
記住我







The GM12878 (Coriell Cell Repository) and CH12.LX (kind gift from the Sherman Weissman lab) cells were cultured at 37 °C with 5% CO2 in RPMI 1640 medium (GIBCO, cat. no. 11875–093) containing 15% FBS (GIBCO, cat. no. 10437–028), 100 U/ml Penicillin Streptomycin (GIBCO, cat. no. 15140–122). Cells were counted and split into either 300,000 (GM12878) or 100,000 (CH12.LX) cells/ml three times a week. The cell lines used in this study were not authenticated or checked for mycoplasma contamination.
Human and mouse brain tissue samplesHuman cortex samples from the middle frontal gyrus were sourced from the Oregon Brain Bank from a 50-year-old female of normal health status. Samples were collected by an OHSU neuropathologist, placed into a labeled cassette, and cryopreserved in an airtight container in a − 80 °C freezer. The duration of time between the time of death and brain biopsy sample freezing, or post-mortem interim (PMI), was < 24 h.
Mouse brain tissue was collected as discarded tissue from mice used for unrelated studies approved by the OHSU IACUC. Whole mouse brains were dissected from sacrificed C57BL/6 J mice and flash-frozen in an isopentane-LN2 double-bath and stored at − 80 °C.
Mouse lung and liver tissue samplesAll animal activity was approved by the University of Arizona IACUC. Mice were euthanized via exsanguination followed by cervical dislocation to ensure death. For the samples used to evaluate the performance of txci-ATAC-seq in Fig. 4, whole mouse lungs and liver were dissected from 2 male C57BL/6 J mice that were 24 weeks old.
For the samples used to study the CC16-mediated chromatin dynamics in Fig. 5, age-matched (~ 8 weeks) WT and CC16−/− male mice on a C57BL/6 J background (as described in [64, 65]) were used to dissect whole lungs. Three replicates from each genotype were profiled. All six animals were born and raised in the same room and were tested to be specific-pathogen-free according to standard protocols using sentinel mice from the same room.
The dissected samples were flash-frozen in liquid nitrogen and then transferred to − 80 °C for long-term storage.
Human lung tissue samplesDe-identified lung pieces were provided by the Arizona Donor Network from two deceased male donors (a 36-year-old American Indian and a 62-year-old Hispanic Latino) as soon as possible after the time of death. All human lung samples were quickly frozen in the − 80 °C freezer and stored there prior to nuclear extraction.
Nuclei isolationNuclei isolation of cell linesThe nuclei isolation followed the procedures described in [13]. The cells were collected and washed with 1 × PBS (pH 7.4, Gibco, cat. no. 10–010-023) supplemented with 0.1% BSA (New England Biolabs, cat. no. B9000S) and then resuspended in 200 μl of ATAC-seq lysis buffer, which was made by supplementing ATAC resuspension buffer (RSB) with detergents (see below). RSB buffer is 10 mM Tris–HCl (pH 7.5, Invitrogen, cat. no. 15567027), 10 mM NaCl (Invitrogen, cat. no. AM9759), and 3 mM MgCl2 (Invitrogen, cat. no. AM9530G) in nuclease-free water. RSB was made in bulk and stored at 4 °C long-term. On the day of the experiment, the ATAC lysis buffer was made by adding 0.1% IGEPAL (Sigma, cat. no. I3021), 0.01% digitonin (Invitrogen, cat. no. BN2006), and 0.1% Tween-20 (Bio-Rad, cat. no. 1610781) to RSB. The detergent percentages reported are final concentrations. After resuspending cell pellets in the lysis buffer, they were incubated on ice for 3 min, and then the lysis was stopped by adding 1 ml RSB containing 0.1% Tween-20. The nuclei were counted with a hemocytometer by diluting 10 μl nuclei in 40 μl of 2 × Omni TD Buffer (20 mM Tris HCl pH 7.5, 10 mM MgCl2 and 20% Dimethyl Formamide) followed by adding 50 μl Trypan blue solution. In our previous report [56], we found that adding nuclei straight to Trypan blue solution will cause inflation of nuclei and diluting nuclei in TD buffer before exposure to Trypan blue improves the nuclei integrity. Following counting, we centrifuged nuclei at 500 r.c.f for 10 min at 4 °C and removed the supernatant. Then, the nuclei were either used to perform downstream experiments directly or resuspended in a nuclei-freezing buffer (NFB) containing 50 mM Tris-HCI (pH 8.0, Invitrogen, cat. no. 15568025), 5 mM Magnesium Acetate (Sigma, cat. no. 63052), 25% glycerol (VWR, cat. no. RC3290-32), 0.1 mM EDTA (Fisher, cat.no. AM9260G), 5 mM DTT (Fisher, cat. no. P2325), and 2% (v/v) protease inhibitor (Sigma, cat. no. P8340) for storage. The NFB was adopted from [66] and we previously used this buffer for preservation of nuclei for sci-ATAC-seq [2, 3, 67]. After diluting in NFB, 1 ml aliquots of the nuclei were flash-frozen in liquid nitrogen and then transferred to a liquid nitrogen dewar for long-term storage.
