
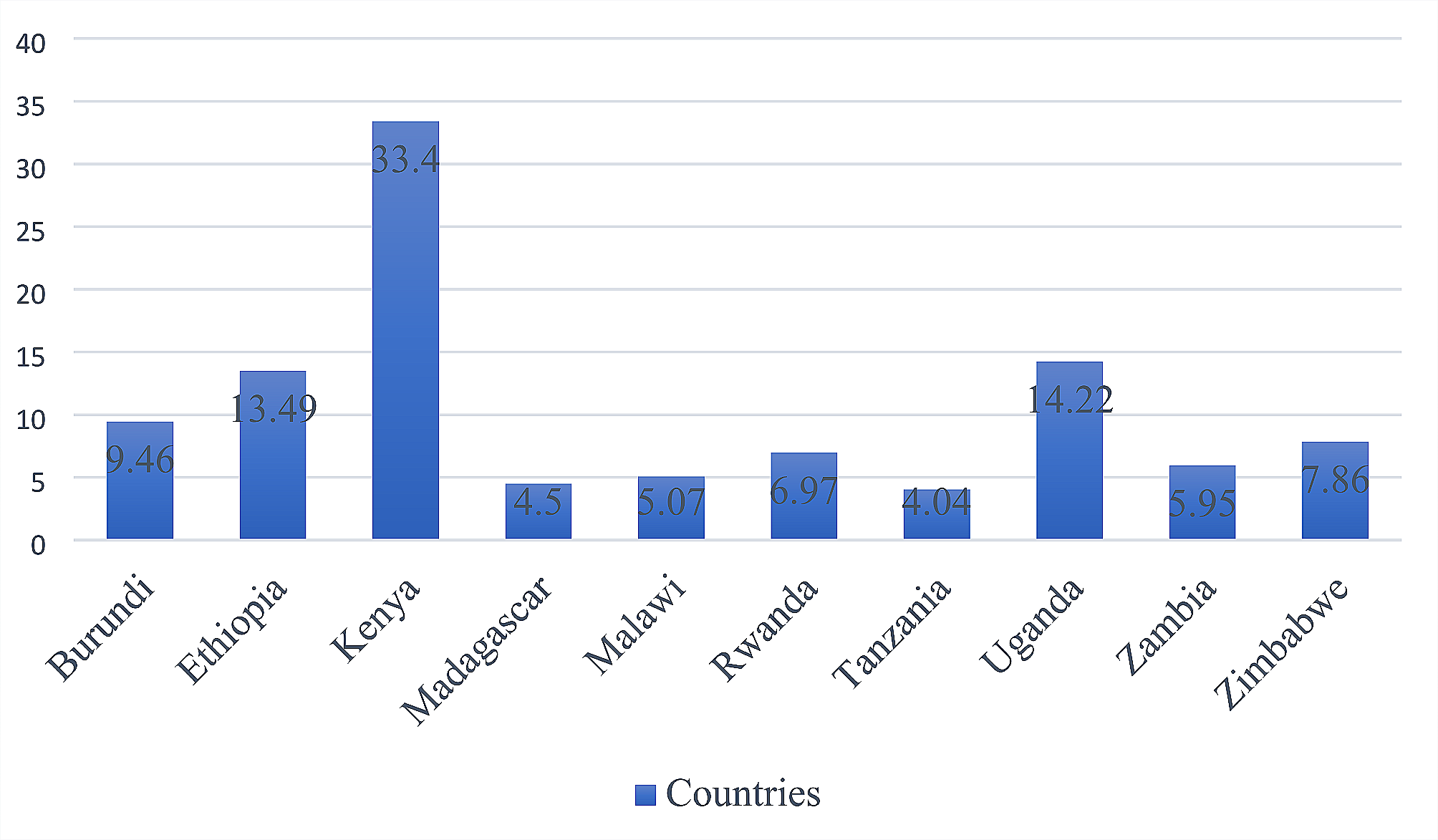
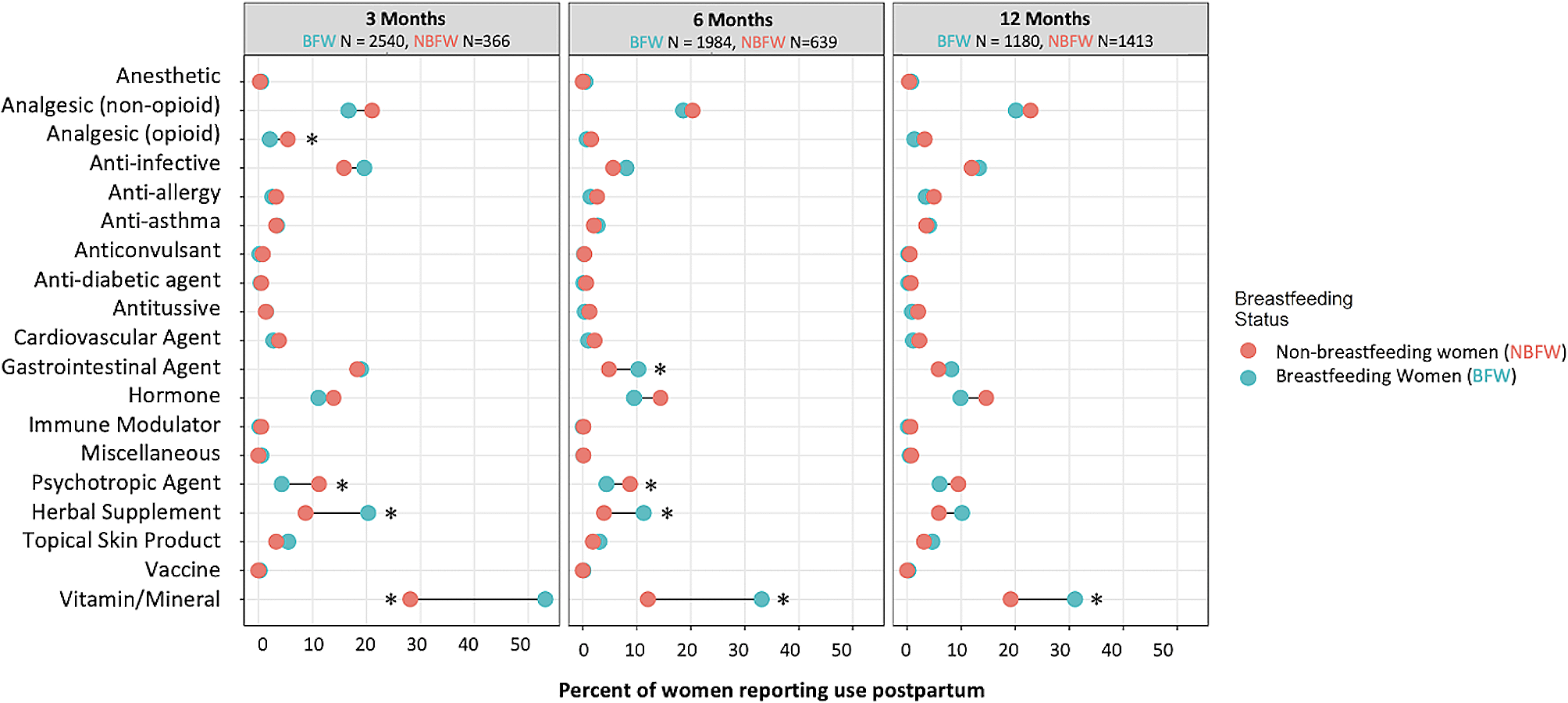
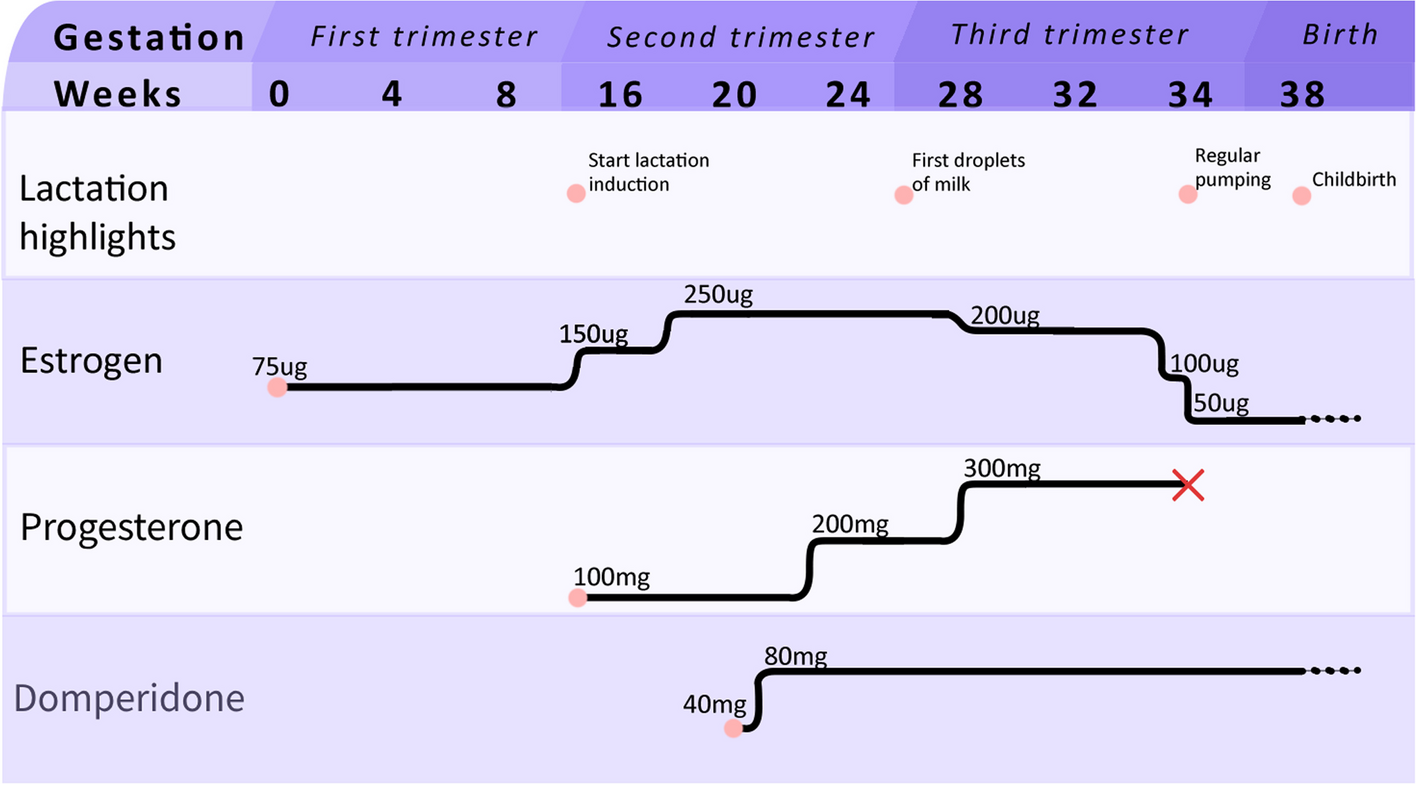
記住我

Mothers’ sociodemographic and clinical data were collected by investigators using the questionnaire developed by the researchers. The mothers’ sociodemographic and clinical data included (1) sociodemographic data, (2) gestational age, (3) pregnancy and birth history, (4) mode of birth, (5) medical history, and (6) neonatal situation.
BMSThe BMS was developed by Israeli academic Miri Kestler-Peleg and his team members [20] in 2015. The original English-language BMS initially contained 24 items, but after principal axis factor analysis, the developers removed item 1, "Breastfeeding is more convenient because there is no need to wash and sterilize bottles, and breastfeeding can be done anywhere, anytime". Therefore, the final BMS in English consists of 23 items covering 5 subscales: (1) enjoyment and bonding, (2) maternal self-perception, (3) significant others' pressure, (4) baby's health, and (5) instrumental needs. Each item is scored on a 4-point Likert scale ranging from 1 meaning “strongly disagree” to 4 meaning “strongly agree”. Respondents are asked to rate extent to which each item matched the reason they chose to breastfeed. The scale has no total score. As the subscale score increases, the motivation that represents that subscale also increases [23]. The Cronbach's α for each subscale of the BMS in English ranged from 0.62 ~ 0.93. The Cohen’s kappa consistency coefficients of the scale ranged from 87.5% to 100 percent.
Participants, site and designWe conducted a cross-sectional study in Shanghai First Maternity and Infant Hospital, which is a high-level national maternity hospital in China. The hospital, affectionately known as the "Great Cradle of Shanghai" by Shanghai residents, handles approximately 30,000 deliveries a year. The instruments were applied during the mother’s hospital stay after childbirth at the second week postnatal follow-up.
