
記住我
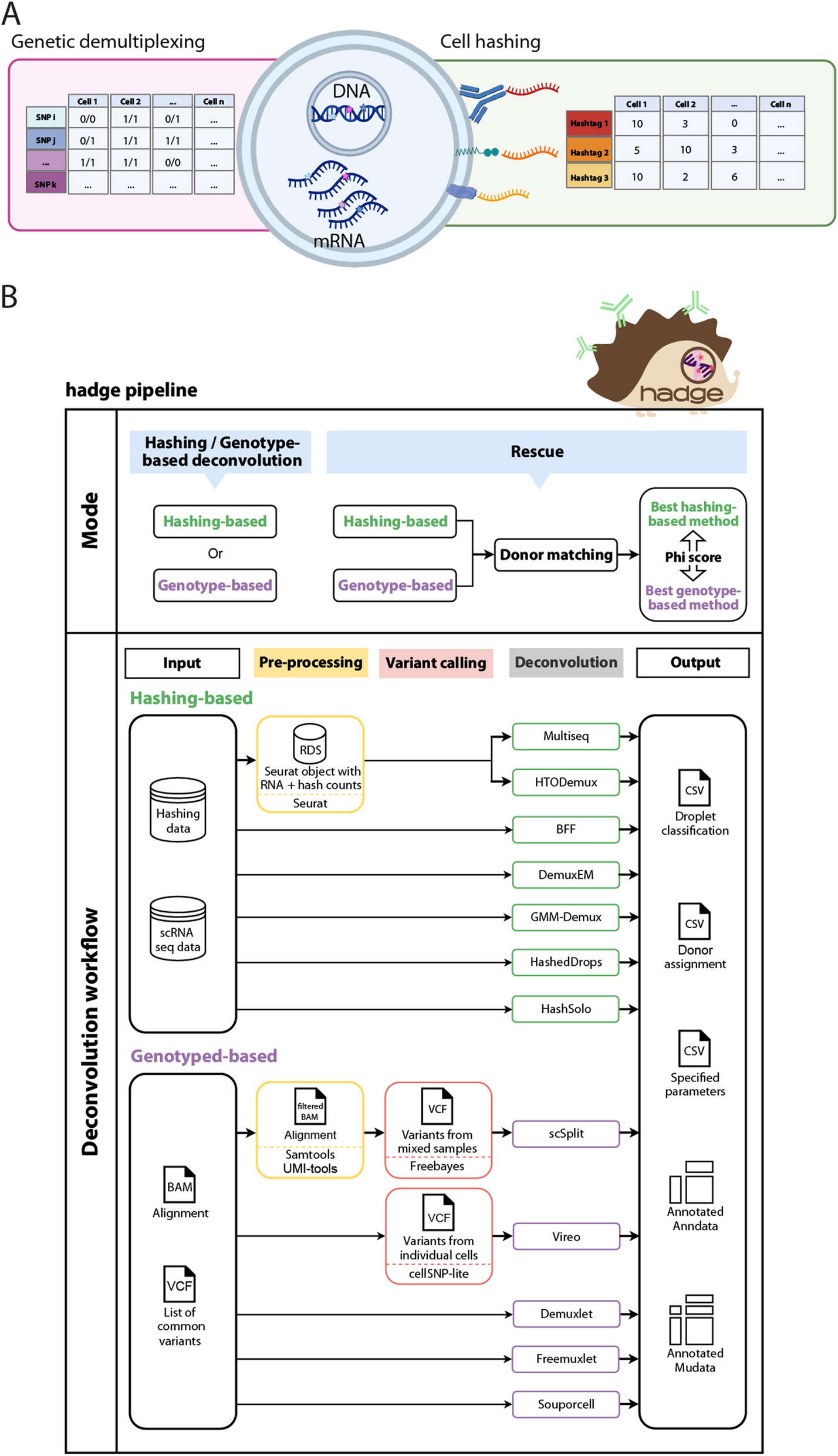






We sequenced whole blood from 7179 individuals to an average coverage of 20.6 × per sample (median 19.5 × , ranging from 10 to 108 ×) on 8906 promethION flowcells from ONT. The same set of samples was used to investigate the correlation between CpG methylation, gene expression, and sequence variants (Stefansson OA, Sigurpalsdottir BD, Rognvaldsson S, Halldorsson GH, Juliusson K, Sveinbjornsson G et al: The correlation between CpG methylation and gene expession is driven by sequenced variance [Unpublished]). CpG methylation detection was performed using Nanopolish [18], which groups CpGs located within 10 bp of each other, referred to here as CpG units. Nanopolish takes reference-aligned reads as input and outputs for each read the strand of the reference that was sequenced and for each CpG unit a log-likelihood ratio (LLR) of it being methylated or not. The LLR is then translated to binary values indicating the methylation status of sequenced CpGs. We classified CpG units as “unreliable” when the LLR did not meet our criteria for predicting a CpG unit as either methylated or unmethylated. Here we restrict our analysis to 22,178,458 autosomal CpG units, containing the 27,651,488 CpG sites, detected by Nanopolish in our cohort.
