
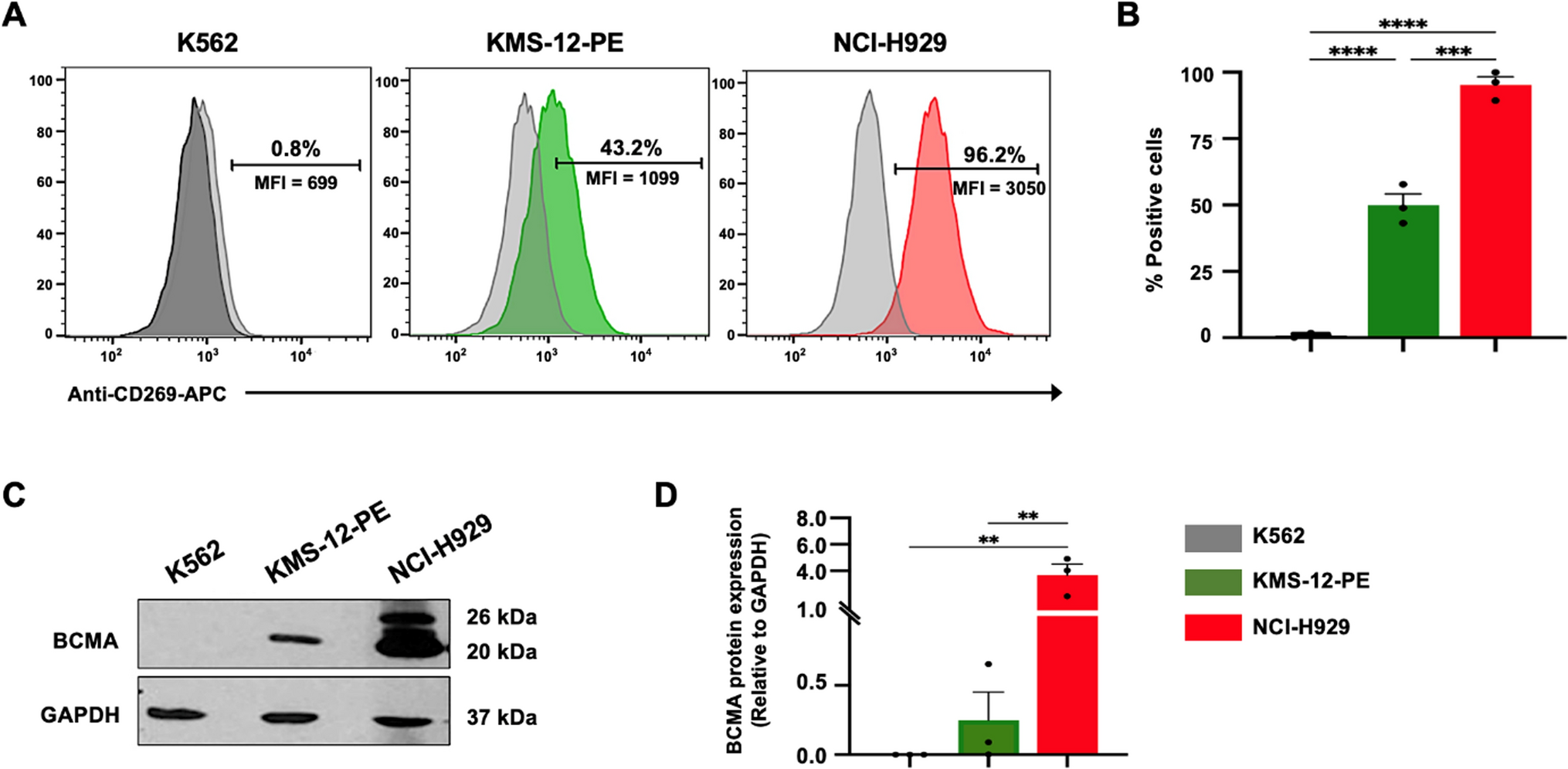
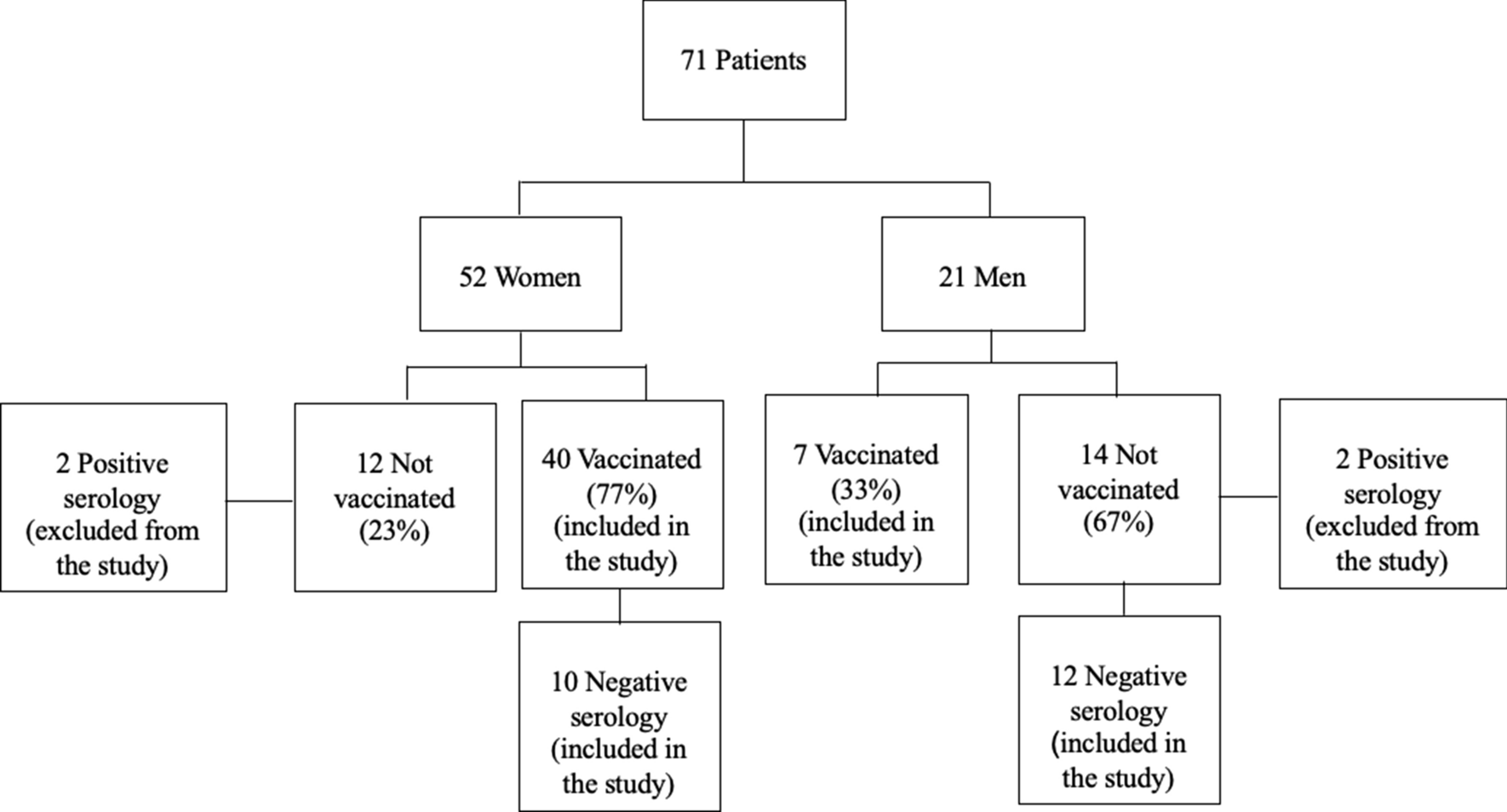
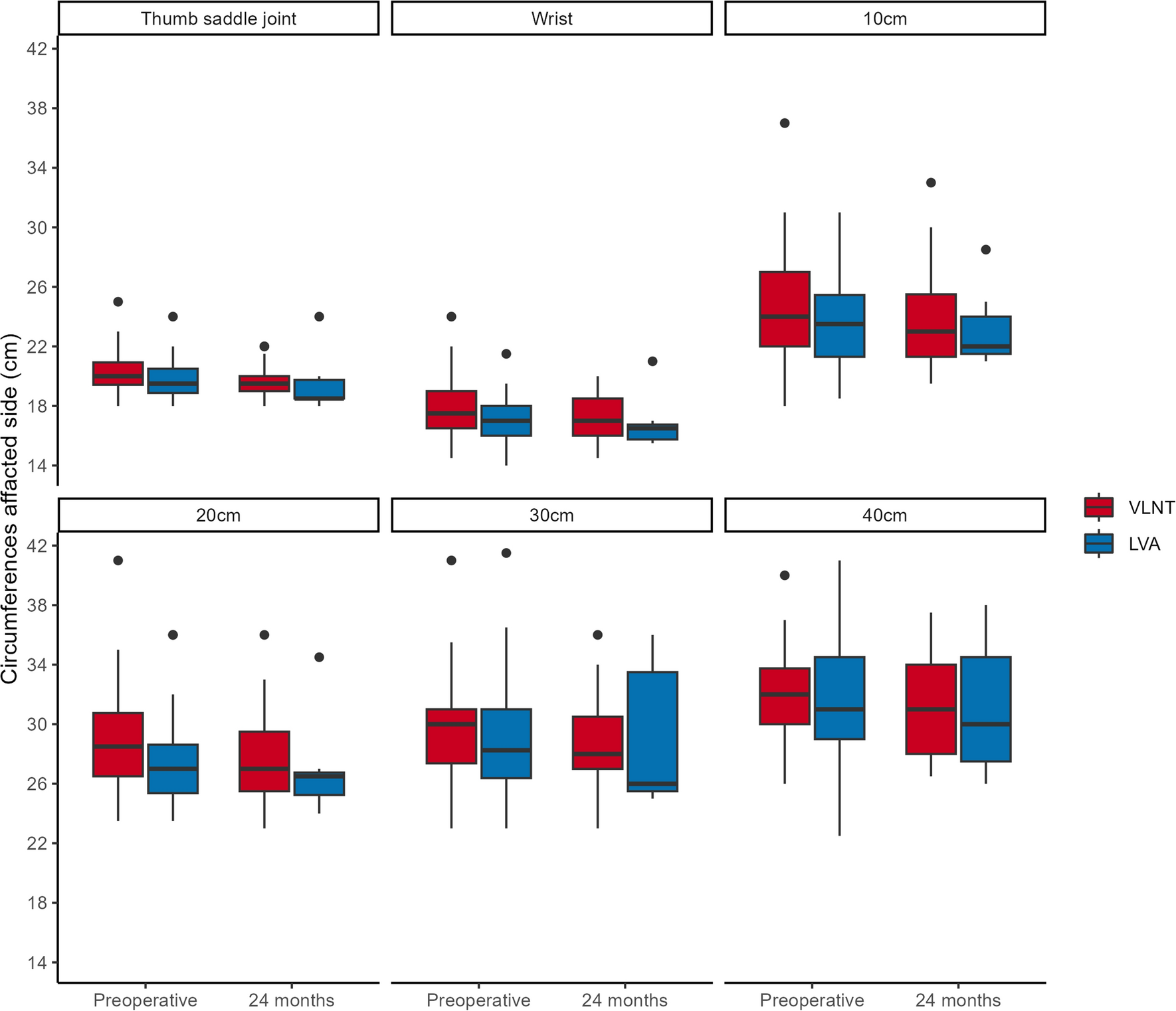
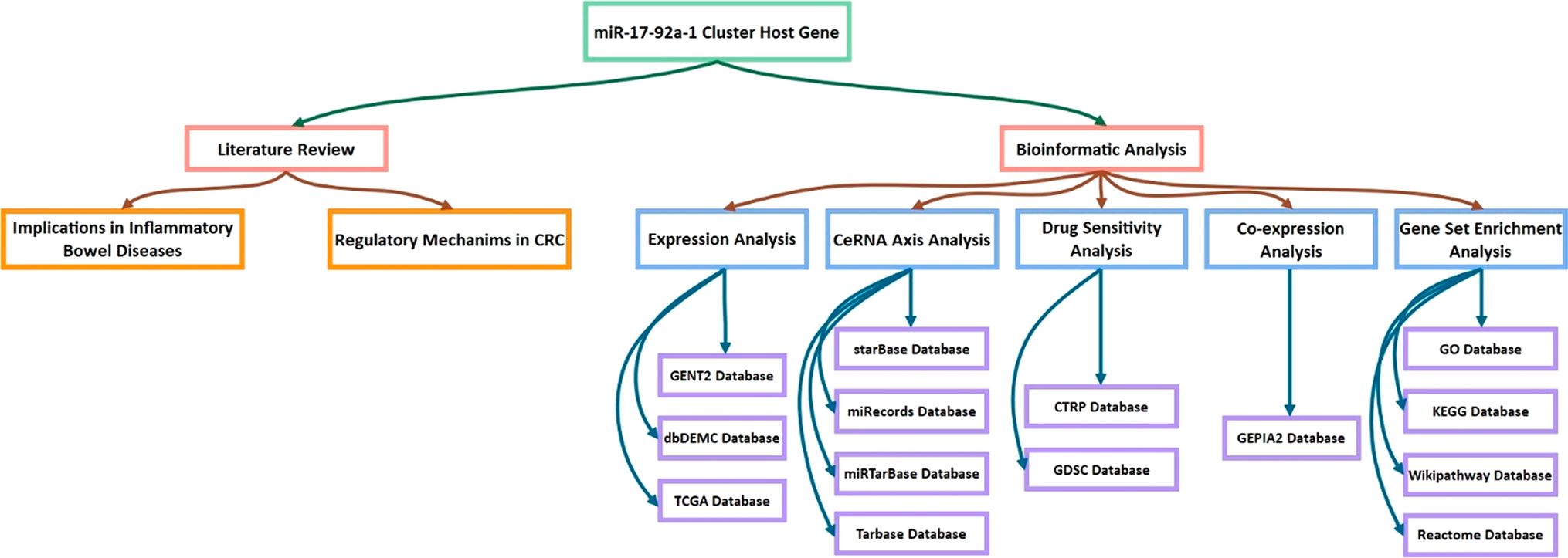
記住我

Disclaimer: according to the Bavarian hospitals act [8], all analyses were conducted on site in LMU hospital’s own IT infrastructure. At no point, aside from aggregated/anonymized results, was data transferred out of the hospital. All analyses were conducted using Python 3.8.8. For clarity: within the section of Material and methods as well as Results we used the term NGS test in the model synonymously to performed molecular profiling.
Data cleaningThe first step was to identify and prepare the relevant data. Two datasets, LMU’s local tumor documentation dataset (CREDOS—cancer retrieval evaluation and documentation system) [9, 10], as well as a custom MTB database, served as source data.
While the local tumor documentation at CCC MunichLMU contains more than 46.000 (19.07.2022) tumor entries, only a fraction of those have been discussed by the MTB (N = 1834, 19.07.2022). The MTB cases are labeled with a specific flag in the CREDOS database and have additional information—e.g., the occurrence of pathogenic alterations.