Nuclei isolation from brain tissueAt the time of nuclei dissociation, 50 ml of nuclei isolation buffer (NIB-HEPES) was freshly prepared with final concentrations of 10 mM HEPES–KOH (Fisher Scientific, BP310-500 and Sigma Aldrich 1,050,121,000, respectively), pH 7.2, 10 mM NaCl (Fisher Scientific S271-3), 3 mM MgCl2 (Fisher Scientific AC223210010), 0.1% (v/v) IGEPAL CA-630 (Sigma Aldrich I3021), 0.1% (v/v) Tween-20 (Sigma-Aldrich P-7949), and diluted in PCR-grade Ultrapure distilled water (Thermo Fisher Scientific 10,977,015). After dilution, two tablets of Pierce™ Protease Inhibitor Mini Tablets, EDTA-free (Thermo Fisher A32955) were dissolved and suspended to prevent protease degradation during nuclei isolation.
An at-bench dissection stage was set up prior to nuclei extraction. A petri dish was placed over dry ice, with fresh sterile razors pre-chilled by dry-ice embedding; 7 ml capacity Dounce homogenizers were filled with 2 ml of NIB-HEPES buffer and held on wet ice. Dounce homogenizer pestles were held in ice-cold 70% (v/v) ethanol (Decon Laboratories Inc 2701) in 15 ml tubes on ice to chill. Immediately prior to use, pestles were rinsed with chilled distilled water. For tissue dissociation, mouse and human brain samples were treated similarly. The still-frozen block of tissue was placed on the clean pre-chilled petri dish and roughly minced with the razors. Razors were then used to transport roughly 1 mg of the minced tissue into the chilled NIB-HEPES buffer within a Dounce homogenizer. Suspended samples were given 5 min to equilibrate to the change in salt concentration prior to douncing. Tissues were then homogenized with 5 strokes of a loose (A) pestle, another 5-min incubation, and 5–10 strokes of a tight (B) pestle. Nuclei were transferred to a 15-ml conical tube and pelleted with a 400 r.c.f centrifugation at 4 °C in a centrifuge for 10 min. The supernatant was removed and pellets were resuspended in 5 ml of ATAC-PBS buffer (APB) consisting of 1X PBS (Thermo Fisher 10,010) and 0.04 mg/ml (f.c.) of bovine serum albumin (BSA, Sigma Aldric A2058). Samples were then filtered through a 35-µm cell strainer (Corning 352,235). A 10 μl aliquot of suspended nuclei was diluted in 90 μl APB (1:10 dilution) and manually counted on a hemocytometer with Trypan Blue staining (Thermo Scientific T8154). The stock nuclei suspension was then diluted to a concentration of 2857 nuclei/μl in APB. Dependent on experimental schema, pools of tagmented nuclei were combined to allow for the assessment of pure samples and to test index collision rates.
Nuclei isolation of human lung, mouse lung, and mouse liver tissueThe human and mouse samples were dissected and stored at − 80 °C. The nuclei isolation procedure of lung and liver tissues was performed following the single-nucleus isolation protocol described in [68]. To do so, we cut a ~ 0.1 − 0.2 g piece from either human or mouse samples removed from − 80 °C and kept it on dry ice until use. The tissue block was thawed almost completely on ice for 1 min and then injected with 1 ml of cell lysis buffer, which was made of 1 × cOmplete protease inhibitor cocktail (1 tablet per 10 ml solution, Sigma-Aldrich, Cat. 11,836,153,001) in Nuclei EZ prep buffer (Sigma-Aldrich, Cat. NUC101), into the center of the tissue with a 30-G needle and syringe. Following lysis buffer injection, the tissue was chopped into small pieces with scissors and then transferred along with the lysing buffer into a gentleMACS C tube (Miltenyi Biotec, Cat. 130–096-334). An additional 1 ml of lysing buffer was added into the C tube to make a final volume of 2 ml. The minced tissue was then homogenized using a gentleMACS tissue dissociator by running the “m_lung_01” program followed by the first 20 s of the “m_lung_02” program. After homogenization, tissue lysate was briefly centrifuged to reduce foam and then passed through a 40-μm cell strainer in a 50-ml tube. After passing the sample through, the strainer was rinsed with 4 ml of washing buffer (PBS with 1% BSA). The nuclei were counted with a hemocytometer (see “nuclei isolation of cell lines” for details) and centrifuged at 500 r.c.f for 5 min at 4 °C. Then, we removed the supernatant and resuspended the nuclei in the NFB to make a concentration of 4–5 million nuclei/ml; 1 ml aliquots of the nuclei were flash-frozen in liquid nitrogen and then transferred to a liquid nitrogen dewar for long-term storage.