CpG methylation measurements are comparable between nanopore sequencing and oxBSAs a baseline for 5-mCpG rates, we used 132 DNA samples sequenced by oxBS in our previous study [19] to an average coverage of 25 × (median 24.7 × , range 15–41 ×). For each CpG unit, we calculated the average 5-mCpG rate over all individuals in each dataset separately (7179 in nanopore and 132 in oxBS) and assessed the performance of Nanopolish by evaluating the Pearson correlation coefficient between average 5-mCpG rates from oxBS data and the corresponding average 5-mCpG rates predicted from Nanopolish, across all CpGs. We refer to this correlation as per the CpG average Pearson correlation (APC).
Our analysis revealed a high APC between the 5-mCpG rates in the two datasets (r = 0.9594; 95%CI = 0.9594–0.9595) and the mean absolute difference (MAD) in the 5-mCpG predictions per CpG was 0.0471 (95%CI = 0.0471–0.0472) per CpG.
We measured the overall methylation levels per individual by counting the number of times a methylated status was assigned to a CpG detected in sequences obtained from a given DNA sample to then divide this number by the total number of times we were able to assign a methylation status (unmethylated/methylated) to CpG sites in sequences obtained from that same DNA sample. We find that the overall methylation levels were on average lower in nanopore-sequenced samples than in those sequenced by oxBS (\(\overline\) Nanopolish = 0.767; 95%CI = 0.763–0.770 versus \(\overline\) ox-BS = 0.773; 95%CI = 0.770–0.775, Wilcoxon rank sum test p = 2 × 10−6) (Fig. 1A). As short-read sequences can be more difficult than long-read sequences to align to the reference genome, it is possible that these subtle differences in overall methylation levels between nanopore and oxBS sequenced samples are due to challenges in accurately aligning short-read sequences to the reference genome, which may affect the detectability and thereby measurement of certain CpGs by each of the two methods.
Fig. 1
Nanopore sequencing and oxBS performance in the same DNA samples. The consistency in 5-mCpG rates measured by nanopore sequencing and oxBS in DNA samples isolated from the same 132 individuals was estimated by the following: A The overall measurement of 5-mCpG rates in each of the 132 DNA samples measured by ONT (red) and oxBS (green), Y-axis is limited to (0.7,0.8). The center line (solid black) shown in each box represents the median; the box limits represent the upper and lower quartiles; the whiskers represent 1.5 × interquartile range. B The Pearson r correlation coefficient, y-axis, and C mean of the absolute differences in 5-mCpG rates of each CpG, y-axis, with respect to nanopore sequencing coverage in each sample on the x-axis. Panels D, E, and F analyze sites that have > 25 × coverage in oxBS. D CpG coverage underlying the 5-mCpG rates, i.e., the number of sequences that were used to compute the 5-mCpG rate for a given CpG, in nanopore sequenced samples, x-axis, influences the consistency (Pearson r), y-axis, with 5-mCpG rates measured with high coverage by oxBS. The y-axis is limited to (0.5, 1) E CpG rates in nanopore (y-axis) and oxBS (x-axis, binned). The mean is represented with red (ONT) and green (oxBS). F Number (y-axis, unit = million CpGs) of correctly classified (blue) by nanopore sequencing in a sample-to-sample comparison. Incorrectly classified CpGs are colored according to the absolute difference in 5-mCpG rates (color legend)
Coverage affects the consistency of CpG methylation measurements in nanopore dataNext, we performed a matched sample-to-sample analysis based on the 132 individuals for which DNA samples were sequenced using both nanopore and oxBS and evaluated the Pearson correlation and MAD. We found that the correlation varied from 0.71 to 0.94 and the MAD from 0.076 to 0.14. The correlation was notably higher and MAD lower for high-coverage samples, indicating that sequencing coverage of approximately 12 × or more per sample is advisable for accurate methylation detection and sequencing at 20 × or greater yields even more accurate results (Fig. 1B, C). We then calculated the Pearson correlation for each sample, for all CpG sites with high sequence coverage (greater than 25 ×) supporting a minimum nanopore sequencing depth of a CpG unit as 20 × for obtaining a highly reliable measurement of its 5-mCpG rate (Fig. 1D).
