The diagnosis and analysis of skin conditions are an enormous burden on the healthcare system, with at least 3000 distinct skin diseases identified (Bickers et al., 2006) so far. Both human dermatologists and sophisticated computerized approaches struggle to address this complex task of analyzing skin conditions. Computerized analysis of skin diseases often rely on 2D colored images, with significant research efforts devoted to analysis of conditions within clinical (Li et al., 2021) and dermoscopy images (Celebi et al., 2019). While clinical images can capture a variety of skin conditions using a common digital camera, dermoscopy images offer a more standardized acquisition using a dermatoscope, which captures a highly magnified image of the lesion with details imperceptible to the naked eye.
Dermoscopy images generally focus on the analysis of a single lesion, with large scale annotated dermoscopy datasets now available for public use (Tschandl et al., 2018, Combalia et al., 2019, Rotemberg et al., 2021). While dermoscopy has been shown to improve the diagnostic ability of trained specialists, the field-of-view of a dermoscopy image is generally limited to a localized patch of skin on the body (e.g., a mole). In contrast, clinical images vary considerably in their acquisition protocols, ranging from a closeup view focused on a single lesion, to a view that captures a significant portion of the body (Fig. 1). The contextual information in large-scale clinical images of skin lesions may provide valuable cues regarding the underlying disease that may not be present in dermoscopic images alone (Rotemberg et al., 2021, Birkenfeld et al., 2020).
Clinical images exhibit considerable variability across datasets. For example, the public DermoFit Image Library dataset (The University of Edinburgh, 2013, Ballerini et al., 2013) contains 1300 clinical images and manual lesion segmentations from 10 types of skin conditions. These are high-quality images acquired under standardized conditions. In contrast, other clinical datasets, such as SD-198 (Sun et al., 2016), SD-260 (Yang et al., 2019), or Fitzpatrick17K (Groh et al., 2021), contain hundreds of types of skin disorders and are much less standardized, exhibiting a high variability in camera position relative to the lesion, resulting in dramatic changes in the field-of-view. We use the term “in-the-wild clinical dataset” to describe these types of image collections, where the camera position, field-of-view, and background, are inconsistent.
In-the-wild clinical images are often used to train a classification model (Sun et al., 2016, Kawahara et al., 2018, Groh et al., 2021, Wu et al., 2022, Daneshjou et al., 2023), where the entire image is taken as input, and the model is trained to produce a label (e.g., class of skin disorder). However, there are several important dermatological tasks apart from classification of skin disorders, such as lesion segmentation (Mirikharaji et al., 2022, Hasan et al., 2023), lesion tracking (Young et al., 2021, Fried et al., 2020, Sondermann et al., 2019), lesion management (Abhishek et al., 2021), and skin tone prediction (Kinyanjui et al., 2019). As an example, Wang et al. (2020a) motivated their release of a public wound segmentation dataset of 2D clinical images by noting that wound segmentation may help automate the process of measuring the wound area to monitor healing and determine therapies. In addition, Gholami et al. (2017) showed that chronic wound bioprinting based on image segmentation can help facilitate wound treatments. Groh et al. (2021) created a public dataset of 2D clinical images with skin disorder and Fitzpatrick skin tone labels (Fitzpatrick, 1975, Fitzpatrick, 1988) and noted the need to segment pixels containing healthy skin when applying automated methods to estimate the skin tones of the imaged subjects. Other works (Lee et al., 2005, Mirzaalian et al., 2016, Rayner et al., 2018, Zhao et al., 2022) have motivated the importance of considering multiple lesions over a widely imaged area, as opposed to focusing on a single lesion, noting that the presence of multiple nevi (moles) is an important indicator for melanoma (Gandini et al., 2005).
One approach to curate the necessary data is to synthesize images with their corresponding annotations, which has shown success in other domains, both medical and non-medical. For example, for non-medical applications, image synthesis with annotations has been used in face analysis (Wood et al., 2021) and indoor scene segmentation (McCormac et al., 2017). For a more comprehensive review of image synthesis, particularly using generative adversarial network (GAN) models (Goodfellow et al., 2014, Wang et al., 2021b), we direct the interested readers to the survey by Shamsolmoali et al. (2021). Since medical image datasets tend to be small (Kohli et al., 2017, Curiel-Lewandrowski et al., 2019, Asgari Taghanaki et al., 2021), synthesis for medical image analysis applications has also gained popularity in recent years to generate ground truth-annotated images, including but not limited to MRI (Chartsias et al., 2017, Dar et al., 2019), CT (Nie et al., 2017, Chuquicusma et al., 2018), PET (Bi et al., 2017, Wang et al., 2018), and ultrasound (Tom and Sheet, 2018, Liang et al., 2022). For a more in-depth review of the use of GANs and image synthesis in medical imaging, we refer the interested readers to comprehensive surveys by Yi et al. (2019), Kazeminia et al. (2020), Wang et al. (2021a), Skandarani et al. (2023), and Yang (2023).