Sample multiplexingA 96-well plate pre-loaded with 5 μl of 500 nM pre-indexed Tn5 transposase per well (iTSM plate, kind gift of Illumina Inc.) was used to multiplex samples and perform barcoded transposition. Before using, the iTSM plate was thawed on ice and briefly mixed at 1400 rpm for 30 s on a pre-chilled thermomixer and then quickly spun to collect the enzyme at the bottom of the wells. To avoid sequencing with a custom recipe, the Tn5 enzyme was loaded with a common Tn5ME-A and a custom Tn5ME-B containing a partial sequence of i7 TruSeq primer (see Additional file 5: Table S4 for oligo sequence) and an 8-bp unique barcode (Additional file 5: Table S5). Both Tn5ME-A and Tn5ME-B were annealed to the Tn5MErev (Additional file 5: Table S4) before loading to Tn5.
Barnyard experimentsTwo different barnyard settings were designed to estimate the total collisions arising from pre- and/or post-pooling events. To test the total collision rate, the human and mouse cells were mixed in the same well at a 1:1 ratio to perform barcoded transposition (“true barnyard”). The collision rate driven by events downstream of pooling was evaluated by performing barcoded transposition on wells containing pure species (“pseudo-barnyard”) and pooling the human and mouse nuclei afterward. Detailed information about the cell sources used in each barnyard assay and each figure is shown in Additional file 5: Table S6.
Optimization of txci-ATAC-seq protocolCoupling barcoded transposition with standard 10× protocolThe nuclei isolated from human and mouse lungs were removed from the liquid nitrogen dewar (see “Nuclei isolation of human lung, mouse lung, and mouse liver tissue” for details) and then thawed in the water bath at 37 °C for 1 to 2 min until a tiny ice crystal remained. After thawing, the nuclei stored in 1 ml freezing buffer were diluted with 3 ml RSB supplemented with 0.1% Tween-20 and 0.1% BSA (RSB washing buffer) and then centrifuged at 500 r.c.f for 10 min in a pre-chilled (4 °C) swinging bucket centrifuge. The nuclei pellet was resuspended with another 1 ml of RSB washing buffer and then transferred to a 1.5-ml LoBind tube through a 40-μm Flowmi Cell strainer (Bel-Art SP Scienceware, Cat. 14–100-150). The filtered nuclei were pelleted at 500 r.c.f for 5 min in a pre-chilled fixed-angle centrifuge and then resuspended in 25 μl of 1.25 × Tagment DNA Buffer (Nextera XT Kit, Illumina Inc. FC-131–1024). For cell cultures, the human and mouse nuclei were freshly isolated as described in “Nuclei isolation of cell lines” and resuspended in 50 μl of 1 × Nuclei Buffer (10× Genomics, PN-2000207). Then, we counted nuclei for each sample and added 5000 nuclei diluted in 20 μl of 1.25 × Tagment DNA buffer to each well of the iTSM plate (see “Sample multiplexing” for details), except for the wells used to test the 10× reagents in which 5000 nuclei diluted in 5 μl of 1 × Nuclei Buffer were added to a mixture of 7 μl of ATAC Buffer B (10× Genomics, PN-2000193) and 3 μl of barcoded Tn5. The plate layout and well IDs for each barnyard condition are shown in Additional file 1: Fig. S1 and Additional file 5: Table S6. The tagmentation was performed at 55 °C for 30 min on a thermocycler with a heated lid. To quench the Tn5 activity, we added a 2 × Tagmentation Stop Buffer containing 40 mM EDTA (Invitrogen™, Cat. AM9260G) and 1 mM Spermidine (Sigma-Aldrich, Cat. S0266-1G) to the transposition reactions at a 1:1 ratio and incubated the plate on ice for 15 min. We found that stopping the transposition reaction was unnecessary and thereby removed this step from our final txci-ATAC-seq protocol. All nuclei were pooled and centrifuged at 500 r.c.f for 10 min. After aspirating the supernatant, nuclei were resuspended in 400 μl 1 × Nuclei Buffer and pelleted again. Then, we carefully removed the supernatant and resuspended nuclei in 30 μl 1 × Nuclei Buffer. After quantification of nuclei with a hemocytometer, 75,000 nuclei were taken and diluted in 1 × Nuclei Buffer to make a total volume of 15 μl, which underwent the standard 10× Chromium Next GEM protocol (v1.1, Document No. CG000209 Rev D from Steps 2 to 4) except following steps. For Sample Index PCR (step 4.1), we substituted the Single Index N Set A with a 25 μM i7 TruSeq primer and added 2.5 μl of customized i7 primer (Additional file 5: Table S7) to each 10× library followed by performing 8 cycles of PCR amplification. The resulting library was sequenced on a NextSeq 550 Platform (Illumina Inc.) using a Mid Output Kit with the following cycles: Read 1, 50 cycles; i7 index, 8 cycles; i5 index, 16 cycles; and Read 2, 77 cycles.