The accuracy of the measured 5-mCpG rate is not affected by different versions of the basecalling algorithm nor changes in the error rate within the range of the reported error rate of nanopore sequencing (Additional file 1: Fig. S1, S2, Additional file 2: Tab. S1).
Nanopore data is more consistent in unmethylated and methylated CpG unitsTo capture the distribution of the methylation predictions, we divided the paired data into four categories based on methylation rates in oxBS: unmethylated (0–0.15), low-methylated (0.15–0.5), intermethylated (0.5–0.85), and methylated (0.85–1). We found that Nanopolish predictions were consistent with oxBS measurements (Fig. 1E, Additional file 2: Tab. S2). We limit our analysis to CpGs with at least 25 × coverage in oxBS and consider a prediction made by Nanopolish to be correct if the prediction falls into the same of the four categories as the oxBS. We see that the highest fraction of correctly predicted CpG units was for unmethylated CpGs (86%), followed by methylated (77%), intermethylated (56%), and low methylated (52%) (Fig. 1F). The lower fraction of correct predictions among low- and intermethylated CpGs may be due to a higher propensity of the methylation in these categories to fall close to the boundaries of these classes and the higher variance of 5-mCpG rates expected for these categories, i.e., as the distribution of predicted methylation states is far more uniform for unmethylated and methylated CpGs in comparison to low- and intermethylated CpGs.
Nanopolish methylation prediction quality is affected by CpG unit sequence contextAlthough the results of nanopore and oxBS are highly correlated, there are regions in the genome where methylation detection is more difficult due to limitations in the sequencing method, mapping, or methylation detection algorithms. To evaluate the performance of the methylation detection in nanopore-sequenced DNA, we compared the APC of CpG units located inside and outside of regions where we expected difficulties in methylation predictions.
Nanopolish predicts methylation status from reads aligned to the human reference genome (GRCh38) [20], which instigates a risk of error when predicting the methylation status of CpG units located close to sequence variants. We found that CpG units located within 5 bp of a sequence variant had a lower APC (r = 0.9219; 95%CI = 0.9218–0.9221) than other CpG units (r = 0.96560, 95%CI = 0.96557–0.96563) (Fig. 2A). This likely is because Nanopolish assumes that aligned sequences are the same as those found in the reference genome. As a result, the electric signal, produced by a short stretch of a DNA sequence containing an unmethylated CpG, but including the alternative allele of a nearby sequence variant, may be similar to the signal produced in the presence of reference allele and a 5-mCpG.
Fig. 2
The quality of 5-mCpG rate measurements by DNA sequence attributes. A APC estimates (x-axis), for CpG sites located outside (pink) and inside (gray) of DNA sequence attributes, y-axis, and the APC estimates based on all CpGs (vertical black line). B The number of CpG units (red) and sites (green), x-axis, found inside of each attribute, y-axis. C The proportion of high-quality (dark blue) and non-high-quality (light blue) CpG units among singletons and non-singletons, x-axis. D The proportion of high-quality and non-high-quality CpG units within each methylation state category, x-axis, defined by binning the mean of 5-mCpG rates measured by Nanopolish
We define dark regions [21] as sequences where ≥ 90% of the reads have mapping quality < 10, coverage < 5 × on average, and base quality < 20 in DNA samples analyzed on Illumina sequencers. Dark regions often contain large contiguous tandem repeats (e.g., centromeres and telomeres) or larger specific DNA regions that have been duplicated [21], causing the mapping to be unreliable. The APC for CpG units within dark regions was lower (r = 0.698; 95%CI = 0.697–0.699) than other CpG units (r = 0.96320; 95%CI = 0.96318–0.96323) (Fig. 2A). This poor correlation in these regions is likely largely attributable to the difficulty in measuring the methylation rates of CpG units that reside within these regions using oxBS, as mapping is generally more reliable in long reads. When the mapping is incorrect, the 5-mCpG rates are predicted from the wrong reference sequence leading to incorrect predictions.