All participants involved in the study provided their informed consent before completing the surveys, and they came from all over China. Data were collected from 1 December 2021 to 1 July 2022. According to the statistics department of the hospital, there are approximately 8 to10 new mothers in a maternity ward per day. The study sample consisted of mothers who were: (1) over 18 years old, (2) delivered a single-born full-term baby with a neonatal Apgar score ≥ 8, (3) had no breast diseases, (4) were able to stay in the same room with the baby after birth, (5) were able to understand the study and the instruments involved, (8) had a short hospital stay of ≤ 4 days, and (9) were informed about the purpose of the study and its circumstances in advance and provided informed consent to participate. The exclusion criteria were as follows, mothers who had cognitive impairment or mental illness who could not establish meaningful communication, or mothers who were prohibited from breastfeeding due to medical factors or diseases such as taking drugs that affect breastmilk within two weeks after delivery. The sample size was determined based on the rule that the sample should contain 5 to10 mothers for each item. Assuming a 10% rate of invalid questionnaires, 237 mothers were recruited in this study, and 206 mothers completed the questionnaire for data collection. Mothers excluded from the study included those who rejected breastfeeding and could not be reached because they gave wrong or unused phone numbers or refused to fill out the questionnaires again.
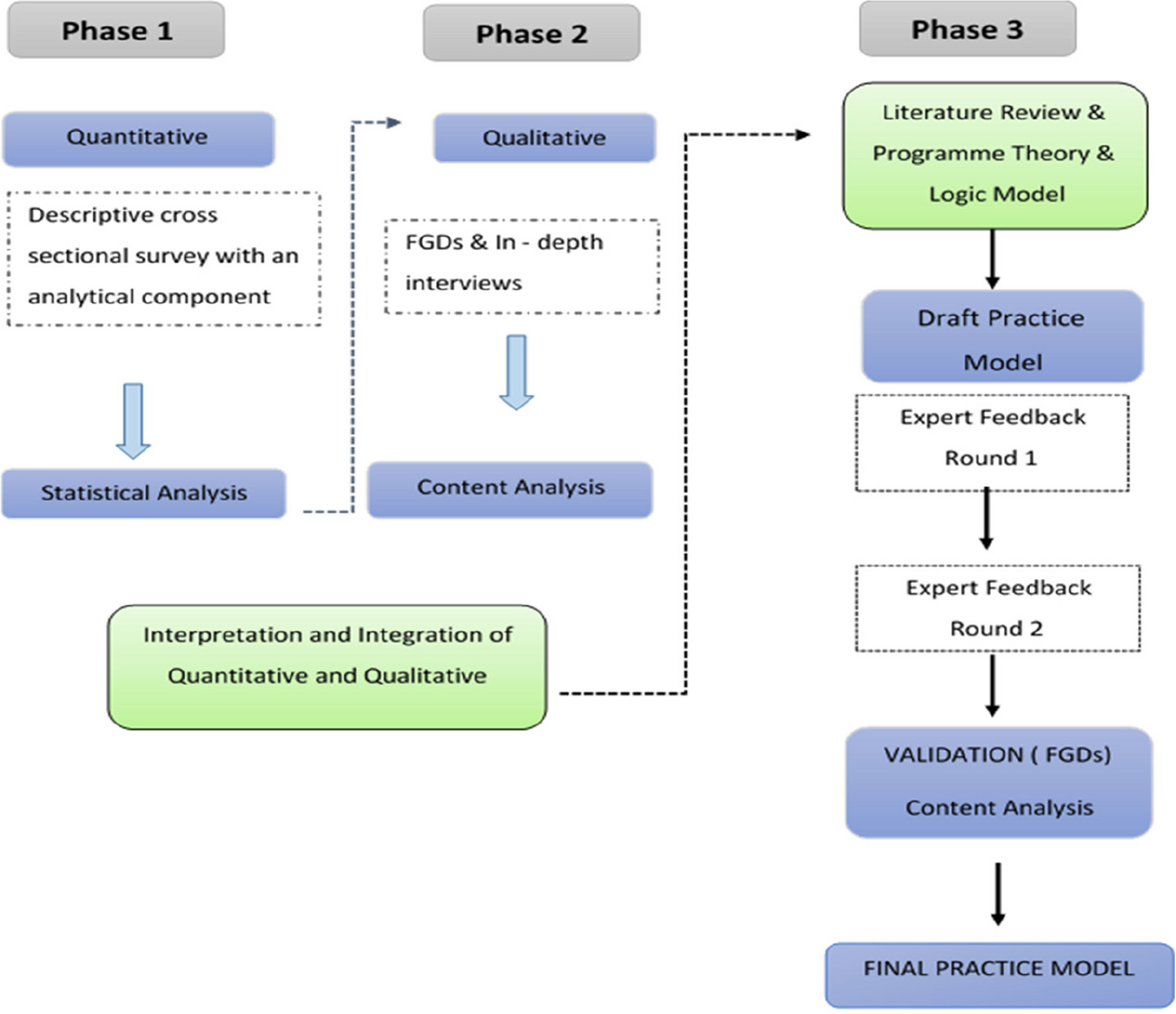
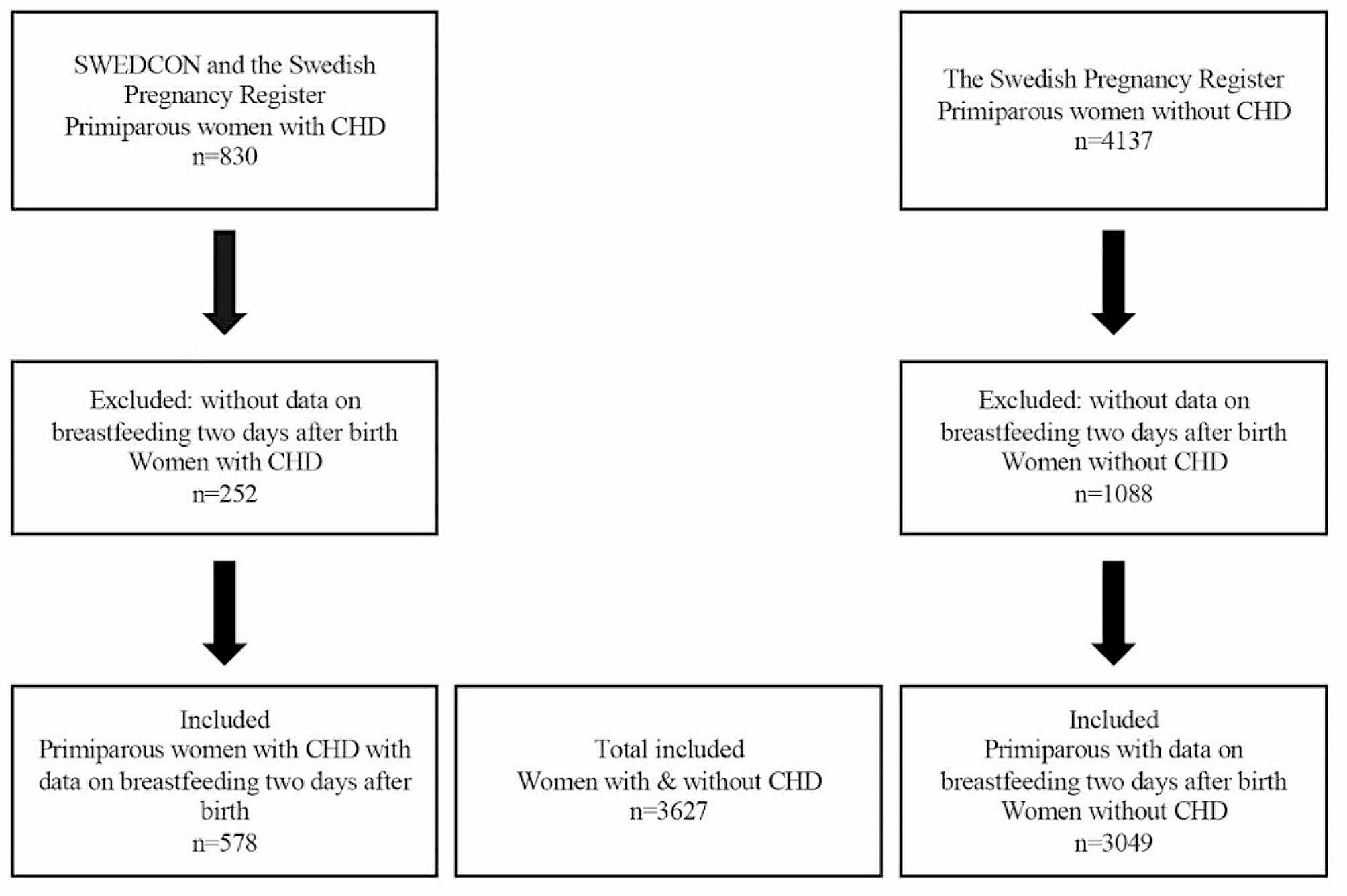
To translate the BMS into Chinese and assess its psychometric properties among Chinese mothers during the postpartum period, the study was conducted in two phases: (1) comprehensive translation, back-translation, cross-cultural adaptation, and pretest; and (2) reliability testing, such as testing of the internal consistency and test–retest reliability following translation and the content validity, construct validity, and convergent and discriminant validity. The flow chart of the study procedures is shown in Fig. 1.