Similarly, for skin image analysis, there have been several works towards the synthesis of skin lesion images. The first two works to explore skin lesion image synthesis used a variety of noise-based GANs (Baur et al., 2018) and conditioned the output on the diagnostic category (Bissoto et al., 2018). Abhishek and Hamarneh (2019) then proposed a GAN-based framework to generate skin lesion images constrained to binary lesion segmentation masks, while Pollastri et al. (2020) used GANs to generate both skin lesion images as well as the corresponding binary segmentation masks. For a more detailed review of the literature on deep learning-based synthetic data generation for skin lesion images, we refer interested readers to the comprehensive survey by Mirikharaji et al. (2022).
While there are numerous publicly available 2D dermatological image datasets (Mirikharaji et al., 2022), existing “in-the-wild” clinical datasets have limitations in creating semantically rich ground truth (GT) labels that can be used for the diverse range of dermatological tasks discussed earlier. Consequently, compared to dermoscopic images’ synthesis, there is considerably less research in the synthetic data generation of clinical images. Li et al. (2017) proposed to synthesize 2D data by blending small lesions onto a larger 2D image of the torso, which allowed them to create training data for a neural network that detects lesions’ masks across a large region of the body. Dai et al. (2021) proposed to generate burn images with automatic annotations. They used a Style-GAN (Karras et al., 2019) to synthesize burn wounds, blended the generated burns with textures from a 3D human avatar, and generated a 2D training dataset through sampling from different 2D views of the 3D avatar with the synthetic burns. Both approaches motivated their use of synthetic data by noting the difficulties in collecting appropriate real labeled training data that is specific to their dermatological task.
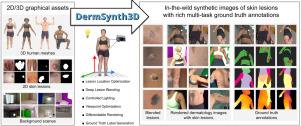
Our proposed work is similar to that of Dai et al. (2021) in that we follow a similar pipeline where 2D images of the skin disorder are blended onto the 3D textured meshes and used to create a large-scale 2D dataset with corresponding annotations. However, we extend this framework by incorporating a deep blending approach to blend lesions across seams in 2D rendered views. Additionally, we broaden the scope of this work by including a diverse range of skin tones and background scenes, enabling us to generate semantically rich and meaningful labels for 2D in-the-wild clinical images that can be used for a variety of dermatological tasks, as opposed to just one. Furthermore, the annotated data generated by DermSynth3D in the form of semantic segmentation masks, depth maps, and 3D scene parameters, can be used to train machine learning models for a variety of medical tasks that may benefit clinical practice. For instance, the scene parameters may be used to train models for reconstruction and visualization of 3D anatomical organs, longitudinal tracking of lesions, illumination, and skin tone estimation for consistent imaging and tracking. The surgeons can use these reconstructed 3D models for pre-operative planning, allowing them to better visualize the patient’s anatomy and anticipate potential challenges. Longitudinal tracking of lesions can help the doctors in measuring the progress of diseases, evaluating the effectiveness of treatments and administer better-suited treatments. The measurement bias introduced across time due to change in background and lighting conditions can be further corrected by training deep models to accurately estimate the illumination, skin-tone and camera parameters. To facilitate future extensions to our framework, we have made our code base highly modular and publicly available.
Despite the availability of numerous skin image datasets (e.g., Ballerini et al., 2013, Tschandl et al., 2018, Kawahara et al., 2018, Wang et al., 2020a, Groh et al., 2021, Wen et al., 2022, Daneshjou et al., 2023), there is a lack of a large-scale skin-image dataset that can be applied to a variety of skin analysis tasks, especially in an in-the-wild clinical setting. Moreover, existing datasets are limited in their scope and are often task-specific, requiring extensive additional annotation for generalizing them to other dermatological applications.
To address this gap, we present DermSynth3D, a computational pipeline along with an open-source software library, for generating synthetic 2D skin image datasets using 3D human body meshes blended with skin disorders from clinical images. Our approach uses a differentiable renderer to blend the skin lesions within the texture image of the 3D human body and generates 2D views along with corresponding annotations, including semantic segmentation masks for skin conditions, healthy skin, non-skin regions, and anatomical regions. Furthermore, we demonstrate the utility of the synthesized data by using it to train machine learning models and evaluating them on real-world dermatological images, showcasing that the DermSynth3D-trained model learns to generalize to a variety of dermatological tasks. Additionally, the open-source and modular design of our framework offers opportunities for researchers in the community to experiment and choose from a range of 2D skin disorders, renderers, 3D scans, and various other scene parameters. We present a simplified code snippet in Listing 1 that exemplifies the modular implementation of our proposed framework and emphasizes its user-friendliness and ease of use.








留言 (0)