Blocking barcode-swappingFlash-frozen (human and mouse lung samples and human cell line, see “Nuclei isolation” for details) and fresh nuclei (mouse cell line, see “Nuclei isolation” for details) were used to test the efficiency of strategies to block barcode-swapping. The flash-frozen nuclei were thawed, washed, and filtered following the procedures described in the “Coupling barcoded transposition with standard 10× protocol” section. Both flash-frozen and freshly isolated nuclei were resuspended in 100 μl of PBS containing 0.04% BSA (PBSB) and quantified using a hemocytometer (See “Nuclei isolation of cell lines” for details). After counting, the nuclei were diluted in PBSB to a concentration of 2857 per μl (20,000 nuclei per well in 7 μl) and then mixed with a Tagmentation buffer solution (TBS, which was modified from the Omni protocol [13]) followed by transferring to the iTSM plate (see “Sample multiplexing” for details). Each 13 μl of TBS contains 12.5 μl of Illumina Tagment DNA Buffer, 0.25 μl of 1% Digitonin in DMSO (Promega (2%), Cat. PRG9441), and 0.25 μl of 10% Tween-20 (Bio-Rad, Cat. 1,610,781) in nuclease-free water. The barcoded transposition reaction was performed at 37 °C for 30 min on a thermocycler with a heated lid at 47 °C. Each blocking condition was assigned to 8 columns leading to a total of two 96-well plates for all 3 conditions. The plate layout and well IDs for each barnyard design in each blocking condition are shown in Additional file 1: Fig. S2a and Additional file 5: Table S6. After tagmentation, the nuclei used to test the Decoy DNA were transferred to a new 96-well plate with a multi-channel pipette, and 2.5 μl of 50 μM duplex DNA (see Additional file 5: Table S8 for the oligo sequence) was added to each well followed by incubating at 55 °C for 10 min. Then, we added the 2 × Tagmentation Stop Buffer (see “Coupling barcoded transposition with standard 10× protocol” for details) to the transposition reactions at a 1:1 ratio for all three blocking conditions and incubated the plates on ice for 15 min. Subsequently, the nuclei from the same blocking condition were pooled together and pelleted at 500 r.c.f for 10 min at 4 °C. After removal of supernatant from each tube, the nuclei were washed with 500 μl of 1 × Nuclei Buffer (10× Genomics, PN-2000207) with centrifugation of 500 r.c.f for 5 min at 4 °C and resuspended in 25 μl of 1 × Nuclei Buffer. Then, we counted nuclei with Trypan blue on a hemocytometer and diluted 100,000 nuclei in 1 × Nuclei Buffer to make a total of 15 μl for each blocking condition. The resulting three aliquots of nuclei were run on separate lanes of the 10× as per the manufacturer’s instructions (10× Chromium Next GEM Single Cell ATAC protocol v1.1, Document No. CG000209 Rev D) with the following modifications. During GEM Generation and Barcoding (Step 2.1a), the nuclei dedicated to evaluating the Blocking oligo were mixed with the Master Mix supplemented with 2.5 μl of 100 μM DNA oligo incorporating an inverted dT at the 3’-end (see Additional file 5: Table S8 for the oligo sequence); and the nuclei dedicated to testing the SBS primer were mixed with the Master Mix supplemented with 2.5 μl of 25 μM full SBS primer (Additional file 5: Table S8) for in-droplet exponential amplification. After GEM PCR (Step 2.5a), a 10 μl PCR product (10% GEM) was slowly aspirated and transferred to a new PCR tube and subjected to Post GEM Incubation Cleanup in parallel with the 90% sample. Following cleanup, we performed the Sample Index PCR on the 10% sample (step 4.1) by supplementing the PCR mixes of SBS primer, Decoy DNA, and Blocking oligo with 2.5 μl of 25 μM barcoded i7 TruSeq primer (Additional file 5: Table S7), which was used to replace the Single Index N Set A. The PCR mixes were amplified and monitored on a Bio-Rad CFX Connect Real-time cycler. The amplification was stopped when it appeared to be leveling off (i.e., the SBS primer was stopped at 4 cycles; the Decoy DNA and Blocking oligo were stopped at 15 cycles). To monitor the relative efficiencies of amplification in our initial test, we ended up introducing two different barcoded SBS primers in the SBS condition: one barcode was used for in-droplet amplification and another barcode was used for final library sample indexing. Both barcodes were assigned to thousands of reads per cell, indicating that both reactions were working. However, the theoretical expectation for the ratio between the two barcodes was 1/16 (because the second primer was used for 4 cycles of PCR). When we examined the ratio in our actual data, it was consistently ~ 1/3, indicating that the sample index amplification is not perfectly efficient (Additional file 1: Fig. S18). Therefore, in subsequent experiments using lung and liver tissues, we reduced the in-droplet PCR to 8 cycles and added an additional cycle of PCR for sample indexing. The resulting libraries with 10% GEM were pooled together with a library from an unrelated experiment to balance nucleotide diversity through the fixed sequence at the Tn5MErev region in Read 2, and then sequenced on a NextSeq 550 Platform (Illumina Inc.) using a Mid Output Kit with the following cycles: Read 1, 50 cycles; i7 index, 10 cycles; i5 index, 16 cycles; and Read 2, 92 cycles. While 8 cycles in i7 index and 77 cycles in Read 2 were sufficient for the libraries generated in this study, we ran 10 and 92 cycles for those two steps, respectively, to accommodate the other library.