We defined abnormal sequencing coverage, as greater than 1.5 times the average coverage or less than 0.5 times the average coverage, and show that these CpG units tend to have lower APC (r = 0.7223; 95%CI = 0.7218–0.7225) than other (r = 0.9646; 95%CI = 0.9645–0.9646) (Fig. 2A, Additional file 1: Fig. S3A, B), likely because of duplicated regions (such as tandem repeats) or mapping errors.
As DNA methylation is in most cases symmetric, meaning that cytosines in CpGs are methylated on both DNA strands [22], and hemi-methylated CpGs, where one strand is methylated while the other is unmethylated, are rare in the genome [23] we investigated strand bias, defined as the difference in the absolute value of the estimated 5-mCpG rates of the forward and reverse strands. We found that the magnitude of strand bias is low in oxBS data, with mean strand bias of 0.026 (quartiles = 0.0055, 0.028) (Additional file 1: Fig. S4). Strand bias was much higher in ONT Nanopolish data (mean = 0.095, quartiles = 0.017, 0.11, Wilcoxon rank sum test, p < 2 × 10–16), suggesting that strand bias may indicate problematic regions with unreliable methylation predictions. As there is far less strand bias in oxBS, we assume that these are unreliable in nanopore because of methylation detection artifacts. Notably, CpG units with strand bias greater than 0.2 (Additional file 1: Fig. S3C, D) had lower APC (r = 0.8279; 95%CI = 0.8275–0.8282) than other CpG units (r = 0.97411; 95%CI = 0.97409–0.97414) (Fig. 2A).
To further investigate the quality of methylation predictions in our nanopore-sequenced DNA samples, we examined CpG units with a low fraction of reliable reads (FRR), defined as the fraction of reads where the absolute log-likelihood ratio exceeds the defined cut-off. CpG units with FRR below 0.5 had a lower APC (r = 0.819; 95%CI = 0.816–0.820) than other CpG units (r = 0.96868; 95%CI = 0.96866–0.96871) (Fig. 2A, Additional file 1: Fig. S3E, F).
Consequently, we define problematic CpG units as being within dark regions, within 5-bp distance from a SNP, having coverage ≤ 0.5 times the average coverage or ≥ 1.5 times, strand bias ≥ 0.2, and FRR ≤ 0.5. These CpGs were removed from our analysis, resulting in a set of 15,644,462 (70.5%) high-quality CpG units (hq-CpGs), containing 19,685,181 (71.2%) CpG sites in the reference genomes (hg38). The APC for the hq-CpGs was 0.98582 (95%CI = 0.98581–0.98584) compared to 0.9594 (95%CI = 0.9594–0.9595) for the complete set and we found lowered MAD (Additional file 2: Tab. S4), between the predictions of hq-CpGs, indicating improved accuracy. The overall 5-mCpG rates were higher among hq-CpGs than among non-hq-CpGs (Additional file 2: Tab. S4). Furthermore, correlation coefficients were consistently higher for methylation measurements of hq-CpGs in the same DNA samples analyzed by Nanopolish and oxBS (Additional file 1: Fig. S5).
The highest number of CpG units were excluded from the set of hq-CpGs due to their proximity to a sequence variant, followed by high strand bias and low FRR (Fig. 2B). A similar proportion of singletons, defined as CpG units containing one CpG and non-singletons, were excluded from the set of high-quality CpG units or 30% and 26%, respectively (Fig. 2C). Notably, a higher proportion of low- (50%) and intermethylated (51%) CpG units were excluded from the set of hq-CpGs than unmethylated (17%) and methylated (19%) (Fig. 2D). Most CpGs (57.7%) are removed from the low- and intermethylated groups because of high strand bias. The hq-CpGs were evenly distributed across the number of CpGs within a unit and chromosomes (Additional file 1: Fig. S6).
