
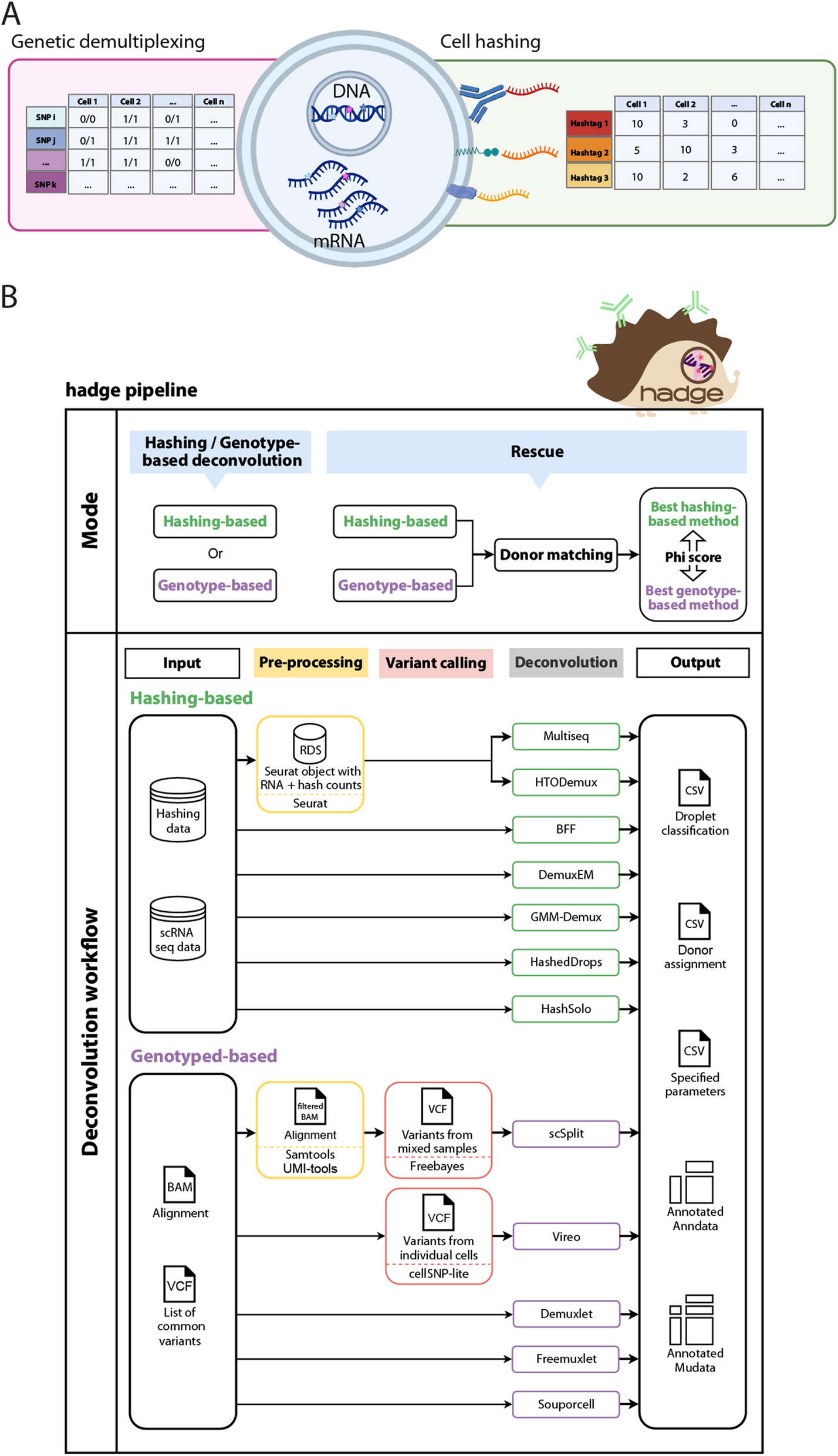
記住我






To our knowledge, there are currently twelve graph-based genotyping tools available (Additional file 1: Table S1). For this study, we selected eight open-source graph-based genotyping tools that broadly fall into two categories: read alignment based (including vg map [16], vg giraffe [20], Paragraph [24], GraphTyper2 [17] and Gramtools [29]) and k-mers alignment based (including BayesTyper [18] and PanGenie [19]) (Additional file 1: Table S1). We also conducted experiments to assess the performance of GraphAligner [28], a graph-based aligner that can utilize graphs constructed by vg to do alignment. Other tools were excluded from this study either because they are currently unsuitable for plant genomes (such as HISAT [30] and Minos [31]) or because they cannot genotype all types of genetic variations (like KAGE [32]). Among them, Minos is designed for bacterial genomes, while HISAT-genotype requires reconstruction of a typing database and complex conversion for plants in the algorithm.