As the tumor documentation is complex (more than 2000 data fields), the quality of its contents can be challenging, as is the case with most routine data in general. To improve this situation, based on discussions with data experts of the CCC, the data contents were restricted and filtered for further analysis. Only those cases primarily treated at the CCC are referred to as primary cases (according to OnkoZert guidelines [11]). About 63% of the CREDOS cohort consists of primary cases. Non-primary cases were not considered for the next steps, as they typically lack data completeness. Another way to improve the data quality was to only include cases with a diagnosis date after 01.01.2016. According to the Center, this decision was based on the introduction of new data standards, which were imposed due to new regional laws (Bayerisches Krebsregistergesetz (state law on the Bavarian cancer registry), [12]). This improved the completeness for many data categories.
Furthermore, a filter was set to exclude benign tumors, defined as those beginning with a ‘D’ code in the ICD-10 classification—e.g., D17—benign lipomatous neoplasm [13]. In addition, those patients with two or more tumors were removed because the MTB database contained only patient IDs but no tumor IDs; hence, the link to CREDOS (which also contains individual tumor IDs) would have been ambivalent. Finally, we considered those patients who received only one NGS test.
While CREDOS contains most of the clinical information about a tumor case, some of the data is difficult to process. For example, chemotherapy substances have been documented quite heterogeneously. For this reason, we translated substance names into standardized ATC codes—e.g., Cisplatin → L01XA01 [14]—which facilitated further steps.
Despite the presence of information regarding patient mutations in the MTB database, the primary aim of this study is not to predict mutations. Instead, it focuses on facilitating the decision-making process for including patients in an MTB. Hence, only this information from the MTB database was necessary for the study’s objectives.
Selection and description of the featuresAfter restricting the number of patients, we then selected the features of interest. These features were selected according to interviews with local data experts as well as MTB experts. Some features were added from other data sources, in particular information about the NGS test performed, which came from the molecular database, and additional information on transport data, which came from the hospital admission or cancer incidence calculated from The German Centre for Cancer Registry Data [15]. Table 1 shows the final selection of features.
Table 1 Final selection of features with possible valuesThe selected features can be divided into 5 categories; see Table 1. The first category contains the demographic data gender and age at diagnosis, which are examples of the features that were only added after discussion with the MTB experts, as they pointed out that they are very important in deciding whether a patient should receive an NGS test. The younger the patient, the higher the probability that a gene mutation is the cause of the tumor [16,17,18,19].
The next category is anamnesis, which includes information about initial findings, such as initial diagnosis according to the ICD-10 classification and number of initial metastases, as well as UICC [20], TNM [21], and grading, which are common staging classifications used to describe the severity of a case. ECOG performance status describes the physician’s impression about a patient’s well-being as a value between ‘0’ and ‘4’ [22]. ECOG was one of the fields identified to have insufficient data quality/completeness.
The following category includes those features that describe the patient’s progress. Here, some features from the previous category were reused for the model. Staging, ECOG and number of metastases can change during the course of the patient’s disease, and such information might be important for further treatment. The revaluation feature identified the status of a tumor at different timestamps in terms of remission, progression, recurrence, stable and mixed response. The next feature showed whether the patient was in a curative or palliative situation, while the survival status provided information about the date of death or the last vital date. Acquiring vital data is often a problem, but the primary cases in CREDOS usually have a follow-up rate of over 80%. This high follow-up rate is due to the CCC’s own efforts as well as supporting information from the Bavarian Cancer Registry [23].
The next category includes treatment features such as the type of therapy, which is differentiated into surgery, radiation therapy, medical therapy with and without personalized treatment, and ‘others’. The next feature, the therapy phase, described whether the therapy performed was in the primary or secondary phase. The last feature from this category was used to describe the therapeutic goal, and it had the following values: curative, palliative, neoadjuvant, adjuvant or diagnostic.
