., 2023). Compared with the traditional support vector machine method (Zabihi et al., 2013), it has a greater improvement: 19.3%, 14.5%, 16.7%, and 12.6% corresponding to ACC, F1, Pre and Re, respectively. The excellent performance of the proposed model is further described through multiple evaluation dimensions.
On the CHB-MIT scalp EEG dataset, we used the model and the leave-one-out cross-validation method to conduct a full experiment on this dataset. The experimental results (ACC) are shown in Table 4.
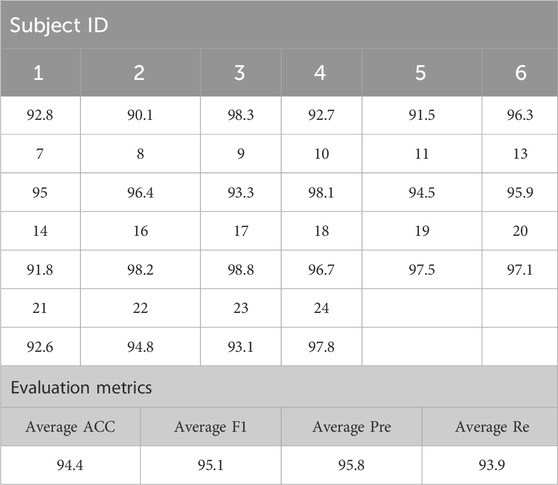
Table 4. Experimental results.
The generalization ability of the proposed model was tested on the CHB-MIT scalp EEG dataset. From the experimental results in the table, it can be concluded that the ACC, F1, Pre and Re of 22 patients evaluated by the model were as high as 94.4%, 95.1%, 95.8%, and 93.9%. Each evaluation index is above 90%, and the comprehensive ability is outstanding. Among them, the EEG test results of patient 17 were as high as 98.8%, and the model’s worst performance was patient 16, at 89.4%. The experimental data of the two datasets show that the proposed model has good generalization ability and robustness.
5 DiscussionsIn order to analyze the effectiveness of the proposed method, we conducted extensive ablation experiments on TUH dataset with its components and parameters. First, in the feature extraction stage, to validate the effectiveness of the dual-branch structure, we conducted two sets of experiments: “Only Conv-LSTM,” “Only PSD,” “Only Conv-Att” and “Only Ene,” which respectively represented only using Conv-LSTM to extract features, only using PSD to extract features, using only channel attention convolution and only energy representations. Secondly, for the important parameters k∈2,3,4,5,6 required for hypergraph construction, we conducted sequential k-value experiments to explore the impact of the hypergraph constructed by different k values, the individual k-value and the combined six k values on the network detection accuracy. All experiments were conducted using leave-one-out cross-validation on the TUH dataset. The ACC results of the branch ablation experiment are shown in Table 5; Figure 4, and the hypergraph parameter experiment results are shown in Table 6.
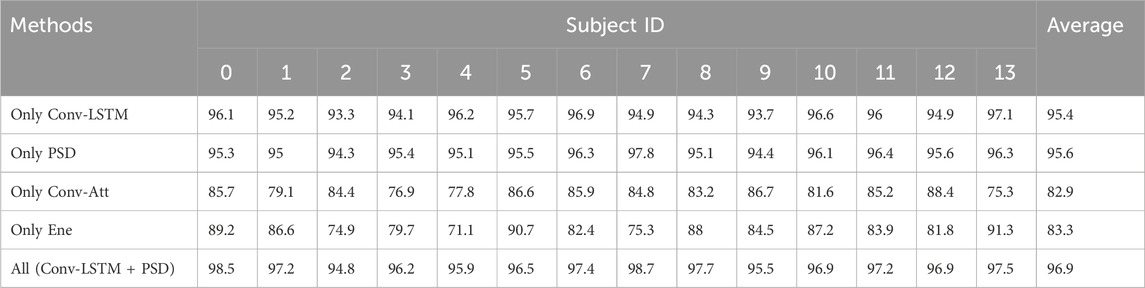
Table 5. Experimental results of branch ablation.