These tools utilize different graph indexing approaches to improve alignment efficiency and/or support multiple graph manipulations (Additional file 1: Table S1). Specifically, vg employs GBWT [33], GCSA2 [34], and Minimizers [35] for graph storage and searching, whereas BayesTyper relies on k-mer-based graph indexing. To avoid potential memory overload, BayesTyper leverages Bloom filters to screen read k-mers, storing only those present in the haplotype [18]. Similarly, PanGenie adopts k-mer-based graph indexing using De Bruijn graphs. Subsequently, the software either aligns reads to nodes or directly counts k-mer coverage at nodes [19]. The genotyping results are then probabilistically scored based on statistical distribution modeling of observed and noise read/k-mer coverages.
Overall performance on simulated dataTo evaluate the performance of the tools, we first constructed a comprehensive simulation panel. Considering that plant genomes vary widely in size and repeats [36, 37], a series of data sets of paired-end shorted reads were simulated for each of five representative plant genomes (Arabidopsis thaliana, Oryza sativa, Glycine max, Zea mays, and Brassica napus) with different genome sizes (135–2300 Mb) and repeat contents (21.42–88.9%) (Additional file 1: Table S2). To generate simulated short reads from alternative (no-reference) genomes, we introduced different types (SNP, indels (< 50 bp), and SVs (≥ 50 bp)) and numbers of variants into the reference genome of each plant species [5, 26, 38,39,40] (see Methods for details). We repeat such a simulation of paired-end short reads with varying read lengths (100 bp, 150 bp, 250 bp), insert sizes (300 bp, 400 bp, 500 bp, 600 bp), and sequencing depths (5×, 10×, 20×, 30×, 50×) (Additional file 1: Table S3). Precision and recall were used to assess the genotyping performance of different software, and receiver operating characteristic (ROC) curves were drawn according to the genotype quality (GQ) or read depth (DP).
As graph-based genotyping tools can leverage sequence information from multiple genomes, we first determined the overall performance of these tools based on the genome graph from eight A. thaliana genomes (one reference genome assembly, and all variants from the other seven genomes) (Fig. 1a–c; Additional file 1: Fig. S1a). For one genome to be genotyped, we simulated 467,512 SNPs, 38,207 indels, 4572 insertions, 4364 deletions, 232 inversions, and 100 duplications (Additional file 1: Table S4). Note that all these variants are incorporated into the genome graph. To genotype this genome using each tool, we simulated 30× paired-end (2 × 150 bp) short reads. For SNP genotyping, all tools demonstrate high precision (> 0.97), while only BayesTyper (0.99), Paragraph (0.98), and GraphTyper2 (0.93) have a recall rate greater than 0.90 (Additional file 1: Fig. S1a). Similarly, nearly all tools show high precision rates (0.80–0.99) and relatively lower recall rates (0.81–0.98) for indels genotyping. However, only BayesTyper (0.98), PanGenie (0.99), Gramtools (0.98), and Paragraph (0.97) maintain precision above 0.95 (Fig. 1a). The performance of genotyping large insertions and deletions (≥ 50 bp) varies greatly among the tools. Despite different recall rates, all tools except Gramtools present genotyping precision above 0.8 (Fig. 1b, c). Overall, Paragraph, GraphTyper2, and BayesTyper outperformed other tools in terms of genotyping performance (Fig. 1b, c).
