
記住我
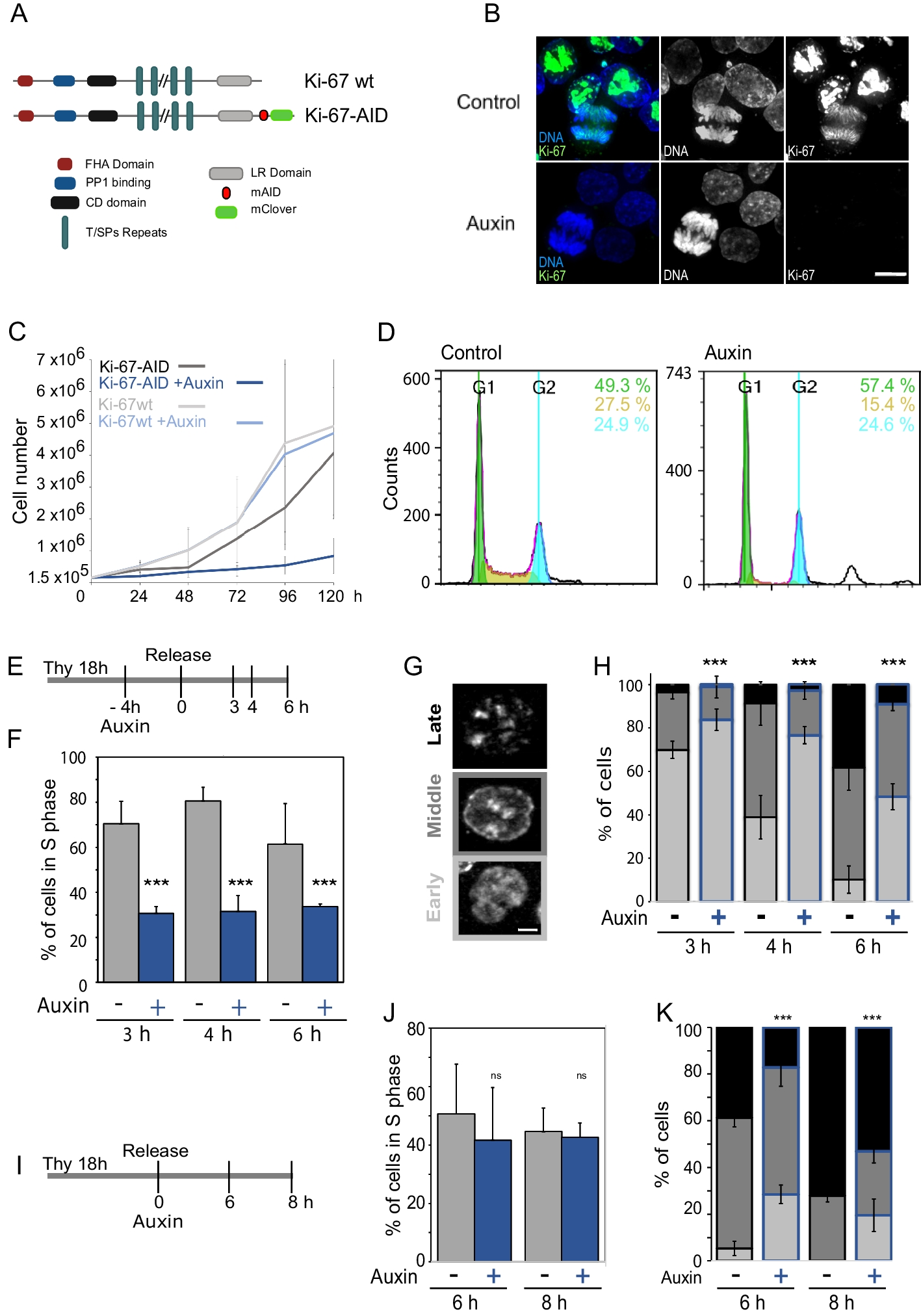







The results presented below are obtained by applying mutscan and other tools (Table 1) to four deep mutational scanning data sets (Table 2). These data sets represent a variety of typical MAVE experimental designs and have been previously used for evaluation purposes [20].
