Plant material and growth conditions
The maize kernels used in this study were obtained from the USDA National Plant Germplasm System (https://npgsweb.ars-grin.gov). The seedlings were grown in Sungro Horticulture professional growing mix (Sungro Horticulture Canada) under controlled conditions. The soil was saturated with tap water and the seedlings were exposed to a mixture of 4100 K (Sylvania Supersaver Cool White Delux F34CWX/SS, 34 W) and 300 K (GE Ecolux with starcoat, F40CX30ECO, 40 W) light, with a photoperiod of 16 h of light and 8 h of darkness. The temperature was maintained at approximately 25 °C during the light hours, and the relative humidity was approximately 54%. The above-ground seedling tissues were harvested between 8 and 9 AM, 6 days after sowing. Flash-frozen seedling tissue was used to generate scifi-ATAC-seq libraries for B73 and Mo17 mixed genotypes. And fresh seedling tissue was used for the scifi-ATAC-seq library with seven different maize genotypes.
scifi-ATAC-seq protocol
A detailed step-by-step sci-ATAC-seq protocol with lists of necessary reagents and equipment is included in the Supplementary Methods. The Tn5 expression and purification steps were carried out according to the method described by Tu et al. (2020) [22], and the plasmids were obtained from Addgene (accession number 127916).
Assembly of indexed Tn5 transposase complexes
To generate indexed Tn5 transposase complexes, we modified the Tn5-ME-A and Tn5-ME-B by adding a 5-nucleotide barcode (with 12 distinct barcodes for Tn5-ME-A and 8 distinct barcodes for Tn5-ME-B; see Supplementary Methods Table S1 for barcode sequences). Each indexed oligonucleotide was annealed to a 19-bp complementary mosaic-end oligonucleotide (Tn5-ME-rev, 5′ phosphorylated, Supplementary Methods). The annealing reaction was carried out by mixing the oligonucleotides at a 1:1 molar ratio (Tn5-ME-A or Tn5-ME-B: Tn5-ME-rev) at a final concentration of 100 μM. The mixture was heated to 95 °C, cooled gradually to 20 °C at a rate of – 1 °C per minute, and then held at 20 °C. The annealed oligonucleotides were then mixed at a 1:1 molar ratio (Tn5-ME-A: Tn5-ME-B). To assemble the transposase, 10 μL of Tn5 transposase was added to 0.143 μL of the annealed adapter mixture, mixed well by pipetting slowly, incubated at room temperature for 60 min, and then stored at – 20 °C until the tagmentation reactions were performed [23].
Nuclei isolation with quick purification
Approximately 3–4 maize seedlings were chopped on ice for about 2 min in 600 μL of pre-chilled Nuclei Isolation Buffer (NIB cutting, 10 mM MES-KOH pH 5.4, 10 mM NaCl, 250 mM sucrose, 0.1 mM spermine, 0.5 mM spermidine, 1 mM DTT, 1% BSA, 0.5% TritonX-100), which was modified from the original buffer composition [24]. After chopping, the total mixture was filtered with a 40-μm cell strainer and then centrifuged at 500 rcf for 5 min at 4°C. The supernatant was carefully removed, and the pellet was resuspended in 500 μL of NIB wash buffer (10 mM MES-KOH, pH 5.4, 10 mM NaCl, 250 mM sucrose, 0.1 mM spermine, 0.5 mM spermidine, 1 mM DTT, and 1% BSA). The sample was filtered with a 20-μm cell strainer and then carefully loaded onto the surface of 1 mL 35% Percoll buffer (made by mixing 35% Percoll and 65% NIB wash buffer) in a 1.5-mL centrifuge tube. The nuclei were centrifuged at 500 rcf for 10 min at 4°C. After centrifugation, the supernatant was carefully removed, and the pellets were washed once in 100 μL TAPS buffer (25 mM TAPS-NaOH, pH 8.0, and 12.5 mM MgCl2) and then resuspended in 30 μL of 2.5 × TAPS buffer. About 5 μL of nuclei were diluted 10 times and stained with DAPI (Sigma Cat. D9542). The nuclei quality and density were evaluated with a hemocytometer under a microscope. Finally, after nuclei for both genotypes were isolated separately, equal nuclei numbers of B73 and Mo17 were mixed together and the nuclei density was adjusted to 0.5 k ~ 1 k/μL with TAPS buffer.