Fig. 1
Overall genotyping performance of different graph-based tools based on simulated data. The genome graphs of Arabidopsis thaliana (a, b, c), Oryza sativa (d, e, f), Glycine max, (g, h, i), and Zea mays (j, k, l), are constructed based on one reference genome and seven alternative genomes derived by introducing known variants into the reference genome. Paired-end (2 × 150 bp) short reads with 30× depth are simulated for genotyping. For each genotyper, precision is plotted against recall as the genotyping quality threshold varies. Read Depth on variant sites is used as a substitution score when genotype quality is not available. Arrows indicate the circles hidden by other circles in the plot due to identical or nearly identical precision values. Detailed results are also provided in Additional file 2: Table S5
We also evaluated these tools using the simulated data from rice, soybean, maize, and Brassica napus genomes (Additional file 1: Tables S2, S3). Note that Gramtools is excluded from the assessment for other plant genomes due to potential issues related to excessive chromosome length. For the large maize genomes, we conducted our evaluation on chromosome 10 instead of the entire genome to reduce testing time. We observed a similar recall of genotyping all types of variants in rice genomes as in A. thaliana, but with slightly decreased precision. (Fig. 1d–f; Additional file 1: Fig. S1c). The genotyping performance in soybean genomes was better than that of maize, but worse than A. thaliana and rice genomes (Fig. 1g–i; Additional file 1: Fig. S1e). For genotyping in the maize genome, vg map and vg giraffe are the only tools that maintain high precision (0.93–0.98) and recall (0.72–0.80) in SV genotyping, while BayesTyper and Paragraph present high precision (0.87, 0.83) and recall (0.85, 0.83) for indel genotyping (Fig. 1j–l; Additional file 1: Fig. S1f). When genotyping in the allotetraploid Brassica napus, the performance is even worse, especially for SNPs and indels (Additional file 1: Fig. S2). This may be due to the inference of homoeologous alleles between the two subgenomes of Brassica napus.
When genotyping complex SVs like inversions and duplications, the performance differences between the software are obvious. Although all software can detect inversion, vg map, vg giraffe, GraphAligner, and Gramtools only worked effectively when the number of genomes was one. On the other hand, Paragraph and BayesTyper demonstrated superior performance with F-scores over or around 0.8 when genotyping inversion and duplications in graphs containing multiple A. thaliana or rice genomes (Additional file 1: Fig. S3a, b). Apparently, these tools presented lower F-scores for genotyping heterozygous SVs, especially the duplications (Additional file 1: Fig. S3).
As a comparison, we also employed three linear reference-based genotypers including GATK [41] and DeepVariant [42] (for both SNPs and indels), and Delly [43] (for SV) to do genotyping using the same simulated short reads dataset. Both GATK and DeepVariant had a F-score above 0.9 for SNP genotyping in all plant genomes except the maize, but a relatively lower F-score in indel genotyping for the same plant genomes (Additional file 1: Fig. S4a, b). We found that some graph-based tools have higher or very close F-scores compared to GATK and DeepVariant, although other tools presented relatively lower F-scores. However, the graph-based tools exhibited much better performance compared to the tool Delly, especially for the large insertions (Additional file 1: Fig. S4c, d).
Performance on plant genomes with different complexityMoreover, tests conducted across various plant genomes revealed that certain tools, such as GraphAligner and GraphTyper2, exhibited relatively poor performance when dealing with larger genomes. Conversely, BayesTyper were able to retain high precision and recall even when working with more complex genomes (Fig. 1; Additional file 1: Fig. S1; Additional file 2: Table S5).
As numerous plant genomes are heterozygous, we also simulated heterozygous A. thaliana and rice for the same test. Among the tools we evaluated, Paragraph, BayesTyper, and GraphTyper2 were less affected by heterozygosity, whereas other software experienced a decrease in recall for all variants (Additional file 1: Fig. S1, S5). We also explored the influence of heterozygosity on genotyping by testing on synthetic diploid genomes with varying levels of heterozygosity (Fig. 2; Additional file 1: Fig. S6; Additional file 2: Table S6). The results showed that the damage to genotyping was proportional to the level of heterozygosity, especially for deletions and inversions. Paragraph and BayesTyper proved to be the most stable tools, both with high precision (0.75–0.97) and recall (0.79–0.96) for small and large indel genotyping (Fig. 2; Additional file 1: Fig. S6). However, tools such as vg map, vg giraffe, GraphAligner, and Gramtools were relatively more influenced by heterozygosity (Fig. 2; Additional file 1: Fig. S6), especially for genotyping in repetitive regions (Additional file 1: Fig. S7b).