Table 2 Overview of deep mutational scanning data sets used in this studyOverview of the mutscan workflowmutscan is implemented as an R package, with core processing modules written in C++ for efficiency. Figure 1B, C provides an overview of the full analysis workflow (for more details about the individual steps, see the “Methods” section). The first part of the workflow processes each sequencing library independently. Hence, additional samples can easily be added to an experiment without the need to re-process the existing samples. In this step, reads that do not adhere to the user specifications (e.g., too low base quality, too many or forbidden mutations compared to a provided wild-type sequence) are filtered out, and the remaining ones are used to tabulate the number of reads (or unique UMI sequences, if applicable) corresponding to each observed sequence variant. For increased processing speed, this step can be parallelized. In the second part, the output from all samples in the experiment is combined into a joint SummarizedExperiment object [26], containing the merged count matrix, a summary of the filtering applied to each individual sample, and additional information about the detected variants, such as the nucleotide and amino acid sequence; the number of mutated bases, codons, and amino acids; and the type of mutations (silent, non-synonymous, stop). Finally, the merged object can be used as the input to functions generating diagnostic plots and reports, as well as statistical analysis functions that estimate log-fold changes and find variants that are increasing or decreasing significantly in abundance during the selection process. Since the data is represented as a SummarizedExperiment object, it can also be directly used as input to a wide range of analysis and visualization tools from the Bioconductor ecosystem [27].
Case study: evaluating interaction strength between FOS and JUN variantsTo illustrate the practical use of mutscan, we reprocess the “trans” data set from [6]. Here, libraries of single amino acid mutants of FOS and JUN’s basic leucine zipper domains were constructed by oligonucleotide replacing each codon by one of the 32 codons ending with a C or a G (encoded by NNS in the IUPAC code [28]). The two libraries were then cloned together on the same plasmid to measure the effects of combining one mutation on each partner on the protein–protein interaction (PPI) between FOS and JUN. The interaction was scored by deepPCA [6], which couples protein–protein interaction to the growth rate in a typical MAVE setting. A rendered report detailing the full analysis can be found in Additional file 1. The data set contains three replicates, each with an input and an output sequencing library (before/after the selection assay, respectively). As indicated above, we start by processing each of the six FASTQ files separately with the digestFastqs() function from mutscan. This step extracts the sequences of the variable regions corresponding to the FOS and JUN variants from the paired reads, compares them to the provided wild-type sequences and identifies the differences, and tabulates the number of reads and unique UMIs for each identified variant combination. Since the variable regions of the forward and reverse reads correspond to variants of different proteins encoded at two different loci and do not share any common sequence, we instruct digestFastqs() to process them separately rather than attempting to merge them. This also allows us to submit separate wild-type sequences for the variable regions in the forward and reverse reads. We retain only reads with at most one mutated codon in each of the two proteins.
The output of this initial processing step is a list for each sample, containing a count table, a filtering summary, and a record of the parameters that were used (Fig. 1B). While these objects can be explored as they are, it is more convenient to merge them into a joint SummarizedExperiment [26] object for downstream analysis (Fig. 1C), which is done via the summarizeExperiment() function in mutscan. The resulting object contains a matrix with the UMI counts for all variants in all six samples, as well as a summary of the number of reads filtered out at each step, and any metadata provided for the samples (replicate ID, condition, optical density, etc.), and feeds directly into the diagnostic plot and statistical analysis functions in mutscan, including plotPairs() and plotFiltering(), the outputs of which are shown in Fig. 2. We observe that, as expected, we find more unique variants with multiple base mutations, but the observed abundance of individual variants with multiple mutations is markedly lower than for variants with no or a single mutated base (Fig. 2A, B). Using mutscan to visualize the filtering process further illustrates that across all samples, the main reasons for read pairs being filtered out are that they contain an adapter or that they contain more than the allowed number of mutated codons (Fig. 2C, D).