Guppy outperforms Nanopolish per CpG-site in comparison to oxidative bisulfite sequencing dataThe recent improvements in algorithms for ONT basecalling have greatly enhanced the accuracy and efficiency of the basecalling. Specifically, a recent version of the basecaller, referred to as Guppy, can now perform CpG methylation detection at the basecalling stage by adding 5-mCpG to the DNA alphabet. We predicted the 5-mCpG rates of CpGs in 304 samples with Guppy (version 6.2.1) and calculated the average rates for each CpG over all individuals. Since Guppy does not group the CpGs like Nanopolish, we assumed the same rates for each CpG within a CpG unit in Nanopolish and compared the rates at the CpG site level.
The methylation calls from Guppy and Nanopolish were highly correlated, with an APC of 0.96558 (95%CI = 0.96555–0.96561) for the full set of CpGs. Guppy had higher APC with oxBS data (r = 0.97256; 95%CI = 0.97255–0.97259) than Nanopolish (r = 0.9594; 95%CI = 0.9594–0.9595). The overall 5-mCpG rates were lower for Guppy (\( }_\) = 0.7634; 95%CI = 0.7633, 0.7635) than oxBS (\( }_\) = 0.7756; 95%CI = 0.7755–0.7757; p < 2 × 10−16 Wilcoxon rank sum test). Interestingly, Guppy had lower mean strand bias (\(\overline\) = 0.064; quartiles = 0.016, 0.077) than Nanopolish (\(\overline\) = 0.095; quartiles = 0.017, 0.11; Wilcoxon rank sum test, p < 2 × 10−16), although the strand bias was still higher than in oxBS (\(\overline\) = 0.026; quartiles = 0.0055, 0.028; Wilcoxon rank sum test, p < 2 × 10−16).
By applying the same quality filters as specified for Nanopolish, we identified 22,256,402 (80.5%) hq-CpGs. This represents a 9.3% increase compared to the set of hq-CpGs identified using Nanopolish data. This difference is mainly explained by two factors: first this version of Guppy does not report number of reads where the probability of the call was below the threshold and therefore the FRR filter is not applicable, and second, Guppy has a lower strand bias, leading to more hq-CpGs being retained. The APC between the set of Guppy hq-CpGs and oxBS data was 0.98691 (95%CI = 0.98690–0.98693), compared to 0.97257 (95%CI = 0.97255–0.97259) for the complete set of CpGs (Additional file 2: Tab. S4, S5).
Moreover, we found high correlations between the matched samples for the methylation predictions generated by Nanopolish and Guppy, and Guppy and oxBS (Additional file 1: Fig. S7, S8). The sample-to-sample correlation between the 5-mCpG predictions from Guppy and the corresponding oxBS rates ranged from 0.62 to 0.90 for the full set of CpGs and increased to 0.65–0.91 for the set of hq-CpGs. For most samples, the correlation was higher between Guppy and oxBS than Nanopolish and oxBS (Additional file 1: Fig. S8A). The strand bias and MAD were also lower for Guppy on average per sample (Additional file 1: Fig. S8B, C).
The latest chemistry attains higher accuracy and improved methylation predictionsONT has made several improvements to its protein nanopore and motor protein, releasing nine versions of the system to date [15]. Our dataset consists mainly of samples sequenced on R9.4 flowcells (released in October 2016) and in addition we sequenced 22 samples on 28 R10.4 flowcells (received as early access) to an average depth of 9.64 × . R10.4 flowcells have two sensing regions designed to provide higher consensus accuracy with homopolymers than the R.9.4 flowcells [15].