txci-ATAC-seq using brain tissue samplesTagmentation plates were prepared by the combination of 1430 μl of TBS with 770 μl nuclei solution. The TBS recipe was described in “Blocking barcode-swapping”, but a different version of Digitonin (Bivision 2082–1) was used here. This solution was mixed briefly on ice; 20 μl of the mixture was placed into the 96-well iTSM plate (see “Sample multiplexing” for details). Tagmentation was performed at 37 °C for 60 min on a 300 r.c.f Eppendorf ThermoMixer with a lid heated to 65 °C. Following this incubation, plate temperature was brought down with a 5-min incubation on ice to stop the reaction. Tagmented nuclei were then pooled into a single 15-ml conical tube; 5 ml of tagmentation wash buffer (TMG) was prepared consisting of a final concentration of 10 mM Tris acetate pH 7.5 (Sigma 93,352 and Sigma A6283, respectively), 5 mM magnesium acetate (Sigma M5661), and 10% (v/v) glycerol (Sigma G5516), diluted in PCR grade water; 1 ml of TMG was added on top of the chilled tagmented nuclei. Nuclei were pelleted at 500 r.c.f for 10 min at 4 °C. Most of the supernatant was removed with care not to disturb the pellet. Then 500 μl of TMG was added to the pellet and the tube was once again spun at 500 r.c.f. for 5 min at 4 °C; 490 μl was removed leading to a low volume of concentrated nuclei. Loading buffer was prepared by combining two 5 × stock buffers and diluting them to 1 × in water (buffer 1 consisted of 50 mM Tris acetate pH 7.6, 25 mM magnesium acetate, and 50% (v/v) dimethyl formamide; buffer 2 consisted of 50% (v/v) glycerol, 100 mM NaCl, 50 mM Tris–HCl pH 7.5, 0.1 mM EDTA (Fisher Scientific AM9260G), and 1 mM DTT (VWR 97061–340)). The nuclear pellet was resuspended with an additional 30 μl of loading buffer. An aliquot of 2 μl of sample was diluted 20–50 × and quantified with Trypan Blue on a hemocytometer. Depending on the experiment, a 14 μl nuclei solution containing the desired amount of nuclei in the loading buffer was then combined with 1 μl of 75 μM short SBS oligo (Additional file 5: Table S8).
The 10× Chromium was then run with the custom nuclei solution as per the manufacturer’s instructions (10 × Document CG000209 Rev D) with the following adaptations. In step 2.4e, during GEM aspiration and transfer, 100 μl GEM volume was split into two tubes, with one receiving 10 μl and the other 90 μl (henceforth referred to as 10% and 90% samples). In step 2.5.a, GEM incubation cycles were limited to 6. For Pre-PCR wash elution (Step 3.2.j), the 10% sample was eluted in 8.5 μl whereas the 90% sample was eluted in 32.5 μl. For step 3.2.n, the 10% sample had 8 μl transferred to a new strip, while the 90% sample had 32 μl transferred to a new strip. At step 4.1.b, the sample Index PCR mix was split with 11.5 μl and 46 μl being combined with the 10% and 90% samples, respectively. For step 4.1.c, 1 μl and 2 μl of a 10 μM i7 TruSeq primer was used, respectively. For step 4.1.d, 8 and 7 PCR cycles were used, respectively. Libraries were then checked for quality and quantified by Qubit DNA HS assay (Agilent Q32851) and Tapestation D5000 (Agilent 5067–5589) following the manufacturer’s instructions. Libraries were then diluted and sequenced on a NextSeq 500 Mid flow cell or a NovaSeq 6000 S4 flow cell (Illumina Inc.).
txci-ATAC-seq using human lung, mouse lung, and mouse liver tissue samplesFlash-frozen nuclei isolated from human lung, mouse lung, and mouse liver tissues were thawed, washed, and filtered following the procedures described in “Coupling barcoded transposition with standard 10× protocol”, and then resuspended in 150 μl PBSB (PBS containing 0.04% BSA). To count nuclei, we added 1.5 μl of 300 μM DAPI to 150 μl of PBSB containing nuclei for a final concentration of 3 μM DAPI, and incubated the nuclei on ice for 5 min. Then, we loaded 10 μl on a Countess Cell Counting Chamber Slide to count the nuclei with Countess II Automated Cell Counter.