Fig. 2
Results from the mutscan re-analysis of the FOS/JUN protein interaction data set from [6]. A The number of variants detected with different numbers of mutated bases. B The average abundance of variants with different numbers of mutated bases. While a larger number of different variants with two or more mutations are observed, these are generally much less abundant than variants with no or a single mutated base. C, D Diagnostic plots of read filtering performed by digestFastqs(). In this data set, the main reasons for filtering out read pairs are that they either contain an adapter sequence or that the number of mutated codons exceeds the defined threshold of maximum one mutated codon per protein. E Pairs plot displaying the concordance of the observed counts across the six samples. Generally, high correlations are observed between the three input samples as well as between the three output samples, indicating good robustness of the measurements. The correlation between the input and output samples is considerably lower, reflecting the impact of the selection. F Heatmap showing the estimated protein–protein interaction score for all single-amino acid variants of each of the two proteins. Red color indicates an increased interaction, while blue signifies decreased interaction
Next, we use mutscan to investigate the concordance among the six samples, by plotting the estimated variant counts (Fig. 2E). As expected, the correlation within each type of sample (input/output) is considerably higher than the correlation between input and output samples, indicating that the selection step indeed influences the sample composition.
After the initial quality assessment, we use mutscan to summarize the counts for variants with the same amino acid sequence. From this matrix, we then estimate a protein–protein interaction score for each variant and replicate, indicating the effect of the variant relative to the wild-type sequence as described by [6]. Focusing only on variants with a mutated amino acid in either FOS or JUN (but not both), we can generate a heatmap summarizing the impact of each single amino acid mutation on the overall interaction score (Fig. 2F). These heatmaps serve as the basis for interpreting the mechanisms by which mutations impact the molecular activity studied. For instance, as was observed in the original paper [6] for this data set, positions crucial for heterodimerization are highly sensitive to mutations. Any substitution of the leucine at positions 4, 11, 18, and 25, which form the hydrophobic core of the interaction interface, is detrimental. Positions involved in salt bridge formation across the interface, for instance, between position 21 in Fos and position 26 in Jun, are also typically detrimental for heterodimer formation, although the magnitude of the effect is lower than at core positions. The heatmap can also reveal positions where the wild-type appears sub-optimal, such as position 8 in Fos where substitution of the hydrophilic wild-type threonine by more hydrophobic amino acids leads to an increase in interaction score, as one would expect for a position at the hydrophobic core of the interface. The presence of this sub-optimal residue in the wild-type sequence might thus result from an evolutionary trade-off with other properties of Fos, such as interaction with other partners.
mutscan enables processing flexibilityThe digestFastq() function in mutscan, which performs the initial processing of each individual library, is designed to provide flexibility in the sample processing, thereby enabling the analysis of a wide range of library designs, not limited to MAVE experiments. Here, we highlight some of the main features.
Processing of single- or paired-end reads with arbitrary composition of basic elements: mutscan accepts FASTQ files from both single-end and paired-end experiments. In addition, a vector of (pairs of) FASTQ files can be provided, and these will be internally concatenated. If some part of the variable regions of the forward and reverse reads is shared, e.g., if they correspond to overlapping parts of the same protein, the reads in a pair can be merged before further processing. The size of the overlap can be anywhere between a single base and the length of the whole read, and restrictions on what constitutes a valid overlap can be specified by the user. For each read, the user further specifies the sequence composition in terms of five element types (see Box 1): variable regions (typically the sequences of interest), constant regions, skipped regions, primers, and UMIs. Each read can contain multiple (adjacent or nonadjacent) regions of each element type except primers, and the lengths of the regions can be defined by the user or automatically inferred by mutscan. This design provides an intuitive interface for the user and implies that many different types of experiments can be analyzed within the same framework. Moreover, processing parameters and read compositions are specified separately for the forward and reverse reads, which allows direct processing of constructs with multiple variable regions, e.g., corresponding to different proteins.
Sequence-based analysis or comparison (or collapsing) to one or more wild-type sequences: mutscan allows the optional specification of one or more wild-type sequences, against which the extracted variable regions will be compared. If more than one wild-type sequence is provided, mutscan will find the most similar one for each read, and match the read against that. The variant identifiers used by mutscan consist of the name of the most similar wild-type sequence, augmented with the observed deviation(s). For example, an identifier of the form GENEX.10. A indicates that the closest wild-type sequence was that of GENEX, and the observed read deviated from this wild-type sequence in that the tenth base was an A, rather than the reference base. It is also possible to collapse all variants to their closest reference sequence, if the mutations are not of interest. If no wild-type sequence is provided, mutscan represents each identified variant by its actual nucleotide sequence.