The R10.4 flowcells have an average sequencing error rate [24] of 3.9%, significantly lower than the 8% average sequencing error rate for the R9.4 chemistry. Although there is high APC between 5-mCpG rates measured in all CpGs with the two types of flowcells (r = 0.98190, 95%CI = 0.98188–0.98191), the APC between 5-mCpG rates predicted from nanopore data in all CpGs and oxBS data is higher for R10.4 flowcells (rR10.4 = 0.97845; 95%CI = 0.97843–0.97846, rR9.4 = 0.97256; 95%CI = 0.97255–0.97259, Additional file 2: Tab. S5). R10.4 flowcells also show lower average strand bias of 0.047 (quartiles = 0.0097, 0.053) over all CpGs in comparison to R9.4 (\(\overline\) = 0.064; quartiles = 0.016, 0.077) (Wilcoxon rank sum test, p < 2e − 16) indicating improved accuracy (Additional file 2: Tab. S4). Nonetheless, the strand bias observed in R10.4 flowcells is still higher than that observed in oxBS data. Guppy R10.4 further showed lower MAD between methylation predictions with oxBS than Guppy R9.4 (Additional file 2: Tab. S4).
Applying the same quality filters as before to the R10.4 dataset, we obtain 22,893,522 (82.8%) high-quality autosomal CpGs, with APC of 0.99067 with oxBS (95%CI = 0.99066–0.99068, Additional file 2: Tab. S4, S5). This is a 2.3% increase in the number of hq-CpGs compared to Guppy data sequenced on R9.4 flowcells and an increase in APC.
CpG methylation measurements are comparable between SMRT-sequencing, nanopore sequencing, and oxBSWe SMRT-sequenced whole-blood samples from 50 individuals on 170 flowcells to average sequencing coverage of 28.5 × per sample (range 13.6–41.7 ×), which was higher than for nanopore R9.4 and R10.4 sequencing methods (Additional file 1: Fig. S9A). The average N50, defined as the length of the sequence read at 50th percentile of the total sequence read length, was similar for SMRT and nanopore R9.4 and R10.4 sequencing methods (Additional file 1: Fig. S9B), but the average sequencing error rate was lower for SMRT-sequencing than either of the two nanopore sequencing methods, or 1.12% (range 1.02–1.31%, Additional file 1: Fig. S9C). We used primrose for methylation detection of SMRT-sequenced samples. The methylation detection step is performed by the sequencer after basecalling. The APC between predicted 5-mCpG rates across all 27,527,663 autosomal CpGs from SMRT-sequencing and oxBS data was 0.97010 (95%CI = 0.97008–0.97013) and the MAD was 0.05691 (95%CI = 0.05689–0.05694). After applying our quality filters, we identify 22,554,423 (81.9%) hq-CpGs of the autosomal CpGs with APC of 0.979956 (95%CI = 0.97955–0.97579) (Additional file 2: Tab. S4, S5). In summary, the number of hq-CpGs is similar to R10.4, with fewer filters applied and the APC with oxBS is lower than for either the R10.4 or R9.4 nanopore sequencing methods.
Comparison of CpG methylation predictions from nanopore sequencing and SMRT sequencingIn this comparison, we used the 50 SMRT-sequenced samples (average coverage 26.7 ×) and 50 nanopore-sequenced samples analyzed using Nanopolish (average coverage 23.4 ×), 50 nanopore-sequenced samples on R9.4 flowcells and methylation called using Guppy (average coverage 22.0 ×), all of the 22 nanopore sequenced samples on R10.4 flowcells analyzed using Guppy (average coverage 9.64 ×), and 50 DNA samples sequenced by oxBS (average coverage 25.0 ×) (Additional file 2: Tab. S3).
We averaged the 5-mCpG rates over all samples and compared the APC correlation coefficient between all five methods (SMRT, R9.4-Guppy, R10.4-Guppy, R9.4-Nanopolish, and oxBS) and the absolute difference between 5-mCpG rates and oxBS (Table 1 (A)). 26,345,529 autosomal CpGs were detected in all datasets and used for the comparison. The highest APC was seen for Guppy applied to R10.4 and Guppy applied to R9.4. In comparison to oxBS, the highest APC and the lowest MAD were also seen for Guppy applied to R10.4 (Table 1 (A)). We note, however, that some of the differences in APC and MAD observed between methods may be due to differences in age, gender, or smoking status of the samples (Additional file 2: Tab. S3).