Indexed Tn5 tagmentation and pooling
To generate a combination of 96 indexed transposases, 1.5 μL of Tn5-ME-A with 12 distinct barcodes were dispensed by rows, and 1.5 μL of Tn5-ME-B with 8 distinct barcodes were dispensed by columns in a 96-well plate. Each well had a unique combination of A and B indexed Tn5. To each well, 10 μL of nuclei in TAPS buffer with 0.1% Tween 20 and 0.01% digitonin was added, and the plate was sealed. The tagmentation reaction was carried out for 60 min at 37°C. The reaction was stopped by adding 12 μL of stop buffer (10 mM Tris–HCl pH 7.8, 20 mM EDTA, pH 8.0, 2% BSA) supplemented with ethylenediaminetetraacetic acid (EDTA) to quench the Mg2 + . All nuclei were transferred to a reservoir and then divided into two 1.5 mL centrifuge tubes. The nuclei were pelleted, resuspended in 200 μL diluted nuclei buffer (DNB, 10 × Genomics Cat#2,000,207), filtered with a 40 um strainer, pooled into one PCR tube, and centrifuged at 500 rcf for 2 min at 4°C. After centrifugation, the supernatant was carefully removed, and the nuclei (approximately 3 μL) were resuspended in 5 μL of DNB and 7 μL ATAC buffer B (10 × Genomics Cat#2,000,193).
Library preparation and sequencing
scATAC-seq libraries were prepared using the Chromium scATAC v1.1 (Next GEM) kit from 10xGenomics, following the manufacturer’s instructions. (10xGenomics, CG000209_Chromium_NextGEM_SingleCell_ATAC_ReagentKits_v1.1_UserGuide_RevE). The leftover nuclei after loading to ChIP-H were diluted and stained with DAPI, and nuclei quality and density were evaluated with a hemocytometer under a microscope. The final libraries were sequenced using an Illumina NovaSeq 6000 S4 in the dual-index mode using custom sequencing primer sets (Supplementary Methods). To balance the nucleotide distribution at the beginning of the forward and reverse reads, the proportion of the scifi-ATAC-seq library in a lane should be less than 50% or an extra spike-in library (e.g., PhiX control from Illumina) should be added to the lane. The libraries were sequenced to an average depth of 7,617 read pairs per cell, with an average unique reads rate at 62.3%. The scATAC-seq libraries were sequenced about 51.7 k read pairs per cell [4].
Raw reads processing and alignment
During the preprocessing of all single-cell ATAC-seq data, the 16-bp i5 beads barcode was added to the read names of the paired-end reads using the extract function from UMItools v.1.01 [25]. The customization parameter “–bc-pattern = NNNNNNNNNNNNNNNN” was used for this process. Moreover, for scifi-ATAC-seq data, the inline Tn5 barcode was demultiplexed and subsequently appended to the read names using cutadapt v3.4 [26]. Next, the processed reads were aligned to the Zea mays reference genome v5 [27] using BWA-MEM v0.7.17 [28]. To obtain high-quality, properly paired, and unique alignments, the view function from samtools v1.9 [29] was applied with the parameters “-q 10 -f 3.” Additionally, reads with XA tags were filtered out. Subsequently, the cell barcodes were included in the alignments using the CB tag and BC tag for the 10X Genomics scATAC-seq and scifiATAC-seq datasets, respectively. To eliminate duplicate reads, Picard Tools v.2.21.6 (http://broadinstitute.github.io/picard/) was employed while considering the cell barcode. Finally, the alignments were converted to single base-pair Tn5 integration sites in a BED format by adjusting the start coordinates of the forward and reverse strands by + 4 and − 5, respectively. Only unique Tn5 insertion sites within a cell were retained for downstream analysis.
