Artificial Intelligence (AI) methods have obtained impressive results in digital pathology and in some cases, AI models even outperformed expert pathologists in cancer classification (Zhang et al., 2019, Hekler et al., 2019, Ehteshami Bejnordi et al., 2017). The hope is that AI can make the diagnosis more accurate, objective, reproducible, and faster in the future (Dimitriou et al., 2019).
To achieve this goal, trained, specialized AI models for each subtask are required, for example for the quantification of tumor-infiltrating lymphocytes in lung cancer (Shvetsov et al., 2022), metastasis detection of breast cancer in lymph nodes (Ehteshami Bejnordi et al., 2017, Schmidt et al., 2022) or Gleason grading of prostate cancer (Bulten et al., 2022, Otálora et al., 2020). Openly available, labeled datasets are limited to certain subtasks, and for many future applications, the aggregation of large amounts of labeled data remains challenging because the annotation requires medical experts. This makes the labeling process time-consuming and expensive. A common approach to labeling is to divide a region or Whole Slide Image (WSI) into small patches that are individually labeled (Dimitriou et al., 2019). The model is then trained to make local patch-level predictions that can be aggregated for the final diagnosis. The problem with supervised deep learning methods is the need for large amounts of detailed (patch-level) annotations for training to obtain a satisfying predictive performance. To alleviate this burden, semi-supervised learning (Li et al., 2018, Marini et al., 2021, Lu et al., 2020, Schmidt et al., 2022, Otálora et al., 2020) and multiple instance learning (Campanella et al., 2019, Chikontwe et al., 2020, Li et al., 2021) have become major fields of interest in the recent years. Another very promising approach to efficiently handle labeling resources is active learning.
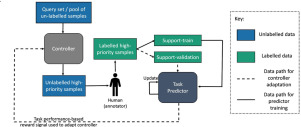
Active Learning (AL) describes machine learning methods that actively query the most informative labels. In the AL setting, the AI model starts training with a small set of labeled images and iteratively selects images from a large pool of unlabeled data. These selected images are labeled in each iteration by an ’oracle,’ in our application a medical expert. AL has several benefits: (i) The model training and dataset creation go hand-in-hand. The performance of the model is constantly monitored to assess if the collected labeled data is enough — or if more labeled data is needed to reach the desired performance. (ii) The model looks for the most informative images automatically in the acquisition step. In other approaches that require labeling (e.g. semi-supervised learning), finding these informative, salient images may require a lot of manual searching. (iii) AL is very data-efficient, while other paradigms such as multiple instance learning often require large datasets to compensate for missing instance labels (Campanella et al., 2019).
Notice that AL methods can be combined with other paradigms such as semi-supervised and multiple instance learning to leverage the advantages of multiple different perspectives (Gao et al., 2020, Huang et al., 2021). To narrow down our contribution, in this article we focus on improving existing probabilistic models in a pure AL setting, but we make several suggestions to combine the proposed FocAL method with other approaches as future work in Section 4.
Related work In AI research, different AL strategies have been proposed to determine the most informative images. Early approaches used the uncertainty estimation of support vector machines (Joshi et al., 2009), Gaussian processes (Li and Guo, 2013) or Gaussian random fields (Zhu et al., 2003) to rate the image informativeness. With the rise of deep learning, the focus shifted to Bayesian Neural Networks (BNNs) for AL (Gal et al., 2017), which was adapted several times for histopathological images (Rączkowski et al., 2019, Carse and McKenna, 2019, Meirelles et al., 2022). This approach has the advantage of a probabilistic uncertainty estimation which is not only used for acquisition, but it is also crucial for diagnostic predictions in medical applications. BNNs allow the application of several different uncertainty-based acquisition functions, such as BALD (Houlsby et al., 2011), Max Entropy (Rączkowski et al., 2019, Shannon, 1948), and Mean Std (Alex Kendall and Cipolla, 2017). Other publications focus on the user interface and server application of AL (Lee et al., 2021, Marée et al., 2016) rather than the AL model itself. In the existing literature, the uncertainty estimation is often only used to determine the amount of new information in each image. We extend this idea by using complementary uncertainty measures to avoid labeling uninformative, ambiguous, or artifactual images. In digital pathology, several data-related challenges like artifacts, ambiguities, and the typical huge class imbalance hinder the application of AL (see “Problem analysis” paragraph below). Our proposed method tackles these problems successfully by precise uncertainty estimations which leads to improved performance.
BNNs are not only of interest for the AL acquisition, their capacity to estimate the predictive uncertainty is highly important in safety-critical areas like medicine (Kwon et al., 2020) or autonomous driving (Alex Kendall and Cipolla, 2017). The uncertainty estimation helps to distinguish confident predictions from risky ones. In our case, we aim to decompose uncertainty into epistemic uncertainty and aleatoric uncertainty describing the model and data uncertainty, respectively (Der Kiureghian and Ditlevsen, 2009). Epistemic uncertainty describes uncertainty in model parameters that can be reduced by training with additional labeled data. Therefore it can serve as a measure of informativeness in the active learning process. Unfortunately, the epistemic uncertainty is not only high for informative, in-distribution images but also for OoD images. In fact, epistemic uncertainty has recently been used explicitly for OoD detection (Xiao et al., 2019, Mukhoti et al., 2021, Nguyen et al., 2022). Aleatoric uncertainty describes irreducible uncertainty in the data due to ambiguities that cannot be improved with additional labeling. Studies have shown that training with ambiguous data can harm the performance of the algorithm considerably if not taken into account (Gao et al., 2017, Bernhardt et al., 2022). In the Panda challenge, label noise associated with the subjective grading assigned by pathologists was considered to be a major problem (Bulten et al., 2022).