The last category includes features that do not fit into any of the above categories. The first feature is information on how many quarters have passed since the patient’s first event (e.g., initial diagnosis) until the next event (e.g., until the performing of an NGS test or the start of personalized therapy). The transport data, which give information similar to that of the ECOG in that they indicate a patient’s condition, were added after consultation with the MTB experts in order to solve the problem of the ECOG’s lack of completeness. When cancer patients are transported at the hospital, they are either coming by foot or are moved (e.g., in a wheelchair or bed). While these data are not as precise as the ECOG, it has been documented for many more timestamps. If an NGS test had been performed is another feature of this category. The value ‘0’ was given when the test was not performed in a given quarter, and the value ‘1’ was give when it was performed in given quarter. The last feature is the cancer incidence, which was calculated using age at diagnosis, gender and tumor entity in relation to the epidemiological cohorts represented in The Centre for Cancer Registry Data, resulting in individual incidence-values ranging from 0 to 1 for each case.
Additional feature preparationAfter selecting the features, some of them had to be prepared according to the requirements of the prediction model. In some cases, we trimmed down complexity and reduced dimensionality by aggregating some of the data into generalized groups.
The generalization into groups was applied to the initial diagnosis (ICD-10 codes) of the tumor documentation, which was grouped into the following subgroups: breast, lung, pancreas, prostate, colon, biliary tract and others. Generalization was also used for UICC, TNM, grading, and revaluation, reducing the dimensionality of their categories by about half.
Another method of preparing some of the features was to represent their value set via the count of their occurrences in a quarter instead of their actual value. For example, instead of storing two individual surgery dates, a count of ‘2’ was documented. To illustrate this better, the aforementioned procedure is shown in the ‘Type of therapy—surgery’ column in Table 2. This was done analogously for the transport data as well, which showed how often the patient moved (e.g., by foot or in a wheelchair) during a given quarter.
Table 2 Extract of the input format for the prognostic model. This example shows how some features, like the type of therapy, were aggregated by counting occurrences during a quarter instead of listing each date value in order to decrease complexity.Creation of quarterly panelThe cohort with the selected features was reorganized in a quarterly panel. Each patient in each quarter between Q1-2016 and Q3-2021 was represented as a row. Each row contained information on the selected features. Table 2 gives an impression of the given data model.
Since multiple events per feature can occur in one quarter, we had to aggregate this information to be represented as a single row. For some features (therapies, transport data, and number of detected metastases), this was explained above. For all other features, only the last available value of a feature in the given quarter was taken into consideration and imputed into the quarterly panel. For example, if a patient’s ECOG was documented with a value of ‘0’ at first but then with a value of ‘1’ at a later point in the same quarter, the value of ‘1’, as the latest documented value, was used for further analysis.
The outcome is named ‘NGS Test’ (see Table 2) and indicates whether a NGS test was performed in the given quarter (‘NGS Test’ = 1) or not (‘NGS Test’ = 0) for the respective patient. The prediction model described in the following section is used to estimate this outcome on the first day of each respective quarter, given the most recent available information about the patient—i.e., aggregated information from the previous quarter. For example, a patient’s grading from 15 January (Q1) is used as a feature for predicting the necessity of an NGS test in Q2.
The next step to obtain the best possible data model was to replace missing values with three options. First, if no value for grading was documented in a given quarter, the last available grading value from the previous quarters was rewritten. Second, in the case of no therapy per quarter, the value ‘0’ was used as a replacement for the missing value. Third, for other features, the missing values were labeled as ‘unknown.’
Implementation of the modelThe created data model with all selected features was split into training and test data sets. The different splits for the training and test sets were not described. Only the best split was shown in the work, which resulted in the best model performance. The test set contained data from the last available quarter (Q3-2021), while the training set contained all other quarters. It is important to note that our dataset is imbalanced, and the implications of this are discussed in detail later on. This imbalance requires careful consideration and planning in the analysis steps that will follow.
To estimate the probability that an NGS test would be performed for patients during the test quarter, a machine-learning algorithm was trained. It can identify the most important of the various prepared features and automatically approximate the clinically complex function between these features and the target variable.