Fig. 1
Flow chart of the study procedures
Ethical considerationsWritten permission was obtained via email from Ariel University (Israel) Lecturer Miri Kestler–Peleg, the author who developed the original version of the BMS. The study was approved by the Human Research Ethics Committee of Shanghai First Maternity and Infant Hospital in Shanghai, China (No. KS22340 from 1 December 2021). The study complied with the ethical principles of the World Medical Association Declaration of Helsinki principles.
ProceduresPhase 1-Translation, back-translation, cross-cultural adaptation and pilot applicationThe final English version of the BMS was clarified with the author via email. The translation of the BMS closely followed the guidelines of the principles of good practices for translation and cultural adaptation of measures established by the International Society for Pharmacoeconomics and Outcomes Research (ISPOR) [26]. Phase 1 involved four steps. Step (1) Translation: Two bilingual native Chinese speakers who were also fluent in the English language were asked to independently translate the English version of the BMS and the accompanying instructions provided with the scale from the English to Chinese language. The two translators were a Ph.D. in nursing who worked in the US and a Ph.D. in obstetrics who had returned from studying in the US. The two translations were then assessed by two native Chinese speakers online, who reached a consensus on any discrepancies to produce a single translated scale in Chinese named Chinese version 1 of the BMS. Step (2) Back-translation: Two translators with knowledge of both the Chinese language and culture independently back-translated the Chinese version 1 of the BMS to English. The two translators were a Ph.D. in obstetrics and gynecology nursing who studied and worked in the United States and an English teacher from a popular university in the U.S. The two translators discussed the discrepancies of the back-translation and reached a consensus. Then, they synthesized the details of the back-translation to produce a single back-translated scale in English, which was named the back-translation version 1 of the BMS. The researchers sent the Chinese version 1 of the BMS and the back-translated version 1 of the BMS to the original author of the BMS to ask for his advice. The original author proposed changes in three items of the scale, and two modifications (“among us” represents the closest circle in item 3 and only mothers can breastfeed the baby in item 10) were made based on the author’s advice. Then, we reached a consensus to produce Chinese version 2 of the BMS. Step (3) For cross-cultural adaptation, five experts who majored in obstetrics and were skilled at translation (a nursing specialist familiar with cross-cultural adaptation, a nursing management specialist, an obstetric nursing specialist, an obstetrical clinician and an international board-certified lactation consultant) were invited to evaluate the accuracy of the translation, whether the translated version was clear and easy to understand, and whether it was consistent with the cultural background of Chinese people. The experts rated each item on a 4-point Likert scale ("very relevant" = 4, "relevant" = 3, "not very relevant" = 2, "not relevant at all" = 1). They provided few comments, and no further modifications were needed. Then, Chinese version 3 of the BMS was produced. Step (4) To perform an initial evaluation and to assess the understanding of the Chinese version 3 of the BMS in the Chinese population, a small sample pilot study was conducted. Twenty-five native-Chinese-speaking mothers were recruited after labor at the hospital according to the inclusion and exclusion criteria to fill out a sample scale (Chinese version 3 of the BMS). Cognitive interviews were also conducted to collect modification suggestions from respondents. Cognitive interviews are a common method used to pretest whether survey questions are understandable and answerable. The 25 mothers were encouraged to describe their thoughts while answering the scale questions, which could be done through think aloud, verbal probing, and paraphrasing methods, etc. [27]. We developed a semi structured interview guide to collect further information about the scale from the women. The interview questions were as follows: Can you repeat this question in your own words? What does that word mean to you? Tell me more about your thinking when you think about the question. Are there questions you believe should be modified? Why? What do you think the word in ‘...’ could be adjusted to make the question more understandable? Are there questions you believe should be deleted? Why? Any other questions? The interviews were recorded via audio, were held in the meeting room of the ward and were conducted by an investigator who was trained in cognitive interviewing. Then, the translation team modified Chinese version 3 of the BMS according to the interview content, which the investigator summarized after the interviews. Generally, respondents reported that the sample scale could not be misunderstood, and four slight changes of items were made after the interviews (see Table 1 for the modifications made after the interviews). Finally, Chinese version 4 of the BMS was formed. This was the final Chinese version of the BMS before psychometric property testing. We call Chinese version 4 of BMS ‘the Chinese version of the BMS’ below.