Table 1 Comparison between methods. (A) APC comparisons are shown below the main diagonal whereas MAD comparisons are shown above the main diagonal. (B) APC comparisons between methods based on all CpGs, or after restricting to those located close to sequence variants or those located within dark regions as indicatedSequence variants around or within CpG introduce mapping bias in oxBS, leading to inaccurate methylation measurements and low APC. Therefore, it is less important to filter on CpGs located close to sequence variants for Guppy and PacBio, because low APC is most likely caused by inaccurate measurements in oxBS (Table 1 (B)) and higher APC is seen between Guppy R9.4, Guppy R10.4, and PacBio. We note however that likely all methods benefit from filtering on CpGs where sequence variants are located close to the CpG as all long-read sequencing technologies use the local sequence context and comparison to the reference genome for predicting the methylation status of CpGs. Not filtering on sequence variants would increase the number of hq-CpGs to about 25.1 M (90.7%) and 25.8 M (93.7%) hq-CpG for Guppy and PacBio with APC 0.98545 (95%CI = 0.98544–0.98546) and 0.97561 (95%CI = 0.97559–0.97563), respectively.
Distribution of the 5-mCpG rates5-mCpG rates computed across all individuals in the five subsets of 50 individuals yielded the expected bimodal distribution for all methods (Fig. 3A, B). However, we noticed a shift in the distribution of methylated and unmethylated CpG sites away from 1 and 0, for both Guppy applied to R9.4 flowcells and PacBio. PacBio never reaches 0 or 1, while Guppy R9.4 rarely does. Guppy applied to R10.4 flowcells more closely follows the methylation distribution patterns seen in oxBS sequenced samples than R9.4. Additionally, all methods showed a higher number of intermethylated CpGs than oxBS. The distribution for hq-CpGs is similar with a slightly lower fraction of low- and intermethylated CpGs for Guppy R10.4 and PacBio (Additional file 1: Fig. S10). Less CpGs are removed due to strand bias and abnormal coverage for Guppy R10.4 and R9.4 compared to Nanopolish. Interestingly, more are removed because of abnormal coverage for PacBio (Additional file 1: Fig. S11).
Fig. 3
Comparison of CpG methylation detection by method. CpG methylation rates (ranging from 0 to 1) averaged across individuals yield the expected bimodal distribution seen in oxBS data for A oxBS, Guppy R9.4, and R10.4 and B oxBS, PacBio, and Nanopore. The units on y-axis are millions (M). C CpG methylation rates averaged in 50-bp bins relative to transcription start sites (TSSs) of genes expressed in whole blood. D Number of CpGs called by each method. For Nanopolish, we count all CpGs within a CpG unit. Note that the y-axis is limited from 24.5 to 27.7 M (millions). The center line (solid black) shown in each box represents the median; the box limits represent the upper and lower quartile; the whiskers represent the 1.5 × interquartile range
5-mCpG rates of functional regionsTo investigate the influence of biological context on the accuracy of the methylation predictions, we calculated the average 5-mCpG rates in 50-bp intervals relative to the start of the transcription start sites (TSSs) of genes expressed in whole blood. All methylation detection methods closely replicate the methylation patterns observed in oxBS-sequenced samples, which demonstrated a lack of methylation within TSSs (Fig. 3C). Notably, PacBio and Guppy R9.4 exhibited higher rates of CpG methylation at TSSs and lower rates away from TSSs, which is consistent with the slight shift in the methylation distributions observed for these two methods (Fig. 3A, B). Guppy applied to R10.4 flowcells, however, more closely follows the TSS methylation levels seen in oxBS (Fig. 3C). Further, Nanopolish has the lowest MAD with oxBS in unmethylated CpG units (Supplementary Fig. S12).
Long-read sequencing calls more CpGs than oxBSLong-read sequencing provides a significant advantage in the number of CpG sites captured over previous methods. To quantify this, we compared the number of CpGs called per sample by each long-read-based method and found that they all called similar number of CpGs. Restricting our analysis to autosomes, all three methylation detection tools for long-reads called similar number of CpGs (Guppy R9.4 = 27,467,383, Guppy R10.4 = 27,369,144, PacBio = 26,739,539 CpGs, and Nanopolish = 26,487,587, within 22,058,476 CpG units). As expected, oxBS called the fewest CpGs, with an average of 26,002,520 CpGs (Fig. 3D). The varying number of CpGs detected in long-read sequencing is most likely because of the criteria set by each method to make confident methylation predictions.
留言 (0)