Codon- or nucleotide-based analysis: mutscan allows the processing of both coding and non-coding sequences. If wild-type sequences are provided, the user can choose to limit either the number of mutated bases or the number of distinct mutated codons that are allowed in the identified variants. This choice will further impact the naming of the variants (in terms of the codon or nucleotide deviations from the closest wild-type sequence).
Collapsing of similar sequences: If no wild-type sequences are provided, the user has the option to collapse variants (unique variable sequences) with at most a given number of mutations between them. The collapsing is done in a greedy way, starting from the most abundant variant, and can be limited to only collapsing variants with a large enough abundance ratio.
Processing only a subset of the reads: For testing purposes, it is often useful to process only a small subset of the reads. mutscan allows the user to limit the processing to the first N reads in the FASTQ file, where N is specified by the user.
Various filtering criteria: mutscan implements a range of filtering criteria, including the number of “N” bases in the variable and/or UMI sequence, the number of mutations in the constant and/or variable sequence (if a reference sequence is provided), the base quality of the identified mutations and/or the average base quality in the read, the presence of forbidden codons (specified using IUPAC code), or the invalid overlap between forward and reverse reads for merging. The output object contains a table listing the number of reads filtered out by each of the criteria.
Export of excluded reads (with a reason for exclusion) to FASTQ files for further investigation: In cases where reads are filtered out for any of the reasons listed above, it may be helpful to be able to process these further. mutscan can write reads that are filtered out to a (pair of) FASTQ file(s), including the reason for exclusion in the read identifier.
Estimation of sequencing error rate: If the input reads contain a constant region, mutscan estimates the sequencing error rate by counting the number of mismatches compared to the expected sequence across the reads. The error rate is further stratified by the base quality reported in the FASTQ file.
Nucleotide- or amino acid-based analysis: The main output from digestFastqs() is represented in base or codon space. However, the corresponding amino acid information is recorded, and the count matrix can easily be collapsed on the amino acid level. In addition, mutscan reports the type of mutations (silent, non-synonymous, stop) present in each variant.
Flexible analysis frameworks: The statistical testing module in mutscan is based on established packages for the analysis of digital gene expression data (edgeR [29] and limma-voom [30]). Both tools allow the user to specify an arbitrary (fixed-effect) design and thus provides excellent flexibility for testing complex hypotheses, not limited to paired comparisons of input and output samples. Moreover, several different normalizations are available, allowing calculation of both “absolute” and “relative” log-fold changes (e.g., changes relative to a wild-type reference).
Box 1 Read componentsmutscan requires the user to specify the composition of the input read(s) in terms of the following five component types:
- Variable regions (V): these are typically the regions of interest. If one or more wild-type sequences are provided, the variable regions will be compared to those to identify variants. If no wild-type sequences are provided, the sequence of the variable region will be used to represent the variant
- Constant regions (C): these regions are used to estimate the sequencing error rates. Reads can also be filtered out if they have too many mutations in the constant region
- Skipped regions (S): these regions will be ignored in the processing
- Primers (P): a primer sequence differs from a constant region by the fact that it is not required to occur in a pre-defined position in the read. Instead, mutscan will search the read for a perfect match for the primer sequence
- UMIs (U): these sequences will be used to correct PCR amplification biases. If present, the output count table will contain, for each variant, both the number of reads and the number of unique associated UMIs
For example, an experiment where the reads have the following composition:
[1 skipped nt] − [10 nt UMI] − [18 nt constant sequence] − [96 nt variable region]
would be specified to digestFastqs() by an element string “SUCV” and an element length vector c(1, 10, 18, 96)
For a library design with a primer sequence, the primer acts as an “anchor,” and the read composition before and after the primer is specified. For example, reads with the following composition:
[unknown sequence] − [10 nt primer] − [variable region, constituting the remainder of the read]
would be represented by an element string “SPV” and an element length vector c(-1, 10, -1), where the -1 indicates that the corresponding read part consists of the remaining part of the read, not accounted for by any of the other specified parts
mutscan controls the type I errorTo evaluate whether the statistical approaches employed by mutscan are able to control the type I error rate at the expected level, we designed a null comparison for each of the example data sets. Briefly, we assigned approximately half of the replicates to group “A,” and the rest of the replicates to group “B,” and tested, for each variant, whether the output/input count ratio was different between the two artificial groups. The procedure was repeated for all possible assignments of the replicates to two approximately equally sized groups. Overall, the nominal p-value distributions from mutscan, using either edgeR and limma as the inference engine, were largely uniform, indicating that the tests are well calibrated (Fig. 3).