After counting nuclei, we diluted the samples with PBSB to a concentration of 2857 per μl and mixed 7 μl of nuclei solution (20,000 nuclei) with 13 μl of TBS (see “Blocking barcode-swapping” for details) for each well. This 20 μl nuclei/transposition mixture was then added to each well of the iTSM plate pre-loaded with 5 μl of barcoded Tn5 per well (see “Sample multiplexing” for details) to make a total volume of 25 μl reaction per well. For native samples shown in Fig. 4, 20,000 mouse nuclei were added to each well from rows A to F. But for rows G and H, 10,000 mouse nuclei were mixed with 10,000 human nuclei and then transferred to each well to estimate the empirical collision rate for each sample. For WT and CC16−/− lungs shown in Fig. 5, each well was loaded with 20,000 nuclei. The well IDs for each sample in each experiment are specified in Additional file 5: Table S6. After loading nuclei, the iTSM plate was sealed and briefly shaken at 1000 rpm for 1 min on a pre-chilled thermomixer. The barcoded transposition was performed at 37 °C for 1 h on a thermocycler with a heated lid at 47 °C. At the end of incubation, the plate was briefly centrifuged at 500 r.c.f for 10 s and then chilled on ice for 5 min to stop the transposition reaction. After quenching enzyme activity, the nuclei were pooled into a 12-tube strip and then transferred to a 15-ml conical tube preloaded with 400 μl tagmentation washing buffer (TMG, which contains 10 mM Tris acetate pH 7.8 (Boston BioProducts, Cat. BB-2412), 5 mM magnesium acetate (Sigma, Cat. 63,052-100ML), and 10% (v/v) glycerol (VWR, Cat. RC3290-32) diluted in nuclease-free water. Subsequently, we added 50 μl/well of TMG to the first row of the plate and pipetted them throughout the whole plate to wash out the residual nuclei remaining in the plate. After washing the last row of the plate, the TMG was transferred to the same conical tube that was used to collect the barcoded nuclei. The pooled nuclei were then centrifuged at 500 r.c.f for 10 min in a pre-chilled swinging-bucket centrifuge at 4 °C. After aspirating the supernatant, the nuclei were resuspended in 500 μl TMG and then transferred to a 1.5-ml LoBind tube through a 40 μm Flowmi Cell strainer. The nuclei suspension was then centrifuged at 500 r.c.f for 5 min in a pre-chilled fixed-angle centrifuge at 4 °C. After centrifugation, 400 μl of supernatant was removed. The 100 μl of supernatant left from the first aspiration was then carefully removed by pipetting with a P200 pipette tip to avoid disturbing the nuclei pellet. The nuclei were resuspended with 30 μl of loading buffer supplemented with 5 μM short SBS oligo (see Additional file 5: Table S8 for the oligo sequence). The loading buffer was prepared as described above in the “txci-ATAC-seq using brain tissue samples” section (final concentrations: 10% (v/v) glycerol, 20 mM NaCl, 10 mM Tris–HCl pH 7.5, 0.02 mM EDTA, 0.2 mM DTT, 10 mM Tris acetate pH 7.6, 5 mM magnesium acetate, and 10% (v/v) dimethyl formamide). After counting nuclei using a hemocytometer (see “Nuclei isolation of cell lines” for details), the volume of solution, containing the appropriate number of nuclei, was taken and diluted with the loading buffer supplemented with 5 μM short SBS oligo to make a total volume of 15 μl, which was subsequently used as an input into the 10× Chromium Controller. The GEM generation, Barcoding, and Post GEM Incubation Cleanup were performed following steps 2 and 3 described in the 10× Chromium Next GEM Single Cell ATAC protocol (v1.1, Document No. CG000209 Rev D) except for step 2.5, in which 8 cycles were used for GEM incubation. For Sample Index PCR (step 4.1), we substituted the Single Index N Set A (10× Genomics) with 25 μM i7 TruSeq primer containing an 8 bp custom barcode (Additional file 5: Table S7) and added 2.5 μl of customized i7 primer to each 10× library. The PCR was performed following the 10× protocol shown in Step 4.1 but with 5 total cycles. The Double Sided Size Selection was then conducted as described in Step 4.2 shown in the 10× protocol. Following the size selection, the txci-ATAC-seq libraries were quantified by Qubit 1X dsDNA HS Assay Kit (Invitrogen, Cat. Q33231) and run on a 6% PAGE gel to check the library quality. To balance nucleotide diversity of the fixed sequence at the Tn5MErev region in Read 2, we pooled these libraries with 5% of bulk ATAC libraries (from an unrelated experiment) and sequenced them on a NextSeq 550 Sequencer (Illumina Inc.) using a High Output Kit with following cycles: Read 1, 51 cycles; i7 index, 10 cycles; i5 index, 16 cycles; and Read 2, 78 cycles. The txci-ATAC-seq library only has 8 bp of i7 barcode, but we ran 10 cycles in i7 index to accommodate the barcode length of the bulk ATAC libraries. In cases where txci-ATAC-seq libraries are sequenced alone, we recommend either spiking in an appropriate amount of PhiX as per the manufacturer's instruction or performing dark cycles for the cycles from 9 to 27 in Read 2.