Table 1 Modifications made to create the Chinese version of the BMS after cognitive interviewsPhase 2 – Testing of the psychometric properties of the Chinese version of the BMSAfter obtaining permission to carry out the study from the human research ethics committee of Shanghai First Maternity and Infant Hospital, we oriented the investigators and registered nurses working in Shanghai First Maternity and Infant Hospital to clarify the details of the survey, including the team members, survey tools, time, communication method, data collection methods, and so on. The questionnaires were administered to the mothers from 1 December 2021 to 1 July 2022. To avoid affecting the clinical work of the hospital and the nonparticipating mothers, we collected the questionnaires from 3:00 to 5:00 p.m. to reduce the possibility of survey interruption and to reduce the number of invalid questionnaires. Before the survey began, the investigators explained the study protocol to the mothers again. The mothers were instructed on how to understand the questionnaires and how to complete them.
The questionnaires were collected and checked by the investigators on site, i.e., in the maternity wards. The mothers completed an online version of the self-administered questionnaires. The mothers were asked to scan a QR code to fill out the questionnaire, and all responses were anonymous. It took approximately 15 min to complete the questionnaire, and this amount of time was assessed as adequate. Twenty mothers were randomly selected to answer the Chinese version of the BMS twice, with second time being 2 weeks after the first to assess the test–retest reliability during the postpartum 2-week visit. This 2-week duration was proposed by Stewart and Bass because it is difficult to affect a person's memory and practice in 2 weeks [28]. The participating mothers’ telephone numbers and gestational age were recorded when the data were collected for the first time. We invited the five experts for the two rounds of expert consultation to test the content validity as mentioned above. All experts had bachelor's degrees or above.
Statistical analysisStatistical analyses were performed using Excel, SPSS 24.0, and Amos 22.0. Reliability was assessed in two ways: test–retest reliability and internal consistency. It was important to ensure that the assessment reflected the mothers’ true breastfeeding motivation. Test–retest reliability was assessed by item-by-item testing. The instrument was reapplied in approximately 10% of the sample 2 weeks later. The intraclass correlation coefficient (ICC) was calculated. The closer the ICC of the scale is to 1, the higher the stability of the scale is, indicating that the instrument is more reliable. The ICC was ≥ 0.75, indicating that the test–retest reliability of the scale was good. The internal consistency of the scale was analyzed with Cronbach’s α. Values ≥ 0.70 are considered acceptable [29]. Content validity was tested using a content validity index, including scale-level CVI (S-CVI) and item-level CVI (I-CVI). These items were revised and supplemented through two rounds of expert consultation above to verify the content validity. Confirmatory factor analysis (CFA) was employed to analyze the construct validity, convergent validity and discriminant validity. The suitability of the dataset was verified through the Kaiser‒Meyer‒Olkin measure (KMO) (> 0.50) and Bartlett’s test of sphericity (P < 0.05). The parameters were carried out using the maximum likelihood estimation method [30]. The goodness of fit of the model was evaluated using the following statistics and the minimum standards of indices: (a) the standardized χ2(CMIN/df) (chi-square mean/degree of freedom) should be lower than 3.0 [31], (b) the root mean square error of the approximation (RMSEA) should be lower than 0.1 [32], and (c) the comparative fit index (CFI), incremental fit index (IFI), and Tucker-Lewis index (TLI) should all be ≥ 0.90 [31, 33]. Convergent validity refers to the similarity of measurement results when using different measurement methods to measure the same goal. Convergent validity was evaluated by the average variance extracted (AVE) and composite reliability (CR). Discriminant validity means that the observed values should be distinguishable from each other when measuring different indicators. The discrimination validity is generally tested by comparing the AVE square root with the phase relation value. The level of significance was set at < 0.05.
留言 (0)