Fig. 3
mutscan p-value distributions for null comparisons. For each data set, repeated null data sets were generated by artificially splitting the replicates into two approximately equally sized groups. For each such artificial null data set, mutscan (with the method set to edgeR and limma, respectively) was used to fit a model and test whether the log-fold change between input and output samples differed significantly between the two artificial groups. The colored densities represent the individual data splits, while the dark gray density represents the union of p-values from all data splits. Since the groupings are artificial, uniform p-value distributions are expected. While technical differences among the samples, and the low sample size in general, imply that not all comparisons provide exactly uniform p-value distributions, we do not observe a systematic bias in the p-values from mutscan. Only variants with more than 50 counts in all input samples were considered for this analysis. The number of retained features is indicated in each panel
mutscan is computationally efficientIn order to evaluate the computational efficiency of mutscan (v0.2.31), we applied it to the four example data sets and used the benchmarking capabilities of snakemake [31] to track CPU and memory usage as well as the volume of data input and output. We also ran DiMSum v1.2.11 (on all data sets) and Enrich2 v1.3.1 (for the Diss_FOS data set only, due to the long execution time), attempting to set the parameters of the different tools in such a way that the similarity between the performed analyses would be maximized (see the “Methods” section). We evaluated the entire process, from raw FASTQ files to output tables and additionally included the generation of the summary report where applicable.
For all data sets, the total execution time for mutscan was lower than for DiMSum (Fig. 4), and both of these finished in less time than Enrich2. The distribution of time spent in the different stages varied across data sets as the processing time for individual samples is largely determined by the number of reads, while the time required to perform statistical tests and generate plots for quality assessment is rather dependent on the number of identified and retained variants. The same effect is seen for the memory consumption. Only a small amount of memory is required for the initial sample processing by mutscan, while the memory required for the later analysis and statistical testing depends on the number of retained variants, and thus, the size of the count matrix that needs to be loaded into the R session for processing. We also note that, apart from reading the FASTQ files, the total volume of input and output data for mutscan is very low, as the whole sample processing is performed by a single function that traverses the input files only once and without the need to create intermediate files on disk for transfer of data between different software tools. The total runtime of DiMSum, which is reading and writing much larger volumes of data to disk, also likely depends more strongly on the performance of the storage system. Another consequence of mutscan’s design is that a larger fraction of the time is spent on actions that are parallelizable, which can be seen by its higher average CPU load (400–600% for mutscan when run with 10 cores, compared with 100–200% for DiMSum with 10 cores). Enrich2 is not parallelizable and thus exhibits a constant load of 100%.
Fig. 4
Comparison of computational performance metrics for mutscan, Enrich2, and DiMSum. Generally, mutscan processes the included data sets faster and with a lower memory footprint than competing methods. In addition, only small amounts of data are being read from and written to disk during the processing. The digestFastqs() metrics for the Li_tRNA_sel30 data set are averaged across the five runs on the single input sample, since only one run is required for mutscan. Total I/O volumes are separated in input and output, indicated above by I and O, respectively. RSS, resident set size
While the evaluations mentioned above were all run with 10 cores, we also investigated how the key performance parameters scaled with the number of cores provided to mutscan when running the digestFastqs() function on a single pair of FASTQ files (Additional file 2: Fig. S1). The results suggest that while the average load increases linearly with an increasing number of cores, indicating good scalability of the parallel parts of the code, the benefit in terms of decreased total execution time is significantly reduced when more than 10 cores are used. This is likely explained by the constant runtime consumed by the serial parts in the code. In addition, for a fixed number of cores, the raw data processing performed by digestFastqs() scales linearly with the number of input reads in terms of execution time and close to linearly in terms of memory requirement (Additional file 2: Fig. S2).
mutscan counts and log-fold changes are comparable to those from Enrich2 and DiMSumIn order to further compare the return values of mutscan to those obtained from DiMSum and Enrich2, we contrasted the sets of variants identified by the different tools. In addition, we chose a representative sample for each of the data sets and contrasted the estimated counts for all variants identified by at least one tool (Fig. 5, Additional file 2: Fig. S3-S10). As previously described, we attempted to set the parameters of each tool in such a way as to maximize the similarity between the analysis workflows (see the “Methods” section). In general, most variants with up to two mutations (bases or amino acids, depending on the data set) were detected by all methods (Additional file 2: Fig. S3, S5, S7, S9). The variants that were found with only one of the tools also generally had a lower abundance than the variants found consistently with all tools.