Nuclei calling and quality control
The R package Socrates [4] was utilized for nuclei identification and quality control. In summary, the BED file containing single base-pair Tn5 integration sites was imported into Socrates along with the Zea mays v5 GFF gene annotation and the genome index file. The scaffolds (“scaf_23,” “scaf_34,” and “scaf_36”) were considered as organelle genomes. To identify bulk-scale ACRs (Accessible Chromatin Regions) in Socrates, the callACRs function was employed with the following parameters: genome size = 8.5e8, shift = − 75, extsize = 150, and FDR = 0.1. This step allowed us to estimate the fraction of Tn5 integration sites located within ACRs for each nucleus. Metadata for each nucleus were collected using the buildMetaData function, using a TSS (Transcription Start Site) window size of 2 kb (tss.window = 2000). Subsequently, sparse matrices were generated with the generateMatrix function, using a window size of 500. High-quality nuclei were identified based on the following criteria: a minimum of 1000 Tn5 insertion sites per nucleus, at least 20% of Tn5 insertions within 2 kb of TSSs, and at least 20% of Tn5 insertions within ACRs across all datasets. Additionally, a maximum of 30% of Tn5 insertions in organelle genomes was allowed.
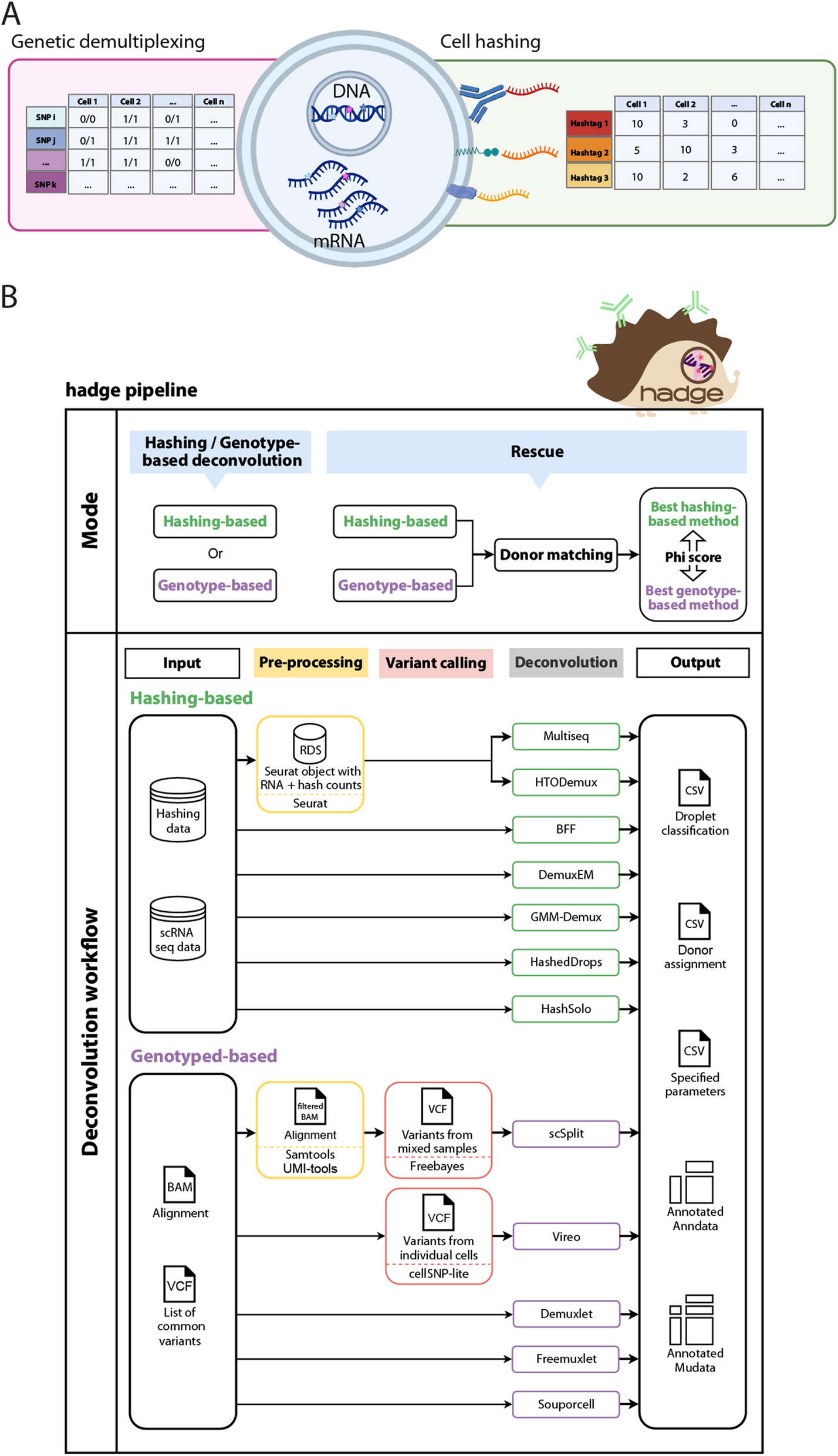
Cell barcode collision detection
The term “cell barcode” refers to the barcode used to determine cell identity. In the standard scATAC-seq, the cell barcode corresponds exclusively to the barcode derived from hydrolyzed GEM beads following microfluidic partitioning. However, in scifi-ATAC-seq, the cell barcode encompasses both the beads barcode and the Tn5 barcode. Cell barcode collision occurs when more than one cell shares the same cell barcode. In traditional droplet-based assays, cell barcode collision occurs if multiple cells enter one droplet. In scifi-ATAC-seq, cell barcode collision happens when multiple cells occupy the same droplet, and simultaneously, they share identical Tn5 barcodes. Cell barcode collisions were identified using a previously described approach [4]. Specifically, the known genotype data were obtained from Panzea[30] and lifted over to v5 genome [27] coordinates using CrossMap (v0.5.1) [31]. Only homozygous biallelic SNPs were retained for further analysis. The Souporcell (git version 6872d88) pipeline [32] was used to count the number of reads for each genotype, using known common variants and specific non-default parameters (–min_alt 50, –min_ref 50, –max_loci 25,000,000, –skip_remap TRUE). In the dataset comprising a mixture of two genotypes (B73 and Mo17), genotype identification was performed by modeling allele counts as a binomial distribution, accounting for a conservative sequencing error rate of 0.05. Posterior probabilities were estimated via Bayes theorem to assign the genotype or identify cell barcode collisions (i.e., mixtures of genotypes) with the highest probability. A minimum threshold of 50 reads covering common variants within a cell was used to confidently assign the genotype. The total SNP number between genotypes is around 1.6 million and the SNP rate is about 0.70/kb. The index hopping contamination was calculated as the proportion of reads that did not match the assigned genotype among all reads covering the biallelic SNPs. In the dataset featuring a mixture of two genotypes, cell doublets can originate from either two cells of the same genotype (A × × A or B × B) or cells from different genotypes (A × B or B × A). However, the observed collisions consist entirely of cell doublets from different genotypes, representing only approximately half of the collision events that actually take place in the experiment. Therefore, there should be an equal proportion of doublets mixed with nuclei of the same genotype. For the seven-genotype-mixed scifi-ATAC-seq data, expected genotypes were assigned by matching known Tn5 barcodes. Any reads that did not match the expected genotype were considered as belonging to another genotype. The same genotype calling approach described above was then used to assign nuclei to their expected genotype and identify mixtures of genotypes resulting from index hopping contamination. Given the varying cell numbers per well, we used a modeling-based approach to estimate the barcode collision rate by calculating the probability of obtaining any two cells from the same well in a four-nuclei droplet (mean nuclei number per droplet is 3.4, Fig. S6c).