Phased-txci-ATAC-seqTo decouple sample processing from library preparation, the nuclei freshly isolated from WT and CC16−/− mouse lungs (see “Nuclei isolation of human lung, mouse lung, and mouse liver tissue” for details) were diluted in NFB (see Nuclei isolation of cell lines) at 3175 nuclei/μl. For each sample, 6.3 μl of diluted nuclei (20,000 nuclei) were added to each well of an 8-tube strip for a total of 8 wells. Then, the nuclei were flash-frozen in liquid nitrogen and transferred to − 80 °C for storage. The paired WT and CC16−/− samples were processed together but each pair was processed on a separate day. On the designated library preparation day, the nuclei flash-frozen in the tube strips were thawed on ice and 13.7 μl of transposition buffer (which contains 12.5 μl of 2X Illumina Tagment DNA Buffer, 0.7 μl of 10 × PBS, 0.25 μl of 1% Digitonin, 0.25 μl of 10% Tween-20) was added to each well containing nuclei followed by adding 5 μl of 500 nM pre-indexed Tn5 transposase per well. Then, the barcoded transposition reaction was performed on all six samples simultaneously by incubating at 37 °C for 60 min. Since each sample was distributed into 8 wells, a total of 48 Tn5 barcodes were used. As described above in the txci-ATAC-seq protocol, the barcoded nuclei were then cooled down on ice, pooled, washed, and loaded on the 10× Chromium Controller with either 50,000 or 100,000 nuclei in a lane. The well IDs of Tn5 barcodes assigned to each sample are shown in Additional file 5: Table S6, and the TruSeq i7 index used for each loading input is provided in Additional file 5: Table S7.
Data processing and analysisRaw code for the brain analysis is available at https://github.com/adeylab/txci-atac. Raw code for the cell line and lung/liver datasets is available at https://github.com/cusanovichlab/txciatac. The specific programs (and their version) used in data analyses were as follows: bcl2fastq (v2.19.0 for brain analysis and v2.20.0.422 for the other samples, Illumina Inc.), Trimmomatic (v0.36) [69], SAMtools and tabix (v1.7 for brain analysis and v1.10 for the other samples) [70, 71], BWA-MEM (v0.7.15-r1140) [72], Bowtie2 (v2.4.1) [73], Perl (v5.16.3) [74], MACS2 (v.2.2.7.1 for brain analysis and v2.1.2 for the other samples) [75], bedtools (v2.28.0) [76], Python (2.7.13 [77] and 3.6.7 [78]), PyPy (5.10.0), pybedtools (0.7.10) [79], R (v4.1.1) [80], cisTopic (v0.3.0) [15], Cicero (v1.3.4.10) [18], Signac (v1.0.0 for brain analysis and v1.5.0 for the other samples) [19], Presto (v1.0.0) [22], chromVAR (v1.16.0) [23], Seurat (v4.1.0) [29], corrplot (v0.92) [81], LIGER (v1.0.0) [82], uwot (v0.1.8) [83], Harmony (v1.0) [84], irlba (v2.3.5) [85], mclust (v5.4.9) [86], bap2 [40], edgeR (v3.40.0) [87], rGREAT (v2.0.2) [88], KEGGREST (v1.38.0) [89], BCFtools (v1.15.1) [90], GATK (4.3.0.0) [91], MOODS (1.9.4) [92], ggplot2 (v3.3.5) [93], and ComplexHeatmap (v2.5.5) [94].
Computational analysis of brain samplesPreprocessing for brain tissuesAfter sequencing, data was converted from bcl format to FastQ format using bcl2fastq with the following options “–with-failed-reads”, “–no-lane-splitting”, “–fastq-compression-level = 9”, and “–create-fastq-for-index-reads”. Data were then demultiplexed, aligned, and de-duplicated using the in-house scitools pipeline [95]. Briefly, FastQ reads were assigned to their expected primer index sequence allowing for sequencing error (Hamming distance ≤ 2) and indexes were concatenated to form a “cellID”. Reads that could be assigned unambiguously to a cellID were then aligned to reference genomes. Paired reads were first aligned to a concatenated hybrid genome of hg38 and GRCm38 (“mm10”, Genome Reference Consortium Mouse Build 38 (GCA_000001635.2)) with BWA-MEM. Reads were then de-duplicated to remove PCR and optical duplicates by a Perl script aware of cellID, chromosome number, read start coordinate, read end coordinate, and strand. From there, the putative single-cells were distinguished from debris and error-generated cellIDs by both unique reads and percentage of unique reads.