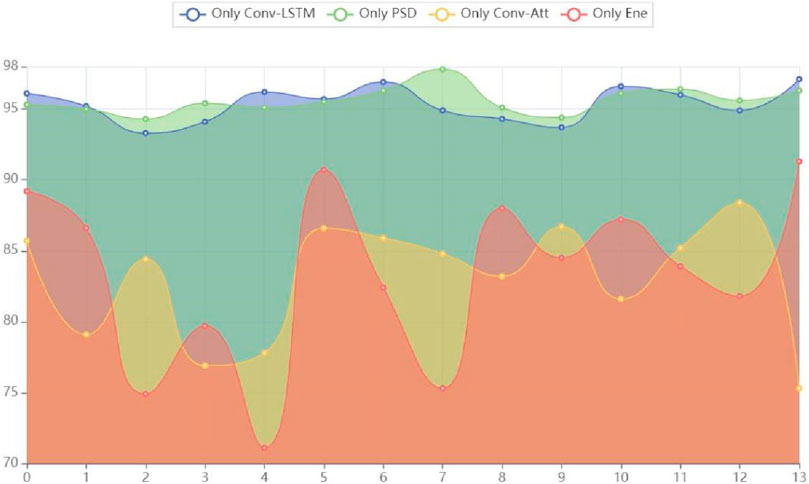
Figure 4. Area of experimental results for branch ablation.
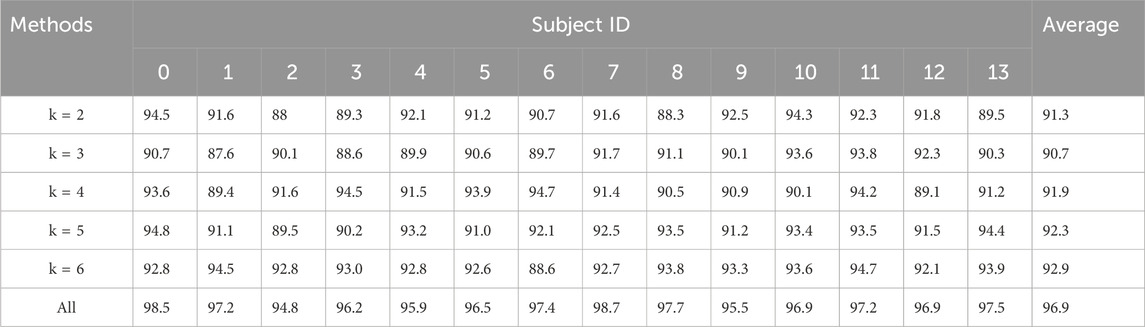
Table 6. Experimental results of hypergraph parameters.
To validate the effectiveness of the proposed dual-branch structure, a comparison between the results of single-branch experiments and dual-branch experiments revealed that the model testing average accuracy was 95.4% when only using Conv-LSTM to extract features, while the model testing average accuracy was 95.6% when only using PSD to extract features. At the same time, “Only Conv-Att” and “Only Ene” performed significantly lower in ACC at 82.9% and 83.3%, respectively, than “Only Conv-LSTM” and “Only PSD.” This shows that the essential ability of hypergraph convolutional representation data constructed after spatial attention extraction branch and energy branch extraction is inferior to Conv-LSTM branch and PSD branch. Therefore, Conv-LSTM branch and PSD branch are selected as more effective feature extraction methods in this paper.
By comparing the model performance of using only the Conv-LSTM feature extraction branch and using only the PSD feature extraction branch, it was found that the model performance using only the PSD feature extraction branch was superior to the model performance using only the Conv-LSTM feature extraction branch. We conducted a model performance comparison using an area chart, as shown in Figure 2, where the model performance using only the PSD feature extraction branch dominated in total area, highlighting its outstanding testing performance. The reason for this result may be that frequency domain features have advantages in explaining the essence of epilepsy EEG information, while spatiotemporal domain information is more focused on connecting temporal information to construct context. Therefore, after extracting frequency domain features, the fusion of temporal information can effectively reveal multiple aspects of the essential characteristics of epilepsy EEG signals, achieving a superior detection accuracy of 96.9%.