Integrated clustering analysis
The integrated clustering analysis of the four datasets, combining scifi-ATAC-seq and 10X Genomics scATAC-seq data, was performed using the R package Socrates [4]. In brief, firstly, the ACRs were identified by treating each library as a traditional bulk ATAC-seq library with function callACRs (genomesize = 8.5e8, shift = − 75, extsize = 150, fdr = 0.1). Then a binary nucleus × ACR matrix was generated with the function generateMatrix (peaks = T). The ACRs that were accessible in less than 0.15% of all nuclei, and nuclei with less than 100 accessible ACRs were removed. Then the filtered nucleus × × ACR matrix were normalized with the term-frequency inverse-document-frequency (TF-IDF) algorithm(doL2 = T). The dimensionality of the normalized accessibility scores was reduced using the function reduceDims (method = "SVD", n.pcs = 25, cor.max = 0.5). The reduced embedding was visualized as a UMAP embedding using projectUMAP (k.near = 15). Approximately 5% of potential cell doublets were identified and filtered by performing a modified version of the Socrates workflow on each library separately with the function detectDoublets and filterDoublets (removeDoublets = T). To address genotype and batch effects, we used the R package Harmony with non-default parameters (do_pca = F, vars_use = c("library", "genotype"), tau = c(5), lambda = c(0.1, 0.1), nclust = 50, max.iter.cluster = 100, max.iter.harmony = 30). The dimensionality of the nuclei embedding was further reduced with Uniform Manifold Approximation Projection (UMAP) via the R implementation of umap (n_neighbors = 30, metric = “cosine”, a = 1.95, b = 0.75, ret_model = T). Finally, the nuclei were clustered with function callClusters (res = 0.4, k.near = 30, cl.method = 4, m.clust = 100).
A similar clustering process was applied to the 7-genotype-mixed scifi-ATAC-seq dataset with minor modifications. Specifically, we removed only the genotype effect using Harmony, and the final clusters were identified at a resolution of 0.5.
Cell-type annotation
To assign cell types for each cluster, we used a combination of marker gene-based annotation and gene set enrichment analysis. Initially, we compiled a list of known cell-type-specific marker genes for maize seedlings through an extensive literature review, primarily referring to Marrand et al. (2021) (Additional file 2: Table S5) [4]. Firstly, the gene chromatin accessibility score was calculated using the Tn5 integration number in the gene body, 500-bp upstream and 100-bp downstream region, then the raw counts were normalized with the cpm function in edgeR. The Z-score was calculated for each marker gene across all cell types with scale function in R, and key cell types were assigned based on the most enriched marker genes with the highest Z-score. Ambiguous clusters displaying similar patterns to key cell types were assigned to the same cell type as the key cell types, reflecting potential variations in cell states within a cell type. For gene set enrichment analysis, we used the R package fgsea [33], following a methodology described previously [4]. Firstly, we constructed a reference panel by uniformly sampling nuclei from each cluster, with the total number of reference nuclei set to the average number of nuclei per cluster. Subsequently, we aggregated the read counts across nuclei in each cluster for each gene and identified the differential accessibility profiles for all genes between each cluster and the reference panel using the R package edgeR. For each cluster, we generated a gene list sorted in decreasing order of the log2 fold-change value compared to the reference panel and utilized this list for gene set enrichment analysis. We excluded GO terms with gene sets comprising less than 10 or greater than 600 genes from the analysis and GO terms were considered significantly enriched at an FDR < 0.05 with 10,000 permutations. The cell type annotation was additionally validated by identifying the top enriched GO terms that align with the expected cell type functions (Additional file 2: Table S6,7).
ACR identification
Following cell clustering and annotation, ACRs were further identified using all Tn5 integration sites for each cell type and genotype with running MACS2 [34] with non-default parameters: –extsize 150 –shift -75 –nomodel –keep-dup all –qvalue 0.05. Then the cell type-based ACRs for each genotype were further redefined as 500-bp windows centered on the ACR coverage summit. To consolidate information across all clusters and genotypes, we concatenated all ACRs into a unified master list using a custom script, as previously described by Marrand et al. (2021) [4], calculated the ACR chromatin accessibility score based on the Tn5 integration count within the ACR region and then normalized it using the “cpm” function in edgeR [35]. ACRs with less than 3 cpm in all cell types and genotypes were removed for downstream analysis.







留言 (0)