Fig. 5
Comparison of counts estimated by mutscan, DiMSum, and Enrich2. For each data set, a representative sample is shown (indicated in the respective figure titles, together with the data set). In general, the counts estimated by the three methods show a high correlation, and deviations are likely explained by differences in aspects such as how the set of allowed or forbidden mutations is specified, how the filtering of low-quality sequences is implemented, and whether mismatches or partial matches are allowed in the specified primer sequence
Also, when comparing the estimated counts for the variants between the tools, we noticed a high degree of similarity, but also data set-specific differences. For the Diss_FOS_JUN data set, we hypothesize that one reason for the generally higher counts observed with DiMSum than with mutscan is the different way in which the allowed codon mutations are specified. More precisely, with mutscan we are defining the format of any forbidden mutated codon (in our case, IUPAC code “NNW”). DiMSum, on the other hand, approaches this by specifying the allowed IUPAC code for each position in the entire variable sequence. Hence, with this setup, mutated codons that already end in a “T” or an “A” in the wild-type sequence will not disqualify the read from being included in the analysis. The shift from the diagonal line in the Bolognesi_TDP43_290_331 data set may be caused by the differences between approaches in mutscan and DiMSum for detecting the primer sequence immediately preceding the variable sequence. While DiMSum utilizes cutadapt to trim the unwanted sequence, mutscan requires a perfect match to the specified primer sequence whenever its position in the read is not fully specified.
Similarly to the sets of detected variants, the correlation between the estimated counts from the different tools also decreased as the number of mutations in the variant increased (Additional file 2: Fig. S4, S6, S8, S10).
Finally, we calculated enrichment scores using the three tools (Fig. 6). For mutscan, we evaluated both built-in frameworks, based on limma-voom and edgeR, respectively. The log-fold change of a variant relative to that of the wild-type (obtained by using the latter as a replacement for the library size in the offset/normalization steps of edgeR/limma) is used as an enrichment score for mutscan and compared to the returned enrichment score from DiMSum (called “fitness score” in DiMSum), and the average of the sample-wise scores from Enrich2. As for the variant counts, we see a strong correlation between the enrichment scores from the different methods. This corroborates findings from [32], where DiMSum’s enrichment scores were found to be highly correlated with log-fold changes calculated using DESeq2 [33] on the same count matrix. As for the detected variants, the correlation between the enrichment scores is much stronger for variants with only a single mutation and decreases as the number of mutations increases (Additional file 2: Fig. S11-S14), possibly due to the lower absolute counts observed for variants with more mutations. It is worth noting that the data set with the lowest correlation among the enrichment scores (Bolognesi_TDP43_290_331) is also the one where the correlations between the DiMSum enrichment scores for the individual replicates are the lowest (Additional file 2: Fig. S15). Again, most of the discrepancies are contributed by variants with more mutated bases (Additional file 2: Fig. S13).
Fig. 6
Comparison of enrichment scores estimated by mutscan, DiMSum, and Enrich2. For mutscan, the values are logFCs estimated by either edgeR or limma. For DiMSum, they correspond to the enrichment score derived from all replicates. For Enrich2, they are the averages of the scores for the replicates. The lower correlations seen in the Bolognesi_TDP43_290_331 data set, and to some extent, the Diss_FOS_JUN data set reflect the less stringent variant filtering criteria used in these data sets (up to 3 mutated bases for Bolognesi_TDP43_290_331 and up to two mutated codons for Diss_FOS_JUN, see the “Methods” section). Considering only variants with fewer recorded mutations leads to higher correlations, more comparable to the Diss_FOS data set where only up to two mutated bases were allowed (Additional file 2: Figs. S11-S14)
留言 (0)