To estimate these uncertainties with BNNs, Kendall and Gal (2017) proposed a network with two final probabilistic layers, corresponding to the two uncertainty measures. A theoretically sound, more stable, and efficient approach (relying on a single probabilistic layer) was proposed by Kwon et al. (2020). We base our BNN for uncertainty estimations on the latter method due to the mentioned advantages. In Section 3.2 we outline how the uncertainty estimations can be interpreted in the context of clinical applications like pathology.
To avoid acquiring image patches with artifacts, we apply OoD detection. Commonly, OoD data refers to the data that originate from a different distribution than the training data (which are called “in-distribution”) (Sun et al., 2022). In the context of AL and pathology, we define the in-distribution as the distribution of patches containing (cancerous or non-cancerous) tissue. All the images with artifacts (such as pen markings, tissue folds, blood, or ink) (Kanwal et al., 2022) will be considered OoD. These artifacts are inevitable in real-world data and there are several reasons to exclude them from the distribution of interest for acquisition: (i) It is impossible to learn all possible artifacts explicitly due to their wide variability. We argue that a model should reliably classify tissue and predict a high uncertainty for everything it does not know. (ii) It harms the performance of AL algorithms to acquire images with artifacts, as we show empirically in Section 3. (iii) The model should focus on learning what is cancerous instead of everything that is not cancerous. By learning cancerous patterns it automatically learns what is not cancerous (everything else).
In OoD detection, early methods used the depth (Johnson et al., 1998, Ruts and Rousseeuw, 1996) or distance (Knorr and Ng, 1998, Knorr and Ng, 1999) of datapoints, represented by low-dimensional feature vectors. With the rise of deep learning, OoD metrics were often applied to the features extracted by a deep neural network (Abati et al., 2019, Sun et al., 2022, Lee et al., 2018). In line with previous research, we utilize extracted feature vectors and implement a density-based OoD scoring method (Breunig et al., 2000) to detect artifacts in the data.
Problem Analysis Although AL has a huge potential for digital pathology, we analyze several challenges that hinder its application in practice:
•
Medical imaging problems like pathology often have a high class imbalance. For example, in prostate cancer grading, the highest Gleason patterns may be underrepresented which needs to be taken into account during acquisition. Other AL algorithms treat each class equally and are not able to acquire a sufficient number of images of this underrepresented class in our experiments (Section 3).
•
Many patches are ambiguous. There may be patches for which even subspecialists disagree on their label, or patches containing multiple classes. Assigning labels to these patches is difficult and may be detrimental to the quality of the dataset and the algorithm’s performance. This not only slows the labeling process down, but it can also add noise to the training data as only one label per patch is assigned. In fact, label noise associated with the subjective grading assigned by pathologists was considered one key problem in the Panda challenge (Bulten et al., 2022).
•
WSIs can contain many different artifacts, such as pen markings, tissue folds, ink, or cauterized tissue. Existing AL algorithms often assign a high informativeness to these patches although they do not contain important information for model training, as we show empirically in the experimental Section 3.
We want to stress that similar problems of class imbalance, ambiguities, and artifacts are present in many other medical imaging applications, such as CT scans for hemorrhage detection (Wu et al., 2021), dermatology images for skin cancer classification (Esteva et al., 2017) or retinal images for the detection of retinopathy (Gulshan et al., 2016-12).
Contribution To address these challenges we propose Focused Active Learning (FocAL), a probabilistic deep learning approach that focuses on the underrepresented malignant classes while ignoring artifacts and ambiguous images. More specifically, we combine a Bayesian Neural Network (BNN) with Out of Distribution (OoD) Detection to estimate the three major elements of the proposed acquisition function. The weighted epistemic uncertainty rates the image informativeness, taking the class imbalance into account. The aleatoric uncertainty is used to avoid ambiguous images for acquisition. The OoD score helps to ignore outliers (like artifacts) that do not contribute information for the classification of tissue. While BNNs uncertainties, OoD scores, and AL based on an acquisition function are known concepts/approaches in machine learning literature, our contribution lies in combining them in a principled and sound manner to tackle class imbalance, ambiguities, and artifacts for medical images. We show empirically that the proposed acquisition function help focus on labeling salient, informative images while other methods often fail to address this realistic data setting.
The article is structured as follows. We outline the theory of the proposed model, including the BNN and OoD components of the acquisition function in Section 2. In Section 3, we perform an illustrative MNIST experiment to analyze the behavior of existing AL approaches when artifacts and ambiguities are present. Furthermore, we demonstrate that each of our model components works as expected to avoid acquiring images with ambiguities and artifacts, overcoming the problems of the existing approaches. For the Panda prostate cancer dataset, we perform an ablation study about the introduced hyperparameters, analyze the uncertainty estimations, and report in the final experiments that our method can reach a Cohen’s kappa of 0.763 with less than 1% of the labeled data (4400 labeled image patches). Finally, in Section 4 we conclude our article and give an outlook of future research.








留言 (0)