For this paper, LightGBM, a gradient boosting framework that uses tree-based learning algorithms [24], was used. Gradient boosted trees are a potent machine learning algorithm that typically yields superior performance compared to alternative methods, such as neural networks or simple statistical models like logistic regression, when applied to tabular data [25]. Furthermore, this algorithm is highly recommended for imbalanced classification tasks [26].
The LGBMClassifier is a class of the framework that can predict the probability of class memberships—e.g., the probability for ‘NGS test’ vs. ‘no NGS test’—and offers many hyper-parameters that can be tuned to improve prediction accuracy.
Cross-validation was performed, using GridSearchCV [27] to find the optimal combination of hyper-parameters for the model. In particular, we decided to tune the following hyperparameters: the learning rate, the number of boosted trees, the number of leaves in each tree and the minimum number of observations per leaf in the training data [28].
Evaluation of model performanceThe final step in building the prediction model was an evaluation to check the performance of the obtained model.
Since the model predicts a continuous probability, its outputs have to be mapped to one of two decisions or classes by using a probability threshold. The model in this paper predicted the probability that an NGS test would be performed in the given quarter; thus, it returned a value in the interval [0, 1] for each observation. In order to classify the observations, a probability threshold for the model at hand was set: values below this threshold were interpreted as a recommendation for ‘no NGS test’, while values above were interpreted as a recommendation for ‘NGS test.’ In general, specifying an optimal threshold does not change the method of probability estimation, but it does affect the method of case classification. The selection of an appropriate threshold value is critical for achieving the desired objectives in classification tasks. The default threshold value is conventionally set to 0.5; nevertheless, this value may not always be appropriate, especially for models based on imbalanced data [29]. In such cases, the model may not achieve high accuracy, or it may generate a large number of false positives, resulting in elevated costs within the confusion matrix. Therefore, it is imperative to adjust the threshold value as necessary to optimize model performance.
Positive and negative classifications can be represented using a confusion matrix (see Fig. 1).
Fig. 1
General setup of a confusion matrix
A negative classification means that the event does not occur (value ‘N’), while a positive classification indicates the occurrence of the event (value ‘P’). Figure 1 summarizes the decisions made by the model in relation to the actual values. The correct decisions are marked in green: true negatives (TN) and true positives (TP). The red identifies errors: negative cases classified as positive by the prediction model (false positives—FP) and positive cases classified as negative (false negatives—FN) [29, 30]. FP for our model indicated that patients who did not receive the NGS test were assigned a test, while FN indicated that the test was underestimated—i.e., patients who actually had the test were classified as patients without the test. We aimed for the values for these errors to be as low as possible.
Appropriate evaluation metrics are crucial for accurately assessing model performance based on the confusion matrix. These metrics are used to compare different models and estimate the impact of manipulating the classification threshold. While there are numerous evaluation metrics available, in this study, we focused solely on those that best reflect the true nature of imbalanced data.
In this study, the model was evaluated using the receiver operating characteristics (ROC) curve with its associated AUC for both the training and test sets. [29, 30].
As an alternative to the ROC curve, we calculated the Precision-Recall curve, which can provide better results for imbalanced data.
Sensitivity, represented by formula (1), measures how well the positive class (‘NGS test’) was predicted. A higher sensitivity value indicates better positive class prediction. This metric might be particularly important in medical data, where it is desirable to minimize the number of missed positive cases [31, 32].
$$}/}/} = \frac}}}} + }} \right)}}$$
(1)
Another important metric is specificity, representing the percentage of correctly classified negative cases (‘No NGS test’), represented by the formula (2) [29]. In big health datasets, it is important to detect rare but significant cases to measure sensitivity. However, a trade-off between sensitivity and specificity should be considered, as indiscriminately increasing the sensitivity score may result in a higher number of false positives, and thus a low specificity score [31].
$$} = \frac}}}} + }} \right)}}$$
(2)
留言 (0)