Fig. 2
The effect of heterozygous rate on the performance of different graph-based genotyping methods. The six ROC curve plots correspond to the genotyping results for synthetic heterozygous A. thaliana genomes with different heterozygous rates (0%, 0.27%, 0.52%, 1.03%, 2.07%, and 2.35%). The genome graph for genotyping is constructed from the A. thaliana reference genome and seven alternative genomes. Paired-end (2 × 150 bp) short reads with 30× depth are simulated for genotyping. For each genotyper, precision is plotted against recall as the genotyping quality threshold varies. Read Depth on variant sites is used as a substitution score when genotype quality is not available. Arrows indicate the circles hidden by other circles in the plot due to identical or nearly identical precision values. Detailed results are also provided in Additional file 2: Table S6
Influence of sequencing parametersNext, we conducted a comparison of each genotyper’s performance across datasets of paired-end reads with a range of read lengths (100 bp, 150 bp, 250 bp), fragment size (300 bp, 400 bp, 500 bp, 600 bp), and sequencing depths (5×, 10×, 20×, 30×, 50×). When the read length was shorter, such as 100 bp, only Paragraph showed a similarly high F-score for both small and large variants compared to testing with longer reads (Additional file 1: Fig. S8). Other tools, such as vg map and PanGenie, also had close F-scores with shorter (100 bp) or longer reads (150 bp, 250 bp) for variants except inversions. Additionally, a marginal effect could be observed when increasing the read length from 150 to 250 bp (Additional file 1: Fig. S8). Apparently, various types of variants had similar requirements for sequencing length (Additional file 1: Fig. S8). The performance on rice and heterozygous Arabidopsis genomes followed the same trend as A. thaliana, suggesting that genome size and complexity may not affect the read length requirement by software (Additional file 1: Fig. S9, S10). In addition to using short reads, we also tested GraphAligner to map third-generation data against the genome graph, using long reads of 20 kb and 75 kb. The genotyping accuracy of 20 kb reads was superior to that of 75 kb reads, likely due to the former’s higher accuracy (0.96 vs. 0.85) (Additional file 1: Fig. S8, S10). Furthermore, when the read length was 150 bp, fragment sizes (300–600 bp) had no obvious effect on the genotyping accuracy of these genotypers (Additional file 1: Fig. S11).
Overall, when the sequencing depth was around 5–10×, Paragraph was able to achieve relatively high performance (precision > 0.81, recall > 0.91), whereas other software required more than 10× reads (Additional file 1: Fig. S12). Besides, increasing the sequencing depth beyond 20×, only brought marginal improvements in genotyping performance across all variant types. With 30× data, all tested software almost reached the upper limit of genotyping precision and recall (Additional file 1: Fig. S12). These findings were consistent across different genomes, including the rice and heterozygous A. thaliana genomes, suggesting that genome size and complexity may not affect the sequencing depth requirements of these genotypers (Additional file 1: Fig. S13, S14). Besides, genotyping SVs requires more sequencing data than SNPs and indels (Additional file 1: Fig. S12, S14).
Effects of genome number in the graphAs the search space of alignment may expand exponentially when more variants or genomes are graphed, we next evaluated how the number of graphed genomes affects variant genotyping. We reconstructed genome graphs for A. thaliana with a range (1, 7, 15, 30, 50) of individual genomes. From our evaluation, only tools Paragraph, BayesTyper, and GraphTyper2 demonstrated relatively stable precision and recall for SNP, indel, and insertion genotyping when graphed genomes increased (Fig. 3a, c; Additional file 1: Fig. S15a). When only seven alternative genomes’ variants were graphed, existing methods could still achieve a good genotyping F-score (0.85–0.99 for SNPs, 0.81–0.97 for indels, 0.73–0.93 for deletions, 0.79–0.98 for insertions, 0.01–0.89 for inversions). However, when 50 alternative genomes were incorporated into the genome graph, the F-scores of deletion genotyping decreased to only 0.4–0.74. The recall of genotyping for vg map, vg giraffe, and GraphAligner decreased as more genomes were incorporated. For example, as the number of graphed genomes increased from 1 to 50, the recall rate of vg giraffe decreased considerably (0.97 vs. 0.61 for SNPs, 0.99 vs. 0.66 for indels, 0.99 vs. 0.48 for deletions, and 0.92 vs. 0.53 for insertions, 0.55 vs. 0.23 for inversions), while the precision did not change much (Fig. 3a; Additional file 1: Fig. S15). In contrast, Paragraph, BayesTyper, and GraphTyper2 showed greater robustness in terms of recall (Fig. 3a; Additional file 1: Fig. S15). For example, BayesTyper’s recall rates remained above 0.95 for all types of variants except duplication (0.78), but the genotyping precision of deletions and inversions decreased by 0.52 (1.0 vs. 0.48) and 0.49 (1.0 vs. 0.51), respectively. Notably, the insertions precision of PanGenie was higher than that of deletions, possibly because PanGenie needs to count the number of k-mers for each haplotype at nodes. However, as only breakpoint sequences can be used for deletions, this will result in reduced genotyping precision.