Upon completing the dual-branch feature extraction, it is crucial to effectively construct the hypergraph for feature representation and hypergraph learning. In hypergraph construction, each EEG data channel served as a vertex ν∈V in the hypergraph, and each hyperedge e∈E was formed by connecting a vertex ν with its k-nearest neighboring vertices at the minimum Euclidean distance. The parameter k determined the number of adjacency matrices and the dimensionality of hypergraph information, reflecting the quality of hypergraph construction and the richness of classification information. To investigate the impact of different k∈2,3,4,5,6 on model performance, experiments were conducted. By comparing experiment results with different k value: ACC (k = 2) = 91.3%, ACC (k = 3) = 90.7%, ACC (k = 4) = 91.9%, ACC (k = 5) = 92.3%, ACC (k = 6) = 92.9%, ACC [k= (Sporns et al., 2005; Shuting et al., 2019; Yan et al., 2019; Sala et al., 2022; Thiebaut de Schotten and Forkel, 2022)] = 96.9%, it was observed that ACC (k = 6) = 92.9% outperformed ACC (k = 2) = 91.3%. During the hypergraph construction process, this occurred due to that the more adjacent vertices ν∈V found by the minimum Euclidean distance allows the hypergraph to contain more feature information, and the constructed hyperedges can better reflect common features. However, the situation as ACC (k = 3) = 90.7% being lower than ACC (k = 2) = 91.3% also existed. This could be because: for the three adjacency matrices constructed via the three nearest neighboring vertices (searched through the KNN algorithm), comparing with k = 2, the additionally constructed adjacency matrix may introduce distant noise information for the original vertex, which did not effectively contribute to the construction of the hypergraph for the original vertex. To effectively mitigate the impact of the k value on the model’s performance, we employed multiple k values in the study to construct hypergraphs respectively and adopted a systematic ensemble approach, resulting in ACC [k= (Sporns et al., 2005; Shuting et al., 2019; Yan et al., 2019; Sala et al., 2022; Thiebaut de Schotten and Forkel, 2022)] = 96.9%.
In future study, we propose three recommendations as the following:
Firstly, the proposed method employed a dual-branch parallel extraction and hypergraph learning structure, capturing frequency domain information and spatiotemporal domain information respectively. Next, we can increase the data volume in parallel branches to extract more discriminative features from multiple dimensions, thereby enhancing the model’s performance.
Secondly, in the hypergraph construction stage, the current approach only utilized the KNN method to search for vertices and construct hyperedges. Next, we can explore various ways of constructing hypergraphs and integrate them to enhance the feature representation capability of hypergraphs.
Lastly, the proposed method was trained and tested only on two public datasets, lacking validation on real clinical datasets. Therefore, we will conduct validation on the actual performance of the model using clinical data in the future.
6 ConclusionIn the study, we have first ever introduced a novel neural network model for epilepsy detection based on hypergraph convolution. Addressing the insufficient feature extraction in traditional methods for epilepsy datasets, which fails to deeply reveal the high-order characteristics of seizure data, we have proposed the dual-branch approach to extract features from each channel using Conv-LSTM module and PSD. This has been a highly effective way to explore both the frequency domain features and spatiotemporal domain features information of epilepsy signals. Based on this, hypergraphs were constructed using the KNN algorithm, exploring the commonalities and intrinsic information of epilepsy data in the hypergraph structure. Finally, hypergraph convolution was applied to achieve graph feature extraction and automatic epilepsy detection. In the testing and validation phase, we conducted leave-one-out cross-validation with 14 patients’ data selected from the TUH dataset according to experimental requirements and compared the results with relevant literature. The proposed method achieved the best results. In addition, the effectiveness and generalization ability of the proposed model are verified on CHB-MIT Scalp EEG dataset. It indicates that the high-order hypergraph features, which the model explores, are highly discriminative, being able to achieve higher detection accuracy and provide valuable reference for the clinical application of epilepsy detection.
Data availability statementPublicly available datasets were analyzed in this study. This data can be found here: I. Obeid and J. Picone, “The Temple University Hospital EEG Data Corpus,” Frontiers in Neuroscience, vol. 10, p. 196, 2016.
Author contributionsJaL: Conceptualization, Methodology, Software, Writing–original draft, Writing–review and editing. YY: Conceptualization, Methodology, Software, Writing–original draft, Writing–review and editing. FL: Investigation, Supervision, Validation, Writing–review and editing. JnL: Investigation, Supervision, Validation, Writing–review and editing.
FundingThe author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This research was partly supported by the National Natural Science Foundation of China (Nos 62376168 and 62371438), the National Key R&D Program of China (No. 2023YFB3308601), Science and Technology Service Network Initiative (No. KFJ-STS-QYZD-2021-21-001), the Talents by Sichuan provincial Party Committee Organization Department, and Chengdu—Chinese Academy of Sciences Science and Technology Cooperation Fund Project (Major Scientific and Technological Innovation Projects).
Conflict of interestThe authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s noteAll claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
留言 (0)