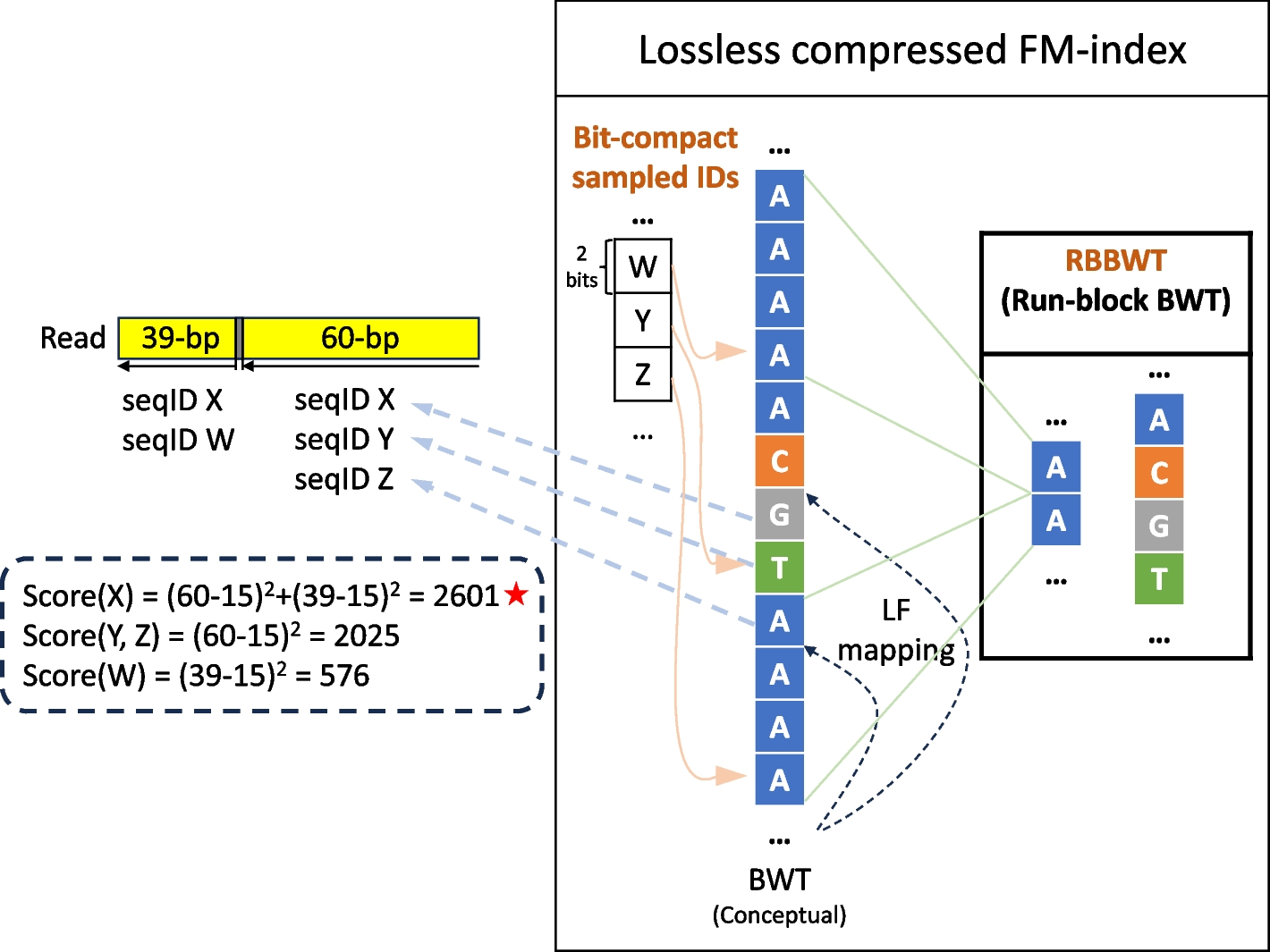
Barnyard analysis for brain tissuesWith single-cell libraries distinguished, we next quantified contamination between nuclei during library generation. We calculated the read count of unique reads per cellID aligning to either human reference or mouse reference chromosomes (Additional file 1: Fig. S3b). CellIDs with ≥ 90% of reads aligning to a single reference genome were considered bona fide single cells. Those not passing this filter were considered collisions. The collision rate was estimated using the equation in [14] to account for cryptic collisions (two cells from the same species). Bona fide single-cell cell IDs were then split from the original FastQ files to be aligned to the proper hg38 or mm10 genomes with BWA-MEM as described above. Human and mouse assigned cellIDs were then processed in parallel for the rest of the analysis. After alignment, reads were again de-duplicated to obtain proper estimates of library complexity.
Dimensionality reduction for brain tissuesPseudo-bulked data (agnostic of cellID) was then used to call read pile-ups or “peaks” via MACS2 with the option “–keep-dup all”. Narrowpeak bed files were then merged by overlap and extended to a minimum of 500 bp for a total of 350,261 peaks for human and 292,304 peaks for mouse. A scitools Perl script was then used to generate a sparse matrix of peaks × cellID to count the occurrence of reads within peak regions per cell. FRiP was calculated as the number of unique, usable reads per cell that are present within the peaks out of the total number of unique, usable reads for that cell for each peak bed file. Tabix-formatted files were generated using samtools and tabix. The count matrix and tabix files were then input into a SeuratObject for Signac processing. We performed LDA-based dimensionality reduction via cisTopic with 28 and 30 topics for human and mouse cells, respectively. The number of topics was selected after generating 25 separate models per species with topic counts of 5,10,20–30,40,50,55,60–70 and selecting the topic count using selectModel based on the second derivative of model perplexity. Cell clustering was performed with Signac “FindNeighbors” and “FindClusters” functions on the topic weight × cellID data frame. For the “FindClusters” function call, resolution was set to 0.01 and 0.02 for human and mouse samples, respectively. The respective topic weight × cellID was then projected into two-dimensional space via UMAP by the function “umap” in the uwot package. To check for putative doublets within species, we then ran scrublet analysis and removed the scrublet-identified doubles from further analysis [
留言 (0)