Fig. 3
The effect of genome number on the performance of different graph-based genotyping methods. The five ROC curve plots correspond to genotyping results with different numbers (1, 7, 15, 30, 50) of graphed genomes. The genome graph for genotyping is constructed from the A. thaliana reference genome and different numbers of alternative genomes. Paired-end (2 × 150 bp) short reads with 30× depth are simulated for genotyping. For each genotyper, precision is plotted against recall as the genotyping quality threshold varies. Read depth on variant sites is used as a substitution score when genotype quality is not available. Arrows indicate the circles hidden by other circles in the plot due to identical or nearly identical precision values. Detailed results are also provided in Additional file 2: Tables S7–S8
Influence of breakpoint errors on SVs genotypingThe breakpoints of SVs often have some deviation to the true coordinates. To evaluate the tolerance of graph-based genotypers for such SV breakpoint errors, we introduced a 1–20-bp deviation to the true breakpoint coordinates of SVs. For almost all tools, a negative correlation was observed between F-scores and breakpoint deviations (Fig. 4a; Additional file 1: Fig. S16). Consistent with the previous report, BayesTyper, which is based on exact k-mer alignments, was more susceptible to breakpoint deviations. However, another k-mer alignment-based genotyper, PanGenie, performed much better than BayesTyper. This may be because PanGenie can also leverage already known haplotypes to infer genotypes [19].
Fig. 4
The impact of sequence context and event size on different graph-based genotyping methods. a Impact of breakpoint errors on genotyping (0 bp, 1 bp, 3 bp, 5 bp, 10 bp, 20 bp). b Impact of variant length (alternative allele length minus reference allele length) on genotyping. c Impact of number of SNPs and indels around breakpoints on genotyping. d, e Effects of repeat sequence types around breakpoints on genotype, partitioned by variant type: d deletions and e insertions. Different types of repeat sequences are annotated by RepeatMasker. The genome graph for genotyping is constructed from the A. thaliana reference genome and seven alternative genomes. Paired-end (2 × 150 bp) short reads with 30× depth are simulated for genotyping. For each genotyper, precision is plotted against recall as the genotyping quality threshold varies. Read depth on variant sites is used as a substitution score when genotype quality is not available. Detailed results are also provided in Additional file 2: Tables S9–S12
Overall, the performance on genotyping deletions was better than that of insertions, inversions, and duplications. For genotyping deletions, PanGenie, vg map, vg giraffe, Paragraph, and GraphAligner displayed consistent performance with breakpoint deviations smaller than 10 bp (Fig. 4a). For genotyping insertions, the F-scores of vg map, GraphAligner, Paragraph, and Gramtools still had 50% to 90% of that of 0 bp when the breakpoint error reached 5 bp, while the F-scores of other software at 1 bp deviation were reduced by more than 50% (Fig. 4a). Further, only Paragraph and vg giraffe maintained performance within a 10 bp error on the genotyping of inversions (Additional file 1: Fig. S16a). However, none of the software was able to tolerate breakpoint errors in duplications (Additional file 1: Fig. S16b).
Impact of event size and sequence context on SV genotypingIn addition, we stratified SVs based on event size, number of SNPs and indels within breakpoints of 100 bp, and families of repetitive sequences around to estimate the effect of sequence context on SV genotyping. Overall, Paragraph and BayesTyper demonstrated the best genotyping performance across different size ranges of SVs. Although the F-scores of both Paragraph and BayesTyper were lower (ranging from 0.17 to 0.81) for deletions larger than 5 kb, they still maintained high F-scores (≥ 0.95) for insertions (Fig. 4b). Previous studies have reported that small variants near the breakpoints could affect the accuracy of SV calling [11]. However, our experiment showed that small variants had no serious damage on SV genotyping for these graph-based tools (Fig. 4c), which might be attributed to the improved alignment accuracy as alternative alleles (small variants) are introduced into the graphs.
The genotyping performance of all methods was reduced in the repetitive regions compared to the non-repetitive regions (Fig. 4d, e; Additional file 1: Fig. S7). For example, the GraphAligner F-score was even 47% lower in deletions than in non-repetitive regions (Additional file 1: Fig. S7). Compared to other software, Paragraph and BayesTyper demonstrated comparatively stable performance in repetitive regions (Additional file 1: Fig. S7). Repeat sequences had a more severe influence on the genotyping of deletions (17%) than SNPs (9%), indels (11%) and insertions (8%) (Fig. 4d, e; Additional file 1: Fig. S7). Similar to the linear reference-based SV genotyping [11], LTRs had the greatest impact on genotyping. For example, the recalls of deletion genotyping for vg map, vg giraffe, and GraphAligner were reduced by 0.31, 0.31, and 0.36, respectively (Figs. 4d, e).
Development of an ensemble genotyperIn summary, these graph-based genotypers performed differentially for small and large variants in terms of precision and recall. Further analysis on the overlap of true variant genotyping among the eight genotypers revealed that many variants were not correctly genotyped by some genotypers but were correctly genotyped by others (Additional file 1: Fig. S17, an example shown in Additional file 1: Fig. S18), suggesting an ensemble genotyping strategy may improve genotyping performance.
Here, we developed an Ensemble Variant Genotyper (EVG) by integrating various graph-based genotyping methods (Fig. 5a). Before running the genotyping pipeline, EVG modifies VCF-formatted variants input files provided by users to a common format that can be used for downstream analysis (EVG convert). For instance, graph genotyping tools normally require sequence information from input files but not containing any special characters. Additionally, EVG could filter variants based on minor allele frequency (MAF) and missing rate, if indicated. The EVG pipeline starts with the selection of the most suitable software according to the reference genome size, sequencing data quality, type of variants, and software running requirements (Additional file 1: Fig. S19, see the “Methods” section for details).
Fig. 5
The workflow and performance of the ensemble variant genotyping method EVG. a The variant genotyping workflow of EVG mainly consists of three steps: (1) subsample sequencing reads, filter variants, and reformat the input variant VCF file; (2) select one or multiple suitable graph-based genotypers (shown as colored dots) and do genotyping with each of them in parallel; (3) merge the genotype results from step 2 and determine the final genotype for each variant. b Genotyping performance of SNPs, indels, ins & del (insertions and deletions), inversions, and duplications on simulated A. thaliana genomes under different sequencing depths (5×, 10×, 20×, 30×, 50×) and genome numbers (1, 15, 50). The genome graph for genotyping is constructed from the A. thaliana reference genome and different numbers of simulated alternative genomes. Paired-end short-reads (read length: 2 × 150 bp) are simulated for variant genotyping. For each genotyping scenario, the F-measure values of the other two best-performing genotypers are shown here. Transparent and solid bars represent the ability to predict variant “presence” (detection of variant regardless of the genotype) and exact “genotype” (requires both the detection of the variant and agreement between its called genotype and the true genotype). Detailed results are also provided in Additional file 2: Table S13
To address the issue caused by inconsistent coordinates of the same variants from different software, EVG then clusters the outputs based on the size and position of variants and constructs a variant graph (EVG merge) (Additional file 1: Fig. S20, see the “Methods” section for details). Finally, the most probable combination of genotypes is determined as the genotype with the most support by different genotyping tools at each node (Fig. 5a). To accelerate genotyping, EVG can randomly downsample reads to default depth (15×) when sequencing data is high enough. For oversized genome graphs with numerous variants, EVG offers an optional fast mode where Paragraph is only used for SVs genotyping. These allow EVG to significantly accelerate genotyping while sacrificing very little precision and recall (Fig. 5b).
To assess the performance of EVG, we tested it on all simulated datasets from this study. Firstly, unlike other graph-based genotypers, EVG achieved the highest F-score for both small and large variants with just 5 × 150 bp paired-end short-reads (Fig. 5b; Additional file 1: Fig. S21). Secondly, EVG’s performance was more robust when more genomes were graphed. Specifically, for genome graphs with 50 genomes, EVG achieved a F-score above 0.95 for SVs with only 5× short reads, while other best genotypers only reached 0.79 (Fig. 5b; Additional file 1: Fig. S21). In terms of SNP genotyping, the fast mode of EVG performed slightly lower than the best-performing software, as Paragraph is only used for SV genotyping in order to reduce CPU time consumption (Fig. 5b).
Performance on real dataFinally, we carried out testing on real data consisting of 30× Illumina short reads from three diploid homozygous genomes (A. thaliana, rice, and maize) [5, 38, 40, 44, 45] as well as one diploid heterozygous genome of Apricot (Prunus armeniaca) [46, 47]. Testing was also performed on a genome graph of seven genomes for all genotypers. (Additional file 1: Table S14). Notably, Gramtools was also excluded from the real data testing. The evaluation of maize was also limited to chromosome 10 to reduce resource consumption. In comparison to the simulated data, the F-score across genotypers in the real data was lower (Fig. 6). Such a reduction was even worse (< 0.65) for the maize genome, probably because of the h
留言 (0)